4. Caratteri in LaTeX standard
Questo articolo contiene una breve introduzione ai caratteri di testo standard distribuiti insieme al LaTeX. Quindi copre il supporto standard di LaTex per le codifiche input e font. L’articolo si conclude con una descrizione di un pacchetto per la traccia di elaborazione dei caratteri del LaTeX e un altro pacchetto per la visualizzazione di grafici a gesso.
4.1. Computer romano moderno
Una famiglia di caratteri chiamati Computer Modern è stata sviluppata da Donald Knuth insieme a Tex. Fino all’inizio degli anni ‘90, solo questi caratteri erano per lo più utilizzabili con Tex e, di conseguenza, con LaTeX. Ognuno di questi caratteri contiene solo 128 glifi, quindi non può includere caratteri accentati come singoli glifi. Pertanto, l’uso di questi caratteri significa che i personaggi accentati devono essere prodotti con la primitiva \accento di Tex, che, a sua volta, significa che è impossibile l’ifemazione automatica delle parole con personaggi accentati. Sebbene questa restrizione sia accettabile con i documenti inglesi, è un evidente svantaggio per altre lingue.
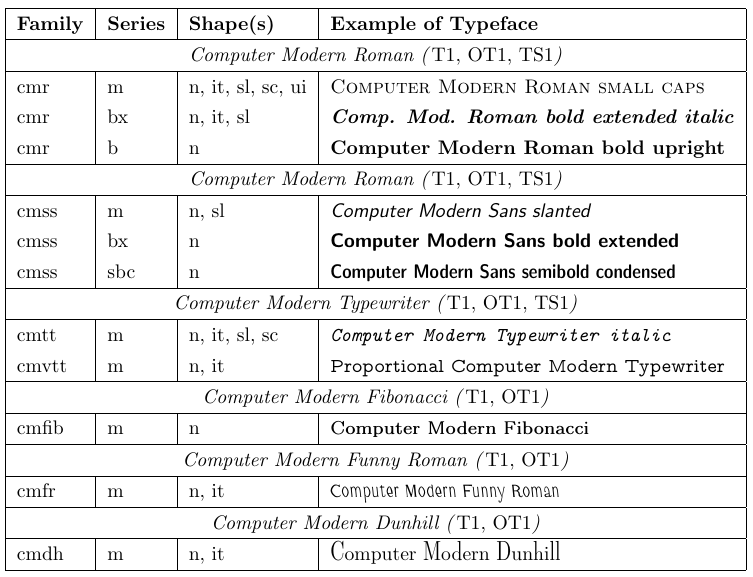
Queste carenze erano di grande preoccupazione per gli utenti del Tex in Europa e alla fine hanno portato a una reimplementazione di Tex nel 1989 per supportare personaggi a 8 bit internamente ed esternamente. Nel 1990 è stata sviluppata una codifica standard a 8 bit per caratteri di testo (t1). Contiene molti caratteri diacritici e consente la composizione in più di 30 lingue in base all’alfabeto latino. Quindi, le famiglie di caratteri moderne del computer sono state reimplementate e sono stati progettati ulteriori personaggi in modo che i caratteri risultanti siano completamente conformi a questo schema di codifica.
4.2. Selezione della codifica input: il pacchetto inputenc
Se puoi digitare caratteri accentati tramite singoli tasti o con qualche altro metodo di input (ad esempio, premendo `` e poi a` per ottenere ‘a-thrave’) e il tuo computer li visualizza correttamente nell’editor …

… quindi idealmente useresti un tale testo direttamente con LaTeX invece di dover digitare \`a, \^e, ecc.
Con lingue come il francese e il tedesco, quest’ultimo approccio è fattibile. Tuttavia, per lingue come il russo e il greco, è necessario il potenziale di input diretto, poiché quasi ogni personaggio in queste lingue ha un nome di comando come forma di LaTeX interno. Ad esempio, la definizione russa predefinita per \refTextAfter contiene il seguente testo (che significa" nella pagina successiva “):
1\cyrn\cyra\ \cyrs\cyrl\cyre\cyrd\cyru\cyryu\cyrshch\cyre\cyrishrt
2\ \cyrs\cyrt\cyrr\cyra\cyrn\cyri\cyrc\cyreÈ improbabile che qualcuno vorrebbe digitare tali cose su base regolare. Tuttavia, ha il vantaggio di essere universalmente portatile, in modo che possa essere interpretato correttamente su qualsiasi installazione in LaTeX. D’altra parte, digitare
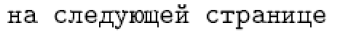
Su una tastiera appropriata è chiaramente preferibile, se è possibile far comprendere il LaTeX a questo input. Il problema è che ciò che viene archiviato in un file non sono i caratteri che vediamo nella sequenza sopra, ma piuttosto gli ottetti che rappresentano i personaggi. In circostanze diverse (usando codifiche diverse), gli stessi ottetti potrebbero rappresentare caratteri diversi.
Finché tutto accade su un singolo computer e tutti i programmi interpretano gli ottetti nei file allo stesso modo, di solito tutto va bene. In tal caso, ha senso attivare un meccanismo di traduzione automatico integrato in alcune recenti implementazioni di Tex. Ma quando un file prodotto in tale ambiente viene inviato a un altro computer, è probabile che l’elaborazione fallisca o, peggio ancora, possa sembrare avere successo, ma in realtà produrrà risultati errati visualizzando caratteri errati.
Il pacchetto inputenc è stato creato per far fronte a questo problema. Il suo scopo principale è informare il LaTeX della codifica utilizzata nel documento o in una parte del documento. Questo viene fatto caricando il pacchetto con il nome di codifica come opzione. Per esempio:
1\usepackage[cp1252]{inputenc} % Windows 1252 (Western Europe) code pageDa quel momento in poi, il LaTeX sa come interpretare gli ottetti nel resto del documento su qualsiasi installazione, indipendentemente dalla codifica utilizzata per altri scopi su quel computer.
Un esempio tipico è mostrato di seguito. È un breve testo scritto nella codifica Koi8-R, che è popolare in Russia. Il codice sorgente mostra come appare il testo su un computer usando una codifica latina 1 (ad esempio, in Germania). L’output dimostra che il LaTeX era ancora in grado di interpretare correttamente il testo perché è stato detto quale codifica input veniva utilizzato.

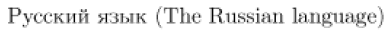
L’elenco delle codifiche attualmente supportate da inputenc è fornito di seguito. L’interfaccia è ben documentata e il supporto per nuovi codifica può essere facilmente aggiunto. Pertanto, vale la pena consultare la documentazione del pacchetto inputenc se la codifica utilizzata dal computer non è elencata qui. È inoltre possibile cercare su Internet la codifica di file per inputenc creati da altri autori. Ad esempio, le codifiche relative alle lingue cirilliche sono distribuite insieme ad altri pacchetti di supporto per i linguaggi cirillici.
Lo standard ISO-8859 definisce una serie di importanti codifiche singoli. Le codifiche relative all’alfabeto latino sono supportate da inputenc. Per il sistema operativo di Windows, Microsoft è stata definita una serie di codifiche a singolo byte. Inoltre, sono disponibili alcune codifiche definite da altri fornitori di computer.
Latin1Questa è la codifica ISO-8859-1 (a.k.a. latino 1). Può rappresentare la maggior parte delle lingue dell’Europa occidentale, tra cui albanese, catalano, danese, olandese, inglese, faroese, finlandese, francese, galiziano, tedesco, islandese, irlandese, italiano, norvegese, portoghese, spagnolo e svedese.Latin2La codifica ISO Latin 2 (ISO-8859-2) supporta le lingue slave dell’Europa centrale che usano l’alfabeto latino. Può essere usato per le seguenti lingue: croato, ceco, tedesco, ungherese, polacco, rumeno, slovacco e sloveno.Latin3Questo set di personaggi (ISO-8859-3) viene utilizzato per esperanto, galiziano, maltese e turco.Latin4La codifica ISO Latin 4 (ISO-8859-4) può rappresentare lingue come estone, lettone e lituano.Latin5La codifica ISO Latin 5 (ISO 8859-9) è strettamente correlata al latino 1 e sostituisce le lettere islandesi usate raramente dal latino 1 con lettere turche.Latin9Latino 9 (o ISO-8859-15) è un’altra piccola variazione sul latino 1 che aggiunge il segno della valuta euro e alcuni altri personaggi, come la ligatura\ae, che mancavano in francese e finlandese. Sta diventando sempre più popolare in sostituzione del latino 1.- Pagina del codice
CP437IBM 437 (latino MS-DOS ma contenente molti caratteri grafici per disegnare caselle). - Pagina di codice
CP850IBM 850 (MS-DOS multilingue, simile a latino1). - Pagina di codice
CP852IBM 852 (MS-DOS multilingue, simile a latin2). - Pagina del codice
CP858IBM 858 (IBM 850 con il simbolo Euro aggiunto). - Pagina del codice
CP865IBM 865 (MS-DOS Norvegia). - Pagina di codice
CP1250Windows 1250 (Europa centrale e orientale). - Pagina di codice
CP1252Windows 1252 (Europa occidentale). - Pagina di codice
CP1257Windows 1257 (Baltico). - Codifica
AnsinewWindows 3.1 ANSI; un sinonimo di CP1252. - Decmulti` Dec Multinational Caratteri Set codifica.
- Codifica
ApplemacMacintosh (standard). - Pagina del codice dell’Europa centrale
MacCEMacintosh. NextNext Computer codifica.UTF8Supporto di codifica UTF8 di Unicode. La maggior parte delle installazioni di Tex accetta caratteri a 8 bit per impostazione predefinita. Tuttavia, senza ulteriori aggiustamenti, come quelli eseguiti dainpuenc, i risultati possono essere imprevedibili: alcuni personaggi possono scomparire o potresti ottenere qualunque personaggio sia presente nell’attuale carattere nella posizione dell’ottetto a cui si fa riferimento, che può o meno essere il gesso desiderato. Questo comportamento è stato predefinito per molto tempo, quindi non è stato cambiato in latex2e perché alcune persone si affidano a esso. Tuttavia, per garantire che tali errori possano essere catturati,inputencoffre l’opzioneascii, che rende illegale qualsiasi personaggio al di fuori dell’intervallo 32-126.
1\inputencoding{encoding}Inizialmente, il pacchetto inputenc era progettato per specificare la codifica utilizzata per un documento nel suo insieme, da cui l’uso di opzioni nel preambolo. Tuttavia, è possibile modificare la codifica nel mezzo di un documento utilizzando il comando \inputencoding. Questo comando prende il nome di una codifica come argomento.
Quando è stato sviluppato inputenc, la maggior parte delle installazioni in LaTeX erano su computer che utilizzavano codifiche a singolo byte come quelle discusse in questa sezione. Tuttavia, oggi un altro codifica è popolare poiché i sistemi forniscono supporto per Unicode: UTF8. Questa codifica a lunghezza variabile rappresenta caratteri Unicode in uno o quattro ottetti. Il supporto di codifica è stato aggiunto a inputenc tramite l’opzione utf8. Tecnicamente, non fornisce un’implementazione UTF8 completa. Vengono mappati solo i caratteri Unicode che hanno una rappresentazione nei caratteri standard in LaTeX (ovvero set di caratteri latini e cirillici): tutti gli altri si tradurranno in un messaggio di errore adatto. Inoltre, gli Unicode che combinano caratteri non sono supportati, sebbene quella particolare omissione non debba essere un problema nella pratica.
1\usepackage[utf8]{inputenc}
2\usepackage{textcomp} % for Latin interpretation
3-----------------------------------------------
4German umlauts in UTF-8: ^^c3^^a4^^c3^^b6^^c3^^bc
5\par\inputencoding{latin1}% switch to Latin 1
6But interpreted as Latin 1: ^^c3^^a4^^c3^^b6^^c3^^bc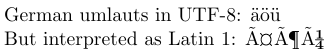
In UTF8, i personaggi ASCII rappresentano se stessi e la maggior parte dei caratteri latini sono rappresentati da due byte. Nel codice sorgente dell’esempio, le rappresentazioni a due byte degli Umlaut tedeschi in UTF8 sono mostrate nella notazione esadecimale di Tex, cioè con ogni ottetto preceduto da ^^. In un editore che non comprende UTF8, ON probabilmente li vedrebbe simili all’output che viene prodotto quando vengono interpretati come caratteri latini 1.
Un pacchetto con supporto UTF8 più completo (incluso il supporto per i personaggi coreani, cinesi e giapponesi), sebbene di conseguenza più complesso nella sua configurazione, è il pacchetto UCS scritto da Dominique Unruh. Puoi provarlo se la soluzione `inputenc ’non copre le tue esigenze.
4.3. Selezione delle codifiche dei caratteri con il pacchetto Fontenc
Per abilitare una codifica del carattere di testo per l’uso con LaTeX, la codifica deve essere caricata nella classe di preambolo o documento. Più precisamente, devono essere caricate le definizioni per accedere ai glifi nei caratteri con una certa codifica. Il modo canonico per farlo è tramite il pacchetto Fontenc, che prende un elenco di codifiche di font separate da virgola come opzione di pacchetto. L’ultimo di queste codifiche viene automaticamente reso la codifica del documento predefinito. Se vengono caricate le codifiche cirilliche, l’elenco dei comandi interessati da \makeuppercase e \makelowercase viene automaticamente esteso. Per esempio,
1\usepackage[T2A,T1]{fontenc}caricherà tutte le definizioni necessarie per la codifica cirillica t2a e t1 e impostare quest’ultimo come codifica del documento predefinito.
A differenza del normale comportamento del pacchetto, è possibile caricare questo pacchetto più volte con diverse opzioni per il comando \usapackage. Ciò è necessario per consentire a una classe di documenti di caricare una determinata serie di codifica e consentire all’utente di caricare ancora più codifica nel preambolo. Il caricamento delle codifiche più di una volta viene eseguita senza effetti collaterali oltre a modificare potenzialmente la codifica del carattere predefinita del documento.
Se nel documento vengono utilizzati pacchetti di supporto linguistico (ad esempio, quelli che vengono con il sistema * Babele *), è spesso il caso che le codifica di carattere necessarie siano già caricate dal pacchetto di supporto.
4.4. Come tracciare la selezione dei caratteri con il pacchetto Tracefnt
Per rilevare i problemi nel sistema di selezione dei caratteri, è possibile utilizzare il pacchetto Tracefnt. Supporta diverse opzioni che consentono di personalizzare la quantità di informazioni visualizzate da NFSS sullo schermo e nel file di trascrizione.
ErrorShowQuesta opzione sopprime tutti gli avvertimenti e i messaggi di informazione sul terminale; Saranno scritti solo nel file di trascrizione. Verranno mostrati solo errori reali. Dovresti studiare attentamente il file di trascrizione prima di stampare un’importante pubblicazione perché avvertimenti sulle sostituzioni dei caratteri e così via può significare che il risultato finale sarà errato.WarningshowQuando questa opzione è specificata, nel terminale vengono mostrati avvertimenti ed errori. Questa impostazione ti fornisce informazioni dettagliate come il latex2e senza il pacchettotracefntcaricato.InfoshowQuesta opzione è il valore predefinito quando si carica il pacchettoTracefnt. Informazioni aggiuntive, che normalmente vengono scritte solo nel file di trascrizione, ora vengono visualizzate anche sul tuo terminale.DebugshowQuesta opzione mostra inoltre informazioni sulle modifiche al carattere di testo e sul ripristino di tali caratteri alla fine di un gruppo di tute o alla fine di un ambiente. Fai attenzione quando si accende questa opzione perché può produrre file di trascrizione molto grandi.PausaQuesta opzione trasforma tutti gli avvertimenti in errori per aiutare il rilevamento di problemi in pubblicazioni importanti.CaricamentoQuesta opzione mostra il caricamento di caratteri esterni. Tuttavia, se il formato o la classe di documenti utilizzati ha già caricato alcuni caratteri, questi non saranno mostrati da questa opzione.
4.5. Come visualizzare tabelle e campioni di carattere con nfssfont.tex
Il file chiamato nfssfont.tex può essere utilizzato per testare nuovi caratteri, produrre tabelle di carattere che mostrano tutti i caratteri ed eseguire altre operazioni relative ai caratteri. Puoi trovare questo file in qualsiasi distribuzione in LaTeX. Quando si esegue questo file tramite LaTex, ti verrà richiesto il test del nome del carattere. La risposta può essere il nome del carattere esterno senza estensione - come cmr10 (computer moderno romano 10pt) - se lo sai o un nome di carattere vuoto. In quest’ultimo caso, ti verrà richiesto una specifica del carattere NFSS: un nome di codifica (impostazione predefinita t1), un nome familiare di carattere (impostazione predefinita cmr), una serie di caratteri (predefinita m), una forma del carattere (default n) e una dimensione del carattere (inadempienza 10pt). Il programma carica quindi il file esterno corrispondente a tale classificazione.
Successivamente, ti verrà chiesto di inserire un comando. Il più importante è probabilmente \table, che produce un grafico dei caratteri come quello qui sotto. Il comando \text è anche interessante in quanto produce un campione di testo più lungo. Per passare a un nuovo carattere di prova, digitare \init; Per finire il test, digitare \ciao o\stop; E per conoscere tutti gli altri test disponibili, digitare \help.
1**********************************************
2* NFSS font test program version <v2.2b>
3*
4* Follow the instructions
5**********************************************
6
7Input external font name, e.g., cmr10
8(or <enter> for NFSS classification of font):
9
10\currfontname=cmr10
11Now type a test command (\help for help):)
12*\table
13
14*\newpage
15*\init
16Input external font name, e.g., cmr10
17(or <enter> for NFSS classification of font):
18
19\currfontname=
20*** NFSS classification ***
21
22Font encoding [T1]:
23
24\encoding=OT1
25(ot1enc.def)
26Font family [cmr]:
27
28\family=cmdh
29Font series [m]:
30
31\series=m
32Font shape [n]:
33
34\shape=n
35Font size [10pt]:
36
37\size=10
38(ot1cmdh.fd) Now type a test command (\help for help):
39*\text
40
41*\bye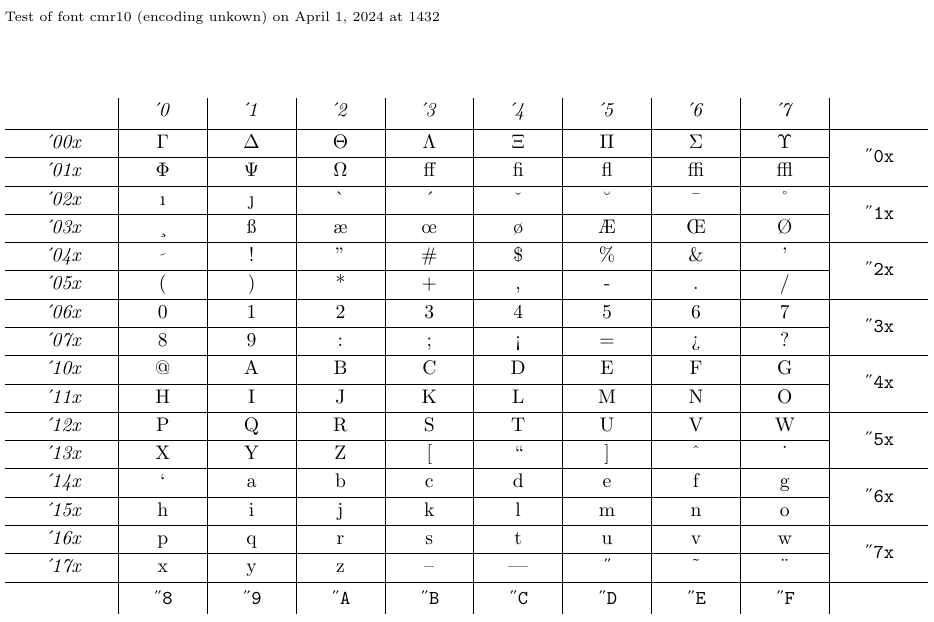

Ci sono due punti da tenere a mente. In primo luogo, il programma
nfssfont.texemette un comando\initimplicito, quindi la prima riga di input dovrebbe contenere il nome del font o essere completamente vuota per indicare che segue una classificazione NFSS. In secondo luogo, l’input di\initdeve apparire su singole righe senza nient’altro (nemmeno un commento), perché la fine della riga indica la fine della risposta a un prompt del tipoFont encoding[T1]: \encoding=che si otterrà.