Модель LaTeX для кодировок символов
В этой статье подробно рассматриваются кодировки LaTeX. Он начинается с обсуждения потока символьных данных в системе LaTeX. Далее мы более подробно рассмотрим модель внутреннего представления символьных данных в LaTeX, а затем обсудим механизмы, используемые для отображения входящих данных посредством входных кодировок в это внутреннее представление. Наконец, мы объясним, как внутреннее представление преобразуется через выходные кодировки в форму, необходимую для набора текста.
7.1. Поток символьных данных в LaTeX
Обработка документа с помощью LaTeX начинается с интерпретации данных, присутствующих в одном или нескольких исходных файлах. Эти данные, представляющие содержимое документа, хранятся в исходных файлах в виде последовательностей октетов, представляющих символы. Чтобы правильно интерпретировать эти октеты, любая программа (включая LaTeX), используемая для обработки файла, должна знать соответствие между абстрактными символами и представляющими их октетами. Другими словами, он должен знать кодировку, которая использовалась при записи файла.
При неправильном отображении вся дальнейшая обработка будет более или менее ошибочной, если только файл не содержит только символы подмножества, общего как в правильной, так и в неправильной кодировке. В этот момент LaTeX делает фундаментальное предположение: почти все видимые символы ASCII (десятичные 32–126) представлены номерами, которые они имеют в таблице кодов ASCII.

Одной из причин этого предположения является то, что большинство 8-битных кодировок, используемых сегодня, имеют общую 7-битную плоскость. Другая причина заключается в том, что для эффективного использования TeX большая часть видимой части ASCII должна обрабатываться как символы категории буква, поскольку только символы этой категории могут использоваться в многосимвольных именах команд в TEX или категории. other — поскольку TEX, например, не распознает десятичные цифры как часть числа, если они не имеют этого кода категории.
Когда символ (или, точнее, 8-битное число) объявлен в TeX как принадлежащий к категории буква или другое, то это 8-битное число будет прозрачно передаваться через TeX. Это означает, что TeX напечатает любой символ, который есть в шрифте, в позиции, указанной этим номером.
Как следствие вышеупомянутого предположения, шрифты, предназначенные для использования в общем тексте, требуют, чтобы (большая часть) видимых символов ASCII присутствовала в шрифте и была закодирована в соответствии с кодировкой ASCII.
Всем остальным 8-битным числам (за пределами видимого ASCII), потенциально присутствующим во входном файле, присваивается код категории active, что заставляет их действовать как команды внутри TeX. Следовательно, LaTeX может преобразовать их посредством входных кодировок в форму, которую мы назовем внутренним представлением символов LaTeX (LICR).
Что касается кодировки Unicode UTF8, она обрабатывается аналогично. Символы ASCII представляют собой сами себя, а начальные октеты для многобайтового представления действуют как активные символы, которые сканируют входные данные на предмет оставшихся октетов. Результат будет преобразован в объект в LICR, если он сопоставлен, или LaTeX выдаст ошибку, если данный символ Юникода не сопоставлен.
Самое важное в объектах в LICR заключается в том, что представление 7-битных символов ASCII инвариантно к любому изменению кодировки, поскольку все входные кодировки должны быть прозрачными по отношению к видимому ASCII. Кодировки вывода (или шрифта) затем служат для сопоставления внутренних представлений символов с позициями глифов в текущем шрифте, используемом для набора текста, или, в некоторых случаях, для инициирования более сложных действий. Например, он может разместить акцент (присутствующий в одной позиции текущего шрифта) над некоторым символом (в другой позиции текущего шрифта), чтобы получить напечатанное изображение абстрактного символа, представленного командой(ами) во внутреннем кодировка символов.
LICR кодирует все возможные символы, адресуемые в LaTeX. Таким образом, оно намного больше, чем количество символов, которое может быть представлено одним шрифтом TeX (который может содержать не более 256 глифов). В некоторых случаях символ во внутренней кодировке можно отобразить с помощью шрифта путем комбинирования глифов, например символов с диакритическими знаками. Однако когда внутренний символ требует особой формы, его невозможно подделать, если этот глиф отсутствует в шрифте.
Тем не менее, модель кодировки символов LaTeX поддерживает автоматические механизмы извлечения глифов из разных шрифтов, так что символы, отсутствующие в текущем шрифте, будут набраны при условии, что доступен подходящий дополнительный шрифт, содержащий их.
7.2. Внутреннее представление символов LaTeX (LICR)
Текстовые символы представляются внутри LaTeX одним из трех способов.
Представление в виде персонажей
Небольшое количество персонажей представлено «самими собой». Например, латинская буква A представлена буквой «A». Такие символы показаны в таблице выше. Они образуют подмножество видимого ASCII, и внутри TeX всем им присвоен код категории letter или other. Некоторые символы из видимого диапазона ASCII не представлены таким образом либо потому, что они являются частью синтаксиса TeX, либо потому, что они присутствуют не во всех шрифтах. Если кто-то использует, например, ‘<’ в тексте, текущая кодировка шрифта определяет, будет ли в печатном выводе отображаться < (T1) или, возможно, перевернутый восклицательный знак (OT1).
Представление в виде последовательностей символов
Внутренний механизм лигатуры TeX может генерировать новые символы из последовательности входных символов. На самом деле это свойство шрифта, хотя некоторые такие последовательности были специально разработаны для использования в качестве ярлыков ввода для символов, которые иначе трудно использовать с помощью большинства клавиатур. Лишь несколько символов, сгенерированных таким способом, считаются принадлежащими внутреннему представлению LaTeX. К ним относятся тире и длинное тире, которые генерируются лигатурами -- и ---, а также открывающие и закрывающие двойные кавычки, которые генерируются `` и '' (последний обычно также может быть представлен одним "). Хотя большинство шрифтов также реализуют !` и ?` для создания перевернутых восклицательных и вопросительных знаков, это не так. универсально доступен во всех шрифтах. Вот почему все такие символы имеют альтернативное внутреннее представление в виде команды (например, \textendash или \textexclamdown).
Представление в виде команд, специфичных для кодировки шрифта.
Третий способ представления символов внутри LaTeX, который охватывает большинство символов, — это специальные команды LaTeX (или последовательности команд), которые остаются нераскрытыми при записи в файл или при помещении в движущийся аргумент. Мы будем называть такие специальные команды командами, специфичными для кодировки шрифта, поскольку их значение зависит от кодировки шрифта, используемой в данный момент, когда LaTeX готов к их набору. Такие команды объявляются с использованием специальных объявлений, как мы обсудим ниже, которые обычно требуют индивидуальных определений для каждой кодировки шрифта. Если для текущей кодировки не существует определения, используется либо значение по умолчанию (если оно доступно), либо пользователю предоставляется сообщение об ошибке. Когда в какой-то момент документа изменяется кодировка шрифта, определения команд, специфичных для кодировки, не меняются немедленно, поскольку это означало бы немедленное изменение большого количества команд. Вместо этого эти команды реализованы таким образом, что после их использования они замечают, что их текущее определение больше не подходит для действующей кодировки шрифта. В таком случае они вызывают своих коллег в текущей кодировке шрифта, чтобы выполнить фактическую работу.
Набор команд, специфичных для кодировки шрифта, не фиксирован, но неявно определяется как объединение всех команд, определенных для отдельных кодировок шрифта. Таким образом, при добавлении новых кодировок шрифтов в LaTeX могут потребоваться новые команды, специфичные для кодировки шрифтов.
7.3. Входные кодировки
После загрузки пакета inputenc становятся доступны два объявления \DeclareInputText и \DeclareInputMath для сопоставления 8-битных входных символов с объектами LICR. Их следует использовать только в файлах кодировки (см. ниже), пакетах или, при необходимости, в преамбуле документа.
Эти команды принимают в качестве первого аргумента 8-битное число, которое может быть задано как десятичное, восьмеричное число или в шестнадцатеричном формате. Рекомендуется использовать десятичную систему счисления, поскольку символы ' и/или " могут иметь специальные значения в пакете языковой поддержки, например, как ярлыки для акцентов, тем самым делая восьмеричную и/или шестнадцатеричную систему счисления недействительной, если пакеты загружаются в неправильном формате. заказ.
1\DeclareInputText{number}{LICR-object}Команда \DeclareInputText объявляет сопоставления символов для использования в тексте. Его второй аргумент содержит команду (или последовательность команд), специфичную для кодировки, то есть объекты LICR, которым должен быть сопоставлен номер символа. Например,
1\DeclareInputText{239}{\"\i}сопоставляет число 239 с представлением i-umlaut, зависящим от кодировки, то есть \"\i. Входные символы, объявленные таким образом, не могут использоваться в математических формулах.
1\DeclareInputMath{number}{math-object}Если число представляет собой символ для использования в математических формулах, то необходимо использовать объявление \DeclareInputMath. Например, во входной кодировке cp437de (немецкая клавиатура MS-DOS)
1\DeclareInputMath{224}{\alpha}сопоставляет число 224 с командой \alpha. Важно отметить, что это объявление сделает ключ, создающий это число, доступным только в математическом режиме, поскольку \alpha нигде больше не разрешен.
1\DeclareUnicodeCharacter{hex-number}{LICR-object}Это объявление доступно только в том случае, если используется опция utf8. Он сопоставляет номера Юникода с объектами LICR (т. е. символами, которые можно использовать в тексте). Например,
1\DeclareUnicodeCharacter{00A3}{\textsterling}
2\DeclareUnicodeCharacter{011A}{\v E}
3\DeclareUnicodeCharacter{2031}{\textpertenthousand}Теоретически между двумя пространствами должно быть только одно уникальное двунаправленное сопоставление, чтобы все такие объявления могли быть сделаны автоматически при выборе опции utf8. На практике все немного сложнее. Во-первых, автоматическое предоставление всей таблицы потребует огромного количества памяти TeX. Кроме того, существует множество символов Юникода, для которых не существует объекта LICR, и наоборот, многие объекты LICR не имеют эквивалента в Юникоде. Эта проблема решается в пакете inputenc путем загрузки только тех сопоставлений Юникода, которые соответствуют кодировкам, используемым в конкретном документе (насколько они известны), и ответа на любой другой запрос символа Юникода подходящим сообщением об ошибке. Тогда задачей пользователя становится либо предоставить правильную информацию о сопоставлении, либо, при необходимости, загрузить дополнительную кодировку шрифта.
Как мы упоминали выше, объявления входной кодировки могут использоваться в пакетах или в преамбуле документа. Чтобы все работало таким образом, важно сначала загрузить пакет inputenc, выбрав тем самым подходящую кодировку. Последующие объявления входной кодировки будут действовать как замена (или дополнение) объявлений, определенных текущей входной кодировкой.
При использовании пакета inputenc вы можете увидеть команду \@tabacckludge, что означает «табуляция акцента». Это необходимо, поскольку текущая версия LaTeX унаследовала перегрузку команд \=, \` и \', которые обычно обозначают определенные акценты (т. е. являются командами, специфичными для кодировки), но имеют особое значение внутри среды табуляции. Вот почему отображения, включающие любой из этих акцентов, необходимо кодировать особым образом. Например, если вы хотите сопоставить 232 с символом ’e-grave’ (который имеет внутреннее представление \`e), вам следует написать
1\DeclareInputText{232}{\@tabacckludge`e}вместо
1\DeclareInputText{232}{\`e}Сопоставление с текстом и/или математикой
По техническим и концептуальным причинам TeX проводит очень четкое различие между символами, которые можно использовать в тексте и в математических вычислениях. За исключением видимых символов ASCII, команды, создающие символы, обычно могут использоваться либо в текстовом, либо в математическом режиме, но не в обоих режимах.
Файлы входной кодировки для 8-битных кодировок
Входные кодировки хранятся в файлах с расширением .def, где базовым именем является имя входной кодировки (например, latin1.def). Такие файлы должны содержать только команды, обсуждаемые в текущем разделе.
Файл должен начинаться с идентификационной строки, содержащей команду \ProvidesFile, описывающую характер файла. Например:
1\ProvidesFile{latin1.def}[2000/07/01 v0.996 Input encoding file]Если существуют сопоставления с командами, специфичными для кодировки, которые могут быть недоступны, если не загружены дополнительные пакеты, для них можно объявить значения по умолчанию с помощью \ProvideTextCommandDefault. Например:
1\ProvideTextCommandDefault{\textonehalf}{\ensurement{\frac12}}
2\ProvideTextCommandDefault{\textcent}{\TextSymbolUnavailable\textcent}Команда \TextSymbolUnavailable выдает предупреждение, указывающее, что определенный символ недоступен в используемых в данный момент шрифтах. Это может быть полезно в качестве значения по умолчанию, когда такие символы доступны только в том случае, если загружены специальные шрифты и нет подходящего способа подделать символы существующими символами (как это было возможно для значения по умолчанию для \textonehalf).
Оставшаяся часть файла должна включать только объявления входной кодировки \DeclareInputText и \DeclareInputMath. Как упоминалось выше, использование последней команды не рекомендуется, но разрешено. Внутри входного файла кодировки не следует использовать никакие другие команды, в частности команды, предотвращающие многократное чтение файла (например, \newcommand), поскольку файлы кодировки часто загружаются несколько раз в одном документе.
Входные файлы сопоставления для UTF8
Как упоминалось ранее, сопоставление Unicode с объектами LICR организовано таким образом, что позволяет LaTeX загружать только те сопоставления, которые соответствуют кодировкам шрифтов, используемым в текущем документе. Это делается путем загрузки для каждой кодировки <name> файла <name>enc.dfu, который, если он существует, содержит информацию о сопоставлении для символов Юникода, предоставляемых этой конкретной кодировкой. Помимо ряда объявлений \DeclareUnicodeCharacter, такие файлы должны включать только строку \ProvidesFile.
Поскольку разные кодировки шрифтов часто содержат более или менее одни и те же символы, объявления одного и того же символа Юникода часто встречаются в разных файлах .dfu. Поэтому очень важно, чтобы эти объявления в разных файлах были идентичными. В противном случае сохранится декларация, загруженная последней, которая может отличаться от документа к документу.
Таким образом, любой, кто хочет предоставить новый файл .dfu для какой-либо кодировки, которая ранее не рассматривалась, должен внимательно проверить существующие определения в файлах .dfu на наличие связанных кодировок. Стандартные файлы, поставляемые с inputenc, гарантированно имеют единообразные определения. Фактически, все они создаются из единого списка, который соответствующим образом разделен. Полный список существующих на данный момент сопоставлений можно найти в файле utf8enc.dfu.
7.4. Выходные кодировки
Мы уже упоминали, что выходные кодировки определяют отображение LICR на глифы (или конструкции, построенные из глифов), доступные в шрифтах, используемых для набора текста. Эти сопоставления внутри LaTeX обозначаются двух- или трехбуквенными именами (например, OT1 и T3). Мы говорим, что определенный шрифт находится в определенной кодировке, если отображение соответствует положениям глифов в шрифте. Давайте теперь посмотрим на точные компоненты такого отображения.
Символы, внутренне представленные символами ASCII, просто передаются в шрифт. Другими словами, TeX использует код ASCII для выбора глифа из текущего шрифта. Например, символ «A» с кодом ASCII 65 приведет к набору глифа в позиции 65 в текущем шрифте. Вот почему LaTeX требует, чтобы шрифты для текста содержали все такие буквы ASCII в позициях их кода ASCII, поскольку нет способа взаимодействовать с этим базовым механизмом TeX. Следовательно, для видимого ASCII сопоставление «один к одному» неявно присутствует во всех выходных кодировках.
Символы, внутренне представленные как последовательности символов ASCII (например, «--»), обрабатываются следующим образом: когда текущий шрифт загружается впервые, TeX сообщается, что шрифт содержит ряд так называемых лигатурных программ. Эти программы определяют определенные последовательности символов, которые не следует набирать напрямую, а следует заменять некоторыми другими глифами из шрифта. Например, когда TeX встречает «--» во входных данных (т. е. код ASCII 45 дважды), лигатурная программа может вместо этого направить его к глифу в позиции 123 (который затем будет содержать глиф в виде тире). Опять же, нет возможности взаимодействовать с этим механизмом.
Тем не менее, большая часть внутреннего представления символов состоит из команд, специфичных для кодировки шрифта, которые отображаются с помощью описанных ниже объявлений. Все объявления имеют одинаковую структуру в своих первых двух аргументах: команда, специфичная для кодировки шрифта (или первый ее компонент, если это последовательность команд), за которой следует имя кодировки. Любые оставшиеся аргументы будут зависеть от типа объявления.
Итак, кодировка «XYZ» определяется набором объявлений, каждый из которых имеет имя «XYZ» в качестве второго аргумента. Тогда, конечно, некоторые шрифты должны быть закодированы в этой кодировке. Фактически, разработка кодировок шрифтов обычно осуществляется в обратном порядке: кто-то начинает с существующего шрифта, а затем предоставляет соответствующие объявления для его использования. Затем этому набору объявлений присваивается подходящее имя, например «OT1». Ниже мы возьмем шрифт ecrm1000 (см. диаграмму глифов), кодировка шрифта которого в LaTeX называется T1, и построим соответствующие объявления для доступа к глифам из шрифта, закодированного таким образом. Синие символы в диаграмме глифов — это те, которые должны присутствовать в одной и той же позиции в каждой текстовой кодировке, поскольку они прозрачно передаются через LaTeX.
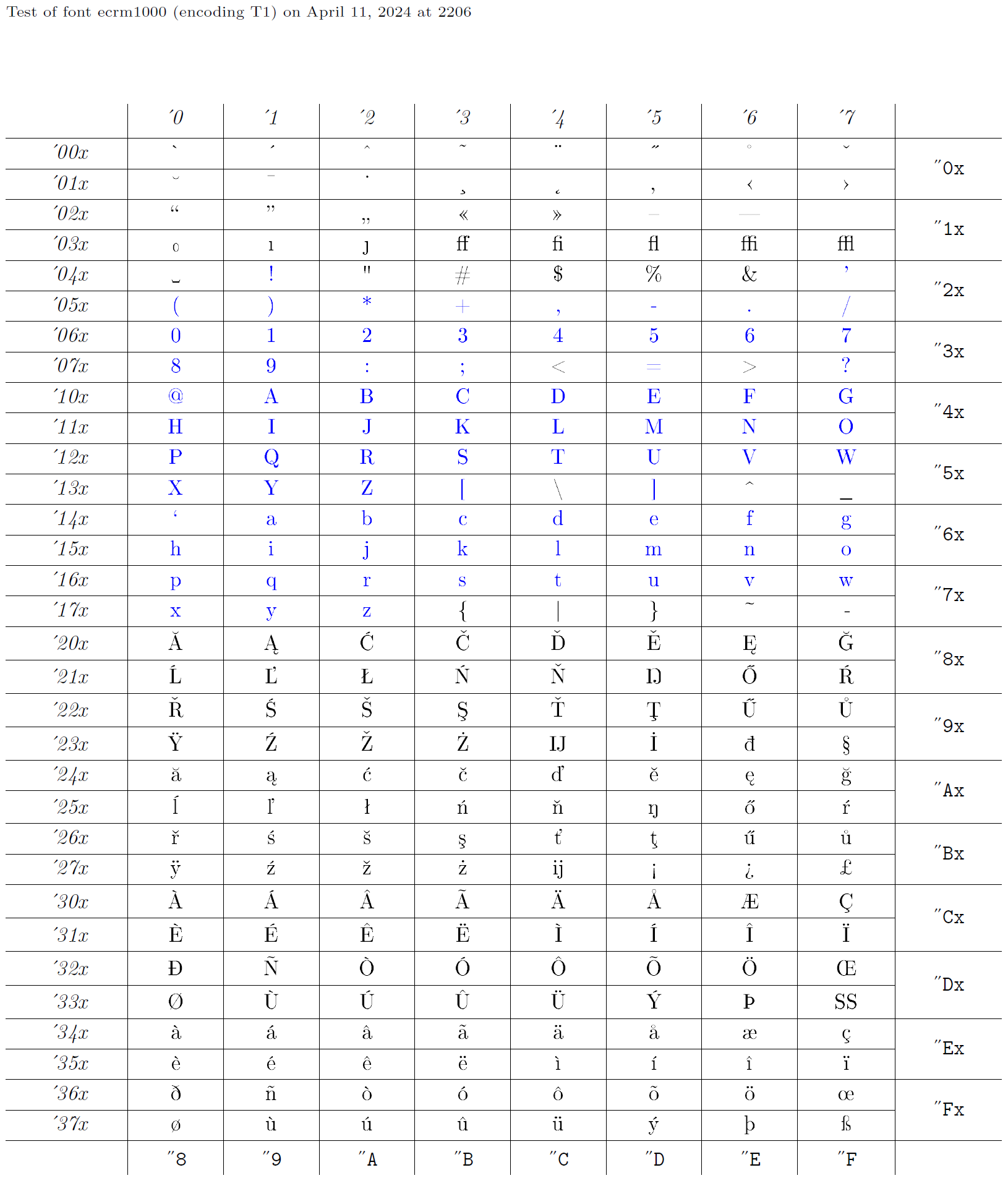
Выходные файлы кодирования
Файлы выходного кодирования идентифицируются тем же расширением .def, что и входные файлы кодирования. Однако базовое имя файла немного более структурировано. Он состоит из имени кодировки, написанного строчными буквами, за которым следует enc (например, t1enc.def для кодировки T1).
Эти файлы должны включать только объявления, описанные в текущем разделе. Поскольку файлы выходной кодировки могут быть прочитаны LaTeX несколько раз, важно следовать этому правилу и воздерживаться от использования, например, \newcommand, который предотвращает чтение такого файла более одного раза!
Опять же, выходной файл кодирования начинается с идентификационной строки, описывающей природу файла. Например:
1\ProvidesFile{t1enc.def}[2001/06/05 v1.94 Standard LaTeX file]Прежде чем объявить какие-либо команды, специфичные для конкретной кодировки, мы сначала должны сообщить об этой кодировке LaTeX. Это делается с помощью команды \DeclareFontEncoding. На этом этапе также полезно объявить правила замены по умолчанию для кодировки. Мы можем сделать это с помощью команды \DeclareFontSubstitution. Оба объявления подробно обсуждаются в разделе
Как настроить новые шрифты.
1\DeclareFontEncoding{T1}{}{}
2\DeclareFontSubstitution{T1}{cmr}{m}{n}Теперь, когда мы таким образом ввели кодировку T1 в LaTeX, мы можем приступить к объявлению того, как команды, специфичные для кодировки шрифта, должны вести себя в этой кодировке.
1\DeclareTextSymbol{LICR-Object}{encoding}{slot}Объявление текстовых символов кажется самым простым. Здесь внутреннее представление может быть напрямую сопоставлено с одним глифом в целевом шрифте. Это достигается с помощью объявления \DeclareTextSymbol, третий аргумент которого — позиция глифа — может быть задан как десятичное, восьмеричное или шестнадцатеричное число. Например,
1\DeclareTextSymbol{\ss}{T1}{255}
2\DeclareTextSymbol{\AE}{T1}{'306} %font position as octal number
3\DeclareTextSymbol{\ae}{T1}{"E6} %...as hexadecimal numberобъявить, что команды \ss, \AE и \ae, специфичные для кодировки шрифта, должны быть сопоставлены с позициями шрифта (десятичными) 255, 198 и 230 соответственно в кодировке T1. шрифт. Как мы упоминали выше, в таких объявлениях безопаснее всего использовать десятичную запись. В любом случае смешивать обозначения, как в предыдущем примере, — это, конечно, плохой стиль.
1\DeclareTextAccent{LICR-accent}{encoding}{slot}Шрифты часто содержат диакритические знаки в виде отдельных глифов, что позволяет создавать акцентированные символы путем объединения такого диакритического знака с каким-либо другим глифом. Такие акценты (если они должны быть размещены поверх других глифов) объявляются с помощью команды \DeclareTextAccent. Третий аргумент, slot, — это позиция диакритического знака в шрифте. Например,
1\DeclareTextAccent{\"}{T1}{4}определяет акцент «умлаут». С этого момента внутреннее представление, такое как \"a, имеет следующее значение в кодировке ``T1: набирайте 'a с умляутом', помещая ударение в позицию 4 над глифами в позиции 97 (код ASCII символ a). Такое объявление фактически неявно определяет огромный диапазон внутренних представлений символов - то есть что-либо типа "*<base-glyph>*, где *<base-glyph>* это что-то определенное через \DeclareTextSymbol` или любой символ ASCII, принадлежащий LICR, например, ‘a’.
Даже те комбинации, которые не имеют особого смысла, такие как \"\P (т. е. знак пилорамы с умляутом), таким образом концептуально становятся членами набора команд, специфичных для кодировки шрифта.
1\DeclareTextComposite
2 {LICR-accent}{encoding}{simple-LICR-object}{slot}Приведенная выше таблица глифов содержит большое количество символов с диакритическими знаками в виде отдельных глифов — например, «a с умлаутом» в восьмеричной позиции «240». Таким образом, в T1 команда \"a, специфичная для кодировки, не должна приводить к помещению акцента над символом “a”, а вместо этого должна напрямую обращаться к глифу в этой позиции шрифта. Это достигается с помощью объявления
1\DeclareTextComposite{\"}{T1}{a}{228}в котором говорится, что команда \"a, специфичная для кодировки, приводит к набору глифа 228, тем самым отключая приведенное выше объявление акцента. Для всех других команд, специфичных для кодировки, начинающихся с \", объявление акцента остается на месте. Например, \"b создаст букву ‘b с умляутом’, поставив ударение над базовым глифом ‘b’.
Третий аргумент, simple-LICR-object, должен представлять собой одну букву, например «a», или одну команду, например \j или \oe.
1\DeclareTextCompositeCommand
2 {LICR-object}{encoding}{simple-LICR-object}{code}Хотя он не используется для кодировки «T1», существует также более общая версия «\DeclareTextComposite», которая позволяет использовать произвольный код вместо позиции слота. Это используется, например, в кодировке OT1 для понижения кольцевого акцента над буквой A по сравнению с тем, как это было бы набрано с помощью примитива TeX \accent. Акценты над «i» также реализуются с использованием этой формы объявления:
1\DeclareTextCompositeCommand{\'}{OT1}{i}{\@tabacckludge'\i}
2\DeclareTextCompositeCommand{\^}{OT1}{i}{\^\i}Ряд диакритических знаков ставится не поверх других символов, а где-то под ними. Для таких знаков не существует специальной формы объявления, поскольку фактическое расположение акцента включает низкоуровневый код TeX. Вместо этого для этой цели можно использовать общий \DeclareTextCommand.
1\DeclareTextCommand{LICR-object}{encoding}[num][default]{code}Например, акцент «\b» в кодировке «T1» определяется следующим кодом:
1\DeclareTextCommand{\b}{T1}[1]
2 {\hmode$bgroup\o$lign{\relax#1\crcr\hidewidth\sh$ft{29}%
3 \vbox to.2ex{\hbox{\char9}\vss}\hidewidth}\egroup}В этом обсуждении не имеет большого значения, что именно означает код, но мы видим, что \DeclareTextCommand в некотором смысле похож на \newcommand. Он имеет необязательный аргумент num, обозначающий количество аргументов (здесь один), второй необязательный аргумент default (здесь нет) и последний обязательный аргумент, содержащий код, в котором можно сослаться на аргумент( s) используя #1, #2 и так далее.
\DeclareTextCommand также можно использовать для создания команд, специфичных для кодировки шрифта, состоящих из одной управляющей последовательности. В этом случае он используется без необязательного аргумента, тем самым определяя команду с нулевыми аргументами. Например, в «T1» нет значка для знака «за тысячу», но есть маленькая буква «o» в позиции «30», которая, если ее поместить непосредственно за знаком «%», даст соответствующий глиф. . Таким образом, мы можем предоставить следующие объявления:
1\DeclareTextCommand{\textperthousand} {T1}{\%\char 24}
2\DeclareTextCommand{\textpertenthousand}{T1}{\%\char 24\char 24 }Мы рассмотрели все команды, необходимые для объявления команд, специфичных для кодировки шрифта, для новой кодировки. Как мы уже говорили, в файлах определения кодировки должны присутствовать только эти команды.
Настройки кодировки вывода по умолчанию
Давайте теперь посмотрим, что произойдет, если используется команда, специфичная для кодировки, для которой нет объявления в текущей кодировке шрифта. В этом случае может произойти одно из двух: либо LaTeX имеет определение по умолчанию для объекта LICR, и в этом случае используется это значение по умолчанию, либо выдается сообщение об ошибке, в котором говорится, что запрошенный объект LICR недоступен в текущей кодировке. Существует несколько способов установки значений по умолчанию для объектов LICR.
1\DeclareTextCommandDefault{LICR-object}[num][default]{code}Команда \DeclareTextCommandDefault предоставляет определение по умолчанию для LICR-объекта, который будет использоваться всякий раз, когда для объекта в текущей кодировке нет определенных настроек. Такие определения могут, например, имитировать определенного персонажа. Например, \textregistered имеет определение по умолчанию, в котором символ состоит из двух других, например:
1\DeclareTextCommandDefault{\textregistered}{\textcircled{\scshape r}}Технически определения по умолчанию хранятся в виде кодировки с именем ?. Хотя на этот факт полагаться не стоит, так как в будущем реализация может измениться, а это означает, что вы не сможете объявить кодировку с таким именем.
1\DeclareTextSymbolDefault{LICR-object}{encoding}В большинстве случаев определение по умолчанию не требует кодирования, а просто предписывает LaTeX взять символ из некоторой кодировки, в которой он, как известно, существует. Например, пакет textcomp содержит большое количество объявлений по умолчанию, все из которых указывают на кодировку TS1. Например:
1\DeclareTextSymbolDefault{\texteuro}{TS1}Команда \DeclareTextSymbolDefault может использоваться для определения значения по умолчанию для любого объекта LICR без аргументов, а не только для тех, которые объявлены с помощью команды \DeclareTextSymbol в других кодировках.
1\DeclareTextAccentDefault{LICR-accent}{encoding}Аналогичное объявление существует для объектов LICR, которые принимают один аргумент, например акценты. Опять же, эту форму можно использовать для любого объекта LICR с одним аргументом. Ядро LaTeX, например, содержит ряд объявлений типа:
1\DeclareTextAccentDefault{\"}{OT1}
2\DeclareTextAccentDefault{\t}{OML}Это означает, что если \" не определен в текущей кодировке, используйте шрифт из шрифта с кодировкой OT1. Аналогично, чтобы получить акцент, выберите его из OML, если ничего лучшего не доступно. .
1\ProvideTextCommandDefault{LICR-object}[num][default]{code}Объявление \ProvideTextCommandDefault позволяет «предоставить» другой тип значения по умолчанию. Он выполняет ту же работу, что и объявление \DeclareTextCommandDefault, за исключением того, что значение по умолчанию предоставляется только в том случае, если ранее не было определено значение по умолчанию. В основном это используется во входных файлах кодирования, чтобы обеспечить своего рода тривиальные значения по умолчанию для необычных объектов LICR. Например:
1\ProvideTextCommandDefault{\textonequarter}{\ensuremath{\frac14}}
2\ProvideTextCommandDefault{\textcent}{\TextSymbolUnavailable\textcent}Такие пакеты, как textcomp, могут затем заменять такие определения объявлениями, указывающими на настоящие глифы. Использование \Provide... вместо \Declare... гарантирует, что лучшее значение по умолчанию не будет случайно перезаписано при чтении входного файла кодировки.
1\UndeclareTextCommand{LICR-object}{encoding}В некоторых случаях существующее объявление необходимо удалить, чтобы вместо него использовалось объявление по умолчанию. Это можно сделать с помощью \UndeclareTextCommand. Например, пакет textcomp удаляет определения \textdollar и \textsterling из кодировки OT1, поскольку не каждый шрифт, закодированный OT1, на самом деле имеет эти символы.
1\UndeclareTextCommand{\textsterling}{OT1}
2\UndeclareTextCommand{\textdollar} {OT1}Без этого удаления новые объявления по умолчанию для извлечения символов из TS1 не будут использоваться для шрифтов, закодированных с помощью OT1.
1\UseTextSymbol{encoding}{LICR-object}
2\UseTextAccent{encoding}{LICR-object}{simple-LICR-object}Действие, скрытое за объявлениями \DeclareTextSymbolDefault и \DeclareTextAccentDefault, также можно использовать напрямую. Предположим, например, что текущая кодировка — «U». В этом случае
1\UseTextSymbol{OT1}{\ss}
2\UseTextAccent{OT1}{\'}{a}имеет тот же эффект, что и ввод кода ниже. Обратите внимание, в частности, что a набрана в кодировке U — из другой кодировки берется только ударение.
1{\fontencoding{OT1}\selectfont\ss}
2{\fontencoding{OT1}\selectfont\'{\fontendcoding{U}\selectfont a}}Список стандартных объектов LICR
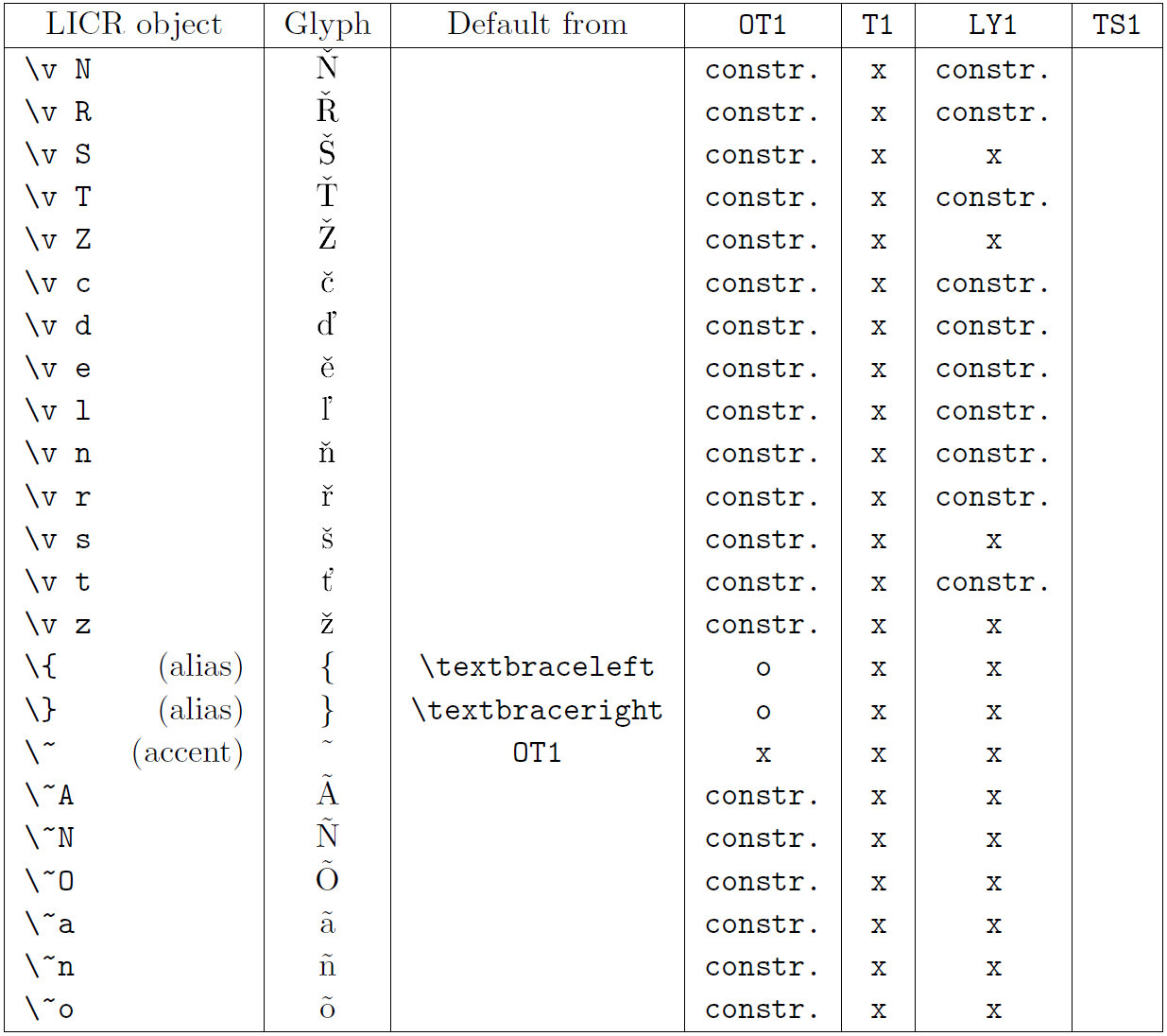
В таблице в этом подразделе представлен обзор внутренних представлений LaTeX, доступных в трех основных кодировках для языков на основе латиницы: OT1 (исходная кодировка TeX), T1 (стандартная кодировка LaTeX) и LY1 ( альтернативная 8-битная кодировка, предложенная Y&Y). Кроме того, он показывает все объекты LICR, объявленные TS1 (стандартная кодировка текстовых символов LaTeX), предоставляемые при загрузке пакета textcomp.
В первом столбце таблицы показаны имена объектов LICR в алфавитном порядке, указывая, какие объекты LICR действуют как акценты. Во втором столбце показано глифическое представление объекта.
Третий столбец описывает, имеет ли объект объявление по умолчанию. Если кодировка указана, это означает, что по умолчанию глиф извлекается из подходящего шрифта в этой кодировке; constr. означает, что по умолчанию создается из низкоуровневого кода TeX; если столбец пуст, это означает, что для этого объекта LICR не определено значение по умолчанию. В последнем случае возвращается ошибка «Символ недоступен», если вы используете его в кодировке, для которой он не имеет явного определения. Если объект является псевдонимом какого-либо другого объекта LICR, в этом столбце указывается альтернативное имя.
Столбцы с четвертого по седьмой показывают, доступен ли объект в данной кодировке. Здесь «x» означает, что объект изначально доступен (в виде глифа) в шрифтах с этой кодировкой, «o» означает, что он доступен по умолчанию для всех кодировок, а «constr.» означает, что он сгенерирован из нескольких глифы, знаки ударения или другие элементы. Если значение по умолчанию выбрано из TS1, объект LICR доступен только в том случае, если загружен пакет textcomp.
Объекты LICR. Часть 1
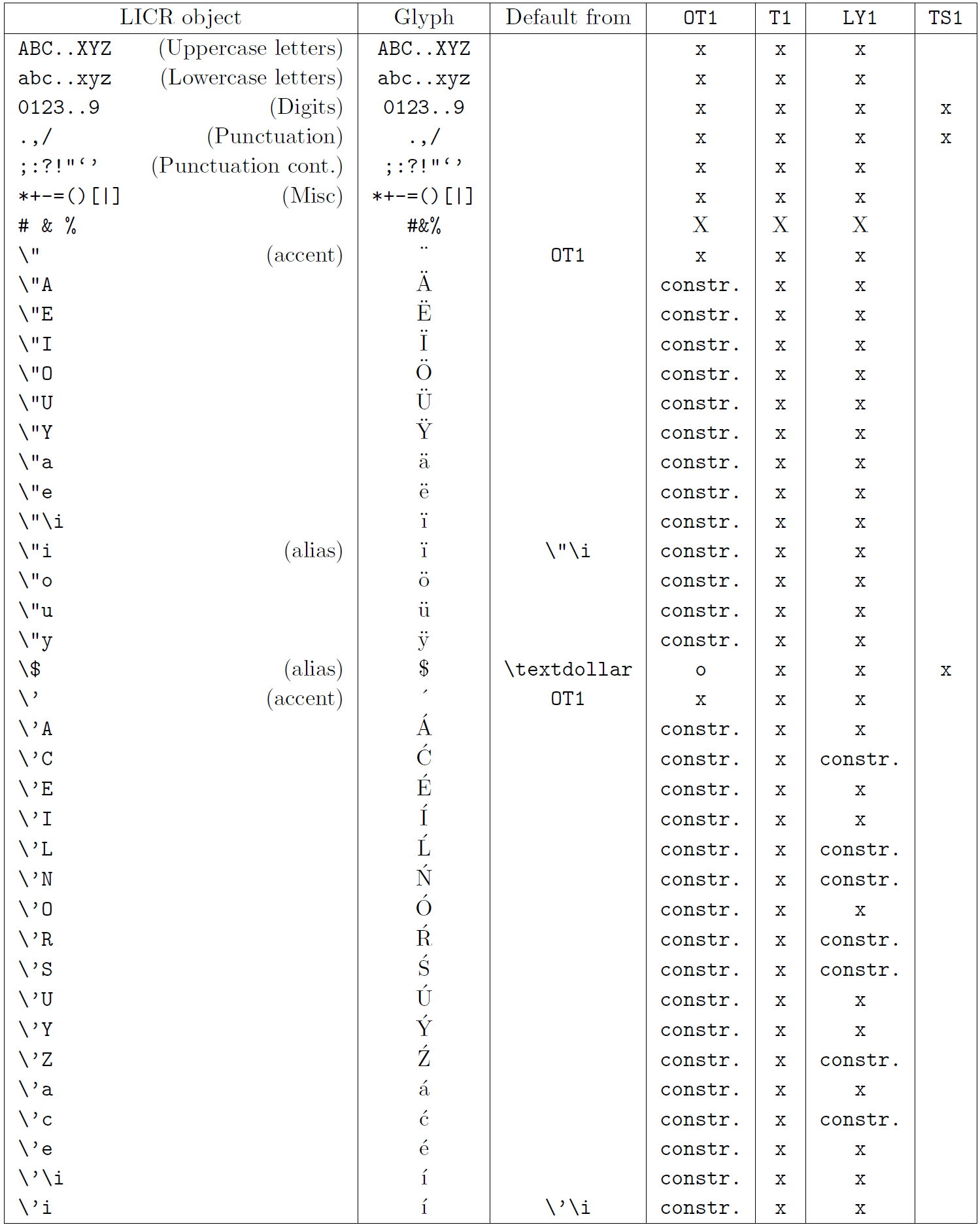
LICR-объекты. Часть 2
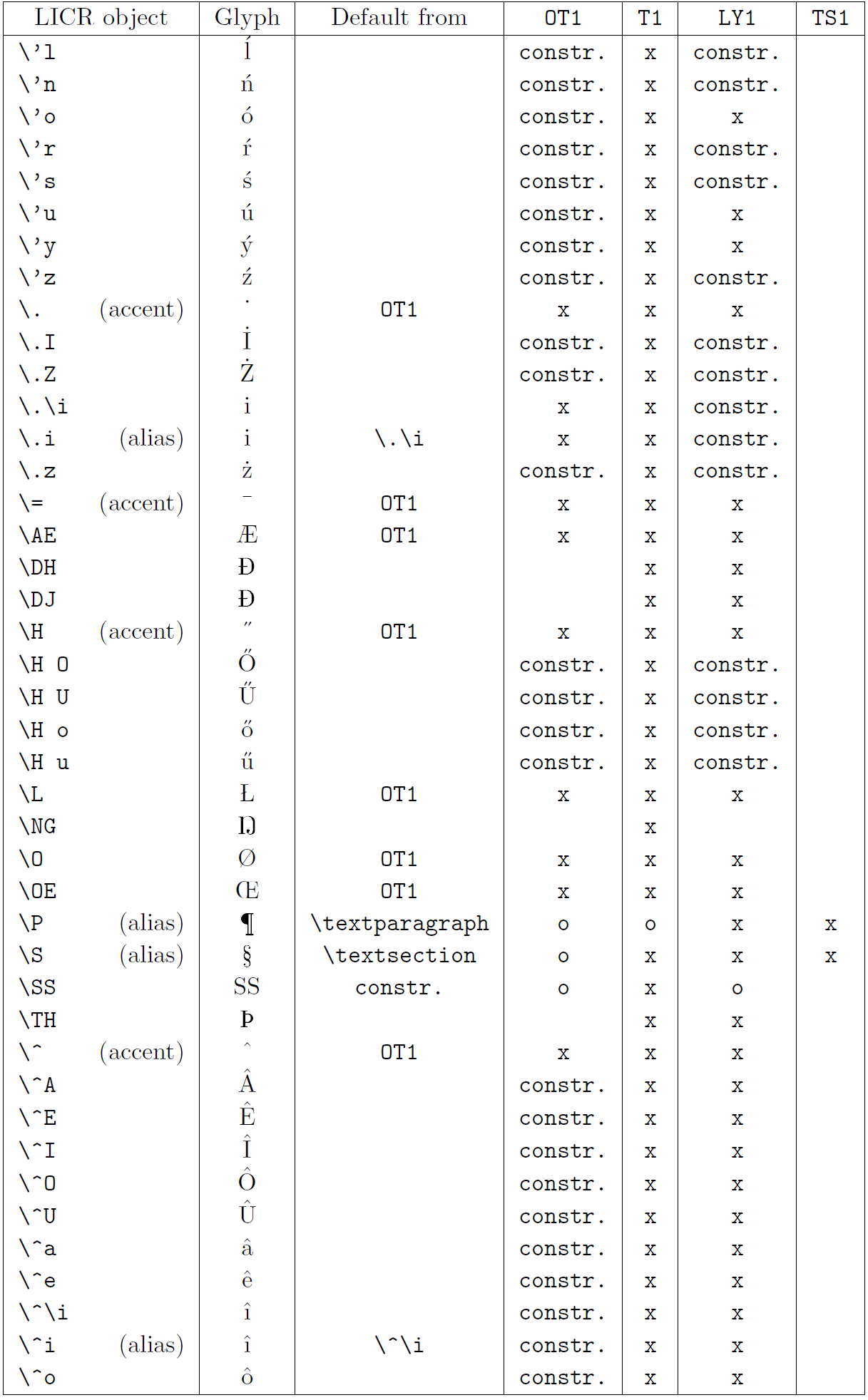
LICR-объекты. Часть 3
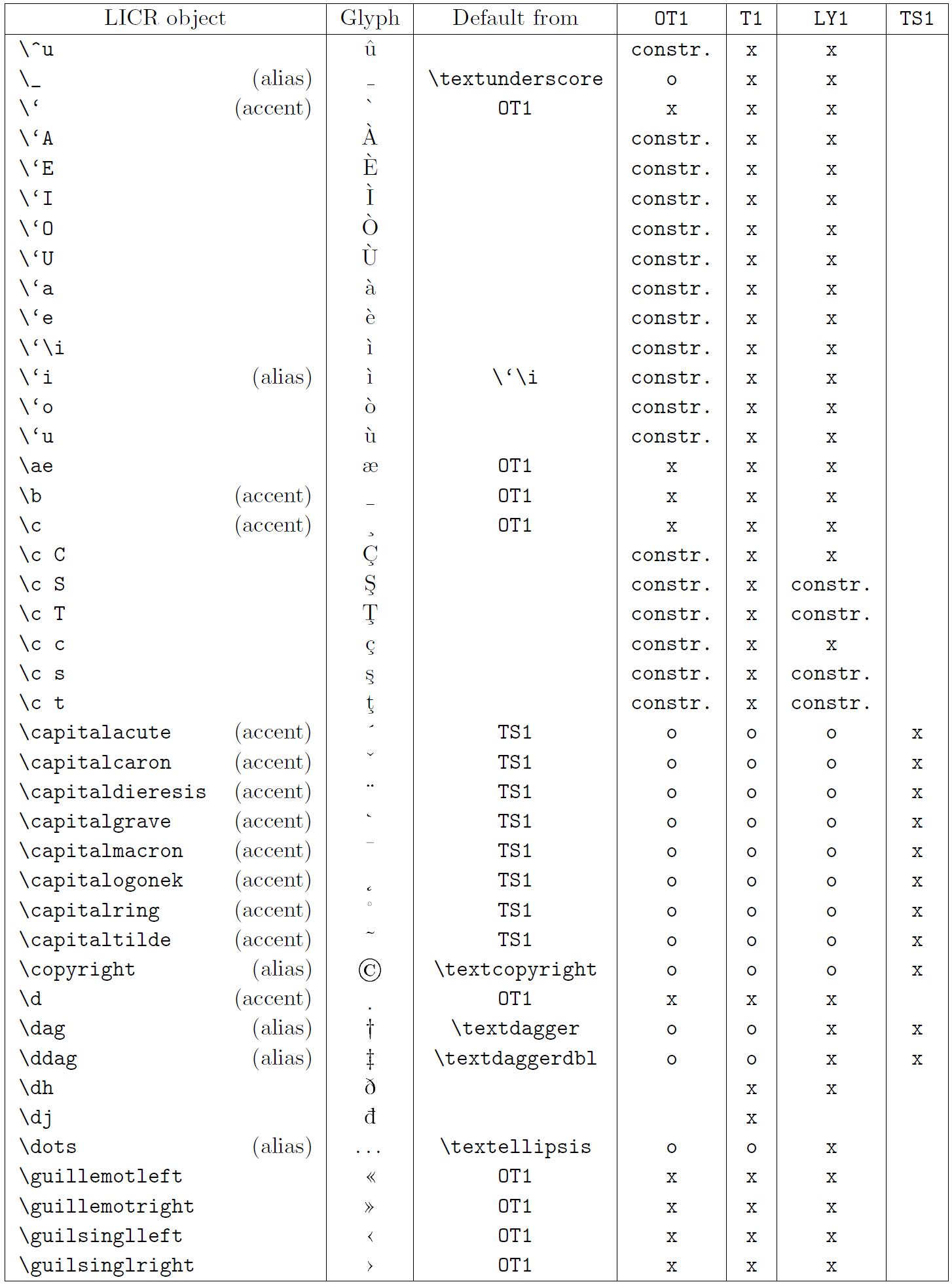
LICR-объекты. Часть 4
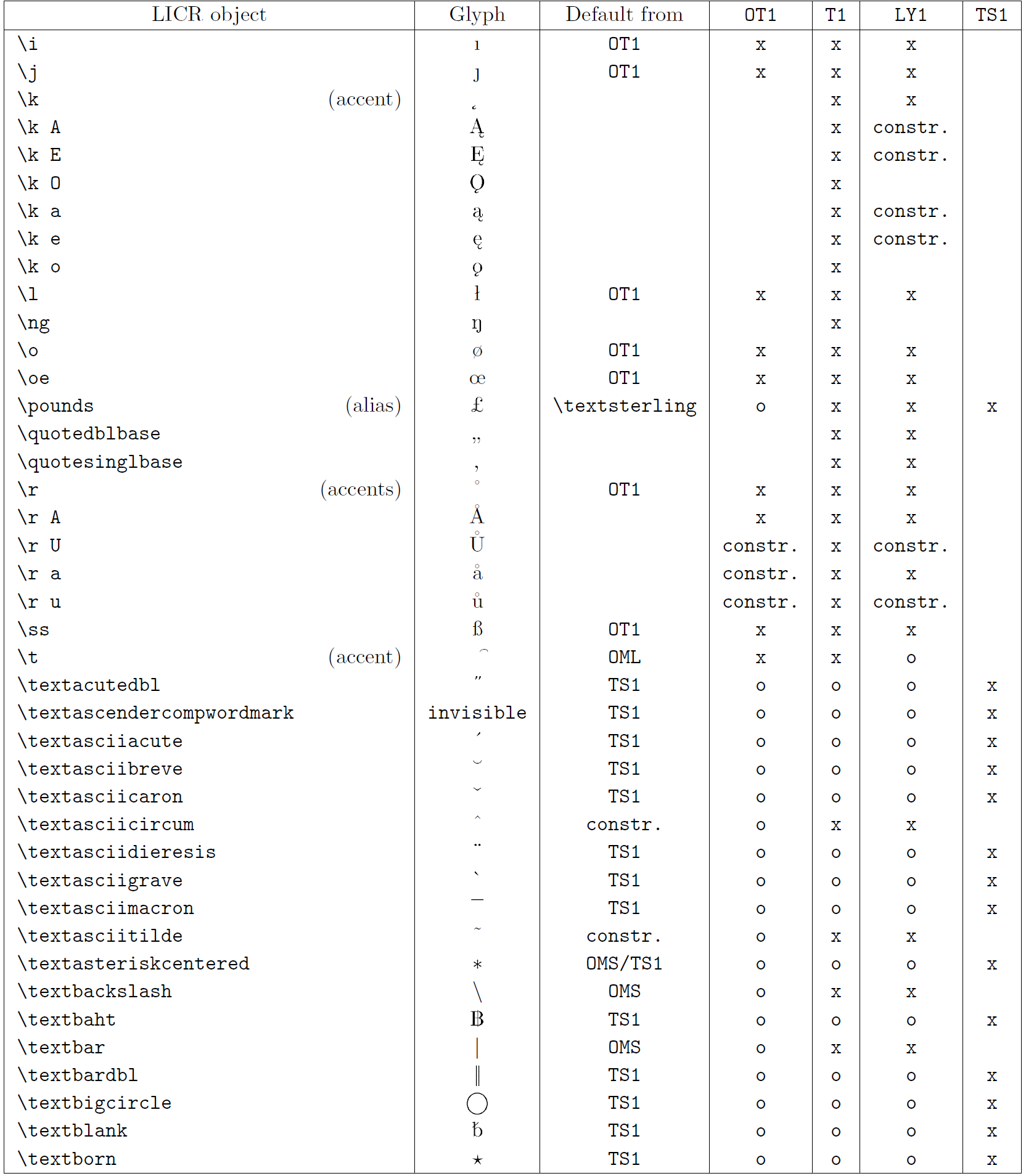
LICR-объекты. Часть 5
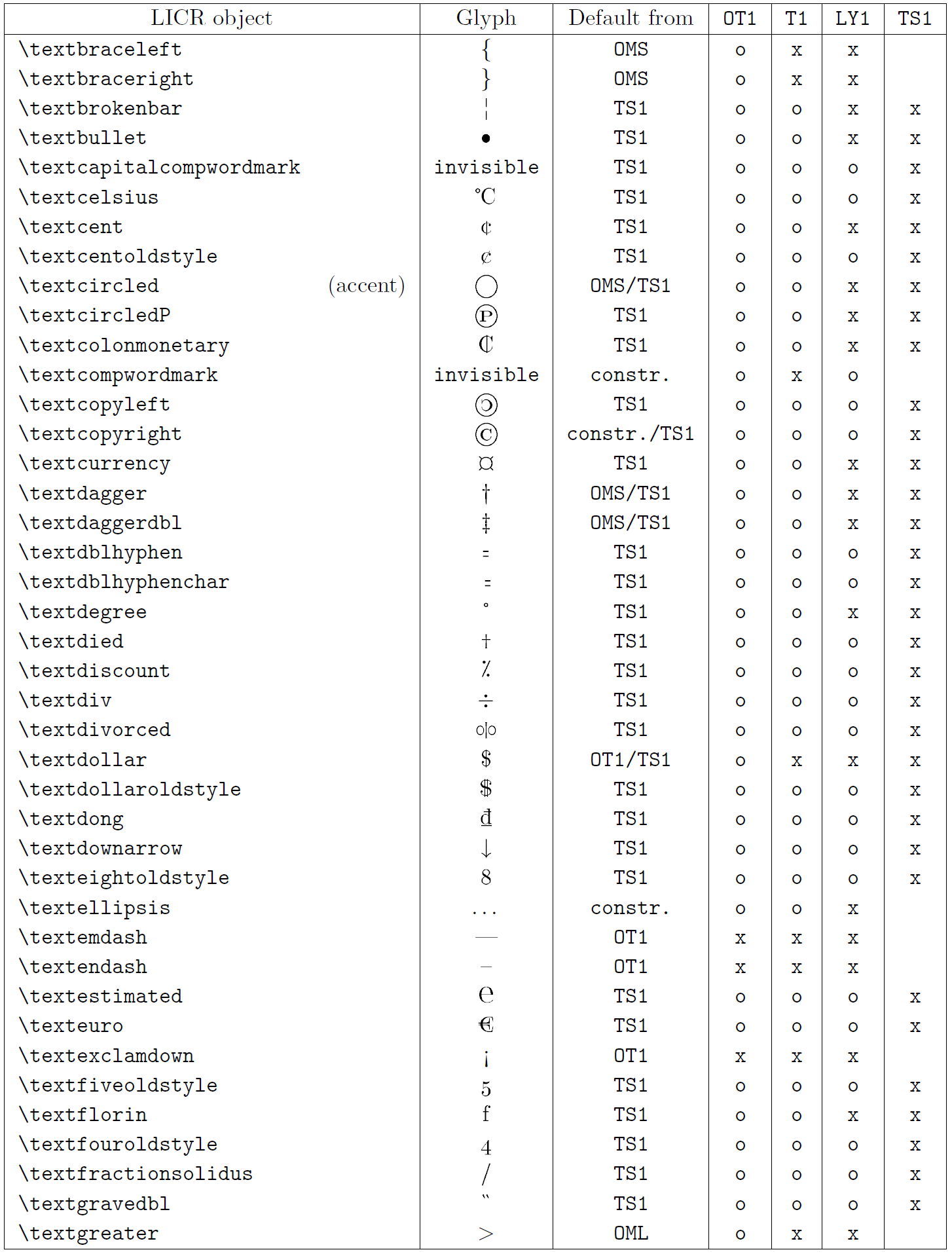
LICR-объекты. Часть 6
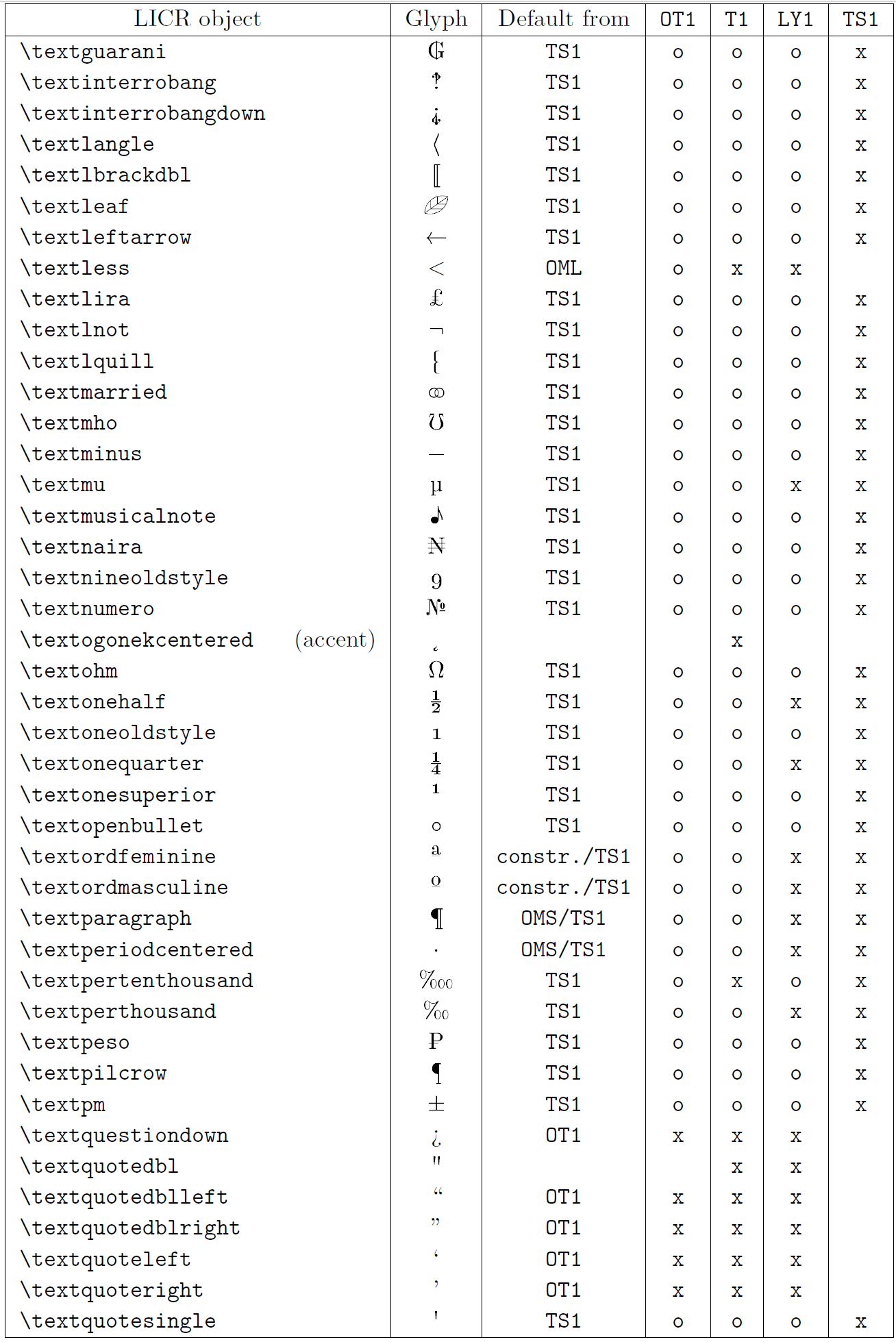
LICR-объекты. Часть 7
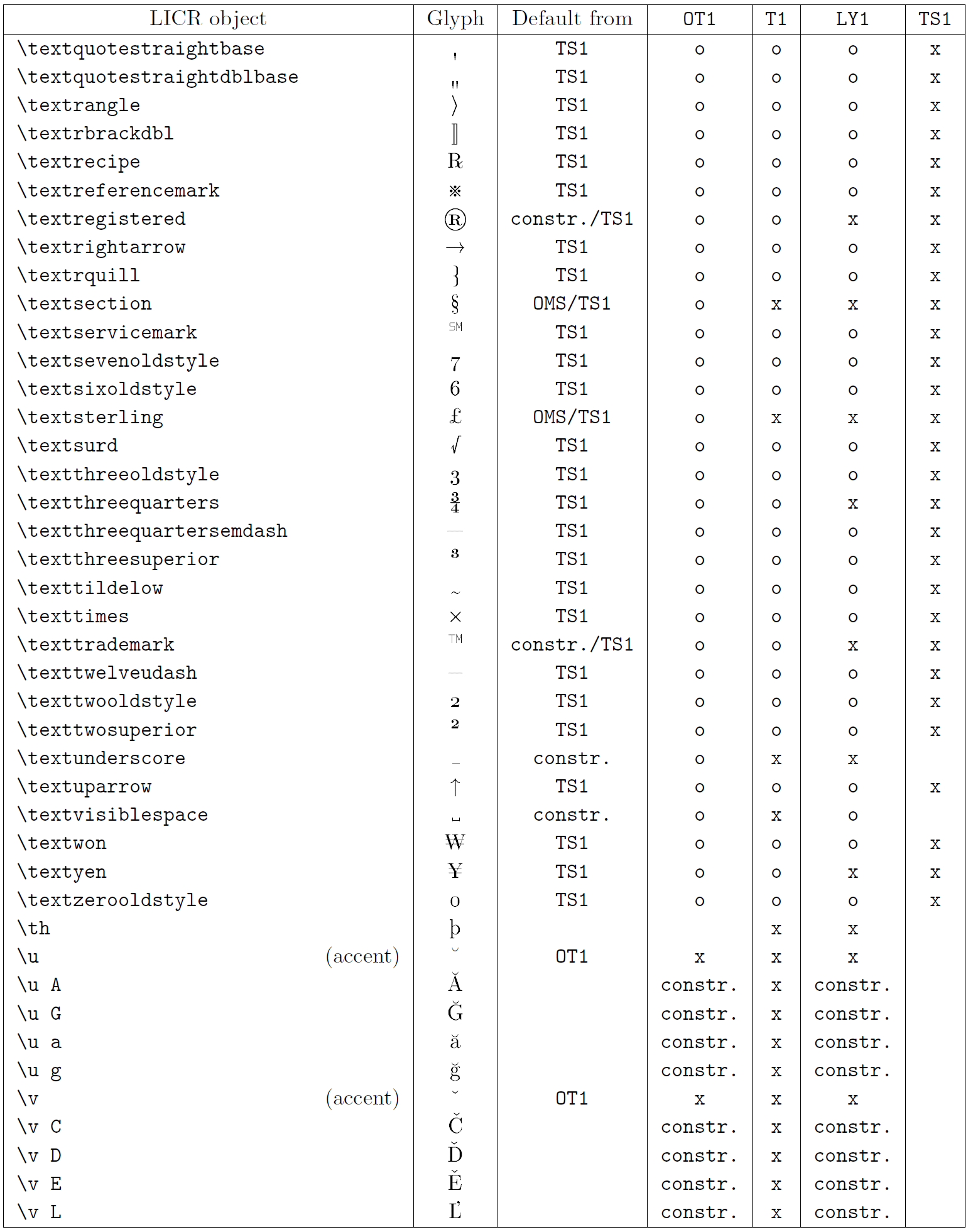
LICR-объекты. Часть 8