7. Модель LaTeX для кодування символів
У цій статті детально розглядаються кодування LaTeX. Він починається з обговорення потоку символьних даних у системі LaTeX. Далі ми детальніше розглянемо внутрішню модель представлення символьних даних у LaTeX, а потім обговоримо механізми, які використовуються для відображення вхідних даних через кодування вхідних даних у це внутрішнє представлення. Нарешті, ми пояснюємо, як внутрішнє представлення перекладається через вихідні кодування у форму, необхідну для верстки.
7.1. Потік символьних даних у LaTeX
Обробка документа за допомогою LaTeX починається з інтерпретації даних, присутніх в одному або кількох вихідних файлах. Ці дані, що представляють вміст документа, зберігаються у вихідних файлах як послідовності октетів, що представляють символи. Щоб правильно інтерпретувати ці октети, будь-яка програма (включаючи LaTeX), яка використовується для обробки файлу, повинна знати відображення між абстрактними символами та октетами, які їх представляють. Іншими словами, він повинен знати кодування, яке використовувалося під час запису файлу.
З неправильним відображенням уся подальша обробка буде більш-менш помилковою, якщо тільки файл не містить лише символів підмножини, спільних як у правильному, так і в неправильному кодуванні. На цьому етапі LaTeX робить фундаментальне припущення: майже всі видимі символи ASCII (десяткові числа 32-126) представлені числом, яке вони мають у кодовій таблиці ASCII.

Однією з причин цього припущення є те, що більшість 8-бітних кодувань, які використовуються сьогодні, мають спільну 7-бітну площину. Інша причина полягає в тому, що для ефективного використання TeX більшість видимої частини ASCII потрібно обробити як символи категорії літери - оскільки лише символи цієї категорії можна використовувати в багатосимвольних іменах команд у TEX - або категорії інше - оскільки TEX, наприклад, не розпізнає десяткові цифри як частину числа, якщо вони не мають цього коду категорії.
Коли символ (або, точніше, 8-бітне число) оголошено як такий, що належить до категорії літера або інше в TeX, тоді це 8-бітне число буде прозоро передано через TeX. Це означає, що TeX набере будь-який символ у шрифті в позиції, адресованій цим номером.
Як наслідок вищезгаданого припущення, шрифти, призначені для використання в загальному тексті, вимагають, щоб (більшість) видимих символів ASCII були присутні в шрифті та закодовані відповідно до кодування ASCII.
Усім іншим 8-бітним числам (за межами видимого ASCII), потенційно присутнім у вхідному файлі, присвоюється код категорії active, що змушує їх діяти як команди в TeX. Тому LaTeX може перетворити їх за допомогою вхідних кодувань у форму, яку ми назвемо внутрішнє представлення символів LaTeX (LICR).
Що стосується кодування Unicode UTF8, воно обробляється аналогічно. Символи ASCII представляють себе, а початкові октети для багатобайтового представлення діють як активні символи, які сканують вхідні дані для пошуку решти октетів. Результат буде перетворено на об’єкт у LICR, якщо він зіставлений, або LaTeX видасть помилку, якщо даний символ Unicode не зіставлено.
Найважливіша річ щодо об’єктів у LICR полягає в тому, що представлення 7-бітових символів ASCII є інваріантним до будь-якої зміни кодування, оскільки всі вхідні кодування мають бути прозорими щодо видимого ASCII. Кодування виводу (або шрифту) служить потім для зіставлення внутрішніх представлень символів із позиціями гліфів у поточному шрифті, який використовується для набору тексту, або, у деяких випадках, для ініціювання більш складних дій. Наприклад, він може розмістити акцент (присутній в одній позиції в поточному шрифті) над деяким символом (в іншій позиції в поточному шрифті), щоб отримати друковане зображення абстрактного символу, представленого командою(-ами) у внутрішньому кодування символів.
LICR кодує всі можливі символи, адресовані в LaTeX. Таким чином, це набагато більше, ніж кількість символів, які можуть бути представлені одним шрифтом TeX (який може містити щонайбільше 256 гліфів). У деяких випадках символ у внутрішньому кодуванні можна відобразити за допомогою шрифту шляхом комбінування гліфів, наприклад символів із акцентами. Однак, коли внутрішній символ потребує спеціальної форми, неможливо підробити його, якщо цей гліф відсутній у шрифті.
Незважаючи на це, модель LaTeX для кодування символів підтримує автоматичні механізми для отримання гліфів з різних шрифтів, так що символи, відсутні в поточному шрифті, будуть набрані, якщо доступний відповідний додатковий шрифт, який їх містить.
7.2. Внутрішнє представлення символів LaTeX (LICR)
Текстові символи представлені всередині LaTeX одним із трьох способів.
Уявлення як персонажі
Невелика кількість персонажів представлена «самими собою». Наприклад, латинська буква A представлена як символ «A». Такі символи наведені в таблиці вище. Вони утворюють підмножину видимого ASCII, і всередині TeX усім їм присвоюється код категорії letter або other. Деякі символи з видимого діапазону ASCII не представлені таким чином, тому що вони є частиною синтаксису TeX або тому, що вони присутні не в усіх шрифтах. Якщо хтось використовує, наприклад, «<» у тексті, поточне кодування шрифту визначає, чи буде надруковано «<» (T1) або, можливо, перевернутий знак оклику (OT1).
Представлення як послідовності символів
Механізм внутрішньої лігатури TeX може генерувати нові символи з послідовності вхідних символів. Насправді це властивість шрифту, хоча деякі такі послідовності були спеціально розроблені, щоб служити ярликами для введення символів, які інакше важко адресувати за допомогою більшості клавіатур. Лише кілька символів, згенерованих таким чином, вважаються такими, що належать до внутрішнього представлення LaTeX. Сюди входять тире «En» і «Em Dash», які утворюються за допомогою лігатур -- і ---, а також початкові та закриваючі подвійні лапки, які генеруються `` і '' (останній зазвичай також може бути представлений одним "). Хоча більшість шрифтів також реалізують !` і ?` для створення інвертованих знаків оклику та питання, це не універсально доступний у всіх шрифтах, тому всі такі символи мають альтернативне внутрішнє представлення як команда (наприклад, \textendash або \textexclamdown).
Представлення у вигляді команд «специфічного кодування шрифту».
Третій спосіб внутрішнього представлення символів у LaTeX, який охоплює більшість символів, — це спеціальні команди LaTeX (або послідовності команд), які залишаються нерозгорнутими при записі у файл або при розміщенні в рухомому аргументі. Ми називатимемо такі спеціальні команди специфічними для кодування шрифту командами, тому що їхнє значення залежить від кодування шрифту, яке зараз використовується, коли LaTeX готовий їх набирати. Такі команди оголошуються за допомогою спеціальних декларацій, як ми обговоримо нижче, які зазвичай вимагають окремих визначень для кожного кодування шрифту. Якщо для поточного кодування не існує визначення, або використовується стандартне кодування (якщо доступне), або користувачеві відображається повідомлення про помилку. Коли кодування шрифту змінюється в певному місці документа, визначення команд, що стосуються кодування, не змінюються відразу, оскільки це означатиме зміну великої кількості команд на місці. Натомість ці команди реалізовано таким чином, що після їх використання вони помічають, якщо їхнє поточне визначення більше не підходить для чинного кодування шрифту. У такому випадку вони викликають своїх аналогів у поточному кодуванні шрифту для виконання фактичної роботи.
Набір специфічних для кодування шрифту команд не є фіксованим, а неявно визначений як об’єднання всіх команд, визначених для окремих кодувань шрифтів. Таким чином, нові кодування шрифтів можуть знадобитися, коли до LaTeX додаються нові кодування шрифтів.
7.3. Вхідні кодування
Після завантаження пакета inputenc стають доступними дві декларації \DeclareInputText і \DeclareInputMath для відображення 8-розрядних символів введення в об’єкти LICR. Їх слід використовувати лише у файлах кодування (див. нижче), пакетах або, якщо необхідно, у преамбулі документа.
Ці команди приймають 8-розрядне число як свій перший аргумент, який може бути заданий як десяткове число, вісімкове число або шістнадцяткове число. Рекомендується використовувати десяткову систему запису, оскільки символи ' та/або " можуть отримати особливі значення в пакеті підтримки мови, наприклад, скорочення до наголосів, що робить вісімкову та/або шістнадцяткову систему недійсною, якщо Пакети завантажено в неправильному порядок.
1\DeclareInputText{number}{LICR-object}Команда \DeclareInputText оголошує відображення символів для використання в тексті. Його другий аргумент містить специфічну для кодування команду (або послідовність команд), тобто об’єкти LICR, на які має бути зіставлено номер символу. Наприклад,
1\DeclareInputText{239}{\"\i}відображає число 239 на специфічне для кодування представлення ‘i-umlaut’, яке є \"\i. Символи введення, оголошені таким чином, не можна використовувати в математичних формулах.
1\DeclareInputMath{number}{math-object}Якщо число представляє символ для використання в математичних формулах, тоді слід використовувати оголошення \DeclareInputMath. Наприклад, у кодуванні введення cp437de (німецька клавіатура MS-DOS),
1\DeclareInputMath{224}{\alpha}відображає число 224 на команду \alpha. Важливо зауважити, що ця декларація зробить ключ, що створює це число, придатним для використання лише в математичному режимі, оскільки \alpha більше ніде не дозволяється.
1\DeclareUnicodeCharacter{hex-number}{LICR-object}Це оголошення доступне, лише якщо використовується параметр utf8. Він відображає числа Unicode на об’єкти LICR (тобто символи, які можна використовувати в тексті). Наприклад,
1\DeclareUnicodeCharacter{00A3}{\textsterling}
2\DeclareUnicodeCharacter{011A}{\v E}
3\DeclareUnicodeCharacter{2031}{\textpertenthousand}Теоретично між двома просторами повинно бути лише одне унікальне двонаправлене відображення, щоб усі такі оголошення вже могли бути зроблені автоматично, коли вибрано параметр utf8. На практиці все трохи складніше. По-перше, автоматичне надання всієї таблиці потребувало б величезного обсягу пам’яті TeX. Крім того, існує багато символів Unicode, для яких не існує об’єктів LICR, і навпаки, багато об’єктів LICR не мають еквівалента в Unicode. Цю проблему вирішено в пакеті inputenc шляхом завантаження лише тих відображень Unicode, які відповідають кодуванням, використаним у конкретному документі (наскільки вони відомі), і відповіді на будь-який інший запит символу Unicode відповідним повідомленням про помилку. Тоді завданням користувача стає або надати правильну інформацію про відображення, або, якщо необхідно, завантажити додаткове кодування шрифту.
Як ми зазначали вище, декларації кодування вхідних даних можна використовувати в пакетах або в преамбулі документа. Щоб усе працювало таким чином, важливо спочатку завантажити пакет inputenc, вибравши таким чином відповідне кодування. Подальші оголошення кодування вхідних даних діятимуть як заміна (або доповнення до) тих, що визначені поточним кодуванням вхідних даних.
Під час використання пакета inputenc ви можете побачити команду \@tabacckludge, яка розшифровується як “tabbing accent kludge”. Це необхідно, тому що поточна версія LaTeX успадкувала перевантаження команд \=, \` і \', які зазвичай позначають певні наголоси (тобто є командами, специфічними для кодування), але мають спеціальні значення в середовищі tabbing. Ось чому відображення, які включають будь-який із цих наголосів, потрібно кодувати особливим чином. Наприклад, якщо ви хочете відобразити 232 на символ ’e-grave’ (який має внутрішнє представлення \`e), вам слід написати
1\DeclareInputText{232}{\@tabacckludge`e}замість
1\DeclareInputText{232}{\`e}Відображення в тексті та/або математикі
З технічних і концептуальних причин TeX робить дуже сильну різницю між символами, які можна використовувати в тексті та в математиці. За винятком видимих символів ASCII, команди, які створюють символи, зазвичай можна використовувати в текстовому або математичному режимі, але не в обох режимах.
Файли вхідного кодування для 8-бітного кодування
Вхідні кодування зберігаються у файлах із розширенням .def, де базове ім’я є назвою вхідного кодування (наприклад, latin1.def). Такі файли повинні містити лише команди, розглянуті в поточному розділі.
Файл має починатися з ідентифікаційного рядка, який містить команду \ProvidesFile, що описує природу файлу. наприклад:
1\ProvidesFile{latin1.def}[2000/07/01 v0.996 Input encoding file]Якщо є зіставлення команд, що стосуються певного кодування, які можуть бути недоступні, якщо не завантажено додаткові Пакети, можна оголосити для них значення за замовчуванням за допомогою \ProvideTextCommandDefault. Наприклад:
1\ProvideTextCommandDefault{\textonehalf}{\ensurement{\frac12}}
2\ProvideTextCommandDefault{\textcent}{\TextSymbolUnavailable\textcent}Команда \TextSymbolUnavailable видає попередження про те, що певний символ недоступний для поточних шрифтів. Це може бути корисним як стандартне значення, коли такі символи доступні, лише якщо завантажено спеціальні шрифти та немає відповідного способу підробити символи за допомогою існуючих символів (як це було можливо для типового значення для \textonehalf).
Решта файлу має включати лише оголошення вхідного кодування \DeclareInputText і \DeclareInputMath. Як згадувалося вище, використання останньої команди не рекомендується, але дозволено. Жодні інші команди не повинні використовуватися у вхідному файлі кодування, зокрема, жодні команди, які перешкоджають багаторазовому читанню файлу (наприклад, \newcommand), оскільки файли кодування часто завантажуються кілька разів в один документ.
Вхідні файли зіставлення для UTF8
Як згадувалося раніше, відображення з Unicode на об’єкти LICR організоване таким чином, що дозволяє LaTeX завантажувати лише ті відображення, які відповідають кодуванням шрифтів, що використовуються в поточному документі. Це робиться шляхом спроби завантажити для кожного кодування <ім’я> файл <ім’я>enc.dfu, який, якщо існує, містить інформацію зіставлення для тих символів Юнікоду, наданих цим конкретним кодуванням. Окрім ряду оголошень \DeclareUnicodeCharacter, такі файли мають містити лише рядок \ProvidesFile.
Оскільки різні кодування шрифтів часто надають більш-менш однакові символи, досить часто оголошення для того самого символу Unicode з’являються в різних файлах .dfu. Тому дуже важливо, щоб ці оголошення в різних файлах були ідентичними. В іншому випадку декларація, завантажена останньою, збережеться, і вона може відрізнятися від документа до документа.
Отже, будь-хто, хто хоче надати новий файл .dfu для кодування, яке раніше не розглядалося, повинен уважно перевірити існуючі визначення у файлах .dfu на предмет відповідних кодувань. Стандартні файли, надані з inputenc, гарантовано мають уніфіковані визначення. Насправді всі вони створені з одного списку, який відповідним чином розділений. Повний список існуючих наразі відображень можна знайти у файлі utf8enc.dfu.
7.4. Вихідні кодування
Ми вже згадували, що вихідні кодування визначають відображення з LICR на гліфи (або конструкції, створені з гліфів), доступні у шрифтах, які використовуються для набору. На ці відображення всередині LaTeX посилаються імена з двох або трьох букв (наприклад, OT1 і T3). Ми говоримо, що певний шрифт знаходиться в певному кодуванні, якщо відображення відповідає позиціям гліфів у шрифті. Давайте тепер подивимося на точні компоненти такого відображення.
Символи, які внутрішньо представлені символами ASCII, просто передаються до шрифту. Іншими словами, TeX використовує код ASCII для вибору гліфа з поточного шрифту. Наприклад, символ «A» з кодом ASCII 65 призведе до набору гліфа в позиції 65 у поточному шрифті. Ось чому LaTeX вимагає, щоб шрифти для тексту містили всі такі літери ASCII у їхніх кодових позиціях ASCII, оскільки немає способу взаємодії з цим базовим механізмом TeX. Таким чином, для видимого ASCII відображення один до одного неявно присутнє в усіх вихідних кодуваннях.
Символи, внутрішньо представлені як послідовності символів ASCII (наприклад, «--»), обробляються наступним чином: коли поточний шрифт завантажується вперше, TeX повідомляється, що шрифт містить ряд так званих лігатурних програм. Ці програми визначають певні послідовності символів, які не слід набирати безпосередньо, а замінити деякими іншими гліфами зі шрифту. Наприклад, коли TeX зустрічає “--” у вхідних даних (тобто код ASCII 45 двічі), програма лігатури може натомість спрямувати його до гліфа в позиції 123 (який тоді утримуватиме гліф тире). Знову ж таки, немає можливості взаємодіяти з цим механізмом.
Тим не менш, більша частина внутрішнього представлення символів складається зі специфічних для кодування шрифту команд, які відображаються за допомогою описаних нижче декларацій. Усі оголошення мають однакову структуру в своїх перших двох аргументах: специфічна для кодування шрифту команда (або її перший компонент, якщо це послідовність команд), за якою йде назва кодування. Решта аргументів залежатиме від типу оголошення.
Отже, кодування XYZ визначається купою декларацій, усі мають назву XYZ як другий аргумент. Потім, звичайно, деякі шрифти повинні бути закодовані в цьому кодуванні. Насправді розробка кодувань шрифтів зазвичай відбувається у зворотному порядку - хтось починає з існуючого шрифту, а потім надає відповідні оголошення для його використання. Ця колекція оголошень отримує відповідне ім’я, наприклад OT1. Нижче ми візьмемо шрифт ecrm1000 (див. діаграму гліфів), кодування шрифту якого в LaTeX називається T1, і створимо відповідні оголошення для доступу до гліфів із шрифту, закодованого таким чином. Сині символи в діаграмі гліфів – це ті символи, які мають бути присутніми в одній позиції в кожному кодуванні тексту, оскільки вони прозоро передаються через LaTeX.
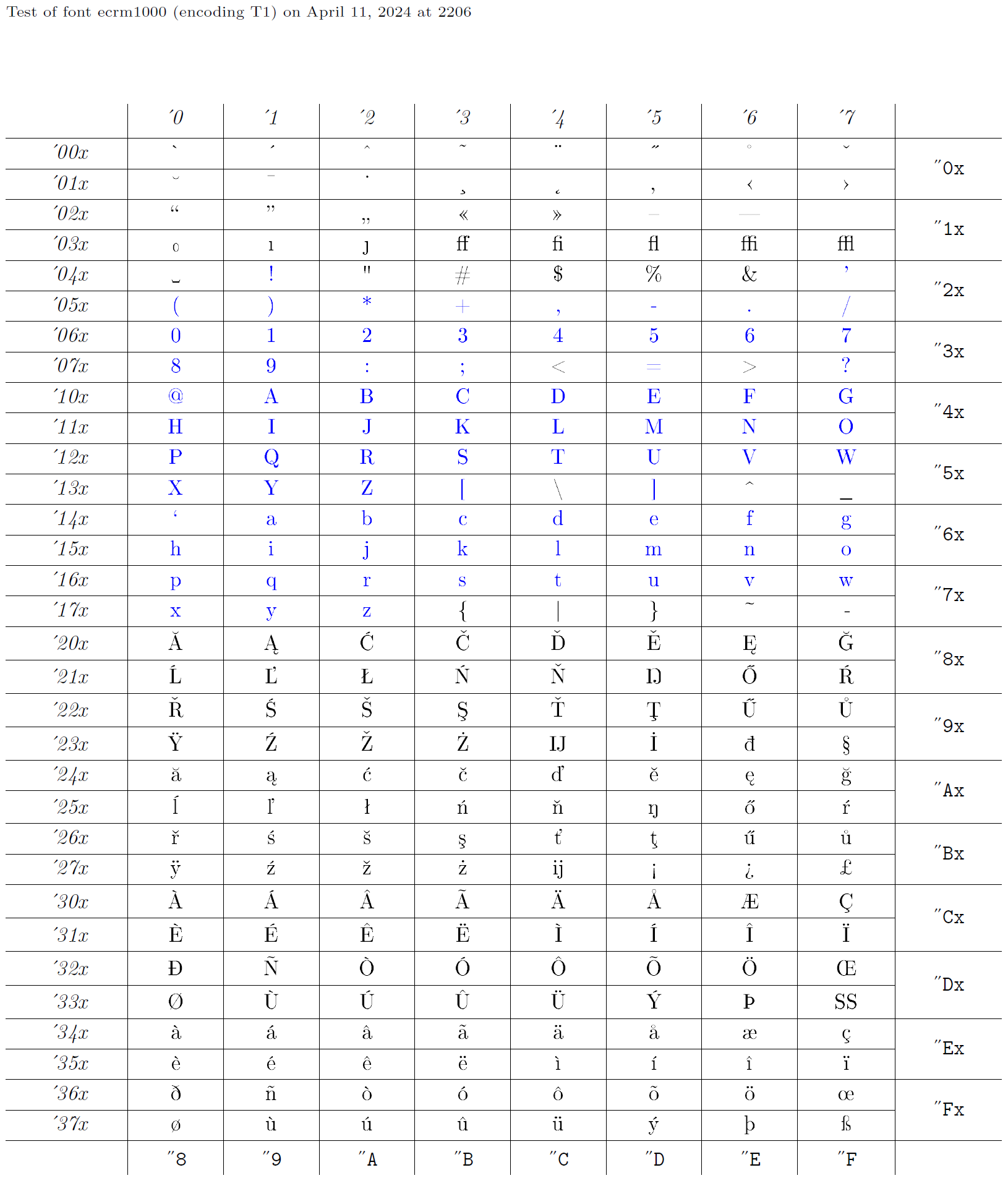
Файли вихідного кодування
Файли вихідного кодування ідентифікуються тим самим розширенням .def, що й файли вхідного кодування. Однак базова назва файлу є трохи більш структурованою. Він складається з назви кодування малими літерами, за якою йде “enc” (наприклад, “t1enc.def” для кодування “T1”).
Ці файли мають містити лише оголошення, описані в поточному розділі. Оскільки файли вихідного кодування можуть бути прочитані LaTeX кілька разів, важливо дотримуватися цього правила та утримуватися від використання, наприклад, \newcommand, який запобігає читанню такого файлу більше одного разу!
Знову ж таки, файл вихідного кодування починається з рядка ідентифікації, що описує природу файлу. Наприклад:
1\ProvidesFile{t1enc.def}[2001/06/05 v1.94 Standard LaTeX file]Перш ніж ми оголосимо будь-які специфічні команди кодування для певного кодування, ми спочатку повинні зробити це кодування відомим LaTeX. Це робиться за допомогою команди \DeclareFontEncoding. На цьому етапі також корисно оголосити правила заміни за замовчуванням для кодування. Ми можемо зробити це за допомогою команди \DeclareFontSubstitution. Обидва оголошення детально обговорюються в
Як налаштувати нові шрифти.
1\DeclareFontEncoding{T1}{}{}
2\DeclareFontSubstitution{T1}{cmr}{m}{n}Тепер, коли ми представили кодування T1 у LaTeX таким чином, ми можемо продовжити з оголошенням того, як команди, специфічні для кодування шрифту, повинні поводитися в цьому кодуванні.
1\DeclareTextSymbol{LICR-Object}{encoding}{slot}Оголошення текстових символів здається найпростішим. Тут внутрішнє представлення можна безпосередньо зіставити з одним гліфом цільового шрифту. Це досягається за допомогою оголошення \DeclareTextSymbol, чий третій аргумент - позиція гліфа - може бути заданий як десяткове, вісімкове або шістнадцяткове число. Наприклад,
1\DeclareTextSymbol{\ss}{T1}{255}
2\DeclareTextSymbol{\AE}{T1}{'306} %font position as octal number
3\DeclareTextSymbol{\ae}{T1}{"E6} %...as hexadecimal numberоголосити, що специфічні для кодування шрифту команди \ss, \AE і \ae мають бути зіставлені з позиціями шрифту (десяткові) 255, 198 і 230, відповідно, у кодованому T1 шрифт. Як ми зазначали вище, у таких оголошеннях найбезпечніше використовувати десяткове число. У будь-якому випадку змішування нотацій, як у попередньому прикладі, безумовно, поганий стиль.
1\DeclareTextAccent{LICR-accent}{encoding}{slot}Шрифти часто містять діакритичні знаки як окремі гліфи, щоб дозволити побудову акцентованих символів шляхом поєднання такого діакритичного знака з іншим гліфом. Такі наголоси (за умови, що вони розміщуються поверх інших гліфів) оголошуються за допомогою команди \DeclareTextAccent. Третій аргумент, slot, — це положення діакритичного знака в шрифті. Наприклад,
1\DeclareTextAccent{\"}{T1}{4}визначає наголос «умляут». З цього моменту внутрішнє представлення, таке як \"a, має таке значення в кодуванні T1: введіть ‘a з умляутом’, розмістивши наголос у позиції 4 над гліфами в позиції 97 (код ASCII) Таке оголошення фактично неявно визначає величезний діапазон представлень внутрішніх символів, тобто будь-що типу \"\DeclareTextSymbol або будь-який символ ASCII, що належить до LICR, наприклад ‘a’.
Навіть ті комбінації, які не мають особливого сенсу, такі як \"\P (тобто знак pilcrow з умляутом), концептуально стають членами набору команд, що стосуються кодування шрифту, таким чином.
1\DeclareTextComposite
2 {LICR-accent}{encoding}{simple-LICR-object}{slot}Наведена вище таблиця гліфів містить велику кількість символів із наголосами як окремих гліфів, наприклад, «a з умляутом» у вісімковій позиції «240». Таким чином, у T1 спеціальна команда \"a для кодування не повинна призводити до розміщення акценту над символом ‘a’, а натомість повинна мати прямий доступ до гліфа в цій позиції шрифту. Це досягається оголошенням
1\DeclareTextComposite{\"}{T1}{a}{228}який стверджує, що специфічна для кодування команда \"a призводить до верстки гліфа 228, тим самим вимикаючи декларацію наголосу вище. Для всіх інших команд, специфічних для кодування, що починаються з \", декларація наголосу залишається на місці. Наприклад, \"b утворить ‘b з умляутом’ шляхом розміщення акценту над основним гліфом ‘b’.
Третій аргумент, simple-LICR-object, має бути однією літерою, як-от ‘a’, або однією командою, як-от \j або \oe.
1\DeclareTextCompositeCommand
2 {LICR-object}{encoding}{simple-LICR-object}{code}Хоча він не використовується для кодування T1, існує також більш загальна версія \DeclareTextComposite, яка дозволяє довільний код замість позиції слота. Це використовується, наприклад, у кодуванні OT1, щоб знизити кільцевий наголос над ‘A’ порівняно зі способом набору тексту за допомогою примітиву \accent TeX. Наголоси над «i» також реалізуються за допомогою такої форми оголошення:
1\DeclareTextCompositeCommand{\'}{OT1}{i}{\@tabacckludge'\i}
2\DeclareTextCompositeCommand{\^}{OT1}{i}{\^\i}Кілька діакритичних знаків розміщуються не поверх інших символів, а десь під ними. Не існує спеціальної форми декларації для таких позначок, оскільки фактичне розміщення наголосу включає низькорівневий код TeX. Натомість для цієї мети можна використовувати загальний \DeclareTextCommand.
1\DeclareTextCommand{LICR-object}{encoding}[num][default]{code}Наприклад, наголос \b під штрихом у кодуванні T1 визначається таким кодом:
1\DeclareTextCommand{\b}{T1}[1]
2 {\hmode$bgroup\o$lign{\relax#1\crcr\hidewidth\sh$ft{29}%
3 \vbox to.2ex{\hbox{\char9}\vss}\hidewidth}\egroup}У цьому обговоренні не має великого значення, що саме означає код, але ми бачимо, що \DeclareTextCommand певним чином схожий на \newcommand. Він має необов’язковий аргумент num, що вказує на кількість аргументів (один тут), другий необов’язковий аргумент default (тут його немає) і останній обов’язковий аргумент, що містить код, у якому можна посилатися на аргумент ( s) використовуючи #1, #2 тощо.
\DeclareTextCommand також можна використовувати для створення команд, що стосуються кодування шрифту, що складається з однієї послідовності керування. У цьому випадку він використовується без необов’язкового аргументу, таким чином визначаючи команду з нульовими аргументами. Наприклад, у T1 немає гліфа для знака «проміле», але є невелика «о» в позиції ``30`», яка, якщо її поставити безпосередньо за «%», дасть відповідний гліф . Таким чином, ми можемо надати такі декларації:
1\DeclareTextCommand{\textperthousand} {T1}{\%\char 24}
2\DeclareTextCommand{\textpertenthousand}{T1}{\%\char 24\char 24 }Тепер ми розглянули всі команди, необхідні для оголошення команд, що стосуються кодування шрифту, для нового кодування. Як ми вже говорили, тільки ці команди повинні бути присутніми у файлах визначення кодування.
Стандартне кодування виводу
Давайте тепер подивимося, що станеться, якщо використано команду, що стосується конкретного кодування, для якої немає оголошення в поточному кодуванні шрифту. У цьому випадку може статися одна з двох речей: або LaTeX має визначення за замовчуванням для об’єкта LICR, і в цьому випадку використовується це за замовчуванням, або видається повідомлення про помилку про те, що запитуваний об’єкт LICR недоступний у поточному кодуванні. Існує кілька способів встановлення стандартних значень для об’єктів LICR.
1\DeclareTextCommandDefault{LICR-object}[num][default]{code}Команда \DeclareTextCommandDefault надає визначення за замовчуванням для LICR-об’єкта, який буде використовуватися щоразу, коли для об’єкта немає певних налаштувань у поточному кодуванні. Такі визначення можуть, наприклад, підробити певного персонажа. Наприклад, \textregistered має визначення за замовчуванням, у якому символ складається з двох інших, як це:
1\DeclareTextCommandDefault{\textregistered}{\textcircled{\scshape r}}Технічно визначення за замовчуванням зберігаються як кодування з назвою ?. Хоча ви не повинні покладатися на цей факт, оскільки реалізація може змінитися в майбутньому, це означає, що ви не можете оголосити кодування з таким ім’ям.
1\DeclareTextSymbolDefault{LICR-object}{encoding}У більшості випадків визначення за замовчуванням не вимагає кодування, а просто вказує LaTeX взяти символ із певного кодування, у якому відомо, що він існує. Пакет textcomp, наприклад, містить велику кількість декларацій за замовчуванням, які всі вказують на кодування TS1. наприклад:
1\DeclareTextSymbolDefault{\texteuro}{TS1}Команда \DeclareTextSymbolDefault може бути використана, щоб визначити значення за замовчуванням для будь-якого об’єкта LICR без аргументів, а не лише для тих, які оголошено командою \DeclareTextSymbol в інших кодуваннях.
1\DeclareTextAccentDefault{LICR-accent}{encoding}Існує подібне оголошення для об’єктів LICR, які приймають один аргумент, наприклад, наголоси. Знову ж таки, цю форму можна використовувати для будь-якого об’єкта LICR з одним аргументом. Ядро LaTeX, наприклад, містить кілька декларацій типу:
1\DeclareTextAccentDefault{\"}{OT1}
2\DeclareTextAccentDefault{\t}{OML}Це означає, що якщо \" не визначено в поточному кодуванні, тоді використовуйте шрифт із кодуванням OT1. Так само, щоб отримати краватковий акцент, виберіть його з OML, якщо нічого кращого немає .
1\ProvideTextCommandDefault{LICR-object}[num][default]{code}Оголошення \ProvideTextCommandDefault дозволяє “надавати” інший тип типового значення. Він виконує ту саму роботу, що й оголошення \DeclareTextCommandDefault, за винятком того, що значення за замовчуванням надається лише в тому випадку, якщо раніше не було визначено значення за умовчанням. Це в основному використовується у файлах кодування вхідних даних, щоб забезпечити якісь тривіальні значення за замовчуванням для незвичайних об’єктів LICR. наприклад:
1\ProvideTextCommandDefault{\textonequarter}{\ensuremath{\frac14}}
2\ProvideTextCommandDefault{\textcent}{\TextSymbolUnavailable\textcent}Такі пакети, як textcomp, можуть потім замінити такі визначення оголошеннями, що вказують на справжні гліфи. Використання \Provide... замість \Declare... гарантує, що краще значення за умовчанням не буде випадково перезаписано, якщо вхідний файл кодування буде прочитано.
1\UndeclareTextCommand{LICR-object}{encoding}У деяких випадках наявну декларацію необхідно видалити, щоб забезпечити використання замість неї декларації за замовчуванням. Це можна зробити за допомогою \UndeclareTextCommand. Наприклад, пакет textcomp видаляє визначення \textdollar і \textsterling із кодування OT1, оскільки не кожен шрифт, закодований OT1, насправді має ці символи.
1\UndeclareTextCommand{\textsterling}{OT1}
2\UndeclareTextCommand{\textdollar} {OT1}Без цього видалення нові декларації за замовчуванням для отримання символів із TS1 не використовувалися б для шрифтів, закодованих OT1.
1\UseTextSymbol{encoding}{LICR-object}
2\UseTextAccent{encoding}{LICR-object}{simple-LICR-object}Дія, прихована за оголошеннями \DeclareTextSymbolDefault і \DeclareTextAccentDefault, також може використовуватися безпосередньо. Припустімо, наприклад, що поточне кодування U. У такому разі
1\UseTextSymbol{OT1}{\ss}
2\UseTextAccent{OT1}{\'}{a}має той самий ефект, що й введення наведеного нижче коду. Зверніть увагу, зокрема, що a набирається в кодуванні U - лише наголос береться з іншого кодування.
1{\fontencoding{OT1}\selectfont\ss}
2{\fontencoding{OT1}\selectfont\'{\fontendcoding{U}\selectfont a}}Перелік стандартних об’єктів LICR
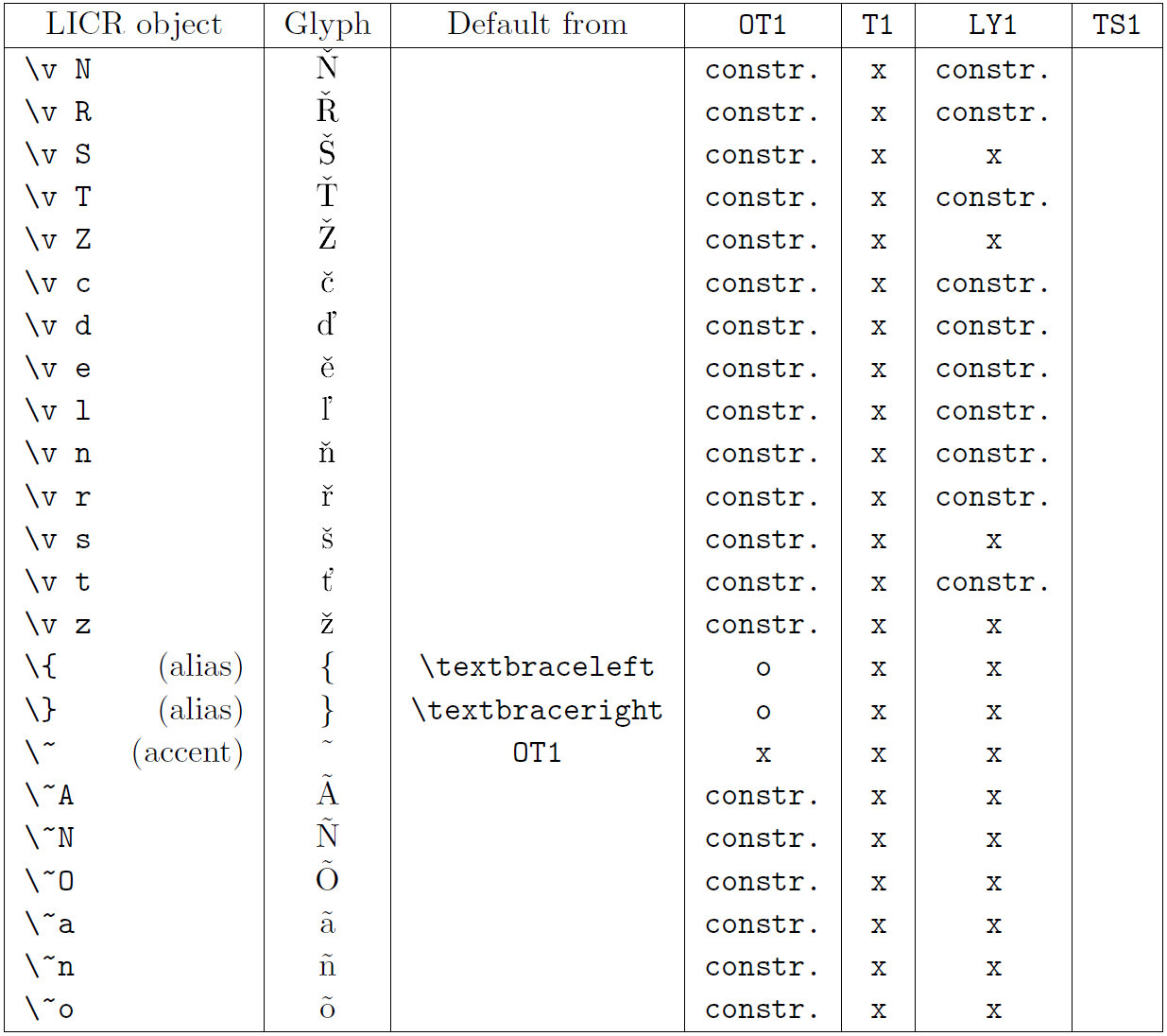
Таблиця в цьому підрозділі містить огляд внутрішніх представлень LaTeX, доступних із трьома основними кодуваннями для латинських мов: OT1 (оригінальне кодування TeX), T1 (стандартне кодування LaTeX) і LY1 ( альтернативне 8-бітне кодування, запропоноване Y&Y). Крім того, він показує всі об’єкти LICR, оголошені TS1 (стандартне кодування текстових символів LaTeX), що надається під час завантаження пакета textcomp.
Перший стовпець таблиці показує назви об’єктів LICR в алфавітному порядку, вказуючи, які об’єкти LICR діють як наголоси. Другий стовпець показує гліфове представлення об’єкта.
Третій стовпець описує, чи має об’єкт оголошення за замовчуванням. Якщо кодування вказано, це означає, що за замовчуванням гліф отримується з відповідного шрифту в цьому кодуванні; constr. означає, що за умовчанням створюється з низькорівневого коду TeX; якщо стовпець порожній, це означає, що для цього об’єкта LICR не визначено замовчування. В останньому випадку повертається помилка «Символ недоступний», якщо ви використовуєте його в кодуванні, для якого він не має явного визначення. Якщо об’єкт є псевдонімом для іншого об’єкта LICR, альтернативне ім’я вказується в цьому стовпці.
Стовпці з четвертого по сьомий показують, чи доступний об’єкт у заданому кодуванні. Тут «x» означає, що об’єкт є початково доступним (як гліф) у шрифтах із таким кодуванням, «o» означає, що він доступний за замовчуванням для всіх кодувань, а «constr.» означає, що він згенерований з кількох гліфи, знаки наголосу чи інші елементи. Якщо значення за замовчуванням отримано з TS1, об’єкт LICR доступний, лише якщо завантажено пакунок textcomp.
Об’єкти LICR. Частина 1
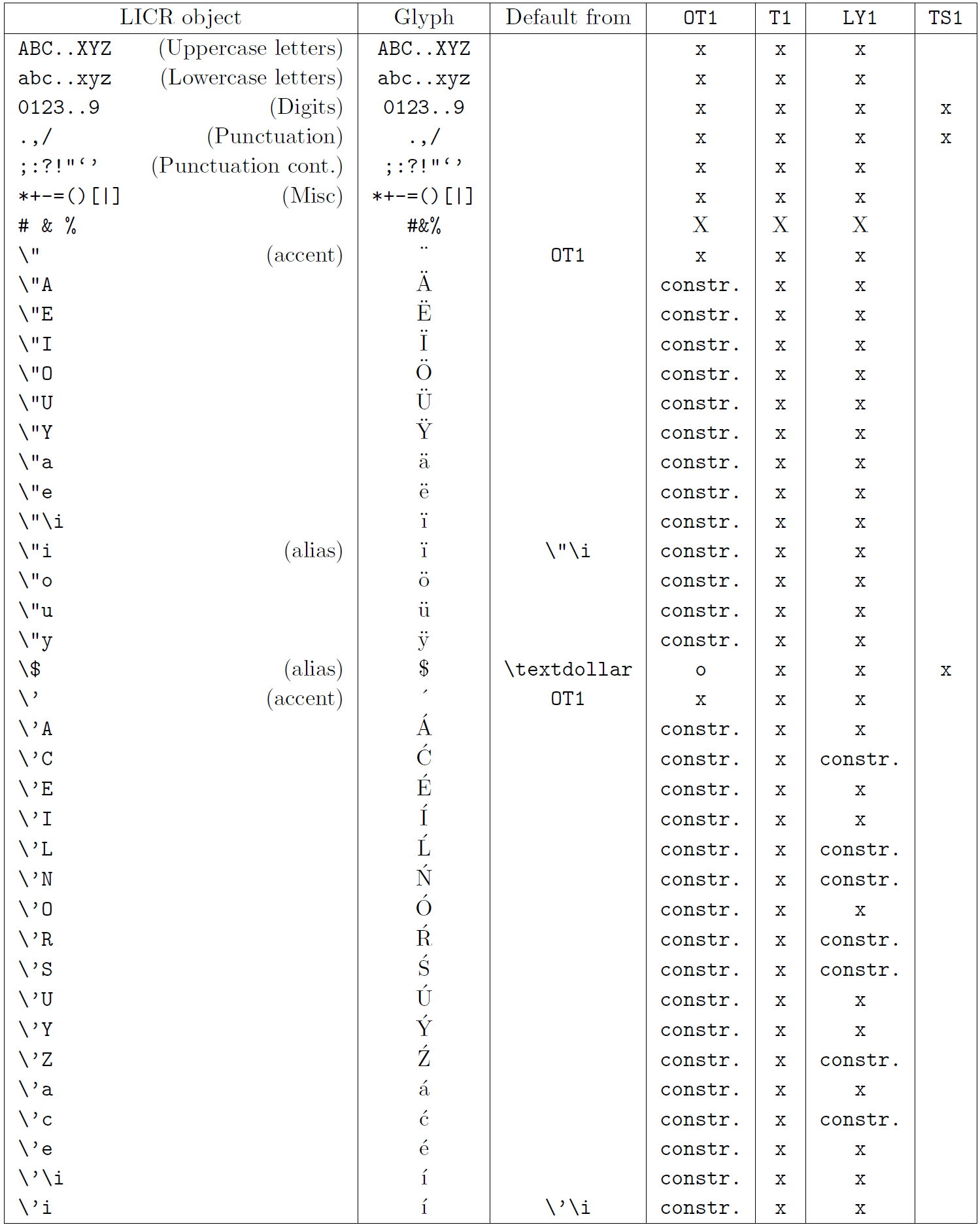
Об’єкти LICR. Частина 2
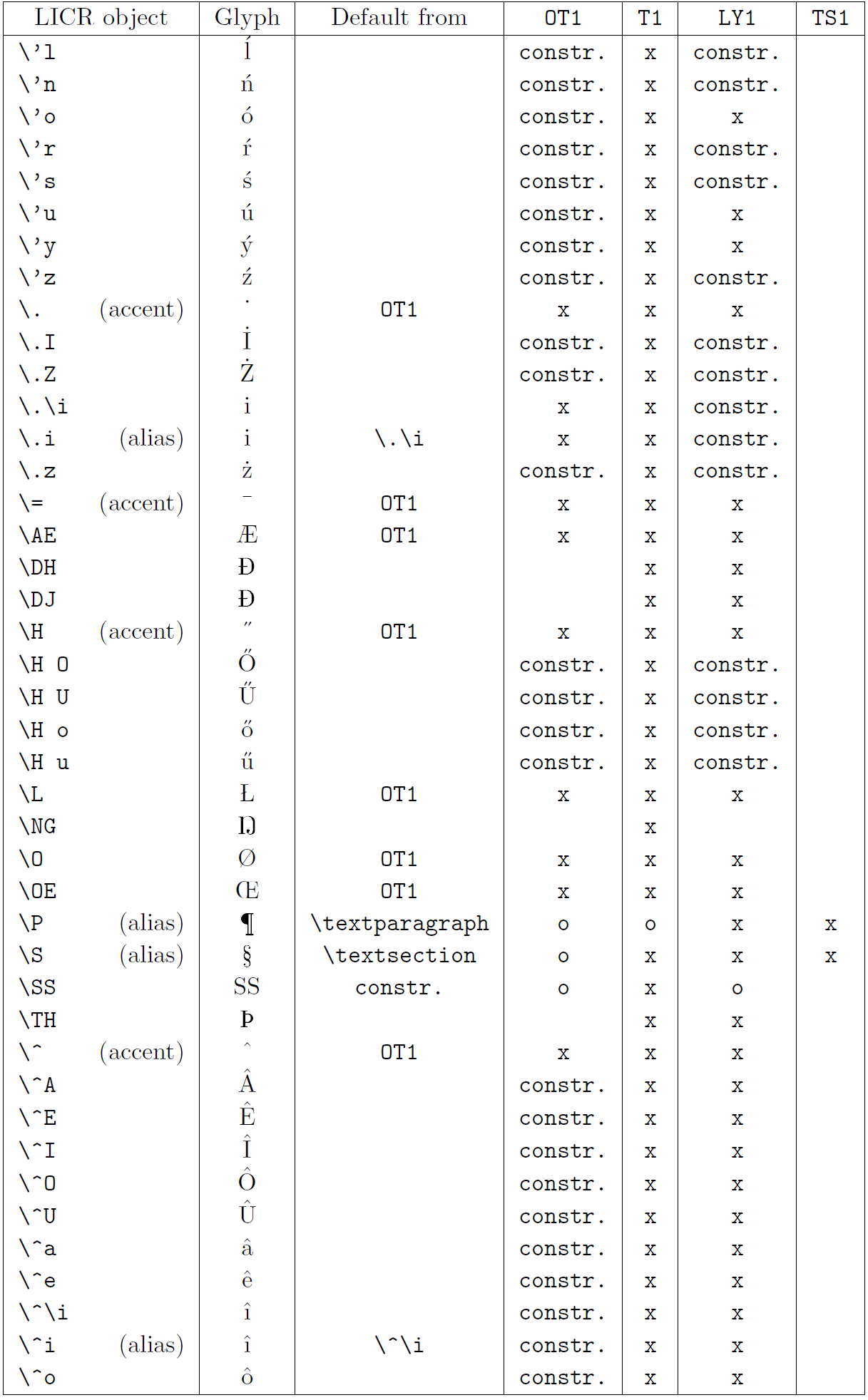
Об’єкти LICR. Частина 3
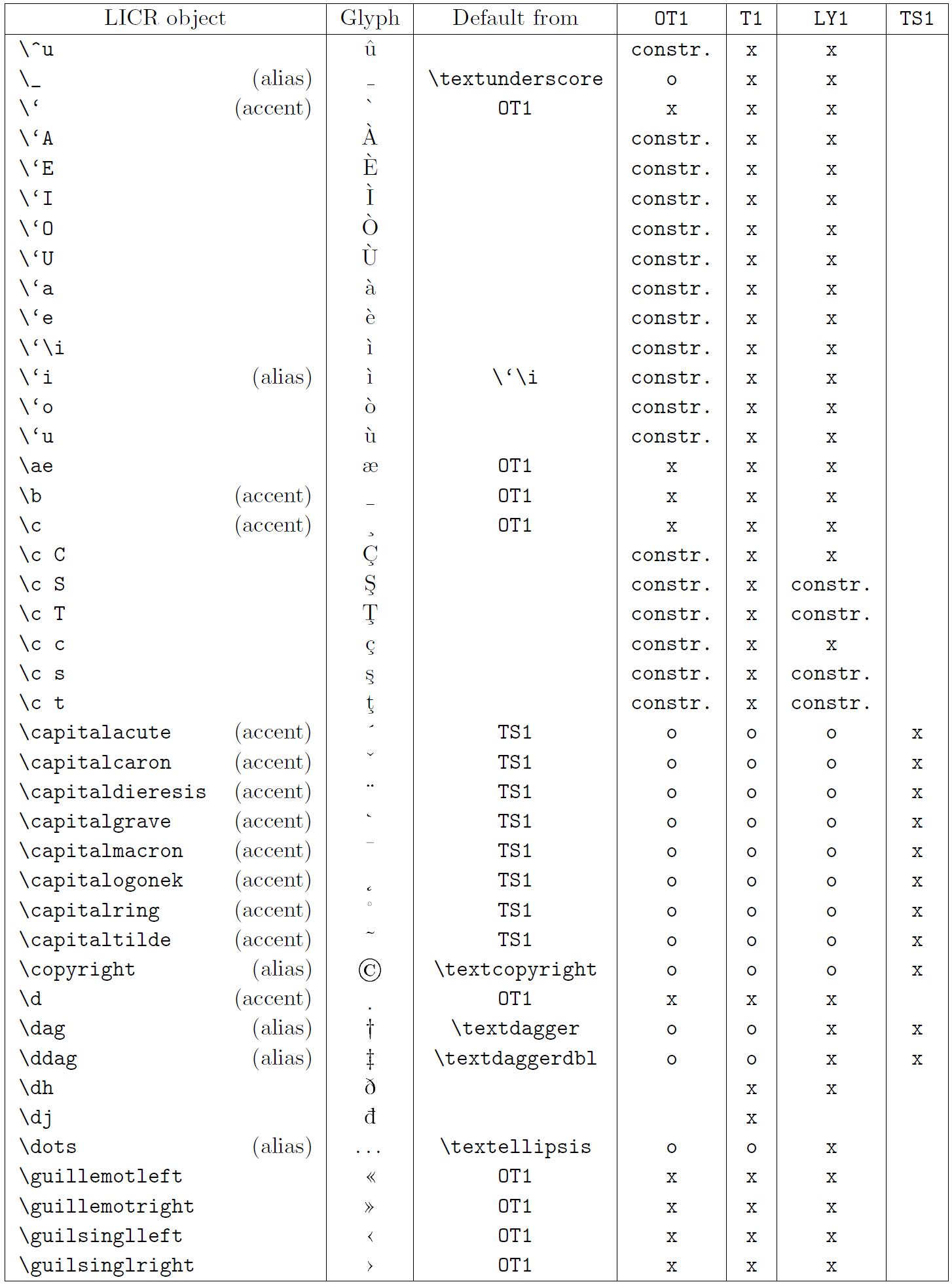
Об’єкти LICR. Частина 4
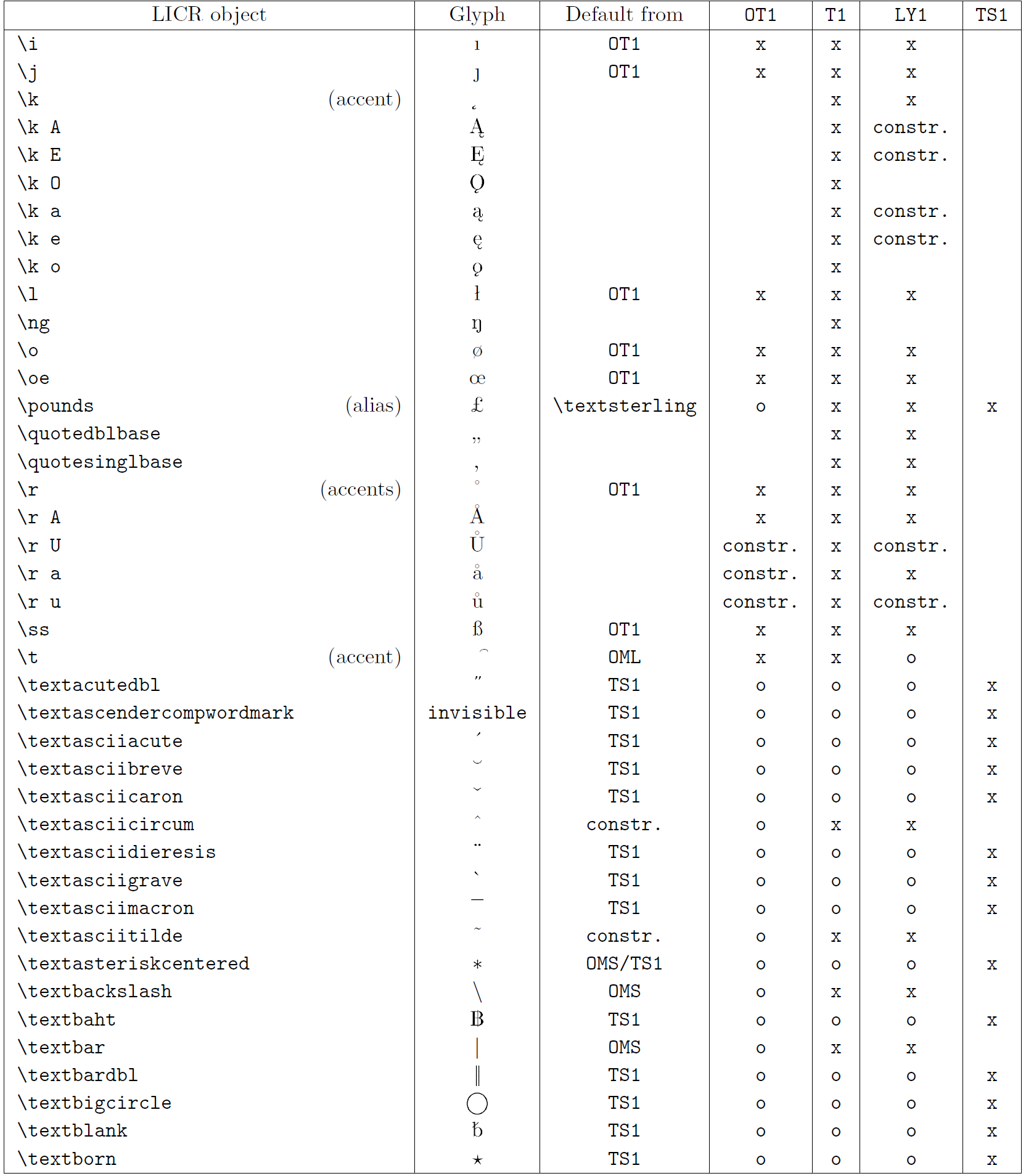
Об’єкти LICR. Частина 5
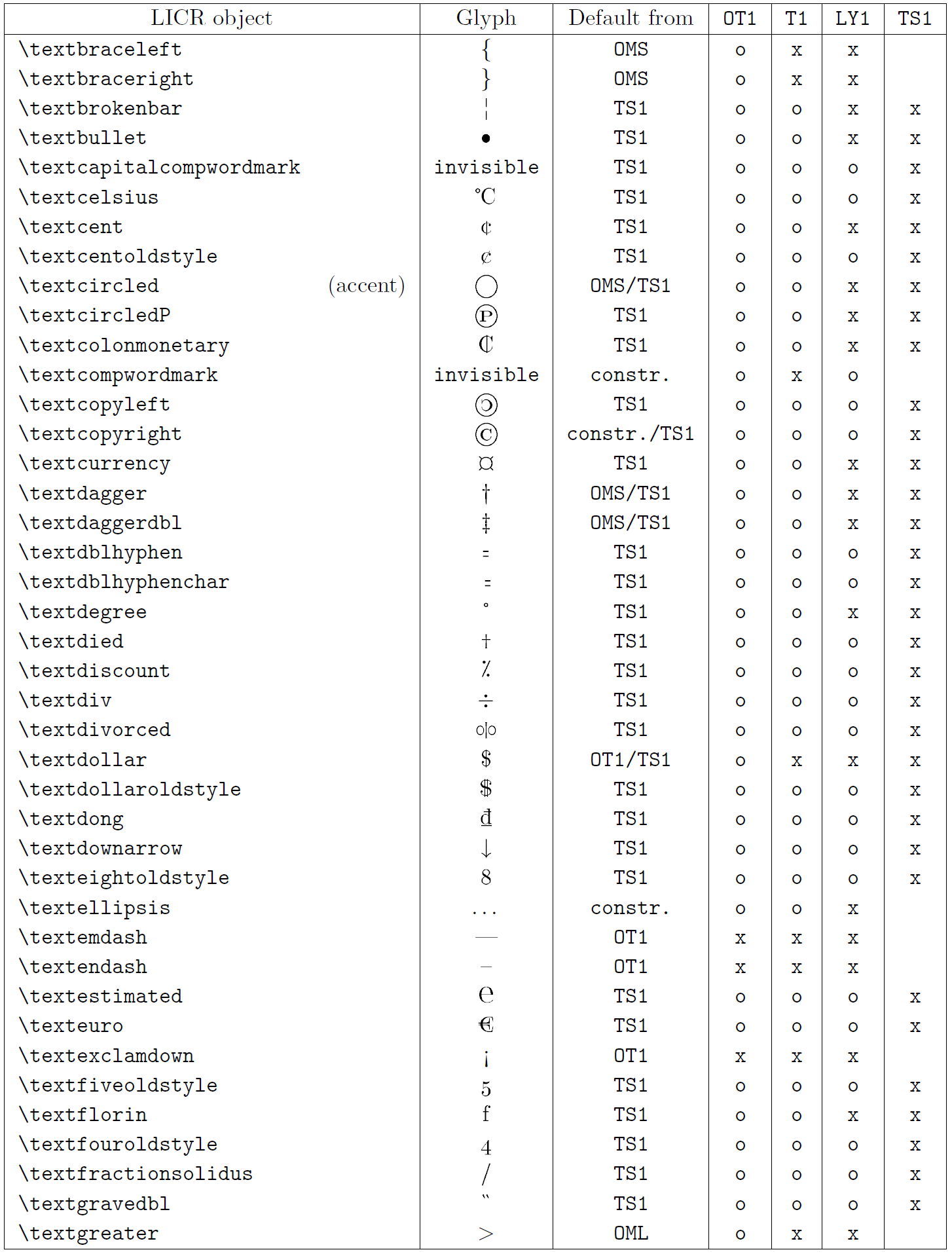
Об’єкти LICR. Частина 6
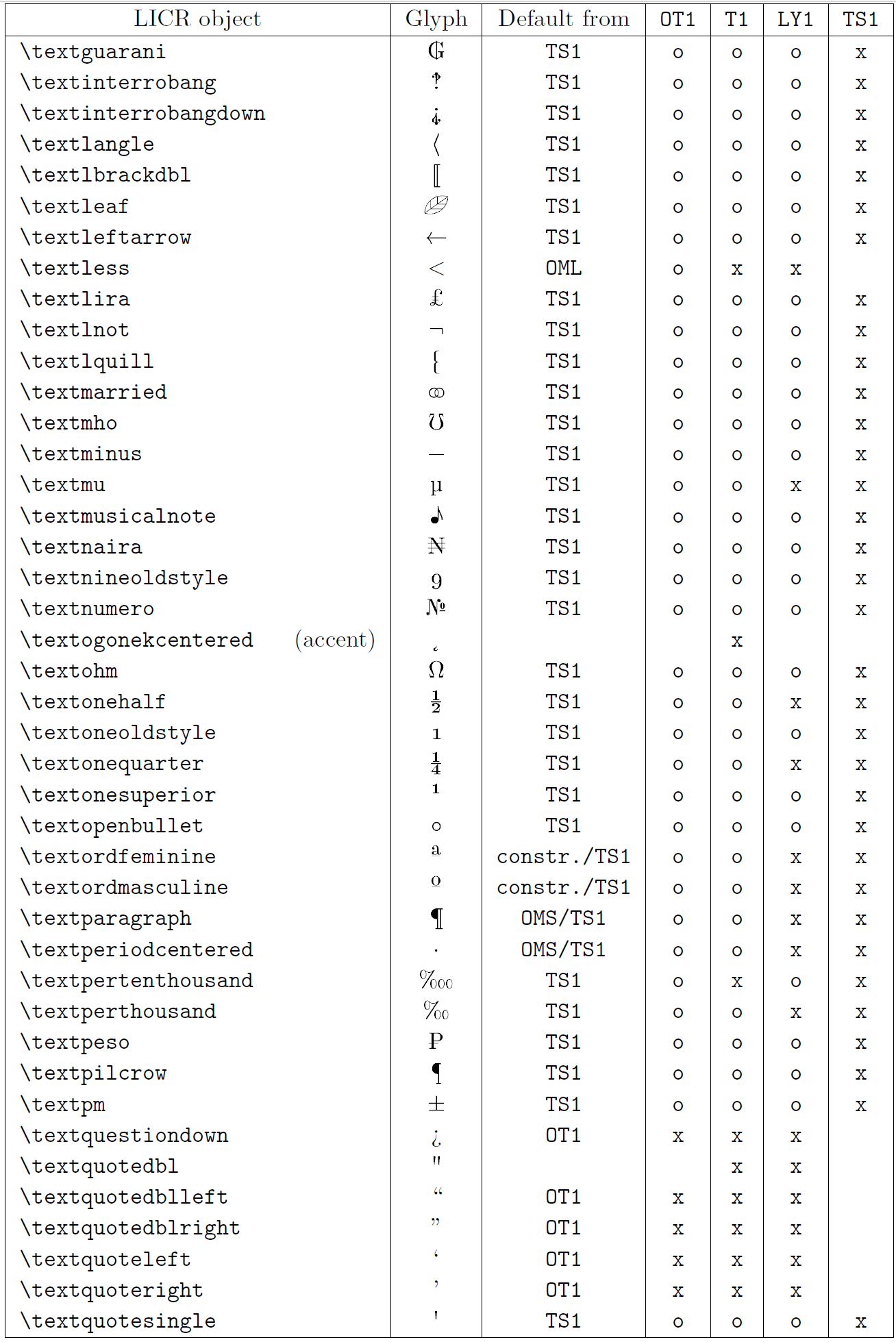
Об’єкти LICR. Частина 7
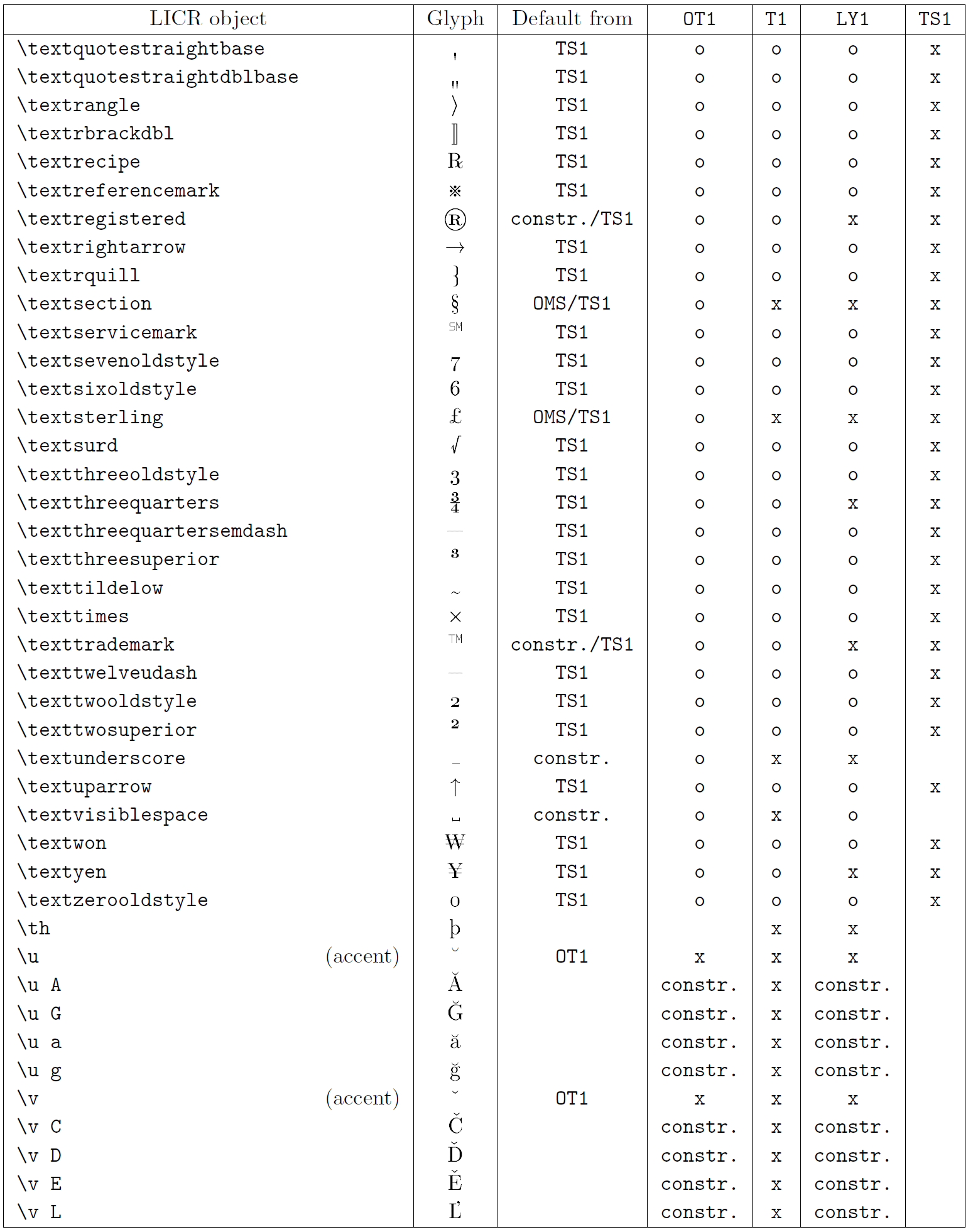
Об’єкти LICR. Частина 8