4. Polices LaTeX standards
Cet article contient une brève introduction aux polices de texte standard distribuées avec LaTeX. Il couvre ensuite la prise en charge standard de LaTeX pour les encodages d’entrée et de polices. L’article se termine par une description d’un package permettant de tracer le traitement des polices LaTeX et d’un autre package permettant d’afficher des graphiques de glyphes.
4.1. Ordinateur moderne romain
Une famille de polices appelée Computer Modern a été développée par Donald Knuth avec TeX. Jusqu’au début des années 1990, seules ces polices étaient principalement utilisables avec TeX et, par conséquent, avec LaTeX. Chacune de ces polices ne contient que 128 glyphes, elles ne peuvent donc pas inclure de caractères accentués en tant que glyphes individuels. Par conséquent, l’utilisation de ces polices signifie que les caractères accentués doivent être produits avec la primitive \accent de TeX, ce qui, à son tour, signifie que la césure automatique des mots avec des caractères accentués est impossible. Bien que cette restriction soit acceptable pour les documents anglais, elle constitue un inconvénient évident pour les autres langues.
Ces lacunes préoccupaient grandement les utilisateurs de TeX en Europe et ont finalement conduit à une réimplémentation de TeX en 1989 pour prendre en charge les caractères 8 bits en interne et en externe. Un codage standard sur 8 bits pour les polices de texte (« T1 ») a été développé en 1990. Il contient de nombreux caractères diacritiques et permet la composition dans plus de 30 langues basées sur l’alphabet latin. Ensuite, les familles de polices Computer Modern ont été réimplémentées et des caractères supplémentaires ont été conçus afin que les polices résultantes soient entièrement conformes à ce schéma de codage.
4.2. Sélection de l’encodage d’entrée : le package inputenc
Si vous pouvez saisir des caractères accentués soit via des frappes simples, soit par une autre méthode de saisie (par exemple, en appuyant sur ` puis sur a pour obtenir ‘a-grave’), et que votre ordinateur les affiche correctement dans le éditeur…

… alors idéalement, vous utiliseriez un tel texte directement avec LaTeX au lieu d’avoir à taper \`a, \^e, etc.
Avec des langues comme le français et l’allemand, cette dernière approche est réalisable. Cependant, pour des langues comme le russe et le grec, la possibilité d’une saisie directe est nécessaire, car presque tous les caractères de ces langues ont un nom de commande comme forme interne LaTeX. Par exemple, la définition russe par défaut de « \reftextafter » contient le texte suivant (qui signifie « sur la page suivante ») :
1\cyrn\cyra\ \cyrs\cyrl\cyre\cyrd\cyru\cyryu\cyrshch\cyre\cyrishrt
2\ \cyrs\cyrt\cyrr\cyra\cyrn\cyri\cyrc\cyreIl est peu probable que quelqu’un veuille taper de telles choses régulièrement. Néanmoins, il présente l’avantage d’être universellement portable, de sorte qu’il puisse être correctement interprété sur n’importe quelle installation LaTeX. Par contre, en tapant
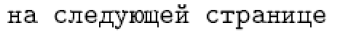
sur un clavier approprié est clairement préférable, s’il est possible de faire comprendre à LaTeX cette saisie. Le problème est que ce qui est stocké dans un fichier, ce ne sont pas les caractères que nous voyons dans la séquence ci-dessus, mais plutôt les octets qui représentent les caractères. Dans différentes circonstances (en utilisant des codages différents), les mêmes octets peuvent représenter des caractères différents.
Tant que tout se passe sur un seul ordinateur et que tous les programmes interprètent les octets des fichiers de la même manière, tout va généralement bien. Si tel est le cas, il est logique d’activer un mécanisme de traduction automatique intégré à certaines implémentations récentes de TeX. Mais lorsqu’un fichier produit dans un tel environnement est envoyé vers un autre ordinateur, le traitement risque d’échouer ou, pire encore, peut sembler réussir, mais produira en fait des résultats erronés en affichant des caractères incorrects.
Le package inputenc a été créé pour résoudre ce problème. Son objectif principal est d’informer LaTeX de l’encodage utilisé dans le document ou dans une partie du document. Cela se fait en chargeant le package avec le nom d’encodage en option. Par exemple:
1\usepackage[cp1252]{inputenc} % Windows 1252 (Western Europe) code pageÀ partir de ce moment, LaTeX sait comment interpréter les octets du reste du document sur n’importe quelle installation, quel que soit l’encodage utilisé à d’autres fins sur cet ordinateur.
Un exemple typique est présenté ci-dessous. Il s’agit d’un court texte écrit avec le codage « koi8-r », populaire en Russie. Le code source montre à quoi ressemble le texte sur un ordinateur utilisant un codage Latin 1 (par exemple en Allemagne). Le résultat démontre que LaTeX était toujours capable d’interpréter le texte correctement car il lui était indiqué quel codage d’entrée était utilisé.

La liste des encodages actuellement pris en charge par « inputenc » est fournie ci-dessous. L’interface est bien documentée et la prise en charge de nouveaux encodages peut facilement être ajoutée. Par conséquent, il vaut la peine de consulter la documentation du package inputenc si l’encodage utilisé par votre ordinateur n’est pas répertorié ici. Vous pouvez également rechercher sur Internet des fichiers de codage pour « inputenc » créés par d’autres auteurs. Par exemple, les encodages liés aux langues cyrilliques sont distribués avec d’autres packages de prise en charge de polices pour les langues cyrilliques.
La norme ISO-8859 définit un certain nombre de codages importants sur un octet. Les codages liés à l’alphabet latin sont pris en charge par inputenc. Pour le système d’exploitation Windows, un certain nombre de codages sur un seul octet ont été définis par Microsoft. De plus, certains codages définis par d’autres fournisseurs d’ordinateurs sont disponibles.
latin1Il s’agit du codage ISO-8859-1 (alias Latin 1). Il peut représenter la plupart des langues d’Europe occidentale, notamment l’albanais, le catalan, le danois, le néerlandais, l’anglais, le féroïen, le finnois, le français, le galicien, l’allemand, l’islandais, l’irlandais, l’italien, le norvégien, le portugais, l’espagnol et le suédois.latin2Le codage ISO Latin 2 (ISO-8859-2) prend en charge les langues slaves d’Europe centrale qui utilisent l’alphabet latin. Il peut être utilisé pour les langues suivantes : croate, tchèque, allemand, hongrois, polonais, roumain, slovaque et slovène.latin3Ce jeu de caractères (ISO-8859-3) est utilisé pour l’espéranto, le galicien, le maltais et le turc.latin4Le codage ISO Latin 4 (ISO-8859-4) peut représenter des langues telles que l’estonien, le letton et le lituanien.latin5Le codage ISO Latin 5 (ISO 8859-9) est étroitement lié au Latin 1 et remplace les lettres islandaises rarement utilisées du Latin 1 par des lettres turques.latin9Latin 9 (ou ISO-8859-15) est une autre petite variation du Latin 1 qui ajoute le signe monétaire de l’euro ainsi que quelques autres caractères, comme la ligature\AE, qui manquaient en français et Finlandais. Il devient de plus en plus populaire en remplacement du latin 1.- Page de codes IBM 437
cp437(MS-DOS Latin mais contenant de nombreux caractères graphiques pour dessiner des boîtes). - Page de codes IBM 850
cp850(MS-DOS multilingue, similaire à latin1). - Page de codes IBM 852
cp852(MS-DOS multilingue, similaire à latin2). - Page de codes IBM 858
cp858(IBM 850 avec le symbole euro ajouté). - Page de codes IBM 865
cp865(MS-DOS Norvège). - Page de codes
cp1250Windows 1250 (Europe centrale et orientale). - Page de codes
cp1252Windows 1252 (Europe occidentale). - Page de codes Windows 1257 (Baltique)
cp1257. - Encodage ANSI
ansinewWindows 3.1 ; un synonyme de cp1252. - Encodage du jeu de caractères multinational DEC
decmulti. - Encodage Macintosh (standard)
applemac. - Page de codes Macintosh d’Europe centrale
macce. suivantEncodage de l’ordinateur suivant.utf8Prise en charge de l’encodage UTF8 d’Unicode.
La plupart des installations TeX acceptent les caractères 8 bits par défaut. Néanmoins, sans ajustements supplémentaires, comme ceux effectués par inpuenc, les résultats peuvent être imprévisibles : certains caractères peuvent disparaître, ou vous pouvez obtenir n’importe quel caractère présent dans la police actuelle à l’emplacement de l’octet référencé, qui peut ou non être le glyphe souhaité. Ce comportement a été le comportement par défaut pendant longtemps, il n’a donc pas été modifié dans LaTeX2e car certaines personnes l’utilisent. Cependant, pour garantir que de telles erreurs puissent être détectées, inputenc propose l’option ascii, qui rend illégal tout caractère en dehors de la plage 32-126.
1\inputencoding{encoding}À l’origine, le package inputenc a été conçu pour spécifier l’encodage utilisé pour un document dans son ensemble - d’où l’utilisation d’options dans le préambule. Cependant, il est possible de modifier l’encodage au milieu d’un document en utilisant la commande \inputencoding. Cette commande prend le nom d’un encodage comme argument.
Lorsque inputenc a été développé, la plupart des installations de LaTeX se trouvaient sur des ordinateurs qui utilisaient des codages à un octet comme ceux abordés dans cette section. Cependant, aujourd’hui, un autre codage est populaire car les systèmes prennent en charge Unicode : UTF8. Ce codage de longueur variable représente les caractères Unicode sur un à quatre octets. La prise en charge de l’encodage a été ajoutée à « inputenc » via l’option « utf8 ». Techniquement, il ne fournit pas une implémentation UTF8 complète. Seuls les caractères Unicode qui ont une certaine représentation dans les polices LaTeX standard sont mappés (c’est-à-dire principalement les jeux de caractères latins et cyrilliques) : tous les autres entraîneront un message d’erreur approprié. De plus, les caractères de combinaison Unicode ne sont pas pris en charge, bien que cette omission particulière ne devrait pas poser de problème en pratique.
1\usepackage[utf8]{inputenc}
2\usepackage{textcomp} % for Latin interpretation
3-----------------------------------------------
4German umlauts in UTF-8: ^^c3^^a4^^c3^^b6^^c3^^bc
5\par\inputencoding{latin1}% switch to Latin 1
6But interpreted as Latin 1: ^^c3^^a4^^c3^^b6^^c3^^bc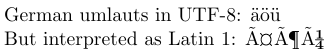
En UTF8, les caractères ASCII se représentent eux-mêmes et la plupart des caractères latins sont représentés par deux octets. Dans le code source de l’exemple, les représentations sur deux octets des trémas allemands en UTF8 sont affichées dans la notation hexadécimale de TeX, c’est-à-dire avec chaque octet précédé de « ^^ ». Dans un éditeur qui ne comprend pas UTF8, on les verrait probablement comme similaires à la sortie produite lorsqu’ils sont interprétés comme des caractères Latin 1.
Un package avec une prise en charge UTF8 plus complète (y compris la prise en charge des caractères coréens, chinois et japonais), bien que par conséquent plus complexe dans sa configuration, est le package « ucs » écrit par Dominique Unruh. Vous pouvez l’essayer si la solution inputenc ne couvre pas vos besoins.
4.3. Sélection des encodages de polices avec le package fontenc
Pour activer un codage de police de texte à utiliser avec LaTeX, le codage doit être chargé dans le préambule ou la classe du document. Plus précisément, les définitions permettant d’accéder aux glyphes dans les polices avec un certain encodage doivent être chargées. La manière canonique de procéder consiste à utiliser le package fontenc, qui prend une liste d’encodages de polices séparés par des virgules comme option du package. Le dernier de ces codages devient automatiquement le codage par défaut du document. Si des encodages cyrilliques sont chargés, la liste des commandes affectées par \MakeUppercase et \MakeLowercase est automatiquement étendue. Par exemple,
1\usepackage[T2A,T1]{fontenc}chargera toutes les définitions nécessaires pour les encodages cyrilliques T2A et T1 et définira ce dernier comme encodage de document par défaut.
Contrairement au comportement normal d’un package, on peut charger ce package plusieurs fois avec différentes options pour la commande \usepackage. Ceci est nécessaire pour permettre à une classe de document de charger un certain ensemble de codages et permettre à l’utilisateur de charger encore plus de codages dans le préambule. Le chargement des encodages plusieurs fois est effectué sans effets secondaires autres que la modification potentielle de l’encodage de police par défaut du document.
Si des packages de support linguistique (par exemple, ceux fournis avec le système babel) sont utilisés dans le document, il arrive souvent que les encodages de polices nécessaires soient déjà chargés par le package de support.
4.4. Comment tracer la sélection de polices avec le package tracefnt
Pour détecter les problèmes dans le système de sélection des polices, vous pouvez utiliser le package tracefnt. Il prend en charge plusieurs options qui permettent de personnaliser la quantité d’informations affichées par NFSS à l’écran et dans le fichier de transcription.
errorshowCette option supprime tous les messages d’avertissement et d’information sur le terminal ; ils seront écrits uniquement dans le fichier de transcription. Seules les erreurs réelles seront affichées. Vous devez étudier attentivement le fichier de transcription avant d’imprimer une publication importante, car les avertissements concernant les substitutions de polices, etc. peuvent signifier que le résultat final sera incorrect.warningshowLorsque cette option est spécifiée, les avertissements et les erreurs sont affichés sur le terminal. Ce paramètre vous donne des informations aussi détaillées que LaTeX2e sans le packagetracefntchargé.infoshowCette option est celle par défaut lorsque vous chargez le packagetracefnt. Les informations supplémentaires, qui sont normalement uniquement écrites dans le fichier de transcription, sont désormais également affichées sur votre terminal.debugshowCette option affiche en outre des informations sur les modifications apportées à la police du texte et la restauration de ces polices à la fin d’un groupe d’accolades ou à la fin d’un environnement. Soyez prudent lorsque vous activez cette option car elle peut produire des fichiers de transcription très volumineux.pausingCette option transforme tous les avertissements en erreurs pour faciliter la détection des problèmes dans les publications importantes.loadingCette option affiche le chargement des polices externes. Cependant, si le format ou la classe de document que vous utilisez a déjà chargé certaines polices, celles-ci ne seront pas affichées par cette option.
4.5. Comment afficher des tables de polices et des exemples avec nfssfont.tex
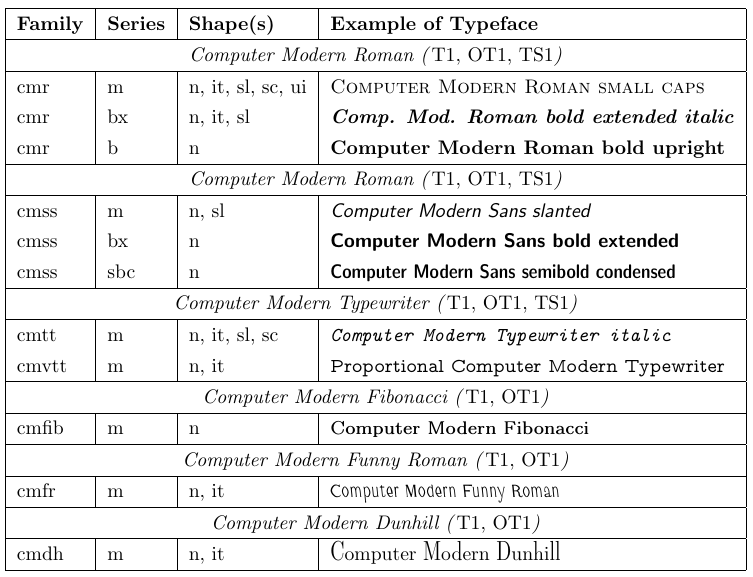
Le fichier appelé « nfssfont.tex » peut être utilisé pour tester de nouvelles polices, produire des tables de polices affichant tous les caractères et effectuer d’autres opérations liées aux polices. Vous pouvez trouver ce fichier dans n’importe quelle distribution LaTeX. Lorsque vous exécutez ce fichier via LaTeX, vous serez invité à saisir le nom de la police à tester. La réponse peut être soit le nom de police externe sans extension - tel que « cmr10 » (Computer Modern Roman 10pt) - si vous le connaissez, soit un nom de police vide. Dans ce dernier cas, il vous sera demandé une spécification de police NFSS : un nom d’encodage (par défaut T1), un nom de famille de police (par défaut cmr), une série de polices (par défaut m), une forme de police ( par défaut n) et une taille de police (par défaut 10pt). Le programme charge ensuite le fichier externe correspondant à cette classification.
Ensuite, il vous sera demandé de saisir une commande. Le plus important est probablement \table, qui produit un tableau de polices comme celui ci-dessous. La commande \text est également intéressante car elle produit un échantillon de texte plus long. Pour passer à une nouvelle police de test, tapez « \init » ; pour terminer le test, tapez \bye ou \stop ; et pour en savoir plus sur tous les autres tests disponibles, tapez \help.
1**********************************************
2* NFSS font test program version <v2.2b>
3*
4* Follow the instructions
5**********************************************
6
7Input external font name, e.g., cmr10
8(or <enter> for NFSS classification of font):
9
10\currfontname=cmr10
11Now type a test command (\help for help):)
12*\table
13
14*\newpage
15*\init
16Input external font name, e.g., cmr10
17(or <enter> for NFSS classification of font):
18
19\currfontname=
20*** NFSS classification ***
21
22Font encoding [T1]:
23
24\encoding=OT1
25(ot1enc.def)
26Font family [cmr]:
27
28\family=cmdh
29Font series [m]:
30
31\series=m
32Font shape [n]:
33
34\shape=n
35Font size [10pt]:
36
37\size=10
38(ot1cmdh.fd) Now type a test command (\help for help):
39*\text
40
41*\bye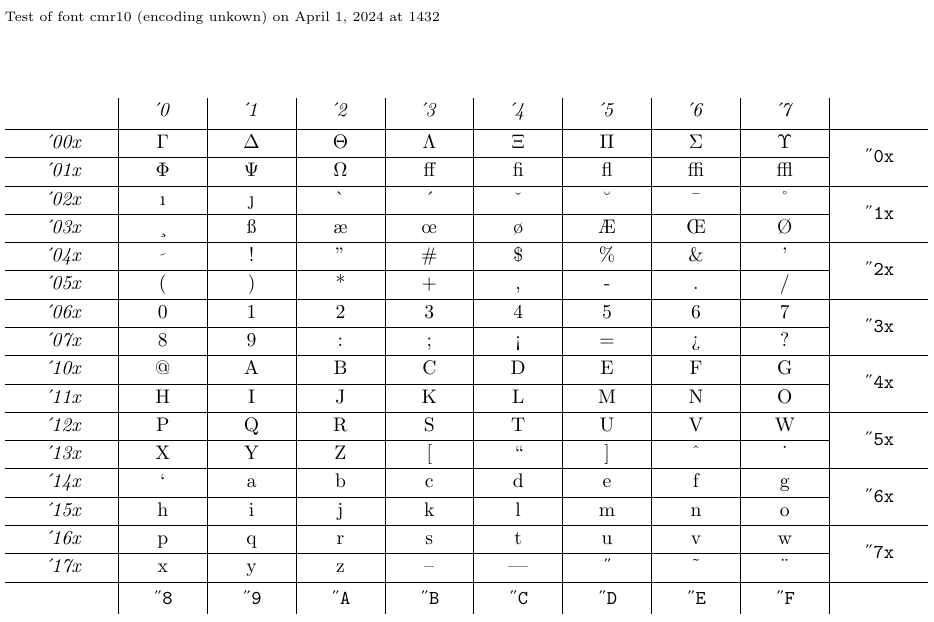

Il y a deux points à prendre en compte. Tout d’abord, le programme
nfssfont.texémet une commande\initimplicite, donc la première ligne d’entrée doit soit contenir un nom de police, soit être complètement vide pour indiquer qu’une classification NFSS suit. Ensuite, l’entrée de\initdoit apparaître sur des lignes individuelles sans rien d’autre (pas même un commentaire) car la fin de la ligne indique la fin de la réponse à une invite commeFont encoding[T1]: \encoding=que vous obtiendrez.