4. Standard-LaTeX-Schriftarten
Dieser Artikel enthält eine kurze Einführung in die Standardtextschriftarten, die zusammen mit LaTeX vertrieben werden. Anschließend wird die Standardunterstützung von LaTeX für Eingabe- und Schriftartenkodierungen behandelt. Der Artikel endet mit einer Beschreibung eines Pakets zum Verfolgen der Schriftartenverarbeitung von LaTeX und eines weiteren Pakets zum Anzeigen von Glyphendiagrammen.
4.1. Computer Modern Roman
Eine Schriftfamilie namens Computer Modern wurde von Donald Knuth zusammen mit TeX entwickelt. Bis Anfang der 1990er Jahre waren nur diese Schriftarten größtenteils mit TeX und damit auch mit LaTeX verwendbar. Jede dieser Schriftarten enthält nur 128 Glyphen, daher können sie keine Akzentzeichen als einzelne Glyphen enthalten. Daher bedeutet die Verwendung dieser Schriftarten, dass akzentuierte Zeichen mit dem Grundelement „\accent“ von TeX erzeugt werden müssen, was wiederum bedeutet, dass eine automatische Silbentrennung von Wörtern mit akzentuierten Zeichen nicht möglich ist. Während diese Einschränkung bei englischen Dokumenten akzeptabel ist, stellt sie für andere Sprachen einen offensichtlichen Nachteil dar.
Diese Mängel bereiteten den TeX-Benutzern in Europa große Sorgen und führten schließlich 1989 zu einer Neuimplementierung von TeX, um 8-Bit-Zeichen intern und extern zu unterstützen. Eine standardmäßige 8-Bit-Kodierung für Textschriften („T1“) wurde 1990 entwickelt. Sie enthält viele diakritische Zeichen und ermöglicht den Satz in mehr als 30 Sprachen basierend auf dem lateinischen Alphabet. Anschließend wurden die Computer Modern-Schriftfamilien neu implementiert und zusätzliche Zeichen entworfen, sodass die resultierenden Schriftarten vollständig diesem Kodierungsschema entsprechen.
4.2. Auswahl der Eingabekodierung: das Paket „inputenc“.
Wenn Sie Akzentzeichen entweder über einzelne Tastenanschläge oder mit einer anderen Eingabemethode eingeben können (z. B. durch Drücken von „“ „“ und dann „a“, um „a-grave“ zu erhalten) und Ihr Computer sie korrekt im anzeigt Editor…

… dann würden Sie einen solchen Text idealerweise direkt mit LaTeX verwenden, anstatt \`a, \^e usw. eingeben zu müssen.
Bei Sprachen wie Französisch und Deutsch ist letzterer Ansatz machbar. Für Sprachen wie Russisch und Griechisch ist jedoch die Möglichkeit einer direkten Eingabe erforderlich, da nahezu jedes Zeichen in diesen Sprachen einen Befehlsnamen als interne LaTeX-Form hat. Beispielsweise enthält die russische Standarddefinition für „\reftextafter“ den folgenden Text (was „auf der nächsten Seite“ bedeutet):
1\cyrn\cyra\ \cyrs\cyrl\cyre\cyrd\cyru\cyryu\cyrshch\cyre\cyrishrt
2\ \cyrs\cyrt\cyrr\cyra\cyrn\cyri\cyrc\cyreEs ist unwahrscheinlich, dass jemand solche Dinge regelmäßig tippen möchte. Dennoch hat es den Vorteil, dass es universell portierbar ist, sodass es auf jeder LaTeX-Installation korrekt interpretiert werden kann. Andererseits das Tippen
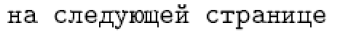
auf einer geeigneten Tastatur ist eindeutig vorzuziehen, wenn es möglich ist, dass LaTeX diese Eingabe versteht. Das Problem besteht darin, dass in einer Datei nicht die Zeichen gespeichert werden, die wir in der obigen Sequenz sehen, sondern Oktette, die die Zeichen darstellen. Unter verschiedenen Umständen (bei Verwendung unterschiedlicher Codierungen) können dieselben Oktette unterschiedliche Zeichen darstellen.
Solange alles auf einem einzigen Computer geschieht und alle Programme Oktette in Dateien auf die gleiche Weise interpretieren, ist normalerweise alles in Ordnung. Wenn ja, ist es sinnvoll, einen automatischen Übersetzungsmechanismus zu aktivieren, der in einige neuere TeX-Implementierungen integriert ist. Wenn jedoch eine in einer solchen Umgebung erstellte Datei an einen anderen Computer gesendet wird, schlägt die Verarbeitung wahrscheinlich fehl oder, noch schlimmer, sie scheint erfolgreich zu sein, führt jedoch tatsächlich zu falschen Ergebnissen, da falsche Zeichen angezeigt werden. Um dieses Problem zu lösen, wurde das Paket „inputenc“ erstellt. Sein Hauptzweck besteht darin, LaTeX über die im Dokument oder in einem Teil des Dokuments verwendete Kodierung zu informieren. Dies geschieht durch Laden des Pakets mit dem Codierungsnamen als Option. Zum Beispiel:
1\usepackage[cp1252]{inputenc} % Windows 1252 (Western Europe) code pageVon diesem Zeitpunkt an weiß LaTeX, wie die Oktette im Rest des Dokuments bei jeder Installation zu interpretieren sind, unabhängig von der Kodierung, die für andere Zwecke auf diesem Computer verwendet wird.
Ein typisches Beispiel ist unten dargestellt. Es handelt sich um einen kurzen Text, der in der in Russland beliebten Kodierung „koi8-r“ geschrieben ist. Der Quellcode zeigt, wie der Text auf einem Computer mit Latin-1-Kodierung aussieht (z. B. in Deutschland). Die Ausgabe zeigt, dass LaTeX den Text immer noch korrekt interpretieren konnte, da ihm mitgeteilt wurde, welche Eingabekodierung verwendet wurde.

Die Liste der derzeit von „inputenc“ unterstützten Kodierungen finden Sie unten. Die Schnittstelle ist gut dokumentiert und die Unterstützung neuer Kodierungen kann problemlos hinzugefügt werden. Daher lohnt es sich, die Dokumentation des „inputenc“-Pakets zu konsultieren, wenn die von Ihrem Computer verwendete Kodierung hier nicht aufgeführt ist. Sie können auch im Internet nach Kodierungsdateien für „inputenc“ suchen, die von anderen Autoren erstellt wurden. Beispielsweise werden Kodierungen für kyrillische Sprachen zusammen mit anderen Schriftartenunterstützungspaketen für kyrillische Sprachen verteilt.
Der ISO-8859-Standard definiert eine Reihe wichtiger Einzelbyte-Kodierungen. Die Kodierungen im Zusammenhang mit dem lateinischen Alphabet werden von „inputenc“ unterstützt. Für das Windows-Betriebssystem wurden von Microsoft eine Reihe von Einzelbyte-Kodierungen definiert. Darüber hinaus sind einige von anderen Computerherstellern definierte Kodierungen verfügbar.
- „latin1“ Dies ist die ISO-8859-1-Kodierung (auch bekannt als Latin 1). Es kann die meisten westeuropäischen Sprachen darstellen, darunter Albanisch, Katalanisch, Dänisch, Niederländisch, Englisch, Färöisch, Finnisch, Französisch, Galizisch, Deutsch, Isländisch, Irisch, Italienisch, Norwegisch, Portugiesisch, Spanisch und Schwedisch.
- „latin2“ Die ISO-Latin-2-Kodierung (ISO-8859-2) unterstützt die slawischen Sprachen Mitteleuropas, die das lateinische Alphabet verwenden. Es kann für die folgenden Sprachen verwendet werden: Kroatisch, Tschechisch, Deutsch, Ungarisch, Polnisch, Rumänisch, Slowakisch und Slowenisch.
- „latin3“ Dieser Zeichensatz (ISO-8859-3) wird für Esperanto, Galizisch, Maltesisch und Türkisch verwendet.
- „latin4“ Die ISO-Latin-4-Kodierung (ISO-8859-4) kann Sprachen wie Estnisch, Lettisch und Litauisch darstellen.
- „latin5“ Die ISO-Latin-5-Kodierung (ISO 8859-9) ist eng mit Latin 1 verwandt und ersetzt die selten verwendeten isländischen Buchstaben von Latin 1 durch türkische Buchstaben.
- „latin9“ Latin 9 (oder ISO-8859-15) ist eine weitere kleine Variante von Latin 1, die das Euro-Währungszeichen sowie einige andere Zeichen, wie die Ligatur „\AE“, hinzufügt, die im Französischen und fehlten Finnisch. Als Ersatz für Latein 1 erfreut es sich immer größerer Beliebtheit.
- „cp437“ IBM 437-Codepage (MS-DOS-Latein, enthält aber viele grafische Zeichen zum Zeichnen von Feldern).
- „cp850“ IBM 850-Codepage (MS-DOS mehrsprachig, ähnlich wie latin1).
- „cp852“ IBM 852-Codepage (MS-DOS mehrsprachig, ähnlich wie latin2).
- „cp858“ IBM 858-Codepage (IBM 850 mit hinzugefügtem Euro-Symbol).
- „cp865“ IBM 865-Codepage (MS-DOS Norwegen).
- Codepage „cp1250“ für Windows 1250 (Mittel- und Osteuropa).
- „cp1252“ Codepage für Windows 1252 (Westeuropa).
- „cp1257“ Windows 1257 (Baltic)-Codepage.
- „ansinew“ Windows 3.1 ANSI-Kodierung; ein Synonym für cp1252.
- „decmulti“ DEC-Kodierung für multinationale Zeichensätze.
- „Applemac“ Macintosh-Kodierung (Standard).
macceMacintosh Mitteleuropäische Codepage.nextWeiter Computerkodierung.utf8Unicodes UTF8-Codierungsunterstützung.
Die meisten TeX-Installationen akzeptieren standardmäßig 8-Bit-Zeichen. Dennoch können die Ergebnisse ohne weitere Anpassungen, wie sie von „inpuenc“ durchgeführt werden, unvorhersehbar sein: Einige Zeichen verschwinden möglicherweise, oder Sie erhalten möglicherweise das Zeichen, das in der aktuellen Schriftart an der angegebenen Oktettstelle vorhanden ist, was möglicherweise der Fall ist oder nicht die gewünschte Glyphe. Dieses Verhalten war lange Zeit die Standardeinstellung und wurde daher in LaTeX2e nicht geändert, da einige Leute darauf angewiesen sind. Um jedoch sicherzustellen, dass solche Fehler abgefangen werden, bietet „inputenc“ die Option „ascii“, die jedes Zeichen außerhalb des Bereichs 32-126 illegal macht.
1\inputencoding{encoding}Ursprünglich war das Paket „inputenc“ dazu gedacht, die für ein Dokument als Ganzes verwendete Kodierung anzugeben – daher die Verwendung von Optionen in der Präambel. Es ist jedoch möglich, die Kodierung mitten in einem Dokument zu ändern, indem Sie den Befehl „\inputencoding“ verwenden. Dieser Befehl verwendet den Namen einer Kodierung als Argument.
Als „inputenc“ entwickelt wurde, liefen die meisten LaTeX-Installationen auf Computern, die Einzelbyte-Kodierungen wie die in diesem Abschnitt besprochenen verwendeten. Heutzutage ist jedoch eine andere Kodierung beliebt, da die Systeme Unicode unterstützen: UTF8. Diese Codierung mit variabler Länge stellt Unicode-Zeichen in ein bis vier Oktetten dar. Codierungsunterstützung wurde zu „inputenc“ über die Option „utf8“ hinzugefügt. Technisch gesehen bietet es keine vollständige UTF8-Implementierung. Es werden nur Unicode-Zeichen zugeordnet, die teilweise in Standard-LaTeX-Schriftarten dargestellt werden (d. h. hauptsächlich lateinische und kyrillische Zeichensätze); alle anderen führen zu einer entsprechenden Fehlermeldung. Darüber hinaus werden Unicode-Kombinationszeichen nicht unterstützt, obwohl diese spezielle Auslassung in der Praxis kein Problem darstellen sollte.
1\usepackage[utf8]{inputenc}
2\usepackage{textcomp} % for Latin interpretation
3-----------------------------------------------
4German umlauts in UTF-8: ^^c3^^a4^^c3^^b6^^c3^^bc
5\par\inputencoding{latin1}% switch to Latin 1
6But interpreted as Latin 1: ^^c3^^a4^^c3^^b6^^c3^^bc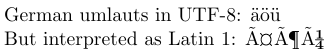
In UTF8 stellen ASCII-Zeichen sich selbst dar und die meisten lateinischen Zeichen werden durch zwei Bytes dargestellt. Im Quellcode des Beispiels werden die Zwei-Byte-Darstellungen der deutschen Umlaute in UTF8 in der Hexadezimalschreibweise von TeX angezeigt, d. h. mit jedem Oktett mit vorangestelltem „^^“. In einem Editor, der UTF8 nicht versteht, würden sie wahrscheinlich als ähnlich zu der Ausgabe angesehen werden, die erzeugt wird, wenn sie als lateinische 1-Zeichen interpretiert werden.
Ein Paket mit umfassenderer UTF8-Unterstützung (einschließlich Unterstützung für koreanische, chinesische und japanische Zeichen), wenn auch folglich komplexer im Aufbau, ist das von Dominique Unruh geschriebene Paket „ucs“. Sie können es versuchen, wenn die „inputenc“-Lösung Ihre Anforderungen nicht erfüllt.
4.3. Auswählen von Schriftartenkodierungen mit dem Paket „fontenc“.
Um eine Textfont-Kodierung für die Verwendung mit LaTeX zu aktivieren, muss die Kodierung in die Präambel oder die Dokumentklasse geladen werden. Genauer gesagt müssen die Definitionen für den Zugriff auf die Glyphen in Schriftarten mit einer bestimmten Kodierung geladen werden. Der kanonische Weg, dies zu tun, ist das Paket „fontenc“, das eine durch Kommas getrennte Liste von Schriftartenkodierungen als Paketoption verwendet. Die letzte dieser Kodierungen wird automatisch zur Standarddokumentkodierung gemacht. Wenn kyrillische Kodierungen geladen werden, wird die Liste der von „\MakeUppercase“ und „\MakeLowercase“ betroffenen Befehle automatisch erweitert. Zum Beispiel,
1\usepackage[T2A,T1]{fontenc}lädt alle notwendigen Definitionen für die kyrillischen Kodierungen „T2A“ und „T1“ und legt letztere als Standarddokumentkodierung fest.
Im Gegensatz zum normalen Paketverhalten kann man dieses Paket mehrmals mit unterschiedlichen Optionen für den Befehl \usepackage laden. Dies ist erforderlich, damit eine Dokumentklasse einen bestimmten Satz von Kodierungen laden kann und der Benutzer in der Präambel noch weitere Kodierungen laden kann. Das mehrmalige Laden von Kodierungen erfolgt ohne Nebenwirkungen, abgesehen von der möglichen Änderung der Standardschriftartkodierung des Dokuments.
Wenn im Dokument Sprachunterstützungspakete (z. B. solche, die mit dem babel-System geliefert werden) verwendet werden, kommt es häufig vor, dass die erforderlichen Schriftartenkodierungen bereits vom Unterstützungspaket geladen werden.
4.4. So verfolgen Sie die Schriftartenauswahl mit dem Paket „tracefnt“.
Um Probleme im Schriftartenauswahlsystem zu erkennen, können Sie das Paket „tracefnt“ verwenden. Es unterstützt mehrere Optionen, mit denen Sie die Menge der von NFSS auf dem Bildschirm und in der Transkriptdatei angezeigten Informationen anpassen können.
errorshowDiese Option unterdrückt alle Warnungen und Informationsmeldungen auf dem Terminal; sie werden nur in die Transkriptdatei geschrieben. Es werden nur echte Fehler angezeigt. Sie sollten die Transkriptdatei sorgfältig studieren, bevor Sie eine wichtige Veröffentlichung drucken, da Warnungen zu Schriftartersetzungen usw. dazu führen können, dass das Endergebnis falsch ist.- „warningshow“ Wenn diese Option angegeben ist, werden Warnungen und Fehler auf dem Terminal angezeigt. Diese Einstellung liefert Ihnen genauso detaillierte Informationen wie LaTeX2e, ohne dass das Paket „tracefnt“ geladen ist.
- „infoshow“ Diese Option ist die Standardeinstellung, wenn Sie das „tracefnt“-Paket laden. Zusätzliche Informationen, die normalerweise nur in die Transkriptdatei geschrieben werden, werden jetzt auch auf Ihrem Terminal angezeigt.
debugshowDiese Option zeigt zusätzlich Informationen über Änderungen an der Textschriftart und die Wiederherstellung solcher Schriftarten am Ende einer Klammergruppe oder am Ende einer Umgebung an. Seien Sie vorsichtig, wenn Sie diese Option aktivieren, da dadurch sehr große Transkriptdateien erstellt werden können.- „Pause“ Diese Option wandelt alle Warnungen in Fehler um, um die Erkennung von Problemen in wichtigen Veröffentlichungen zu erleichtern.
- „Laden“ Diese Option zeigt das Laden externer Schriftarten an. Wenn das von Ihnen verwendete Format oder die Dokumentklasse jedoch bereits einige Schriftarten geladen hat, werden diese von dieser Option nicht angezeigt.
4.5. So zeigen Sie Schriftartentabellen und Beispiele mit „nfssfont.tex“ an
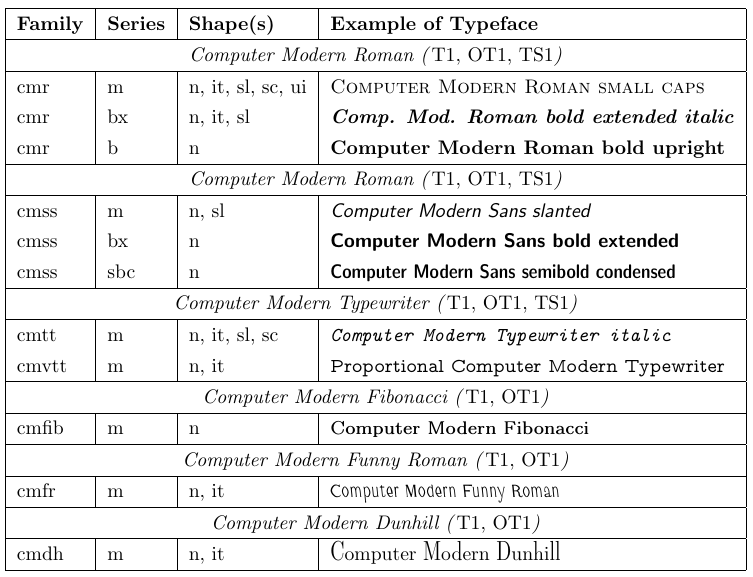
Mit der Datei „nfssfont.tex“ können Sie neue Schriftarten testen, Schriftartentabellen mit allen Zeichen erstellen und andere mit Schriftarten verbundene Vorgänge ausführen. Sie finden diese Datei in jeder LaTeX-Distribution. Wenn Sie diese Datei über LaTeX ausführen, werden Sie nach dem Namen der zu testenden Schriftart gefragt. Die Antwort kann entweder der externe Schriftartname ohne Erweiterung sein – etwa „cmr10“ (Computer Modern Roman 10pt) – sofern Sie ihn kennen, oder ein leerer Schriftartname. Im letzteren Fall werden Sie aufgefordert, eine NFSS-Schriftartspezifikation einzugeben: einen Kodierungsnamen (Standard „T1“), einen Schriftfamiliennamen (Standard „cmr“), eine Schriftserie (Standard „m“), eine Schriftform ( Standardwert „n“) und eine Schriftgröße (Standardwert „10pt“). Das Programm lädt dann die externe Datei, die dieser Klassifizierung entspricht.
Als nächstes werden Sie aufgefordert, einen Befehl einzugeben. Das wichtigste ist wahrscheinlich „\table“, das ein Schriftartendiagramm wie das folgende erzeugt. Interessant ist auch der Befehl „\text“, da er ein längeres Textbeispiel erzeugt. Um zu einer neuen Testschriftart zu wechseln, geben Sie „\init“ ein; Um den Test zu beenden, geben Sie „\bye“ oder „\stop“ ein; und um mehr über alle anderen verfügbaren Tests zu erfahren, geben Sie „\help“ ein.
1**********************************************
2* NFSS font test program version <v2.2b>
3*
4* Follow the instructions
5**********************************************
6
7Input external font name, e.g., cmr10
8(or <enter> for NFSS classification of font):
9
10\currfontname=cmr10
11Now type a test command (\help for help):)
12*\table
13
14*\newpage
15*\init
16Input external font name, e.g., cmr10
17(or <enter> for NFSS classification of font):
18
19\currfontname=
20*** NFSS classification ***
21
22Font encoding [T1]:
23
24\encoding=OT1
25(ot1enc.def)
26Font family [cmr]:
27
28\family=cmdh
29Font series [m]:
30
31\series=m
32Font shape [n]:
33
34\shape=n
35Font size [10pt]:
36
37\size=10
38(ot1cmdh.fd) Now type a test command (\help for help):
39*\text
40
41*\bye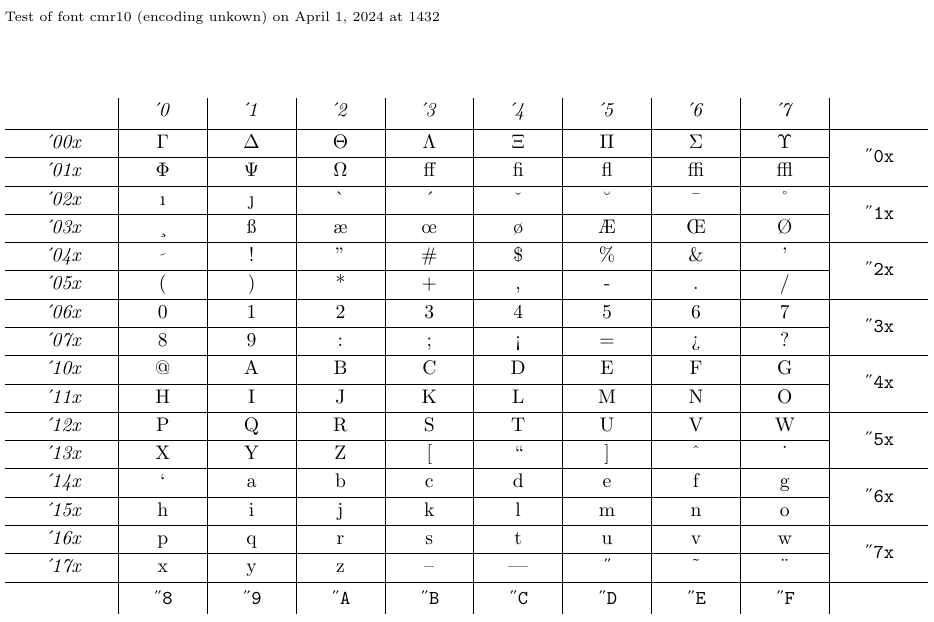

There are two points to be aware of. First, the
nfssfont.texprogram issues an implicit\initcommand, so the first line of input should either contain a font name or be completely empty to indicate that an NFSS classification follows. Second, the input to\initmust appear on individual lines with nothing else (not even a comment) because the line ending indicates the end of the response to a prompt likeFont encoding[T1]: \encoding=that you will get.