4. Fuentes LaTeX estándar
Este artículo contiene una breve introducción a las fuentes de texto estándar distribuidas junto con LaTeX. Luego cubre el soporte estándar de LaTeX para codificaciones de entrada y fuentes. El artículo concluye con una descripción de un paquete para rastrear el procesamiento de fuentes de LaTeX y otro paquete para mostrar gráficos de glifos.
4.1. Computadora romana moderna
Donald Knuth desarrolló una familia de fuentes llamada Computer Modern junto con TeX. Hasta principios de la década de 1990, sólo estas fuentes eran utilizables principalmente con TeX y, en consecuencia, con LaTeX. Cada una de estas fuentes contiene sólo 128 glifos, por lo que no pueden incluir caracteres acentuados como glifos individuales. Por lo tanto, usar estas fuentes significa que los caracteres acentuados deben producirse con la primitiva \accent de TeX, lo que, a su vez, significa que la separación automática de palabras con caracteres acentuados es imposible. Aunque esta restricción es aceptable con documentos en inglés, es una desventaja obvia para otros idiomas.
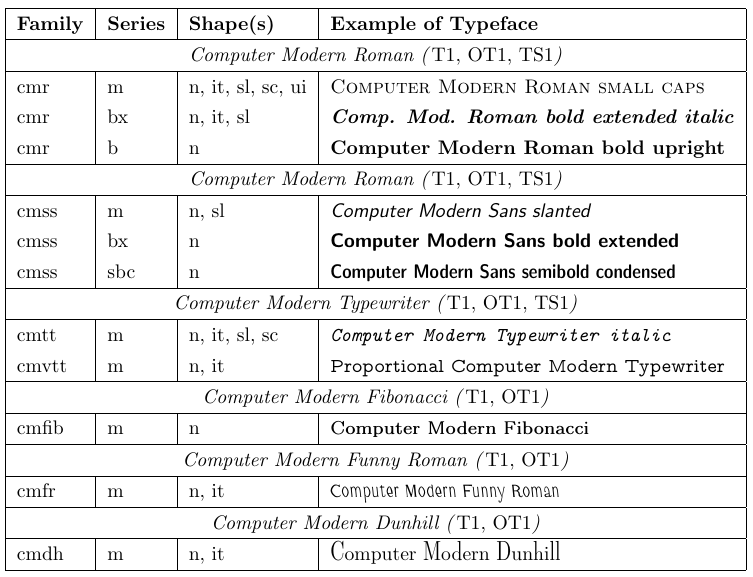
Estas deficiencias preocuparon mucho a los usuarios de TeX en Europa y finalmente llevaron a una reimplementación de TeX en 1989 para admitir caracteres de 8 bits interna y externamente. En 1990 se desarrolló una codificación estándar de 8 bits para fuentes de texto (T1). Contiene muchos caracteres diacríticos y permite la composición tipográfica en más de 30 idiomas basados en el alfabeto latino. Luego, se reimplementaron las familias de fuentes Computer Modern y se diseñaron caracteres adicionales para que las fuentes resultantes se ajustaran completamente a este esquema de codificación.
4.2. Seleccionar la codificación de entrada: el paquete inputenc
Si puede escribir caracteres acentuados mediante una sola pulsación de tecla o mediante algún otro método de entrada (por ejemplo, presionando ` y luego a para obtener ‘a-grave’), y su computadora los muestra correctamente en el editor…

… entonces lo ideal sería usar dicho texto directamente con LaTeX en lugar de tener que escribir \`a, \^e, etc.
En idiomas como el francés y el alemán, este último enfoque es factible. Sin embargo, para idiomas como el ruso y el griego, la posibilidad de entrada directa es necesaria, ya que casi todos los caracteres en estos idiomas tienen un nombre de comando como forma interna de LaTeX. Por ejemplo, la definición rusa predeterminada para \reftextafter contiene el siguiente texto (que significa “en la página siguiente”):
1\cyrn\cyra\ \cyrs\cyrl\cyre\cyrd\cyru\cyryu\cyrshch\cyre\cyrishrt
2\ \cyrs\cyrt\cyrr\cyra\cyrn\cyri\cyrc\cyreEs poco probable que alguien quiera escribir este tipo de cosas con regularidad. Sin embargo, tiene la ventaja de ser universalmente portátil, por lo que puede interpretarse correctamente en cualquier instalación LaTeX. Por otro lado, escribir
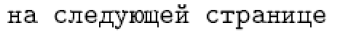
en un teclado apropiado es claramente preferible, si es posible hacer que LaTeX comprenda esta entrada. El problema es que lo que se almacena en un archivo no son los caracteres que vemos en la secuencia anterior, sino octetos que representan los caracteres. En circunstancias diferentes (utilizando codificaciones diferentes), los mismos octetos pueden representar caracteres diferentes.
Siempre que todo suceda en una sola computadora y todos los programas interpreten los octetos de los archivos de la misma manera, todo suele estar bien. Si es así, tiene sentido activar un mecanismo de traducción automática integrado en algunas implementaciones recientes de TeX. Pero cuando un archivo producido en un entorno de este tipo se envía a una computadora diferente, es probable que el procesamiento falle o, peor aún, parezca que tiene éxito, pero en realidad producirá resultados incorrectos al mostrar caracteres incorrectos.
El paquete inputenc se creó para solucionar este problema. Su objetivo principal es informar a LaTeX de la codificación utilizada en el documento o en una parte del documento. Esto se hace cargando el paquete con el nombre de codificación como opción. Por ejemplo:
1\usepackage[cp1252]{inputenc} % Windows 1252 (Western Europe) code pageA partir de ese momento, LaTeX sabe cómo interpretar los octetos del resto del documento en cualquier instalación, independientemente de la codificación utilizada para otros fines en esa computadora.
A continuación se muestra un ejemplo típico. Es un texto breve escrito en la codificación “koi8-r”, que es popular en Rusia. El código fuente muestra cómo se ve el texto en una computadora usando una codificación latina 1 (por ejemplo, en Alemania). El resultado demuestra que LaTeX aún podía interpretar el texto correctamente porque se le dijo qué codificación de entrada se estaba utilizando.

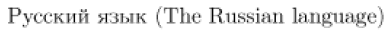
La lista de codificaciones actualmente admitidas por inputenc se proporciona a continuación. La interfaz está bien documentada y se puede agregar fácilmente soporte para nuevas codificaciones. Por lo tanto, vale la pena consultar la documentación del paquete inputenc si la codificación utilizada por su computadora no aparece aquí. También puede buscar en Internet archivos codificados para inputenc creados por otros autores. Por ejemplo, las codificaciones relacionadas con los idiomas cirílicos se distribuyen junto con otros paquetes de soporte de fuentes para idiomas cirílicos.
El estándar ISO-8859 define una serie de codificaciones importantes de un solo byte. Las codificaciones relacionadas con el alfabeto latino están respaldadas por inputenc. Para el sistema operativo Windows, Microsoft ha definido varias codificaciones de un solo byte. Además, se encuentran disponibles algunas codificaciones definidas por otros proveedores de computadoras.
latin1Esta es la codificación ISO-8859-1 (también conocida como Latin 1). Puede representar la mayoría de los idiomas de Europa occidental, incluidos el albanés, catalán, danés, holandés, inglés, feroés, finlandés, francés, gallego, alemán, islandés, irlandés, italiano, noruego, portugués, español y sueco.latin2La codificación ISO Latin 2 (ISO-8859-2) admite las lenguas eslavas de Europa Central que utilizan el alfabeto latino. Se puede utilizar para los siguientes idiomas: croata, checo, alemán, húngaro, polaco, rumano, eslovaco y esloveno.latin3Este conjunto de caracteres (ISO-8859-3) se utiliza para esperanto, gallego, maltés y turco.latin4La codificación ISO Latin 4 (ISO-8859-4) puede representar idiomas como el estonio, el letón y el lituano.latin5La codificación ISO Latin 5 (ISO 8859-9) está estrechamente relacionada con Latin 1 y reemplaza las letras islandesas raramente utilizadas de Latin 1 con letras turcas.latin9Latin 9 (o ISO-8859-15) es otra pequeña variación del Latin 1 que agrega el signo de moneda euro, así como algunos otros caracteres, como la ligadura\AE, que faltaban en francés y Finlandés. Se está volviendo cada vez más popular como reemplazo del latín 1.cp437Página de códigos IBM 437 (MS-DOS latino pero que contiene muchos caracteres gráficos para dibujar cuadros).cp850Página de códigos IBM 850 (MS-DOS multilingüe, similar a latin1).cp852Página de códigos IBM 852 (MS-DOS multilingüe, similar a latin2).cp858Página de códigos IBM 858 (IBM 850 con el símbolo del euro agregado).cp865Página de códigos IBM 865 (MS-DOS Noruega).- Página de códigos
cp1250de Windows 1250 (Europa Central y del Este). - Página de códigos
cp1252de Windows 1252 (Europa occidental). cp1257Página de códigos de Windows 1257 (Báltico).- Codificación ANSI
ansinewde Windows 3.1; un sinónimo de cp1252. - Codificación del conjunto de caracteres multinacional DEC
decmulti. - Codificación
applemacMacintosh (estándar). maccePágina de códigos de Europa Central de Macintosh.nextSiguiente Codificación de computadora.utf8Soporte de codificación UTF8 de Unicode.
La mayoría de las instalaciones de TeX aceptan caracteres de 8 bits de forma predeterminada. Sin embargo, sin ajustes adicionales, como los realizados por inpuenc, los resultados pueden ser impredecibles: algunos caracteres pueden desaparecer, o puede obtener cualquier carácter presente en la fuente actual en la ubicación del octeto mencionada, que puede ser o no el glifo deseado. Este comportamiento fue el predeterminado durante mucho tiempo, por lo que no se cambió en LaTeX2e porque algunas personas confían en él. Sin embargo, para garantizar que se puedan detectar dichos errores, inputenc ofrece la opción ascii, que hace que cualquier carácter fuera del rango 32-126 sea ilegal.
1\inputencoding{encoding}Originalmente, el paquete inputenc fue diseñado para especificar la codificación utilizada para un documento en su conjunto; de ahí el uso de opciones en el preámbulo. Sin embargo, es posible cambiar la codificación en medio de un documento usando el comando \inputencoding. Este comando toma el nombre de una codificación como argumento.
Cuando se desarrolló inputenc, la mayoría de las instalaciones de LaTeX se realizaban en computadoras que usaban codificaciones de un solo byte como las que se analizan en esta sección. Sin embargo, hoy en día otra codificación es popular ya que los sistemas admiten Unicode: UTF8. Esta codificación de longitud variable representa caracteres Unicode en uno a cuatro octetos. Se agregó soporte de codificación a inputenc mediante la opción utf8. Técnicamente, no proporciona una implementación completa de UTF8. Sólo se asignan caracteres Unicode que tienen alguna representación en fuentes LaTeX estándar (es decir, principalmente conjuntos de caracteres latinos y cirílicos): todos los demás generarán un mensaje de error adecuado. Además, no se admite la combinación de caracteres Unicode, aunque esa omisión particular no debería ser un problema en la práctica.
1\usepackage[utf8]{inputenc}
2\usepackage{textcomp} % for Latin interpretation
3-----------------------------------------------
4German umlauts in UTF-8: ^^c3^^a4^^c3^^b6^^c3^^bc
5\par\inputencoding{latin1}% switch to Latin 1
6But interpreted as Latin 1: ^^c3^^a4^^c3^^b6^^c3^^bc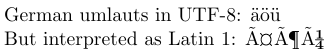
En UTF8, los caracteres ASCII se representan a sí mismos y la mayoría de los caracteres latinos están representados por dos bytes. En el código fuente del ejemplo, las representaciones de dos bytes de las diéresis alemanas en UTF8 se muestran en la notación hexadecimal de TeX, es decir, con cada octeto precedido por “^^”. En un editor que no entiende UTF8, probablemente los vería como similares al resultado que se produce cuando se interpretan como caracteres latinos 1.
Un paquete con soporte UTF8 más completo (incluido soporte para caracteres coreanos, chinos y japoneses), aunque en consecuencia más complejo en su configuración, es el paquete ucs escrito por Dominique Unruh. Puedes probarlo si la solución inputenc no cubre tus necesidades.
4.3. Seleccionar codificaciones de fuentes con el paquete fontenc
Para habilitar una codificación de fuente de texto para su uso con LaTeX, la codificación debe cargarse en el preámbulo o en la clase de documento. Más precisamente, se deben cargar las definiciones para acceder a los glifos en fuentes con una determinada codificación. La forma canónica de hacer esto es a través del paquete fontenc, que toma una lista de codificaciones de fuentes separadas por comas como una opción de paquete. La última de estas codificaciones se convierte automáticamente en la codificación predeterminada del documento. Si se cargan codificaciones cirílicas, la lista de comandos afectados por \MakeUppercase y \MakeLowercase se amplía automáticamente. Por ejemplo,
1\usepackage[T2A,T1]{fontenc}cargará todas las definiciones necesarias para las codificaciones cirílicas T2A y T1 y establecerá esta última como codificación de documento predeterminada.
A diferencia del comportamiento normal de un paquete, uno puede cargar este paquete varias veces con diferentes opciones para el comando \usepackage. Esto es necesario para permitir que una clase de documento cargue un determinado conjunto de codificaciones y permitir al usuario cargar aún más codificaciones en el preámbulo. La carga de codificaciones más de una vez se realiza sin efectos secundarios aparte de cambiar potencialmente la codificación de fuente predeterminada del documento.
Si se utilizan paquetes de soporte de idiomas (por ejemplo, los que vienen con el sistema babel) en el documento, a menudo ocurre que el paquete de soporte ya carga las codificaciones de fuentes necesarias.
4.4. Cómo rastrear la selección de fuentes con el paquete tracefnt
Para detectar problemas en el sistema de selección de fuentes, puede utilizar el paquete tracefnt. Admite varias opciones que permiten personalizar la cantidad de información que muestra NFSS en la pantalla y en el archivo de transcripción.
errorshowEsta opción suprime todas las advertencias y mensajes de información en el terminal; se escribirán únicamente en el archivo de transcripción. Sólo se mostrarán errores reales. Debe estudiar detenidamente el archivo de transcripción antes de imprimir una publicación importante porque las advertencias sobre sustituciones de fuentes, etc., pueden significar que el resultado final será incorrecto.warningshowCuando se especifica esta opción, las advertencias y errores se muestran en el terminal. Esta configuración le brinda información tan detallada como LaTeX2e sin el paquetetracefntcargado.infoshowEsta opción es la predeterminada cuando cargas el paquetetracefnt. La información adicional, que normalmente sólo se escribe en el archivo de transcripción, ahora también se muestra en su terminal.debugshowEsta opción muestra adicionalmente información sobre los cambios en la fuente del texto y la restauración de dichas fuentes al final de un grupo de llaves o al final de un entorno. Tenga cuidado al activar esta opción porque puede producir archivos de transcripción muy grandes.pausarEsta opción convierte todas las advertencias en errores para ayudar a la detección de problemas en publicaciones importantes.cargandoEsta opción muestra la carga de fuentes externas. Sin embargo, si el formato o clase de documento que utiliza ya ha cargado algunas fuentes, esta opción no las mostrará.
4.5. Cómo mostrar tablas de fuentes y ejemplos con nfssfont.tex
El archivo llamado nfssfont.tex se puede utilizar para probar nuevas fuentes, generar tablas de fuentes que muestren todos los caracteres y realizar otras operaciones relacionadas con las fuentes. Puede encontrar este archivo en cualquier distribución de LaTeX. Cuando ejecute este archivo a través de LaTeX, se le solicitará el nombre de la fuente a probar. La respuesta puede ser el nombre de la fuente externa sin extensión, como cmr10 (Computer Modern Roman 10pt), si lo conoce, o un nombre de fuente vacío. En el último caso, se le solicitará una especificación de fuente NFSS: un nombre de codificación (predeterminado T1), un nombre de familia de fuente (predeterminado cmr), una serie de fuente (predeterminada m), una forma de fuente ( predeterminado n) y un tamaño de fuente (predeterminado 10pt). Luego el programa carga el archivo externo correspondiente a esa clasificación.
A continuación, se le pedirá que ingrese un comando. El más importante es probablemente \table, que produce un gráfico de fuentes como el siguiente. El comando \text también es interesante ya que produce una muestra de texto más larga. Para cambiar a una nueva fuente de prueba, escriba \init; para finalizar la prueba, escriba \bye o \stop; y para conocer todas las demás pruebas disponibles, escriba \help.
1**********************************************
2* NFSS font test program version <v2.2b>
3*
4* Follow the instructions
5**********************************************
6
7Input external font name, e.g., cmr10
8(or <enter> for NFSS classification of font):
9
10\currfontname=cmr10
11Now type a test command (\help for help):)
12*\table
13
14*\newpage
15*\init
16Input external font name, e.g., cmr10
17(or <enter> for NFSS classification of font):
18
19\currfontname=
20*** NFSS classification ***
21
22Font encoding [T1]:
23
24\encoding=OT1
25(ot1enc.def)
26Font family [cmr]:
27
28\family=cmdh
29Font series [m]:
30
31\series=m
32Font shape [n]:
33
34\shape=n
35Font size [10pt]:
36
37\size=10
38(ot1cmdh.fd) Now type a test command (\help for help):
39*\text
40
41*\bye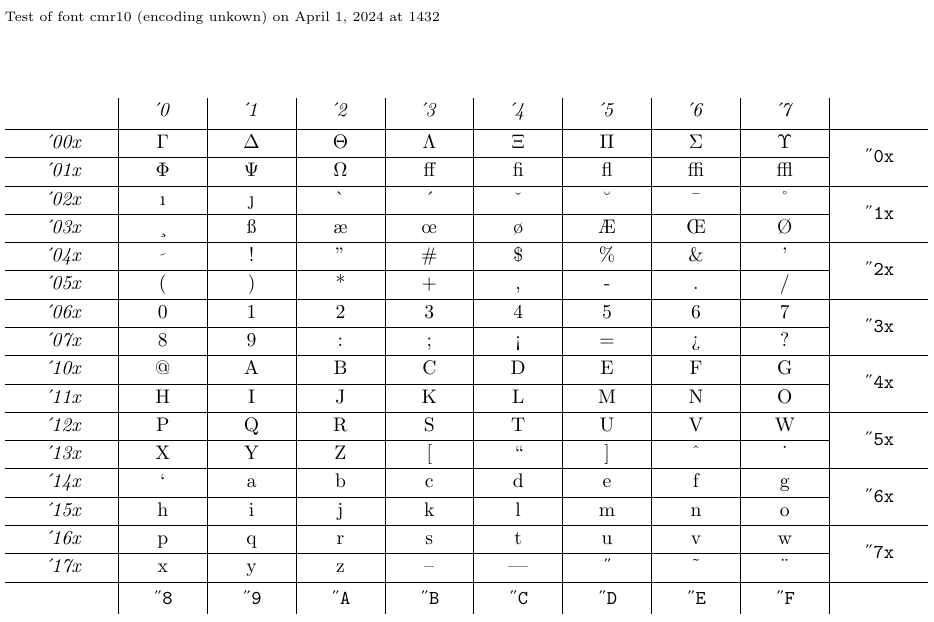

Hay dos puntos que se deben tener en cuenta. En primer lugar, el programa
nfssfont.texemite un comando\initimplícito, por lo que la primera línea de entrada debe contener un nombre de fuente o estar completamente vacía para indicar que se sigue una clasificación NFSS. En segundo lugar, la entrada a\initdebe aparecer en líneas individuales sin nada más (ni siquiera un comentario) porque el final de la línea indica el final de la respuesta a un mensaje comoFont encoding[T1]: \encoding=que recibirá.