7. Modelo do LATEX para codificações de personagens
Este artigo abrange as codificações de LaTeX em detalhes. Começa com uma discussão sobre o fluxo de dados do caractere dentro do sistema de LaTeX. Em seguida, examinamos mais de perto o modelo de representação interna dos dados de caracteres no LATEX, seguido de uma discussão sobre os mecanismos usados para mapear dados recebidos por meio de codificações de entrada nessa representação interna. Finalmente, explicamos como a representação interna é traduzida, através das codificações de saída, para o formulário necessário para o tipógrafo.
7.1. O fluxo de dados de caracteres dentro do LaTeX
O processamento de um documento com o LaTeX é iniciado interpretando os dados presentes em um ou mais arquivos de origem. Esses dados que representam o conteúdo do documento são armazenados em arquivos de origem como sequências de octetos que representam caracteres. Para interpretar corretamente esses octetos, qualquer programa (incluindo LaTeX) usado para processar o arquivo deve conhecer o mapeamento entre caracteres abstratos e os octetos que os representam. Em outras palavras, ele deve saber a codificação usada quando o arquivo foi escrito.
Com um mapeamento incorreto, todo o processamento adicional será mais ou menos errado, a menos que o arquivo contenha apenas caracteres de um subconjunto comum nas codificações corretas e incorretas. O LATEX faz uma suposição fundamental neste momento: quase todos os caracteres ASCII visíveis (decimal 32-126) são representados pelo número que eles têm na tabela de código ASCII.

Uma razão para essa suposição é que a maioria das codificações de 8 bits em uso hoje compartilham um plano comum de 7 bits. Outro motivo é que, para usar efetivamente o TEX, a maioria da parte visível do ASCII precisa ser processada como caracteres da categoria letter - Como apenas caracteres com essa categoria pode ser usada em nomes de comandos de múltiplos caracteres em Tex - ou categoria other - Como o TEX não, por exemplo, reconhece o código de decimal como parte de um número de um número de um número, se não o fizerem
Quando um caractere (ou, mais precisamente, um número de 8 bits) é declarado como de categoria letter ou * outro * em Tex, esse número de 8 bits será transparentemente passado pelo Tex. Isso significa que a Tex digitará qualquer símbolo na fonte na posição abordada por esse número.
Como conseqüência da suposição mencionada acima, as fontes destinadas a serem usadas para o texto geral exigem que (a maioria) os caracteres ASCII visíveis estejam presentes na fonte e codificados de acordo com a codificação ASCII.
Todos os outros números de 8 bits (aqueles fora do ASCII visível) potencialmente presentes no arquivo de entrada recebem um código de categoria de active, o que os leva a agir como comandos dentro do Tex. Portanto, o LATEX pode transformá -los através das codificações de entrada em uma forma que chamaremos de representação de caracteres interna (LICR) *do LATEX *.
Quanto à codificação UTF8 da Unicode, ela é tratada da mesma forma. Os caracteres ASCII se representam, e os octetos iniciais para representação de vários bytes atuam como caracteres ativos que examinam a entrada dos octetos restantes. O resultado será transformado em um objeto no LICR se for mapeado, ou o LATEX lançará um erro se o caractere unicode fornecido não for mapeado.
A coisa mais importante sobre os objetos no LICR é que a representação de caracteres ASCII de 7 bits é invariante para qualquer mudança de codificação, porque todas as codificações de entrada devem ser transparentes em relação ao ASCII visível. As codificações de saída (ou fonte) servem para mapear as representações de caracteres internas para as posições de glifos na fonte atual usada para digitar ou, em alguns casos, iniciar ações mais complexas. Por exemplo, pode colocar um sotaque (presente em uma posição na fonte atual) sobre algum símbolo (em uma posição diferente na fonte atual) para obter uma imagem impressa do caractere abstrato representado pelo (s) comando (s) na codificação de caracteres internos.
O LICR codifica todos os caracteres possíveis endereçáveis no LATEX. Assim, é muito maior que o número de caracteres que podem ser representados por uma única fonte Tex (que pode conter no máximo 256 glifos). Em alguns casos, um personagem na codificação interna pode ser renderizado com uma fonte combinando glifos, como caracteres acentuados. No entanto, quando o caractere interno requer uma forma especial, não há como fingir que esse glifo não estiver presente na fonte.
No entanto, o modelo do LateX para codificações de caracteres suporta mecanismos automáticos para buscar glifos de diferentes fontes, de modo que os caracteres ausentes na fonte atual obtenham o Typeset, desde que uma fonte adicional adequada contenda -as.
7.2. Representação de personagens internos do LATEX (LICR)
Os caracteres de texto são representados internamente pelo LaTeX de uma de três maneiras.
Representação como caracteres
Um pequeno número de caracteres é representado por “eles mesmos”. Por exemplo, o latim a é representado como o personagem ‘A’. Tais caracteres são mostrados na tabela acima. Eles formam um subconjunto de ASCII visível e, dentro do Tex, todos eles recebem o código de categoria de *letra *ou *outro *. Alguns caracteres da faixa ASCII visível não estão representados dessa maneira, nem porque fazem parte da sintaxe Tex ou porque não estão presentes em todas as fontes. Se alguém usa, por exemplo, ‘<’ no texto, a codificação atual da fonte determina se um fica < (t1) ou talvez um ponto de exclamação invertido (ot1) na saída impressa.
Representação como seqüências de personagens
O mecanismo interno da ligadura da TEX pode gerar novos caracteres a partir de uma sequência de caracteres de entrada. Na verdade, essa é uma propriedade da fonte, embora algumas dessas seqüências tenham sido explicitamente projetadas para servir como atalhos de entrada para caracteres que, de outra forma, são difíceis de abordar com a maioria dos teclados. Apenas alguns caracteres gerados dessa maneira são considerados como pertencentes à representação interna do LATEX. These include the en dash and em dash, which are generated by the ligatures --and ---, and the opening and closing double quotes, which are generated by ``and '' (the latter can usually also be represented by the single "). While most fonts also implement !`and ``` ? Para gerar exclamação invertida e pontos de interrogação, isso não está universalmente disponível em todas as fontes.
Representação como comandos “específicos para codificação de fontes”
A terceira maneira de representar caracteres internamente no LATEX, que abrange a maioria dos caracteres, é com comandos especiais de LaTex (ou sequências de comando) que permanecem não especiais quando gravados em um arquivo ou quando colocados em um argumento em movimento. Vamos nos referir a comandos especiais como comandos * de codificação de fontes * porque seu significado depende da codificação da fonte atualmente usada quando o LATEX estiver pronto para digitá-los. Tais comandos são declarados usando declarações especiais, como discutiremos abaixo, que geralmente exigem definições individuais para cada codificação da fonte. Se não houver definição para a codificação atual, um padrão será usado (se disponível) ou uma mensagem de erro será apresentada ao usuário.
Quando a codificação da fonte é alterada em algum momento do documento, as definições dos comandos específicos de codificação não mudam imediatamente, pois isso significaria alterar um grande número de comandos no local. Em vez disso, esses comandos são implementados de tal maneira que, uma vez usados, eles percebem se sua definição atual não for mais adequada para a codificação da fonte em vigor. Nesse caso, eles chamam seus colegas na fonte atual que codifica para fazer o trabalho real.
O conjunto de comandos específicos de codificação de fontes não é corrigido, mas é implicitamente definido como a união de todos os comandos definidos para codificações de fontes individuais. Assim, novos comandos específicos de codificação de fontes podem ser necessários quando novas codificações de fontes forem adicionadas ao LATEX.
7.3. Codificação de entrada
Depois que o pacote inputenc for carregado, as duas declarações \declararInputText e \declararInputMath para mapear caracteres de entrada de 8 bits para objetos LICR estão disponíveis. Eles devem ser usados apenas na codificação de arquivos (veja abaixo), pacotes ou, se necessário, no preâmbulo do documento.
Esses comandos assumem um número de 8 bits como seu primeiro argumento, que pode ser dado como um número decimal, número octal ou notação hexadecimal. O uso da notação decimal é recomendado, pois os caracteres ' e/ou " podem obter significados especiais em um pacote de suporte ao idioma, como atalhos para sotaques, fazendo com que os pacotes octa e/ou hexadecimal inválidos se forem carregados na ordem errada.
1\DeclareInputText{number}{LICR-object}O comando \declarainputText declara mapeamentos de caracteres para uso no texto. Seu segundo argumento contém o comando específico da codificação (ou sequência de comando), que são os objetos LICR para os quais o número do caractere deve ser mapeado. Por exemplo,
1\DeclareInputText{239}{\"\i}Mapas o número 239 para a representação específica da codificação do’ i-unslaut ‘, que é \ "\i. Os caracteres de entrada declarados dessa maneira não podem ser usados nas fórmulas matemáticas.
1\DeclareInputMath{number}{math-object}Se o número representar um caractere para uso em fórmulas matemáticas, a declaração \declarainputMath deverá ser usada. Por exemplo, na codificação de entrada cp437de (teclado alemão ms-dos),
1\DeclareInputMath{224}{\alpha}mapeia o número 224 para o comando \alpha. É importante observar que essa declaração tornaria a chave produzir esse número utilizável apenas no modo de matemática, pois \alpha não é permitido em nenhum outro lugar.
1\DeclareUnicodeCharacter{hex-number}{LICR-object}Esta declaração está disponível apenas se a opção utf8 for usada. Ele mapeia números unicode para objetos LICR (ou seja, caracteres utilizáveis em texto). Por exemplo,
1\DeclareUnicodeCharacter{00A3}{\textsterling}
2\DeclareUnicodeCharacter{011A}{\v E}
3\DeclareUnicodeCharacter{2031}{\textpertenthousand}Em teoria, deve haver apenas um mapeamento bidirecional exclusivo entre os dois espaços, para que todas essas declarações já pudessem ser feitas automaticamente quando a opção utf8 for selecionada. Na prática, as coisas são um pouco mais complicadas. Em primeiro lugar, fornecer a tabela inteira automaticamente exigiria uma enorme quantidade de memória do Tex. Além disso, existem muitos caracteres Unicode para os quais não existe um objeto LICR e, inversamente, muitos objetos LICR não têm equivalente no Unicode. Esse problema é resolvido no pacote inputenc, carregando apenas os mapeamentos Unicode que correspondem às codificações usadas em um documento específico (até onde são conhecidas) e respondendo a qualquer outra solicitação de um caractere unicode com uma mensagem de erro adequada. Torna -se então a tarefa do usuário fornecer as informações de mapeamento correto ou, se necessário, carregar uma codificação adicional de fonte.
Como mencionamos acima, as declarações de codificação de entrada podem ser usadas em pacotes ou no preâmbulo do documento. Para fazer tudo funcionar dessa maneira, é importante carregar o pacote inputencprimeiro, selecionando assim uma codificação adequada. As declarações subsequentes de codificação de entrada atuarão como um substituto para (ou adição a) aquelas definidas pela presente codificação de entrada.
Ao utilizar o pacote inputenc, poderá ver o comando \@tabacckludge, que significa “acento de tabulação”. É necessário porque a versão actual do LaTeX herdou uma sobrecarga dos comandos \=, \` e \', que normalmente denotam determinados acentos (i.e., são comandos específicos da codificação), mas têm significados especiais dentro do ambiente tabbing. É por isso que os mapeamentos que envolvem qualquer um destes acentos precisam de ser codificados de uma forma especial. Por exemplo, se pretender mapear 232 para o caractere ’e-grave’ (que tem a representação interna \`e), deve escrever.
1\DeclareInputText{232}{\@tabacckludge`e}em vez de
1\DeclareInputText{232}{\`e}Mapeamento para texto e/ou matemática
Por razões técnicas e conceituais, a Tex faz uma distinção muito forte entre os personagens que podem ser usados no texto e em matemática. Exceto por caracteres ASCII visíveis, os comandos que produzem caracteres normalmente podem ser usados no modo de texto ou matemática, mas não nos dois modos.
Entrada de arquivos de codificação para codificações de 8 bits
As codificações de entrada são armazenadas em arquivos com a extensão .def, onde o nome base é o nome da codificação de entrada (por exemplo, latin1.def). Esses arquivos devem conter apenas os comandos discutidos na seção atual.
O arquivo deve iniciar com uma linha de identificação que contém o comando \fornecefile, descrevendo a natureza do arquivo. Por exemplo:
1\ProvidesFile{latin1.def}[2000/07/01 v0.996 Input encoding file]Se houver mapeamentos para codificar comandos específicos que podem não estar disponíveis, a menos que pacotes adicionais sejam carregados, é possível declarar padrões para eles usando \proveteTextCommandDefault. Por exemplo:
1\ProvideTextCommandDefault{\textonehalf}{\ensurement{\frac12}}
2\ProvideTextCommandDefault{\textcent}{\TextSymbolUnavailable\textcent}O comando \textsymbolunavilable emite um aviso indicando que um determinado caractere não está disponível com as fontes atualmente usadas. Isso pode ser útil como padrão quando esses caracteres estiverem disponíveis apenas se as fontes especiais forem carregadas e não houver uma maneira adequada de falsificar os caracteres com caracteres existentes (como era possível para um padrão para \textOneHalf).
O restante do arquivo deve incluir apenas as declarações de codificação de entrada \declararInputText e \declarainputMath. Como mencionado acima, o uso deste último comando é desencorajado, mas permitido. Nenhum outro comandos deve ser usado dentro de um arquivo de codificação de entrada, em particular, sem comandos que impedem a leitura do arquivo várias vezes (por exemplo, \newCommand), pois os arquivos de codificação são frequentemente carregados várias vezes em um único documento.
Arquivos de mapeamento de entrada para UTF8
Como mencionado anteriormente, o mapeamento do Unicode para os objetos LICR é organizado de uma maneira que permita que o LATEX carregue apenas os mapeamentos relevantes para as codificações de fontes usadas no documento atual. Isso é feito tentando carregar para cada codificação <name> um arquivo <name> Enc.dfu que, se existe, contém as informações de mapeamento para os caracteres unicode fornecidos por essa codificação em particular. Além de várias declarações \declararunicodecharacter, esses arquivos devem incluir apenas uma linha \fornecefile.
Como diferentes codificações de fontes geralmente fornecem mais ou menos os mesmos caracteres, é bastante comum as declarações para o mesmo caractere unicode aparecer em diferentes arquivos .dfu. Portanto, é muito importante que essas declarações em diferentes arquivos sejam idênticas. Caso contrário, a declaração carregada por último sobreviverá, o que pode ser diferente do documento para o documento.
Portanto, quem deseja fornecer um novo arquivo .dfu para alguma codificação que anteriormente não foi coberta deve verificar cuidadosamente as definições existentes nos arquivos .dfu para codificações relacionadas. Os arquivos padrão fornecidos com inputenc têm garantia de ter definições uniformes. Na verdade, todos eles são gerados a partir de uma única lista que é adequadamente dividida. Uma lista completa dos mapeamentos atualmente existentes pode ser encontrada no arquivo utf8enc.dfu.
7.4. Codificações de saída
Já mencionamos que as codificações de saída definem o mapeamento do LICR para os glifos (ou construções construídas a partir de glifos) disponíveis nas fontes usadas para o tipo de tipo de tipo. Esses mapeamentos são referenciados dentro do LaTeX por nomes de duas ou três letras (por exemplo, ot1 e t3). Dizemos que uma certa fonte está em uma certa codificação se o mapeamento corresponde às posições dos glifos na fonte. Vamos agora dar uma olhada nos componentes exatos de tal mapeamento.
Os caracteres representados internamente por caracteres ASCII são simplesmente transmitidos para a fonte. Em outras palavras, o TEX usa o código ASCII para selecionar um glifo na fonte atual. Por exemplo, o caractere ‘A’ com o Código ASCII 65 resultará na digitação do glifo na posição 65 na fonte atual. É por isso que o LATEX exige fontes para que o texto contenha todas essas letras ASCII em suas posições de código ASCII, pois não há como interagir com esse mecanismo Tex básico. Portanto, para o ASCII visível, um mapeamento individual está implicitamente presente em todas as codificações de saída.
Os caracteres representados internamente como sequências de caracteres ASCII (por exemplo, “ -- “) são tratados da seguinte forma: quando a fonte atual é carregada pela primeira vez, o TEX é informado de que a fonte contém vários programas de ligadura. Esses programas definem certas seqüências de caracteres que não devem ser digitadas diretamente, mas para serem substituídas por outros glifos da fonte. Por exemplo, quando a Tex encontra “-” na entrada (ou seja, código ASCII 45 duas vezes), um programa de ligadura pode direcioná-lo para o glifo na posição 123 (que seguraria o glifo EN Dash). Novamente, não há como interagir com esse mecanismo.
No entanto, a maior parte da representação interna do caractere consiste em comandos específicos de codificação de fontes que são mapeados usando as declarações descritas abaixo. Todas as declarações têm a mesma estrutura nos dois primeiros argumentos: o comando específico para codificação de fontes (ou o primeiro componente dele, se for uma sequência de comando), seguido pelo nome da codificação. Quaisquer argumentos restantes dependerão do tipo de declaração.
Portanto, um codificação xyz é definido por um monte de declarações, todas com o nome xyz como seu segundo argumento. Então, é claro, algumas fontes devem ser codificadas nessa codificação. De fato, o desenvolvimento das codificações de fontes é normalmente feito de maneira reversa - alguém começa com uma fonte existente e fornece declarações apropriadas para usá -la. Esta coleção de declarações recebe um nome adequado, como ot1. Abaixo, levaremos a fonte ecrm1000 (consulte o gráfico de glifos), cuja codificação de fontes é chamada T1 no LaTeX, e construir declarações apropriadas para acessar os glifos de uma fonte codificada dessa maneira. Os caracteres azuis no gráfico de glifos são aqueles que devem estar presentes na mesma posição em todos os textos que codificam, pois são transparentemente passados pelo LaTeX.
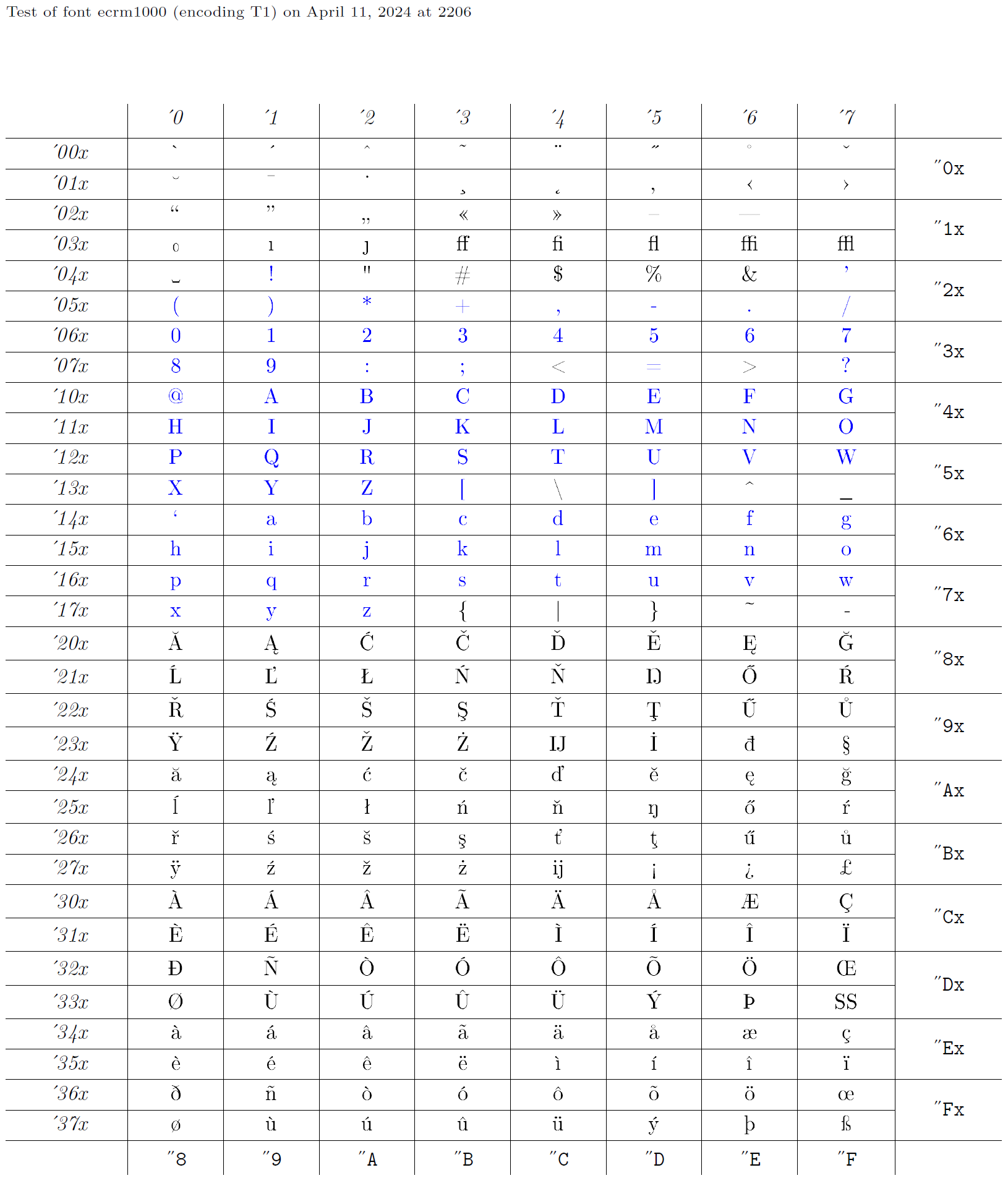
Saída de arquivos de codificação
Os arquivos de codificação de saída são identificados pela mesma extensão .def que os arquivos de codificação de entrada. No entanto, o nome base do arquivo é um pouco mais estruturado. Consiste no nome da codificação em letras minúsculas, seguidas por enc (por exemplo, t1enc.def para a codificação t1).
Esses arquivos devem incluir apenas declarações descritas na seção atual. Como os arquivos de codificação de saída podem ser lidos várias vezes pelo LATEX, é importante seguir esta regra e abster -se de usar, por exemplo, \newCommand, que impede a leitura desse arquivo mais de uma vez!
Novamente, um arquivo de codificação de saída começa com uma linha de identificação que descreve a natureza do arquivo. Por exemplo:
1\ProvidesFile{t1enc.def}[2001/06/05 v1.94 Standard LaTeX file]Antes de declararmos quaisquer comandos específicos de codificação para uma codificação específica, primeiro precisamos divulgar essa codificação pelo LaTeX. Isso é feito através do comando \declararFonteCoding. Neste ponto, também é útil declarar as regras de substituição padrão para a codificação. Podemos fazê -lo usando o comando \declarafontsubstitution. Ambas as declarações são discutidas em detalhes em
como configurar novas fontes.
1\DeclareFontEncoding{T1}{}{}
2\DeclareFontSubstitution{T1}{cmr}{m}{n}Agora que introduzimos a codificação T1 no LATEX dessa maneira, podemos prosseguir com a declaração de como os comandos específicos de codificação de fontes devem se comportar nessa codificação.
1\DeclareTextSymbol{LICR-Object}{encoding}{slot}A declaração para símbolos de texto parece ser a mais simples. Aqui, a representação interna pode ser mapeada diretamente para um único glifo na fonte de destino. Isso é conseguido usando a declaração \decLarEtextSymbol, cujo terceiro argumento - a posição do glifo - pode ser dado como um número decimal, octal ou hexadecimal. Por exemplo,
1\DeclareTextSymbol{\ss}{T1}{255}
2\DeclareTextSymbol{\AE}{T1}{'306} %font position as octal number
3\DeclareTextSymbol{\ae}{T1}{"E6} %...as hexadecimal numberDeclare que os comandos específicos de codificação de fontes \ss, \ae e \ae devem ser mapeados para as posições (decimais) 255, 198 e 230, respectivamente, em uma fonte cegada T1. Como mencionamos acima, é mais seguro usar a notação decimal em tais declarações. De qualquer forma, misturar notações como no exemplo anterior é certamente um estilo ruim.
1\DeclareTextAccent{LICR-accent}{encoding}{slot}As fontes geralmente contêm marcas diacríticas como glifos individuais para permitir a construção de caracteres acentuados, combinando uma marca diacrítica com algum outro glifo. Tais sotaques (desde que sejam colocados em cima de outros glifos) são declarados usando o comando \decLareTextaccent. O terceiro argumento, slot, é a posição da marca diacrítica na fonte. Por exemplo,
1\DeclareTextAccent{\"}{T1}{4}define o sotaque “umlaut”. A partir desse ponto, uma representação interna como \" A tem o seguinte significado na codificação T1: typeet ‘a com umlaut’, colocando o sotaque na posição 4 sobre os glifos na posição 97 (o código ASCII do caracterea). Essa declaração é, em fato, implicitamente range de um enorme \" \declareTextSymbol ou qualquer caractere ASCII pertencente ao LICR, como ‘a’.
Mesmo aquelas combinações que não fazem muito sentido, como \" \ p (ou seja, sinal de pilcrow com umlaut), se tornam conceitualmente membros do conjunto de comandos específicos de codificação de fontes dessa maneira.
1\DeclareTextComposite
2 {LICR-accent}{encoding}{simple-LICR-object}{slot}O gráfico de glifos acima contém um grande número de caracteres acentuados como glifos individuais - por exemplo, ‘a com umlaut’ na posição '240 octal. Assim, em t1, o comando específico da codificação \ "a não deve resultar na colocação de um sotaque sobre o personagem ‘a’, mas deve acessar diretamente o glifo nessa posição da fonte. Isso é alcançado pela declaração
1\DeclareTextComposite{\"}{T1}{a}{228}que afirma que o comando específico da codificação \" a resulta em digitar o glifo 228, desativando assim a declaração de sotaque acima. Para todos os outros comandos específicos da codificação que começam com \" , a declaração de sotaque permanece em vigor. Por exemplo, \" b produzirá A ‘B com umlaut’, colocando um sotaque sobre o glifo base ‘B’.
O terceiro argumento, *simples-licr-object *, deve ser uma única letra, como ‘a’ ou um único comando, como \j ou \ oe.
1\DeclareTextCompositeCommand
2 {LICR-object}{encoding}{simple-LICR-object}{code}Embora não seja usado para a codificação T1, também existe uma versão mais geral de \ DecLareTextComposite, que permite o código arbitrário no lugar de uma posição de slot. Isso é usado, por exemplo, na codificação ot1 para diminuir o sotaque do anel sobre o ‘A’ em comparação com a maneira como seria com o tipógrafo com o \ \ accent da TEX. Os sotaques sobre o ’eu’ também são implementados usando esta forma de declaração:
1\DeclareTextCompositeCommand{\'}{OT1}{i}{\@tabacckludge'\i}
2\DeclareTextCompositeCommand{\^}{OT1}{i}{\^\i}Várias marcas diacríticas não são colocadas em cima de outros caracteres, mas colocados em algum lugar abaixo deles. Não existe um formulário de declaração especial para essas marcas, pois o posicionamento real do sotaque envolve o código TEX de baixo nível. Em vez disso, o genérico \decLareTextCommand pode ser usado para esse fim.
1\DeclareTextCommand{LICR-object}{encoding}[num][default]{code}Por exemplo, o sotaque ‘Underbar’ \b na codificação T1 é definido com o seguinte código:
1\DeclareTextCommand{\b}{T1}[1]
2 {\hmode$bgroup\o$lign{\relax#1\crcr\hidewidth\sh$ft{29}%
3 \vbox to.2ex{\hbox{\char9}\vss}\hidewidth}\egroup}Nesta discussão, não importa muito o que o código significa exatamente, mas podemos ver que \declareTextCommand é semelhante a \newCommand de certa forma. Ele possui um argumento opcional * num * que denota o número de argumentos (um aqui), um segundo argumento opcional * padrão * (não presente aqui) e um argumento obrigatório final que contém o código no qual é possível consultar os argumentos usando (s) usando #1, #2 e assim por diante.
\declareTextCommand também pode ser usado para criar comandos específicos de codificação de fontes que consistem em uma única sequência de controle. Nesse caso, é usado sem o argumento opcional, definindo um comando com zero argumentos. Por exemplo, em t1, não há glifo para um sinal de ‘por mil’, mas há um pouco de ‘o’ na posição'30, que, se colocado diretamente atrás de um ‘%’, dará o glifo apropriado. Assim, podemos fornecer as seguintes declarações:
1\DeclareTextCommand{\textperthousand} {T1}{\%\char 24}
2\DeclareTextCommand{\textpertenthousand}{T1}{\%\char 24\char 24 }Agora, abordamos todos os comandos necessários para declarar os comandos específicos de codificação de fontes para uma nova codificação. Como já dissemos, apenas esses comandos devem estar presentes na codificação de arquivos de definição.
Padrões de codificação de saída
Vamos ver agora o que acontece se um comando específico de codificação, para o qual não houver declaração na codificação atual da fonte, for usada. Nesse caso, uma das duas coisas pode acontecer: o LATEX possui uma definição padrão para o objeto LICR; nesse caso, esse padrão é usado ou uma mensagem de erro é emitida afirmando que o objeto LICR solicitado não está disponível na codificação atual. Existem várias maneiras de configurar padrões para objetos LICR.
1\DeclareTextCommandDefault{LICR-object}[num][default]{code}O comando \decLarETEXTCommandDefault fornece a definição padrão para um Licr-Object ser usado sempre que não houver uma configuração específica para um objeto na codificação atual. Tais definições podem, por exemplo, falsificar um certo personagem. Por exemplo, \textregistered tem uma definição padrão na qual o personagem é construído a partir de outros dois, assim:
1\DeclareTextCommandDefault{\textregistered}{\textcircled{\scshape r}}Tecnicamente, as definições padrão são armazenadas como uma codificação com o nome ?. Embora você não deva confiar nesse fato, pois a implementação pode mudar no futuro, isso significa que você não pode declarar uma codificação com esse nome.
1\DeclareTextSymbolDefault{LICR-object}{encoding}Na maioria dos casos, uma definição padrão não requer codificação, mas simplesmente ordena que o LaTeX retire o personagem de alguma codificação em que se sabe existir. O pacote textComp, por exemplo, contém um grande número de declarações padrão que apontam para a codificação TS1. Por exemplo:
1\DeclareTextSymbolDefault{\texteuro}{TS1}O comando \decLarETEXTSyMBOLDefault pode ser usado para definir o padrão para qualquer objeto LICR sem argumentos, não apenas aqueles declarados com o comando \ DecLarEtextSymbol em outras codificações.
1\DeclareTextAccentDefault{LICR-accent}{encoding}Há uma declaração semelhante para objetos LICR que assumem um argumento, como sotaques. Novamente, este formulário é utilizável para qualquer objeto LICR com um argumento. O kernel do LaTeX, por exemplo, contém várias declarações do tipo:
1\DeclareTextAccentDefault{\"}{OT1}
2\DeclareTextAccentDefault{\t}{OML}Isso significa que, se o \" não estiver definido na codificação atual, use o de uma fonte codificada por ot1. Da mesma forma, para obter um sotaque de gravata, pegue-o de oml, se nada melhor estiver disponível.
1\ProvideTextCommandDefault{LICR-object}[num][default]{code}A declaração \proveTextCommandDefault permite” fornecer “outro tipo de inadimplência. Ele faz o mesmo trabalho que a declaração \decLareTextCommandDefault, exceto que o padrão é fornecido apenas se nenhum padrão tive sido definido antes. Isso é usado principalmente em arquivos de codificação de entrada para fornecer algum tipo de inadimplência trivial para objetos LICR incomuns. Por exemplo:
1\ProvideTextCommandDefault{\textonequarter}{\ensuremath{\frac14}}
2\ProvideTextCommandDefault{\textcent}{\TextSymbolUnavailable\textcent}Pacotes como textcomp podem substituir essas definições por declarações apontando para glifos reais. Usando \forneceu ... em vez de \declarar ... garante que um melhor padrão não seja substituído acidentalmente se o arquivo de codificação de entrada for lido.
1\UndeclareTextCommand{LICR-object}{encoding}Em alguns casos, uma declaração existente precisa ser removida para garantir que uma declaração padrão seja usada. Isso pode ser feito usando o \UndeclareTextCommand. Por exemplo, o pacote textComp remove as definições de \textDollar e \textsterling da codificação ot1, porque nem toda fonte codificada por ot1 realmente tem esses símbolos.
1\UndeclareTextCommand{\textsterling}{OT1}
2\UndeclareTextCommand{\textdollar} {OT1}Sem essa remoção, as novas declarações padrão para pegar os símbolos de ts1 não seriam usados para fontes codificadas com ot1.
1\UseTextSymbol{encoding}{LICR-object}
2\UseTextAccent{encoding}{LICR-object}{simple-LICR-object}A ação oculta por detrás das declarações \DeclareTextSymbolDefault e \DeclareTextAccentDefault também pode ser utilizada diretamente. Suponhamos, por exemplo, que a codificação actual é U. Nesse caso,
1\UseTextSymbol{OT1}{\ss}
2\UseTextAccent{OT1}{\'}{a}tem o mesmo efeito que inserir o código abaixo. Observe, em particular, que o a é compensado na codificação u - apenas o sotaque é retirado da outra codificação.
1{\fontencoding{OT1}\selectfont\ss}
2{\fontencoding{OT1}\selectfont\'{\fontendcoding{U}\selectfont a}}Uma lista de objetos LICR padrão
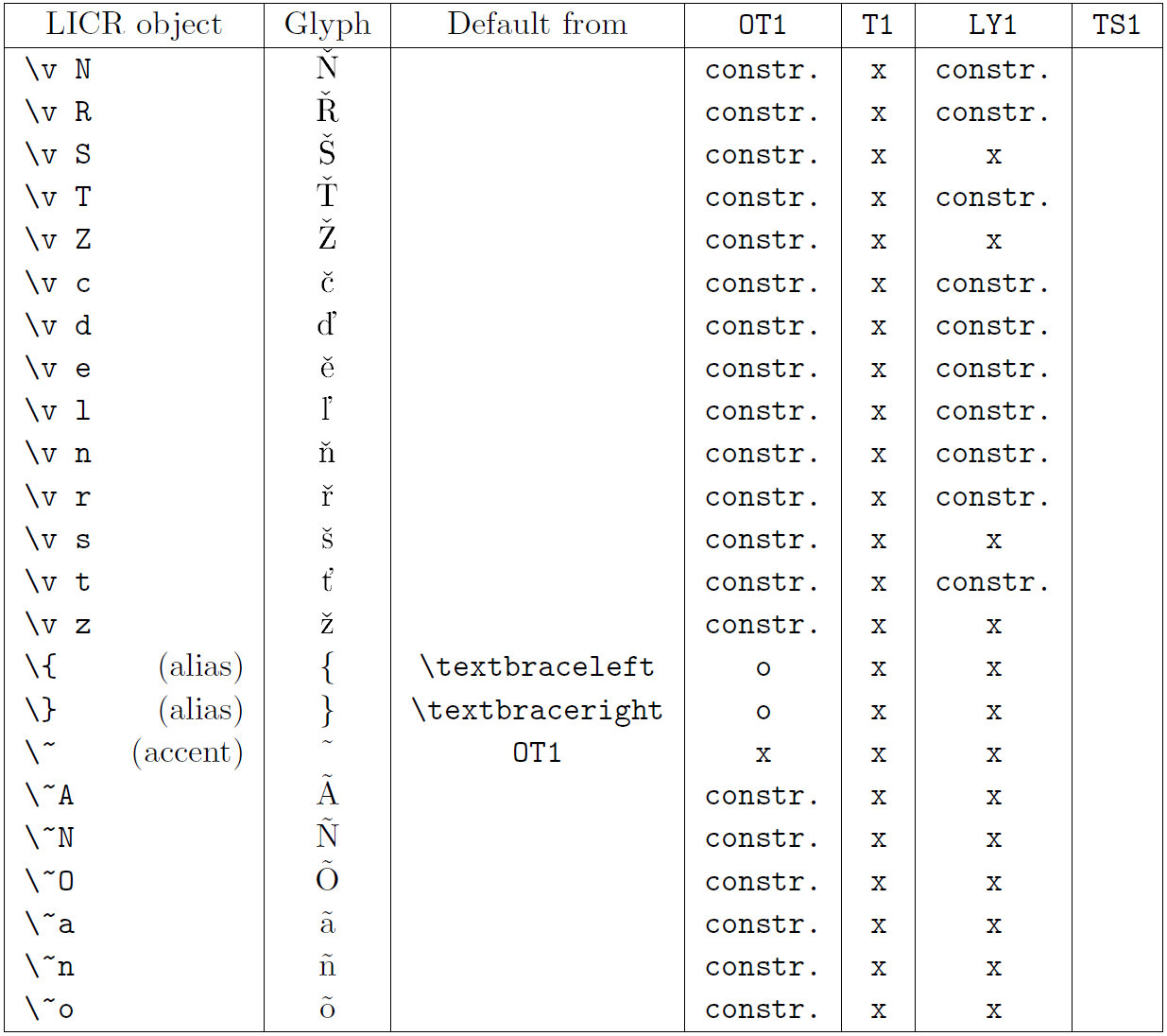
A tabela nesta subseção fornece uma visão geral das representações internas do LaTeX disponíveis com as três principais codificações para os idiomas latinos: ot1 (a codificação Tex original), t1 (o padrão de LaTeX codificação) e ly1 (um alternativo de 8 bits codificando proposto por y & y). Além disso, ele mostra todos os objetos LICR declarados por TS1 (o símbolo de texto padrão do LATEX codificando) fornecido carregando o pacote textcomp.
A primeira coluna da tabela mostra os nomes de objetos LICR em ordem alfabética, indicando quais objetos LICR agem como sotaques. A segunda coluna mostra uma representação de glifo do objeto.
A terceira coluna descreve se o objeto tem uma declaração padrão. Se uma codificação estiver listada, significa que, por padrão, o glifo está sendo buscado a partir de uma fonte adequada nessa codificação; Constr. significa que o padrão é produzido a partir do código TEX de baixo nível; Se a coluna estiver vazia, significa que nenhum padrão será definido para este objeto LICR. No último caso, um erro de “símbolo indisponível” é retornado quando você o usa em uma codificação para a qual não possui uma definição explícita. Se o objeto for um alias para algum outro objeto LICR, o nome alternativo será listado nesta coluna.
Colunas quatro a sete show se um objeto está disponível na codificação especificada. Aqui, ‘x’ significa que o objeto está disponível nativamente (como um glifo) em fontes com a codificação, ‘O’ significa que ele está disponível através do padrão para todas as codificações e constr. Se o padrão for buscado no ts1, o objeto LICR estará disponível apenas se o pacote textComp for carregado.
Objetos Licr. Parte 1
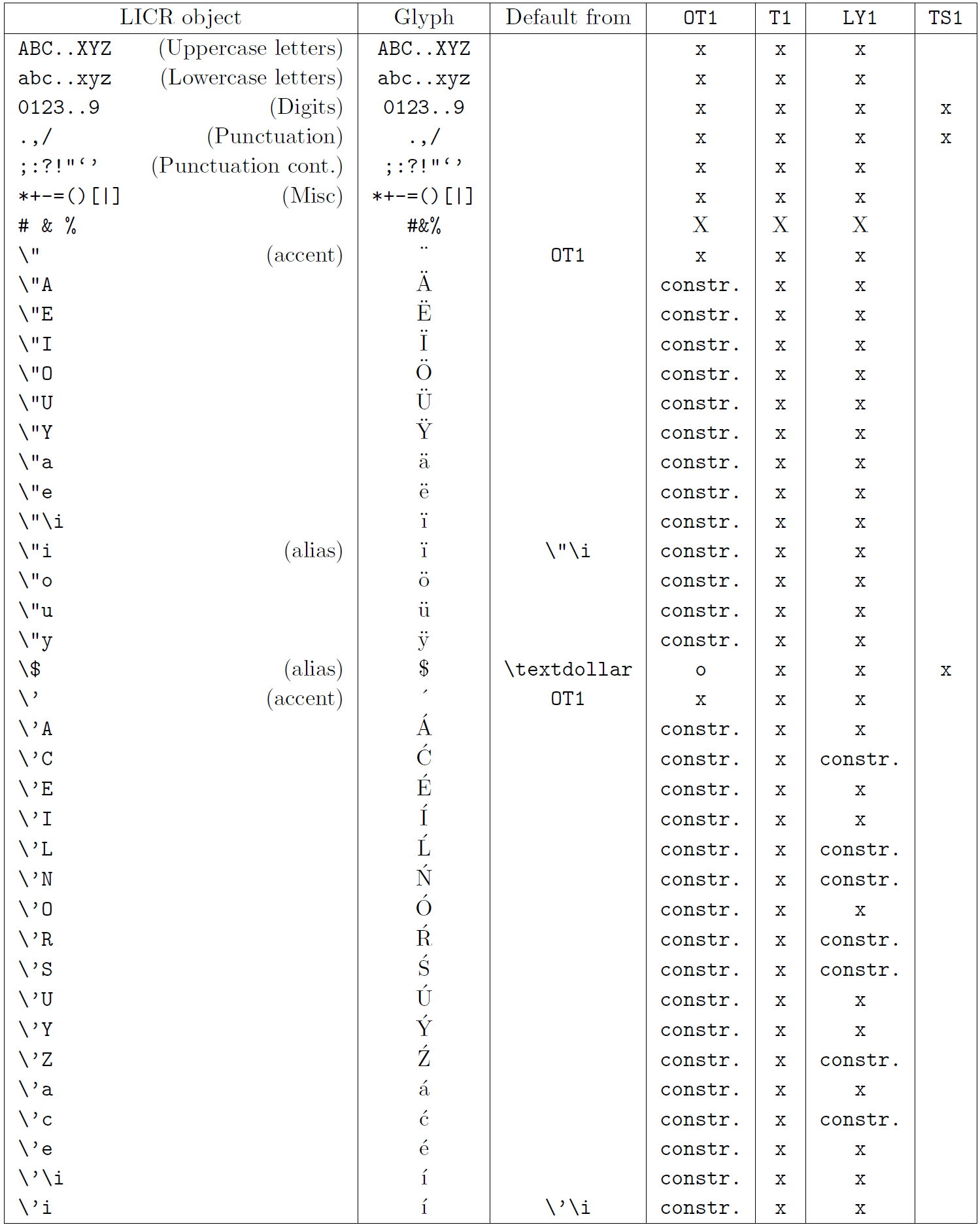
Objetos Licr. Parte 2
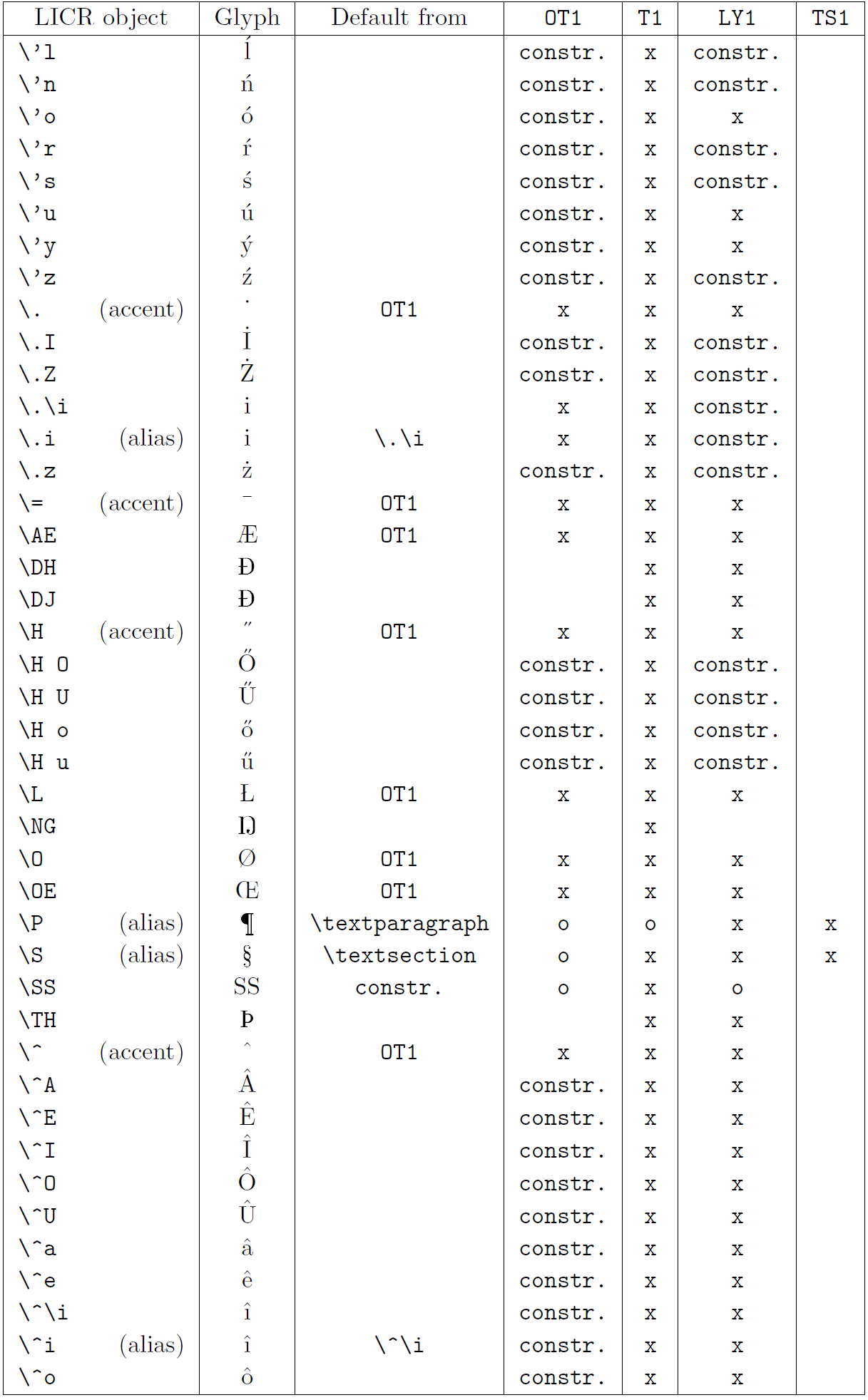
Objetos Licr. Parte 3
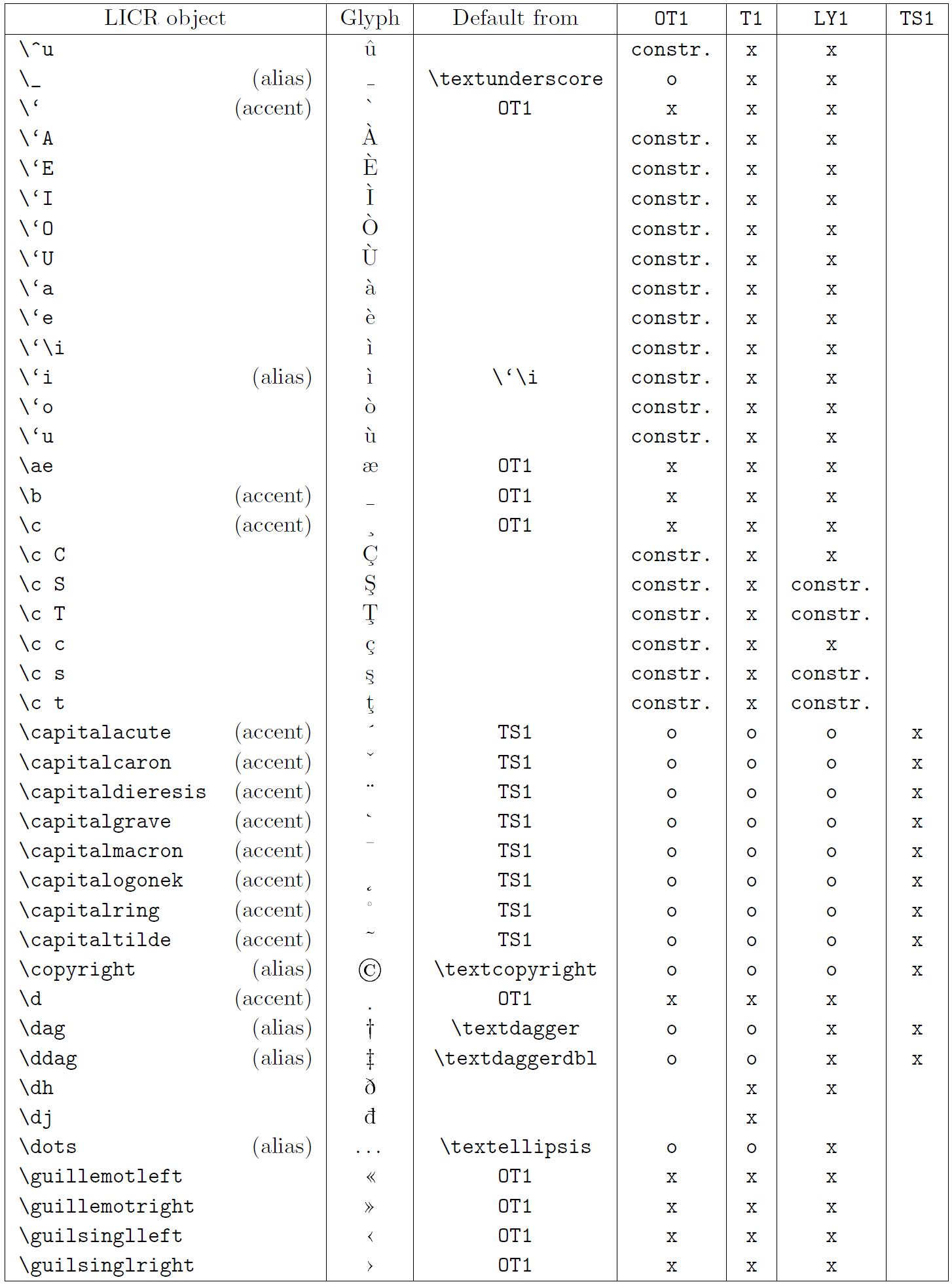
Objetos Licr. Parte 4
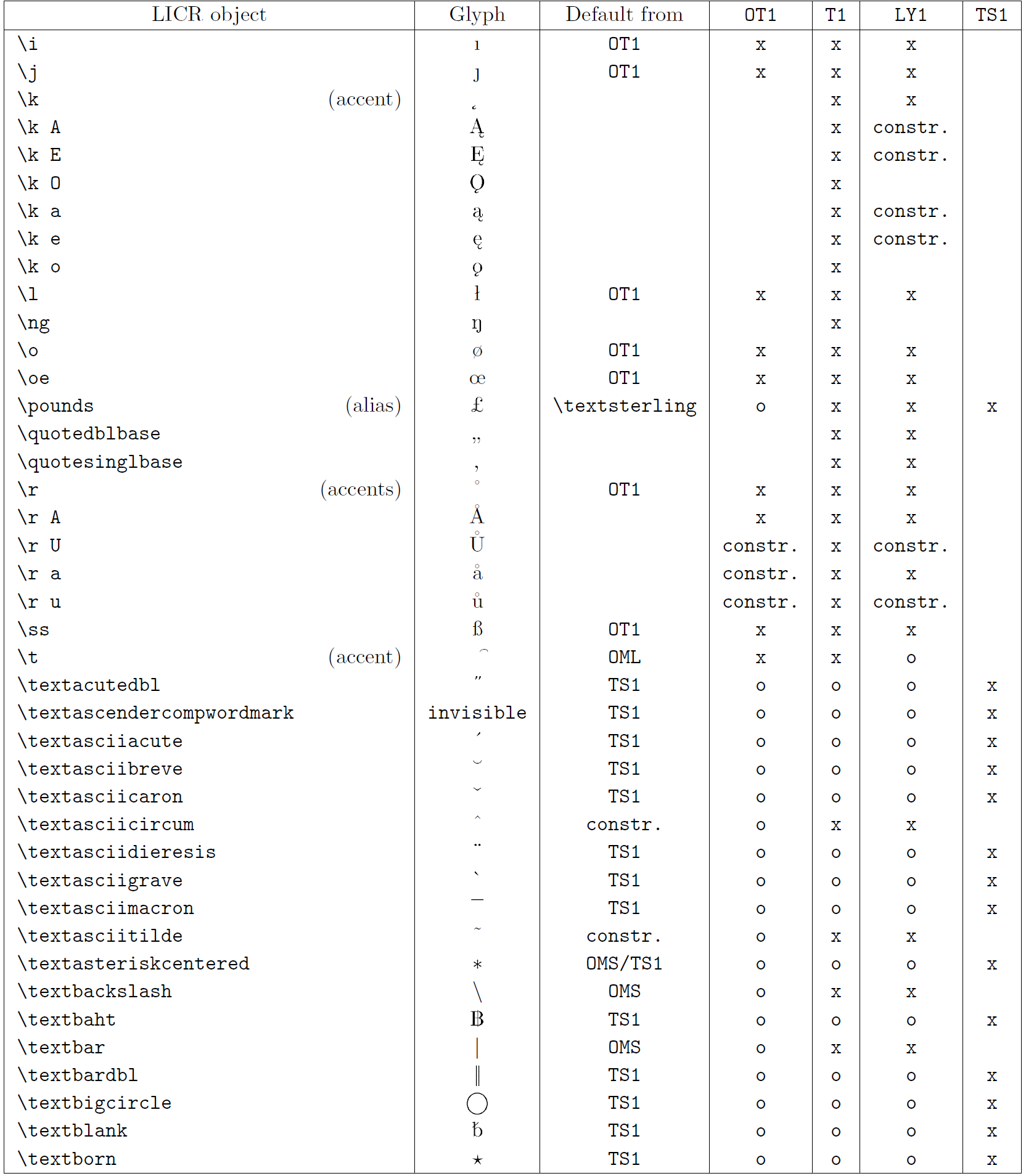
Objetos Licr. Parte 5
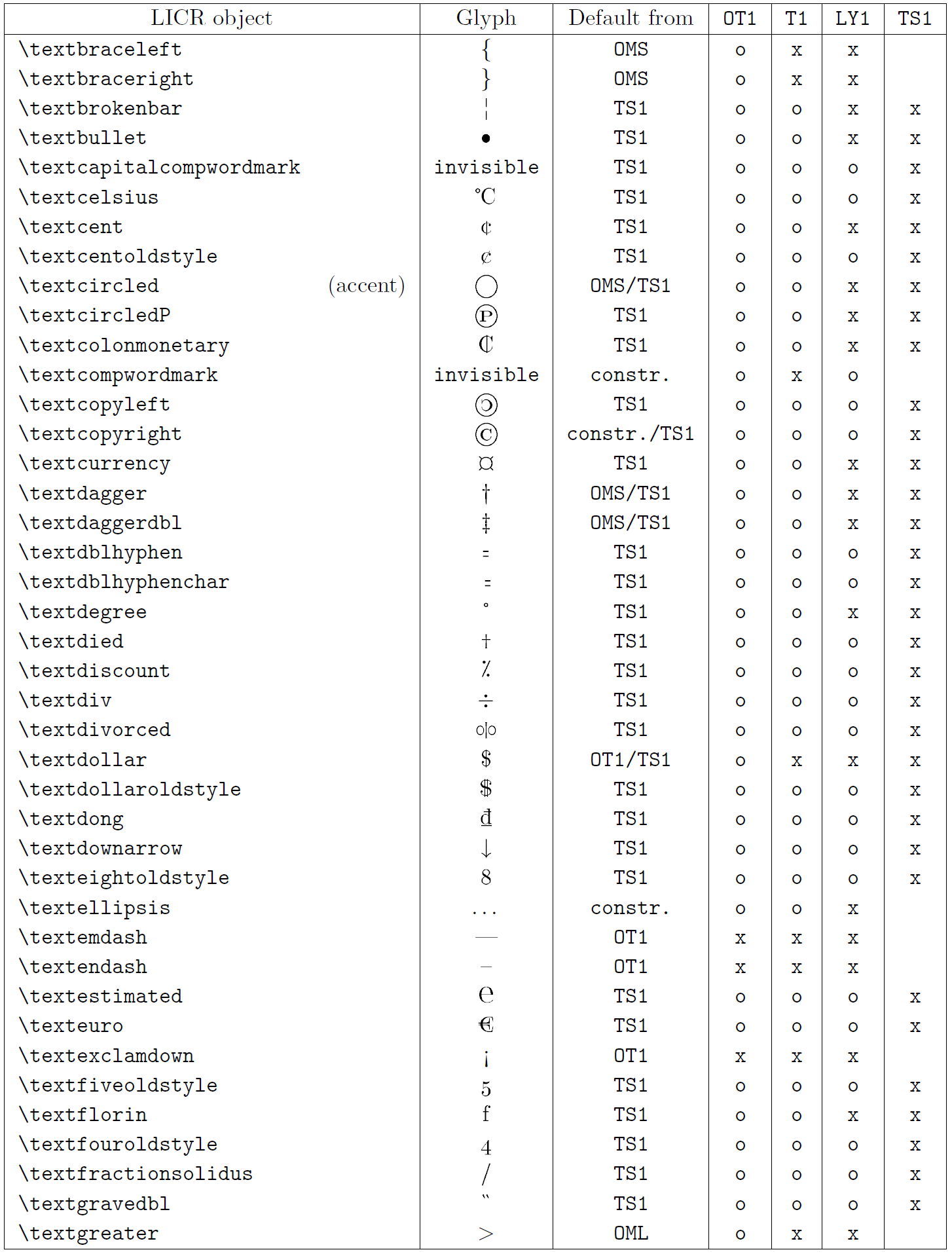
Objetos Licr. Parte 6
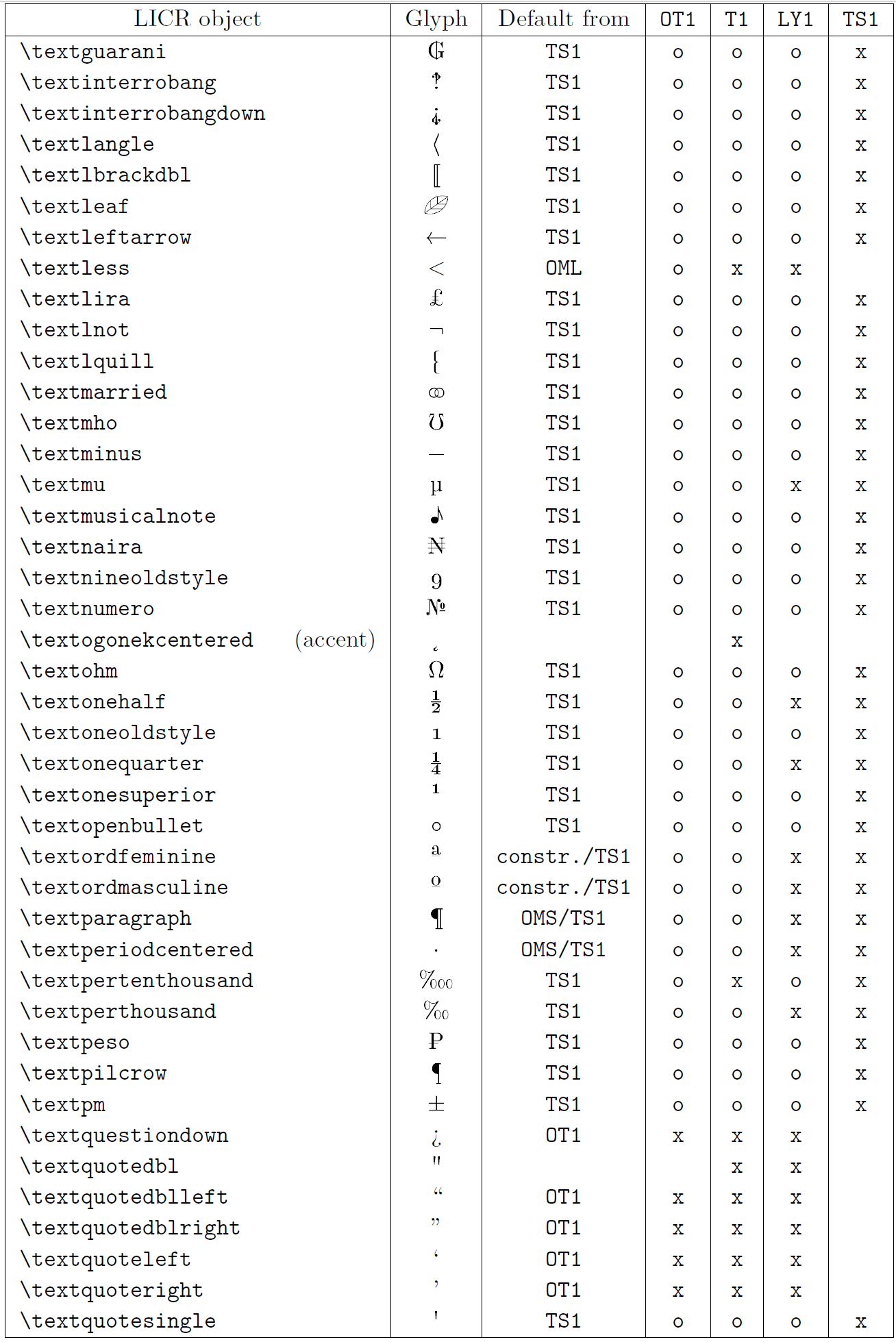
Objetos Licr. Parte 7
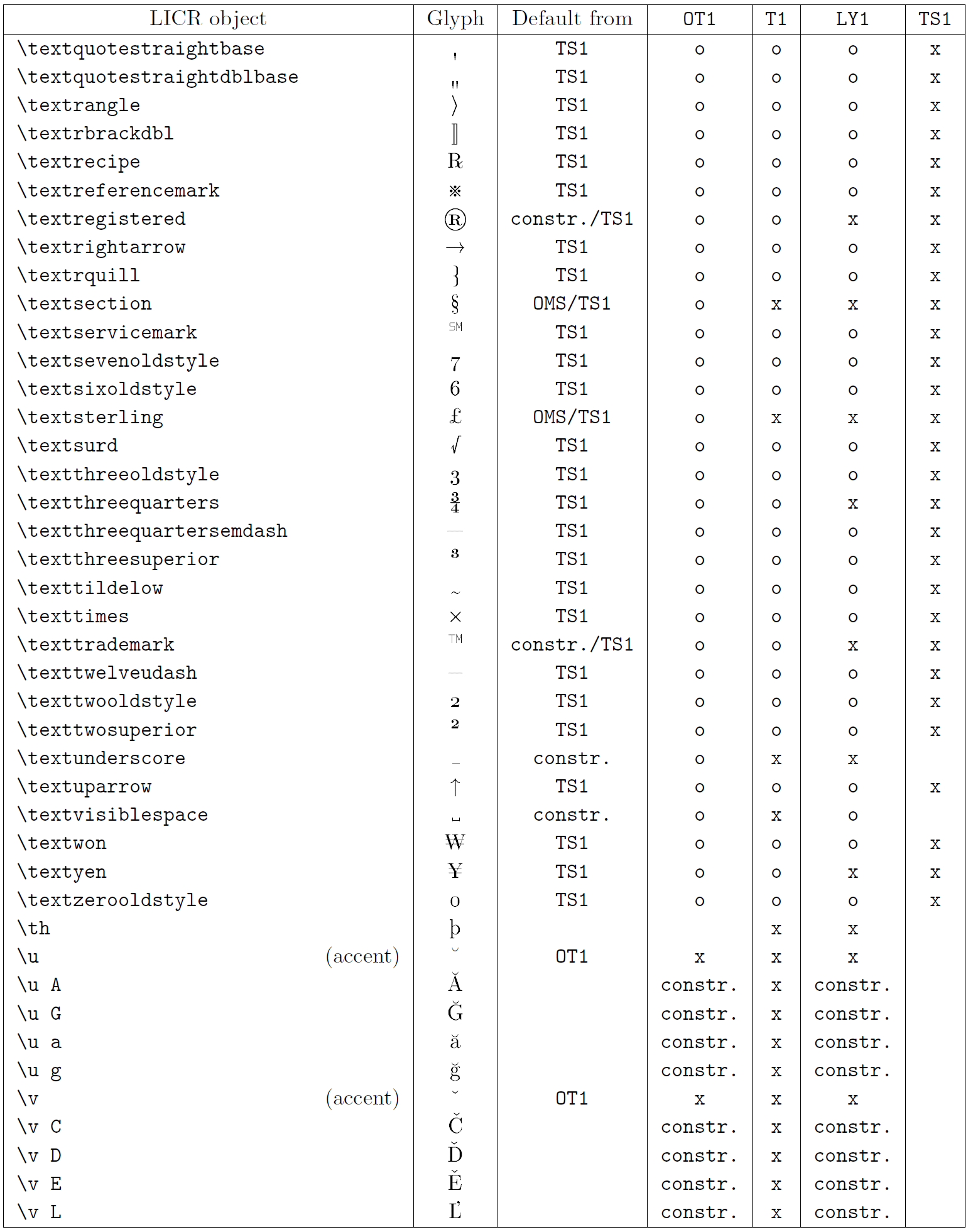
Objetos Licr. Parte 8