字体元数据
文件的元数据
让我们从共同的元数据定义开始,然后理解其对字体的含义。
文件的元数据是有关与文件或单独数据库一起存储的文件的信息。此信息包括有关文件格式,创建日期,作者,位置,大小和其他属性的详细信息。元数据还可以包括有关文件内容的信息,例如关键字,标签和描述。
您可以在设备上看到一些元数据(请参见下图)。这对于管理和组织文件很重要,因为它允许您依赖于不同条件的搜索,过滤和排序文件。例如,通常会根据创建文件的日期来安排文件夹的内容。或者在某些情况下,您可能需要按字母顺序排列文件。软件应用程序还将元数据用于正确显示和操纵文件,以及操作系统以索引和搜索计算机上的文件。
什么是字体元数据?
字体元数据是指有关字体文件本身嵌入的字体的信息。这是字体名称,设计师名称,字体版本编号,版权信息和字体使用限制之类的信息。某些文件还可以包括字体的字符集,其编码和指标信息。这些数据有助于定义字体放置在文本中的方式,对于字体识别,许可和管理很重要。字体元数据通常由软件应用程序使用,以正确显示和操纵字体。
字体元数据的类型
字体元数据可以包括各种类型的信息。这是表中分组的列表:
| 类型 | 描述 |
|---|---|
| 字体名称 | PostScript 语言中用于引用特定字体的唯一标识符。它通常是字体全名的缩写,长度限制为 29 个字符。此度量标准用于在 PostScript 文档中标识字体,通常在嵌入或勾勒字体轮廓时需要用到。 |
| PostScript 名称 | PostScript 语言中用于引用特定字体的唯一标识符。它通常是字体全名的缩写,长度限制为 29 个字符。此度量标准用于在 PostScript 文档中标识字体,通常在嵌入或勾勒字体轮廓时需要用到。 |
| 字体系列 | 简而言之,它是一组具有相似特征(例如粗细、样式和宽度)的相关字体。 |
| 字体样式 | 它将字体分为常规、斜体、粗体或粗斜体。 |
| 字体粗细 | 它代表字体的粗细或重量,从细到粗。 |
| 字体宽度 | 字体的相对宽度,从压缩到扩展。 |
| 字体设计师 | 创建字体的个人或公司的名称。 |
| 制造商名称/字体铸造厂 | 创建或分发字体的公司名称。 |
| 字符集 | 字体支持的字符集,可以包括字母、数字、符号和标点符号。 |
| 字形数量 | 有关字体中 字形数量的信息。 |
| 字体版本 | 字体的具体版本或发行版。 |
| 字体格式 | 字体存储的文件格式,例如 TTF、WOFF、Type1 等。 |
| 字体许可信息 | 此信息分为许可证说明和许可证信息 URL。许可证说明解释了字体的使用条款和条件。它可能因 许可证类型 而异。 |
要查看文件中包含的所有元数据,您可以使用特定的软件或跨平台应用程序,例如Aspose在其生态系统中具有的。 字体元数据查看器现在让您获得有关TTF,Woff和Woff2字体的信息。
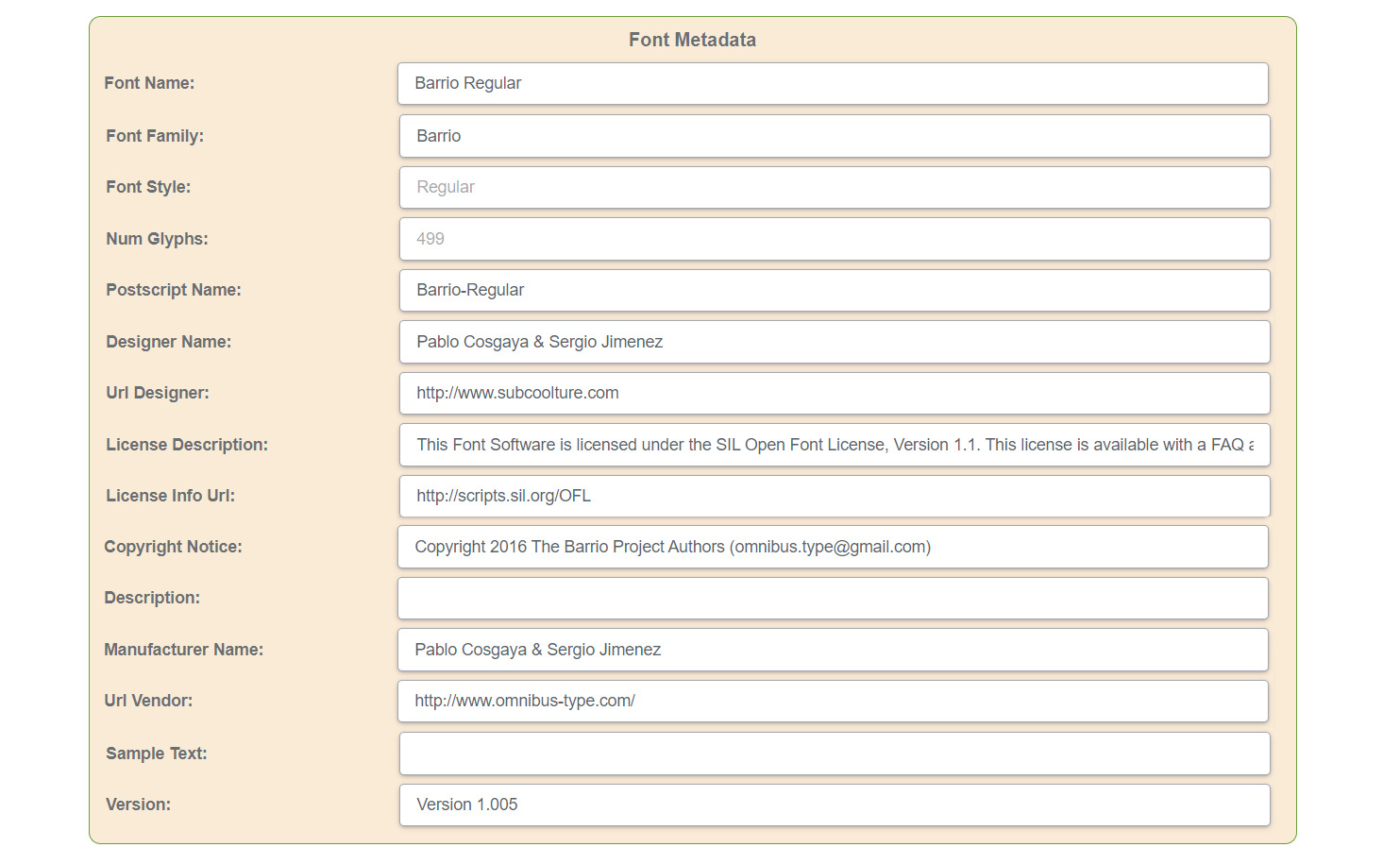
使用字体元数据
字体元数据用于提供有关字体的其他信息,而不仅仅是其设计和外观。它包括不同的通用信息以及技术细节。 但是,所有这些信息的重点以及如何使用呢?
- 版权和许可。 - 字体元数据可以包括有关字体许可证的信息,例如它是免费的商业用途还是需要付款或归因的信息。它提供了许可证说明,许可证和版权信息,可用于确保字体在合法和适当地使用。
- 正确的字体标识。 - 提供有关字体的信息,例如其名称,设计器,铸造厂和版本号字体元数据,有助于确保正确识别和使用该字体。
- 语言支持是元数据的另一个例子,可以有用。您可以在包含哪些字形集的信息中找到它。
- 可搜索性。 - 用户使用某些元数据根据不同标准(例如样式,重量或设计师)对字体进行分类和组织字体。这使得在需要时更容易搜索并进入正确的字体。
- 可访问性。 - 字体元数据可能包括有关字体的可读性和可读性的信息,这对于视觉障碍者可能很有用。- 支持非拉丁蛋白符号。 - 字体元数据可以包括有关语言支持和字体范围的信息。 如果您有一个多语言项目,则可以使用此类数据,其中包含使用非拉丁语脚本的语言,例如阿拉伯语,中文或印地语。在这种情况下,此元数据可以帮助您做出正确的选择。
- 字体文件的大小。 - 如果您查看显示字体中字形数量的元数据,则还可以理解此文件是否适合您的项目,因为其中越重的字形文件越重。 Big Overloaded Font文件不仅占用太多空间,而且管理可能会凌乱。 总体而言,字体元数据在帮助设计师,开发人员和用户以更高效和有效的方式来管理和使用字体上起着重要作用,并有助于确保字体得到正确识别,可访问和合法和适当的使用。
操作系统如何使用字体元数据?
已经解释了使用字体元数据的方式,因此让我们看看操作系统如何使用它来实现上述功能。
- 正确的字体标识 - 用户选择字体时,操作系统会读取元数据以确定如何渲染它。有关字体文件的特性和属性的信息,例如字体家族,样式,重量和大小,有助于操作系统确保字体在不同的应用程序和设备上始终显示。
- 版权和许可。 - 字体创建者在字体元数据中嵌入版权和许可信息。它为用户提供了使用该字体的法律框架。该数据允许操作系统验证该字体是否正确许可并防止其未经授权的分布或使用。
字体文件格式(例如Opentype和TrueType)也支持数字权利管理功能。 DRM功能使用元数据来执行许可限制,并可以限制具有访问字体的设备或用户的数量,防止字体嵌入文档中,并将字体的使用限制在特定的应用程序或平台上。
标准化字体元数据
字体元数据标准是一组指南和规格,以定义字体文件中应包含的信息和数据。字体有几种不同的元数据标准,包括Opentype,TrueType和Postscript字体。他们每个人都有自己的特定要求和格式。
Opentype字体的元数据标准
Opentype字体的元数据标准称为Opentype字体文件规范。它包括有关如何包含可以存储在字体文件本身中的元数据的指南,并在字体旁边的单独文件中或嵌入在字体的数字签名中。
Opentype字体文件规范还描述了字体如何包含有关其功能和功能的其他信息。此信息存储在字体文件中的单独表中,称为Opentype布局表,该表具有语言支持,glyph替换和定位规则之类的数据以及其他高级印刷功能。
Truetype字体的元数据标准
Opentype字体文件规范还定义了 TrueType字体的标准格式。它包括各种元数据场。让我们看一下关键的(其中一些已经描述了):
- 字体姓氏。
- 字体亚家族名称 - 单个字体样式(字体)的名称。
- 字体的唯一标识符,例如版本号或字体创建器分配的标识符。
- 全字体名称由家庭和亚家族名称组成。
- 设计师名称。
- 描述字体的设计特征。
- 许可信息。- 商标提供有关与字体相关的任何商标的信息。
后录字体的元数据标准
它是一组指导方针,可以组织和介绍有关字体的信息,例如其作者,许可和设计特征。这是Adobe 类型1字体格式,它定义了PostScript字体的标准格式,其中包含各种元数据字段,例如:
- fontname。 - 字体名称的字段在PostScript解释器中是唯一的。
- fullname。 - 指定字体的全名的字段。
- familyname, - 为字体家族的名称。
- 重量。
- fontbbox。 - 字体的边界框。需要定义字形的最小值和最大x和y坐标。
- 注意。 - 有关许可证和版权的信息的字段。
- 独特。 - 具有针对字体的唯一标识符。
Woff字体的元数据标准
Web Open字体格式旨在在网络上使用。 WOFF字体的元数据标准由WOFF文件格式规范定义。根据元数据的田地,它是下一步的。
- 家庭, - 用于姓氏。
- 样式, - 有关字体样式的信息。
- 重量, - 包括字体重量的参数。
- 拉伸, - 包括[font -tretch]的参数(15)。
- 设计师, - 用于字体创建者的名字。
- 执照。
- 描述。
- 小贩。
总体而言,不同的字体格式包含不同的元数据标准。它由规格定义,包括有关元数据中可能存在的字段和这些字段格式的信息。对于所有字体格式,它们大多相似,但是字段的名称可能具有不同的格式。
字体元数据的最佳实践
关于如何编写字体元数据有一些建议。跟随他们,您将确保字体易于识别和用户访问。
- 在所有元数据字段中使用一致的命名约定。这将使用户更容易浏览您的字体。
- 包括有关您的字体的完整信息。
- 以简单明了的方式编写描述和其他元数据字段,而没有复杂的句子,术语和本地表达式。
- 使用在不同字体格式中广泛识别的标准元数据字段。
- 使用唯一的标识符来防止与其他字体发生冲突,并使您的字体可区分。
- 保持字体元数据定期更新。
这些简单的规则将帮助用户在各种各样的竞争对手中选择您的字体,并消除未来的错误理解。
构建字体微调和栅格化 AI 代理
核心工程目标是创建一个闭环诊断框架。该代理接收轮廓字体资源,运行模拟的低 DPI 视口分析,检查结构笔画一致性,识别亚像素级可读性缺陷,并调整程序参数指标直至编译节点。
代理实现流程详解
- 查询处理和上下文隔离(LLM 接收层)
用户提供一个轮廓字体文件和一个提示(例如,“针对在低 DPI 屏幕显示器上渲染的小型 UI 文本层,调整此 TrueType 字体的栅格化行为”)。
LLM 处理用户输入,记录目标平台环境,并选择匹配的微调配置文件(屏幕的 TrueType 网格适配指令或打印层的 PostScript Type 1 指令)。
- 原生字形树和词干解析(分析层)
为了评估字体几何形状在低分辨率条件下的变形情况,代理程序会原生解析文件的内部属性。
代理程序通过 Font.Load 创建一个实例。它会映射轮廓矢量配置,逐步分析各个字符的几何形状,并识别关键水平和垂直词干的粗细指标。
- 可读性模拟和指令过滤(验证层)
代理程序会针对不同字号下的结构异常进行检测,并根据基准技术标准过滤字符:
- 标记在相同行高下扭曲或交替显示粗细的字形笔画。
- 测量小写字母基线循环(例如“e”、“a”、“g”)是否缺少替代的蓝色区域值,这会导致内部计数器填充并变得难以辨认。
- 根据模拟的像素网格数组评估渲染路径,以查找舍入布局错误。
- 元数据优化和序列化(执行节点)
代理程序无需人工设计师重新绘制数百个字符的数学控制线,而是原生配置优化标志。
代理程序会在 Font 工作区内调整编译设置。对于下载速度至关重要的网络分发渠道,它会使用剥离变量去除占用大量字节的度量值,或者在通过 Save 命令干净地序列化文件之前注入统一对齐度量值。
结论
字体元数据可能是使您的字体更具竞争力的好工具。了解要添加的信息以及如何正确编写它,将使您的字体更具吸引力,并且可以向用户提供专业的字体。添加所有必要的数据并保持适当的标准化和更新将有助于摆脱与客户的误解。它还将有助于保护字体免于盗版。