4. Fontes de LaTeX padrão
Este artigo contém uma breve introdução às fontes de texto padrão distribuídas juntamente com o LATEX. Em seguida, abrange o suporte padrão do LATEX para codificações de entrada e font. O artigo conclui com uma descrição de um pacote para rastrear o processamento de fontes do Latex e outro pacote para exibir gráficos de glifos.
4.1. Computer Modern Roman
Uma família de fontes chamada * Computer Modern * foi desenvolvida por Donald Knuth junto com Tex. Até o início dos anos 90, apenas essas fontes eram utilizáveis com Tex e, consequentemente, com LaTeX. Cada uma dessas fontes contém apenas 128 glifos, para que não possam incluir caracteres acentuados como glifos individuais. Portanto, usar essas fontes significa que os caracteres acentuados precisam ser produzidos com o \ \ Accent primitivo da TEX, o que, por sua vez, significa que a hifenação automática de palavras com caracteres acentuados é impossível. Embora essa restrição seja aceitável com documentos em inglês, é uma desvantagem óbvia para outros idiomas.
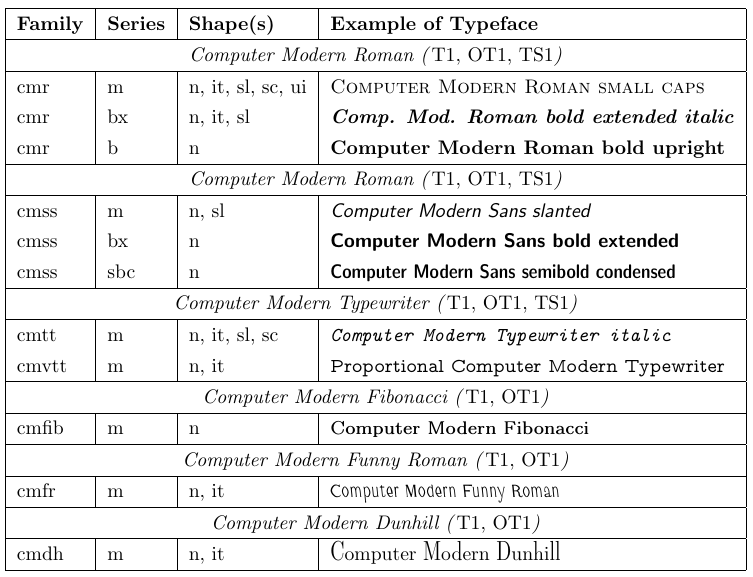
Essas deficiências foram de grande preocupação para os usuários da TEX na Europa e, eventualmente, levaram a uma reimplementação da TEX em 1989 para apoiar os personagens de 8 bits interna e externamente. Uma codificação padrão de 8 bits para fontes de texto (T1) foi desenvolvida em 1990. Ele contém muitos caracteres diacríticos e permite digitar mais de 30 idiomas com base no alfabeto latino. Em seguida, as famílias de fontes modernas do computador foram reimplementadas e caracteres adicionais foram projetados para que as fontes resultantes estejam completamente em conformidade com esse esquema de codificação.
4.2. Selecionando a codificação de entrada: o pacote inputenc
Se você pode digitar caracteres acentuados por meio de pressionamentos de tecla única ou por outro método de entrada (por exemplo, pressionando `` e entãoa` para obter ‘A-Grave’), e seu computador os exibe corretamente no editor …

… Então, idealmente, você usaria esse texto diretamente com LaTeX em vez de ter que digitar a, \^e, etc.
Com idiomas como francês e alemão, a última abordagem é viável. No entanto, para idiomas como russo e grego, é necessário o potencial de entrada direta, pois quase todos os caracteres nesses idiomas têm um nome de comando como sua forma interna de LaTeX. Por exemplo, a definição russa padrão para \reftextfter contém o seguinte texto (que significa" na próxima página “):
1\cyrn\cyra\ \cyrs\cyrl\cyre\cyrd\cyru\cyryu\cyrshch\cyre\cyrishrt
2\ \cyrs\cyrt\cyrr\cyra\cyrn\cyri\cyrc\cyreÉ improvável que alguém queira digitar essas coisas regularmente. No entanto, ele tem a vantagem de ser universalmente portátil, para que possa ser interpretado corretamente em qualquer instalação de LaTeX. Por outro lado, digitando
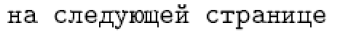
Em um teclado apropriado é claramente preferível, se for possível fazer o LaTeX entender essa entrada. O problema é que o que é armazenado em um arquivo não são os caracteres que vemos na sequência acima, mas os octetos que representam os caracteres. Em circunstâncias diferentes (usando codificações diferentes), os mesmos octetos podem representar caracteres diferentes.
Desde que tudo aconteça em um único computador e todos os programas interpretem octetos em arquivos da mesma maneira, tudo geralmente é bom. Nesse caso, faz sentido ativar um mecanismo de tradução automático que é incorporado em algumas implementações recentes do TEX. Mas quando um arquivo produzido nesse ambiente é enviado para um computador diferente, é provável que o processamento falhe ou, pior ainda, possa parecer ter sucesso, mas de fato produzirá resultados errados, exibindo caracteres incorretos.
O pacote inputenc foi criado para lidar com esse problema. Seu principal objetivo é informar o LaTeX sobre a codificação usada no documento ou em uma parte do documento. Isso é feito carregando o pacote com o nome de codificação como uma opção. Por exemplo:
1\usepackage[cp1252]{inputenc} % Windows 1252 (Western Europe) code pageA partir desse momento, o LATEX sabe como interpretar os octetos no restante do documento em qualquer instalação, independentemente da codificação usada para outros fins nesse computador.
Um exemplo típico é mostrado abaixo. É um texto curto escrito na codificação koi8-r, que é popular na Rússia. O código -fonte mostra como o texto se parece em um computador usando uma codificação latina 1 (por exemplo, na Alemanha). A saída demonstra que o LATEX ainda foi capaz de interpretar o texto corretamente porque foi informado de qual codificação de entrada estava sendo usada.

A lista de codificações atualmente suportadas pelo inputenc é fornecida abaixo. A interface está bem documentada e o suporte para novas codificações pode ser facilmente adicionado. Portanto, vale a pena consultar a documentação do pacote ‘inputEnc’ se a codificação usada pelo seu computador não estiver listada aqui. Você também pode pesquisar na Internet por codificar arquivos para inputenc criado por outros autores. Por exemplo, as codificações relacionadas aos idiomas cirílicos são distribuídos junto com outros pacotes de suporte de fontes para idiomas cirílicos.
O padrão ISO-8859 define uma série de codificações de bytes importantes. As codificações relacionadas ao alfabeto latino são suportadas pelo inputenc. Para o sistema operacional Windows, várias codificações de bytes únicas foram definidas pela Microsoft. Além disso, algumas codificações definidas por outros fornecedores de computadores estão disponíveis.
Latin1Esta é a codificação ISO-8859-1 (também conhecida como latim 1). Pode representar a maioria dos idiomas da Europa Ocidental, incluindo albaneses, catalães, dinamarqueses, holandeses, inglês, distribuído, finlandês, francês, galego, alemão, islandês, irlandês, italiano, norueguês, português, espanhol e sueco.Latin2a codificação ISO Latin 2 (ISO-8859-2) suporta as línguas eslavas da Europa Central que usam o alfabeto latino. Pode ser usado para os seguintes idiomas: croata, tcheco, alemão, húngaro, polonês, romeno, eslovaco e esloveno.Latin3este conjunto de caracteres (ISO-8859-3) é usado para Esperanto, Galian, Maltese e Turkish.Latin4a codificação ISO Latin 4 (ISO-8859-4) pode representar idiomas como estoniana, letã e lituana.Latin5a codificação ISO Latin 5 (ISO 8859-9) está intimamente relacionada ao latim 1 e substitui as letras islandesas raramente usadas do latim 1 com letras turcas.Latin9Latin 9 (ou ISO-8859-15) é outra pequena variação no latim 1 que adiciona o sinal da moeda do euro, bem como alguns outros personagens, como a ligadura\ae, que estavam ausentes em francês e finlandês. Está se tornando cada vez mais popular como um substituto para o latim 1.CP437IBM 437 Código Página (MS-DOS Latin, mas contendo muitos caracteres gráficos para desenhar caixas).CP850IBM 850 Código Página (MS-DOS multilíngue, semelhante ao Latin1).CP852IBM 852 Código Página (MS-DOS multilíngue, semelhante ao Latin2).CP858Página de código IBM 858 (IBM 850 com o símbolo do euro adicionado).CP865IBM 865 Código Página (MS-DOS Noruega).CP1250Windows 1250 (Código Central e Oriental).CP1252Página de código do Windows 1252 (Europa Ocidental).CP1257Página de código Windows 1257 (Báltico).AnsinewWindows 3.1 ANSI Codificação; um sinônimo de CP1252.DecmultiDEC Multinacional conjunto de caracteres codificação.ApplemacMacintosh (Standard) Codificação.MacCeMacintosh Central Central Código da Europa.- `Próximo ‘Próxima codificação do computador.
UTF8UTF8 Coding Support. A maioria das instalações do Tex aceita caracteres de 8 bits por padrão. No entanto, sem mais ajustes, como os realizados por ‘inpuenc’, os resultados podem ser imprevisíveis: alguns caracteres podem desaparecer ou você pode obter qualquer personagem presente na fonte atual no local do octeto, que pode ou não ser o glifo desejado. Esse comportamento foi o padrão por um longo tempo, por isso não foi alterado no LATEX2E porque algumas pessoas confiam nisso. No entanto, para garantir que esses erros possam ser capturados, oInputEnc‘oferece a opçãoASCII, o que torna ilegal qualquer personagem fora do intervalo 32-126.
1\inputencoding{encoding}Originalmente, o pacote inputenc foi projetado para especificar a codificação usada para um documento como um todo - daí o uso de opções no preâmbulo. No entanto, é possível alterar a codificação no meio de um documento usando o comando \inputEncoding. Este comando toma o nome de uma codificação como seu argumento.
Quando o inputenc foi desenvolvido, a maioria das instalações de LaTeX estava em computadores que usavam codificações de bytes de um bytes como as discutidas nesta seção. No entanto, hoje outra codificação é popular, pois os sistemas fornecem suporte ao Unicode: UTF8. Essa codificação de comprimento variável representa caracteres unicode em um a quatro octetos. O suporte à codificação foi adicionado ao inputencatravés da opção utf8. Tecnicamente, ele não fornece uma implementação completa do UTF8. Somente caracteres unicode que têm alguma representação nas fontes de LaTeX padrão são mapeados (ou seja, principalmente conjuntos de caracteres latinos e cirílicos): todos os outros resultarão em uma mensagem de erro adequada. Além disso, os caracteres combinados do Unicode não são suportados, embora essa omissão específica não deva ser um problema na prática.
1\usepackage[utf8]{inputenc}
2\usepackage{textcomp} % for Latin interpretation
3-----------------------------------------------
4German umlauts in UTF-8: ^^c3^^a4^^c3^^b6^^c3^^bc
5\par\inputencoding{latin1}% switch to Latin 1
6But interpreted as Latin 1: ^^c3^^a4^^c3^^b6^^c3^^bc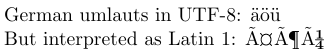
No UTF8, os caracteres ASCII se representam, e a maioria dos caracteres latinos é representada por dois bytes. No código-fonte do exemplo, as representações de dois bytes dos Umlauts alemães no UTF8 são mostrados na notação hexadecimal do TEX, ou seja, com cada octeto precedido por ^^. Em um editor que não entende o UTF8, provavelmente os veria semelhantes à saída produzida quando são interpretados como caracteres latinos 1.
Um pacote com suporte mais abrangente da UTF8 (incluindo suporte para personagens coreanos, chineses e japoneses), embora, consequentemente, mais complexo em sua configuração, é o pacote UCS escrito por Dominique UNruh. Você pode experimentá -lo se a solução InputEnc não cobrir suas necessidades.
4.3. Selecionando as codificações de fontes com o pacote FONTENC
Para ativar uma fonte de texto que codifica para uso com o LATEX, a codificação deve ser carregada no preâmbulo ou na classe de documentos. Mais precisamente, as definições para acessar os glifos em fontes com uma certa codificação devem ser carregadas. A maneira canônica de fazer isso é através do pacote FONTENC, que leva uma lista separada por vírgula de codificações de fontes como uma opção de pacote. A última dessas codificações é automaticamente feita a codificação de documento padrão. Se as codificações do Cirílico forem carregadas, a lista de comandos afetados por \makeuppercase e `\makeLowerCase ‘será estendida automaticamente. Por exemplo,
1\usepackage[T2A,T1]{fontenc}Carregará todas as definições necessárias para as codificações Cirílicas T2A e as codificações T1 e definirá a última codificação do documento padrão.
Ao contrário do comportamento normal do pacote, pode -se carregar este pacote várias vezes com opções diferentes no comando \usepackage. Isso é necessário para permitir que uma classe de documento carregue um certo conjunto de codificações e permitir que o usuário carregue ainda mais codificações no preâmbulo. As codificações de carregamento mais de uma vez são realizadas sem efeitos colaterais além de alterar potencialmente a codificação de fontes padrão do documento.
Se os pacotes de suporte ao idioma (por exemplo, aqueles que vêm com o sistema * Babel *) forem usados no documento, geralmente é o caso de as codificações de fonte necessárias já estão carregadas pelo pacote de suporte.
4.4. Como rastrear a seleção de fontes com o pacote tracefnt
Para detectar problemas no sistema de seleção de fontes, você pode usar o pacote tracefnt. Ele suporta várias opções que permitem personalizar a quantidade de informações exibidas pelo NFSS na tela e no arquivo de transcrição.
ErrorshowEsta opção suprime todos os avisos e mensagens de informação no terminal; Eles serão gravados apenas no arquivo de transcrição. Somente erros reais serão mostrados. Você deve estudar cuidadosamente o arquivo de transcrição antes de imprimir uma publicação importante, pois os avisos sobre substituições de fontes e assim por diante podem significar que o resultado final estará incorreto.WarningshowQuando esta opção é especificada, avisos e erros são mostrados no terminal. Essa configuração fornece informações detalhadas, conforme o LATEX2E, sem o pacoteTracefntcarregado.InfoShowEsta opção é o padrão quando você carrega o pacoteTracefnt. Informações extras, que normalmente são gravadas apenas no arquivo de transcrição, agora também são exibidas no seu terminal.DebugShowEsta opção também mostra informações sobre alterações na fonte de texto e a restauração de tais fontes no final de um grupo de cinta ou no final de um ambiente. Tenha cuidado ao ativar esta opção, pois ela pode produzir arquivos de transcrição muito grandes.- `Possa ‘Esta opção transforma todos os avisos em erros para ajudar a detecção de problemas em publicações importantes.
carregandoEsta opção mostra o carregamento de fontes externas. No entanto, se o formato ou a classe de documentos que você usa já tiver carregado algumas fontes, elas não serão mostradas por esta opção.
4.5. Como exibir tabelas de fontes e amostras com nfssfont.tex
O arquivo chamado nfssfont.tex pode ser usado para testar novas fontes, produzir tabelas de fonte mostrando todos os caracteres e executar outras operações relacionadas a fontes. Você pode encontrar esse arquivo em qualquer distribuição de LaTeX. Quando você executa esse arquivo através do LATEX, você será solicitado o nome da fonte a testar. A resposta pode ser o nome da fonte externa sem uma extensão - como cmr10 (computador Roman 10pt) - se você o conhece ou um nome de fonte vazia. Neste último caso, você será solicitado a uma especificação de fonte NFSS: um nome de codificação (padrão t1), um nome de família da fonte (padrão cmr), uma série de fontes (padrão m), uma forma de fonte (padrão n) e um tamanho de fonte (default 10pt). O programa carrega o arquivo externo correspondente a essa classificação.
Em seguida, você será solicitado a inserir um comando. O mais importante é provavelmente \tabela, que produz um gráfico de fontes como o abaixo. O comando \text também é interessante, pois produz uma amostra de texto mais longa. Para mudar para uma nova fonte de teste, digite \init; Para terminar o teste, digite \bye ou \stop; E para aprender sobre todos os outros testes disponíveis, digite \help.
1**********************************************
2* NFSS font test program version <v2.2b>
3*
4* Follow the instructions
5**********************************************
6
7Input external font name, e.g., cmr10
8(or <enter> for NFSS classification of font):
9
10\currfontname=cmr10
11Now type a test command (\help for help):)
12*\table
13
14*\newpage
15*\init
16Input external font name, e.g., cmr10
17(or <enter> for NFSS classification of font):
18
19\currfontname=
20*** NFSS classification ***
21
22Font encoding [T1]:
23
24\encoding=OT1
25(ot1enc.def)
26Font family [cmr]:
27
28\family=cmdh
29Font series [m]:
30
31\series=m
32Font shape [n]:
33
34\shape=n
35Font size [10pt]:
36
37\size=10
38(ot1cmdh.fd) Now type a test command (\help for help):
39*\text
40
41*\bye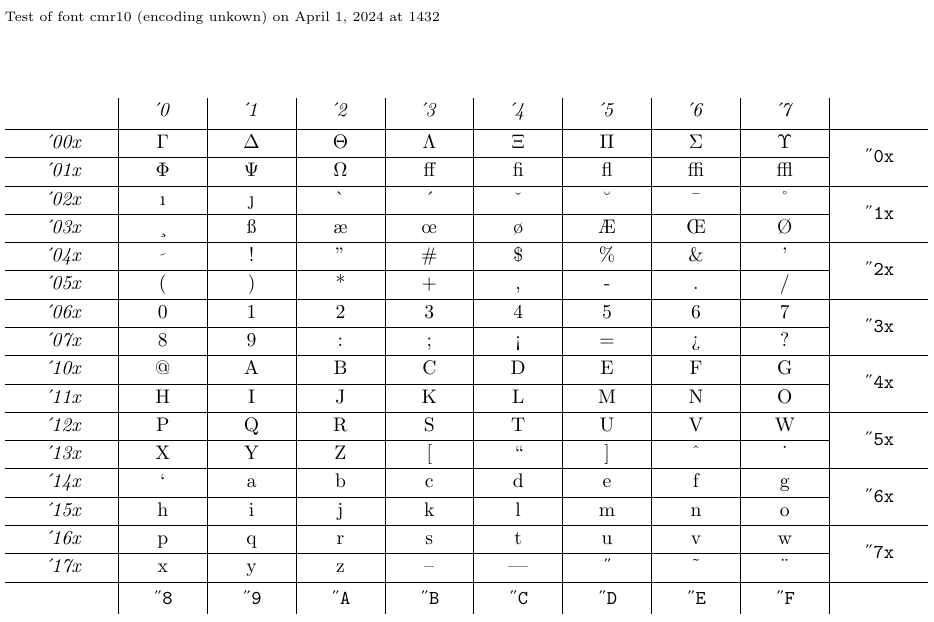

Há dois pontos a considerar. Em primeiro lugar, o programa
nfssfont. texemite um comando\initimplícito, pelo que a primeira linha de entrada deve conter um nome de fonte ou estar completamente vazia para indicar que se segue uma classificação NFSS. Em segundo lugar, a entrada para\initdeve aparecer em linhas individuais, sem mais nada (nem sequer um comentário), porque o fim da linha indica o fim da resposta a um prompt comoFont encoding[T1]: \encoding=que irá receber.