7. Modello di LaTeX per codifica dei caratteri
Questo articolo copre in dettaglio le codifiche in LaTeX. Si inizia con una discussione sul flusso di dati dei caratteri all’interno del sistema LaTex. Successivamente, diamo un’occhiata più da vicino al modello di rappresentazione interna per i dati dei caratteri all’interno del LaTeX, seguito da una discussione dei meccanismi utilizzati per mappare i dati in arrivo tramite codifica di input in quella rappresentazione interna. Infine, spieghiamo come viene tradotta la rappresentazione interna, tramite le codifiche di output, nel modulo richiesto per la composizione.
7.1. Il flusso di dati dei caratteri all’interno del LaTeX
L’elaborazione di un documento con LaTeX inizia interpretando i dati presenti in uno o più file di origine. Questi dati che rappresentano il contenuto del documento sono archiviati nei file di origine come sequenze di ottetti che rappresentano caratteri. Per interpretare correttamente questi ottetti, qualsiasi programma (incluso il LaTeX) utilizzato per elaborare il file deve conoscere la mappatura tra caratteri astratti e gli ottetti che li rappresentano. In altre parole, deve sapere la codifica che è stata utilizzata quando il file è stato scritto.
Con una mappatura errata, ogni ulteriore elaborazione sarà più o meno errata a meno che il file non contenga solo caratteri di un sottoinsieme comune in codifiche sia corrette che errate.
Il LaTeX fa un presupposto fondamentale a questo punto: quasi tutti i caratteri ASCII visibili (decimale 32-126) sono rappresentati dal numero che hanno nella tabella del codice ASCII.

Uno dei motivi di questo presupposto è che la maggior parte delle codifiche a 8 bit in uso oggi condividono un piano comune a 7 bit. Un altro motivo è che, per usare efficacemente Tex, la maggior parte della porzione visibile di ASCII deve essere elaborata come caratteri della lettera di categoria * - poiché solo i personaggi con questa categoria possono essere usati nei nomi dei comandi a più caratteri in tex - o categoria other - All’altra * - poiché Tex non, ad esempio, non riconoscerà le cifre decimali come parte di un numero se non hanno questo codice di categoria.
Quando un personaggio (o, più precisamente, un numero a 8 bit) viene dichiarato di essere di categoria letter o other in tex, allora questo numero a 8 bit verrà trasmesso trasparentemente attraverso Tex. Ciò significa che Tex sottoposti a compensare qualunque simbolo sia nel carattere nella posizione indirizzata da quel numero.
Come conseguenza del presupposto di cui sopra, i caratteri intendevano essere utilizzati per il testo generale richiedono che (la maggior parte) i caratteri visibili ASCII siano presenti nel carattere e codificati in base alla codifica ASCII.
A tutti gli altri numeri a 8 bit (quelli esterni visibili ASCII) potenzialmente presenti nel file di input sono assegnati un codice di categoria active, che li fa agire come comandi all’interno di Tex. Pertanto, il LaTeX può trasformarli tramite le codifiche di input in una forma che chiameremo *la LaTeX di rappresentazione del carattere interno (LICR) *.
Per quanto riguarda la codifica UTF8 di Unicode, viene gestito in modo simile. I caratteri ASCII si rappresentano e gli ottetti iniziali per la rappresentazione multi-byte agiscono come caratteri attivi che scansionano l’input per gli ottetti rimanenti. Il risultato verrà trasformato in un oggetto nel LICR se è mappato, o il LaTeX lancerà un errore se il carattere Unicode dato non è mappato.
La cosa più importante degli oggetti nel LICR è che la rappresentazione di caratteri ASCII a 7 bit è invariante per qualsiasi cambiamento di codifica, poiché tutti i codifica input dovrebbero essere trasparenti rispetto all’ASCII visibile. Le codifiche di output (o carattere) servono quindi a mappare le rappresentazioni del carattere interno su posizioni di glifi nell’attuale carattere utilizzato per la composizione o, in alcuni casi, per avviare azioni più complesse. Ad esempio, può posizionare un accento (presente in una posizione nel carattere corrente) su qualche simbolo (in una posizione diversa nel carattere corrente) per ottenere un’immagine stampata del carattere astratto rappresentato dai comandi nella codifica del carattere interno.
Il LICR codifica tutti i caratteri possibili indirizzabili all’interno del LaTeX. Pertanto, è molto più grande del numero di caratteri che possono essere rappresentati da un singolo carattere Tex (che può contenere al massimo 256 glifi). In alcuni casi, un carattere nella codifica interna può essere reso con un carattere combinando glifi, come caratteri accentati. Tuttavia, quando il carattere interno richiede una forma speciale, non c’è modo di fingere se quel glifo non è presente nel carattere.
Tuttavia, il modello del LaTeX per la codifica dei caratteri supporta meccanismi automatici per recuperare glifi da caratteri diversi, in modo che i caratteri mancanti nell’attuale carattere ricevano il composizione, a condizione che sia disponibile un carattere aggiuntivo adatto contenenti.
7.2. Rappresentazione del personaggio interno di LaTex (LICR)
I caratteri di testo sono rappresentati internamente dal LaTeX in tre modi.
Rappresentazione come personaggi
Un piccolo numero di caratteri è rappresentato da “se stessi”. Ad esempio, il latino A è rappresentato come il personaggio “A”. Tali caratteri sono mostrati nella tabella sopra. Formano un sottoinsieme di ASCII visibile e all’interno di Tex, a tutti viene assegnato il codice di categoria di letter o other. Alcuni personaggi della gamma ASCII visibile non sono rappresentati in questo modo, sia perché fanno parte della sintassi di Tex o perché non sono presenti in tutti i caratteri. Se si usa, ad esempio, ‘<’ nel testo, la codifica del carattere corrente determina se si ottiene < (t1) o forse un marchio esclamativo invertito ( ot1) nell’output stampato.
Rappresentazione come sequenze di caratteri
Il meccanismo di legatura interna di Tex può generare nuovi caratteri da una sequenza di caratteri input. Questa è in realtà una proprietà del carattere, sebbene alcune di queste sequenze siano state esplicitamente progettate per servire come scorciatoie di input per caratteri che sono altrimenti difficili da affrontare con la maggior parte delle tastiere. Solo pochi caratteri generati in questo modo sono considerati appartenenti alla rappresentazione interna del LaTeX. Questi includono il trattino en dash ed em, che sono generati dalle legature -- e ---, e le doppie citazioni di apertura e chiusura, che sono generate da`` `` ``’’ (quest’ultimo può anche essere rappresentato anche dal singolo` ``). ?
Rappresentazione come comandi “specifici per codifica dei caratteri”
Il terzo modo per rappresentare i caratteri internamente nel LaTeX, che copre la maggior parte dei caratteri, è con speciali comandi in LaTeX (o sequenze di comandi) che rimangono non pagati quando scritti in un file o quando vengono inseriti in un argomento in movimento. Faremo riferimento a comandi speciali come * comandi specifici per codifica dei caratteri * perché il loro significato dipende dalla codifica dei caratteri attualmente utilizzata quando il LaTeX è pronto a compromettereli. Tali comandi sono dichiarati utilizzando dichiarazioni speciali, come discuteremo di seguito, che di solito richiedono definizioni individuali per ogni codifica dei caratteri. Se non esiste alcuna definizione per la codifica corrente, viene utilizzato un valore predefinito (se disponibile) o un messaggio di errore viene presentato all’utente. Quando la codifica del carattere viene modificata ad un certo punto nel documento, le definizioni dei comandi specifici della codifica non cambiano immediatamente, poiché ciò significherebbe cambiare un gran numero di comandi sul posto. Invece, questi comandi sono implementati in modo tale che una volta utilizzati, notano se la loro definizione attuale non è più adatta alla codifica del carattere in vigore. In tal caso, chiamano le loro controparti nella codifica del carattere corrente per fare il lavoro effettivo.
L’insieme di comandi specifici per codifica dei caratteri non è fisso ma è implicitamente definito come l’unione di tutti i comandi definiti per i singoli codifica di font. Pertanto, potrebbero essere richiesti nuovi comandi specifici per codifica dei caratteri quando vengono aggiunte nuove codifiche di carattere al LaTeX.
7.3. Codifica input
Una volta caricato il pacchetto inputenc, diventano disponibili le due dichiarazioni\dichiaraInputText e \dichiaraInputMath per la mappatura dei caratteri di input a 8 bit agli oggetti LICR. Dovrebbero essere utilizzati solo in file di codifica (vedi sotto), pacchetti o, se necessario, nel preambolo del documento.
Questi comandi prendono un numero a 8 bit come primo argomento, che può essere dato come numero decimale, numero ottale o in notazione esadecimale. L’uso della notazione decimale è consigliato poiché i personaggi `e/o` possono ottenere significati speciali in un pacchetto di supporto linguistico, come le scorciatoie per gli accenti, rendendo in tal modo la notazione ottale e/o esadecimale non valida se i pacchetti sono caricati nell’ordine sbagliato.
1\DeclareInputText{number}{LICR-object}Il comando `\dichiaraInputText dichiara le mappature dei caratteri per l’uso nel testo. Il suo secondo argomento contiene il comando (o la sequenza di comandi) specifica per codifica, ovvero gli oggetti LICR a cui il numero di carattere dovrebbe essere mappato. Per esempio,
1\DeclareInputText{239}{\"\i}mappa il numero 239 alla rappresentazione specifica della codifica della" i-Umlaut “, che è\"\ i. I caratteri di input dichiarati in questo modo non possono essere usati nelle formule di matematica.
1\DeclareInputMath{number}{math-object}Se il numero rappresenta un carattere da utilizzare nelle formule matematiche, deve essere utilizzata la dichiarazione \dichiaraInputMath. Ad esempio, nella codifica input CP437DE (tastiera MS-DOS tedesca),
1\DeclareInputMath{224}{\alpha}mappa il numero 224 al comando \alpha. È importante notare che questa dichiarazione renderebbe la chiave che produce questo numero utilizzabile solo in modalità matematica, poiché \alpha non è consentito da nessun’altra parte.
1\DeclareUnicodeCharacter{hex-number}{LICR-object}Questa dichiarazione è disponibile solo se viene utilizzata l’opzione UTF8. Mappa i numeri Unicode agli oggetti LICR (ovvero caratteri utilizzabili nel testo). Per esempio,
1\DeclareUnicodeCharacter{00A3}{\textsterling}
2\DeclareUnicodeCharacter{011A}{\v E}
3\DeclareUnicodeCharacter{2031}{\textpertenthousand}In teoria, dovrebbe esserci solo una mappatura bidirezionale unica tra i due spazi, in modo che tutte queste dichiarazioni possano essere già automaticamente fatte quando viene selezionata l’opzione UTF8. In pratica, le cose sono un po ‘più complicate. In primo luogo, fornire automaticamente l’intero tavolo richiederebbe un’enorme quantità di memoria di Tex. Inoltre, ci sono molti caratteri Unicode per i quali non esiste alcun oggetto LICR e, al contrario, molti oggetti LICR non hanno equivalenti in Unicode. Questo problema è risolto nel pacchetto inputenc caricando solo quelle mappature Unicode che corrispondono alle codifiche utilizzate in un determinato documento (per quanto sono conosciuti) e rispondono a qualsiasi altra richiesta per un carattere Unicode con un messaggio di errore adeguato. Diventa quindi l’attività dell’utente di fornire le informazioni di mappatura giusta o, se necessario, caricare una codifica aggiuntiva.
Come accennato in precedenza, le dichiarazioni di codifica input possono essere utilizzate nei pacchetti o nel preambolo del documento. Per far funzionare tutto in questo modo, è importante caricare prima il pacchetto inputenc, selezionando così una codifica adatta. Le dichiarazioni di codifica input successive agiranno come sostituzione di (o aggiunta) definite dalla presente codifica di input.
Utilizzando il pacchetto inputenc, è possibile visualizzare il comando \@tabacckludge, che sta per “tabbing accent kludge”. È necessario perché la versione corrente di LaTeX ha ereditato un sovraccarico dei comandi \=, \` e \', che normalmente indicano determinati accenti (ovvero, sono comandi specifici della codifica), ma hanno significati speciali all’interno dell’ambiente tabbing. Ecco perché le mappature che coinvolgono uno qualsiasi di questi accenti devono essere codificate in modo speciale. Ad esempio, se si desidera mappare 232 al carattere ’e-grave’ (che ha la rappresentazione interna \`e), si dovrebbe scrivere
1\DeclareInputText{232}{\@tabacckludge`e}invece di
1\DeclareInputText{232}{\`e}Mappatura a testo e/o matematica
Per motivi tecnici e concettuali, Tex fa una distinzione molto forte tra personaggi che possono essere utilizzati nel testo e in matematica. Ad eccezione dei caratteri ASCII visibili, i comandi che producono caratteri possono normalmente essere utilizzati in modalità di testo o matematica, ma non in entrambe le modalità.
File di codifica input per codifica a 8 bit
Le codifiche di input sono archiviate nei file con l’estensione .def, in cui il nome di base è il nome della codifica input (ad esempio, latin1.def). Tali file dovrebbero contenere solo i comandi discussi nella sezione corrente.
Il file dovrebbe iniziare con una riga di identificazione che contiene il comando `\fornisce il comando, descrivendo la natura del file. Ad esempio:
1\ProvidesFile{latin1.def}[2000/07/01 v0.996 Input encoding file]Se ci sono mappature per comandi specifici per codifica che potrebbero non essere disponibili a meno che non vengano caricati pacchetti aggiuntivi, si potrebbero dichiarare le impostazioni predefinite per loro utilizzando \ProvidETextCommandDefault. Per esempio:
1\ProvideTextCommandDefault{\textonehalf}{\ensurement{\frac12}}
2\ProvideTextCommandDefault{\textcent}{\TextSymbolUnavailable\textcent}Il comando \textsymbolunavailable emette un avvertimento che indica che un determinato carattere non è disponibile con i caratteri attualmente usati. Questo può essere utile come impostazione predefinita quando tali caratteri sono disponibili solo se vengono caricati caratteri speciali e non esiste un modo adatto per falsificare i personaggi con caratteri esistenti (come è stato possibile per un valore predefinito per \textonehalf).
Il resto del file dovrebbe includere solo le dichiarazioni di codifica input \dichiaraInputText e \dichiaraInputMath. Come accennato in precedenza, l’uso di quest’ultimo comando è scoraggiato ma consentito. Nessun altro comando deve essere utilizzato all’interno di un file di codifica input, in particolare, nessun comando che impedisce la lettura del file più volte (ad esempio, \newCommand), poiché i file di codifica vengono spesso caricati più volte in un singolo documento.
File di mappatura di input per UTF8
Come accennato in precedenza, la mappatura da unicode agli oggetti LICR è organizzata in modo da consentire al LaTeX di caricare solo quelle mappature rilevanti per le codifiche dei caratteri utilizzate nel documento corrente. Questo viene fatto cercando di caricare per ogni codifica <nome> un file <nome> enc.dfu che, se esiste, contiene le informazioni di mappatura per quei caratteri Unicode forniti da quella particolare codifica. Oltre a un numero di dichiarazioni \dichiaraunicodecharacter, tali file dovrebbero includere solo una riga `\fornisce file ‘.
Poiché le codifiche di carattere diverse spesso forniscono più o meno gli stessi caratteri, è abbastanza comune per le dichiarazioni per lo stesso carattere Unicode che appaia in diversi file “.dfu”. Pertanto, è molto importante che queste dichiarazioni in diversi file siano identiche. Altrimenti, la dichiarazione caricata surrai sopravvive, che potrebbe essere diversa da documento a documento.
Quindi, chiunque voglia fornire un nuovo file .dfu per qualche codifica che in precedenza non era coperta dovrebbe controllare attentamente le definizioni esistenti nei file .dfu per le codifiche correlate. I file standard forniti con inputenc sono garantiti per avere definizioni uniformi. In effetti, sono tutti generati da un singolo elenco che è opportunamente diviso. Un elenco completo di mapping attualmente esistenti è disponibile nel file utf8enc.dfu.
7.4. Codifica di output
Abbiamo già menzionato che le codifiche di output definiscono la mappatura dal LICR ai glifi (o costrutti costruiti con glifi) disponibili nei caratteri utilizzati per la composizione. Queste mappature sono citate all’interno del LaTeX con nomi di due o tre lettere (ad esempio, ot1 e t3). Diciamo che un certo carattere è in una certa codifica se la mappatura corrisponde alle posizioni dei glifi nel carattere. Diamo un’occhiata ai componenti esatti di tale mappatura.
I personaggi rappresentati internamente dai personaggi ASCII vengono semplicemente trasmessi al carattere. In altre parole, Tex usa il codice ASCII per selezionare un glifo dal carattere corrente. Ad esempio, il carattere ‘A’ con Codice ASCII 65 comporterà la composizione del glifo nella posizione 65 nel carattere corrente. Questo è il motivo per cui il LaTeX richiede che i caratteri per il testo contengano tutte queste lettere ASCII nelle loro posizioni del codice ASCII, poiché non c’è modo di interagire con questo meccanismo di base TEX. Pertanto, per l’ASCII visibile, una mappatura one-to-one è implicitamente presente in tutte le codifiche di output.
I personaggi rappresentati internamente come sequenze di caratteri ASCII (ad esempio, “ -- “) sono gestiti come segue: quando il carattere corrente viene caricato per la prima volta, Tex viene informato che il carattere contiene una serie di cosiddetti programmi di legatura. Questi programmi definiscono alcune sequenze di caratteri che non dovrebbero essere sottoposti a composizione direttamente ma piuttosto da sostituire con alcuni altri glifi dal carattere. Ad esempio, quando Tex incontra “ -- “nell’input (cioè il codice ASCII 45 due volte), un programma di legatura può invece dirigerlo al glifo in posizione 123 (che manterrebbe il glifo EN Dash). Ancora una volta, non c’è modo di interagire con questo meccanismo.
Tuttavia, la maggior parte della rappresentazione del carattere interno è costituita da comandi specifici per codifica dei caratteri che sono mappati usando le dichiarazioni descritte di seguito. Tutte le dichiarazioni hanno la stessa struttura nei loro primi due argomenti: il comando specifico del carattere (o il primo componente di esso, se si tratta di una sequenza di comandi), seguito dal nome della codifica. Eventuali argomenti rimanenti dipenderanno dal tipo di dichiarazione.
Quindi, una codifica xyz è definita da un gruppo di dichiarazioni, tutti avendo il nome xyz come secondo argomento. Quindi, naturalmente, alcuni caratteri devono essere codificati in quella codifica. In effetti, lo sviluppo delle codifiche di carattere viene normalmente eseguito in modo retrocusato: qualcuno inizia con un carattere esistente e quindi fornisce dichiarazioni appropriate per l’utilizzo. A questa raccolta di dichiarazioni viene quindi dato un nome adatto, come ot1. Di seguito, prenderemo il carattere ECRM1000 (vedi il grafico del glico), la cui codifica del carattere è chiamata t1 in LaTeX e costruire dichiarazioni appropriate per accedere agli glifi da un carattere codificato in questo modo. I caratteri blu nel grafico del glyph sono quelli che dovrebbero essere presenti nella stessa posizione in ogni codifica del testo, poiché vengono passati trasparentemente attraverso il LaTeX.
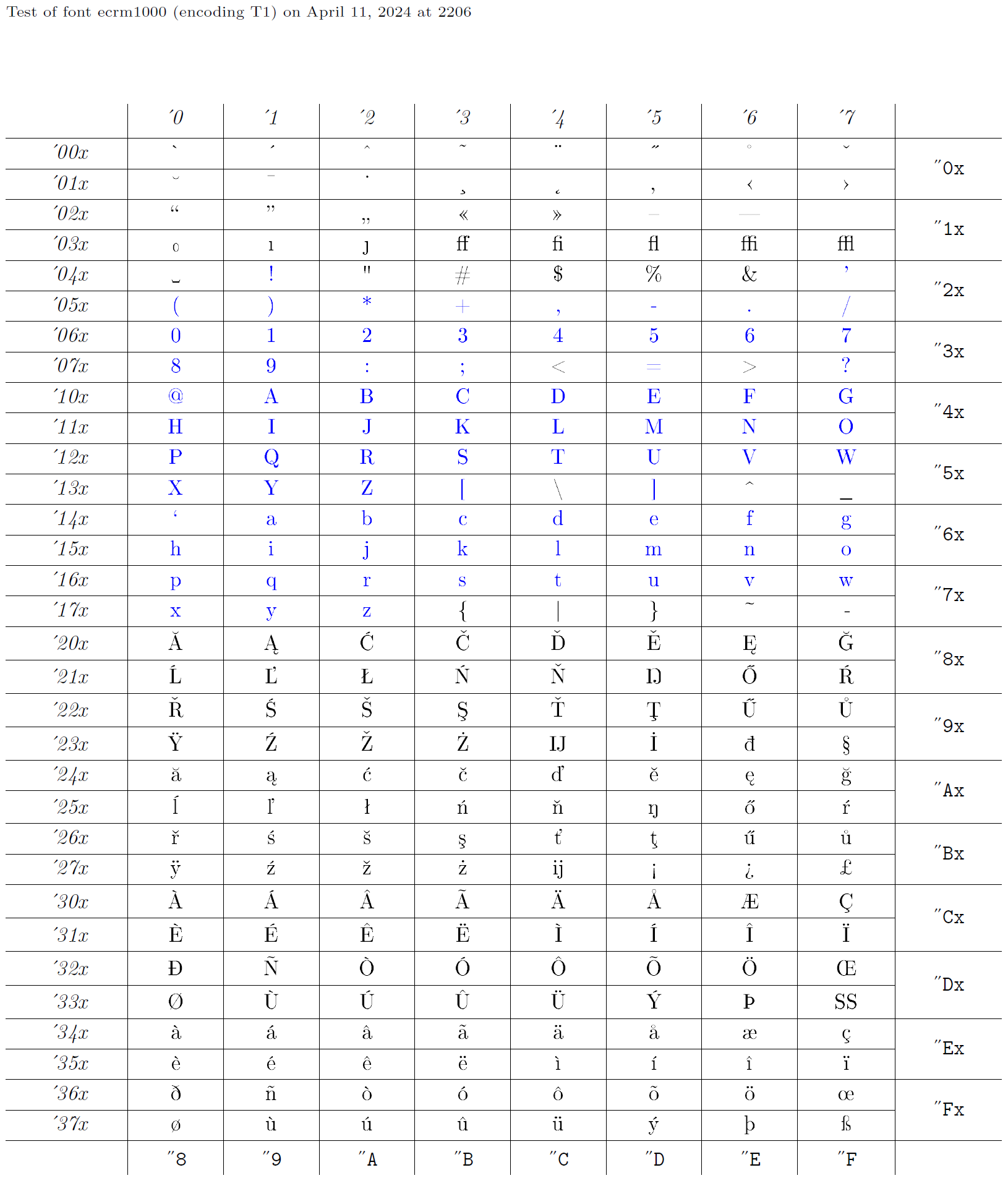
File di codifica output
I file di codifica di output sono identificati dalla stessa estensione .def dei file di codifica input. Tuttavia, il nome di base del file è un po ‘più strutturato. È costituito dal nome di codifica in lettere minuscole, seguito da enc (ad esempio, t1enc.def per la codifica t1).
Questi file dovrebbero includere solo dichiarazioni descritte nella sezione corrente. Poiché i file di codifica di output possono essere letti più volte dal LaTeX, è importante seguire questa regola e astenersi dall’uso, ad esempio, \newCommand, che impedisce di leggere un tale file più di una volta!
Ancora una volta, un file di codifica di output inizia con una riga di identificazione che descrive la natura del file. Per esempio:
1\ProvidesFile{t1enc.def}[2001/06/05 v1.94 Standard LaTeX file]Prima di dichiarare qualsiasi comando specifico per codifica per una particolare codifica, dobbiamo prima far conoscere questa codifica al LaTeX. Questo viene fatto tramite il comando \dichiarafontencoding. A questo punto, è anche utile dichiarare le regole di sostituzione predefinita per la codifica. Possiamo farlo usando il comando \dichiarafontsubstitution. Entrambe le dichiarazioni sono discusse in dettaglio in
come impostare nuovi caratteri.
1\DeclareFontEncoding{T1}{}{}
2\DeclareFontSubstitution{T1}{cmr}{m}{n}Ora che abbiamo introdotto la codifica T1 in LaTex in questo modo, possiamo procedere a dichiarare come i comandi specifici per codifica dei caratteri dovrebbero comportarsi in quella codifica.
1\DeclareTextSymbol{LICR-Object}{encoding}{slot}La dichiarazione per i simboli di testo sembra essere la più semplice. Qui, la rappresentazione interna può essere mappata direttamente su un singolo glifo nel carattere target. Ciò si ottiene usando la dichiarazione \dichiaratextsymbol, la cui terza argomentazione - la posizione del glifo - può essere somministrata come numero decimale, ottale o esadecimale. Per esempio,
1\DeclareTextSymbol{\ss}{T1}{255}
2\DeclareTextSymbol{\AE}{T1}{'306} %font position as octal number
3\DeclareTextSymbol{\ae}{T1}{"E6} %...as hexadecimal numberDichiarare che i comandi specifici del carattere \ss,\ae e \ae dovrebbero essere mappati alle posizioni di carattere (decimale) 255, 198 e 230, rispettivamente, in un carattere codificato T1. Come accennato in precedenza, è più sicuro usare la notazione decimale in tali dichiarazioni. Ad ogni modo, le notazioni di miscelazione come nell’esempio precedente sono sicuramente un cattivo stile.
1\DeclareTextAccent{LICR-accent}{encoding}{slot}I caratteri contengono spesso segni diacritici come singoli glifi per consentire la costruzione di caratteri accentati combinando tale segno diacritico con qualche altro glifo. Tali accenti (fintanto che devono essere posizionati sopra altri glifi) sono dichiarati usando il comando `\dichiaratextaccent ‘. Il terzo argomento, *slot *, è la posizione del segno diacritico nel carattere. Ad esempio,
1\DeclareTextAccent{\"}{T1}{4}Definisce l’accento “Umlaut”. Da quel momento in poi, una rappresentazione interna come \" A ha il seguente significato nella codifica t1: dattire ‘a con umlaut’ posizionando l’accento nella posizione 4 sui gelafi nella posizione 97 (il codice ASCII del personaggio A). Tale dichiarazione, in effetti, implicitamente definisce una vasta gamma di caratteri interni - che è qualsiasi cosa, altra cosa di tipo di tipo. \" \dichiaratextsymbol o qualsiasi carattere ASCII appartenente al LICR, come ‘a’.
Anche quelle combinazioni che non hanno molto senso, come \" \ p (cioè il segno di pilcrow con umlaut), diventano concettualmente membri dell’insieme di comandi specifici per codifica dei caratteri in questo modo.
1\DeclareTextComposite
2 {LICR-accent}{encoding}{simple-LICR-object}{slot}La tabella di glyph sopra contiene un gran numero di caratteri accentati come singoli glifi, ad esempio, “a con umlaut” in posizione '240 ottale. Pertanto, in t1 il comando specifico per codifica\"a non dovrebbe comportare il posizionamento di un accento sul personaggio ‘a’, ma invece dovrebbe accedere direttamente al glifo in quella posizione del carattere. Ciò si ottiene dalla dichiarazione
1\DeclareTextComposite{\"}{T1}{a}{228}che afferma che il comando specifico della codifica \" A si traduce nella composizione del glifo 228, disabilitando così la dichiarazione di accento sopra. Per tutti gli altri comandi specifici della codifica a partire da \" , la dichiarazione di accento rimane in atto. Ad esempio, \" B produrrà A ‘B con umlaut’ posizionando un accento sul glifo di base ‘B’.
Il terzo argomento, semplice-licr-object, dovrebbe essere una singola lettera, come “A”, o un singolo comando, come \j o\oe.
1\DeclareTextCompositeCommand
2 {LICR-object}{encoding}{simple-LICR-object}{code}Sebbene non sia utilizzato per la codifica T1, esiste anche una versione più generale di\dichiaratextComposite che consente il codice arbitrario al posto di una posizione di slot. Questo viene usato, ad esempio, nella codifica OT1 per abbassare l’accento dell’anello su” A “rispetto al modo in cui sarebbe composto da” \ accento “di Tex. Gli accenti su “I” sono anche implementati usando questa forma di dichiarazione:
1\DeclareTextCompositeCommand{\'}{OT1}{i}{\@tabacckludge'\i}
2\DeclareTextCompositeCommand{\^}{OT1}{i}{\^\i}Numerosi segni diacritici non sono posizionati sopra altri caratteri ma piuttosto posizionati da qualche parte sotto di loro. Non esiste un modulo di dichiarazione speciale per tali marchi, poiché il posizionamento effettivo dell’accento prevede un codice TEX di basso livello. Invece, il generico \dichiaracextCommand può essere usato per questo scopo.
1\DeclareTextCommand{LICR-object}{encoding}[num][default]{code}Ad esempio, l’accento “underbar” \b nella codifica T1 è definito con il seguente codice:
1\DeclareTextCommand{\b}{T1}[1]
2 {\hmode$bgroup\o$lign{\relax#1\crcr\hidewidth\sh$ft{29}%
3 \vbox to.2ex{\hbox{\char9}\vss}\hidewidth}\egroup}In questa discussione, non importa molto cosa significhi esattamente il codice, ma possiamo vedere che \dichiaracextCommand è simile a\newCommand in un certo senso. Ha un argomento num opzionale che indica il numero di argomenti (uno qui), un secondo argomento predefinito * opzionale * (non presente qui) e un argomento obbligatorio finale contenente il codice in cui è possibile fare riferimento agli argomenti usando #1,#2 e così via.
\DichiaratextCommand può anche essere utilizzato per creare comandi specifici per codifica dei caratteri costituiti da una singola sequenza di controllo. In questo caso, viene utilizzato senza l’argomento opzionale, definendo così un comando con argomenti zero. Ad esempio, in t1 non esiste un glifo per un segno ‘per mille’, ma c’è un po ‘di’ ‘o’ in posizione'30, che, se posizionato direttamente dietro un ‘%’, darà il glifo appropriato. Pertanto, possiamo fornire le seguenti dichiarazioni:
1\DeclareTextCommand{\textperthousand} {T1}{\%\char 24}
2\DeclareTextCommand{\textpertenthousand}{T1}{\%\char 24\char 24 }Ora abbiamo coperto tutti i comandi necessari per dichiarare i comandi specifici per codifica dei caratteri per una nuova codifica. Come abbiamo già detto, solo questi comandi dovrebbero essere presenti nei file di definizione della codifica.
Predefiniti di codifica output
Vediamo ora cosa succede se viene utilizzato un comando specifico per codifica, per il quale non vi è alcuna dichiarazione nella codifica del carattere corrente, viene utilizzato. In tal caso, una delle due cose può accadere: o LaTEX ha una definizione predefinita per l’oggetto LICR, nel qual caso viene utilizzato questo impostazione predefinita o viene emesso un messaggio di errore che afferma che l’oggetto LICR richiesto non è disponibile nella codifica corrente. Esistono diversi modi per impostare le impostazioni predefinite per gli oggetti LICR.
1\DeclareTextCommandDefault{LICR-object}[num][default]{code}Il comando \dichiaratextCommandDefault fornisce la definizione predefinita per un * Licr-Object * da utilizzare ogni volta che non vi è alcuna impostazione specifica per un oggetto nella codifica corrente. Tali definizioni possono, ad esempio, falsificare un certo personaggio. Ad esempio, \Textregister ha una definizione predefinita in cui il personaggio è costruito da altri due, come questo:
1\DeclareTextCommandDefault{\textregistered}{\textcircled{\scshape r}}Tecnicamente, le definizioni predefinite vengono archiviate come codifica con il nome ?. Sebbene non dovresti fare affidamento su questo fatto, poiché l’implementazione potrebbe cambiare in futuro, significa che non è possibile dichiarare una codifica con questo nome.
1\DeclareTextSymbolDefault{LICR-object}{encoding}Nella maggior parte dei casi, una definizione predefinita non richiede la codifica, ma induce semplicemente il LaTeX a prendere il carattere da una codifica in cui è noto. Il pacchetto TextComp, ad esempio, contiene un gran numero di dichiarazioni predefinite che indicano la codifica TS1. Ad esempio:
1\DeclareTextSymbolDefault{\texteuro}{TS1}Il comando \dichiaratextsymBoldefault può essere utilizzato per definire l’impostazione predefinita per qualsiasi oggetto LICR senza argomenti, non solo quelli dichiarati con il comando \dichiaratextsymbol in altri codifica.
1\DeclareTextAccentDefault{LICR-accent}{encoding}Esiste una dichiarazione simile per gli oggetti LICR che prendono un argomento, come gli accenti. Ancora una volta, questo modulo è utilizzabile per qualsiasi oggetto LICR con un argomento. Il kernel in LaTeX, ad esempio, contiene una serie di dichiarazioni del tipo:
1\DeclareTextAccentDefault{\"}{OT1}
2\DeclareTextAccentDefault{\t}{OML}Ciò significa che se \" non è definito nella codifica corrente, usa quello da un carattere codificato OT1. Allo stesso modo, per ottenere un accento per pareggio, raccoglierlo da Oml se non è disponibile nulla di meglio.
1\ProvideTextCommandDefault{LICR-object}[num][default]{code}La dichiarazione \ProvideTextCommandDefault consente di” fornire “un altro tipo di impostazione predefinita. Fa lo stesso lavoro della dichiarazione \dichiaratetCommandDefault, tranne per il fatto che il valore predefinito è fornito solo se non è stato definito alcun valore predefinito. Questo è utilizzato principalmente nei file di codifica input per fornire una sorta di insufficienza insignificante per oggetti LICR insoliti. Ad esempio:
1\ProvideTextCommandDefault{\textonequarter}{\ensuremath{\frac14}}
2\ProvideTextCommandDefault{\textcent}{\TextSymbolUnavailable\textcent}Pacchetti come TextComp possono quindi sostituire tali definizioni con dichiarazioni che indicano glifi reali. Utilizzando \fornire ... invece di \dichiarare ... Garantisce che un valore predefinito migliore non venga accidentalmente sovrascritto se viene letto il file di codifica input.
1\UndeclareTextCommand{LICR-object}{encoding}In alcuni casi, è necessario rimuovere una dichiarazione esistente per garantire invece una dichiarazione predefinita. Questo può essere fatto usando \undeclareTextCommand. Ad esempio, il pacchetto TextComp rimuove le definizioni di\textdollar e \texterling dalla codifica ot1 perché non tutti i font codificati da OT1 hanno effettivamente questi simboli.
1\UndeclareTextCommand{\textsterling}{OT1}
2\UndeclareTextCommand{\textdollar} {OT1}Senza questa rimozione, le nuove dichiarazioni predefinite per raccogliere i simboli da TS1 non sarebbero usate per i caratteri codificati con ot1.
1\UseTextSymbol{encoding}{LICR-object}
2\UseTextAccent{encoding}{LICR-object}{simple-LICR-object}L’azione nascosta dietro le dichiarazioni \dichiaratextsymBoldefault e \dichiaratextaccentdefault può anche essere utilizzata direttamente. Supponiamo, ad esempio, che la codifica corrente sia u. In quel caso,
1\UseTextSymbol{OT1}{\ss}
2\UseTextAccent{OT1}{\'}{a}ha lo stesso effetto dell’ingresso nel codice seguente. Si noti in particolare che A è composto nella codifica u - solo l’accento viene preso dall’altro codifica.
1{\fontencoding{OT1}\selectfont\ss}
2{\fontencoding{OT1}\selectfont\'{\fontendcoding{U}\selectfont a}}Un elenco di oggetti LICR standard
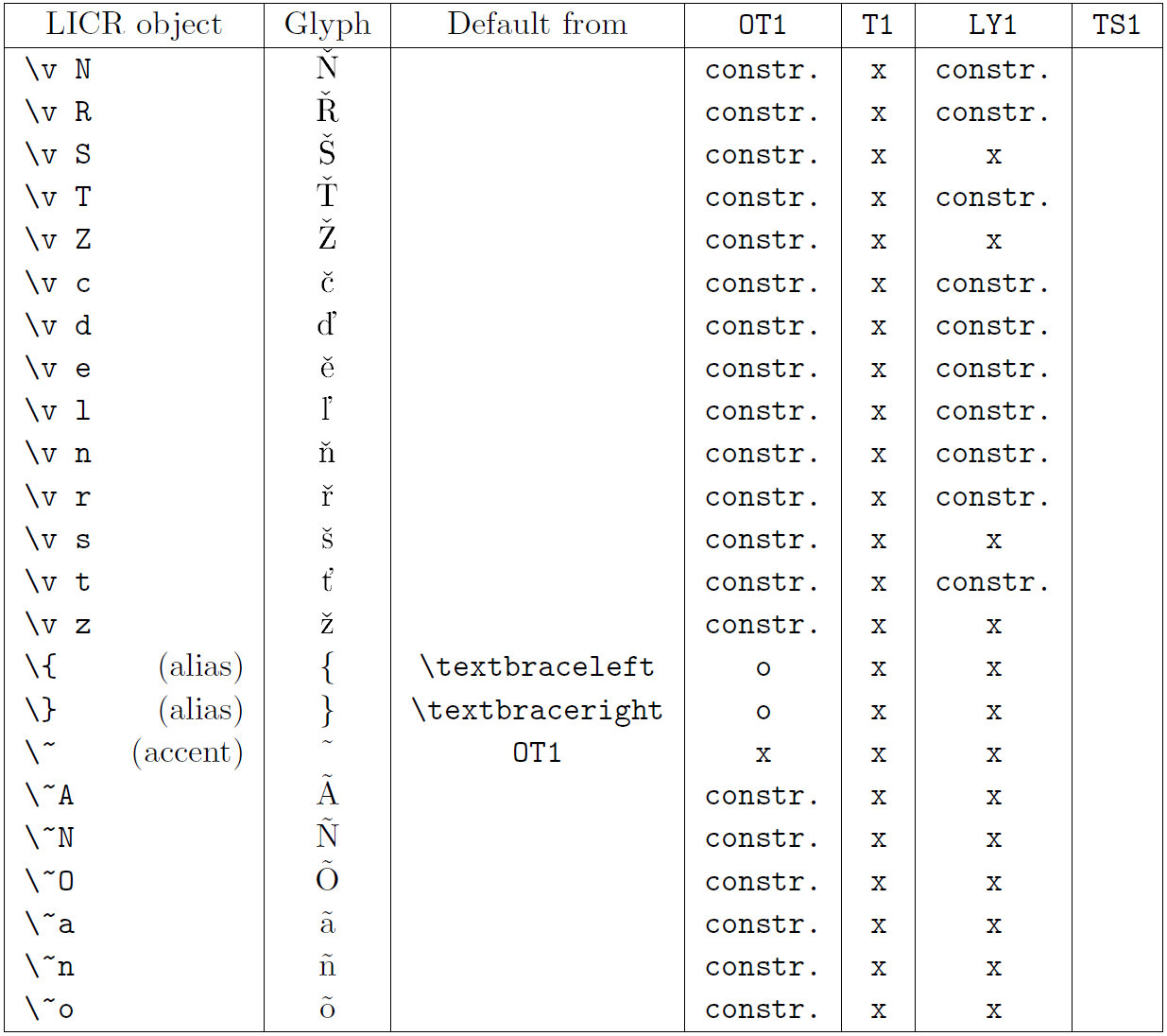
La tabella in questa sottosezione fornisce una panoramica delle rappresentazioni interne del LaTeX disponibili con le tre principali codifiche per i linguaggi a base latina: ot1 (codifica originale TEX), t1 (codifica standard latex) e ly1 (una codifica alternativa a 8 bit proposta da Y & Y). Inoltre, mostra tutti gli oggetti LICR dichiarati da TS1 (codifica del simbolo di testo standard latex) fornito caricando il pacchetto TextComp.
La prima colonna della tabella mostra i nomi degli oggetti LICR in ordine alfabetico, indicando quali oggetti LICR agiscono come accenti. La seconda colonna mostra una rappresentazione di glifi dell’oggetto.
La terza colonna descrive se l’oggetto ha una dichiarazione predefinita. Se è elencata una codifica, significa che per impostazione predefinita il glifo viene recuperato da un carattere adatto in quella codifica; Constring. significa che il valore predefinito è prodotto dal codice TEX di basso livello; Se la colonna è vuota, significa che non viene definito alcun valore predefinito per questo oggetto LICR. Nell’ultimo caso, un errore “simbolo non disponibile” viene restituito quando lo si utilizza in una codifica per la quale non ha una definizione esplicita. Se l’oggetto è un alias per qualche altro oggetto LICR, il nome alternativo è elencato in questa colonna.
Le colonne da quattro a sette mostrano se un oggetto è disponibile nella codifica data. Qui, “x” significa che l’oggetto è disponibile in modo nativo (come glifo) nei caratteri con quella codifica, “o” significa che è disponibile attraverso il valore predefinito per tutte le codifiche e “costre.” Significa che viene generato da diversi glifi, segni di accento o altri elementi. Se il valore predefinito viene recuperato da TS1, l’oggetto LICR è disponibile solo se viene caricato il pacchetto TextComp.
Oggetti LICR. Parte 1
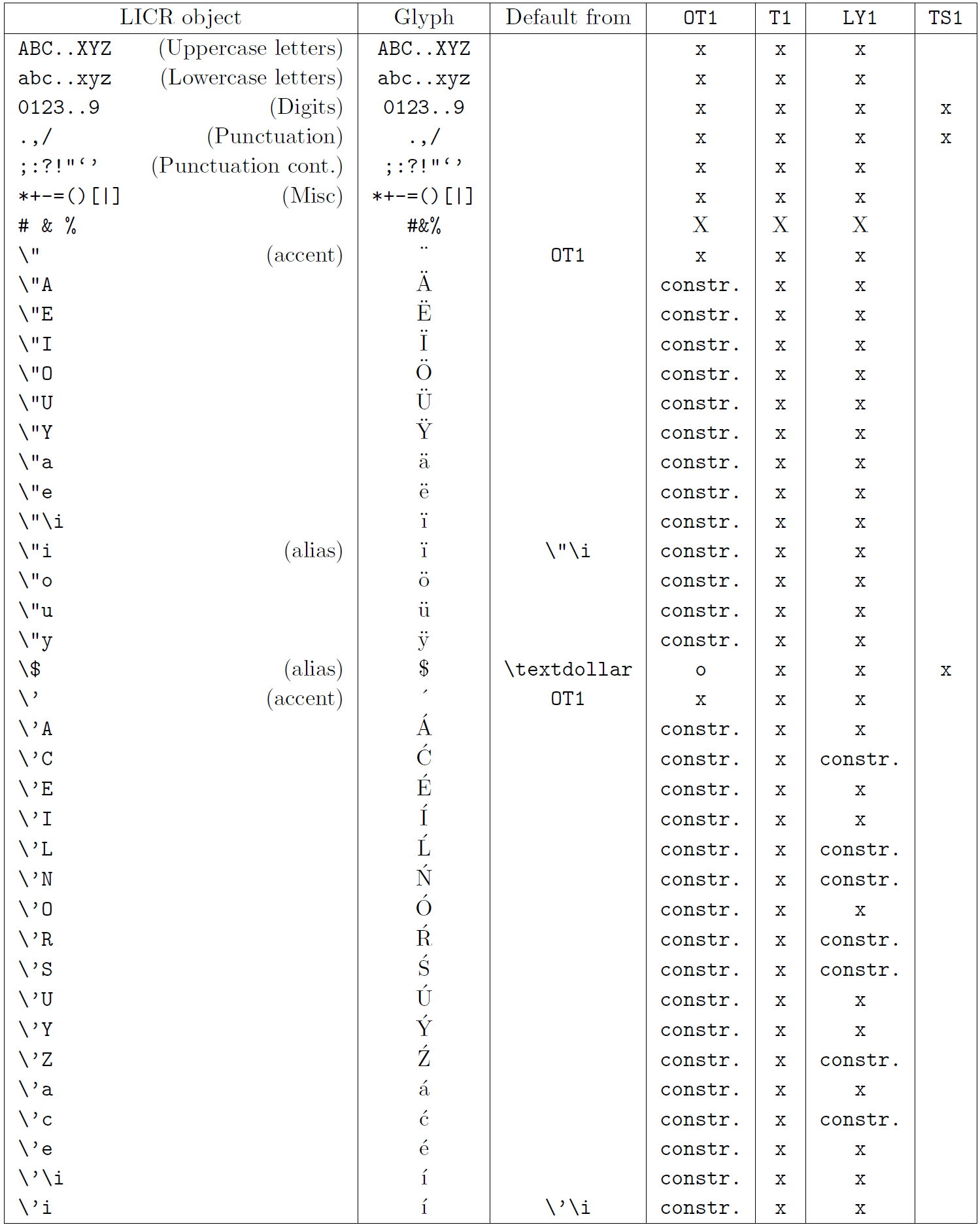
Oggetti LICR. Parte 2
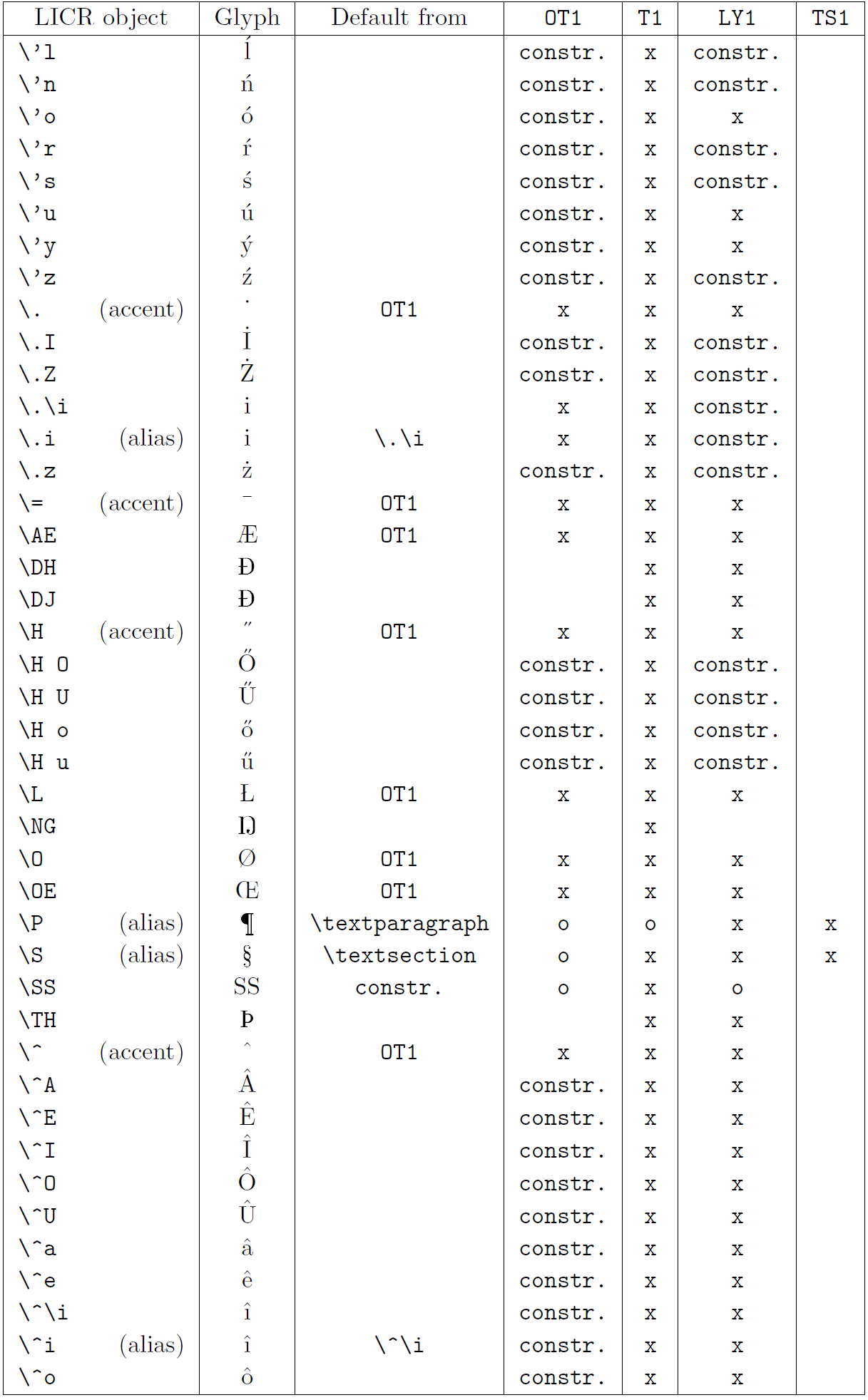
Oggetti LICR. Parte 3
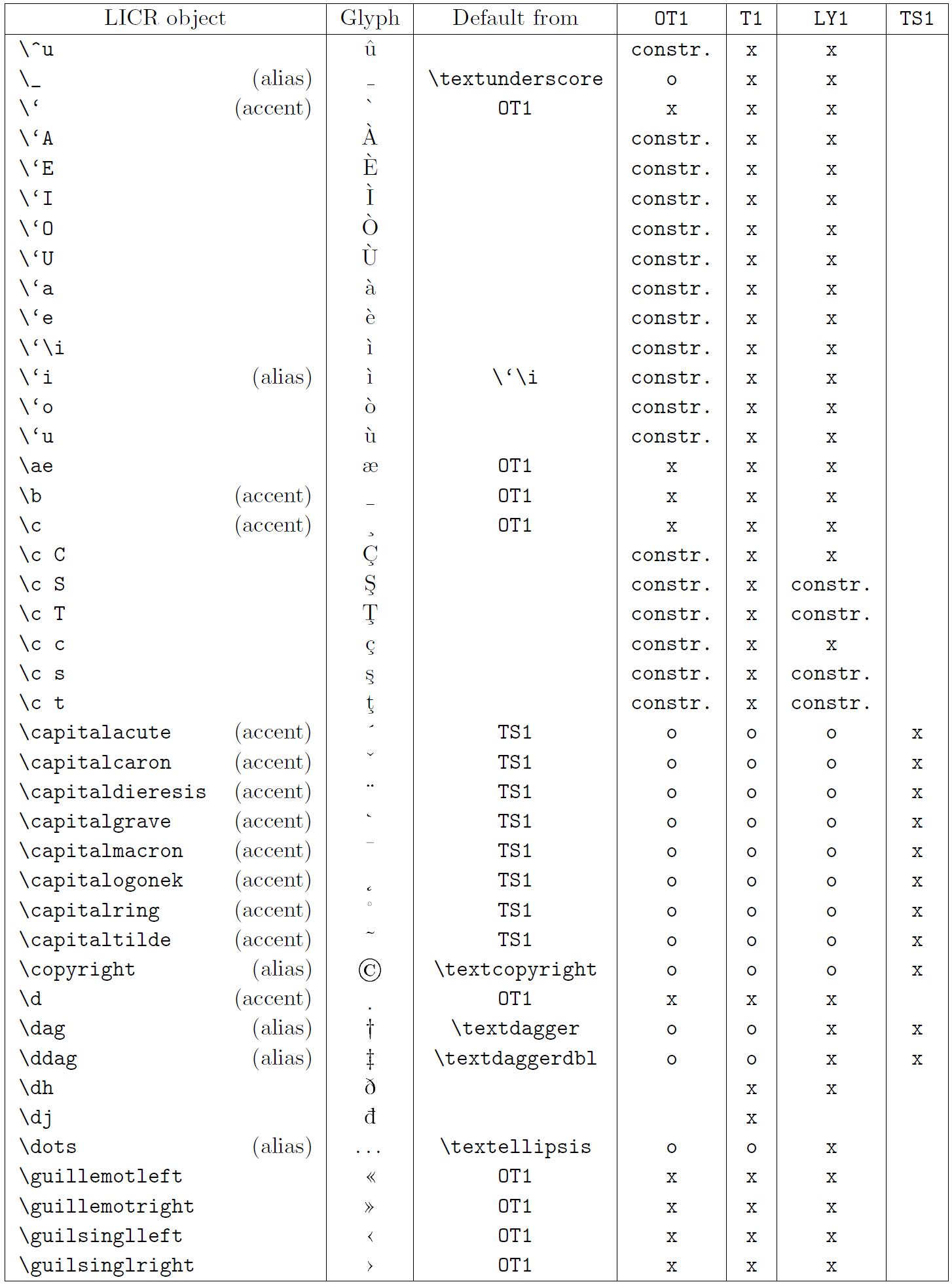
Oggetti LICR. Parte 4
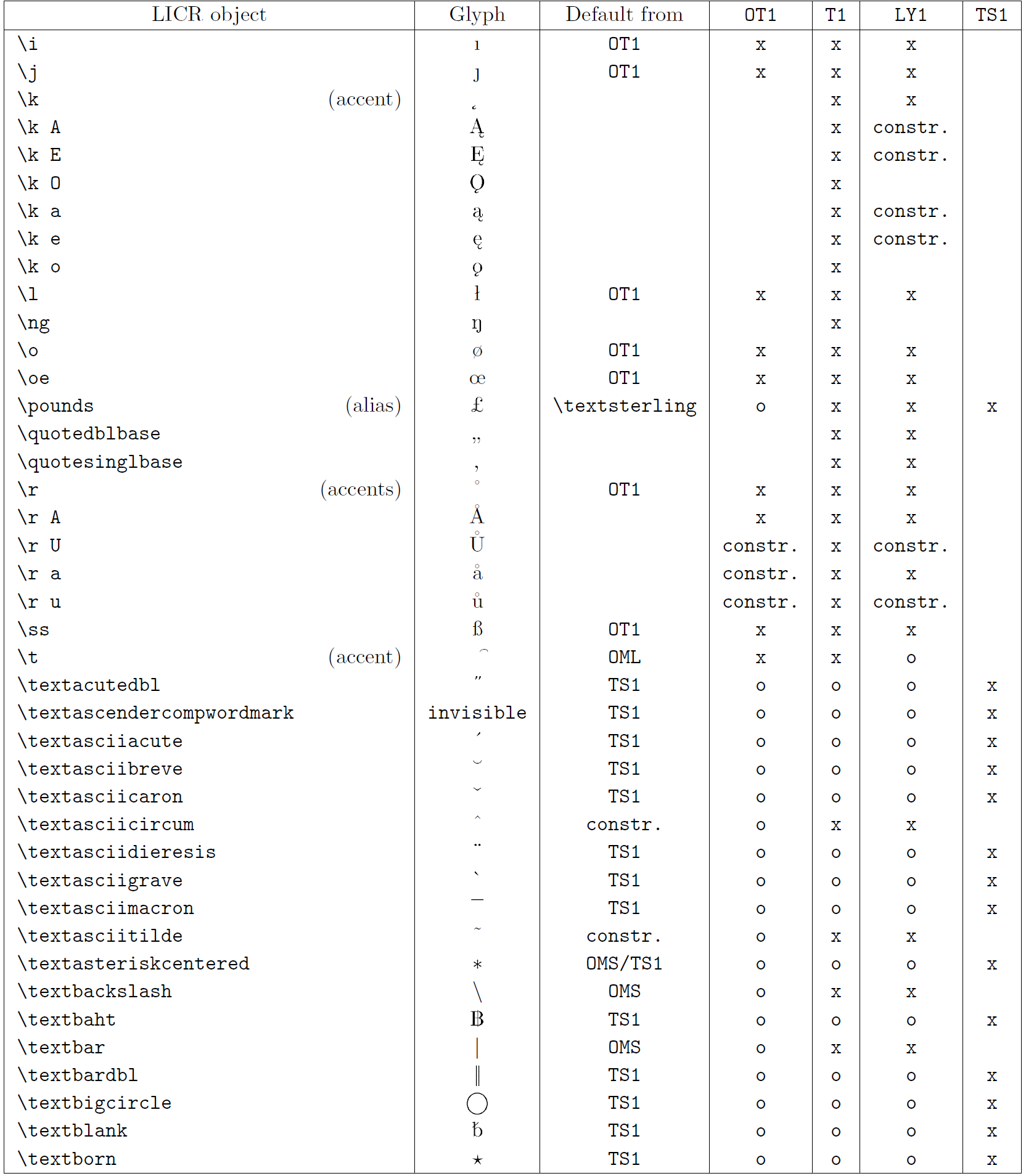
Oggetti LICR. Parte 5
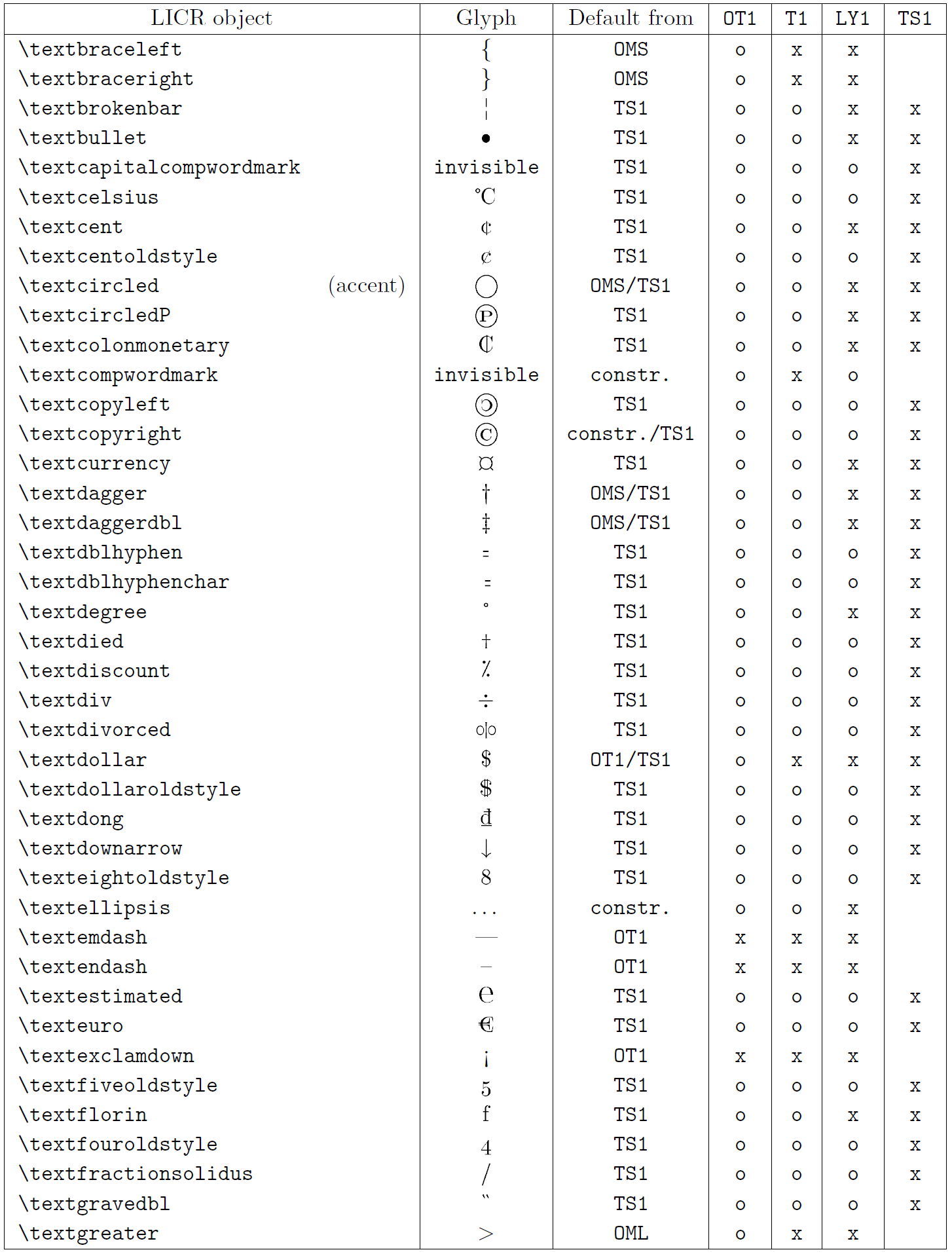
Oggetti LICR. Parte 6
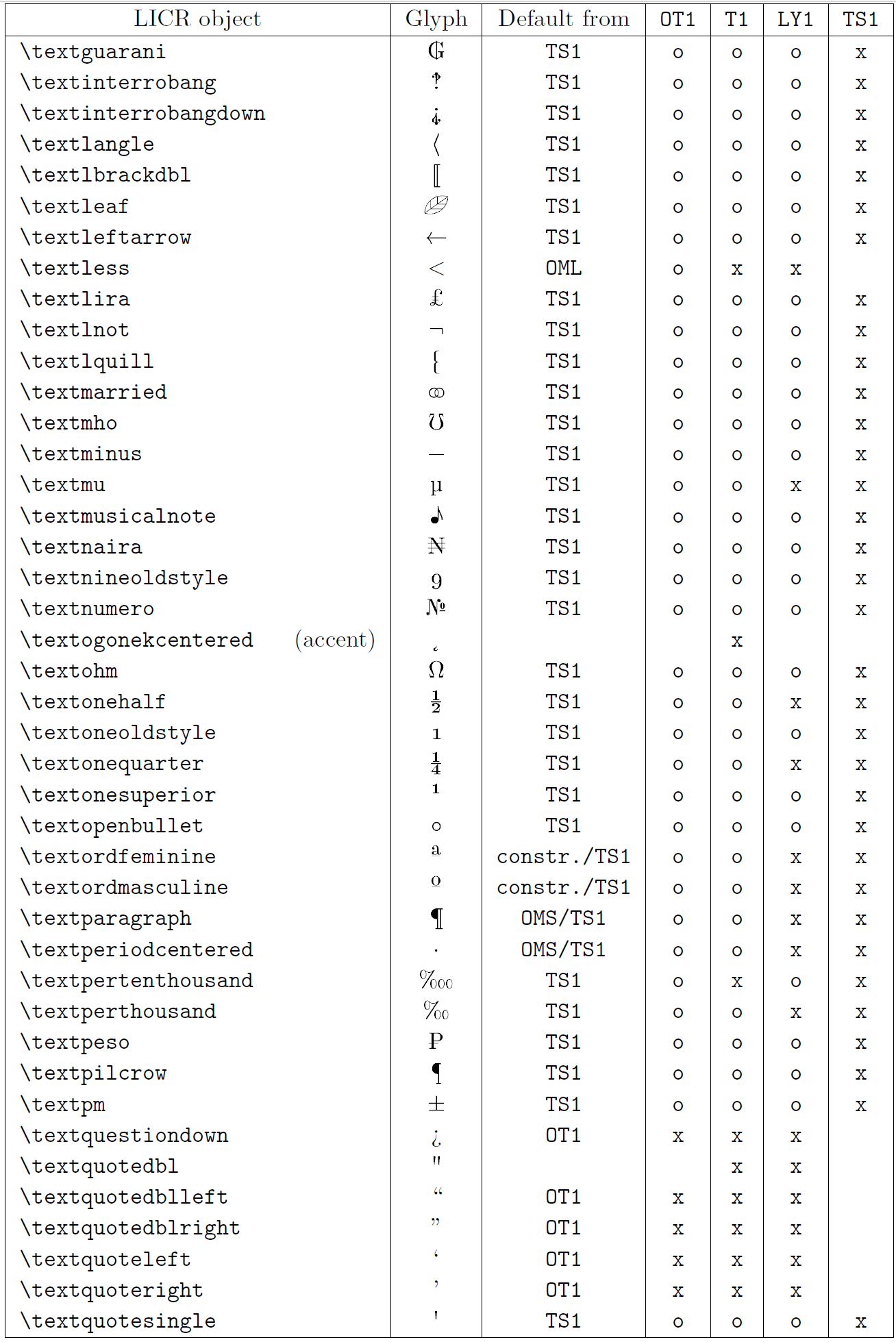
Oggetti LICR. Parte 7
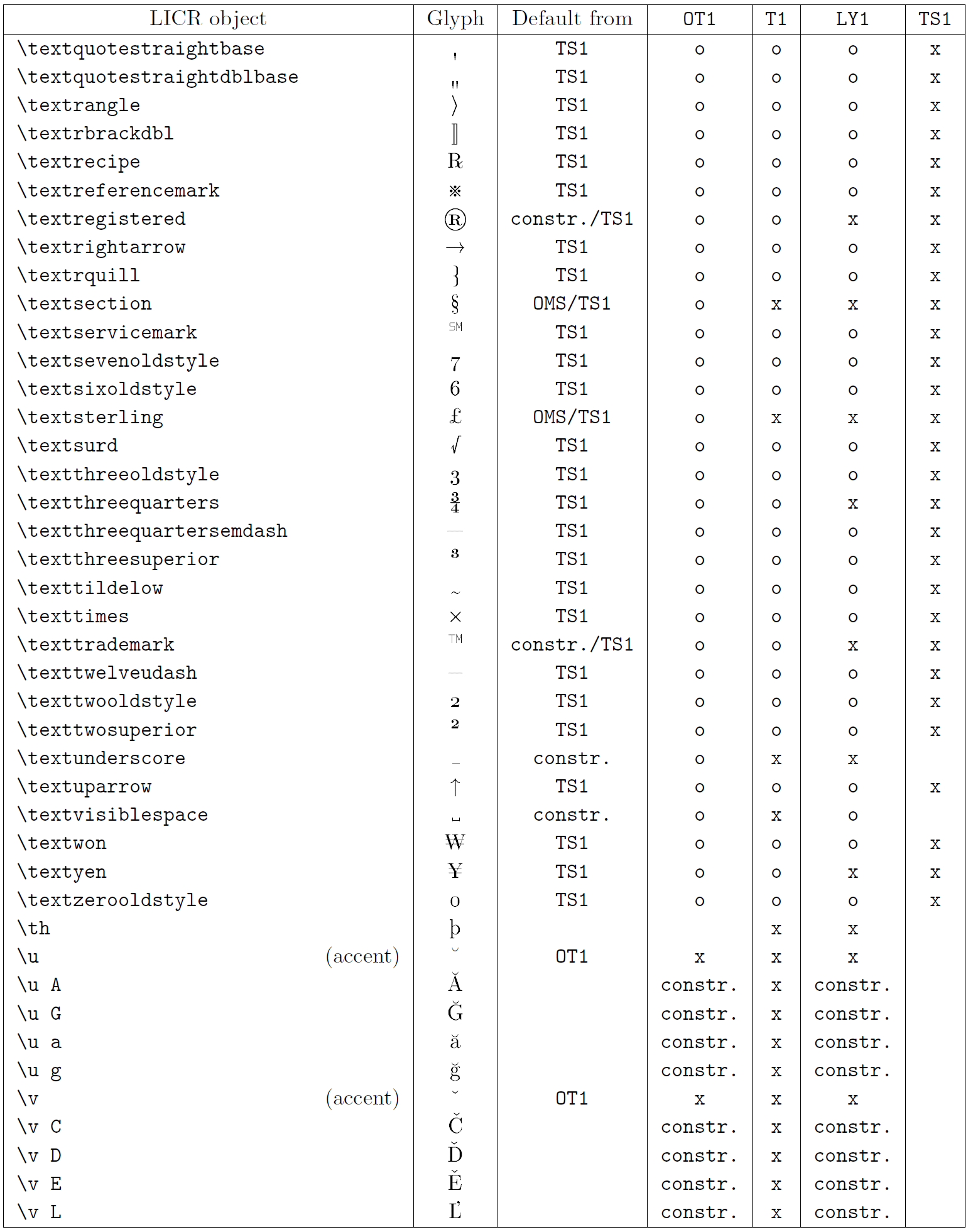
Oggetti LICR. Parte 8