7. Le modèle LaTeX pour les encodages de caractères
Cet article couvre en détail les encodages LaTeX. Cela commence par une discussion sur le flux de données de caractères au sein du système LaTeX. Ensuite, nous examinons de plus près le modèle de représentation interne des données de caractères dans LaTeX, suivi d’une discussion des mécanismes utilisés pour mapper les données entrantes via les codages d’entrée dans cette représentation interne. Enfin, nous expliquons comment la représentation interne est traduite, via les encodages de sortie, sous la forme requise pour la composition.
7.1. Le flux de données de caractères dans LaTeX
Le traitement d’un document avec LaTeX commence par l’interprétation des données présentes dans un ou plusieurs fichiers sources. Ces données représentant le contenu du document sont stockées dans les fichiers sources sous forme de séquences d’octets représentant des caractères. Pour interpréter correctement ces octets, tout programme (y compris LaTeX) utilisé pour traiter le fichier doit connaître le mappage entre les caractères abstraits et les octets qui les représentent. En d’autres termes, il doit connaître l’encodage utilisé lors de l’écriture du fichier.
Avec un mappage incorrect, tout traitement ultérieur sera plus ou moins erroné à moins que le fichier ne contienne uniquement des caractères d’un sous-ensemble commun dans les encodages corrects et incorrects. LaTeX fait une hypothèse fondamentale à ce stade : presque tous les caractères ASCII visibles (décimaux 32-126) sont représentés par le numéro qu’ils ont dans la table de codes ASCII.

L’une des raisons de cette hypothèse est que la plupart des codages 8 bits utilisés aujourd’hui partagent un plan commun 7 bits. Une autre raison est que, pour utiliser efficacement TeX, la majorité de la partie visible de l’ASCII doit être traitée comme des caractères de catégorie lettre - puisque seuls les caractères de cette catégorie peuvent être utilisés dans les noms de commandes à plusieurs caractères dans TEX - ou catégorie. autre - puisque TEX ne reconnaîtra pas, par exemple, les chiffres décimaux comme faisant partie d’un nombre s’ils n’ont pas ce code de catégorie.
Lorsqu’un caractère (ou, plus précisément, un nombre de 8 bits) est déclaré comme étant de catégorie lettre ou autre dans TeX, alors ce nombre de 8 bits sera transmis de manière transparente via TeX. Cela signifie que TeX composera le symbole présent dans la police à la position indiquée par ce numéro.
En conséquence de l’hypothèse susmentionnée, les polices destinées à être utilisées pour du texte général nécessitent que (la plupart des) caractères ASCII visibles soient présents dans la police et codés selon le codage ASCII.
Tous les autres nombres de 8 bits (ceux en dehors de l’ASCII visible) potentiellement présents dans le fichier d’entrée se voient attribuer un code de catégorie actif, ce qui les amène à agir comme des commandes dans TeX. Par conséquent, LaTeX peut les transformer via les encodages d’entrée en une forme que nous appellerons la Représentation interne des caractères LaTeX (LICR).
Quant au codage UTF8 d’Unicode, il est géré de la même manière. Les caractères ASCII se représentent eux-mêmes et les octets de départ pour la représentation multi-octets agissent comme des caractères actifs qui analysent l’entrée pour les octets restants. Le résultat sera transformé en objet dans le LICR s’il est mappé, ou LaTeX générera une erreur si le caractère Unicode donné n’est pas mappé.
La chose la plus importante à propos des objets dans le LICR est que la représentation des caractères ASCII 7 bits est invariante à tout changement de codage, car tous les codages d’entrée sont censés être transparents par rapport à l’ASCII visible. Les codages de sortie (ou de police) servent ensuite à mapper les représentations de caractères internes aux positions des glyphes dans la police actuelle utilisée pour la composition ou, dans certains cas, à lancer des actions plus complexes. Par exemple, il peut placer un accent (présent à une position dans la police actuelle) sur un symbole (à une position différente dans la police actuelle) pour obtenir une image imprimée du caractère abstrait représenté par la ou les commandes dans le fichier interne. codage des caractères.
Le LICR code tous les caractères possibles adressables dans LaTeX. Ainsi, il est bien plus grand que le nombre de caractères pouvant être représentés par une seule police TeX (qui peut contenir au maximum 256 glyphes). Dans certains cas, un caractère du codage interne peut être rendu avec une police en combinant des glyphes, tels que des caractères accentués. Cependant, lorsque le caractère interne nécessite une forme spéciale, il n’y a aucun moyen de le simuler si ce glyphe n’est pas présent dans la police.
Néanmoins, le modèle LaTeX pour l’encodage des caractères prend en charge des mécanismes automatiques pour récupérer les glyphes de différentes polices, de sorte que les caractères manquants dans la police actuelle soient composés, à condition qu’une police supplémentaire appropriée les contenant soit disponible.
7.2. Représentation interne des caractères de LaTeX (LICR)
Les caractères de texte sont représentés en interne par LaTeX de trois manières.
Représentation en tant que personnages
Un petit nombre de personnages sont représentés par « eux-mêmes ». Par exemple, le latin A est représenté par le caractère « A ». Ces caractères sont indiqués dans le tableau ci-dessus. Ils forment un sous-ensemble d’ASCII visible, et dans TeX, chacun d’entre eux se voit attribuer le code de catégorie lettre ou autre. Certains caractères de la plage ASCII visible ne sont pas représentés de cette manière, soit parce qu’ils font partie de la syntaxe TeX, soit parce qu’ils ne sont pas présents dans toutes les polices. Si l’on utilise, par exemple, « < » dans le texte, l’encodage de police actuel détermine si l’on obtient < (T1) ou peut-être un point d’exclamation inversé (OT1) dans la sortie imprimée.
Représentation sous forme de séquences de caractères
Le mécanisme de ligature interne de TeX peut générer de nouveaux caractères à partir d’une séquence de caractères d’entrée. Il s’agit en fait d’une propriété de la police, bien que certaines de ces séquences aient été explicitement conçues pour servir de raccourcis de saisie pour des caractères qui seraient autrement difficiles à traiter avec la plupart des claviers. Seuls quelques caractères ainsi générés sont considérés comme appartenant à la représentation interne de LaTeX. Ceux-ci incluent le tiret en et le tiret em, qui sont générés par les ligatures -- et ---, ainsi que les guillemets doubles d’ouverture et de fermeture, qui sont générés par `` et ``’’ (ce dernier peut généralement aussi être représenté par le simple"). Bien que la plupart des polices implémentent également ``` ! et ?``` pour générer des points d'exclamation et d'interrogation inversés, ce n'est pas le cas. universellement disponible dans toutes les polices. C'est pourquoi **tous** ces caractères ont une représentation interne alternative sous forme de commande (par exemple,\textendashou\textexlamdown`).
Représentation sous forme de commandes “spécifiques au codage de police”
La troisième façon de représenter les caractères en interne dans LaTeX, qui couvre la majorité des caractères, consiste à utiliser des commandes LaTeX spéciales (ou séquences de commandes) qui restent non développées lorsqu’elles sont écrites dans un fichier ou lorsqu’elles sont placées dans un argument mobile. Nous ferons référence à ces commandes spéciales sous le nom de commandes spécifiques à l’encodage de police car leur signification dépend de l’encodage de police actuellement utilisé lorsque LaTeX est prêt à les composer. De telles commandes sont déclarées à l’aide de déclarations spéciales, comme nous le verrons ci-dessous, qui nécessitent généralement des définitions individuelles pour chaque encodage de police. Si aucune définition n’existe pour le codage actuel, soit une valeur par défaut est utilisée (si disponible), soit un message d’erreur est présenté à l’utilisateur.
Lorsque l’encodage de la police est modifié à un moment donné dans le document, les définitions des commandes spécifiques à l’encodage ne changent pas immédiatement, car cela impliquerait de modifier sur place un grand nombre de commandes. Au lieu de cela, ces commandes sont implémentées de telle manière qu’une fois utilisées, elles remarquent si leur définition actuelle n’est plus adaptée à l’encodage de polices en vigueur. Dans un tel cas, ils appellent leurs homologues utilisant le codage de police actuel pour effectuer le travail proprement dit.
L’ensemble des commandes spécifiques au codage de police n’est pas fixe mais est implicitement défini comme l’union de toutes les commandes définies pour les codages de police individuels. Ainsi, de nouvelles commandes spécifiques au codage des polices peuvent être nécessaires lorsque de nouveaux codages de polices sont ajoutés à LaTeX.
7.3. Codages d’entrée
Une fois le package inputenc chargé, les deux déclarations \DeclareInputText et \DeclareInputMath pour mapper les caractères d’entrée 8 bits aux objets LICR deviennent disponibles. Ils doivent être utilisés uniquement dans l’encodage des fichiers (voir ci-dessous), des packages ou, si nécessaire, dans le préambule du document.
Ces commandes prennent un nombre de 8 bits comme premier argument, qui peut être donné sous forme de nombre décimal, de nombre octal ou en notation hexadécimale. L’utilisation de la notation décimale est conseillée car les caractères ' et/ou " peuvent avoir des significations spéciales dans un package de support de langue, comme des raccourcis vers les accents, rendant ainsi la notation octale et/ou hexadécimale invalide si les packages sont chargés dans le mauvais sens. commande.
1\DeclareInputText{number}{LICR-object}La commande \DeclareInputText déclare les mappages de caractères à utiliser dans le texte. Son deuxième argument contient la commande (ou séquence de commandes) spécifique au codage, c’est-à-dire les objets LICR auxquels le numéro de caractère doit être mappé. Par exemple,
1\DeclareInputText{239}{\"\i}mappe le nombre « 239 » à la représentation spécifique au codage du « i-tréma », qui est « "\i ». Les caractères d’entrée déclarés de cette manière ne peuvent pas être utilisés dans les formules mathématiques.
1\DeclareInputMath{number}{math-object}Si le nombre représente un caractère à utiliser dans les formules mathématiques, alors la déclaration \DeclareInputMath doit être utilisée. Par exemple, dans le codage d’entrée cp437de (clavier MS-DOS allemand),
1\DeclareInputMath{224}{\alpha}mappe le nombre « 224 » à la commande « \alpha ». Il est important de noter que cette déclaration rendrait la clé produisant ce nombre utilisable uniquement en mode mathématique, car \alpha n’est autorisé nulle part ailleurs.
1\DeclareUnicodeCharacter{hex-number}{LICR-object}Cette déclaration n’est disponible que si l’option utf8 est utilisée. Il mappe les nombres Unicode aux objets LICR (c’est-à-dire les caractères utilisables dans le texte). Par exemple,
1\DeclareUnicodeCharacter{00A3}{\textsterling}
2\DeclareUnicodeCharacter{011A}{\v E}
3\DeclareUnicodeCharacter{2031}{\textpertenthousand}En théorie, il ne devrait y avoir qu’un seul mappage bidirectionnel unique entre les deux espaces, de sorte que toutes ces déclarations puissent déjà être faites automatiquement lorsque l’option utf8 est sélectionnée. En pratique, les choses sont un peu plus compliquées. Premièrement, fournir automatiquement la table entière nécessiterait une énorme quantité de mémoire de TeX. De plus, il existe de nombreux caractères Unicode pour lesquels aucun objet LICR n’existe et, à l’inverse, de nombreux objets LICR n’ont pas d’équivalent en Unicode. Ce problème est résolu dans le package inputenc en chargeant uniquement les mappages Unicode qui correspondent aux encodages utilisés dans un document particulier (dans la mesure où ils sont connus) et en répondant à toute autre demande de caractère Unicode avec un message d’erreur approprié. Il incombe alors à l’utilisateur de fournir les informations cartographiques appropriées ou, si nécessaire, de charger un encodage de police supplémentaire.
Comme nous l’avons mentionné ci-dessus, les déclarations de codage d’entrée peuvent être utilisées dans des packages ou dans le préambule du document. Pour que tout fonctionne de cette façon, il est important de charger d’abord le package inputenc, sélectionnant ainsi un encodage approprié. Les déclarations de codage d’entrée ultérieures remplaceront (ou ajouteront) celles définies par le codage d’entrée actuel.
Lorsque vous utilisez le package inputenc, vous pouvez voir la commande \@tabacckludge, qui signifie “tabbing accent kludge”. Ceci est nécessaire car la version actuelle de LaTeX a hérité d’une surcharge des commandes \=, \` et \', qui désignent normalement certains accents (c’est-à-dire sont des commandes spécifiques à l’encodage), mais ont des significations particulières dans l’environnement « tabulation ». C’est pourquoi les mappages impliquant l’un de ces accents doivent être codés d’une manière spéciale. Par exemple, si vous souhaitez mapper 232 au caractère ’e-grave’ (qui a la représentation interne \`e), vous devez écrire
1\DeclareInputText{232}{\@tabacckludge`e}au lieu de
1\DeclareInputText{232}{\`e}Mappage avec du texte et/ou des mathématiques
Pour des raisons techniques et conceptuelles, TeX fait une très forte distinction entre les caractères pouvant être utilisés dans le texte et en mathématiques. À l’exception des caractères ASCII visibles, les commandes qui produisent des caractères peuvent normalement être utilisées en mode texte ou mathématique, mais pas dans les deux modes.
Fichiers d’encodage d’entrée pour les encodages 8 bits
Les encodages d’entrée sont stockés dans des fichiers avec l’extension « .def », où le nom de base est le nom de l’encodage d’entrée (par exemple, « latin1.def »). Ces fichiers ne doivent contenir que les commandes décrites dans la section actuelle.
Le fichier doit commencer par une ligne d’identification contenant la commande \ProvidesFile, décrivant la nature du fichier. Par exemple:
1\ProvidesFile{latin1.def}[2000/07/01 v0.996 Input encoding file]S’il existe des mappages vers des commandes spécifiques à l’encodage qui pourraient ne pas être disponibles à moins que des packages supplémentaires ne soient chargés, on pourrait déclarer leurs valeurs par défaut en utilisant \ProvideTextCommandDefault. Par exemple:
1\ProvideTextCommandDefault{\textonehalf}{\ensurement{\frac12}}
2\ProvideTextCommandDefault{\textcent}{\TextSymbolUnavailable\textcent}La commande \TextSymbolUnavailable émet un avertissement indiquant qu’un certain caractère n’est pas disponible avec les polices actuellement utilisées. Cela peut être utile par défaut lorsque de tels caractères ne sont disponibles que si des polices spéciales sont chargées et qu’il n’existe aucun moyen approprié de simuler les caractères avec des caractères existants (comme cela était possible pour une valeur par défaut pour \textonehalf).
Le reste du fichier ne doit inclure que les déclarations de codage d’entrée \DeclareInputText et \DeclareInputMath. Comme mentionné ci-dessus, l’utilisation de cette dernière commande est déconseillée mais autorisée. Aucune autre commande ne doit être utilisée dans un fichier de codage d’entrée, en particulier aucune commande qui empêche la lecture du fichier plusieurs fois (par exemple, \newcommand), car les fichiers de codage sont souvent chargés plusieurs fois dans un seul document.
Fichiers de mappage d’entrée pour UTF8
Comme mentionné précédemment, le mappage des objets Unicode vers les objets LICR est organisé de manière à permettre à LaTeX de charger uniquement les mappages pertinents pour les encodages de polices utilisés dans le document actuel. Cela se fait en essayant de charger pour chaque encodage <name> un fichier <name>enc.dfu qui, s’il existe, contient les informations de mappage pour les caractères Unicode fournis par cet encodage particulier. Outre un certain nombre de déclarations \DeclareUnicodeCharacter, ces fichiers ne doivent inclure qu’une ligne \ProvidesFile.
Étant donné que différents encodages de polices fournissent souvent plus ou moins les mêmes caractères, il est assez courant que des déclarations pour le même caractère Unicode apparaissent dans différents fichiers « .dfu ». Il est donc très important que ces déclarations dans les différents fichiers soient identiques. Sinon, la déclaration chargée en dernier subsistera, qui peut être différente d’un document à l’autre.
Ainsi, toute personne souhaitant fournir un nouveau fichier « .dfu » pour un encodage qui n’était pas couvert auparavant doit vérifier attentivement les définitions existantes dans les fichiers « .dfu » pour les encodages associés. Les fichiers standard fournis avec inputenc sont garantis d’avoir des définitions uniformes. En fait, ils sont tous générés à partir d’une seule liste convenablement divisée. Une liste complète des mappages actuellement existants peut être trouvée dans le fichier utf8enc.dfu.
7.4. Encodages de sortie
Nous avons déjà mentionné que les codages de sortie définissent le mappage du LICR aux glyphes (ou constructions construites à partir de glyphes) disponibles dans les polices utilisées pour la composition. Ces mappages sont référencés dans LaTeX par des noms à deux ou trois lettres (par exemple, « OT1 » et « T3 »). Nous disons qu’une certaine police est dans un certain encodage si le mappage correspond aux positions des glyphes dans la police. Examinons maintenant les composants exacts d’une telle cartographie.
Les caractères représentés en interne par des caractères ASCII sont simplement transmis à la police. En d’autres termes, TeX utilise le code ASCII pour sélectionner un glyphe dans la police actuelle. Par exemple, le caractère « A » avec le code ASCII 65 entraînera la composition du glyphe en position 65 dans la police actuelle. C’est pourquoi LaTeX exige que les polices de texte contiennent toutes ces lettres ASCII dans leurs positions de code ASCII, puisqu’il n’y a aucun moyen d’interagir avec ce mécanisme TeX de base. Par conséquent, pour l’ASCII visible, un mappage un-à-un est implicitement présent dans tous les codages de sortie.
Les caractères représentés en interne sous forme de séquences de caractères ASCII (par exemple, “--”) sont traités comme suit : lorsque la police actuelle est chargée pour la première fois, TeX est informé que la police contient un certain nombre de programmes de ligature. Ces programmes définissent certaines séquences de caractères qui ne doivent pas être composées directement mais plutôt remplacées par d’autres glyphes de la police. Par exemple, lorsque TeX rencontre “--” dans l’entrée (c’est-à-dire le code ASCII 45 deux fois), un programme de ligature peut le diriger vers le glyphe en position 123 à la place (qui contiendrait alors le glyphe tiret). Encore une fois, il n’existe aucun moyen d’interagir avec ce mécanisme.
Néanmoins, la plus grande partie de la représentation interne des caractères consiste en des commandes spécifiques au codage des polices qui sont mappées à l’aide des déclarations décrites ci-dessous. Toutes les déclarations ont la même structure dans leurs deux premiers arguments : la commande spécifique à l’encodage de police (ou le premier composant de celle-ci, s’il s’agit d’une séquence de commandes), suivie du nom de l’encodage. Tous les arguments restants dépendront du type de déclaration.
Ainsi, un codage XYZ est défini par un ensemble de déclarations, toutes ayant le nom XYZ comme deuxième argument. Ensuite, bien sûr, certaines polices doivent être codées dans cet encodage. En fait, le développement des codages de polices se fait normalement à l’envers : quelqu’un commence avec une police existante et fournit ensuite les déclarations appropriées pour son utilisation. Cette collection de déclarations reçoit ensuite un nom approprié, tel que « OT1 ». Ci-dessous, nous prendrons la police ecrm1000 (voir le tableau des glyphes), dont l’encodage de police est appelé T1 dans LaTeX, et construirons les déclarations appropriées pour accéder aux glyphes à partir d’une police ainsi codée. Les caractères bleus dans le graphique de glyphes sont ceux qui doivent être présents à la même position dans chaque encodage de texte, car ils sont transmis de manière transparente via LaTeX.
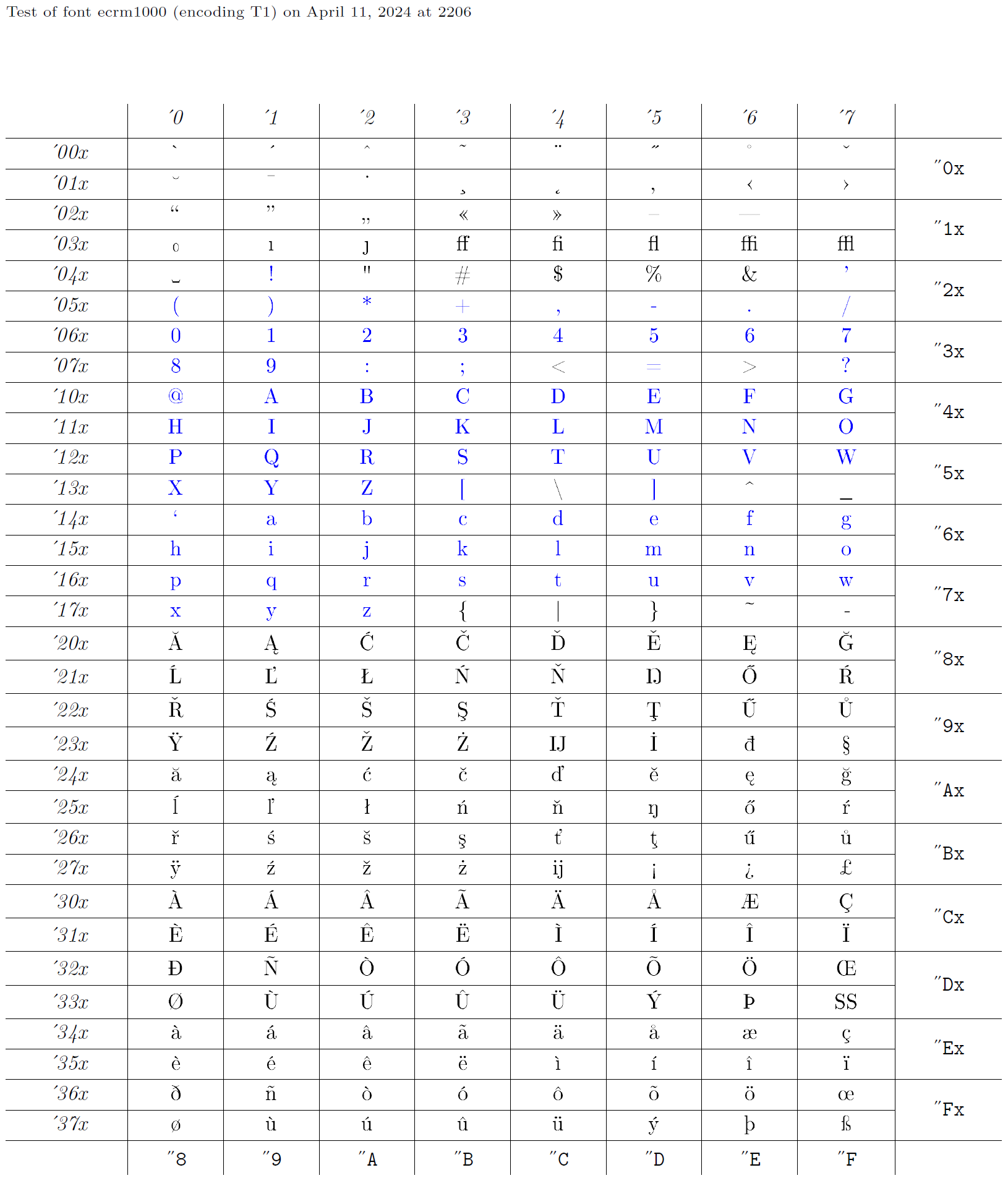
Fichiers d’encodage de sortie
Les fichiers de codage de sortie sont identifiés par la même extension « .def » que les fichiers de codage d’entrée. Cependant, le nom de base du fichier est un peu plus structuré. Il se compose du nom de codage en lettres minuscules, suivi de « enc » (par exemple, « t1enc.def » pour le codage « T1 »).
Ces fichiers ne doivent inclure que les déclarations décrites dans la section actuelle. Étant donné que les fichiers d’encodage de sortie peuvent être lus plusieurs fois par LaTeX, il est important de suivre cette règle et de s’abstenir d’utiliser, par exemple, \newcommand, qui empêche de lire un tel fichier plus d’une fois !
Encore une fois, un fichier de codage de sortie commence par une ligne d’identification décrivant la nature du fichier. Par exemple:
1\ProvidesFile{t1enc.def}[2001/06/05 v1.94 Standard LaTeX file]Avant de déclarer des commandes spécifiques à l’encodage pour un encodage particulier, nous devons d’abord faire connaître cet encodage à LaTeX. Cela se fait via la commande \DeclareFontEncoding. A ce stade, il est également utile de déclarer les règles de substitution par défaut pour l’encodage. Nous pouvons le faire en utilisant la commande \DeclareFontSubstitution. Les deux déclarations sont discutées en détail dans
Comment configurer de nouvelles polices.
1\DeclareFontEncoding{T1}{}{}
2\DeclareFontSubstitution{T1}{cmr}{m}{n}Maintenant que nous avons introduit l’encodage « T1 » dans LaTeX de cette manière, nous pouvons déclarer comment les commandes spécifiques à l’encodage de police doivent se comporter dans cet encodage.
1\DeclareTextSymbol{LICR-Object}{encoding}{slot}La déclaration des symboles textuels semble être la plus simple. Ici, la représentation interne peut être directement mappée sur un seul glyphe dans la police cible. Ceci est réalisé en utilisant la déclaration \DeclareTextSymbol, dont le troisième argument - la position du glyphe - peut être donné sous forme de nombre décimal, octal ou hexadécimal. Par exemple,
1\DeclareTextSymbol{\ss}{T1}{255}
2\DeclareTextSymbol{\AE}{T1}{'306} %font position as octal number
3\DeclareTextSymbol{\ae}{T1}{"E6} %...as hexadecimal numberdéclarez que les commandes spécifiques au codage de police \ss, \AE et \ae doivent être mappées aux positions de police (décimales) 255, 198 et 230, respectivement, dans un code encodé T1 fonte. Comme nous l’avons mentionné ci-dessus, il est plus sûr d’utiliser la notation décimale dans de telles déclarations. Quoi qu’il en soit, mélanger les notations comme dans l’exemple précédent est certainement un mauvais style.
1\DeclareTextAccent{LICR-accent}{encoding}{slot}Les polices contiennent souvent des signes diacritiques sous forme de glyphes individuels pour permettre la construction de caractères accentués en combinant un tel signe diacritique avec un autre glyphe. De tels accents (tant qu’ils doivent être placés au-dessus d’autres glyphes) sont déclarés à l’aide de la commande \DeclareTextAccent. Le troisième argument, slot, est la position du signe diacritique dans la police. Par exemple,
1\DeclareTextAccent{\"}{T1}{4}définit l’accent “tréma”. À partir de ce moment, une représentation interne telle que \"a a la signification suivante dans l’encodage T1 : composez ‘a avec tréma’ en plaçant l’accent en position 4 sur les glyphes en position 97 (le code ASCII de le caractère a). Une telle déclaration, en fait, définit implicitement une vaste gamme de représentations de caractères internes - c’est-à-dire tout ce qui est de type \"\DeclareTextSymbol ou tout caractère ASCII appartenant au LICR, tel que ‘a’.
Même les combinaisons qui n’ont pas beaucoup de sens, telles que \"\P (c’est-à-dire le signe du corbeau avec un tréma), deviennent ainsi conceptuellement des membres de l’ensemble des commandes spécifiques à l’encodage des polices.
1\DeclareTextComposite
2 {LICR-accent}{encoding}{simple-LICR-object}{slot}Le tableau de glyphes ci-dessus contient un grand nombre de caractères accentués sous forme de glyphes individuels - par exemple, « a avec tréma » en position « 240 » octale. Ainsi, dans T1, la commande spécifique au codage \"a ne devrait pas avoir pour résultat de placer un accent sur le caractère ‘a’, mais devrait plutôt accéder directement au glyphe dans cette position de la police. Ceci est réalisé par la déclaration
1\DeclareTextComposite{\"}{T1}{a}{228}qui indique que la commande spécifique à l’encodage \"a entraîne la composition du glyphe 228, désactivant ainsi la déclaration d’accent ci-dessus. Pour toutes les autres commandes spécifiques à l’encodage commençant par \", la déclaration d’accent reste en place. Par exemple, \"b produira un “b avec tréma” en plaçant un accent sur le glyphe de base “b”.
Le troisième argument, simple-LICR-object, doit être une seule lettre, telle que « a », ou une seule commande, telle que « \j » ou « \oe ».
1\DeclareTextCompositeCommand
2 {LICR-object}{encoding}{simple-LICR-object}{code}Bien qu’il ne soit pas utilisé pour l’encodage T1, il existe également une version plus générale de \DeclareTextComposite qui autorise du code arbitraire à la place d’une position d’emplacement. Ceci est utilisé, par exemple, dans l’encodage OT1 pour abaisser l’accent annulaire sur le ‘A’ par rapport à la façon dont il serait composé avec la primitive \accent de TeX. Les accents sur le « i » sont également implémentés en utilisant cette forme de déclaration :
1\DeclareTextCompositeCommand{\'}{OT1}{i}{\@tabacckludge'\i}
2\DeclareTextCompositeCommand{\^}{OT1}{i}{\^\i}Un certain nombre de signes diacritiques ne sont pas placés au-dessus des autres caractères mais plutôt quelque part en dessous d’eux. Il n’existe pas de formulaire de déclaration spécial pour de telles marques, car le positionnement réel de l’accent implique du code TeX de bas niveau. Au lieu de cela, le générique \DeclareTextCommand peut être utilisé à cette fin.
1\DeclareTextCommand{LICR-object}{encoding}[num][default]{code}Par exemple, l’accent ‘underbar’ \b dans l’encodage T1 est défini avec le code suivant :
1\DeclareTextCommand{\b}{T1}[1]
2 {\hmode$bgroup\o$lign{\relax#1\crcr\hidewidth\sh$ft{29}%
3 \vbox to.2ex{\hbox{\char9}\vss}\hidewidth}\egroup}Dans cette discussion, peu importe ce que signifie exactement le code, mais nous pouvons voir que \DeclareTextCommand est similaire à \newcommand d’une certaine manière. Il possède un argument facultatif num désignant le nombre d’arguments (un ici), un deuxième argument facultatif default (non présent ici), et un argument final obligatoire contenant le code dans lequel il est possible de faire référence à l’argument ( s) en utilisant #1, #2, et ainsi de suite.
\DeclareTextCommand peut également être utilisé pour créer des commandes spécifiques au codage des polices consistant en une seule séquence de contrôle. Dans ce cas, il est utilisé sans l’argument facultatif, définissant ainsi une commande avec zéro argument. Par exemple, dans « T1 », il n’y a pas de glyphe pour un signe « pour mille », mais il y a un petit « o » en position « 30 », qui, s’il est placé directement derrière un « % », donnera le glyphe approprié. . Ainsi, nous pouvons fournir les déclarations suivantes :
1\DeclareTextCommand{\textperthousand} {T1}{\%\char 24}
2\DeclareTextCommand{\textpertenthousand}{T1}{\%\char 24\char 24 }Nous avons maintenant couvert toutes les commandes nécessaires pour déclarer les commandes spécifiques à font-encoding pour un nouvel encodage. Comme nous l’avons déjà dit, seules ces commandes doivent être présentes dans les fichiers de définition d’encodage.
Valeurs par défaut du codage de sortie
Voyons maintenant ce qui se passe si une commande spécifique à l’encodage, pour laquelle il n’y a pas de déclaration dans l’encodage de police actuel, est utilisée. Dans ce cas, deux choses peuvent se produire : soit LaTeX a une définition par défaut pour l’objet LICR, auquel cas cette valeur par défaut est utilisée, soit un message d’erreur est émis indiquant que l’objet LICR demandé n’est pas disponible dans l’encodage actuel. Il existe plusieurs façons de définir les valeurs par défaut des objets LICR.
1\DeclareTextCommandDefault{LICR-object}[num][default]{code}La commande \DeclareTextCommandDefault fournit la définition par défaut d’un objet LICR à utiliser chaque fois qu’il n’y a pas de paramètre spécifique pour un objet dans l’encodage actuel. De telles définitions peuvent, par exemple, simuler un certain caractère. Par exemple, \textregistered a une définition par défaut dans laquelle le caractère est construit à partir de deux autres, comme ceci :
1\DeclareTextCommandDefault{\textregistered}{\textcircled{\scshape r}}Techniquement, les définitions par défaut sont stockées sous forme d’encodage avec le nom « ? ». Bien que vous ne deviez pas vous fier à ce fait, car l’implémentation pourrait changer à l’avenir, cela signifie que vous ne pouvez pas déclarer un encodage portant ce nom.
1\DeclareTextSymbolDefault{LICR-object}{encoding}Dans la plupart des cas, une définition par défaut ne nécessite pas de codage mais demande simplement à LaTeX de prendre le caractère à partir d’un codage dans lequel il est connu pour exister. Le package textcomp, par exemple, contient un grand nombre de déclarations par défaut qui pointent toutes vers l’encodage TS1. Par exemple:
1\DeclareTextSymbolDefault{\texteuro}{TS1}La commande \DeclareTextSymbolDefault peut être utilisée pour définir la valeur par défaut de tout objet LICR sans arguments, pas seulement ceux déclarés avec la commande \DeclareTextSymbol dans d’autres encodages.
1\DeclareTextAccentDefault{LICR-accent}{encoding}Il existe une déclaration similaire pour les objets LICR qui acceptent un seul argument, comme les accents. Encore une fois, ce formulaire est utilisable pour tout objet LICR avec un seul argument. Le noyau LaTeX, par exemple, contient un certain nombre de déclarations du type :
1\DeclareTextAccentDefault{\"}{OT1}
2\DeclareTextAccentDefault{\t}{OML}Cela signifie que si le \" n’est pas défini dans l’encodage actuel, alors utilisez celui d’une police encodée OT1. De même, pour obtenir un accent de cravate, récupérez-le dans OML si rien de mieux n’est disponible .
1\ProvideTextCommandDefault{LICR-object}[num][default]{code}La déclaration \ProvideTextCommandDefault permet de “fournir” un autre type de valeur par défaut. Elle fait le même travail que la déclaration \DeclareTextCommandDefault, sauf que la valeur par défaut n’est fournie que si aucune valeur par défaut n’a été définie auparavant. Ceci est principalement utilisé dans les fichiers de codage d’entrée pour fournir une sorte de valeurs par défaut triviales pour les objets LICR inhabituels. Par exemple:
1\ProvideTextCommandDefault{\textonequarter}{\ensuremath{\frac14}}
2\ProvideTextCommandDefault{\textcent}{\TextSymbolUnavailable\textcent}Des packages comme textcomp peuvent alors remplacer ces définitions par des déclarations pointant vers de vrais glyphes. L’utilisation de \Provide... au lieu de \Declare... garantit qu’une meilleure valeur par défaut n’est pas accidentellement écrasée si le fichier de codage d’entrée est lu.
1\UndeclareTextCommand{LICR-object}{encoding}Dans certains cas, une déclaration existante doit être supprimée pour garantir qu’une déclaration par défaut est utilisée à la place. Cela peut être fait en utilisant \UndeclareTextCommand. Par exemple, le package textcomp supprime les définitions de \textdollar et \textsterling du codage OT1 car toutes les polices encodées OT1 n’ont pas réellement ces symboles.
1\UndeclareTextCommand{\textsterling}{OT1}
2\UndeclareTextCommand{\textdollar} {OT1}Sans cette suppression, les nouvelles déclarations par défaut pour récupérer les symboles de « TS1 » ne seraient pas utilisées pour les polices codées avec « OT1 ».
1\UseTextSymbol{encoding}{LICR-object}
2\UseTextAccent{encoding}{LICR-object}{simple-LICR-object}L’action cachée derrière les déclarations \DeclareTextSymbolDefault et \DeclareTextAccentDefault peut également être utilisée directement. Supposons, par exemple, que le codage actuel soit « U ». Dans ce cas,
1\UseTextSymbol{OT1}{\ss}
2\UseTextAccent{OT1}{\'}{a}a le même effet que de saisir le code ci-dessous. Notez en particulier que le « a » est composé dans le codage « U » - seul l’accent est extrait de l’autre codage.
1{\fontencoding{OT1}\selectfont\ss}
2{\fontencoding{OT1}\selectfont\'{\fontendcoding{U}\selectfont a}}Une liste d’objets LICR standard
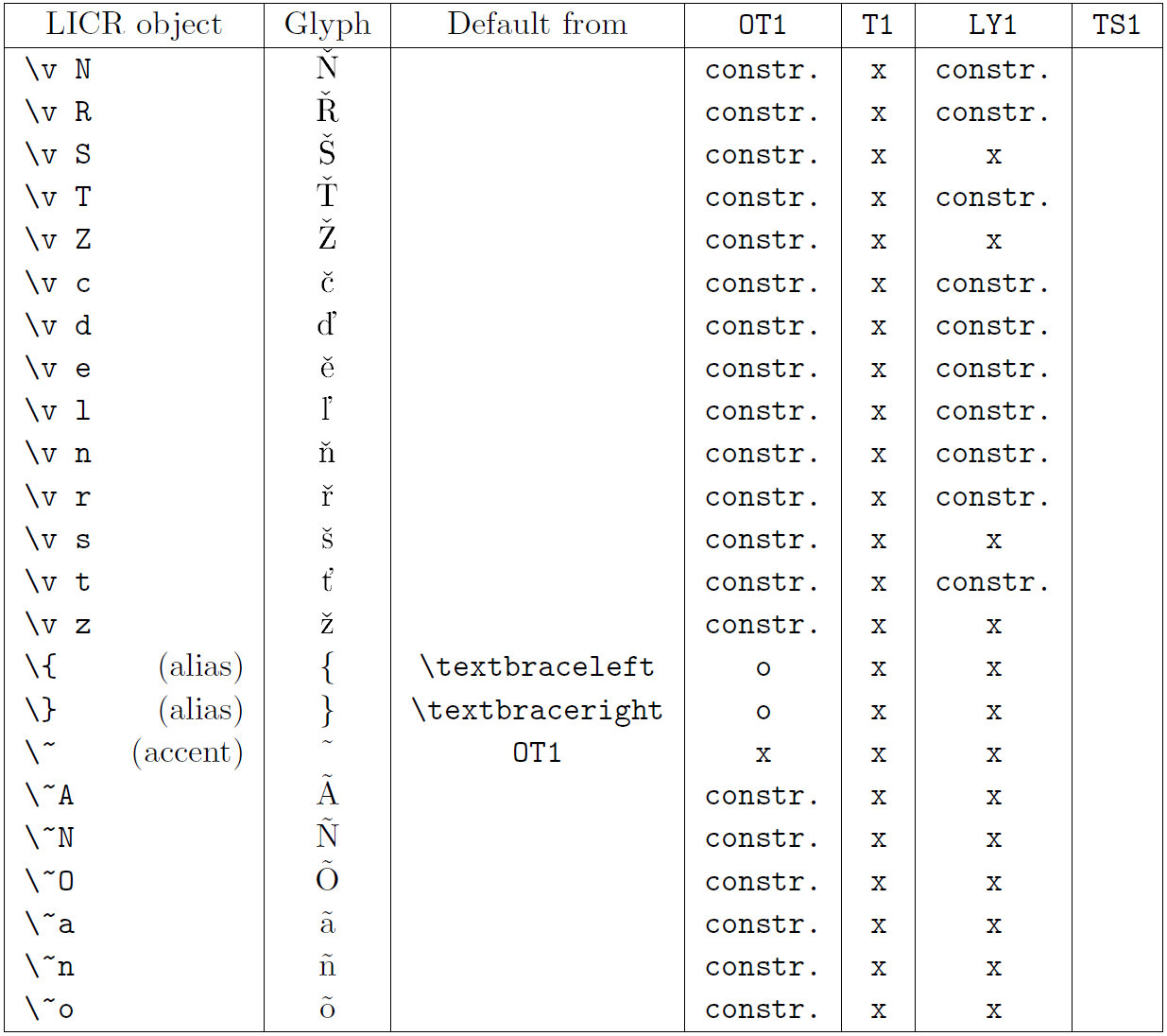
Le tableau de cette sous-section donne un aperçu des représentations internes de LaTeX disponibles avec les trois principaux encodages pour les langues latines : OT1 (l’encodage TeX d’origine), T1 (l’encodage standard LaTeX) et LY1 ( un codage alternatif sur 8 bits proposé par Y&Y). De plus, il affiche tous les objets LICR déclarés par « TS1 » (le codage de symboles de texte standard LaTeX) fournis en chargeant le package « textcomp ».
La première colonne du tableau affiche les noms d’objet LICR par ordre alphabétique, indiquant quels objets LICR agissent comme des accents. La deuxième colonne montre une représentation glyphe de l’objet.
La troisième colonne décrit si l’objet a une déclaration par défaut. Si un encodage est répertorié, cela signifie que par défaut le glyphe est récupéré à partir d’une police appropriée dans cet encodage ; constr. signifie que la valeur par défaut est produite à partir de code TeX de bas niveau ; si la colonne est vide, cela signifie qu’aucune valeur par défaut n’est définie pour cet objet LICR. Dans ce dernier cas, une erreur “Symbole indisponible” est renvoyée lorsque vous l’utilisez dans un encodage pour lequel il n’a pas de définition explicite. Si l’objet est un alias pour un autre objet LICR, l’autre nom est répertorié dans cette colonne.
Les colonnes quatre à sept indiquent si un objet est disponible dans le codage donné. Ici, « x » signifie que l’objet est disponible de manière native (sous forme de glyphe) dans les polices avec cet encodage, « o » signifie qu’il est disponible par défaut pour tous les encodages, et « constr. » signifie qu’il est généré à partir de plusieurs des glyphes, des accents ou d’autres éléments. Si la valeur par défaut est récupérée depuis TS1, l’objet LICR n’est disponible que si le package textcomp est chargé.
Objets LICR. Partie 1
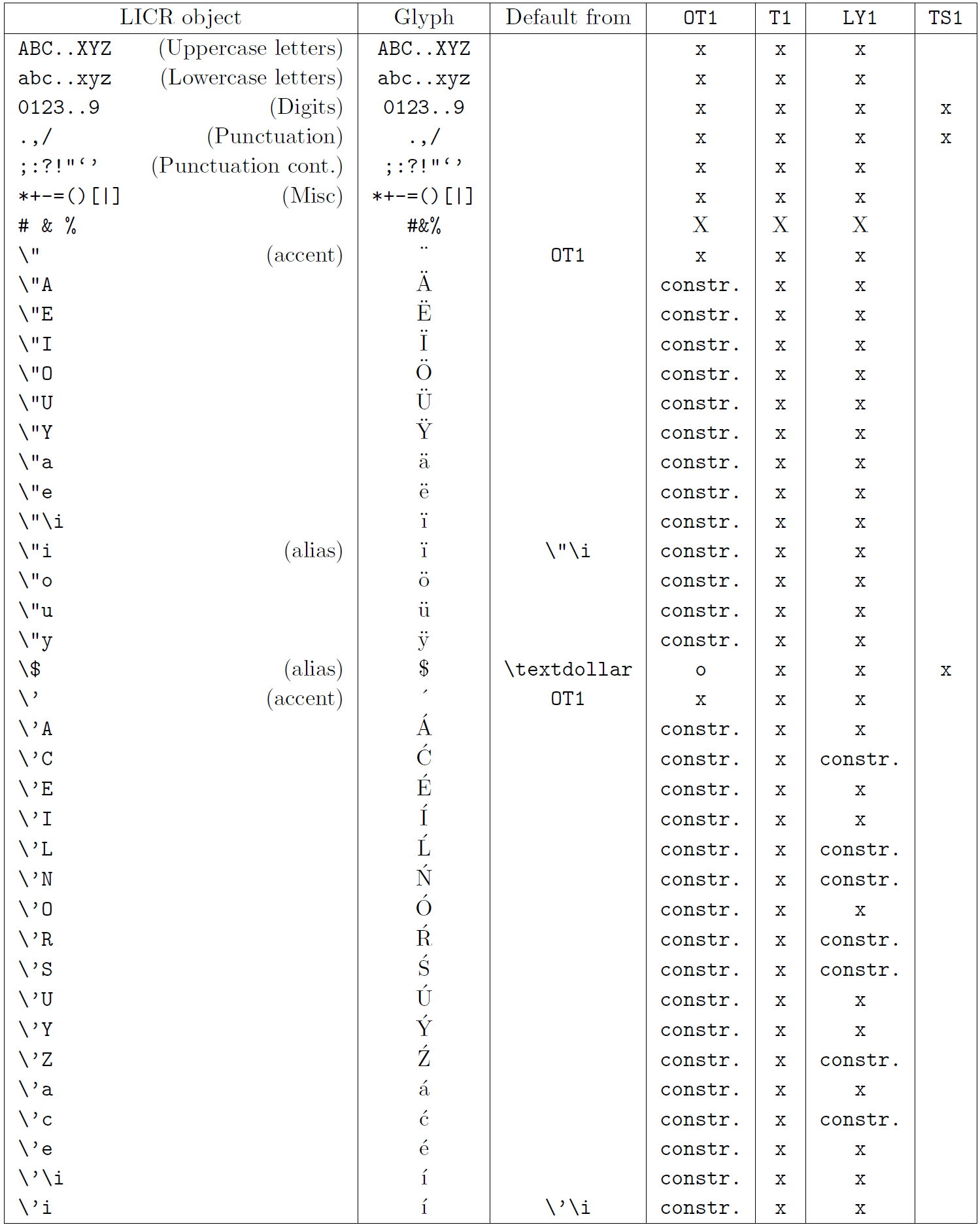
Objets LICR. Partie 2
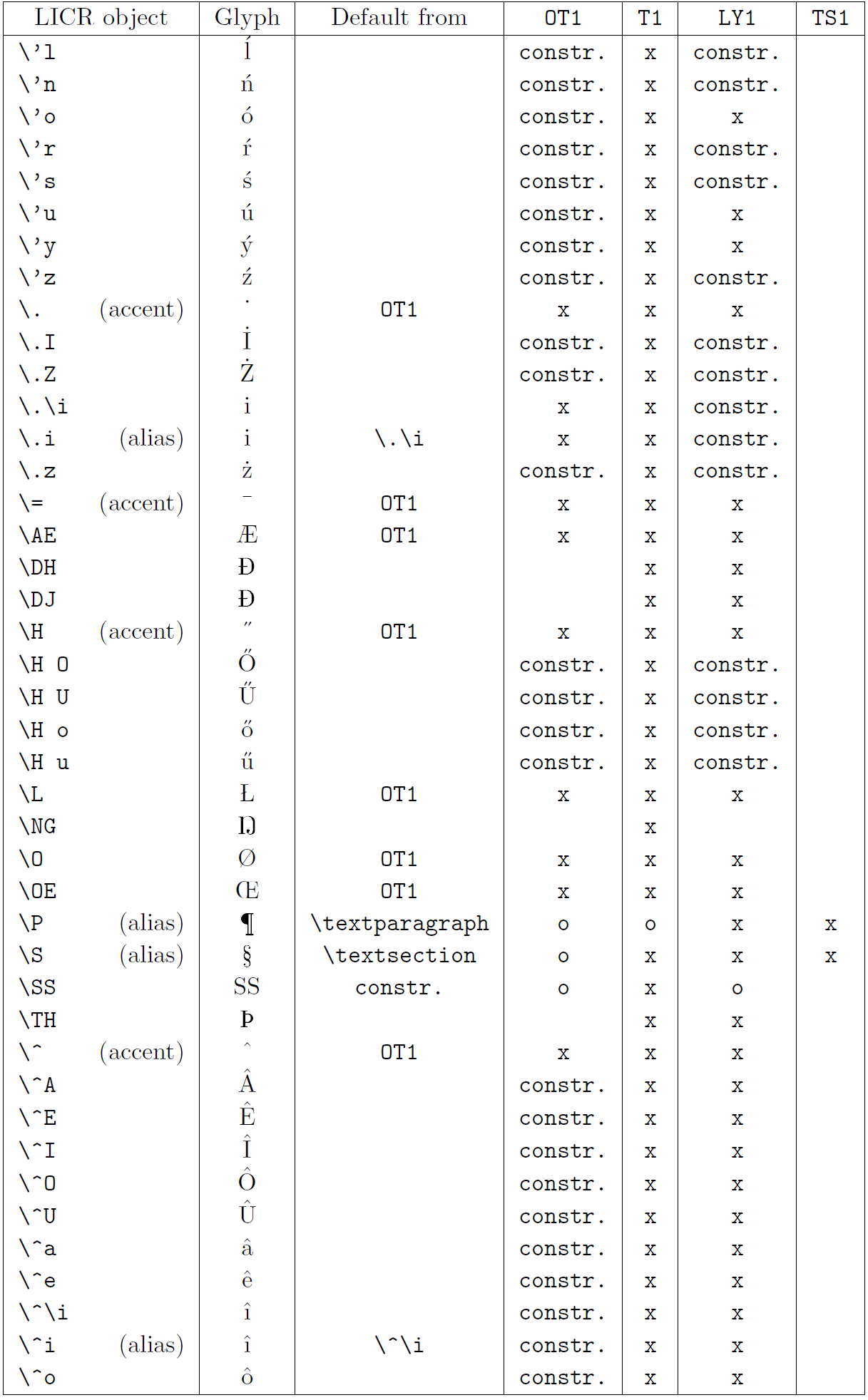
Objets LICR. Partie 3
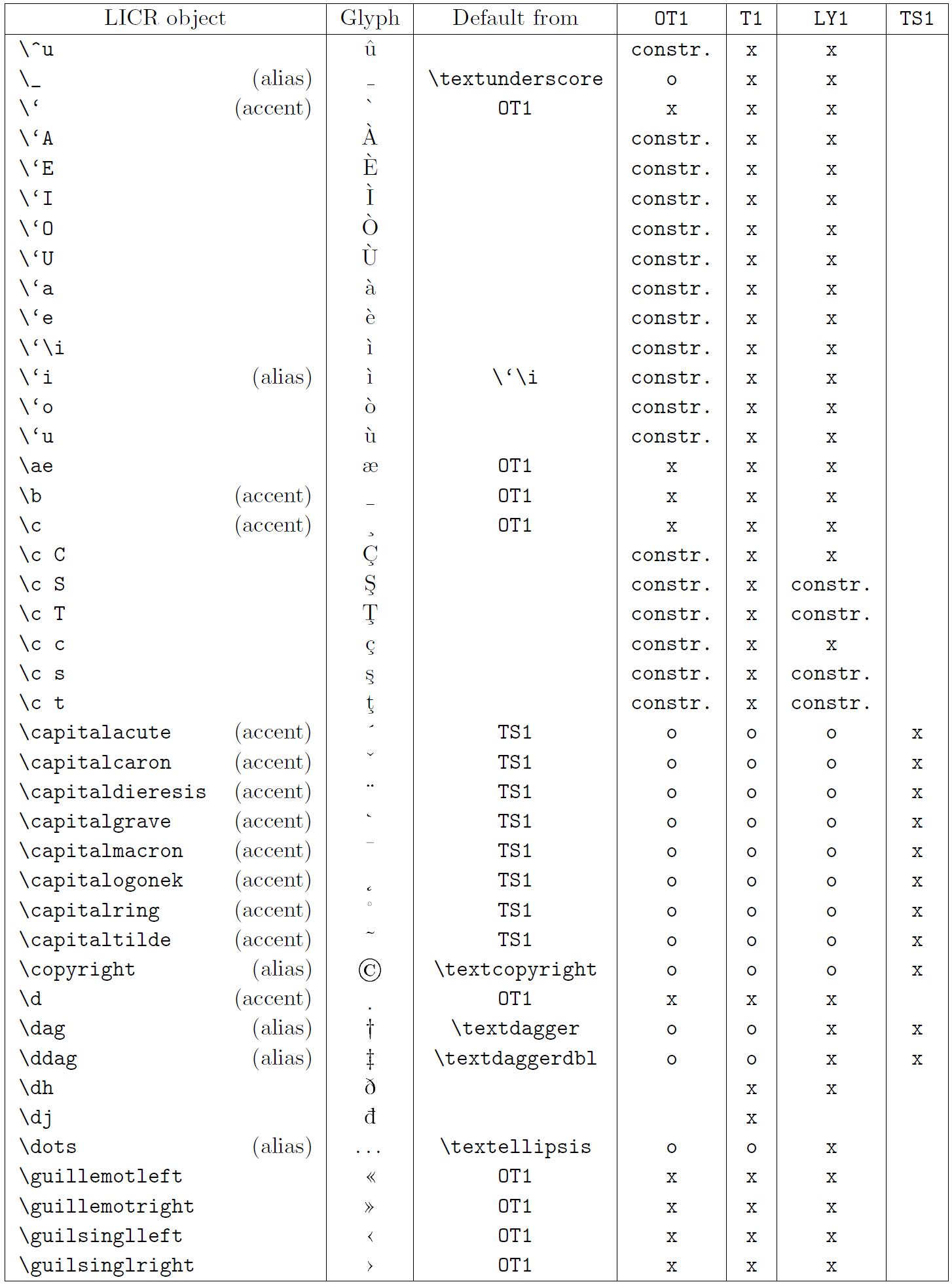
Objets LICR. Partie 4
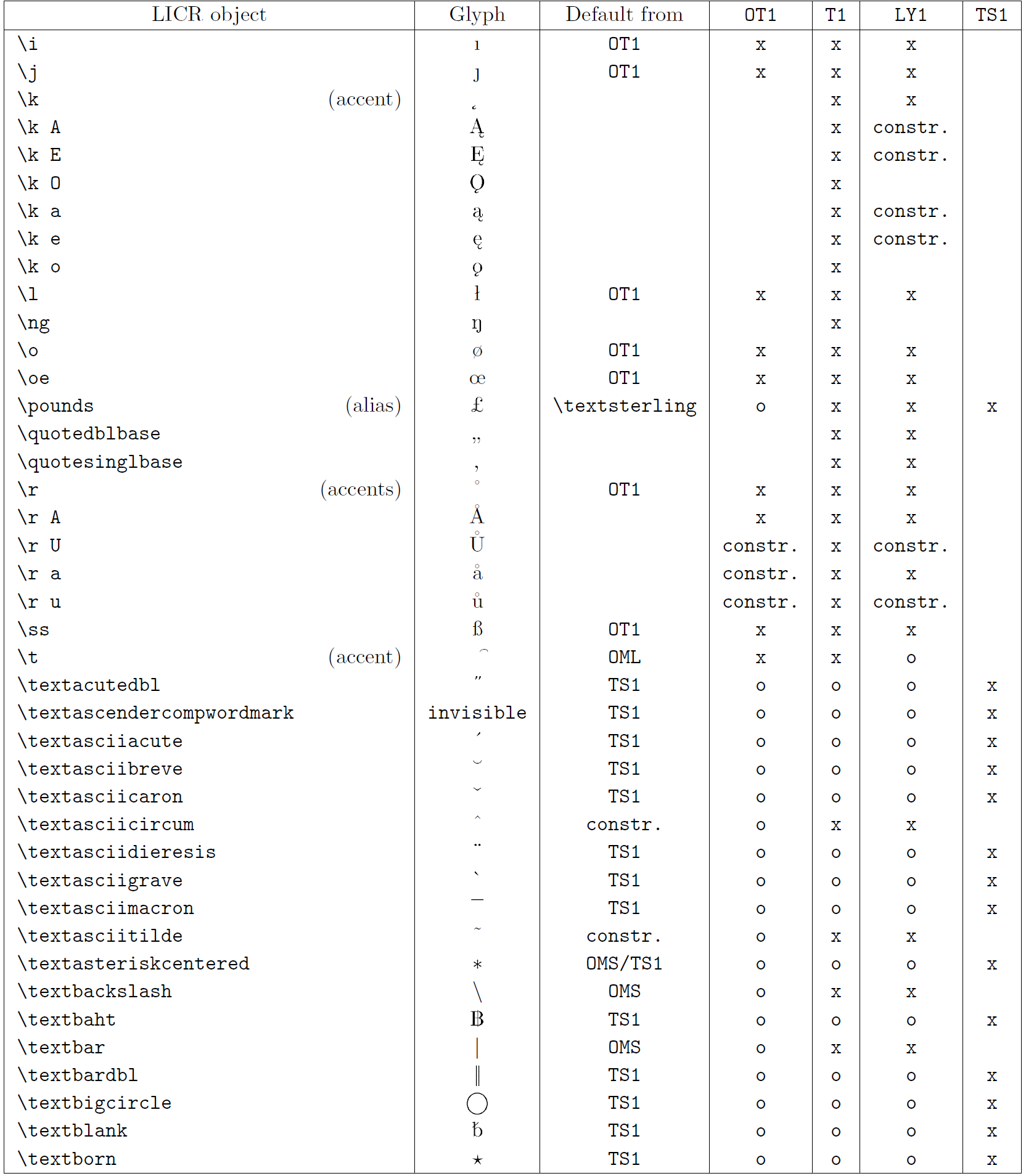
Objets LICR. Partie 5
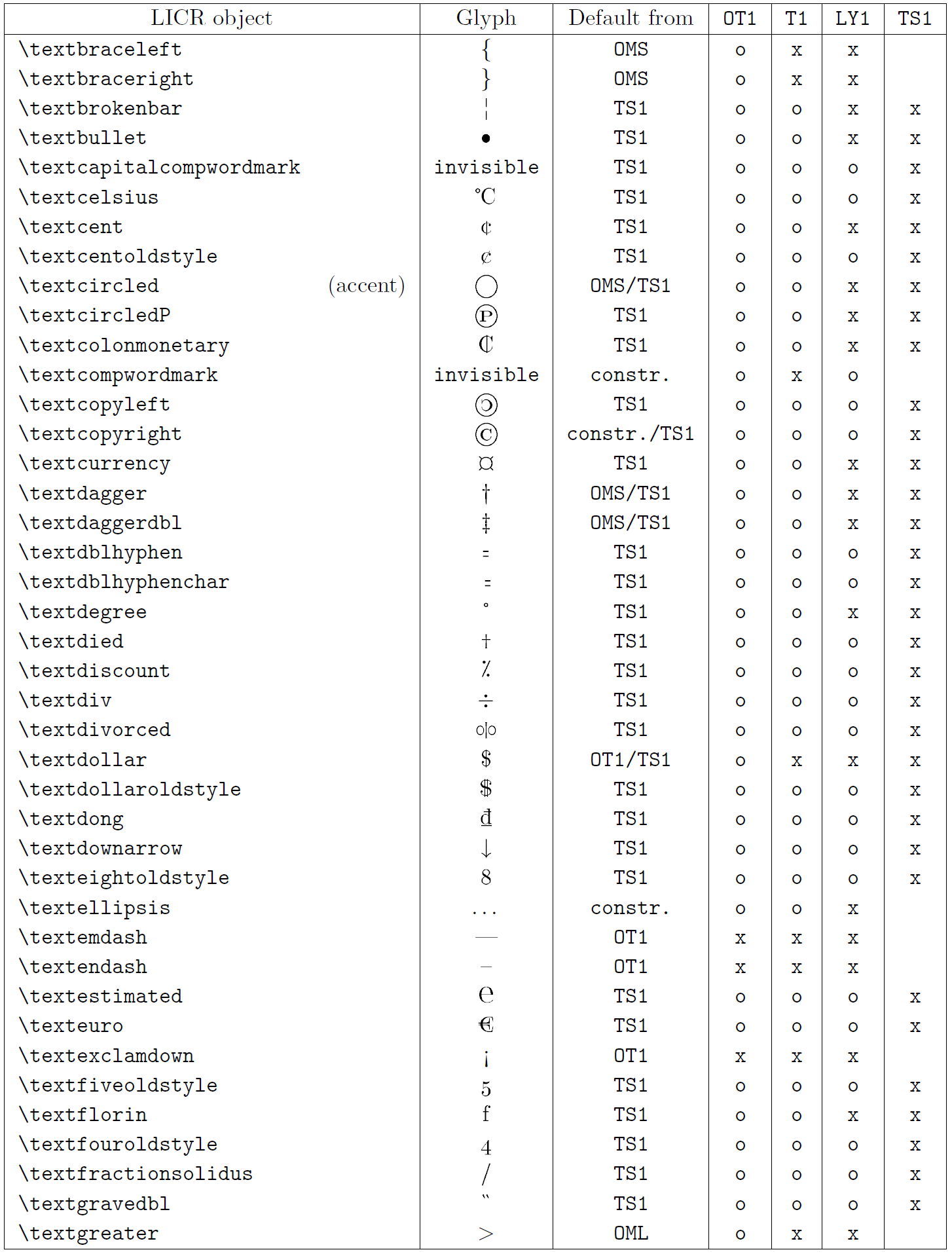
Objets LICR. Partie 6
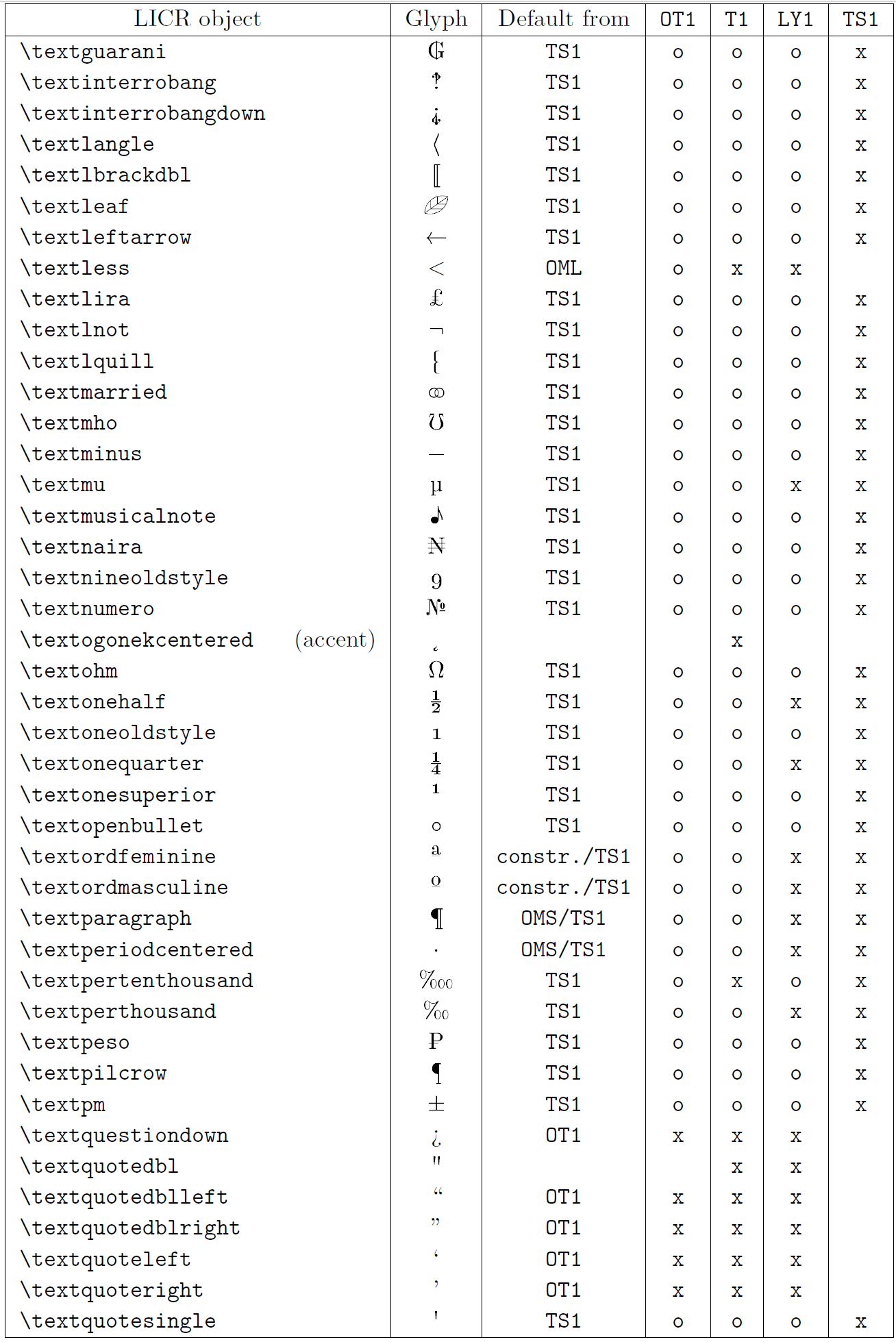
Objets LICR. Partie 7
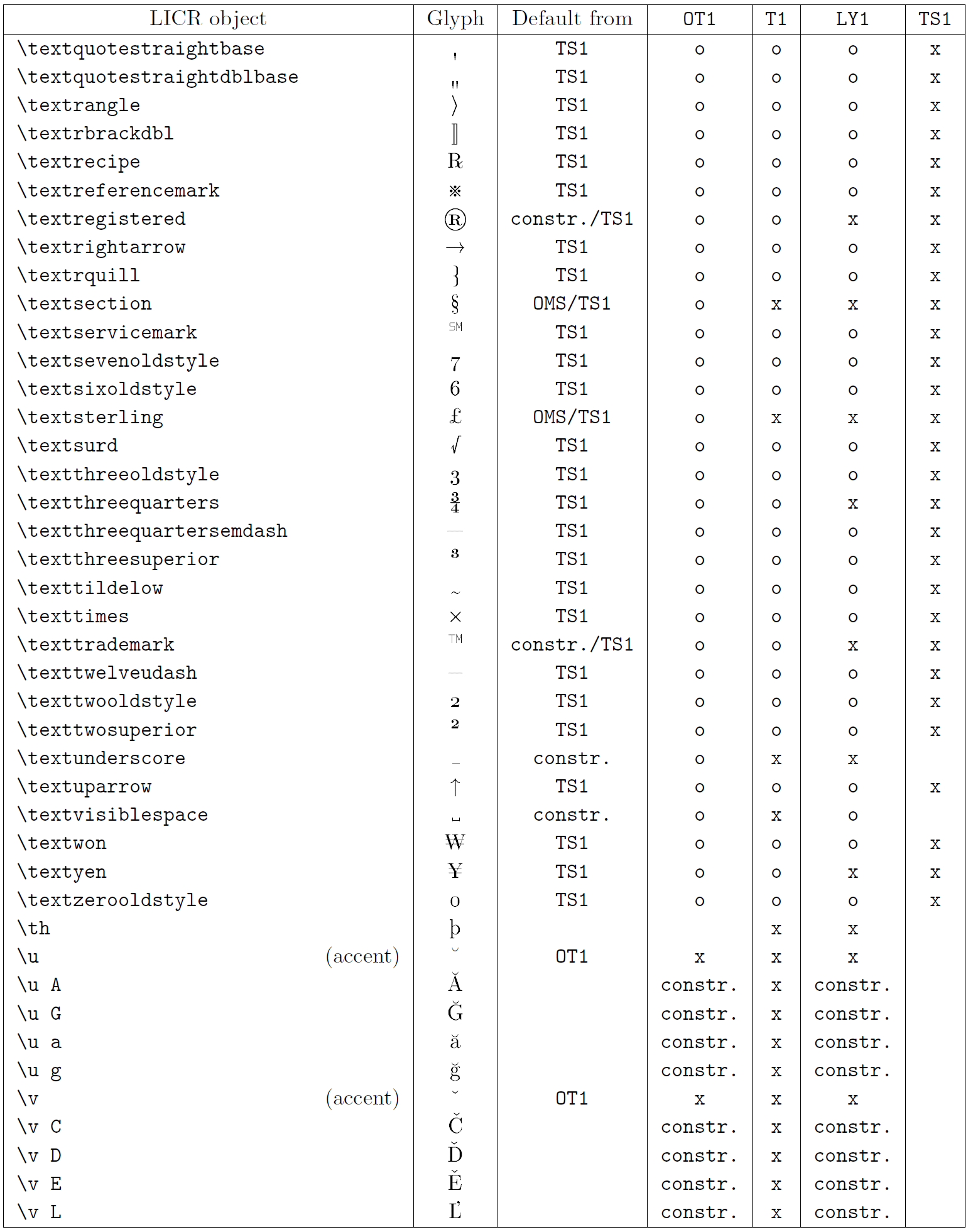
Objets LICR. Partie 8