7. Modelo de LaTeX para codificaciones de caracteres.
Este artículo cubre las codificaciones LaTeX en detalle. Comienza con una discusión sobre el flujo de datos de caracteres dentro del sistema LaTeX. A continuación, analizamos más de cerca el modelo de representación interna para datos de caracteres dentro de LaTeX, seguido de una discusión de los mecanismos utilizados para mapear datos entrantes a través de codificaciones de entrada en esa representación interna. Finalmente, explicamos cómo se traduce la representación interna, a través de las codificaciones de salida, a la forma requerida para la composición tipográfica.
7.1. El flujo de datos de caracteres dentro de LaTeX
El procesamiento de un documento con LaTeX comienza interpretando los datos presentes en uno o más archivos fuente. Estos datos que representan el contenido del documento se almacenan en archivos fuente como secuencias de octetos que representan caracteres. Para interpretar correctamente estos octetos, cualquier programa (incluido LaTeX) utilizado para procesar el archivo debe conocer el mapeo entre los caracteres abstractos y los octetos que los representan. En otras palabras, debe conocer la codificación que se utilizó cuando se escribió el archivo.
Con una asignación incorrecta, todo procesamiento posterior será más o menos erróneo a menos que el archivo contenga sólo caracteres de un subconjunto común tanto en codificaciones correctas como incorrectas. LaTeX hace una suposición fundamental en este punto: casi todos los caracteres ASCII visibles (32-126 decimales) están representados por el número que tienen en la tabla de códigos ASCII.

Una razón para esta suposición es que la mayoría de las codificaciones de 8 bits que se utilizan hoy en día comparten un plano común de 7 bits. Otra razón es que, para usar TeX efectivamente, la mayoría de la porción visible de ASCII necesita ser procesada como caracteres de categoría letra - ya que sólo los caracteres con esta categoría pueden usarse en nombres de comandos de múltiples caracteres en TEX - o categoría otro - ya que TEX no reconocerá, por ejemplo, los dígitos decimales como parte de un número si no tienen este código de categoría.
Cuando un carácter (o, más precisamente, un número de 8 bits) se declara de categoría letra u otro en TeX, entonces este número de 8 bits se pasará de forma transparente a través de TeX. Eso significa que TeX escribirá cualquier símbolo que esté en la fuente en la posición indicada por ese número.
Como consecuencia de la suposición antes mencionada, las fuentes destinadas a ser utilizadas para texto general requieren que (la mayoría de) los caracteres ASCII visibles estén presentes en la fuente y codificados de acuerdo con la codificación ASCII.
A todos los demás números de 8 bits (aquellos fuera del ASCII visible) potencialmente presentes en el archivo de entrada se les asigna un código de categoría activo, lo que hace que actúen como comandos dentro de TeX. Por lo tanto, LaTeX puede transformarlos a través de las codificaciones de entrada en una forma que llamaremos representación de caracteres internos de LaTeX (LICR).
En cuanto a la codificación UTF8 de Unicode, se maneja de manera similar. Los caracteres ASCII se representan a sí mismos y los octetos iniciales para la representación multibyte actúan como caracteres activos que escanean la entrada en busca de los octetos restantes. El resultado se convertirá en un objeto en LICR si está asignado, o LaTeX arrojará un error si el carácter Unicode dado no está asignado.
Lo más importante de los objetos en LICR es que la representación de caracteres ASCII de 7 bits es invariable ante cualquier cambio de codificación, porque se supone que todas las codificaciones de entrada son transparentes con respecto al ASCII visible. Las codificaciones de salida (o fuente) sirven entonces para asignar las representaciones de caracteres internos a las posiciones de los glifos en la fuente actual utilizada para la composición tipográfica o, en algunos casos, para iniciar acciones más complejas. Por ejemplo, puede colocar un acento (presente en una posición en la fuente actual) sobre algún símbolo (en una posición diferente en la fuente actual) para obtener una imagen impresa del carácter abstracto representado por los comandos en el formato interno. codificación de caracteres.
El LICR codifica todos los caracteres posibles direccionables dentro de LaTeX. Por lo tanto, es mucho mayor que la cantidad de caracteres que pueden representarse con una sola fuente TeX (que puede contener como máximo 256 glifos). En algunos casos, un carácter de la codificación interna se puede representar con una fuente combinando glifos, como caracteres acentuados. Sin embargo, cuando el carácter interno requiere una forma especial, no hay forma de falsificarlo si ese glifo no está presente en la fuente.
Sin embargo, el modelo de LaTeX para codificaciones de caracteres admite mecanismos automáticos para recuperar glifos de diferentes fuentes, de modo que los caracteres que faltan en la fuente actual se compongan, siempre que esté disponible una fuente adicional adecuada que los contenga.
7.2. Representación de caracteres internos de LaTeX (LICR)
Los caracteres de texto se representan internamente en LaTeX de tres maneras.
Representación como personajes.
Un pequeño número de personajes están representados por “ellos mismos”. Por ejemplo, la A latina se representa como el carácter ‘A’. Estos personajes se muestran en la tabla anterior. Forman un subconjunto de ASCII visible, y dentro de TeX, a todos ellos se les asigna el código de categoría de letra u otro. Algunos caracteres del rango ASCII visible no se representan de esta forma, ya sea porque forman parte de la sintaxis TeX o porque no están presentes en todas las fuentes. Si uno usa, por ejemplo, ‘<’ en el texto, la codificación de fuente actual determina si se obtiene < (T1) o quizás un signo de exclamación invertido (OT1) en la salida impresa.
Representación como secuencias de caracteres.
El mecanismo de ligadura interna de TeX puede generar nuevos caracteres a partir de una secuencia de caracteres de entrada. En realidad, esto es una propiedad de la fuente, aunque algunas de estas secuencias se han diseñado explícitamente para servir como atajos de entrada para caracteres que de otro modo serían difíciles de abordar con la mayoría de los teclados. Sólo unos pocos caracteres generados de esta manera se consideran pertenecientes a la representación interna de LaTeX. Estos incluyen el guión largo y el guión largo, que se generan mediante las ligaduras -- y ---, y las comillas dobles de apertura y cierre, que se generan mediante `` y ''. (esta última generalmente también se puede representar con un solo "). Si bien la mayoría de las fuentes también implementan !` y ?` para generar signos de exclamación e interrogación invertidos, esto no es disponible universalmente en todas las fuentes. Es por eso que todos estos caracteres tienen una representación interna alternativa como un comando (por ejemplo, \textendash o \textexclamdown).
Representación como comandos “específicos de codificación de fuente”
La tercera forma de representar caracteres internamente en LaTeX, que cubre la mayoría de los caracteres, es con comandos especiales de LaTeX (o secuencias de comandos) que permanecen sin expandirse cuando se escriben en un archivo o cuando se colocan en un argumento en movimiento. Nos referiremos a estos comandos especiales como comandos específicos de codificación de fuente porque su significado depende de la codificación de fuente utilizada actualmente cuando LaTeX esté listo para componerlos. Estos comandos se declaran mediante declaraciones especiales, como veremos a continuación, que normalmente requieren definiciones individuales para cada codificación de fuente. Si no existe una definición para la codificación actual, se utiliza un valor predeterminado (si está disponible) o se presenta un mensaje de error al usuario. Cuando se cambia la codificación de fuente en algún punto del documento, las definiciones de los comandos específicos de codificación no cambian inmediatamente, ya que eso significaría cambiar una gran cantidad de comandos en el acto. En cambio, estos comandos están implementados de tal manera que, una vez utilizados, detectan si su definición actual ya no es adecuada para la codificación de fuente vigente. En tal caso, llaman a sus homólogos con la codificación de fuente actual para que realicen el trabajo real.
El conjunto de comandos específicos de codificación de fuentes no es fijo, pero se define implícitamente como la unión de todos los comandos definidos para codificaciones de fuentes individuales. Por lo tanto, es posible que se requieran nuevos comandos específicos de codificación de fuentes cuando se agregan nuevas codificaciones de fuentes a LaTeX.
7.3. Codificaciones de entrada
Una vez que se carga el paquete inputenc, las dos declaraciones \DeclareInputText y \DeclareInputMath para asignar caracteres de entrada de 8 bits a objetos LICR están disponibles. Deben usarse únicamente para codificar archivos (ver más abajo), paquetes o, si es necesario, en el preámbulo del documento.
Estos comandos toman un número de 8 bits como primer argumento, que se puede dar como un número decimal, un número octal o en notación hexadecimal. Se recomienda utilizar la notación decimal ya que los caracteres ' y/o " pueden tener significados especiales en un paquete de soporte de idioma, como accesos directos a acentos, lo que invalida la notación octal y/o hexadecimal si los paquetes se cargan en el formato incorrecto. orden.
1\DeclareInputText{number}{LICR-object}El comando \DeclareInputText declara asignaciones de caracteres para su uso en texto. Su segundo argumento contiene el comando específico de codificación (o secuencia de comandos), es decir, los objetos LICR a los que se debe asignar el número de carácter. Por ejemplo,
1\DeclareInputText{239}{\"\i}asigna el número 239 a la representación específica de codificación de ‘i-umlaut’, que es \"\i. Los caracteres de entrada declarados de esta manera no se pueden usar en fórmulas matemáticas.
1\DeclareInputMath{number}{math-object}Si el número representa un carácter para usar en fórmulas matemáticas, entonces se debe usar la declaración \DeclareInputMath. Por ejemplo, en la codificación de entrada cp437de (teclado alemán MS-DOS),
1\DeclareInputMath{224}{\alpha}asigna el número 224 al comando \alpha. Es importante tener en cuenta que esta declaración haría que la clave que produce este número solo se pueda utilizar en modo matemático, ya que \alpha no está permitido en ningún otro lugar.
1\DeclareUnicodeCharacter{hex-number}{LICR-object}Esta declaración está disponible solo si se utiliza la opción utf8. Asigna números Unicode a objetos LICR (es decir, caracteres utilizables en texto). Por ejemplo,
1\DeclareUnicodeCharacter{00A3}{\textsterling}
2\DeclareUnicodeCharacter{011A}{\v E}
3\DeclareUnicodeCharacter{2031}{\textpertenthousand}En teoría, debería haber solo un mapeo bidireccional único entre los dos espacios, de modo que todas esas declaraciones puedan realizarse automáticamente cuando se selecciona la opción utf8. En la práctica, las cosas son un poco más complicadas. En primer lugar, proporcionar la tabla completa automáticamente requeriría una gran cantidad de memoria de TeX. Además, hay muchos caracteres Unicode para los cuales no existe ningún objeto LICR y, a la inversa, muchos objetos LICR no tienen equivalente en Unicode. Este problema se resuelve en el paquete inputenc cargando sólo aquellas asignaciones Unicode que corresponden a las codificaciones utilizadas en un documento en particular (hasta donde se conocen) y respondiendo a cualquier otra solicitud de un carácter Unicode con un mensaje de error adecuado. Entonces es tarea del usuario proporcionar la información cartográfica correcta o, si es necesario, cargar una codificación de fuente adicional.
Como mencionamos anteriormente, las declaraciones de codificación de entrada se pueden usar en paquetes o en el preámbulo del documento. Para que todo funcione de esta manera, es importante cargar primero el paquete inputenc, seleccionando así una codificación adecuada. Las declaraciones de codificación de entrada posteriores actuarán como reemplazo (o adición a) aquellas definidas por la codificación de entrada actual.
Al utilizar el paquete inputenc, es posible que vea el comando \@tabacckludge, que significa “tabbing acento kludge”. Es necesario porque la versión actual de LaTeX heredó una sobrecarga de los comandos \=, \` y \', que normalmente denotan ciertos acentos (es decir, son comandos específicos de codificación). pero tienen significados especiales dentro del entorno “tabbing”. Es por eso que las asignaciones que involucran cualquiera de estos acentos deben codificarse de una manera especial. Por ejemplo, si desea asignar 232 al carácter ’e-grave’ (que tiene la representación interna \`e), debe escribir
1\DeclareInputText{232}{\@tabacckludge`e}en lugar de
1\DeclareInputText{232}{\`e}Mapeo a texto y/o matemáticas
Por razones técnicas y conceptuales, TeX hace una distinción muy fuerte entre caracteres que pueden usarse en texto y en matemáticas. A excepción de los caracteres ASCII visibles, los comandos que producen caracteres normalmente se pueden usar en modo texto o matemático, pero no en ambos modos.
Archivos de codificación de entrada para codificaciones de 8 bits
Las codificaciones de entrada se almacenan en archivos con la extensión .def, donde el nombre base es el nombre de la codificación de entrada (por ejemplo, latin1.def). Dichos archivos deben contener solo los comandos discutidos en la sección actual.
El archivo debe comenzar con una línea de identificación que contenga el comando \ProvidesFile, que describe la naturaleza del archivo. Por ejemplo:
1\ProvidesFile{latin1.def}[2000/07/01 v0.996 Input encoding file]Si hay asignaciones a comandos específicos de codificación que podrían no estar disponibles a menos que se carguen paquetes adicionales, se podrían declarar valores predeterminados usando \ProvideTextCommandDefault. Por ejemplo:
1\ProvideTextCommandDefault{\textonehalf}{\ensurement{\frac12}}
2\ProvideTextCommandDefault{\textcent}{\TextSymbolUnavailable\textcent}El comando \TextSymbolUnavailable emite una advertencia que indica que cierto carácter no está disponible con las fuentes utilizadas actualmente. Esto puede ser útil como valor predeterminado cuando dichos caracteres están disponibles solo si se cargan fuentes especiales y no hay una forma adecuada de falsificar los caracteres con caracteres existentes (como era posible con el valor predeterminado \textonehalf).
El resto del archivo debe incluir solo declaraciones de codificación de entrada \DeclareInputText y \DeclareInputMath. Como se mencionó anteriormente, se desaconseja el uso de este último comando, pero se permite. No se deben usar otros comandos dentro de un archivo de codificación de entrada, en particular, ningún comando que impida leer el archivo varias veces (por ejemplo, \newcommand), ya que los archivos de codificación a menudo se cargan varias veces en un solo documento.
Archivos de mapeo de entrada para UTF8
Como se mencionó anteriormente, la asignación de objetos Unicode a LICR está organizada de manera que permite a LaTeX cargar solo aquellas asignaciones que son relevantes para las codificaciones de fuentes utilizadas en el documento actual. Esto se hace intentando cargar para cada codificación <nombre> un archivo <nombre>enc.dfu que, si existe, contiene la información de mapeo para esos caracteres Unicode proporcionados por esa codificación en particular. Además de una serie de declaraciones \DeclareUnicodeCharacter, dichos archivos deben incluir solo una línea \ProvidesFile.
Dado que diferentes codificaciones de fuentes a menudo proporcionan más o menos los mismos caracteres, es bastante común que las declaraciones para el mismo carácter Unicode aparezcan en diferentes archivos .dfu. Por tanto, es muy importante que estas declaraciones en diferentes archivos sean idénticas. De lo contrario, sobrevivirá la declaración cargada en último lugar, que puede ser diferente de un documento a otro.
Por lo tanto, cualquiera que desee proporcionar un nuevo archivo .dfu para alguna codificación que anteriormente no estaba cubierta debe verificar cuidadosamente las definiciones existentes en los archivos .dfu para codificaciones relacionadas. Se garantiza que los archivos estándar proporcionados con inputenc tendrán definiciones uniformes. De hecho, todos ellos se generan a partir de una única lista adecuadamente dividida. Puede encontrar una lista completa de las asignaciones existentes actualmente en el archivo utf8enc.dfu.
7.4. Codificaciones de salida
Ya hemos mencionado que las codificaciones de salida definen la asignación del LICR a los glifos (o construcciones construidas a partir de glifos) disponibles en las fuentes utilizadas para la composición tipográfica. Se hace referencia a estas asignaciones dentro de LaTeX mediante nombres de dos o tres letras (por ejemplo, OT1 y T3). Decimos que una determinada fuente tiene una determinada codificación si el mapeo corresponde a las posiciones de los glifos en la fuente. Echemos ahora un vistazo a los componentes exactos de dicho mapeo.
Los caracteres representados internamente por caracteres ASCII simplemente se pasan a la fuente. En otras palabras, TeX usa el código ASCII para seleccionar un glifo de la fuente actual. Por ejemplo, el carácter ‘A’ con el código ASCII 65 dará como resultado la composición tipográfica del glifo en la posición 65 en la fuente actual. Esta es la razón por la que LaTeX requiere que las fuentes de texto contengan todas esas letras ASCII en sus posiciones de código ASCII, ya que no hay forma de interactuar con este mecanismo básico de TeX. Por lo tanto, para ASCII visible, una asignación uno a uno está implícitamente presente en todas las codificaciones de salida.
Los caracteres representados internamente como secuencias de caracteres ASCII (por ejemplo, “--”) se manejan de la siguiente manera: cuando la fuente actual se carga por primera vez, se informa a TeX que la fuente contiene varios de los llamados programas de ligadura. Estos programas definen ciertas secuencias de caracteres que no deben escribirse directamente sino reemplazarse con otros glifos de la fuente. Por ejemplo, cuando TeX encuentra “--” en la entrada (es decir, código ASCII 45 dos veces), un programa de ligadura puede dirigirlo al glifo en la posición 123 (que luego mantendría el glifo de guión). Nuevamente, no hay forma de interactuar con este mecanismo.
Sin embargo, la mayor parte de la representación interna de caracteres consta de comandos específicos de codificación de fuentes que se asignan mediante las declaraciones que se describen a continuación. Todas las declaraciones tienen la misma estructura en sus dos primeros argumentos: el comando específico de codificación de fuente (o el primer componente del mismo, si es una secuencia de comandos), seguido del nombre de la codificación. Los argumentos restantes dependerán del tipo de declaración.
Entonces, una codificación XYZ se define mediante un conjunto de declaraciones, todas con el nombre XYZ como segundo argumento. Luego, por supuesto, algunas fuentes deben codificarse con esa codificación. De hecho, el desarrollo de codificaciones de fuentes normalmente se hace a la inversa: alguien comienza con una fuente existente y luego proporciona declaraciones apropiadas para usarla. Luego, a esta colección de declaraciones se le asigna un nombre adecuado, como “OT1”. A continuación, tomaremos la fuente ecrm1000 (ver el gráfico de glifos), cuya codificación de fuente se llama T1 en LaTeX, y crearemos declaraciones apropiadas para acceder a los glifos desde una fuente codificada de esta manera. Los caracteres azules en el gráfico de glifos son aquellos que deben estar presentes en la misma posición en cada codificación de texto, ya que pasan de forma transparente a través de LaTeX.
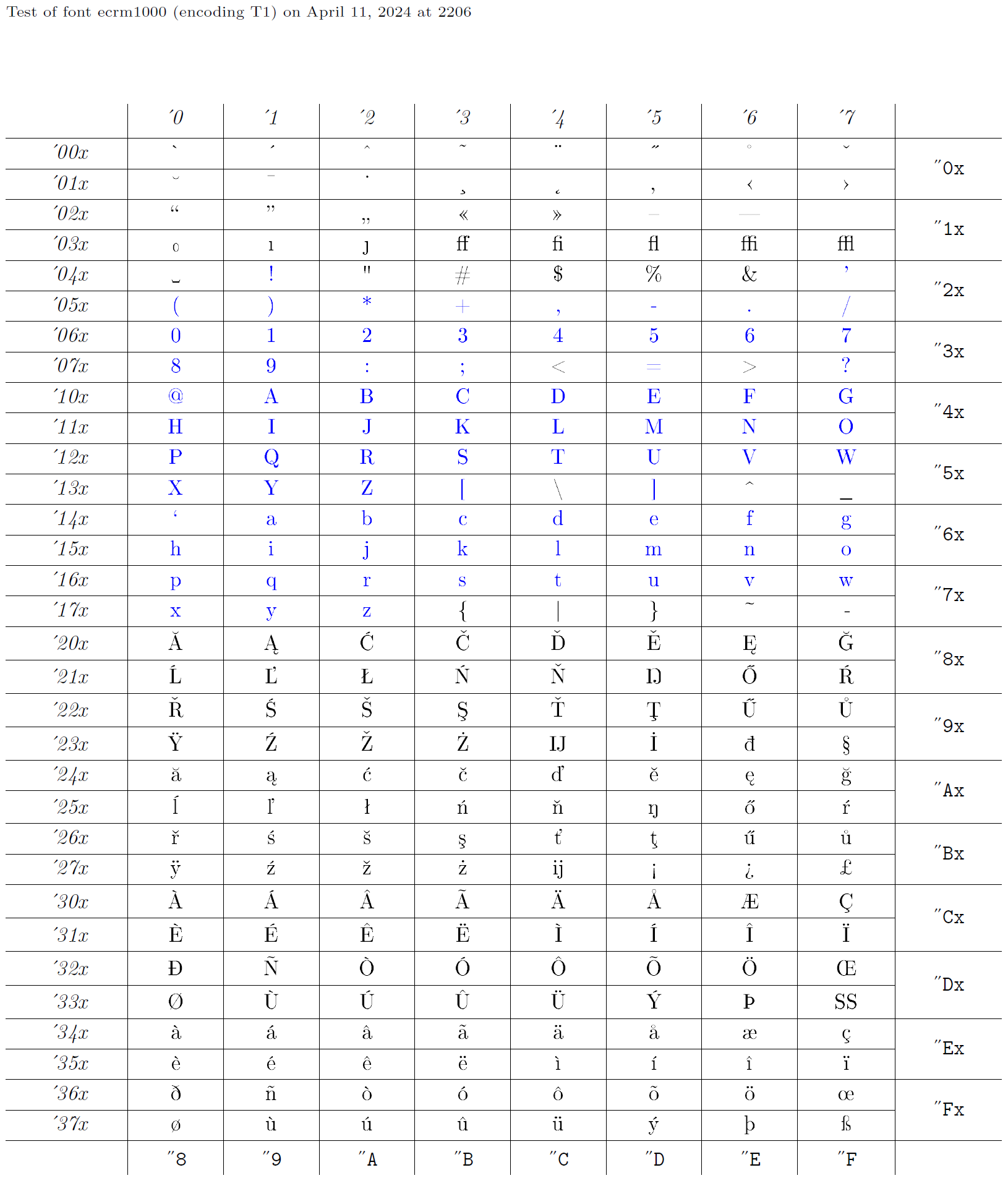
Archivos de codificación de salida
Los archivos de codificación de salida se identifican con la misma extensión .def que los archivos de codificación de entrada. Sin embargo, el nombre base del archivo está un poco más estructurado. Consiste en el nombre de la codificación en letras minúsculas, seguido de “enc” (por ejemplo, “t1enc.def” para la codificación “T1”).
Estos archivos deben incluir únicamente las declaraciones descritas en la sección actual. Dado que LaTeX puede leer los archivos de codificación de salida varias veces, es importante seguir esta regla y abstenerse de utilizar, por ejemplo, \newcommand, que impide leer dicho archivo más de una vez.
Nuevamente, un archivo de codificación de salida comienza con una línea de identificación que describe la naturaleza del archivo. Por ejemplo:
1\ProvidesFile{t1enc.def}[2001/06/05 v1.94 Standard LaTeX file]Antes de declarar cualquier comando específico de codificación para una codificación particular, primero debemos hacer que LaTeX conozca esta codificación. Esto se hace mediante el comando \DeclareFontEncoding. En este punto, también resulta útil declarar las reglas de sustitución predeterminadas para la codificación. Podemos hacerlo usando el comando \DeclareFontSubstitution. Ambas declaraciones se analizan en detalle en
Cómo configurar nuevas fuentes.
1\DeclareFontEncoding{T1}{}{}
2\DeclareFontSubstitution{T1}{cmr}{m}{n}Ahora que hemos introducido la codificación T1 en LaTeX de esta manera, podemos proceder a declarar cómo deben comportarse los comandos específicos de codificación de fuente en esa codificación.
1\DeclareTextSymbol{LICR-Object}{encoding}{slot}La declaración para símbolos de texto parece ser la más sencilla. Aquí, la representación interna se puede asignar directamente a un único glifo en la fuente de destino. Esto se logra utilizando la declaración \DeclareTextSymbol, cuyo tercer argumento (la posición del glifo) se puede dar como un número decimal, octal o hexadecimal. Por ejemplo,
1\DeclareTextSymbol{\ss}{T1}{255}
2\DeclareTextSymbol{\AE}{T1}{'306} %font position as octal number
3\DeclareTextSymbol{\ae}{T1}{"E6} %...as hexadecimal numberdeclara que los comandos específicos de codificación de fuente \ss, \AE y \ae deben asignarse a las posiciones de fuente (decimal) 255, 198 y 230, respectivamente, en un código codificado en T1. fuente. Como mencionamos anteriormente, lo más seguro es utilizar notación decimal en este tipo de declaraciones. De todos modos, mezclar notaciones como en el ejemplo anterior es ciertamente un mal estilo.
1\DeclareTextAccent{LICR-accent}{encoding}{slot}Las fuentes a menudo contienen marcas diacríticas como glifos individuales para permitir la construcción de caracteres acentuados combinando dichas marcas diacríticas con algún otro glifo. Dichos acentos (siempre que se coloquen encima de otros glifos) se declaran usando el comando \DeclareTextAccent. El tercer argumento, ranura, es la posición del signo diacrítico en la fuente. Por ejemplo,
1\DeclareTextAccent{\"}{T1}{4}define el acento “diéresis”. A partir de ese momento, una representación interna como \"a tiene el siguiente significado en la codificación T1: escriba ‘a con diéresis’ colocando el acento en la posición 4 sobre los glifos en la posición 97 (el código ASCII de el carácter a). Tal declaración, de hecho, define implícitamente una amplia gama de representaciones de caracteres internos, es decir, cualquier cosa del tipo \"\DeclareTextSymbol o cualquier carácter ASCII que pertenezca al LICR, como ‘a’.
Incluso aquellas combinaciones que no tienen mucho sentido, como \"\P (es decir, signo de pilcrow con diéresis), conceptualmente se convierten de esta manera en miembros del conjunto de comandos específicos de codificación de fuentes.
1\DeclareTextComposite
2 {LICR-accent}{encoding}{simple-LICR-object}{slot}El gráfico de glifos anterior contiene una gran cantidad de caracteres acentuados como glifos individuales; por ejemplo, ‘a con diéresis’ en la posición octal '240. Por lo tanto, en T1 el comando específico de codificación \"a no debería resultar en colocar un acento sobre el carácter ‘a’, sino que debería acceder directamente al glifo en esa posición de la fuente. Esto se logra mediante la declaración
1\DeclareTextComposite{\"}{T1}{a}{228}que establece que el comando específico de codificación \"a da como resultado la composición tipográfica del glifo 228, deshabilitando así la declaración de acento anterior. Para todos los demás comandos específicos de codificación que comienzan con \", la declaración de acento permanece en su lugar. Por ejemplo, \"b producirá una ‘b con diéresis’ al colocar un acento sobre el glifo base ‘b’.
El tercer argumento, objeto-LICR-simple, debe ser una sola letra, como ‘a’, o un solo comando, como \j o \oe.
1\DeclareTextCompositeCommand
2 {LICR-object}{encoding}{simple-LICR-object}{code}Aunque no se utiliza para la codificación T1, también existe una versión más general de \DeclareTextComposite que permite código arbitrario en lugar de una posición de ranura. Esto se usa, por ejemplo, en la codificación OT1 para reducir el acento de anillo sobre la ‘A’ en comparación con la forma en que se escribiría con la primitiva \accent de TeX. Los acentos sobre la ‘i’ también se implementan mediante esta forma de declaración:
1\DeclareTextCompositeCommand{\'}{OT1}{i}{\@tabacckludge'\i}
2\DeclareTextCompositeCommand{\^}{OT1}{i}{\^\i}Una serie de signos diacríticos no se colocan encima de otros caracteres, sino que se colocan en algún lugar debajo de ellos. No existe un formulario de declaración especial para tales marcas, ya que la ubicación real del acento implica código TeX de bajo nivel. En su lugar, se puede utilizar el \DeclareTextCommand genérico para este propósito.
1\DeclareTextCommand{LICR-object}{encoding}[num][default]{code}Por ejemplo, el acento ‘\b’ en la codificación ‘T1’ se define con el siguiente código:
1\DeclareTextCommand{\b}{T1}[1]
2 {\hmode$bgroup\o$lign{\relax#1\crcr\hidewidth\sh$ft{29}%
3 \vbox to.2ex{\hbox{\char9}\vss}\hidewidth}\egroup}En esta discusión, no importa mucho qué significa exactamente el código, pero podemos ver que \DeclareTextCommand es similar a \newcommand en cierto modo. Tiene un argumento opcional num que indica el número de argumentos (uno aquí), un segundo argumento opcional predeterminado (no presente aquí) y un argumento final obligatorio que contiene el código en el que es posible hacer referencia al argumento( s) usando #1, #2, etc.
\DeclareTextCommand también se puede utilizar para crear comandos específicos de codificación de fuentes que constan de una única secuencia de control. En este caso, se utiliza sin el argumento opcional, definiendo así un comando sin argumentos. Por ejemplo, en “T1” no hay un glifo para el signo “por mil”, pero hay una pequeña “o” en la posición “30”, que, si se coloca directamente detrás de un “%”, dará el glifo apropiado. . Así, podemos proporcionar las siguientes declaraciones:
1\DeclareTextCommand{\textperthousand} {T1}{\%\char 24}
2\DeclareTextCommand{\textpertenthousand}{T1}{\%\char 24\char 24 }Ahora hemos cubierto todos los comandos necesarios para declarar los comandos específicos de codificación de fuente para una nueva codificación. Como ya hemos dicho, sólo estos comandos deben estar presentes en los archivos de definición de codificación.
Valores predeterminados de codificación de salida
Veamos ahora qué sucede si se utiliza un comando específico de codificación, para el cual no existe ninguna declaración en la codificación de fuente actual. En ese caso, puede suceder una de dos cosas: o LaTeX tiene una definición predeterminada para el objeto LICR, en cuyo caso se usa esta predeterminada, o se emite un mensaje de error indicando que el objeto LICR solicitado no está disponible en la codificación actual. Hay varias formas de configurar valores predeterminados para objetos LICR.
1\DeclareTextCommandDefault{LICR-object}[num][default]{code}El comando \DeclareTextCommandDefault proporciona la definición predeterminada para un objeto LICR que se utilizará siempre que no haya una configuración específica para un objeto en la codificación actual. Estas definiciones pueden, por ejemplo, falsificar un personaje determinado. Por ejemplo, \textregistered tiene una definición predeterminada en la que el carácter se construye a partir de otros dos, como este:
1\DeclareTextCommandDefault{\textregistered}{\textcircled{\scshape r}}Técnicamente, las definiciones predeterminadas se almacenan como una codificación con el nombre ?. Si bien no debes confiar en este hecho, ya que la implementación puede cambiar en el futuro, significa que no puedes declarar una codificación con este nombre.
1\DeclareTextSymbolDefault{LICR-object}{encoding}En la mayoría de los casos, una definición predeterminada no requiere codificación, sino que simplemente indica a LaTeX que tome el carácter de alguna codificación en la que se sabe que existe. El paquete textcomp, por ejemplo, contiene una gran cantidad de declaraciones predeterminadas que apuntan todas a la codificación TS1. Por ejemplo:
1\DeclareTextSymbolDefault{\texteuro}{TS1}El comando \DeclareTextSymbolDefault se puede utilizar para definir el valor predeterminado para cualquier objeto LICR sin argumentos, no solo aquellos declarados con el comando \DeclareTextSymbol en otras codificaciones.
1\DeclareTextAccentDefault{LICR-accent}{encoding}Existe una declaración similar para objetos LICR que toman un argumento, como acentos. Nuevamente, este formulario se puede utilizar para cualquier objeto LICR con un argumento. El kernel de LaTeX, por ejemplo, contiene varias declaraciones del tipo:
1\DeclareTextAccentDefault{\"}{OT1}
2\DeclareTextAccentDefault{\t}{OML}Esto significa que si \" no está definido en la codificación actual, entonces use el de una fuente codificada en OT1. De manera similar, para obtener un acento de empate, recójalo de OML si no hay nada mejor disponible. .
1\ProvideTextCommandDefault{LICR-object}[num][default]{code}La declaración \ProvideTextCommandDefault permite “proporcionar” otro tipo de valor predeterminado. Hace el mismo trabajo que la declaración \DeclareTextCommandDefault, excepto que el valor predeterminado se proporciona solo si no se ha definido ningún valor predeterminado antes. Esto se utiliza principalmente en archivos de codificación de entrada para proporcionar algún tipo de valores predeterminados triviales para objetos LICR inusuales. Por ejemplo:
1\ProvideTextCommandDefault{\textonequarter}{\ensuremath{\frac14}}
2\ProvideTextCommandDefault{\textcent}{\TextSymbolUnavailable\textcent}Paquetes como textcomp pueden luego reemplazar dichas definiciones con declaraciones que apunten a glifos reales. El uso de \Provide... en lugar de \Declare... garantiza que no se sobrescriba accidentalmente un valor predeterminado mejor si se lee el archivo de codificación de entrada.
1\UndeclareTextCommand{LICR-object}{encoding}En algunos casos, es necesario eliminar una declaración existente para garantizar que se utilice en su lugar una declaración predeterminada. Esto se puede hacer usando \UndeclareTextCommand. Por ejemplo, el paquete textcomp elimina las definiciones de \textdollar y \textsterling de la codificación OT1 porque no todas las fuentes codificadas en \OT1 realmente tienen estos símbolos.
1\UndeclareTextCommand{\textsterling}{OT1}
2\UndeclareTextCommand{\textdollar} {OT1}Sin esta eliminación, las nuevas declaraciones predeterminadas para recoger los símbolos de “TS1” no se usarían para las fuentes codificadas con “OT1”.
1\UseTextSymbol{encoding}{LICR-object}
2\UseTextAccent{encoding}{LICR-object}{simple-LICR-object}La acción oculta detrás de las declaraciones \DeclareTextSymbolDefault y \DeclareTextAccentDefault también se puede utilizar directamente. Supongamos, por ejemplo, que la codificación actual es “U”. En ese caso,
1\UseTextSymbol{OT1}{\ss}
2\UseTextAccent{OT1}{\'}{a}tiene el mismo efecto que ingresar el código a continuación. Tenga en cuenta en particular que la a está escrita en la codificación U; solo se toma el acento de la otra codificación.
1{\fontencoding{OT1}\selectfont\ss}
2{\fontencoding{OT1}\selectfont\'{\fontendcoding{U}\selectfont a}}Una lista de objetos LICR estándar
La tabla en esta subsección proporciona una descripción general de las representaciones internas de LaTeX disponibles con las tres codificaciones principales para idiomas latinos: OT1 (la codificación TeX original), T1 (la codificación estándar de LaTeX) y LY1 ( una codificación alternativa de 8 bits propuesta por Y&Y). Además, muestra todos los objetos LICR declarados por TS1 (la codificación de símbolos de texto estándar de LaTeX) proporcionados al cargar el paquete textcomp.
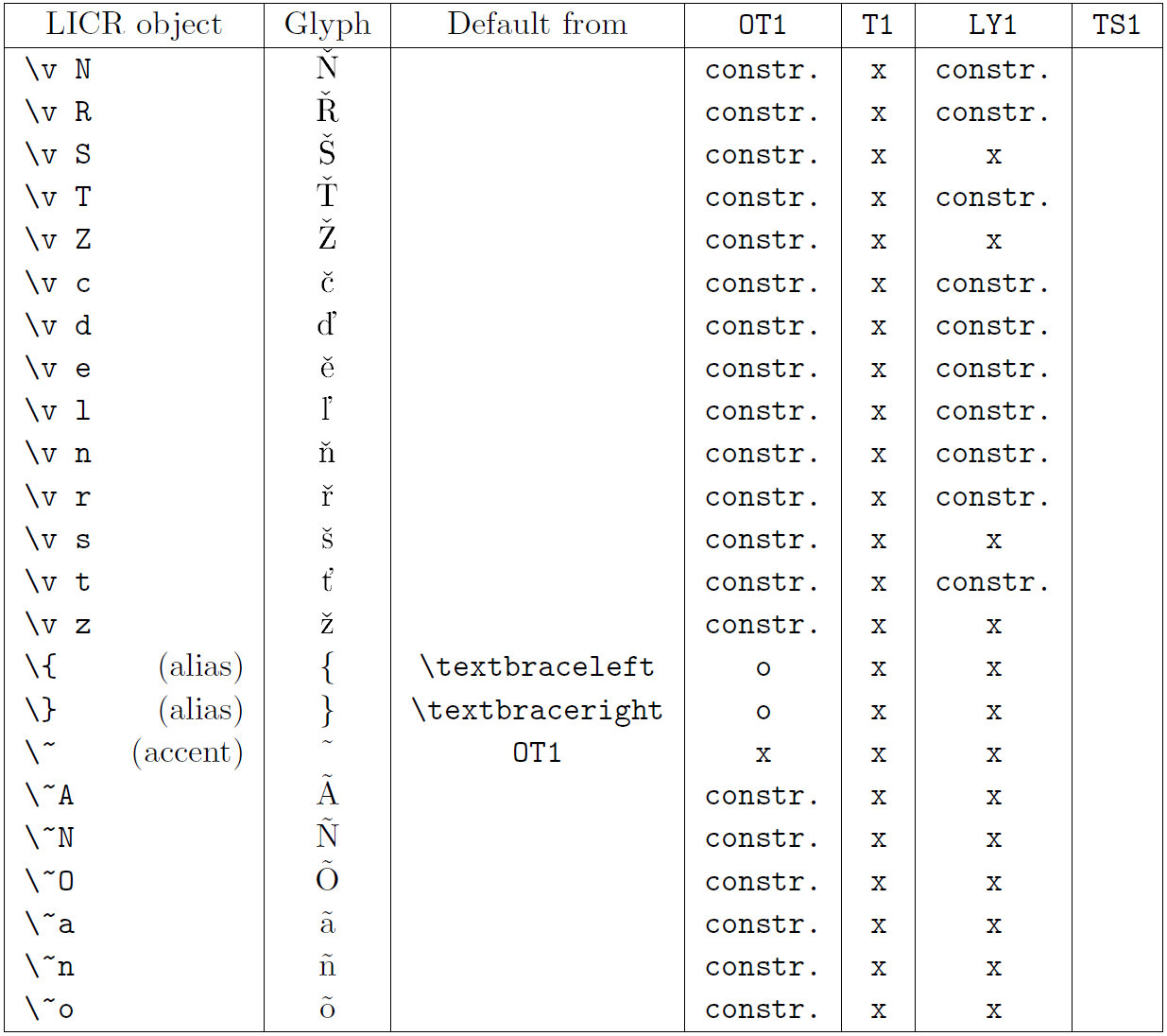
La primera columna de la tabla muestra los nombres de los objetos LICR en orden alfabético, indicando qué objetos LICR actúan como acentos. La segunda columna muestra una representación gráfica del objeto.
La tercera columna describe si el objeto tiene una declaración predeterminada. Si aparece una codificación, significa que, de forma predeterminada, el glifo se obtiene de una fuente adecuada en esa codificación; constr. significa que el valor predeterminado se produce a partir de código TeX de bajo nivel; si la columna está vacía, significa que no se define ningún valor predeterminado para este objeto LICR. En el último caso, se devuelve un error “Símbolo no disponible” cuando lo usa en una codificación para la cual no tiene una definición explícita. Si el objeto es un alias de algún otro objeto LICR, el nombre alternativo aparece en esta columna.
Las columnas cuatro a siete muestran si un objeto está disponible en la codificación dada. Aquí, ‘x’ significa que el objeto está disponible de forma nativa (como un glifo) en fuentes con esa codificación, ‘o’ significa que está disponible de forma predeterminada para todas las codificaciones y constr. significa que se genera a partir de varias glifos, acentos u otros elementos. Si el valor predeterminado se obtiene de TS1, el objeto LICR solo está disponible si el paquete textcomp está cargado.
Objetos LICR. Parte 1
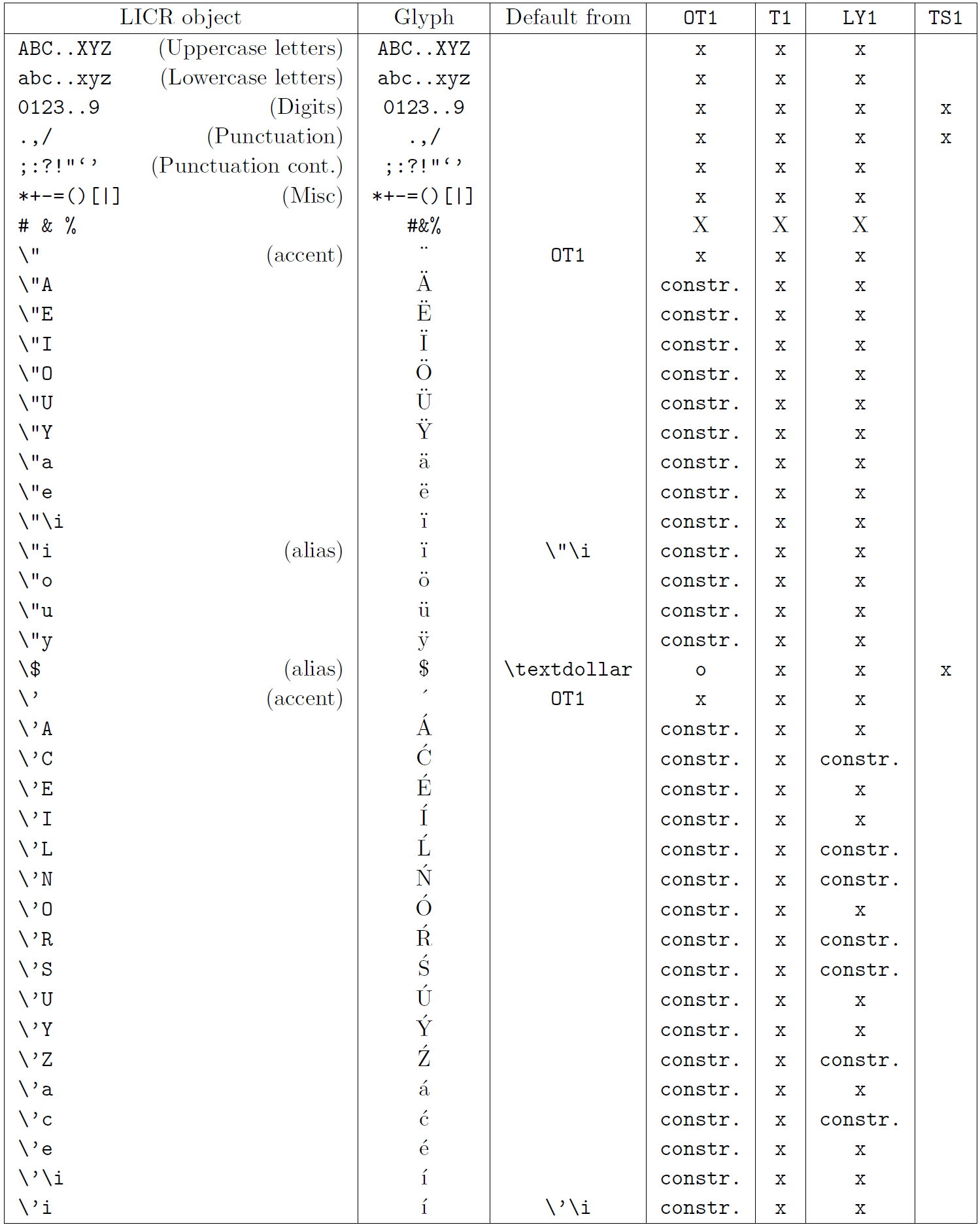
Objetos LICR. parte 2
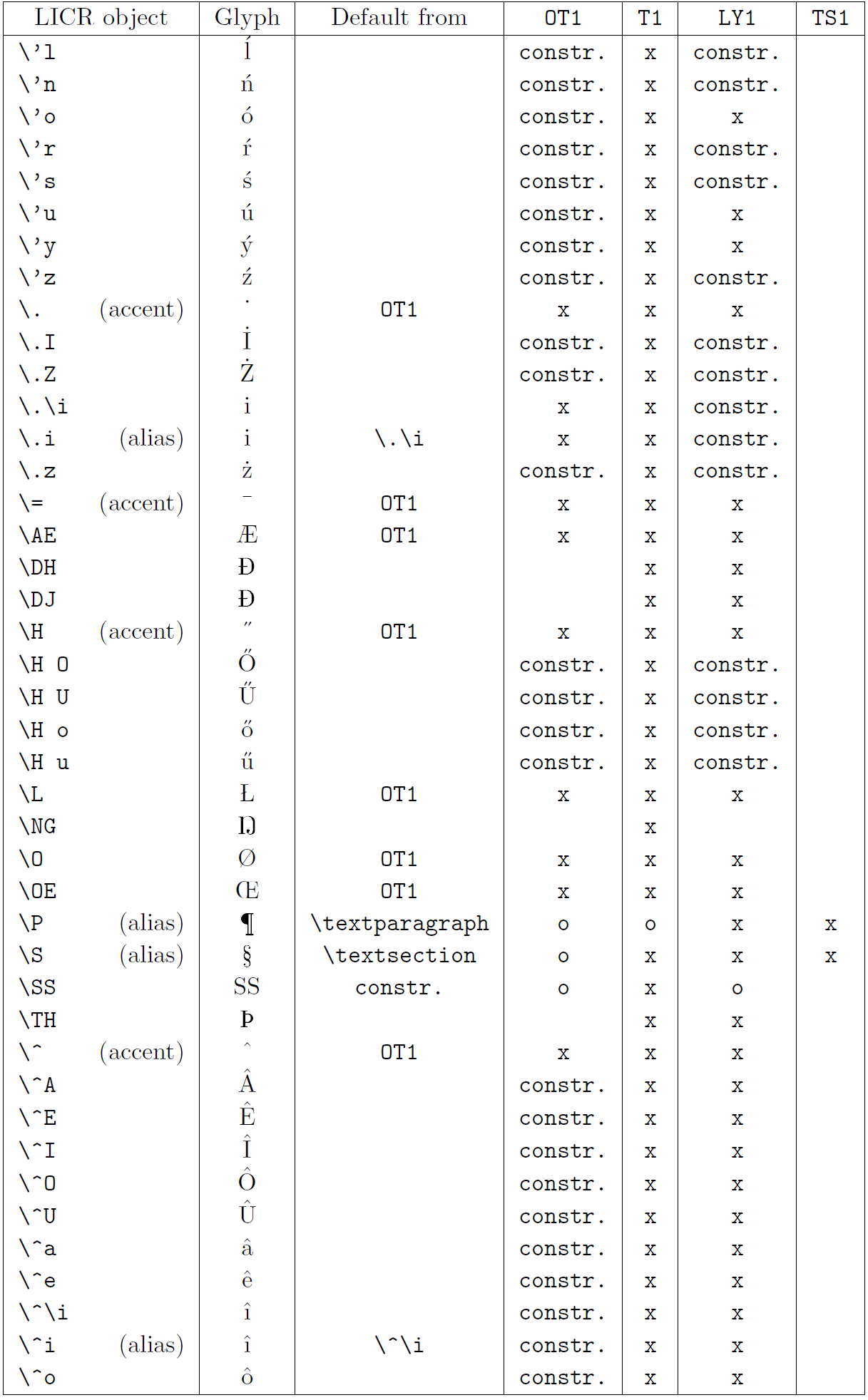
Objetos LICR. parte 3
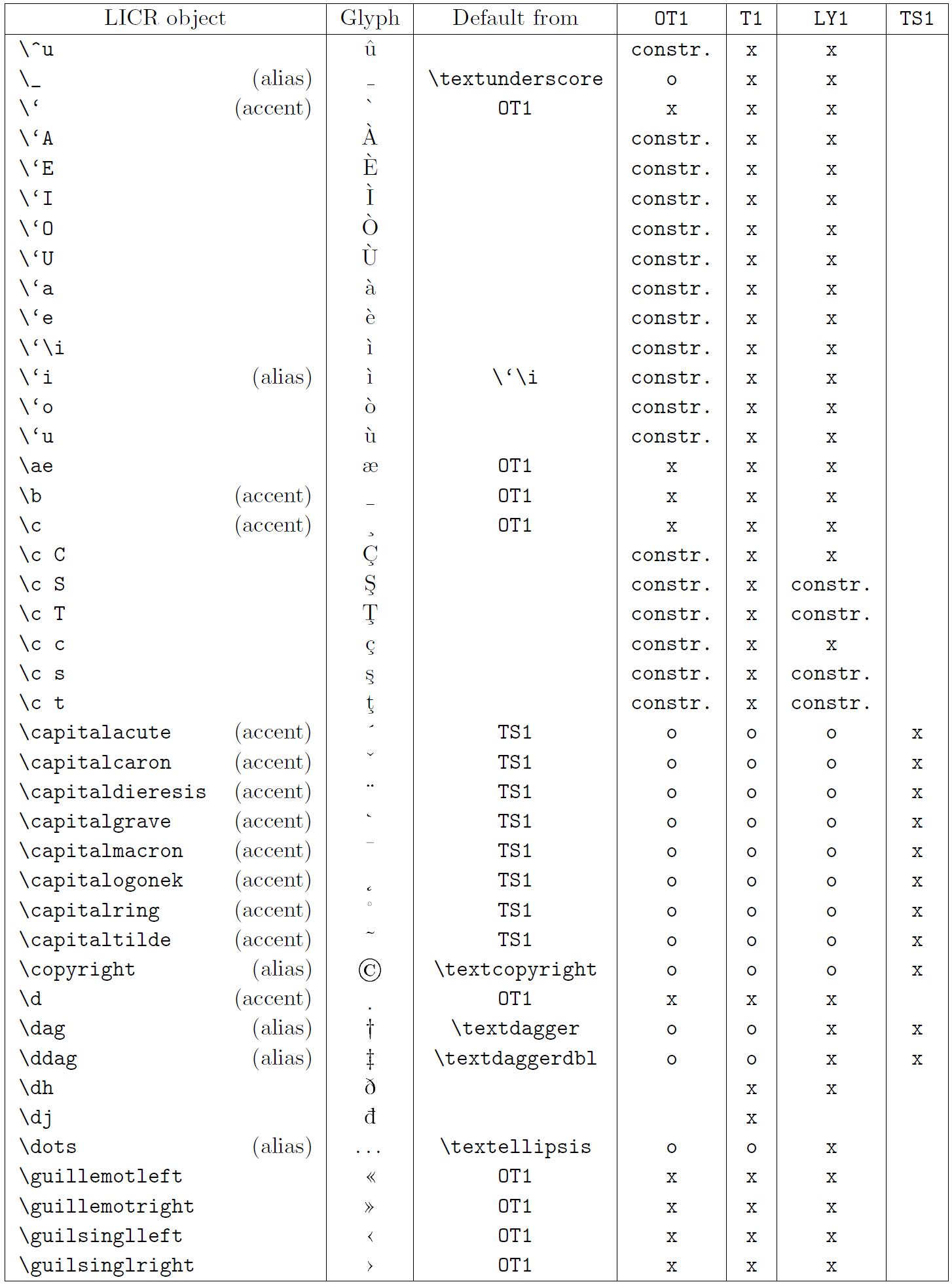
Objetos LICR. parte 4
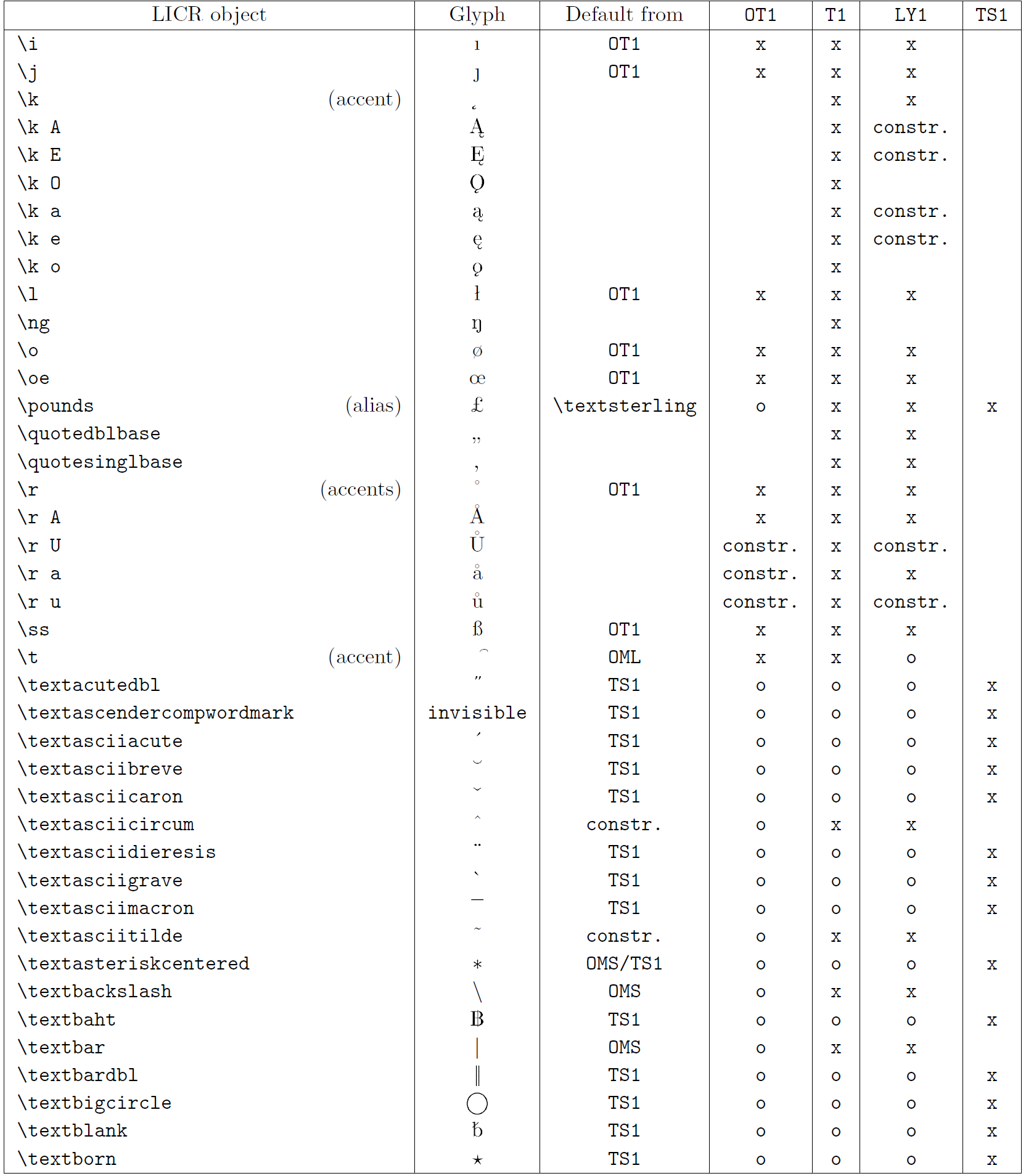
Objetos LICR. parte 5
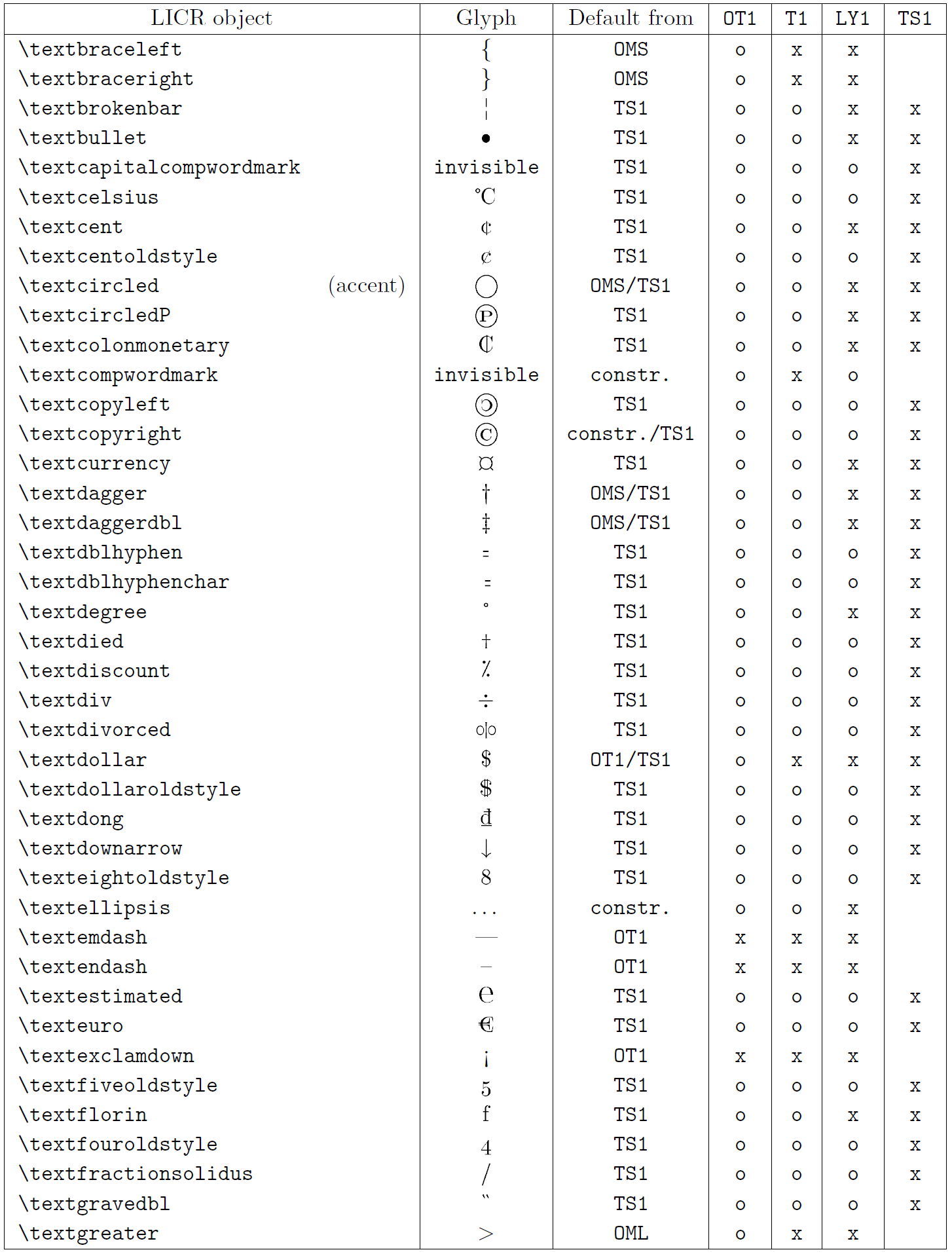
Objetos LICR. parte 6
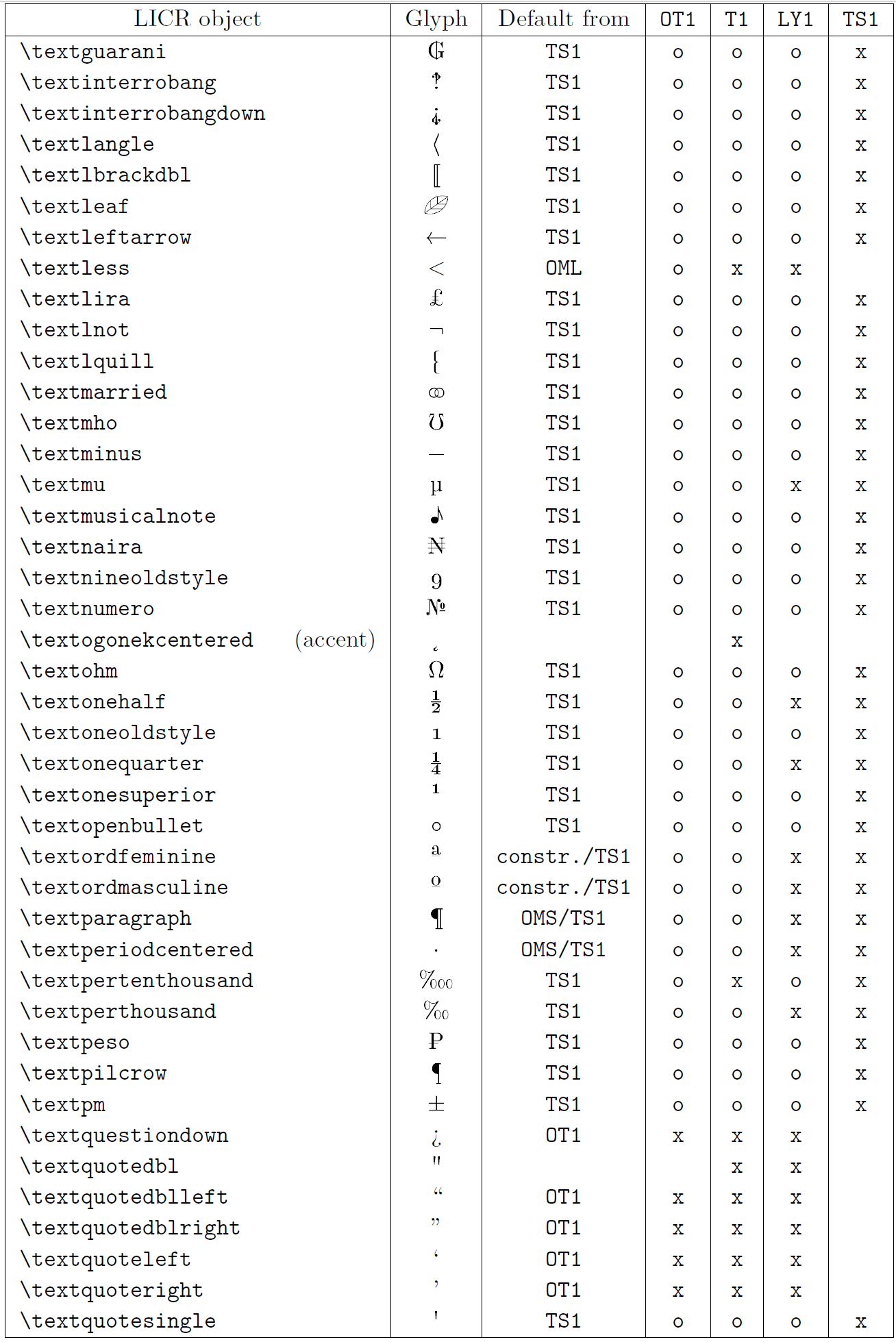
Objetos LICR. parte 7
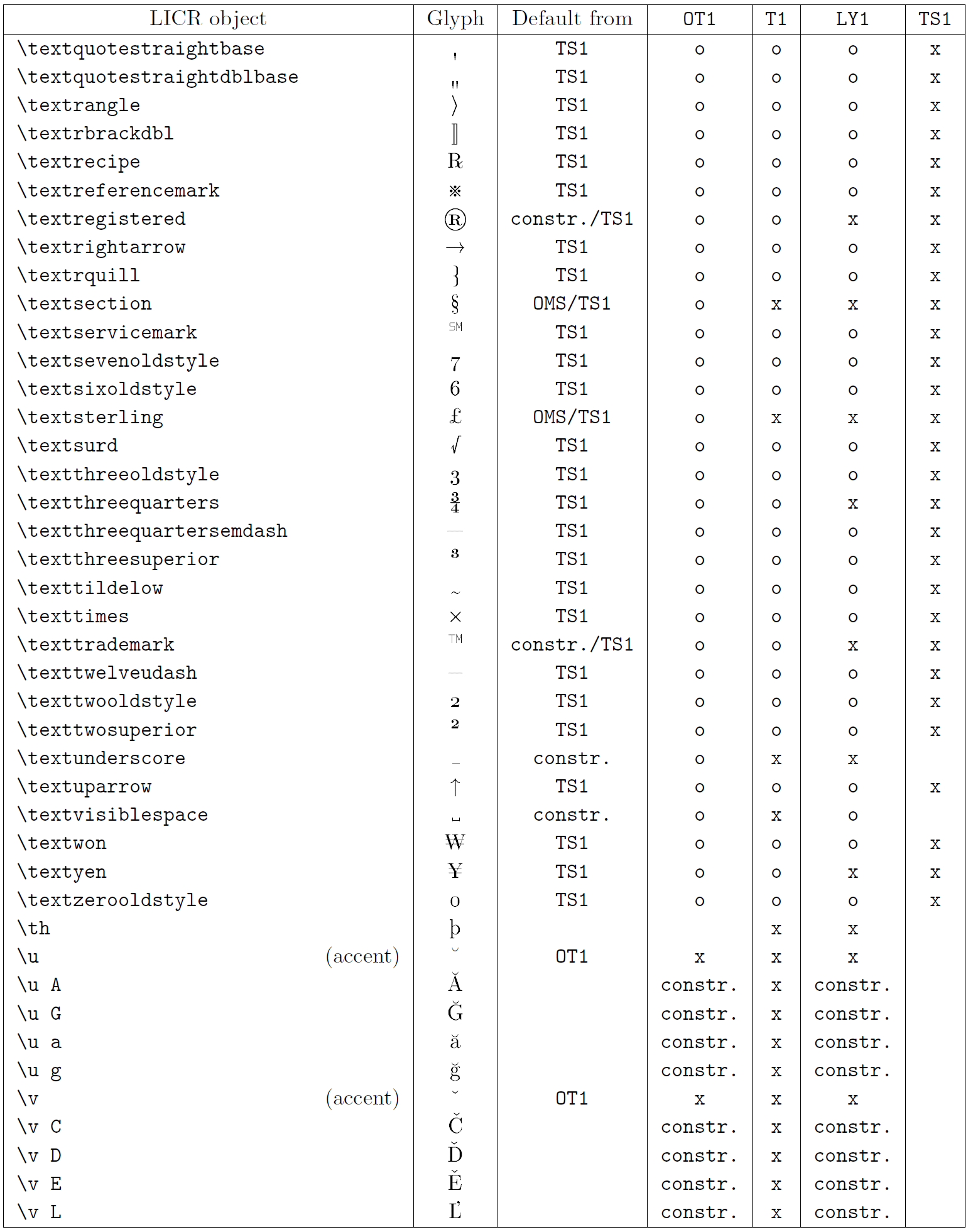
Objetos LICR. parte 8