4. Стандартные шрифты LaTeX
Эта статья содержит краткое введение в стандартные текстовые шрифты, распространяемые вместе с LaTeX. Затем он охватывает стандартную поддержку LaTeX для кодировок ввода и шрифтов. Статья завершается описанием пакета для отслеживания обработки шрифтов LaTeX и другого пакета для отображения диаграмм глифов.
4.1. Компьютерный современный римский
Семейство шрифтов под названием Computer Modern было разработано Дональдом Кнутом вместе с TeX. До начала 1990-х годов только эти шрифты в основном можно было использовать с TeX и, следовательно, с LaTeX. Каждый из этих шрифтов содержит только 128 глифов, поэтому они не могут включать символы с диакритическими знаками в качестве отдельных глифов. Следовательно, использование этих шрифтов означает, что символы с диакритическими знаками должны создаваться с помощью примитива TeX \accent, что, в свою очередь, означает, что автоматическая расстановка переносов в словах с диакритическими символами невозможна. Хотя это ограничение приемлемо для документов на английском языке, оно является очевидным недостатком для документов на других языках.
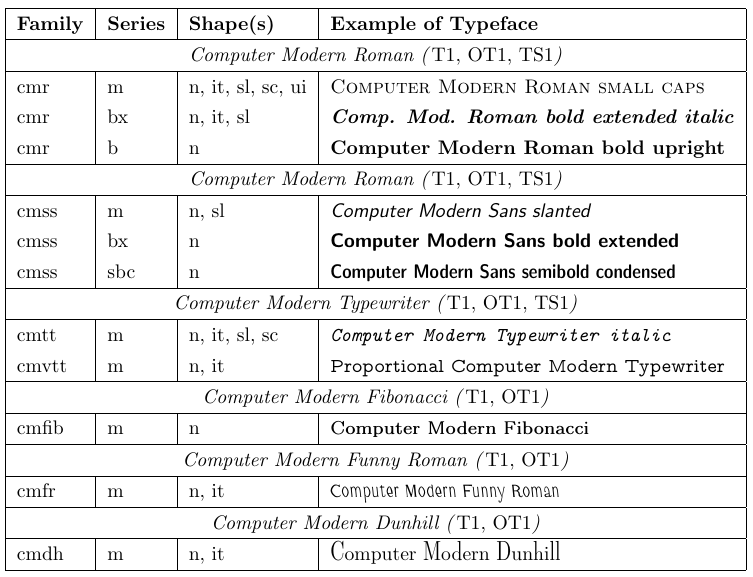
Эти недостатки вызвали большую обеспокоенность пользователей TeX в Европе и в конечном итоге привели к повторной реализации TeX в 1989 году для поддержки 8-битных символов внутри и снаружи. Стандартная 8-битная кодировка текстовых шрифтов («Т1») была разработана в 1990 году. Она содержит множество диакритических символов и позволяет осуществлять набор текста на более чем 30 языках на основе латиницы. Затем были переопределены семейства шрифтов Computer Modern и разработаны дополнительные символы, чтобы полученные шрифты полностью соответствовали этой схеме кодировки.
4.2. Выбор входной кодировки: пакет inputenc
Если вы можете вводить символы с диакритическими знаками либо одним нажатием клавиши, либо каким-либо другим способом ввода (например, нажав ``` ````, а затем ``a`, чтобы получить «a-grave»), и ваш компьютер правильно отображает их в редактор…

… тогда в идеале вам следует использовать такой текст непосредственно с LaTeX вместо того, чтобы набирать \`a, \^e и т. д.
Для таких языков, как французский и немецкий, последний подход возможен. Однако для таких языков, как русский и греческий, необходима возможность прямого ввода, поскольку почти каждый символ в этих языках имеет имя команды в качестве внутренней формы LaTeX. Например, русское определение \reftextafter по умолчанию содержит следующий текст (что означает «на следующей странице»):
1\cyrn\cyra\ \cyrs\cyrl\cyre\cyrd\cyru\cyryu\cyrshch\cyre\cyrishrt
2\ \cyrs\cyrt\cyrr\cyra\cyrn\cyri\cyrc\cyreВряд ли кто-то захочет регулярно печатать подобные вещи. Тем не менее, его преимущество заключается в универсальной переносимости, поэтому его можно правильно интерпретировать в любой установке LaTeX. С другой стороны, набрав
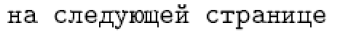
на соответствующей клавиатуре явно предпочтительнее, если можно заставить LaTeX понимать этот ввод. Проблема в том, что в файле хранятся не символы, которые мы видим в приведенной выше последовательности, а октеты, которые представляют символы. В разных обстоятельствах (при использовании разных кодировок) одни и те же октеты могут представлять разные символы.
Пока все происходит на одном компьютере и все программы интерпретируют октеты в файлах одинаково, обычно все в порядке. Если да, то имеет смысл активировать механизм автоматического перевода, встроенный в некоторые недавние реализации TeX. Но когда файл, созданный в такой среде, отправляется на другой компьютер, обработка, скорее всего, завершится неудачей или, что еще хуже, может показаться успешной, но на самом деле она приведет к неправильным результатам из-за отображения неправильных символов. Пакет inputenc был создан для решения этой проблемы. Его основная цель — сообщить LaTeX о кодировке, используемой в документе или в части документа. Это делается путем загрузки пакета с указанием имени кодировки в качестве опции. Например:
1\usepackage[cp1252]{inputenc} % Windows 1252 (Western Europe) code pageС этого момента LaTeX знает, как интерпретировать октеты в оставшейся части документа при любой установке, независимо от кодировки, используемой для других целей на этом компьютере.
Типичный пример показан ниже. Это небольшой текст, написанный в популярной в России кодировке «koi8-r». Исходный код показывает, как текст выглядит на компьютере с использованием кодировки Latin 1 (например, в Германии). Вывод показывает, что LaTeX по-прежнему мог правильно интерпретировать текст, поскольку ему было указано, какая входная кодировка использовалась.

Список кодировок, поддерживаемых в настоящее время inputenc, приведен ниже. Интерфейс хорошо документирован, и можно легко добавить поддержку новых кодировок. Поэтому стоит обратиться к документации пакета inputenc, если кодировка, используемая вашим компьютером, здесь не указана. Вы также можете поискать в Интернете файлы кодировки inputenc, созданные другими авторами. Например, кодировки, относящиеся к кириллице, распространяются вместе с другими пакетами поддержки шрифтов для кириллицы.
Стандарт ISO-8859 определяет ряд важных однобайтовых кодировок. Кодировки, относящиеся к латинице, поддерживаются inputenc. Для операционной системы Windows Microsoft определила ряд однобайтовых кодировок. Кроме того, доступны некоторые кодировки, определенные другими поставщиками компьютеров.
latin1Это кодировка ISO-8859-1 (также известная как Latin 1). Он может представлять большинство западноевропейских языков, включая албанский, каталанский, датский, голландский, английский, фарерский, финский, французский, галисийский, немецкий, исландский, ирландский, итальянский, норвежский, португальский, испанский и шведский.latin2Кодировка ISO Latin 2 (ISO-8859-2) поддерживает славянские языки Центральной Европы, использующие латинский алфавит. Его можно использовать для следующих языков: хорватского, чешского, немецкого, венгерского, польского, румынского, словацкого и словенского.latin3Этот набор символов (ISO-8859-3) используется для эсперанто, галисийского, мальтийского и турецкого языков.latin4Кодировка ISO Latin 4 (ISO-8859-4) может представлять такие языки, как эстонский, латышский и литовский.latin5Кодировка ISO Latin 5 (ISO 8859-9) тесно связана с Latin 1 и заменяет редко используемые исландские буквы из Latin 1 турецкими буквами.latin9Latin 9 (или ISO-8859-15) — это еще одна небольшая вариация Latin 1, в которую добавлен знак валюты евро, а также несколько других символов, таких как лигатура\AE, которые отсутствовали во французском и французском языках. Финский. Он становится все более популярным в качестве замены Latin 1.cp437Кодовая страница IBM 437 (латиница MS-DOS, но содержащая множество графических символов для рисования прямоугольников).cp850Кодовая страница IBM 850 (многоязычная MS-DOS, аналогичная latin1).cp852Кодовая страница IBM 852 (многоязычная MS-DOS, аналогичная latin2).cp858Кодовая страница IBM 858 (IBM 850 с добавленным символом евро).cp865Кодовая страница IBM 865 (MS-DOS, Норвегия).cp1250Кодовая страница Windows 1250 (Центральная и Восточная Европа).cp1252Кодовая страница Windows 1252 (Западная Европа).cp1257Кодовая страница Windows 1257 (Балтика).ansinewкодировка ANSI Windows 3.1; синоним cp1252.decmultiКодировка многонационального набора символов DEC.applemacКодировка Macintosh (стандартная).macceКодовая страница Macintosh для Центральной Европы.nextДалее Компьютерное кодирование.utf8Поддержка кодировки Unicode UTF8.
Большинство установок TeX по умолчанию принимают 8-битные символы. Тем не менее, без дальнейших корректировок, подобных тем, которые выполняются с помощью inpuenc, результаты могут быть непредсказуемыми: некоторые символы могут исчезнуть, или вы можете получить любой символ, присутствующий в текущем шрифте в указанном октете, который может быть, а может и не быть. желаемый глиф. Такое поведение долгое время было значением по умолчанию, поэтому оно не было изменено в LaTeX2e, поскольку некоторые люди полагаются на него. Однако, чтобы гарантировать возможность обнаружения таких ошибок, inputenc предлагает опцию ascii, которая делает любой символ за пределами диапазона 32–126 недопустимым.
1\inputencoding{encoding}Первоначально пакет inputenc был разработан для указания кодировки, используемой для документа в целом — отсюда и использование опций в преамбуле. Однако можно изменить кодировку в середине документа с помощью команды \inputencoding. Эта команда принимает имя кодировки в качестве аргумента.
Когда был разработан inputenc, большинство установок LaTeX было на компьютерах, которые использовали однобайтовые кодировки, подобные тем, которые обсуждаются в этом разделе. Однако сегодня популярна другая кодировка, поскольку системы поддерживают Unicode: UTF8. Эта кодировка переменной длины представляет символы Юникода в диапазоне от одного до четырех октетов. Поддержка кодирования была добавлена в inputenc с помощью опции utf8. Технически он не обеспечивает полную реализацию UTF8. Сопоставляются только символы Юникода, которые имеют некоторое представление в стандартных шрифтах LaTeX (т. е. в основном наборы символов латиницы и кириллицы): все остальные приведут к соответствующему сообщению об ошибке. Кроме того, не поддерживаются комбинированные символы Юникода, хотя на практике это упущение не должно быть проблемой.
1\usepackage[utf8]{inputenc}
2\usepackage{textcomp} % for Latin interpretation
3-----------------------------------------------
4German umlauts in UTF-8: ^^c3^^a4^^c3^^b6^^c3^^bc
5\par\inputencoding{latin1}% switch to Latin 1
6But interpreted as Latin 1: ^^c3^^a4^^c3^^b6^^c3^^bc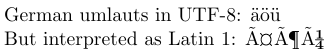
В UTF8 символы ASCII представляют собой сами себя, а большинство символов латинского алфавита представлены двумя байтами. В исходном коде примера двухбайтовые представления немецких умлаутов в UTF8 показаны в шестнадцатеричной системе счисления TeX, то есть каждому октету предшествует ^^. В редакторе, который не поддерживает UTF8, он, вероятно, увидит их похожими на вывод, который получается, когда они интерпретируются как символы Latin 1.
Пакет с более полной поддержкой UTF8 (включая поддержку корейских, китайских и японских символов), хотя, следовательно, и более сложный в настройке, — это пакет ucs, написанный Домиником Унру. Вы можете попробовать, если решение inputenc не соответствует вашим потребностям.
4.3. Выбор кодировки шрифтов с помощью пакета Fontenc.
Чтобы включить кодировку текстового шрифта для использования с LaTeX, кодировку необходимо загрузить в преамбулу или класс документа. Точнее, должны быть загружены определения для доступа к глифам в шрифтах с определенной кодировкой. Канонический способ сделать это — через пакет Fontenc, который принимает список кодировок шрифтов, разделенных запятыми, в качестве опции пакета. Последняя из этих кодировок автоматически становится кодировкой документа по умолчанию. Если загружены кодировки кириллицы, список команд, на которые влияют \MakeUppercase и \MakeLowercase, автоматически расширяется. Например,
1\usepackage[T2A,T1]{fontenc}загрузит все необходимые определения для кодировок кириллицы «T2A» и «T1» и установит последнюю в качестве кодировки документа по умолчанию.
В отличие от обычного поведения пакета, этот пакет можно загружать несколько раз с разными параметрами команды \usepackage. Это необходимо для того, чтобы класс документа мог загружать определенный набор кодировок, а пользователь мог загружать еще больше кодировок в преамбулу. Загрузка кодировок более одного раза выполняется без побочных эффектов, за исключением потенциального изменения кодировки шрифта документа по умолчанию.
Если в документе используются пакеты языковой поддержки (например, поставляемые с системой babel), часто бывает так, что необходимые кодировки шрифтов уже загружены пакетом поддержки.
4.4. Как отследить выбор шрифта с помощью пакета «tracefnt»
Для обнаружения проблем в системе выбора шрифтов можно использовать пакет tracefnt. Он поддерживает несколько опций, позволяющих настроить объем информации, отображаемой NFSS на экране и в файле стенограммы.
errorshowЭта опция подавляет все предупреждения и информационные сообщения на терминале; они будут записаны только в файл стенограммы. Будут показаны только реальные ошибки. Перед печатью важной публикации следует внимательно изучить файл расшифровки, поскольку предупреждения о подменах шрифтов и т. д. могут означать, что конечный результат будет неверным.warningshowЕсли указана эта опция, на терминале отображаются предупреждения и ошибки. Этот параметр дает вам такую же подробную информацию, как и LaTeX2e без загруженного пакетаtracefnt.infoshowЭта опция используется по умолчанию при загрузке пакетаtracefnt. Дополнительная информация, которая обычно записывается только в файл стенограммы, теперь также отображается на вашем терминале.debugshowЭта опция дополнительно показывает информацию об изменении шрифта текста и восстановлении таких шрифтов в конце группы фигурных скобок или в конце окружения. Будьте осторожны при включении этой опции, поскольку она может создавать очень большие файлы расшифровок.pausingЭта опция превращает все предупреждения в ошибки, чтобы помочь обнаружить проблемы в важных публикациях.loadingЭта опция показывает загрузку внешних шрифтов. Однако если в используемый вами формат или класс документа уже загружены некоторые шрифты, они не будут отображаться с помощью этой опции.
4.5. Как отобразить таблицы и образцы шрифтов с помощью nfssfont.tex
Файл с именем nfssfont.tex можно использовать для тестирования новых шрифтов, создания таблиц шрифтов, отображающих все символы, и выполнения других операций, связанных со шрифтами. Вы можете найти этот файл в любом дистрибутиве LaTeX. Когда вы запустите этот файл через LaTeX, вам будет предложено ввести имя тестируемого шрифта. Ответом может быть либо имя внешнего шрифта без расширения, например cmr10 (Computer Modern Roman 10pt), если оно вам известно, либо пустое имя шрифта. В последнем случае вам будет предложено указать спецификацию шрифта NFSS: имя кодировки (по умолчанию «T1»), имя семейства шрифтов (по умолчанию «cmr»), серию шрифта (по умолчанию «m»), форму шрифта ( по умолчанию n) и размер шрифта (по умолчанию 10pt). Затем программа загружает внешний файл, соответствующий этой классификации.
Далее вам будет предложено ввести команду. Самым важным из них, вероятно, является \table, который создает таблицу шрифтов, подобную приведенной ниже. Команда \text также интересна, поскольку она создает более длинный образец текста. Чтобы переключиться на новый тестовый шрифт, введите \init; чтобы завершить тест, введите \bye или \stop; и чтобы узнать обо всех других доступных тестах, введите \help.
1**********************************************
2* NFSS font test program version <v2.2b>
3*
4* Follow the instructions
5**********************************************
6
7Input external font name, e.g., cmr10
8(or <enter> for NFSS classification of font):
9
10\currfontname=cmr10
11Now type a test command (\help for help):)
12*\table
13
14*\newpage
15*\init
16Input external font name, e.g., cmr10
17(or <enter> for NFSS classification of font):
18
19\currfontname=
20*** NFSS classification ***
21
22Font encoding [T1]:
23
24\encoding=OT1
25(ot1enc.def)
26Font family [cmr]:
27
28\family=cmdh
29Font series [m]:
30
31\series=m
32Font shape [n]:
33
34\shape=n
35Font size [10pt]:
36
37\size=10
38(ot1cmdh.fd) Now type a test command (\help for help):
39*\text
40
41*\bye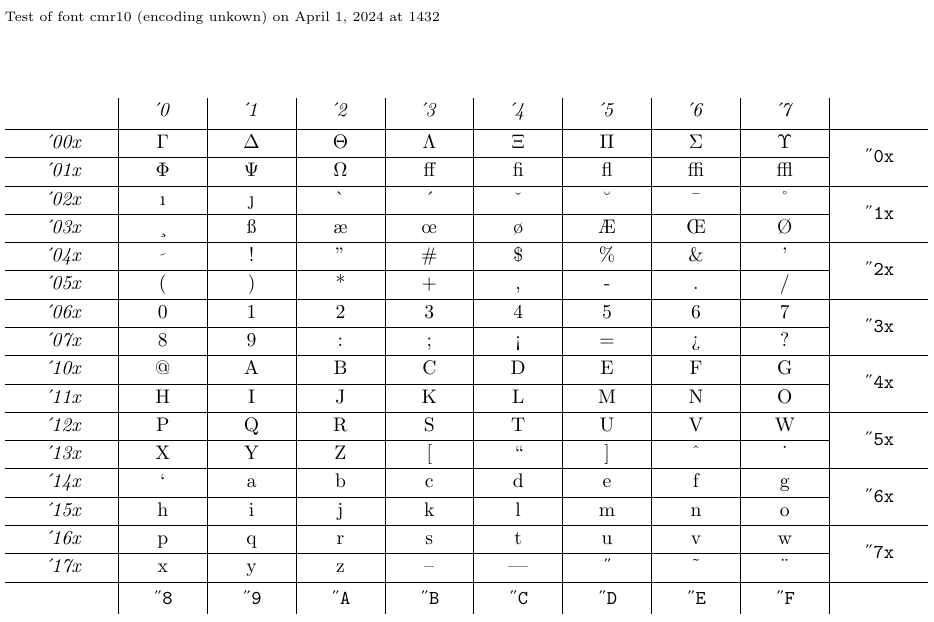

There are two points to be aware of. First, the
nfssfont.texprogram issues an implicit\initcommand, so the first line of input should either contain a font name or be completely empty to indicate that an NFSS classification follows. Second, the input to\initmust appear on individual lines with nothing else (not even a comment) because the line ending indicates the end of the response to a prompt likeFont encoding[T1]: \encoding=that you will get.