7. LaTeX の文字エンコーディングのモデル
この記事では LaTeX のエンコーディングについて詳しく解説します。まず LaTeX システム内部における文字データの流れについて説明し、次に LaTeX 内部での文字データの表現モデルを詳しく見ていきます。その後、入力エンコーディングを介して外部からのデータを内部表現にマッピングする仕組みを解説し、最後に出力エンコーディングを通じて内部表現が組版に必要な形に変換される方法を説明します。
7.1. LaTeX 内の文字データフロー
LaTeX で文書を処理する際は、まず 1 つ以上のソースファイルに含まれるデータを解釈します。このデータは文字を表すバイト列(オクテット)の集合としてソースファイルに保存されています。これらのオクテットを正しく解釈するためには、ファイルを処理するすべてのプログラム(LaTeX を含む)が、抽象的な文字とそれを表すオクテットとの対応関係、すなわちそのファイルが書かれたときに使用されたエンコーディングを知っていなければなりません。
マッピングが間違っていると、ファイルが正しいエンコーディングと不正なエンコーディングの両方で共通して含まれる文字のサブセットだけで構成されている場合を除き、以後の処理はほぼすべてエラーになります。
LaTeX はこの時点で次の基本的な前提を置きます:可視 ASCII 文字(十進数で 32〜126)はすべて、ASCII コード表における番号と同じ番号で表されているということです。

この前提の理由の一つは、現在使用されている多くの 8 ビットエンコーディングが共通の 7 ビット平面を共有していることです。もう一つは、TeX を効果的に利用するために、可視 ASCII の大部分を 文字 カテゴリに分類しておく必要があるからです。なぜなら、TeX ではこのカテゴリに属する文字だけが複数文字からなるコマンド名に使用できるからです(例:letter カテゴリ)— それ以外は other カテゴリとして扱われ、たとえば十進数の数字はこのカテゴリが付与されていなければ数として認識されません。
文字(正確には 8 ビット数値)が TeX で letter または other カテゴリとして宣言されると、その 8 ビット数値は TeX 内部で透過的に渡されます。つまり、フォント内のその位置にあるシンボルがそのまま組版されます。
上記の前提に従い、一般テキスト用のフォントは(ほとんどの)可視 ASCII 文字がフォント内に存在し、かつ ASCII エンコーディングに従って符号化されている必要があります。
可視 ASCII 以外のすべての 8 ビット数値(入力ファイルに現れ得るもの)は active カテゴリが割り当てられ、TeX 内ではコマンドとして扱われます。したがって、LaTeX はこれらを入力エンコーディングを介して LaTeX internal character representation (LICR) と呼ばれる形に変換できます。
Unicode の UTF‑8 エンコーディングについても同様に扱われます。ASCII 文字はそのまま自己を表し、マルチバイト表現の開始オクテットは残りのオクテットをスキャンする active 文字として機能します。結果は LICR のオブジェクトに変換されます(マッピングが存在すれば)。マッピングが無い場合は LaTeX がエラーを出します。
LICR における最も重要な点は、7 ビット ASCII 文字の表現はエンコーディングが変わっても不変であることです。すべての入力エンコーディングは可視 ASCII に対して透過的であることが想定されているからです。
出力(またはフォント)エンコーディングは、内部文字表現を現在組版に使用されているフォントのグリフ位置にマッピングする役割を担います。場合によっては、より複雑な処理を開始させることもあります。たとえば、現在のフォントのある位置にあるアクセントを別のシンボルの上に配置し、内部文字エンコーディングで表される抽象文字の印刷イメージを得る、といったことが可能です。
LICR は LaTeX が扱えるすべての文字をエンコードします。したがって、単一の TeX フォント(最大 256 グリフ)で表現できる文字数をはるかに超えます。ある場合には、内部エンコーディングの文字をフォント内の複数のグリフを組み合わせて表現することができます(例:アクセント付き文字)。しかし、内部文字が特別な形状を必要とする場合、フォントにそのグリフが無ければ偽装する手段はありません。
それでも LaTeX のエンコーディングモデルは、現在のフォントに不足している文字を別のフォントから自動的に取得して組版できる仕組みを備えています。追加の適切なフォントが利用可能であれば、欠けた文字は組版されます。
7.2. LaTeX の内部文字表現 (LICR)
テキスト文字は LaTeX 内部で次の 3 つの方法のいずれかで表現されます。
文字としての表現
ごく少数の文字は「それ自身」として表現されます。たとえばラテン文字 A は文字 'A' として表現されます。このような文字は上の表に示されています。可視 ASCII のサブセットであり、TeX 内ではすべて letter または other カテゴリが割り当てられます。可視 ASCII の範囲にあるもののうち、TeX の構文要素であったりすべてのフォントに存在しないためにこの方法で表現されない文字もあります。たとえばテキスト中で '<' を使用すると、現在のフォントエンコーディングが T1 であれば < が、OT1 であれば倒置感嘆符が印字されます。
文字列としての表現
TeX の内部リガチャ機構は、入力文字列のシーケンスから新しい文字を生成できます。これはフォント固有の性質ですが、一部のシーケンスはキーボードから直接入力しにくい文字へのショートカットとして明示的に設計されています。以下のような文字はこの方式で内部表現に含まれます:en dash と em dash(それぞれ -- と --- によって生成)、開閉二重引用符(`` と ''、後者は単独の " でも表せます)。多くのフォントは !` と ?` によって倒置感嘆符・倒置疑問符を生成できますが、すべてのフォントで利用できるわけではありません。このため すべて の such characters にはコマンド(例:\textendash や \textexclamdown)という代替内部表現が用意されています。
「フォントエンコーディング固有」コマンドとしての表現
LaTeX が内部で文字を表す第 3 の方法は、特別な LaTeX コマンド(またはコマンドシーケンス)を使用するものです。これらはファイルに書き出されたり、可動引数に入れられたときに展開されません。ここでは フォントエンコーディング固有コマンド と呼びます。なぜなら、その意味は LaTeX が組版しようとする時点で選択されているフォントエンコーディングに依存するからです。これらのコマンドは通常、各フォントエンコーディングごとに個別の定義が必要な特殊宣言を通じて定義されます。現在のエンコーディングに対する定義が無い場合は、利用可能なデフォルトが使用されるか、エラーメッセージが表示されます。
文書中でフォントエンコーディングが変更された場合、エンコーディング固有コマンドの定義は直ちには変わりません。大量のコマンドを一括で変更するのは非現実的だからです。代わりに、これらのコマンドは「現在の定義が新しいエンコーディングに適合しない」ことに気付くと、現在のエンコーディングに対応したコマンドに処理を委譲するよう実装されています。
フォントエンコーディング固有コマンドの集合は固定されたものではなく、個々のエンコーディングで定義されたすべてのコマンドの合併として暗黙的に決まります。そのため、新しいエンコーディングが LaTeX に追加されると、必要に応じて新しい固有コマンドが導入されます。
7.3. 入力エンコーディング
inputenc パッケージをロードすると、8 ビット入力文字を LICR オブジェクトにマッピングするための宣言 \DeclareInputText と \DeclareInputMath が利用可能になります。これらはエンコーディングファイル(下記参照)、パッケージ、または文書のプリアンブルで使用します。
これらのコマンドは最初の引数に 8 ビット数値を取ります。数値は十進、八進、十六進のいずれかで指定できます。十進表記の使用が推奨されます。というのも、シングルクォート ' やダブルクォート " が言語サポートパッケージ内で特別な意味を持ち、八進・十六進表記が無効になる可能性があるためです。
1\DeclareInputText{number}{LICR-object}\DeclareInputText はテキスト用の文字マッピングを宣言します。第 2 引数にはエンコーディング固有コマンド(もしくはコマンドシーケンス)、すなわち文字番号がマッピングされる LICR オブジェクトを指定します。例:
1\DeclareInputText{239}{\"\i}は番号 239 を「i-ウムラウト」のエンコーディング固有表現 \"\i にマッピングします。このように宣言された入力文字は数式内では使用できません。
1\DeclareInputMath{number}{math-object}数式中で使用したい文字の場合は \DeclareInputMath を使用します。たとえば、ドイツ語 MS‑DOS キーボード用エンコーディング cp437de では
1\DeclareInputMath{224}{\alpha}が番号 224 をコマンド \alpha にマッピングします。この宣言はその番号が数式モードでのみ使用可能になることを意味します(\alpha はテキストモードでは使用できません)。
1\DeclareUnicodeCharacter{hex-number}{LICR-object}この宣言は utf8 オプションが有効な場合にのみ利用できます。Unicode の番号を LICR オブジェクトにマッピングします。例:
1\DeclareUnicodeCharacter{00A3}{\textsterling}
2\DeclareUnicodeCharacter{011A}{\v E}
3\DeclareUnicodeCharacter{2031}{\textpertenthousand}理論上は 2 つの空間間に一意の双方向マッピングが存在すべきですが、実装上はいくつかの制約があります。すべての Unicode 文字に対応する LICR オブジェクトが存在するわけでもなく、逆に LICR にしかないオブジェクトもあります。inputenc パッケージは、文書で実際に使用されるエンコーディングに対応する Unicode マッピングだけをロードし、対応が無い文字が要求された場合はエラーメッセージを出します。ユーザーは必要に応じて適切なマッピング情報を提供するか、追加のフォントエンコーディングをロードする必要があります。
前述のとおり、入力エンコーディング宣言はパッケージや文書のプリアンブルで使用できます。正しく機能させるためには、まず inputenc パッケージをロードしてエンコーディングを選択し、その後に個別の宣言を行う必要があります。
inputenc パッケージを使用すると \@tabacckludge というコマンドが現れることがあります。これは「タビングアクセントの回避策」の意味です。\=、\`、\' といった本来アクセント用のコマンドが tabbing 環境内で特別な意味を持つため、これらのアクセントを含むマッピングは特別な書き方が必要です。たとえば、e にグレイヴアクセント(内部表現は \`e)を割り当てたい場合は次のように書きます。
1\DeclareInputText{232}{\@tabacckludge`e}instead of
1\DeclareInputText{232}{\`e}テキストと数式へのマッピング
技術的・概念的に、TeX はテキスト向け文字と数式向け文字を厳密に区別します。可視 ASCII 文字を除き、文字を生成するコマンドは通常どちらか一方のモードでしか使用できません。
8 ビットエンコーディング用の入力エンコーディングファイル
入力エンコーディングは拡張子 .def のファイルに格納され、ベース名はエンコーディング名(例:latin1.def)です。これらのファイルは本節で説明した宣言のみを含む必要があります。ファイルは次のような \ProvidesFile 行で始めます。
1\ProvidesFile{latin1.def}[2000/07/01 v0.996 Input encoding file]エンコーディング固有コマンドが追加パッケージなしでは利用できない場合は、\ProvideTextCommandDefault でデフォルトを宣言できます。例:
1\ProvideTextCommandDefault{\textonehalf}{\ensurement{\frac12}}
2\ProvideTextCommandDefault{\textcent}{\TextSymbolUnavailable\textcent}残りは \DeclareInputText と \DeclareInputMath のみです。\newcommand など、ファイルの複数回読込みを妨げるコマンドは使用しないでください。
UTF‑8 用の入力マッピングファイル
Unicode から LICR へのマッピングは、文書で使用されるフォントエンコーディングに応じて必要なものだけをロードできるように構成されています。各エンコーディング名に対応する <name>enc.dfu ファイルが存在すれば読み込み、そこに Unicode 文字のマッピングが記載されています。utf8enc.dfu が全体の一覧です。
7.4. 出力エンコーディング
出力エンコーディングは LICR から使用フォントのグリフ(またはグリフの組み合わせ)へのマッピングを定義します。これらのマッピングは 2 文字または 3 文字の名前(例:OT1、T3)で参照されます。エンコーディングが XYZ の場合、XYZ という名前のエンコーディングが存在すると言います。
ASCII 文字として内部表現される文字はそのままフォントに渡されます。つまり TeX は ASCII コードを用いて現在のフォントから該当グリフを選択します。たとえば ASCII コード 65 の文字 'A' は、現在のフォントの位置 65 にあるグリフが組版されます。そのため、LaTeX ではテキスト用フォントがすべての ASCII 文字を正しい位置に持つことが必須です。
ASCII 文字列(例:"--")として内部表現される文字は、フォントがリガチャプログラムを提供している場合にそれに従って置換されます。たとえば “--"(ASCII 45 が2回)が入力に現れたとき、リガチャプログラムが位置 123 のグリフ(en dash)に置き換えることがあります。
内部文字表現の大部分は、先に述べたフォントエンコーディング固有コマンドです。これらは以下で説明する宣言を用いてマッピングされます。すべての宣言は最初の 2 つの引数が「コマンド(またはシーケンスの最初の要素)」と「エンコーディング名」になり、残りの引数は宣言の種類に応じて変わります。
エンコーディング XYZ は、2 番目の引数がすべて XYZ である多数の宣言から構成されます。実際には、既存のフォントに対して適切な宣言を追加してエンコーディングを定義します。以下では ecrm1000 フォント(T1 エンコーディング)を例に、適切な宣言を作成する過程を示します。
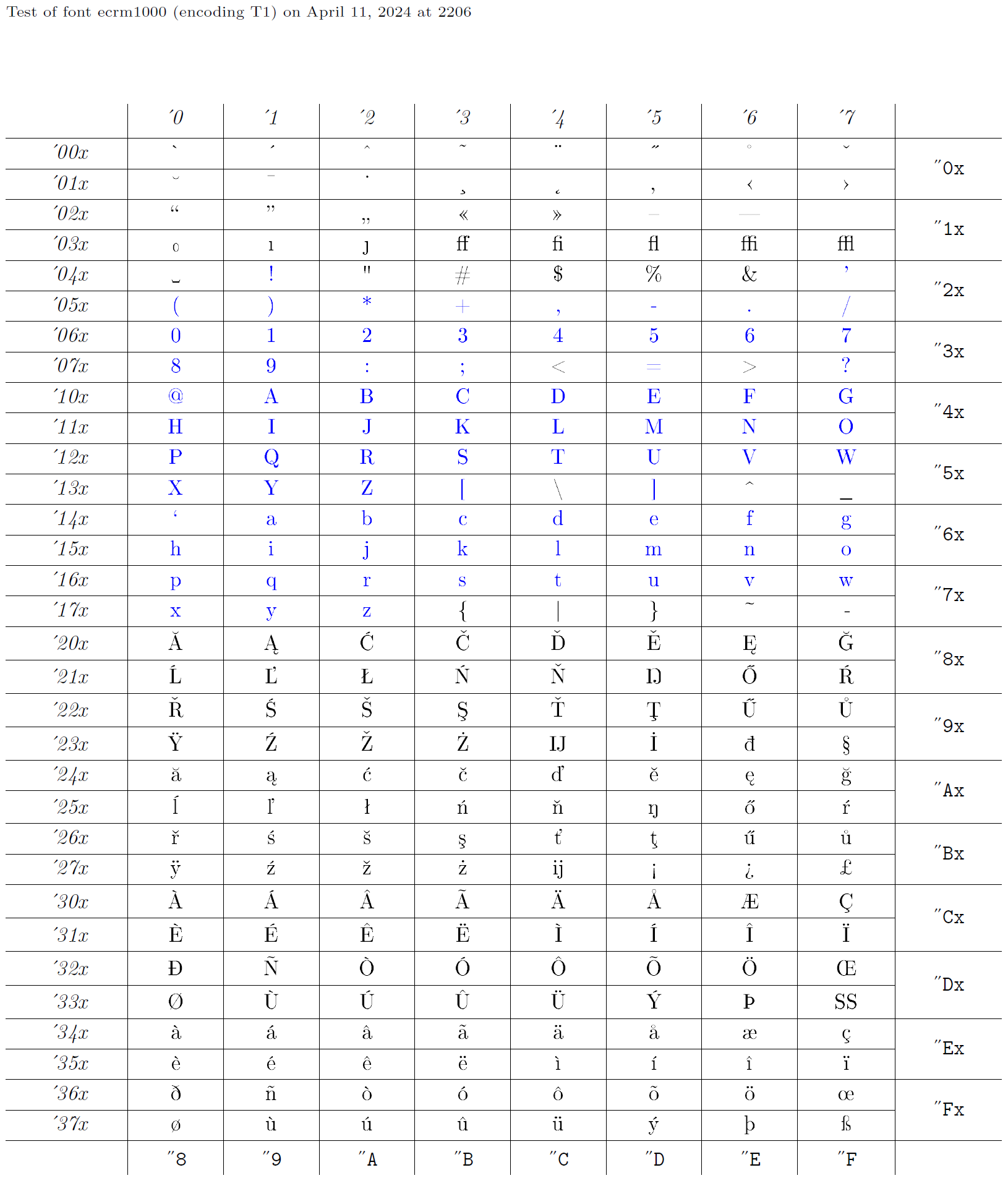
出力エンコーディングファイル
出力エンコーディングファイルも .def 拡張子を持ちますが、ベース名は小文字のエンコーディング名に続けて enc が付く形式です(例:t1enc.def)。
これらのファイルは本節で説明した宣言だけを含めます。複数回読み込まれる可能性があるため、\newcommand などの使用は避けてください。
例:
1\ProvidesFile{t1enc.def}[2001/06/05 v1.94 Standard LaTeX file]エンコーディング固有コマンドを宣言する前に、まず LaTeX にエンコーディングを認識させる必要があります。これは \DeclareFontEncoding で行い、必要に応じて \DeclareFontSubstitution でデフォルト置換規則を設定します。詳しくは
How to set up new fonts を参照してください。
1\DeclareFontEncoding{T1}{}{}
2\DeclareFontSubstitution{T1}{cmr}{m}{n}エンコーディングが認識されたら、次のようにしてフォントエンコーディング固有コマンドの動作を宣言します。
1\DeclareTextSymbol{LICR-Object}{encoding}{slot}\DeclareTextSymbol は最もシンプルです。内部表現をターゲットフォントの単一グリフに直接マッピングします。スロット位置は十進、八進、十六進のいずれかで指定できます。例:
1\DeclareTextSymbol{\ss}{T1}{255}
2\DeclareTextSymbol{\AE}{T1}{'306} % octal
3\DeclareTextSymbol{\ae}{T1}{"E6} % hexadecimal1\DeclareTextAccent{LICR-accent}{encoding}{slot}多くのフォントはアクセント用の個別グリフを持ち、これを他の文字と組み合わせてアクセント付き文字を作ります。\DeclareTextAccent はそのようなアクセントを宣言します。例:
1\DeclareTextAccent{\"}{T1}{4}これにより、\"a などの内部表現は、T1 エンコーディングでは位置 4 のアクセントを ASCII 97(文字 a)の上に置くことで組版されます。
1\DeclareTextComposite
2 {LICR-accent}{encoding}{simple-LICR-object}{slot}T1 では \"a が実際には位置 '240 の単独グリフとして存在します。そのため次のように宣言してアクセントの上書きを防ぎます。
1\DeclareTextComposite{\"}{T1}{a}{228}他の \" 系コマンド(例:\"b)はアクセント宣言が適用されます。
1\DeclareTextCompositeCommand
2 {LICR-object}{encoding}{simple-LICR-object}{code}OT1 エンコーディングではリングアクセントを A の上に低く配置するなど、スロット位置以外のコードを使用した例があります。
1\DeclareTextCompositeCommand{\'}{OT1}{i}{\@tabacckludge'\i}
2\DeclareTextCompositeCommand{\^}{OT1}{i}{\^\i}下付けアクセントなどは \DeclareTextCommand で実装されます。
1\DeclareTextCommand{LICR-object}{encoding}[num][default]{code}例として T1 の下線アクセント \b は次のように定義されています。
1\DeclareTextCommand{\b}{T1}[1]
2 {\hmode$bgroup\o$lign{\relax#1\crcr\hidewidth\sh$ft{29}%
3 \vbox to.2ex{\hbox{\char9}\vss}\hidewidth}\egroup}\DeclareTextCommand は引数の数やデフォルト引数を持つ点で \newcommand に似ています。
単一コマンドのフォントエンコーディング固有コマンドも同様に定義できます。たとえば T1 には千分の一記号用のグリフが無く、代わりに % の直後に小さな o(位置 '30)を置くことで実現します。
1\DeclareTextCommand{\textperthousand} {T1}{\%\char 24}
2\DeclareTextCommand{\textpertenthousand}{T1}{\%\char 24\char 24 }以上で新しいエンコーディングに必要なすべてのコマンド宣言が完了します。
出力エンコーディングのデフォルト
現在のエンコーディングに宣言が無いエンコーディング固有コマンドを使用した場合、次のいずれかが起こります。1) LaTeX がデフォルト定義を持っていればそれが使用され、2) エラーメッセージが出力されます。
1\DeclareTextCommandDefault{LICR-object}[num][default]{code}\DeclareTextCommandDefault は、特定エンコーディングに設定が無い場合に使用されるデフォルトを提供します。たとえば \textregistered は次のようにデフォルトで偽装されます。
1\DeclareTextCommandDefault{\textregistered}{\textcircled{\scshape r}}デフォルトは内部的に名前が ? のエンコーディングに保存されますが、直接参照しないでください。
1\DeclareTextSymbolDefault{LICR-object}{encoding}多くの場合、デフォルトは実際のコードを伴わずに、既知のエンコーディングから文字を取得するだけです。たとえば textcomp パッケージは多数のデフォルト宣言を TS1 エンコーディングに向けています。
1\DeclareTextSymbolDefault{\texteuro}{TS1}1\DeclareTextAccentDefault{LICR-accent}{encoding}アクセント系のデフォルトも同様に宣言できます。
1\DeclareTextAccentDefault{\"}{OT1}
2\DeclareTextAccentDefault{\t}{OML}1\ProvideTextCommandDefault{LICR-object}[num][default]{code}\ProvideTextCommandDefault は「もしまだデフォルトが無ければ」提供する形で、入力エンコーディングファイルでよく使われます。例:
1\ProvideTextCommandDefault{\textonequarter}{\ensuremath{\frac14}}
2\ProvideTextCommandDefault{\textcent}{\TextSymbolUnavailable\textcent}1\UndeclareTextCommand{LICR-object}{encoding}既存の宣言を削除してデフォルトに回す必要がある場合に使用します。textcomp パッケージは OT1 から \textdollar と \textsterling の定義を削除し、TS1 から取得できるようにしています。
1\UndeclareTextCommand{\textsterling}{OT1}
2\UndeclareTextCommand{\textdollar} {OT1}1\UseTextSymbol{encoding}{LICR-object}
2\UseTextAccent{encoding}{LICR-object}{simple-LICR-object}\DeclareTextSymbolDefault や \DeclareTextAccentDefault の裏で行われている処理を直接呼び出すこともできます。たとえば現在のエンコーディングが U の場合、次のように書くと同じ効果があります。
1\UseTextSymbol{OT1}{\ss}
2\UseTextAccent{OT1}{\'}{a}1{\fontencoding{OT1}\selectfont\ss}
2{\fontencoding{OT1}\selectfont\'{\fontencoding{U}\selectfont a}}標準 LICR オブジェクト一覧
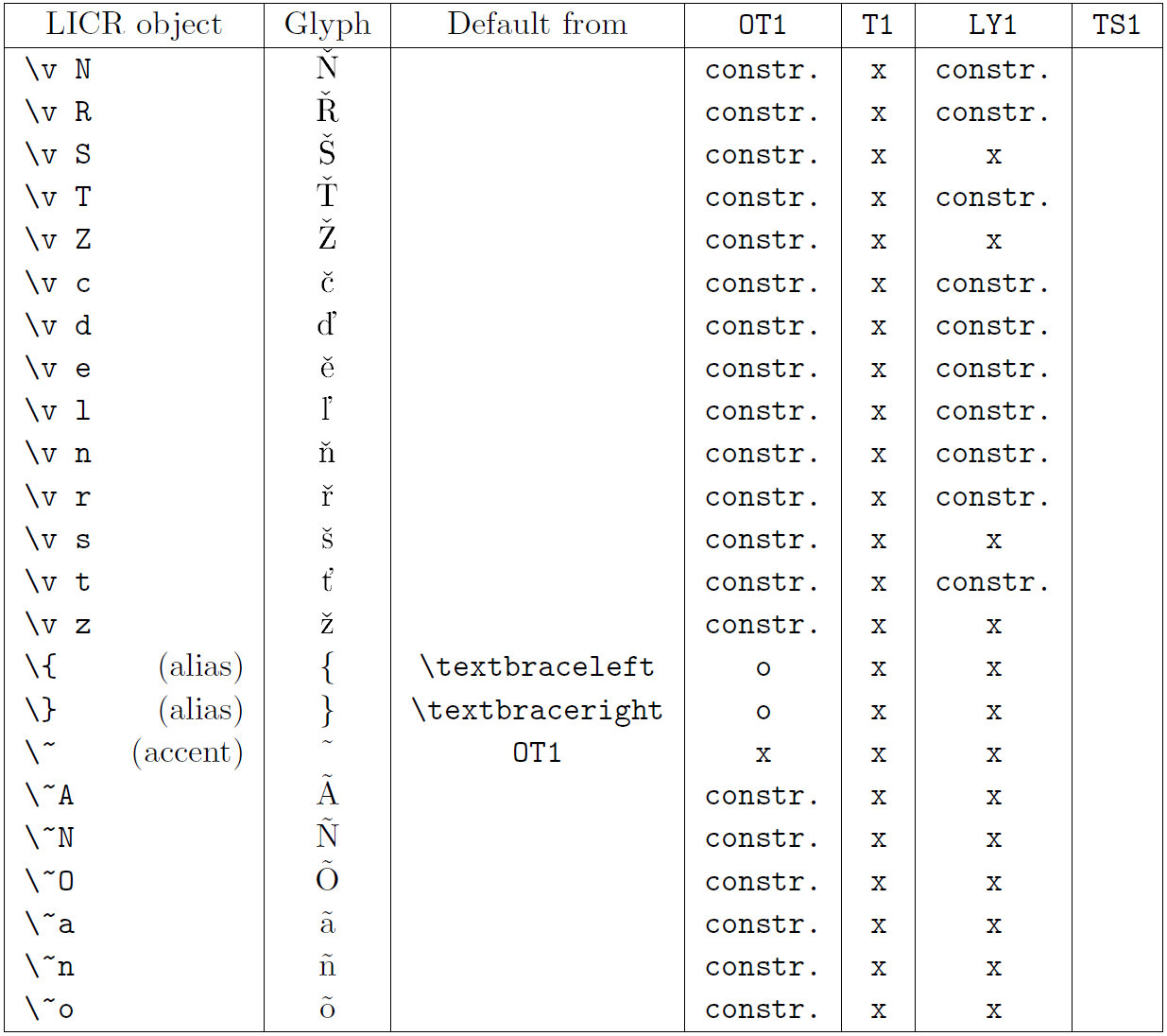
以下の表は、ラテン系言語向けの主要 3 エンコーディング(OT1、T1、LY1)と、textcomp パッケージで提供される TS1 エンコーディングにおける LICR オブジェクトの概要を示しています。
- 第1列はアルファベット順の LICR オブジェクト名で、アクセント系かどうかを示します。
- 第2列はグリフのイメージです。
- 第3列はデフォルト宣言の有無を示し、エンコーディングが記載されていればそのエンコーディングから取得されます。
constr.は低レベル TeX コードで生成されることを示します。空欄はデフォルトが無く、使用すると「Symbol unavailable」エラーになります。 - 第4〜7列はそれぞれのエンコーディングでの利用可否を示します。
xはそのエンコーディングでネイティブに利用可能、oはデフォルト経由で利用可能、constr.は合成で生成されることを示します。TS1から取得する場合はtextcompパッケージのロードが必要です。
LICR objects. Part 1
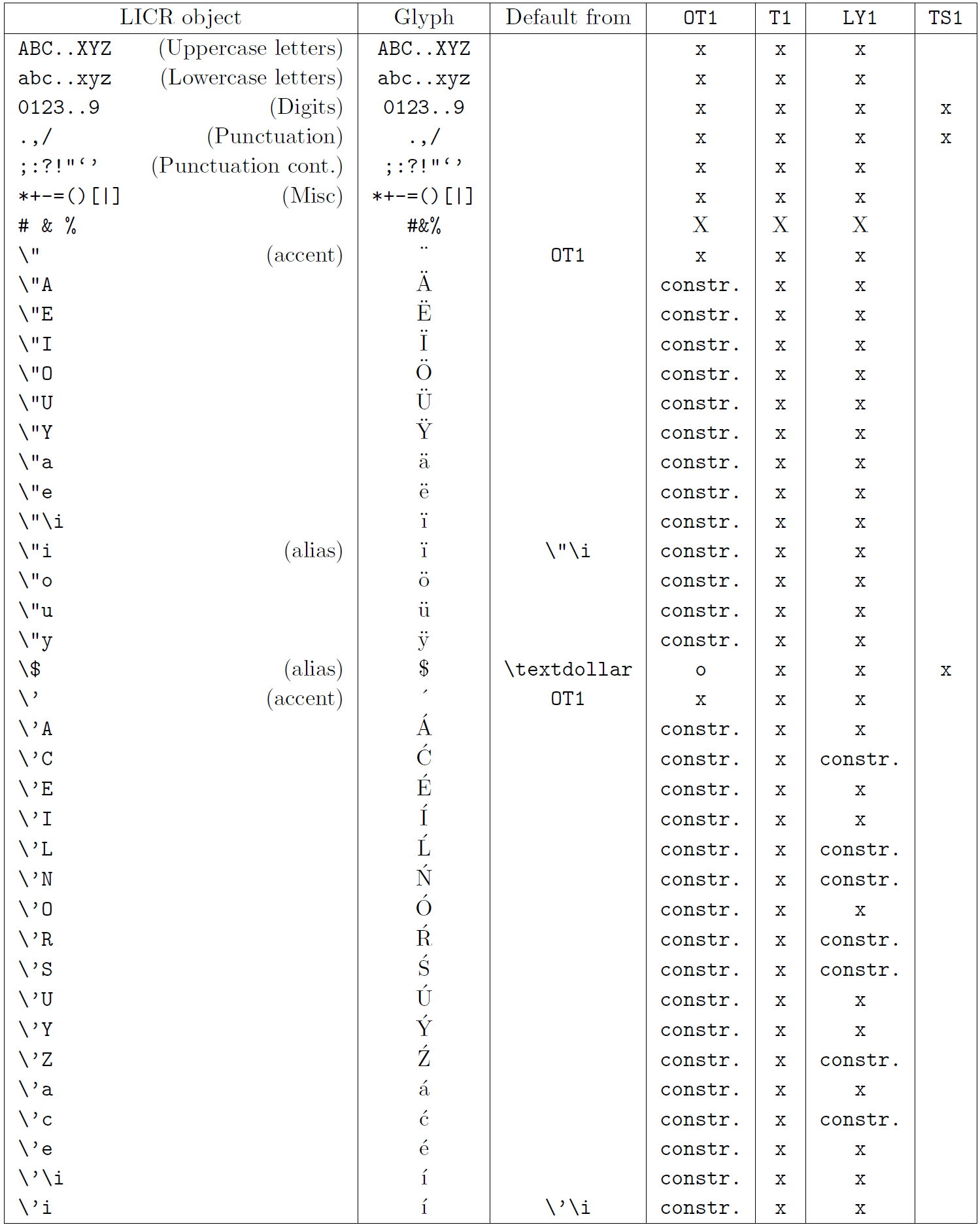
LICR objects. Part 2
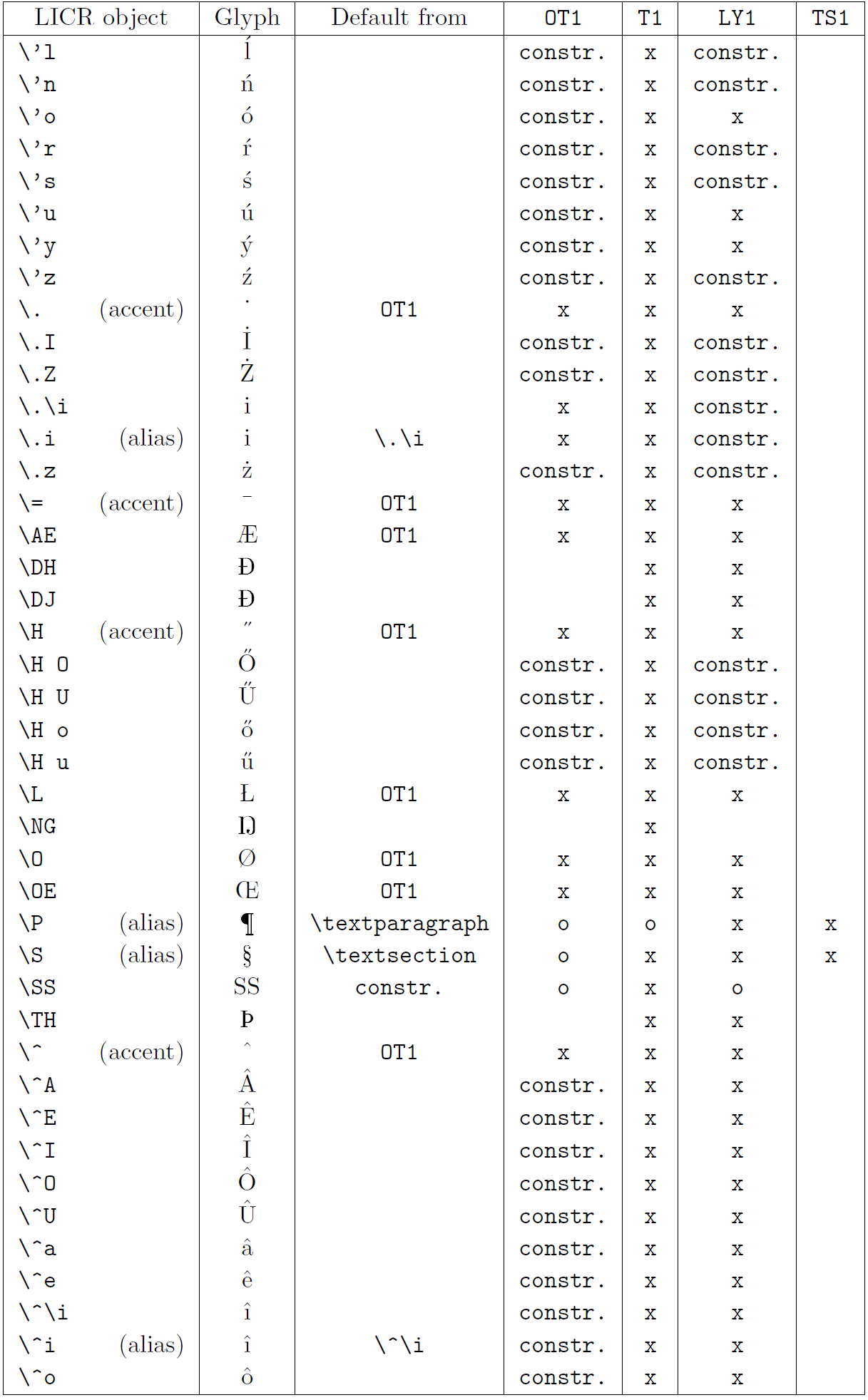
LICR objects. Part 3
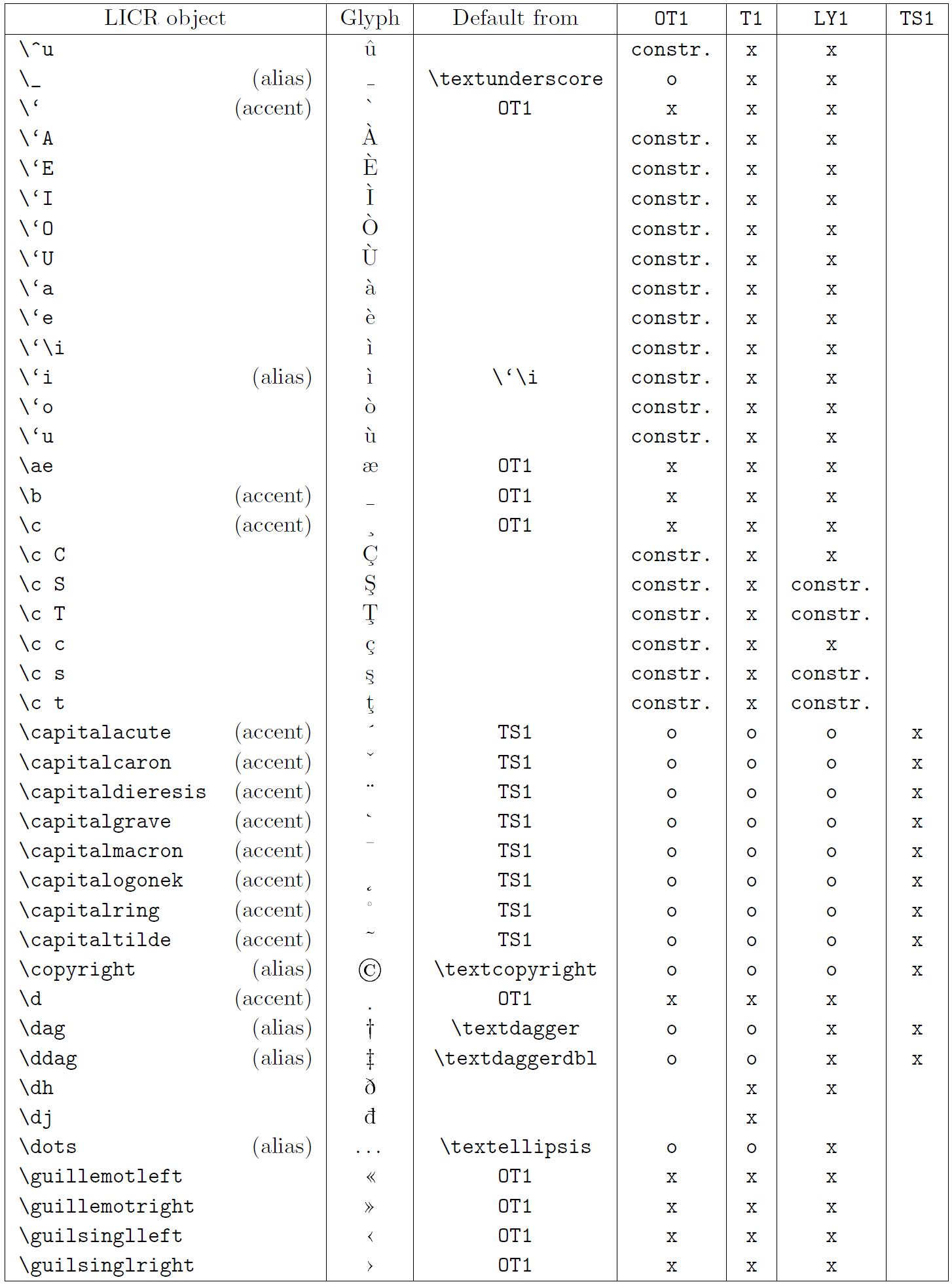
LICR objects. Part 4
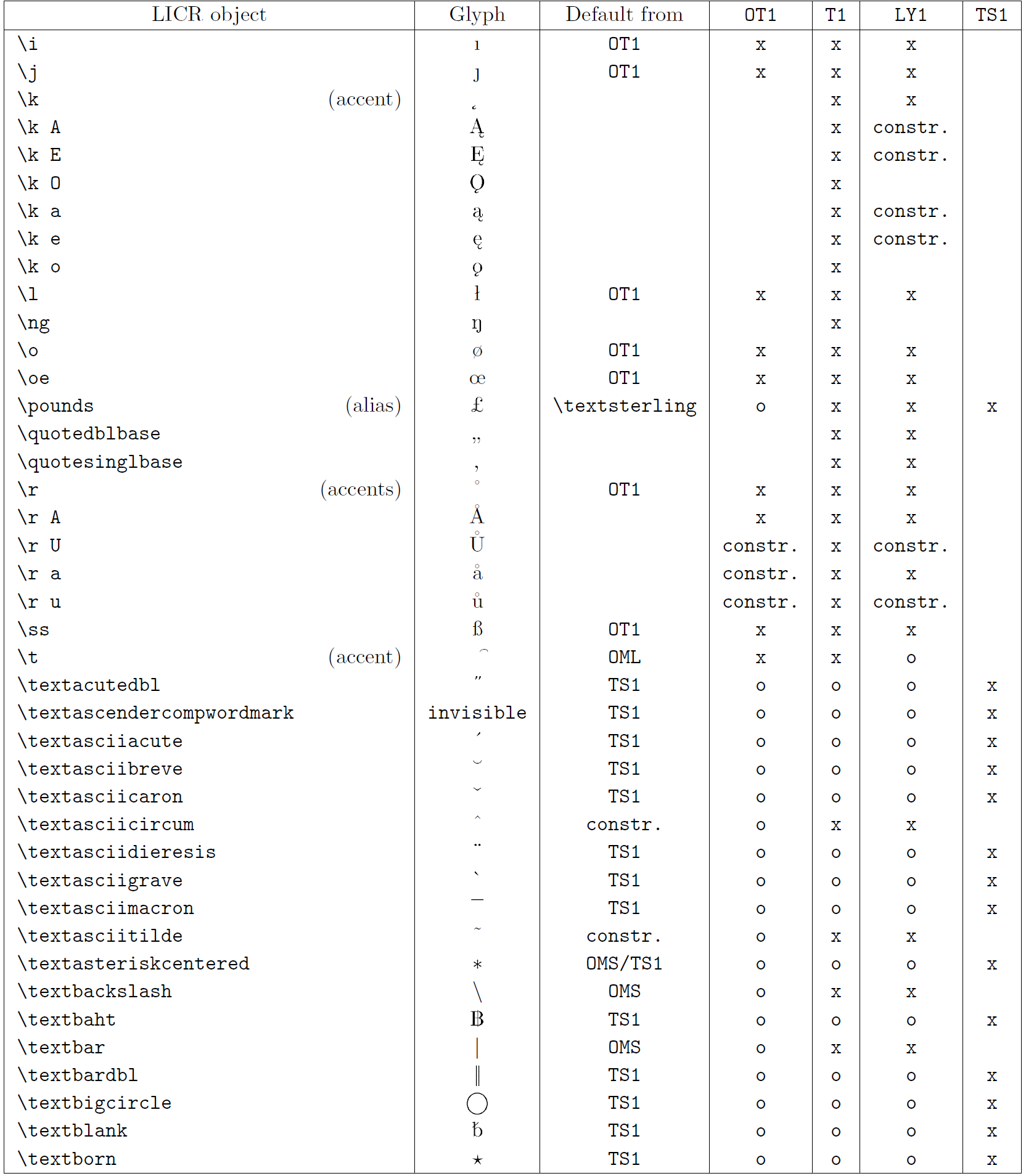
LICR objects. Part 5
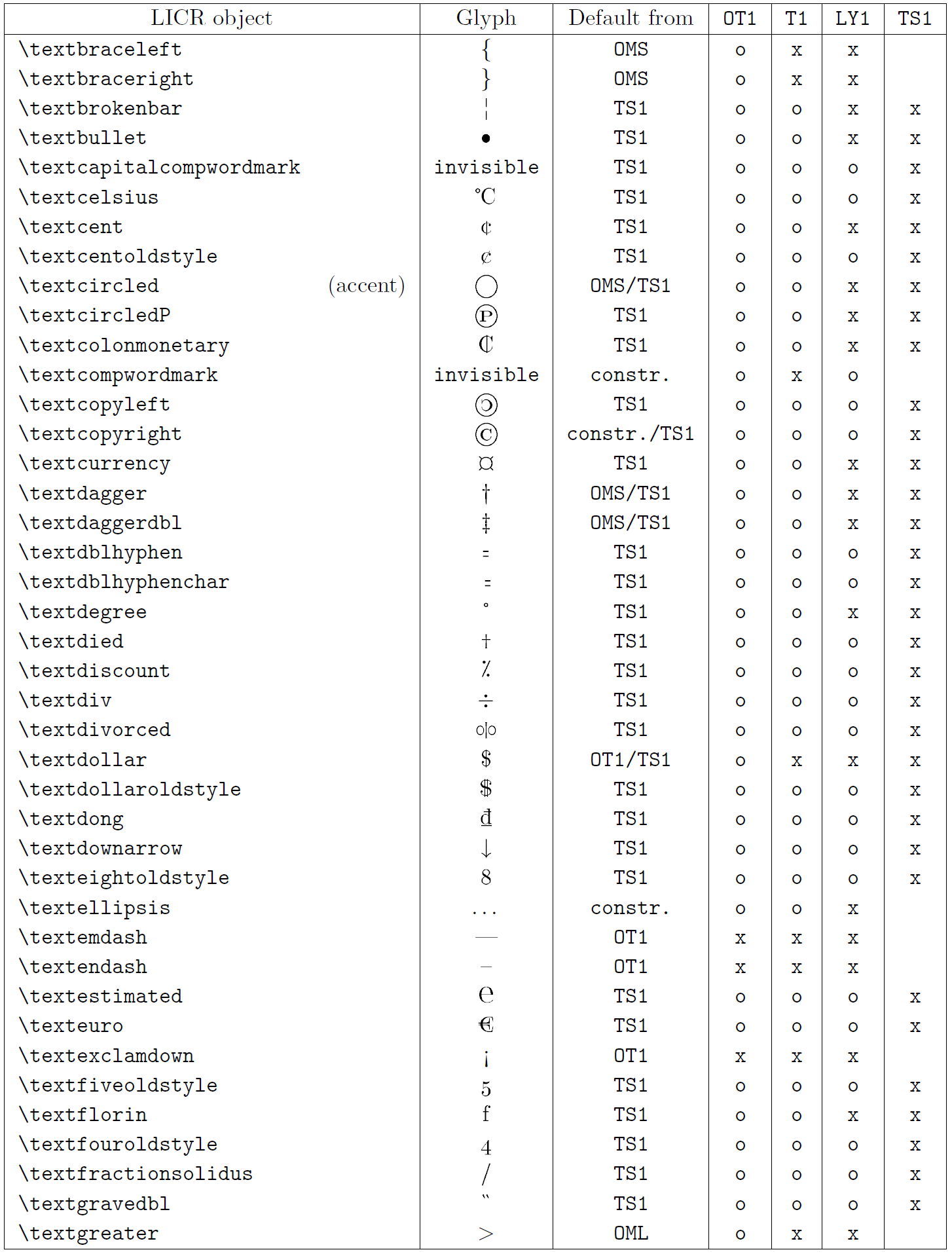
LICR objects. Part 6
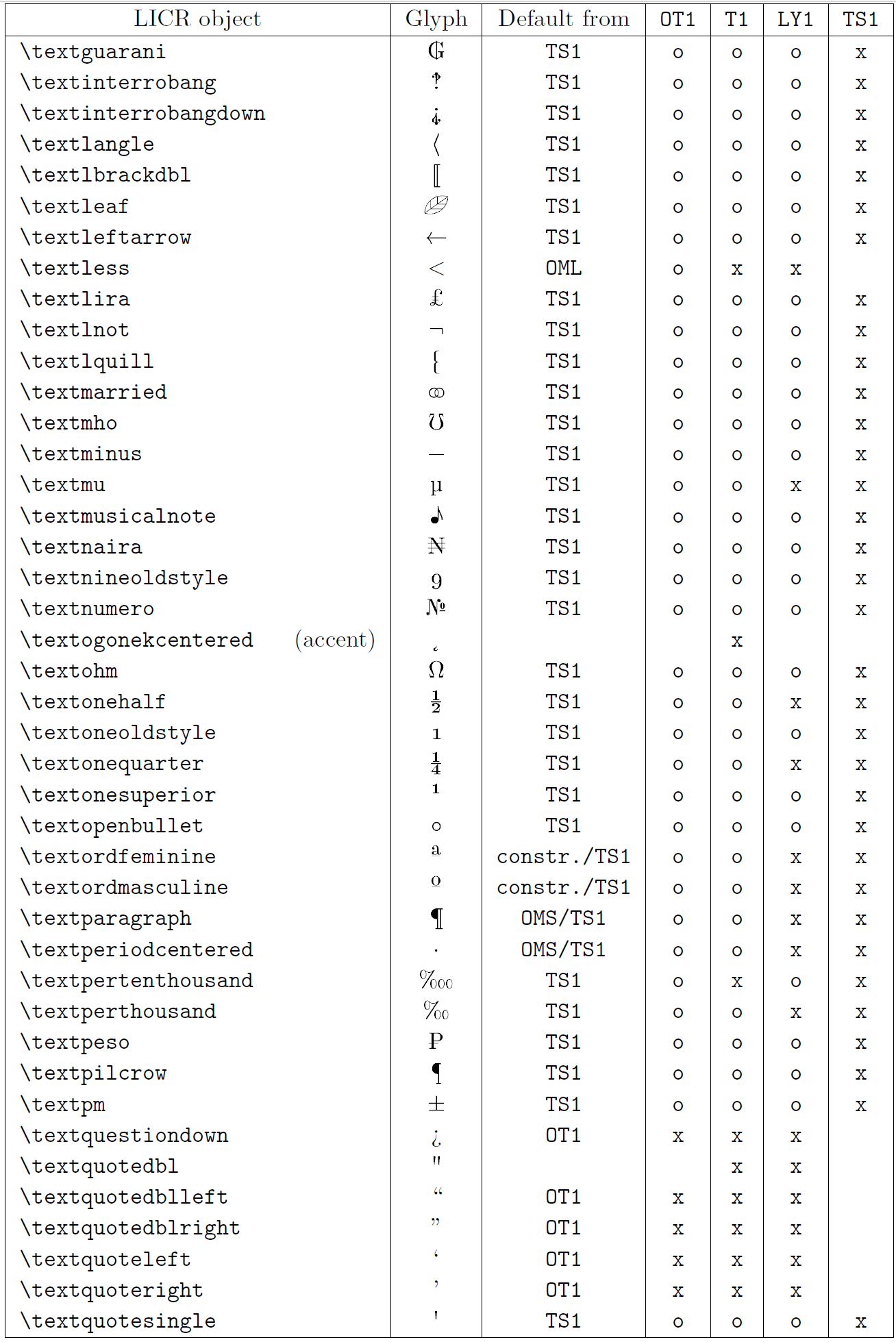
LICR objects. Part 7
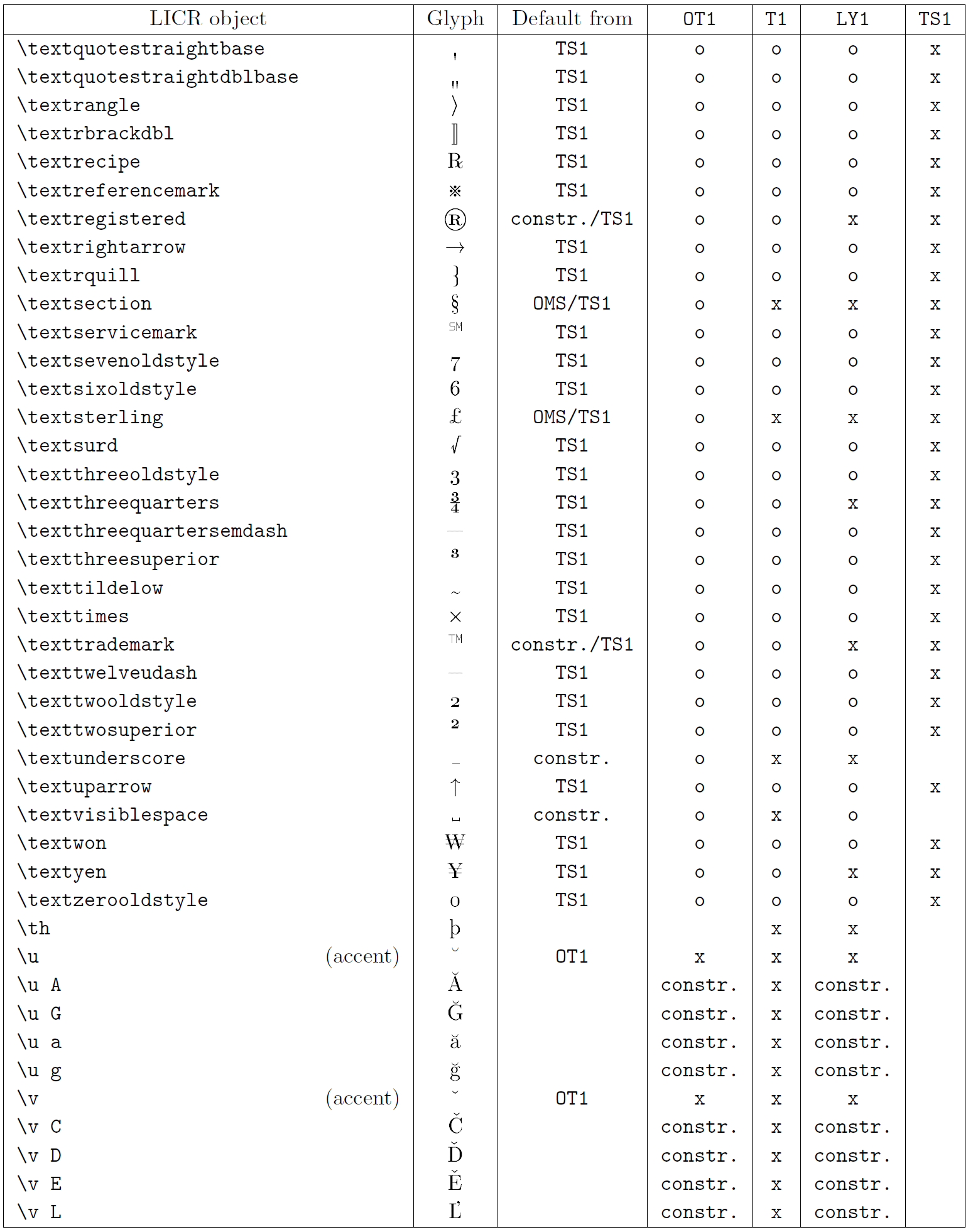
LICR objects. Part 8