4. 標準 LaTeX フォント
この記事では、LaTeX に同梱されている標準テキストフォントの簡単な紹介を行います。その後、LaTeX の入力エンコーディングとフォントエンコーディングの標準的なサポートについて解説します。最後に、LaTeX のフォント処理をトレースするパッケージと、グリフ表を表示するパッケージについて説明します。
4.1. Computer Modern Roman
Donald Knuth が TeX と共に開発したフォントファミリー Computer Modern が存在します。1990 年代初頭まで、これらのフォントは主に TeX、ひいては LaTeX でしか実用的に使用できませんでした。各フォントは 128 個のグリフしか持たないため、アクセント付き文字を個別のグリフとして含めることができません。そのため、これらのフォントを使用する場合、アクセント付き文字は TeX の \accent プリミティブで生成しなければならず、結果としてアクセント付き文字を含む単語の自動ハイフネーションは不可能になります。この制約は英語文書では許容できますが、他言語にとっては明らかな不利益です。
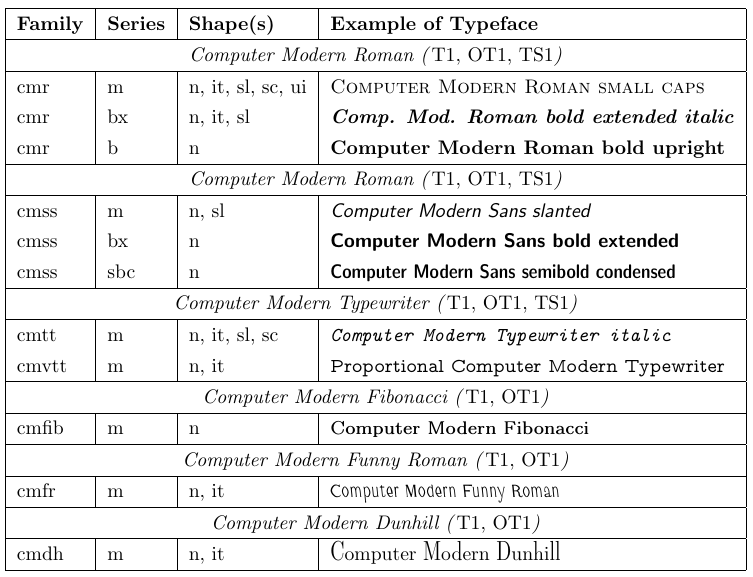
このような欠点は欧州の TeX 利用者にとって大きな問題となり、最終的に 1989 年に 8 ビット文字を内部・外部ともにサポートするよう TeX が再実装されました。1990 年にテキストフォント用の標準 8 ビットエンコーディング (T1) が策定され、30 以上のラテン文字ベースの言語で組版が可能となりました。その後、Computer Modern フォントファミリーが再実装され、追加文字が設計されて、結果としてこれらのフォントはエンコーディングスキームに完全に適合するようになりました。
4.2. Selecting the input encoding: the inputenc package
アクセント付き文字を単一キー入力や別の入力方法(例: ` の後に a を入力して a-grave を得る)で入力でき、エディタ上でも正しく表示される場合…

…理想的には \`a、\^e などと入力する代わりに、直接その文字列を LaTeX に渡したいでしょう。
フランス語やドイツ語などではこのアプローチは実現可能です。しかし、ロシア語やギリシャ語のように、ほぼすべての文字が内部 LaTeX コマンドとして名前を持つ言語では、直接入力が必要となります。たとえば、ロシア語のデフォルト定義 \reftextafter は次のようになっています(「次のページ」を意味します):
1\cyrn\cyra\ \cyrs\cyrl\cyre\cyrd\cyru\cyryu\cyrshch\cyre\cyrishrt
2\ \cyrs\cyrt\cyrr\cyra\cyrn\cyri\cyrc\cyreこのような文字列を日常的に入力したい人はほとんどいませんが、どの LaTeX 環境でも正しく解釈できるという利点があります。一方、適切なキーボードで
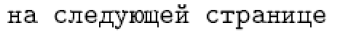
と入力できれば、もちろんそれが望ましいです。問題は、ファイルに保存されているのは画面上に見える文字列ではなく、文字を表すバイト列(オクテット)であることです。エンコーディングが異なると、同じオクテット列が別の文字を表すことがあります。
同一コンピュータ上で全てのプログラムが同じ方式でオクテットを解釈している限り、通常は問題ありません。しかし、ある環境で作成したファイルを別のコンピュータに渡すと、処理が失敗したり、見かけ上は成功したように見えても文字化けしてしまうことがあります。
この問題に対処するために inputenc パッケージが作られました。その主な目的は、文書全体または文書の一部で使用されているエンコーディングを LaTeX に知らせることです。エンコーディング名をオプションとして指定してパッケージを読み込むことで実現します。例:
1\usepackage[cp1252]{inputenc} % Windows 1252(西ヨーロッパ)コードページこれ以降、LaTeX はどのコンピュータでも同じ方法でオクテットを解釈できるようになります。
以下は典型的な例です。koi8-r エンコーディング(ロシアで一般的)で書かれた短いテキストです。ソースコードはラテン1エンコーディング(例: ドイツ)で表示されていますが、inputenc が正しい入力エンコーディングを認識しているため、正しく解釈されます。

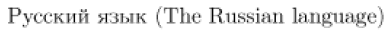
現在 inputenc がサポートしているエンコーディングの一覧を以下に示します。インターフェイスは十分に文書化されており、新しいエンコーディングも容易に追加できます。したがって、使用しているエンコーディングが一覧にない場合は、inputenc のパッケージ文書を参照してください。また、他の作者が作成したエンコーディングファイルをインターネットで検索することもできます。たとえば、キリル文字に関連するエンコーディングは、他のキリル文字サポートパッケージと一緒に配布されています。
ISO‑8859 標準は重要なシングルバイトエンコーディングを多数定義しています。ラテン文字に関連するエンコーディングは inputenc がサポートしています。Windows 向けには Microsoft がいくつかのシングルバイトエンコーディングを定義しています。さらに、他のベンダーが定義したエンコーディングも利用可能です。
latin1ISO‑8859‑1(ラテン 1)。西ヨーロッパ諸語(アルバニア語、カタロニア語、デンマーク語、オランダ語、英語、フェロー語、フィンランド語、フランス語、ガリシア語、ドイツ語、アイスランド語、アイルランド語、イタリア語、ノルウェー語、ポルトガル語、スペイン語、スウェーデン語)を表現できます。latin2ISO‑8859‑2(ラテン 2)。ラテン文字を使用する中欧のスラブ語(クロアチア語、チェコ語、ドイツ語、ハンガリー語、ポーランド語、ルーマニア語、スロバキア語、スロベニア語)に対応。latin3ISO‑8859‑3。エスペラント、ガリシア語、マルタ語、トルコ語に使用。latin4ISO‑8859‑4。エストニア語、ラトビア語、リトアニア語に対応。latin5ISO‑8859‑9(ラテン 5)。ラテン 1 と非常に類似し、アイスランド語のまれな文字をトルコ語の文字に置き換えたもの。latin9ISO‑8859‑15(ラテン 9)。ユーロ記号や\AE合字など、フランス語やフィンランド語で不足していた文字を追加。ラテン 1 の置き換えとして徐々に普及。cp437IBM 437(MS‑DOS ラテン、ボックス描画文字多数)。cp850IBM 850(MS‑DOS 多言語、latin1 に類似)。cp852IBM 852(MS‑DOS 多言語、latin2 に類似)。cp858IBM 858(IBM 850 にユーロ記号を追加)。cp865IBM 865(MS‑DOS ノルウェー)。cp1250Windows 1250(中東欧)。cp1252Windows 1252(西ヨーロッパ)。cp1257Windows 1257(バルト諸語)。ansinewWindows 3.1 ANSI(cp1252 の別名)。decmultiDEC 多国語文字セット。applemacMacintosh 標準エンコーディング。macceMacintosh 中欧コードページ。nextNext Computer エンコーディング。utf8Unicode の UTF‑8 エンコーディング。
ほとんどの TeX 環境はデフォルトで 8 ビット文字を受け入れますが、inputenc のような調整なしに使用すると結果は予測不能です。文字が消失したり、現在使用中のフォントに存在する別のグリフが表示されたりします。長らく LaTeX2e のデフォルト動作だったため、変更されていませんでしたが、誤用を防ぐために inputenc は ascii オプションを提供しています。このオプションを付けると、ASCII 範囲外(32‑126 以外)の文字はエラーとなります。
1\inputencoding{encoding}当初、inputenc パッケージは文書全体のエンコーディングを指定するために設計されていました(プレアンブルでオプションを使用)。しかし、文書途中でエンコーディングを変更したい場合は \inputencoding コマンドを使用できます。このコマンドはエンコーディング名を引数に取ります。
inputenc が開発された当時、ほとんどの LaTeX 環境は本節で紹介したシングルバイトエンコーディングを使用していました。現在は Unicode をサポートするシステムが増え、UTF‑8 が主流です。inputenc の utf8 オプションは完全な UTF‑8 実装ではなく、標準 LaTeX フォントに存在する Unicode 文字(主にラテン文字とキリル文字)だけをマッピングします。その他の文字はエラーメッセージが出ます。また、Unicode の結合文字はサポートされていませんが、実務上は大きな問題にはなりません。
1\usepackage[utf8]{inputenc}
2\usepackage{textcomp} % for Latin interpretation
3-----------------------------------------------
4German umlauts in UTF-8: ^^c3^^a4^^c3^^b6^^c3^^bc
5\par\inputencoding{latin1}% switch to Latin 1
6But interpreted as Latin 1: ^^c3^^a4^^c3^^b6^^c3^^bc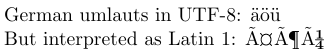
UTF‑8 では ASCII 文字はそのまま表現され、ほとんどのラテン文字は 2 バイトで表されます。上の例では、UTF‑8 のドイツ語ウムラウトが TeX の 16 進表記(各バイトの前に ^^)で示されています。UTF‑8 を理解しないエディタでは、これらはラテン 1 文字として解釈された場合と同様に見えるかもしれません。
Korean、Chinese、Japanese 文字も含むより包括的な UTF‑8 サポートを提供するパッケージとして、Dominique Unruh が書いた ucs パッケージがあります。inputenc だけでは足りない場合は試してみてください。
4.3. Selecting font encodings with the fontenc package
LaTeX でテキストフォントエンコーディングを有効にするには、プリアンブルまたは文書クラスでエンコーディングを読み込む必要があります。具体的には、特定のエンコーディングに対応したグリフへのアクセス定義をロードします。標準的な方法は fontenc パッケージを使用することで、カンマ区切りのエンコーディングリストをオプションとして指定します。リストの最後のエンコーディングがデフォルトの文書エンコーディングになります。キリル系エンコーディングをロードすると、\MakeUppercase と \MakeLowercase が影響を受けるコマンドリストも自動的に拡張されます。例:
1\usepackage[T2A,T1]{fontenc}この例では、キリルの T2A と T1 エンコーディングに必要な定義がすべてロードされ、T1 がデフォルトの文書エンコーディングとして設定されます。
通常のパッケージと異なり、fontenc は異なるオプションで複数回ロードすることができます。これは、文書クラスがあるエンコーディングのセットをロードし、ユーザーがプリアンブルでさらにエンコーディングを追加したい場合に便利です。複数回ロードしても副作用はほとんどなく、文書のデフォルトフォントエンコーディングが変更されるだけです。
babel などの言語サポートパッケージを使用している場合、必要なフォントエンコーディングはすでにそれらのパッケージによってロードされていることが多いです。
4.4. How to trace the font selection with the tracefnt package
フォント選択システムの問題を検出するには、tracefnt パッケージを使用できます。このパッケージはいくつかのオプションを提供し、NFSS が端末とトランスクリプトファイルに出力する情報量をカスタマイズできます。
errorshow警告や情報メッセージは端末に表示せず、トランスクリプトファイルにのみ書き込まれます。実際のエラーだけが端末に表示されます。重要な出版物を印刷する前に、フォント置換に関する警告などが最終結果に影響しないか、トランスクリプトを注意深く確認してください。warningshowこのオプションを指定すると、警告とエラーが端末に表示されます。tracefntパッケージをロードしない場合と同等の詳細情報が得られます。infoshowtracefntパッケージをロードしたときのデフォルトオプションです。通常はトランスクリプトにのみ書き込まれる情報が端末にも表示されます。debugshowテキストフォントの変更や、ブレースグループや環境の終端でフォントが復元される際の情報も表示します。大量のトランスクリプトファイルが生成される可能性があるため注意が必要です。pausingすべての警告をエラーに変換し、重要な出版物での問題検出を助けます。loading外部フォントのロードを表示します。ただし、使用中のフォーマットやクラスがすでにフォントをロードしている場合は表示されません。
4.5. How to display font tables and samples with nfssfont.tex
nfssfont.tex というファイルは、新しいフォントのテストや、すべての文字を示すフォント表の作成、その他フォントに関する操作に使用できます。このファイルはすべての LaTeX 配布に含まれています。LaTeX でこのファイルを実行すると、テストしたいフォント名の入力を求められます。入力は拡張子なしの外部フォント名(例: cmr10)でも、空のフォント名でも構いません。後者の場合、NFSS のフォント指定(エンコーディング名(デフォルト T1)、フォントファミリー名(デフォルト cmr)、フォントシリーズ(デフォルト m)、フォントシェイプ(デフォルト n)、フォントサイズ(デフォルト 10pt))の入力が求められます。プログラムはそれに対応する外部ファイルを読み込みます。
次にコマンドの入力を求められます。最も重要なのは \table で、以下のようなフォント表が生成されます。\text は長めのテキストサンプルを生成します。新しいテストフォントに切り替えるには \init、テストを終了するには \bye または \stop、その他のテストについては \help を入力してください。
1**********************************************
2* NFSS font test program version <v2.2b>
3*
4* Follow the instructions
5**********************************************
6
7Input external font name, e.g., cmr10
8(or <enter> for NFSS classification of font):
9
10\currfontname=cmr10
11Now type a test command (\help for help):)
12*\table
13
14*\newpage
15*\init
16Input external font name, e.g., cmr10
17(or <enter> for NFSS classification of font):
18
19\currfontname=
20*** NFSS classification ***
21
22Font encoding [T1]:
23
24\encoding=OT1
25(ot1enc.def)
26Font family [cmr]:
27
28\family=cmdh
29Font series [m]:
30
31\series=m
32Font shape [n]:
33
34\shape=n
35Font size [10pt]:
36
37\size=10
38(ot1cmdh.fd) Now type a test command (\help for help):
39*\text
40
41*\bye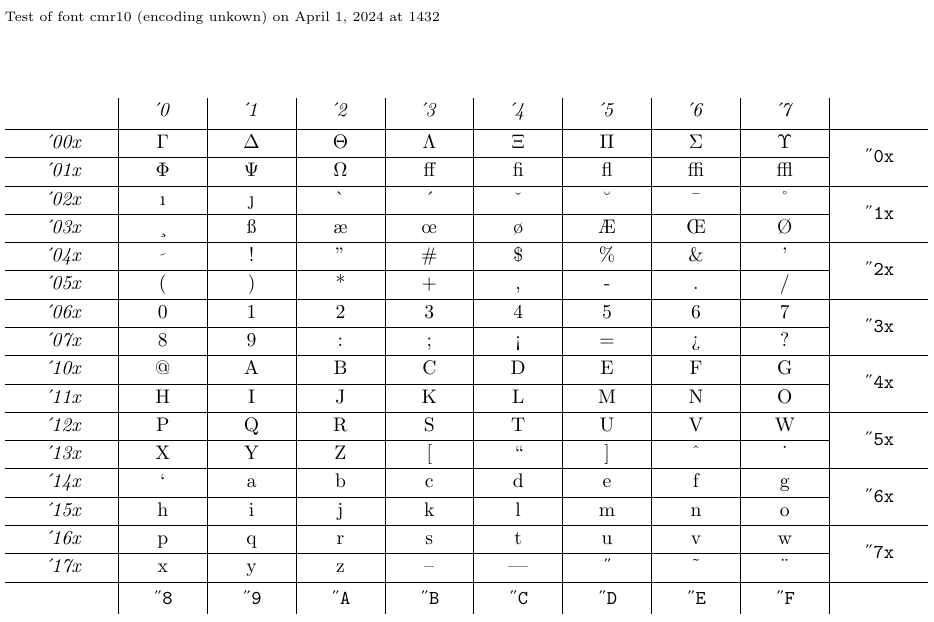

注意すべき点が二つあります。第一に、
nfssfont.texプログラムは暗黙の\initコマンドを実行するため、最初の入力行はフォント名を含むか、NFSS の分類を示すために完全に空にする必要があります。第二に、\initの入力はコメントすら入れずに単独の行で行わなければなりません。これはFont encoding[T1]: \encoding=のようなプロンプトの行末が入力の終端とみなされるためです。