7. LaTeX-Modell für Zeichenkodierungen
In diesem Artikel werden LaTeX-Kodierungen ausführlich behandelt. Es beginnt mit einer Diskussion des Zeichendatenflusses innerhalb des LaTeX-Systems. Als nächstes werfen wir einen genaueren Blick auf das interne Darstellungsmodell für Zeichendaten in LaTeX, gefolgt von einer Diskussion der Mechanismen, die verwendet werden, um eingehende Daten über Eingabekodierungen in diese interne Darstellung abzubilden. Abschließend erklären wir, wie die interne Darstellung über die Ausgabekodierungen in die für den Schriftsatz erforderliche Form übersetzt wird.
7.1. Der Zeichendatenfluss innerhalb von LaTeX
Die Verarbeitung eines Dokuments mit LaTeX beginnt mit der Interpretation der in einer oder mehreren Quelldateien vorhandenen Daten. Diese Daten, die den Inhalt des Dokuments darstellen, werden in Quelldateien als Folgen von Oktetten gespeichert, die Zeichen darstellen. Um diese Oktette korrekt zu interpretieren, muss jedes Programm (einschließlich LaTeX), das zur Verarbeitung der Datei verwendet wird, die Zuordnung zwischen abstrakten Zeichen und den sie darstellenden Oktetten kennen. Mit anderen Worten: Es muss die Kodierung kennen, die beim Schreiben der Datei verwendet wurde.
Bei einer falschen Zuordnung wird die gesamte weitere Verarbeitung mehr oder weniger fehlerhaft sein, es sei denn, die Datei enthält nur Zeichen einer Teilmenge, die sowohl in korrekten als auch in falschen Codierungen üblich ist. LaTeX geht an dieser Stelle von einer Grundannahme aus: Fast alle sichtbaren ASCII-Zeichen (dezimal 32-126) werden durch die Nummer dargestellt, die sie in der ASCII-Codetabelle haben.

Ein Grund für diese Annahme ist, dass die meisten heute verwendeten 8-Bit-Kodierungen eine gemeinsame 7-Bit-Ebene haben. Ein weiterer Grund besteht darin, dass zur effektiven Nutzung von TeX der Großteil des sichtbaren Teils von ASCII als Zeichen der Kategorie Buchstabe verarbeitet werden muss – da nur Zeichen dieser Kategorie in mehrstelligen Befehlsnamen in TEX – oder Kategorie – verwendet werden können andere – da TEX beispielsweise die Dezimalstellen nicht als Teil einer Zahl erkennt, wenn sie diesen Kategoriecode nicht haben.
Wenn ein Zeichen (oder genauer gesagt eine 8-Bit-Zahl) in TeX als der Kategorie Buchstabe oder Sonstiges deklariert wird, wird diese 8-Bit-Zahl transparent durch TeX weitergeleitet. Das bedeutet, dass TeX jedes Symbol in der Schriftart an der durch diese Zahl adressierten Position setzt.
Als Konsequenz aus der oben genannten Annahme erfordern Schriftarten, die für allgemeine Texte verwendet werden sollen, dass (die meisten) der sichtbaren ASCII-Zeichen in der Schriftart vorhanden und gemäß der ASCII-Codierung codiert sind.
Allen anderen 8-Bit-Zahlen (die außerhalb des sichtbaren ASCII liegen), die möglicherweise in der Eingabedatei vorhanden sind, wird der Kategoriecode aktiv zugewiesen, was dazu führt, dass sie sich wie Befehle in TeX verhalten. Daher kann LaTeX sie über die Eingabekodierungen in eine Form umwandeln, die wir die LaTeX-interne Zeichendarstellung (LICR) nennen.
Die UTF8-Codierung von Unicode wird ähnlich gehandhabt. Die ASCII-Zeichen repräsentieren sich selbst und die Startoktette für die Multibyte-Darstellung fungieren als aktive Zeichen, die die Eingabe nach den verbleibenden Oktetten durchsuchen. Das Ergebnis wird in ein Objekt im LICR umgewandelt, wenn es zugeordnet ist, oder LaTeX gibt einen Fehler aus, wenn das angegebene Unicode-Zeichen nicht zugeordnet ist.
Das Wichtigste an Objekten im LICR ist, dass die Darstellung von 7-Bit-ASCII-Zeichen gegenüber jeder Kodierungsänderung unveränderlich ist, da alle Eingabekodierungen in Bezug auf sichtbares ASCII transparent sein sollen.
Die Ausgabe- (oder Schriftarten-)Kodierungen dienen dann dazu, die internen Zeichendarstellungen den Glyphenpositionen in der aktuellen Schriftart zuzuordnen, die für den Schriftsatz verwendet werden, oder in einigen Fällen zum Auslösen komplexerer Aktionen. Beispielsweise kann ein Akzent (an einer Position in der aktuellen Schriftart vorhanden) über einem Symbol (an einer anderen Position in der aktuellen Schriftart) platziert werden, um ein gedrucktes Bild des abstrakten Zeichens zu erhalten, das durch den/die Befehl(e) im internen Symbol dargestellt wird Zeichenkodierung.
Der LICR kodiert alle möglichen Zeichen, die in LaTeX adressierbar sind. Damit ist sie viel größer als die Anzahl der Zeichen, die von einer einzelnen TeX-Schriftart dargestellt werden können (die höchstens 256 Glyphen enthalten kann). In manchen Fällen kann ein Zeichen in der internen Codierung mit einer Schriftart gerendert werden, indem Glyphen, beispielsweise Akzentzeichen, kombiniert werden. Wenn das interne Zeichen jedoch eine spezielle Form erfordert, gibt es keine Möglichkeit, es zu fälschen, wenn dieses Glyph nicht in der Schriftart vorhanden ist.
Dennoch unterstützt das LaTeX-Modell für Zeichenkodierungen automatische Mechanismen zum Abrufen von Glyphen aus verschiedenen Schriftarten, sodass in der aktuellen Schriftart fehlende Zeichen gesetzt werden, sofern eine geeignete zusätzliche Schriftart verfügbar ist, die sie enthält.
7.2. LaTeXs interne Zeichendarstellung (LICR)
Textzeichen werden intern von LaTeX auf eine von drei Arten dargestellt.
Darstellung als Charaktere
Eine kleine Anzahl von Zeichen wird durch „sich selbst“ dargestellt. Beispielsweise wird das lateinische A als das Zeichen „A“ dargestellt. Solche Zeichen sind in der Tabelle oben aufgeführt. Sie bilden eine Teilmenge des sichtbaren ASCII, und in TeX wird ihnen allen der Kategoriecode Buchstabe oder Sonstiges zugewiesen. Einige Zeichen aus dem sichtbaren ASCII-Bereich werden nicht auf diese Weise dargestellt, entweder weil sie Teil der TeX-Syntax sind oder weil sie nicht in allen Schriftarten vorhanden sind. Wenn man beispielsweise „<“ im Text verwendet, bestimmt die aktuelle Schriftartenkodierung, ob man „<“ (‚T1‘) oder vielleicht ein umgekehrtes Ausrufezeichen (‚OT1‘) in der gedruckten Ausgabe erhält.
Darstellung als Zeichenfolgen
Der interne Ligaturmechanismus von TeX kann aus einer Folge von Eingabezeichen neue Zeichen generieren. Dies ist eigentlich eine Eigenschaft der Schriftart, obwohl einige dieser Sequenzen explizit als Eingabekürzel für Zeichen konzipiert wurden, die sonst mit den meisten Tastaturen nur schwer zu adressieren sind. Nur wenige auf diese Weise generierte Zeichen gelten als zur internen Darstellung von LaTeX gehörend. Dazu gehören der Bindestrich „en“ und der Bindestrich „em“, die durch die Ligaturen „–“ und „—“ erzeugt werden, sowie die öffnenden und schließenden doppelten Anführungszeichen, die durch „“ „, „ „“ und „“ erzeugt werden. (Letzteres kann normalerweise auch durch das einzelne" dargestellt werden). Während die meisten Schriftarten auch ``` ! und ?` ``` implementieren, um umgekehrte Ausrufe- und Fragezeichen zu erzeugen, ist dies nicht der Fall universell in allen Schriftarten verfügbar. Aus diesem Grund haben alle dieser Zeichen eine alternative interne Darstellung als Befehl (z. B. „\textendash“ oder „\textexclamdown“).
Darstellung als „fontkodierungsspezifische“ Befehle
Die dritte Möglichkeit, Zeichen in LaTeX intern darzustellen, die die meisten Zeichen abdeckt, besteht in speziellen LaTeX-Befehlen (oder Befehlssequenzen), die nicht erweitert bleiben, wenn sie in eine Datei geschrieben oder in ein bewegliches Argument eingefügt werden. Wir werden solche speziellen Befehle als schriftkodierungsspezifische Befehle bezeichnen, da ihre Bedeutung von der aktuell verwendeten Schriftkodierung abhängt, wenn LaTeX bereit ist, sie zu setzen. Solche Befehle werden mit speziellen Deklarationen deklariert, wie wir weiter unten besprechen werden, die normalerweise individuelle Definitionen für jede Schriftartenkodierung erfordern. Wenn für die aktuelle Kodierung keine Definition vorhanden ist, wird entweder ein Standardwert verwendet (sofern verfügbar) oder dem Benutzer wird eine Fehlermeldung angezeigt. Wenn die Schriftartkodierung an irgendeiner Stelle im Dokument geändert wird, ändern sich die Definitionen der kodierungsspezifischen Befehle nicht sofort, da dies bedeuten würde, dass eine große Anzahl von Befehlen sofort geändert werden müsste. Stattdessen sind diese Befehle so implementiert, dass sie bei ihrer Verwendung erkennen, ob ihre aktuelle Definition nicht mehr für die geltende Schriftartenkodierung geeignet ist. In einem solchen Fall rufen sie ihre Gegenstücke in der aktuellen Schriftartkodierung an, um die eigentliche Arbeit zu erledigen.
Der Satz schriftkodierungsspezifischer Befehle ist nicht festgelegt, sondern implizit als die Vereinigung aller für einzelne Schriftkodierungen definierten Befehle definiert. Daher sind möglicherweise neue schriftkodierungsspezifische Befehle erforderlich, wenn neue Schriftkodierungen zu LaTeX hinzugefügt werden.
7.3. Eingabekodierungen
Sobald das Paket „inputenc“ geladen ist, stehen die beiden Deklarationen „\DeclareInputText“ und „\DeclareInputMath“ zum Zuordnen von 8-Bit-Eingabezeichen zu LICR-Objekten zur Verfügung. Sie sollten nur in Codierungsdateien (siehe unten), Paketen oder, falls erforderlich, in der Dokumentpräambel verwendet werden.
Diese Befehle verwenden als erstes Argument eine 8-Bit-Zahl, die entweder als Dezimalzahl, Oktalzahl oder in Hexadezimalschreibweise angegeben werden kann. Es wird empfohlen, die Dezimalschreibweise zu verwenden, da die Zeichen „“ und/oder „““ in einem Sprachunterstützungspaket besondere Bedeutungen haben können, z. B. Abkürzungen für Akzente, wodurch die Oktal- und/oder Hexadezimalschreibweise ungültig wird, wenn Pakete falsch geladen werden Befehl.
1\DeclareInputText{number}{LICR-object}Der Befehl „\DeclareInputText“ deklariert Zeichenzuordnungen zur Verwendung im Text. Sein zweites Argument enthält den kodierungsspezifischen Befehl (oder die Befehlssequenz), also die LICR-Objekte, denen die Zeichennummer zugeordnet werden soll. Zum Beispiel,
1\DeclareInputText{239}{\"\i}ordnet die Zahl „239“ der codierungsspezifischen Darstellung des „i-Umlauts“ zu, nämlich „\“\i“. Auf diese Weise deklarierte Eingabezeichen können nicht in mathematischen Formeln verwendet werden.
1\DeclareInputMath{number}{math-object}Wenn die Zahl ein Zeichen zur Verwendung in mathematischen Formeln darstellt, muss die Deklaration „\DeclareInputMath“ verwendet werden. Beispielsweise in der Eingabekodierung „cp437de“ (deutsche MS-DOS-Tastatur),
1\DeclareInputMath{224}{\alpha}ordnet die Zahl „224“ dem Befehl \alpha zu. Es ist wichtig zu beachten, dass diese Deklaration dazu führen würde, dass der Schlüssel, der diese Zahl erzeugt, nur im Mathematikmodus verwendbar ist, da \alpha nirgendwo anders zulässig ist.
1\DeclareUnicodeCharacter{hex-number}{LICR-object}Diese Deklaration ist nur verfügbar, wenn die Option „utf8“ verwendet wird. Es ordnet Unicode-Nummern LICR-Objekten zu (d. h. Zeichen, die im Text verwendet werden können). Zum Beispiel,
1\DeclareUnicodeCharacter{00A3}{\textsterling}
2\DeclareUnicodeCharacter{011A}{\v E}
3\DeclareUnicodeCharacter{2031}{\textpertenthousand}Theoretisch sollte es nur eine eindeutige bidirektionale Zuordnung zwischen den beiden Leerzeichen geben, sodass alle derartigen Deklarationen bereits automatisch erfolgen könnten, wenn die Option „utf8“ ausgewählt wird. In der Praxis sind die Dinge etwas komplizierter. Erstens würde die automatische Bereitstellung der gesamten Tabelle eine große Menge an TeX-Speicher erfordern. Darüber hinaus gibt es viele Unicode-Zeichen, für die kein LICR-Objekt existiert, und umgekehrt gibt es für viele LICR-Objekte kein Äquivalent in Unicode. Dieses Problem wird im Paket „inputenc“ gelöst, indem nur diejenigen Unicode-Zuordnungen geladen werden, die den in einem bestimmten Dokument verwendeten Kodierungen entsprechen (sofern diese bekannt sind) und auf jede andere Anfrage nach einem Unicode-Zeichen mit einer entsprechenden Fehlermeldung geantwortet wird. Es ist dann die Aufgabe des Benutzers, entweder die richtigen Zuordnungsinformationen bereitzustellen oder bei Bedarf eine zusätzliche Schriftartenkodierung zu laden.
Wie oben erwähnt, können die Eingabekodierungsdeklarationen in Paketen oder in der Dokumentpräambel verwendet werden. Damit alles so funktioniert, ist es wichtig, zuerst das Paket „inputenc“ zu laden und dabei eine passende Kodierung auszuwählen. Nachfolgende Eingabekodierungsdeklarationen dienen als Ersatz (oder Ergänzung) für diejenigen, die durch die aktuelle Eingabekodierung definiert werden. Wenn Sie das Paket „inputenc“ verwenden, sehen Sie möglicherweise den Befehl „@tabacckludge“, der für „tabbing Accent Kludge“ steht. Es wird benötigt, weil die aktuelle Version von LaTeX eine Überladung der Befehle „=“, „\“ und „\“ geerbt hat, die normalerweise bestimmte Akzente bezeichnen (d. h. kodierungsspezifische Befehle sind). haben aber innerhalb der „Tabbing“-Umgebung besondere Bedeutungen. Aus diesem Grund müssen Zuordnungen, die einen dieser Akzente beinhalten, auf besondere Weise codiert werden. Wenn Sie beispielsweise „232“ dem Zeichen „e-grave“ zuordnen möchten (das intern die Darstellung „`e“ hat), sollten Sie schreiben
1\DeclareInputText{232}{\@tabacckludge`e}anstatt
1\DeclareInputText{232}{\`e}Zuordnung zu Text und/oder Mathematik
Aus technischen und konzeptionellen Gründen unterscheidet TeX sehr stark zwischen Zeichen, die in Texten und in der Mathematik verwendet werden können. Mit Ausnahme sichtbarer ASCII-Zeichen können Befehle, die Zeichen erzeugen, normalerweise entweder im Text- oder im Mathematikmodus verwendet werden, jedoch nicht in beiden Modi.
Eingabekodierungsdateien für 8-Bit-Kodierungen
Eingabekodierungen werden in Dateien mit der Erweiterung „.def“ gespeichert, wobei der Basisname der Name der Eingabekodierung ist (z. B. „latin1.def“). Solche Dateien sollten nur die im aktuellen Abschnitt besprochenen Befehle enthalten. Die Datei sollte mit einer Identifikationszeile beginnen, die den Befehl „\ProvidesFile“ enthält und die Art der Datei beschreibt. Zum Beispiel:
1\ProvidesFile{latin1.def}[2000/07/01 v0.996 Input encoding file]Wenn es Zuordnungen zu kodierungsspezifischen Befehlen gibt, die möglicherweise nicht verfügbar sind, es sei denn, zusätzliche Pakete werden geladen, könnte man mit „\ProvideTextCommandDefault“ Standardwerte für sie deklarieren. Zum Beispiel:
1\ProvideTextCommandDefault{\textonehalf}{\ensurement{\frac12}}
2\ProvideTextCommandDefault{\textcent}{\TextSymbolUnavailable\textcent}Der Befehl „\TextSymbolUnavailable“ gibt eine Warnung aus, die darauf hinweist, dass ein bestimmtes Zeichen in den aktuell verwendeten Schriftarten nicht verfügbar ist. Dies kann als Standard nützlich sein, wenn solche Zeichen nur verfügbar sind, wenn spezielle Schriftarten geladen sind und es keine geeignete Möglichkeit gibt, die Zeichen mit vorhandenen Zeichen zu fälschen (wie es bei einer Standardeinstellung für „\textonehalf“ möglich war).
Der Rest der Datei sollte nur die Eingabekodierungsdeklarationen „\DeclareInputText“ und „\DeclareInputMath“ enthalten. Wie oben erwähnt, wird von der Verwendung des letztgenannten Befehls abgeraten, ist aber zulässig. Innerhalb einer Eingabekodierungsdatei sollten keine anderen Befehle verwendet werden, insbesondere keine Befehle, die das mehrfache Lesen der Datei verhindern (z. B. \newcommand), da die Kodierungsdateien oft mehrfach in einem einzigen Dokument geladen werden.
Eingabezuordnungsdateien für UTF8
Wie bereits erwähnt, ist die Zuordnung von Unicode zu LICR-Objekten so organisiert, dass LaTeX nur die Zuordnungen laden kann, die für die im aktuellen Dokument verwendeten Schriftartenkodierungen relevant sind. Dazu wird versucht, für jede Kodierung <Name> eine Datei <Name>enc.dfu zu laden, die, sofern vorhanden, die Zuordnungsinformationen für die Unicode-Zeichen enthält, die von dieser bestimmten Kodierung bereitgestellt werden. Neben einer Reihe von „\DeclareUnicodeCharacter“-Deklarationen sollten solche Dateien nur eine „\ProvidesFile“-Zeile enthalten.
Da unterschiedliche Schriftartenkodierungen häufig mehr oder weniger dieselben Zeichen bereitstellen, kommt es häufig vor, dass Deklarationen für dasselbe Unicode-Zeichen in verschiedenen „.dfu“-Dateien erscheinen. Daher ist es sehr wichtig, dass diese Deklarationen in verschiedenen Dateien identisch sind. Andernfalls bleibt die zuletzt geladene Deklaration erhalten, die von Dokument zu Dokument unterschiedlich sein kann.
Wer also eine neue „.dfu“-Datei für eine bisher nicht abgedeckte Kodierung bereitstellen möchte, sollte die vorhandenen Definitionen in „.dfu“-Dateien sorgfältig auf verwandte Kodierungen prüfen. Standarddateien, die mit „inputenc“ bereitgestellt werden, haben garantiert einheitliche Definitionen. Tatsächlich werden sie alle aus einer einzigen Liste generiert, die entsprechend aufgeteilt ist. Eine vollständige Liste der aktuell vorhandenen Zuordnungen finden Sie in der Datei „utf8enc.dfu“.
7.4. Ausgabekodierungen
Wir haben bereits erwähnt, dass Ausgabekodierungen die Zuordnung vom LICR zu den Glyphen (oder aus Glyphen erstellten Konstrukten) definieren, die in den für den Schriftsatz verwendeten Schriftarten verfügbar sind. Auf diese Zuordnungen wird in LaTeX durch zwei- oder dreibuchstabige Namen verwiesen (z. B. „OT1“ und „T3“). Wir sagen, dass eine bestimmte Schriftart eine bestimmte Kodierung aufweist, wenn die Zuordnung den Positionen der Glyphen in der Schriftart entspricht. Schauen wir uns nun die genauen Bestandteile einer solchen Zuordnung an.
Intern durch ASCII-Zeichen dargestellte Zeichen werden einfach an die Schriftart weitergegeben. Mit anderen Worten: TeX verwendet den ASCII-Code, um eine Glyphe aus der aktuellen Schriftart auszuwählen. Beispielsweise führt das Zeichen „A“ mit dem ASCII-Code 65 dazu, dass das Glyph an Position 65 in der aktuellen Schriftart gesetzt wird. Aus diesem Grund erfordert LaTeX, dass Schriftarten für Text alle derartigen ASCII-Buchstaben an ihren ASCII-Codepositionen enthalten, da es keine Möglichkeit gibt, mit diesem grundlegenden TeX-Mechanismus zu interagieren. Daher ist für sichtbares ASCII in allen Ausgabekodierungen implizit eine Eins-zu-Eins-Zuordnung vorhanden.
Zeichen, die intern als Folgen von ASCII-Zeichen dargestellt werden (z. B. „–“), werden wie folgt behandelt: Wenn die aktuelle Schriftart zum ersten Mal geladen wird, wird TeX darüber informiert, dass die Schriftart eine Reihe sogenannter Ligaturprogramme enthält. Diese Programme definieren bestimmte Zeichenfolgen, die nicht direkt gesetzt, sondern durch andere Glyphen aus der Schriftart ersetzt werden sollen. Wenn TeX beispielsweise in der Eingabe auf „–“ stößt (d. h. ASCII-Code 45 zweimal), leitet ein Ligaturprogramm es möglicherweise stattdessen an die Glyphe an Position 123 weiter (die dann die End-Dash-Glyphe enthalten würde). Auch hier gibt es keine Möglichkeit, mit diesem Mechanismus zu interagieren.
Dennoch besteht der größte Teil der internen Zeichendarstellung aus schriftkodierungsspezifischen Befehlen, die über die unten beschriebenen Deklarationen abgebildet werden. Alle Deklarationen haben in ihren ersten beiden Argumenten die gleiche Struktur: den schriftartcodierungsspezifischen Befehl (oder die erste Komponente davon, wenn es sich um eine Befehlssequenz handelt), gefolgt vom Namen der Codierung. Alle verbleibenden Argumente hängen vom Deklarationstyp ab.
Eine Kodierung „XYZ“ wird also durch eine Reihe von Deklarationen definiert, die alle den Namen „XYZ“ als zweites Argument haben. Dann müssen natürlich einige Schriftarten in dieser Kodierung kodiert werden. Tatsächlich erfolgt die Entwicklung von Schriftartenkodierungen normalerweise umgekehrt: Jemand beginnt mit einer vorhandenen Schriftart und stellt dann entsprechende Deklarationen für deren Verwendung bereit. Diese Sammlung von Deklarationen erhält dann einen passenden Namen, z. B. „OT1“. Im Folgenden nehmen wir die Schriftart „ecrm1000“ (siehe Glyphendiagramm), deren Schriftartenkodierung in LaTeX „T1“ heißt, und erstellen entsprechende Deklarationen, um auf Glyphen einer auf diese Weise codierten Schriftart zuzugreifen. Die blauen Zeichen im Glyphendiagramm sollten in jeder Textcodierung an derselben Position vorhanden sein, da sie transparent durch LaTeX weitergeleitet werden.
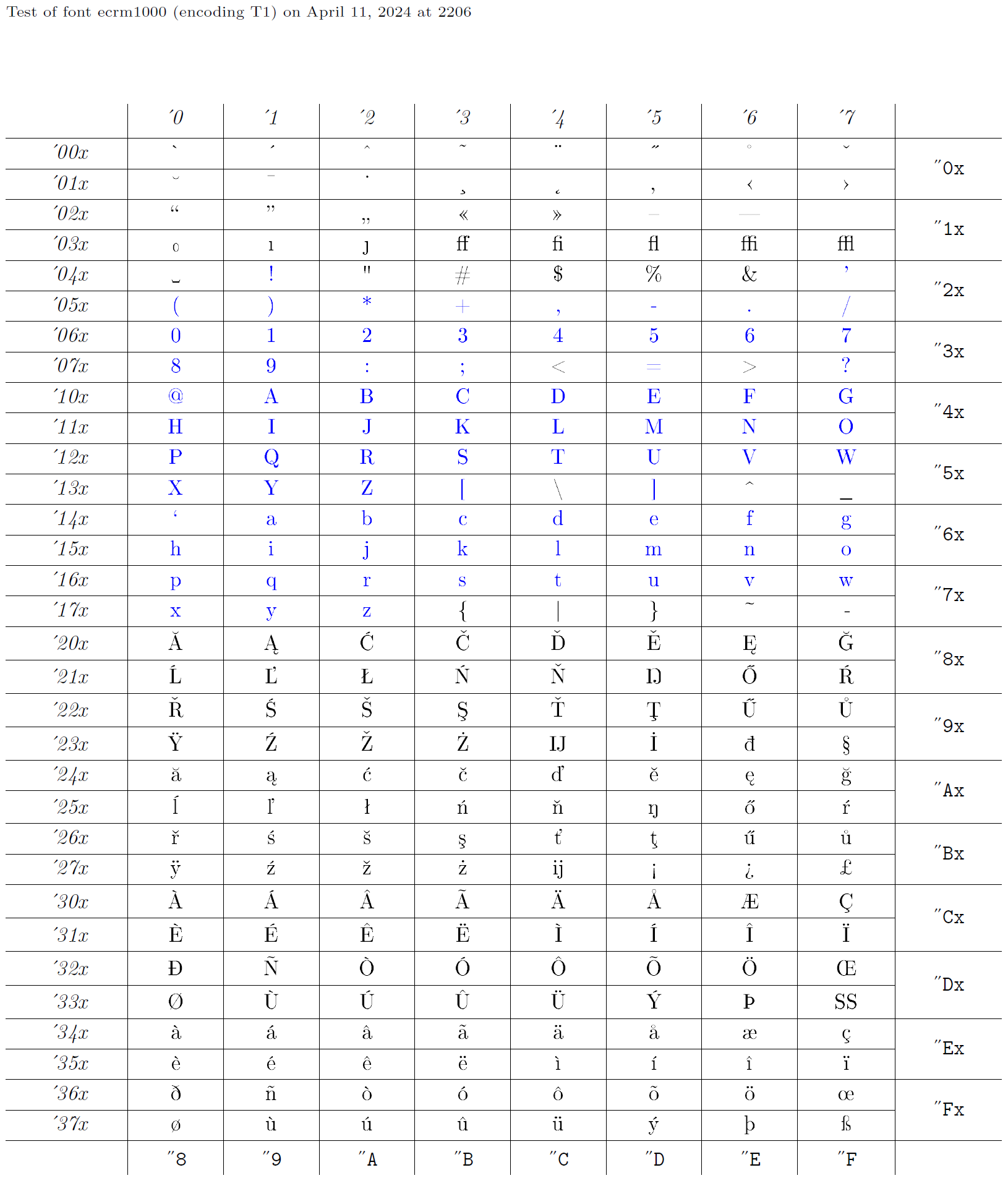
Codierungsdateien ausgeben
Ausgabekodierungsdateien werden durch die gleiche „.def“-Erweiterung identifiziert wie Eingabekodierungsdateien. Allerdings ist der Basisname der Datei etwas strukturierter. Es besteht aus dem Kodierungsnamen in Kleinbuchstaben, gefolgt von „enc“ (z. B. „t1enc.def“ für die Kodierung „T1“).
Diese Dateien sollten nur die im aktuellen Abschnitt beschriebenen Deklarationen enthalten. Da Ausgabekodierungsdateien möglicherweise mehrmals von LaTeX gelesen werden, ist es wichtig, diese Regel zu befolgen und beispielsweise nicht \newcommand zu verwenden, was verhindert, dass eine solche Datei mehr als einmal gelesen wird!
Auch hier beginnt eine Ausgabekodierungsdatei mit einer Identifikationszeile, die die Art der Datei beschreibt. Zum Beispiel:
1\ProvidesFile{t1enc.def}[2001/06/05 v1.94 Standard LaTeX file]Bevor wir kodierungsspezifische Befehle für eine bestimmte Kodierung deklarieren, müssen wir diese Kodierung zunächst LaTeX bekannt machen. Dies geschieht über den Befehl „\DeclareFontEncoding“. An dieser Stelle ist es auch sinnvoll, die Standard-Ersetzungsregeln für die Kodierung zu deklarieren. Wir können dies tun, indem wir den Befehl „\DeclareFontSubstitution“ verwenden. Beide Deklarationen werden im Detail unter So richten Sie neue Schriftarten ein besprochen.
1\DeclareFontEncoding{T1}{}{}
2\DeclareFontSubstitution{T1}{cmr}{m}{n}Nachdem wir nun die „T1“-Kodierung in LaTeX auf diese Weise eingeführt haben, können wir mit der Erklärung fortfahren, wie sich schriftartkodierungsspezifische Befehle in dieser Kodierung verhalten sollen.
1\DeclareTextSymbol{LICR-Object}{encoding}{slot}Am einfachsten scheint die Deklaration für Textsymbole zu sein. Hier kann die interne Darstellung direkt einer einzelnen Glyphe in der Zielschriftart zugeordnet werden. Dies wird durch die Verwendung der Deklaration „\DeclareTextSymbol“ erreicht, deren drittes Argument – die Glyphenposition – als Dezimal-, Oktal- oder Hexadezimalzahl angegeben werden kann. Zum Beispiel,
1\DeclareTextSymbol{\ss}{T1}{255}
2\DeclareTextSymbol{\AE}{T1}{'306} %font position as octal number
3\DeclareTextSymbol{\ae}{T1}{"E6} %...as hexadecimal numberDeklarieren Sie, dass die für die Schriftartenkodierung spezifischen Befehle „\ss“, „\AE“ und „\ae“ den Schriftart-(Dezimal-)Positionen 255, 198 bzw. 230 in einer „T1“-Kodierung zugeordnet werden sollen Schriftart. Wie oben erwähnt, ist es am sichersten, in solchen Deklarationen die Dezimalschreibweise zu verwenden. Wie auch immer, das Mischen von Notationen wie im vorherigen Beispiel ist sicherlich ein schlechter Stil.
1\DeclareTextAccent{LICR-accent}{encoding}{slot}Schriftarten enthalten häufig diakritische Zeichen als einzelne Glyphen, um die Konstruktion akzentuierter Zeichen durch Kombination eines solchen diakritischen Zeichens mit einem anderen Glyphen zu ermöglichen. Solche Akzente (sofern sie über anderen Glyphen platziert werden sollen) werden mit dem Befehl „\DeclareTextAccent“ deklariert. Das dritte Argument, slot, ist die Position des diakritischen Zeichens in der Schriftart. Zum Beispiel,
1\DeclareTextAccent{\"}{T1}{4}definiert den „Umlaut“-Akzent. Ab diesem Zeitpunkt hat eine interne Darstellung wie „\“a“ in der „T1“-Codierung die folgende Bedeutung: Setzen Sie „a mit Umlaut“, indem Sie den Akzent an Position 4 über den Glyphen an Position 97 (dem ASCII-Code von) setzen das Zeichen „a“. Eine solche Deklaration definiert tatsächlich implizit eine große Auswahl an internen Zeichendarstellungen – also alles vom Typ „\“`
Selbst solche Kombinationen, die wenig Sinn ergeben, wie z. B. „\“\P“ (d. h. Pilcrow-Zeichen mit Umlaut), werden auf diese Weise konzeptionell zu Mitgliedern der Menge der für die Schriftartenkodierung spezifischen Befehle.
1\DeclareTextComposite
2 {LICR-accent}{encoding}{simple-LICR-object}{slot}Das obige Glyphendiagramm enthält eine große Anzahl akzentuierter Zeichen als einzelne Glyphen – zum Beispiel „a mit Umlaut“ an der Position „240“ oktal. Daher sollte in „T1“ der codierungsspezifische Befehl „\“a“ nicht dazu führen, dass ein Akzent über dem Zeichen „a“ gesetzt wird, sondern stattdessen direkt auf die Glyphe an dieser Position der Schriftart zugreifen. Dies wird durch die Deklaration erreicht
1\DeclareTextComposite{\"}{T1}{a}{228}Darin wird angegeben, dass der kodierungsspezifische Befehl \"a dazu führt, dass das Glyph 228 gesetzt wird, wodurch die oben genannte Akzentdeklaration deaktiviert wird. Für alle anderen kodierungsspezifischen Befehle, die mit \" beginnen, bleibt die Akzentdeklaration bestehen. Beispielsweise erzeugt \"b ein ‘b mit Umlaut’, indem ein Akzent über das Basisglyph ‘b’ gesetzt wird.
Das dritte Argument, simple-LICR-object, sollte ein einzelner Buchstabe wie „a“ oder ein einzelner Befehl wie „\j“ oder „\oe“ sein.
1\DeclareTextCompositeCommand
2 {LICR-object}{encoding}{simple-LICR-object}{code}Obwohl es nicht für die „T1“-Kodierung verwendet wird, gibt es auch eine allgemeinere Version von „\DeclareTextComposite“, die beliebigen Code anstelle einer Slot-Position zulässt. Dies wird zum Beispiel in der „OT1“-Codierung verwendet, um den Ringakzent über dem „A“ im Vergleich zu der Art und Weise, wie er mit dem Grundelement „\accent“ von TeX gesetzt würde, abzusenken. Auch die Akzente über dem „i“ werden mit dieser Deklarationsform umgesetzt:
1\DeclareTextCompositeCommand{\'}{OT1}{i}{\@tabacckludge'\i}
2\DeclareTextCompositeCommand{\^}{OT1}{i}{\^\i}Einige diakritische Zeichen werden nicht über anderen Zeichen, sondern irgendwo darunter platziert. Für solche Markierungen gibt es kein spezielles Deklarationsformular, da die eigentliche Positionierung des Akzents Low-Level-TeX-Code erfordert. Stattdessen kann zu diesem Zweck das generische „\DeclareTextCommand“ verwendet werden.
1\DeclareTextCommand{LICR-object}{encoding}[num][default]{code}Beispielsweise wird der „Unterstrich“-Akzent „\b“ in der „T1“-Kodierung mit dem folgenden Code definiert:
1\DeclareTextCommand{\b}{T1}[1]
2 {\hmode$bgroup\o$lign{\relax#1\crcr\hidewidth\sh$ft{29}%
3 \vbox to.2ex{\hbox{\char9}\vss}\hidewidth}\egroup}In dieser Diskussion spielt es keine große Rolle, was der Code genau bedeutet, aber wir können sehen, dass „\DeclareTextCommand“ in gewisser Weise \newcommand ähnelt. Es verfügt über ein optionales num-Argument, das die Anzahl der Argumente angibt (hier eines), ein zweites optionales default-Argument (hier nicht vorhanden) und ein letztes obligatorisches Argument, das den Code enthält, in dem auf das Argument verwiesen werden kann( s) mit „#1“, „#2“ usw.
„\DeclareTextCommand“ kann auch verwendet werden, um schriftkodierungsspezifische Befehle zu erstellen, die aus einer einzelnen Steuersequenz bestehen. In diesem Fall wird es ohne das optionale Argument verwendet und definiert somit einen Befehl ohne Argumente. Beispielsweise gibt es in „T1“ keine Glyphe für ein „Promille“-Zeichen, aber es gibt ein kleines o an der Position „30“, das, wenn es direkt hinter einem „%“ platziert wird, die entsprechende Glyphe ergibt . Somit können wir folgende Erklärungen abgeben:
1\DeclareTextCommand{\textperthousand} {T1}{\%\char 24}
2\DeclareTextCommand{\textpertenthousand}{T1}{\%\char 24\char 24 }Wir haben nun alle Befehle behandelt, die zum Deklarieren der schriftartcodierungsspezifischen Befehle für eine neue Codierung erforderlich sind. Wie bereits erwähnt, sollten nur diese Befehle in Codierungsdefinitionsdateien vorhanden sein.
Standardwerte für die Ausgabekodierung
Sehen wir uns nun an, was passiert, wenn ein kodierungsspezifischer Befehl verwendet wird, für den es in der aktuellen Schriftkodierung keine Deklaration gibt. In diesem Fall kann eines von zwei Dingen passieren: Entweder verfügt LaTeX über eine Standarddefinition für das LICR-Objekt. In diesem Fall wird diese Standarddefinition verwendet, oder es wird eine Fehlermeldung ausgegeben, die besagt, dass das angeforderte LICR-Objekt in der aktuellen Codierung nicht verfügbar ist. Es gibt verschiedene Möglichkeiten, Standardwerte für LICR-Objekte einzurichten.
1\DeclareTextCommandDefault{LICR-object}[num][default]{code}Der Befehl „\DeclareTextCommandDefault“ stellt die Standarddefinition für ein LICR-Objekt bereit, das immer dann verwendet wird, wenn in der aktuellen Kodierung keine spezifische Einstellung für ein Objekt vorhanden ist. Solche Definitionen können beispielsweise ein bestimmtes Zeichen vortäuschen. „\textregistered“ hat beispielsweise eine Standarddefinition, in der das Zeichen aus zwei anderen zusammengesetzt ist, wie folgt:
1\DeclareTextCommandDefault{\textregistered}{\textcircled{\scshape r}}Technisch gesehen werden Standarddefinitionen als Kodierung mit dem Namen „?“ gespeichert. Obwohl Sie sich nicht auf diese Tatsache verlassen sollten, da sich die Implementierung in Zukunft ändern kann, bedeutet dies, dass Sie keine Kodierung mit diesem Namen deklarieren können.
1\DeclareTextSymbolDefault{LICR-object}{encoding}In den meisten Fällen erfordert eine Standarddefinition keine Codierung, sondern weist LaTeX einfach an, das Zeichen aus einer Codierung zu übernehmen, in der es bekanntermaßen existiert. Das Paket „textcomp“ enthält beispielsweise eine große Anzahl von Standarddeklarationen, die alle auf die Kodierung „TS1“ verweisen. Zum Beispiel:
1\DeclareTextSymbolDefault{\texteuro}{TS1}Der Befehl „\DeclareTextSymbolDefault“ kann verwendet werden, um den Standard für jedes LICR-Objekt ohne Argumente zu definieren, nicht nur für diejenigen, die mit dem Befehl „\DeclareTextSymbol“ in anderen Kodierungen deklariert wurden.
1\DeclareTextAccentDefault{LICR-accent}{encoding}Es gibt eine ähnliche Deklaration für LICR-Objekte, die ein Argument annehmen, beispielsweise Akzente. Auch dieses Formular kann für jedes LICR-Objekt mit einem Argument verwendet werden. Der LaTeX-Kernel enthält beispielsweise eine Reihe von Deklarationen des Typs:
1\DeclareTextAccentDefault{\"}{OT1}
2\DeclareTextAccentDefault{\t}{OML}Das heißt, wenn das „\““ in der aktuellen Kodierung nicht definiert ist, verwenden Sie das Zeichen einer „OT1“-kodierten Schriftart. Um einen Krawattenakzent zu erhalten, verwenden Sie ihn ebenfalls aus „OML“, wenn nichts Besseres verfügbar ist .
1\ProvideTextCommandDefault{LICR-object}[num][default]{code}Die „\ProvideTextCommandDefault“-Deklaration ermöglicht die „Bereitstellung“ einer anderen Art von Standard. Sie erledigt die gleiche Aufgabe wie die „\DeclareTextCommandDefault“-Deklaration, mit der Ausnahme, dass der Standardwert nur dann bereitgestellt wird, wenn zuvor kein Standardwert definiert wurde. Dies wird hauptsächlich in Eingabekodierungsdateien verwendet, um triviale Standardwerte für ungewöhnliche LICR-Objekte bereitzustellen. Zum Beispiel:
1\ProvideTextCommandDefault{\textonequarter}{\ensuremath{\frac14}}
2\ProvideTextCommandDefault{\textcent}{\TextSymbolUnavailable\textcent}Pakete wie „textcomp“ können solche Definitionen dann durch Deklarationen ersetzen, die auf echte Glyphen verweisen. Durch die Verwendung von „\Provide…“ anstelle von „\Declare…“ wird sichergestellt, dass ein besserer Standardwert nicht versehentlich überschrieben wird, wenn die Eingabekodierungsdatei gelesen wird.
1\UndeclareTextCommand{LICR-object}{encoding}In manchen Fällen muss eine vorhandene Deklaration entfernt werden, um sicherzustellen, dass stattdessen eine Standarddeklaration verwendet wird. Dies kann durch die Verwendung von „\UndeclareTextCommand“ erfolgen. Beispielsweise entfernt das Paket „textcomp“ die Definitionen von „\textdollar“ und „\textsterling“ aus der „OT1“-Kodierung, da nicht jede „OT1“-kodierte Schriftart tatsächlich über diese Symbole verfügt.
1\UndeclareTextCommand{\textsterling}{OT1}
2\UndeclareTextCommand{\textdollar} {OT1}Ohne diese Entfernung würden die neuen Standarddeklarationen zur Übernahme der Symbole von „TS1“ nicht für Schriftarten verwendet, die mit „OT1“ codiert sind.
1\UseTextSymbol{encoding}{LICR-object}
2\UseTextAccent{encoding}{LICR-object}{simple-LICR-object}Die hinter den Deklarationen „\DeclareTextSymbolDefault“ und „\DeclareTextAccentDefault“ verborgene Aktion kann auch direkt verwendet werden. Nehmen wir zum Beispiel an, dass die aktuelle Kodierung „U“ ist. In diesem Fall,
1\UseTextSymbol{OT1}{\ss}
2\UseTextAccent{OT1}{\'}{a}hat den gleichen Effekt wie die Eingabe des untenstehenden Codes. Beachten Sie insbesondere, dass das „a“ in der Kodierung „U“ gesetzt wird – nur der Akzent wird aus der anderen Kodierung übernommen.
1{\fontencoding{OT1}\selectfont\ss}
2{\fontencoding{OT1}\selectfont\'{\fontendcoding{U}\selectfont a}}Eine Liste der Standard-LICR-Objekte
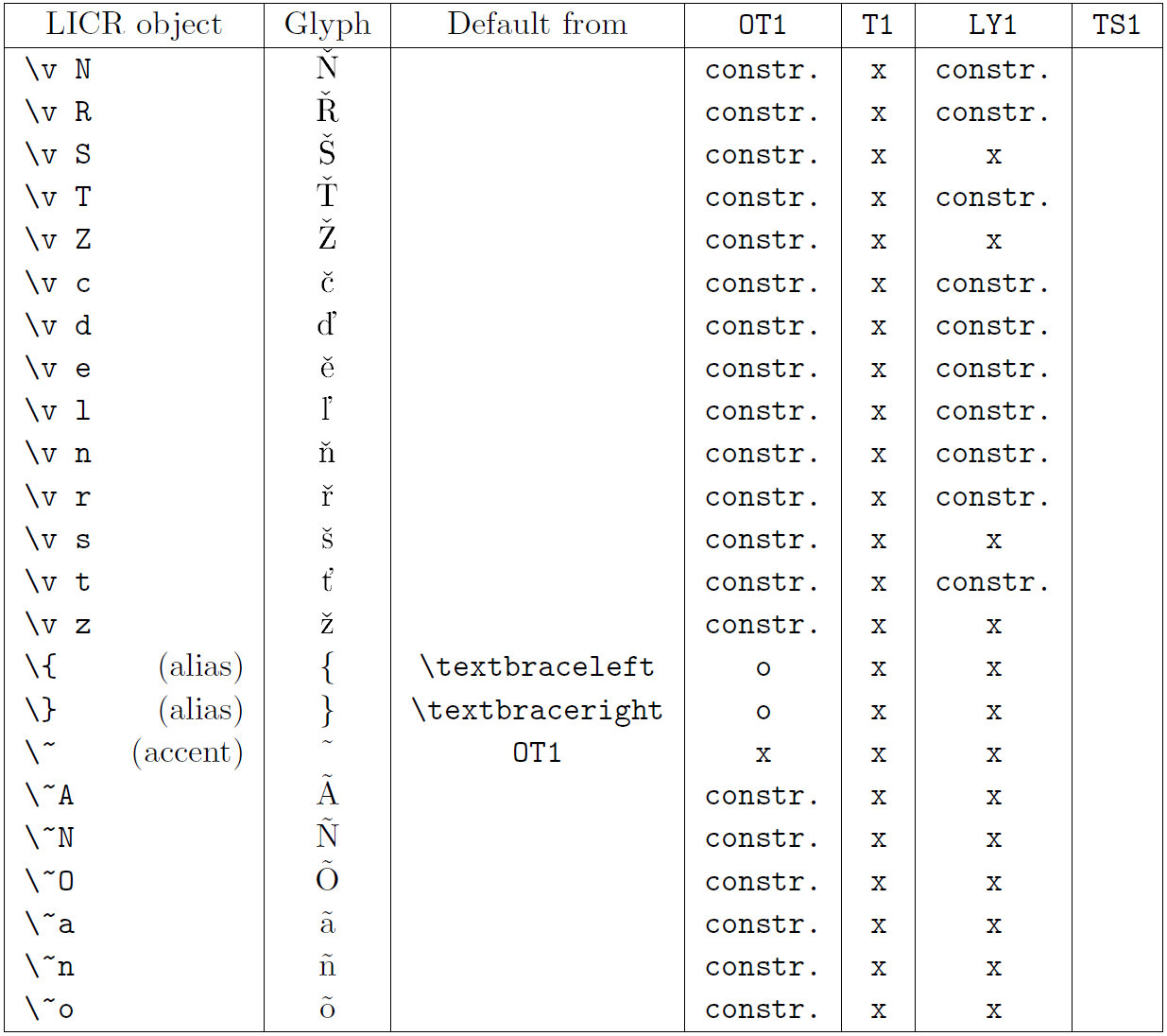
Die Tabelle in diesem Unterabschnitt bietet einen Überblick über die internen Darstellungen von LaTeX, die mit den drei Hauptkodierungen für lateinische Sprachen verfügbar sind: „OT1“ (die ursprüngliche TeX-Kodierung), „T1“ (die LaTeX-Standardkodierung) und „LY1“ ( eine von Y&Y vorgeschlagene alternative 8-Bit-Kodierung). Darüber hinaus werden alle LICR-Objekte angezeigt, die durch „TS1“ (die LaTeX-Standard-Textsymbolkodierung) deklariert wurden und durch das Laden des „textcomp“-Pakets bereitgestellt werden.
Die erste Spalte der Tabelle zeigt die LICR-Objektnamen in alphabetischer Reihenfolge und gibt an, welche LICR-Objekte wie Akzente wirken. Die zweite Spalte zeigt eine Glyphendarstellung des Objekts.
Die dritte Spalte beschreibt, ob das Objekt über eine Standarddeklaration verfügt. Wenn eine Kodierung aufgeführt ist, bedeutet dies, dass die Glyphe standardmäßig aus einer geeigneten Schriftart in dieser Kodierung abgerufen wird; „constr.“ bedeutet, dass der Standard aus Low-Level-TeX-Code erstellt wird; Wenn die Spalte leer ist, bedeutet dies, dass für dieses LICR-Objekt kein Standardwert definiert ist. Im letzten Fall wird der Fehler „Symbol nicht verfügbar“ zurückgegeben, wenn Sie es in einer Codierung verwenden, für die es keine explizite Definition hat. Wenn das Objekt ein Alias für ein anderes LICR-Objekt ist, wird der alternative Name in dieser Spalte aufgeführt.
Die Spalten vier bis sieben zeigen, ob ein Objekt in der angegebenen Kodierung verfügbar ist. Hier bedeutet „x“, dass das Objekt nativ (als Glyphe) in Schriftarten mit dieser Kodierung verfügbar ist, o bedeutet, dass es standardmäßig für alle Kodierungen verfügbar ist, und „constr.“ bedeutet, dass es aus mehreren generiert wird Glyphen, Akzentzeichen oder andere Elemente. Wenn der Standardwert von „TS1“ abgerufen wird, ist das LICR-Objekt nur verfügbar, wenn das Paket „textcomp“ geladen ist.
LICR-Objekte. Teil 1
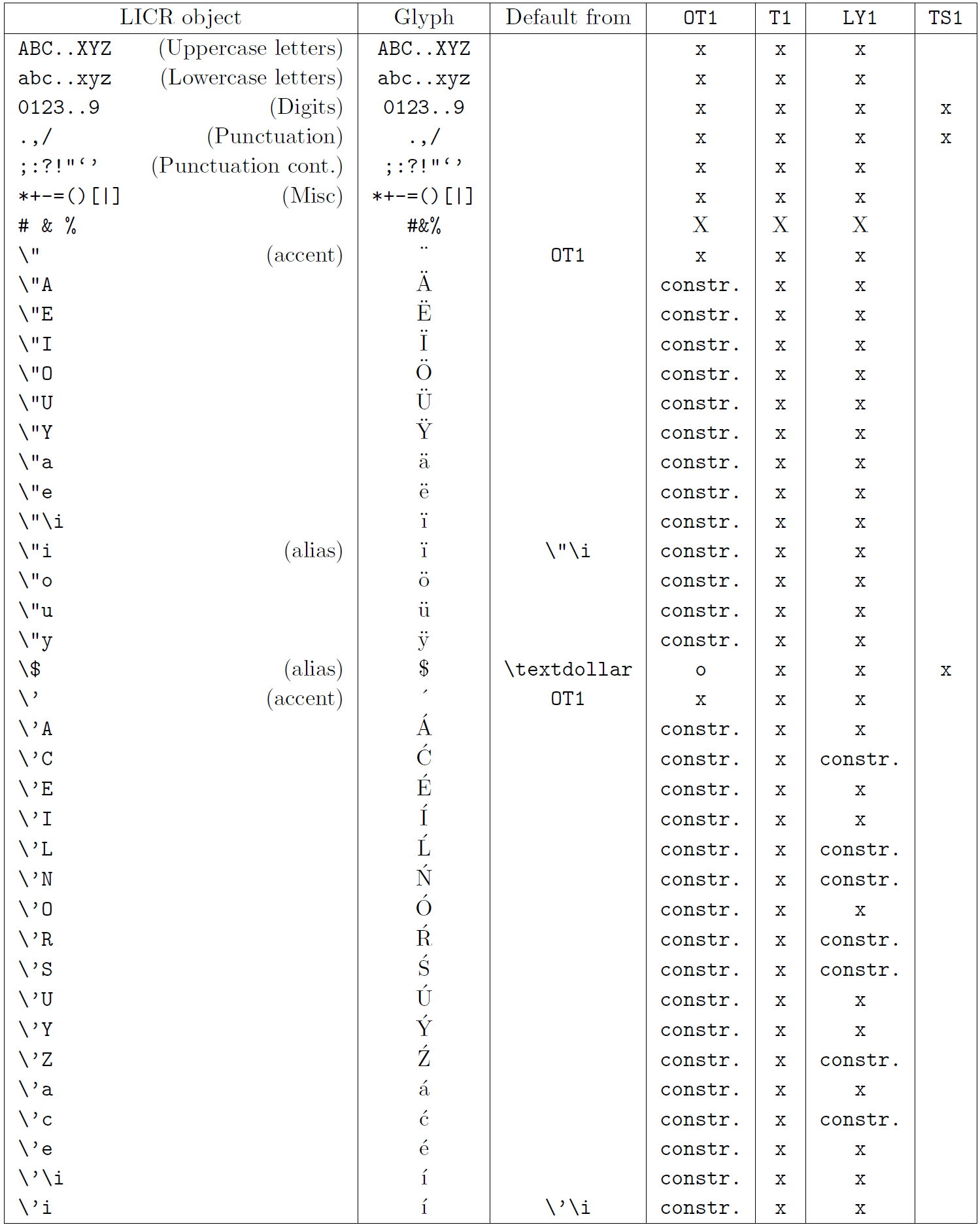
LICR-Objekte. Teil 2
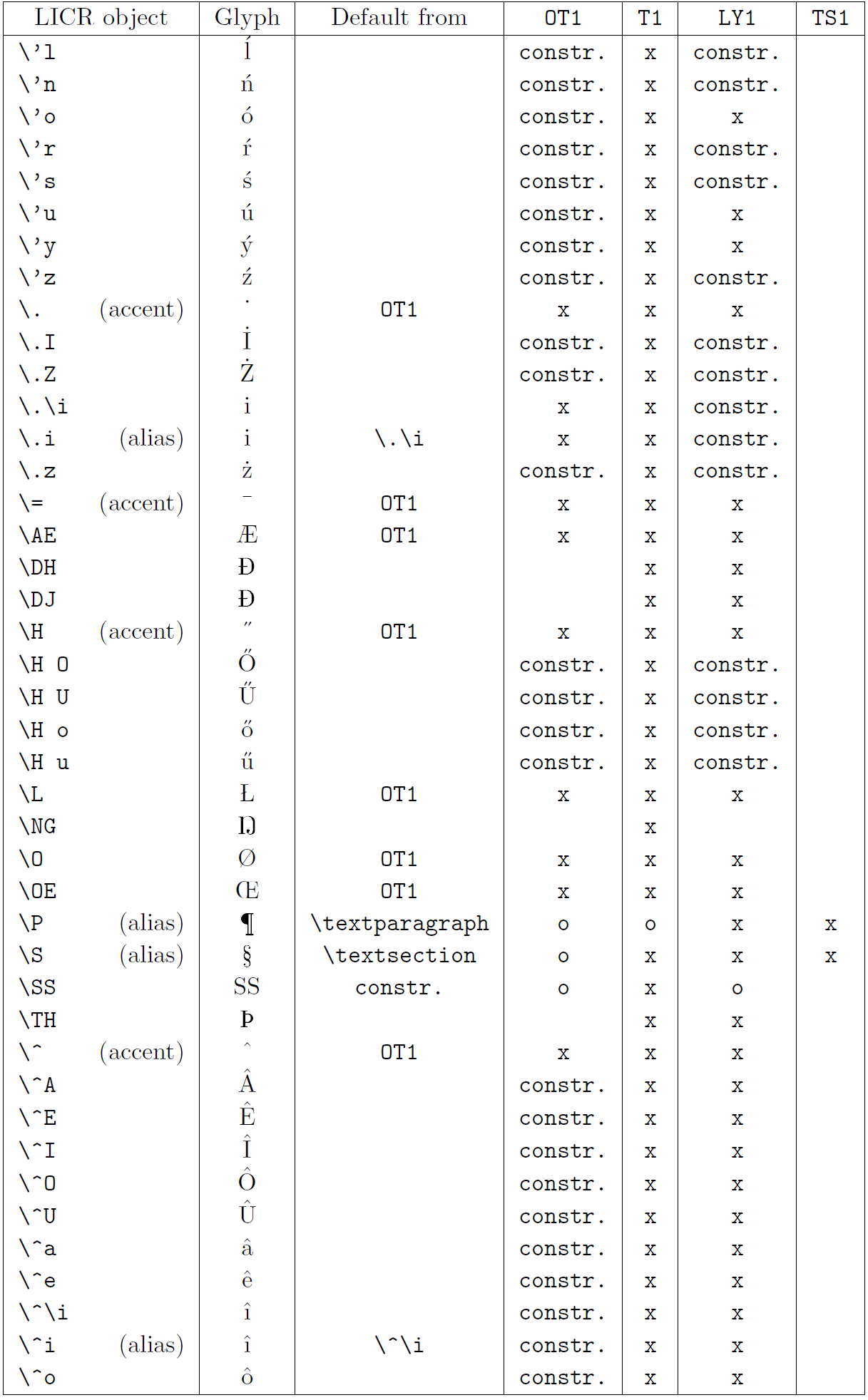
LICR-Objekte. Teil 3
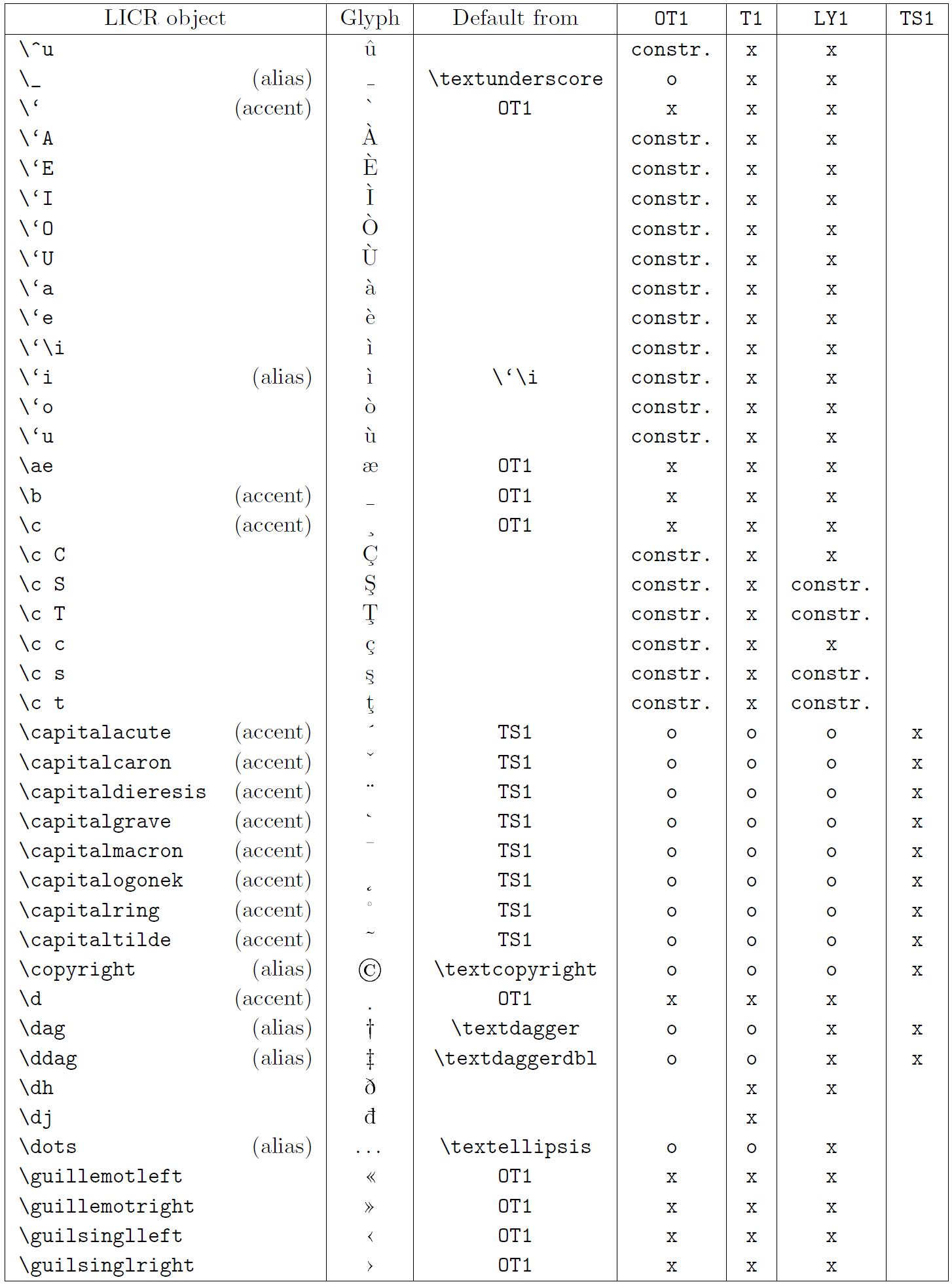
LICR-Objekte. Teil 4
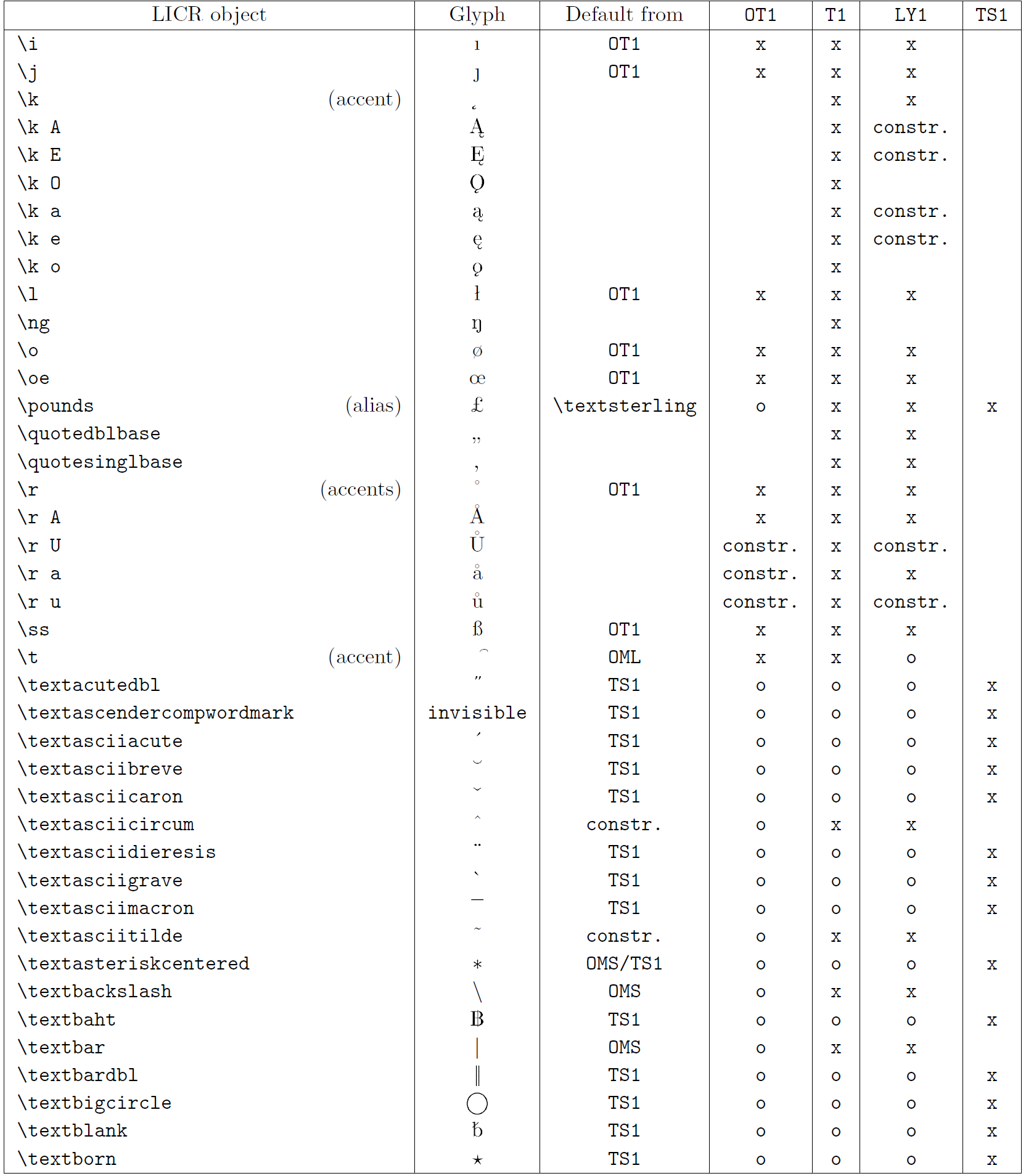
LICR-Objekte. Teil 5
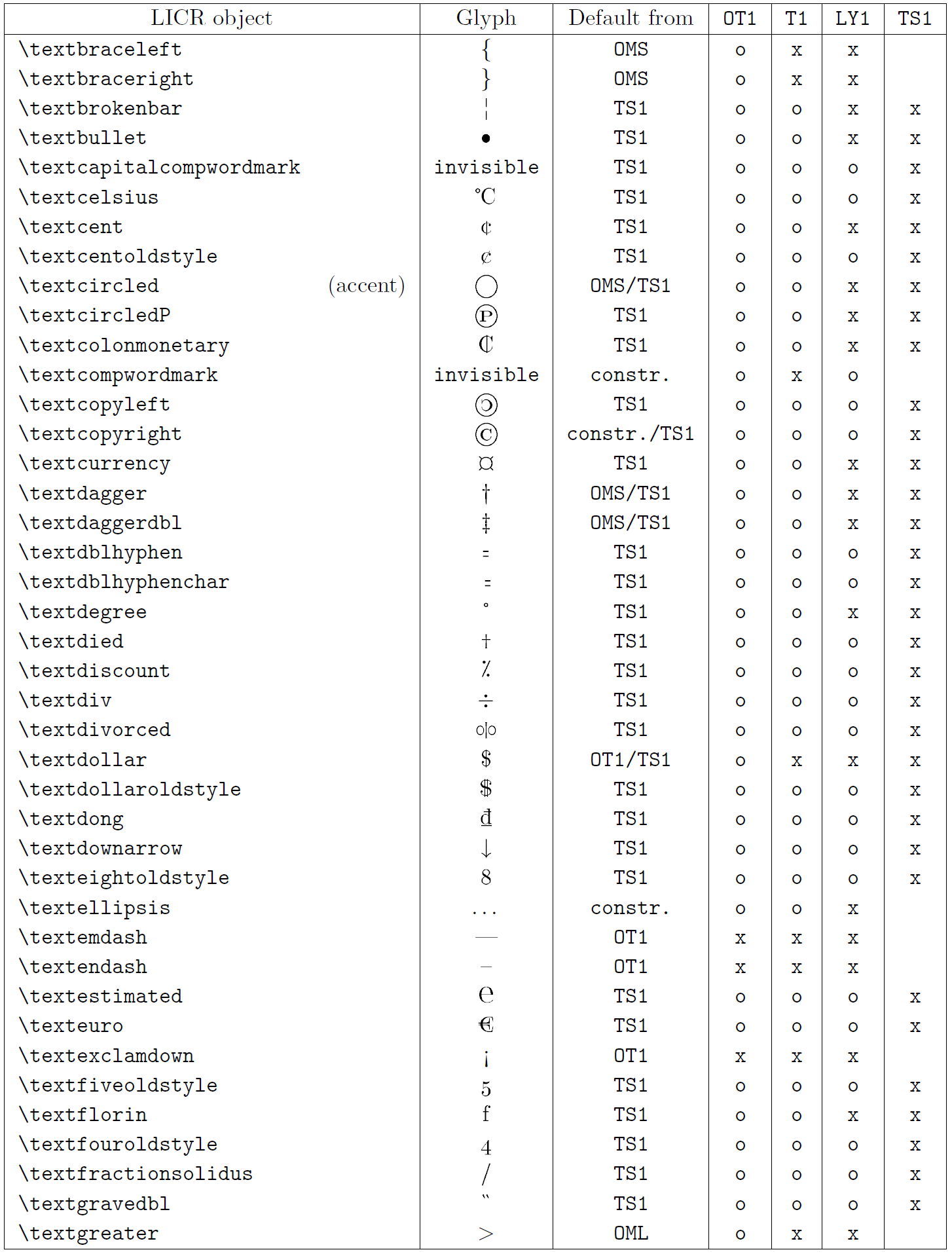
LICR-Objekte. Teil 6
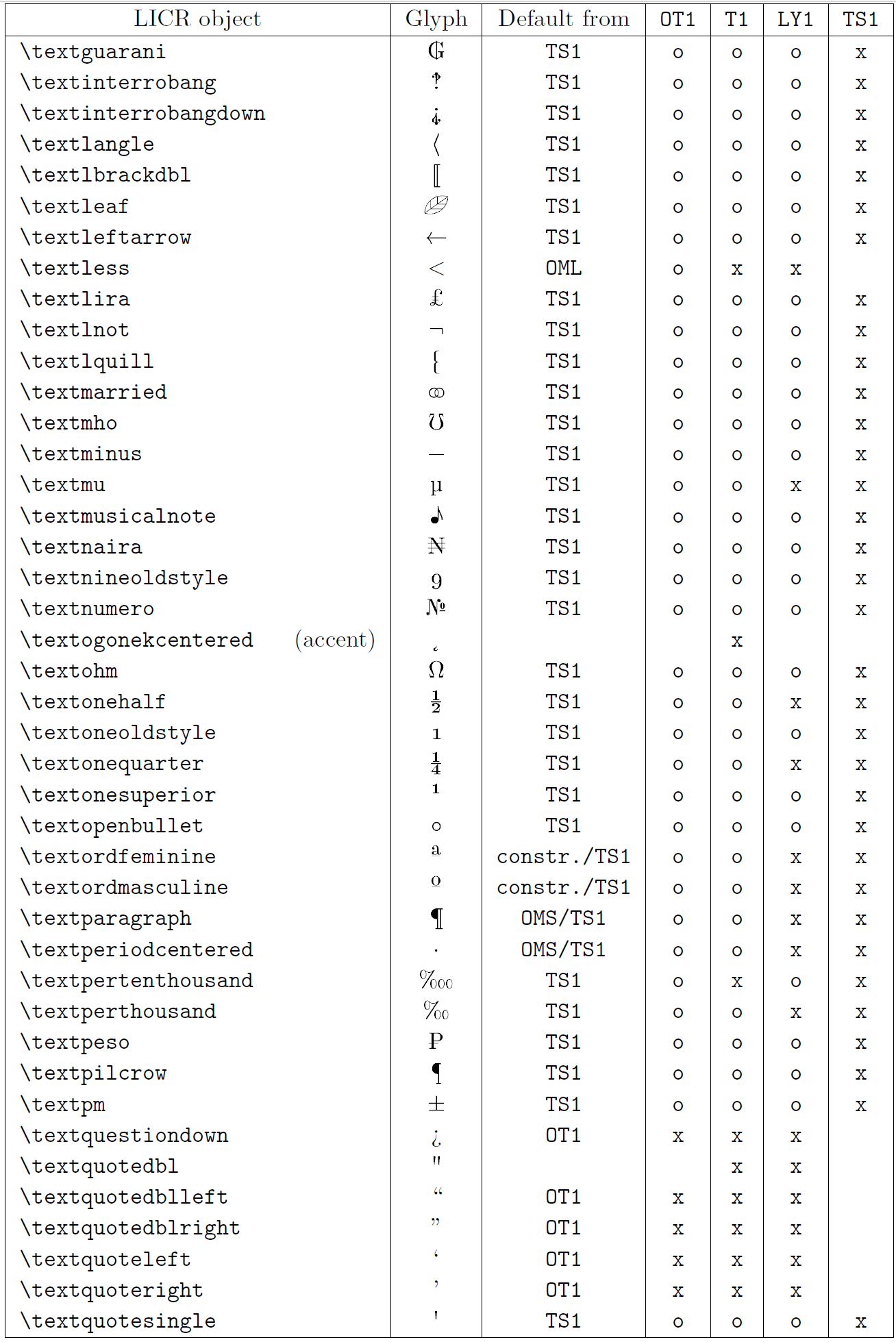
LICR-Objekte. Teil 7
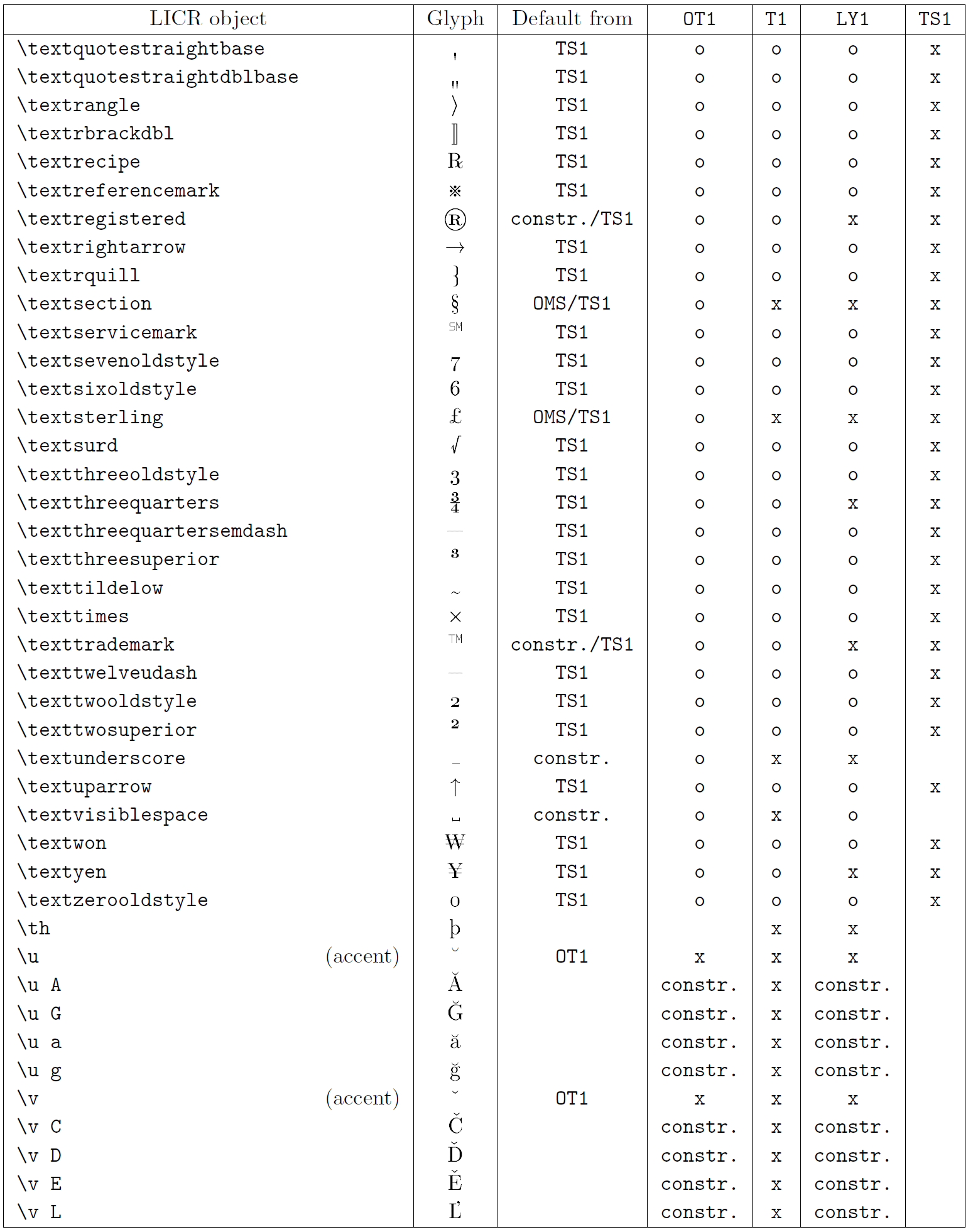
LICR-Objekte. Teil 8