4. Стандартні шрифти в LaTeX
Ця стаття містить короткий вступ до стандартних текстових шрифтів, що поширюються разом із LaTeX. Потім він охоплює стандартну підтримку LaTeX для введення та кодування шрифтів. Стаття завершується описом пакета для відстеження обробки шрифтів LaTeX та іншого пакета для відображення діаграм гліфів.
4.1. Комп’ютер Сучасний Роман
Сімейство шрифтів під назвою Computer Modern було розроблено Дональдом Кнутом разом із TeX. До початку 1990-х лише ці шрифти здебільшого використовувалися з TeX і, відповідно, з LaTeX. Кожен із цих шрифтів містить лише 128 гліфів, тому вони не можуть містити символи з акцентами як окремі гліфи. Таким чином, використання цих шрифтів означає, що символи з наголосами повинні створюватися за допомогою примітиву TeX \accent, що, у свою чергу, означає, що автоматичний перенос слів із символами з наголосами неможливий. Хоча це обмеження прийнятно для документів англійською мовою, воно є очевидним недоліком для інших мов.
Ці недоліки викликали велике занепокоєння у користувачів TeX у Європі і зрештою призвели до повторної реалізації TeX у 1989 році для внутрішньої та зовнішньої підтримки 8-бітних символів. Стандартне 8-розрядне кодування для текстових шрифтів (T1) було розроблено в 1990 році. Воно містить багато діакритичних символів і дозволяє набирати більш ніж 30 мовами на основі латинського алфавіту. Потім сімейства шрифтів Computer Modern були реалізовані заново, а додаткові символи були розроблені так, щоб отримані шрифти повністю відповідали цій схемі кодування.
4.2. Вибір кодування введення: пакет inputenc
Якщо ви можете вводити символи з діакритичними знаками або одним натисканням клавіш, або іншим способом введення (наприклад, натиснувши `, а потім a, щоб отримати ‘a-grave’), і ваш комп’ютер правильно відображає їх у редактор…

… тоді в ідеалі ви б використовували такий текст безпосередньо з LaTeX замість того, щоб вводити \`a, \^e тощо.
Для таких мов, як французька та німецька, останній підхід можливий. Однак для таких мов, як російська та грецька, необхідний потенціал прямого введення, оскільки майже кожен символ у цих мовах має назву команди як внутрішню форму LaTeX. Наприклад, російськомовне визначення \reftextafter містить такий текст (що означає «на наступній сторінці»):
1\cyrn\cyra\ \cyrs\cyrl\cyre\cyrd\cyru\cyryu\cyrshch\cyre\cyrishrt
2\ \cyrs\cyrt\cyrr\cyra\cyrn\cyri\cyrc\cyreНавряд чи хтось захоче регулярно друкувати такі речі. Тим не менш, його перевага полягає в тому, що він універсально переносимий, тому його можна правильно інтерпретувати в будь-якій установці LaTeX. З іншого боку, набір тексту
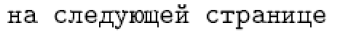
на відповідній клавіатурі явно краще, якщо можливо змусити LaTeX зрозуміти це введення. Проблема полягає в тому, що у файлі зберігаються не символи, які ми бачимо у наведеній вище послідовності, а радше октети, які представляють символи. За різних обставин (з використанням різних кодувань) ті самі октети можуть представляти різні символи.
Поки все відбувається на одному комп’ютері й усі програми інтерпретують октети у файлах однаково, зазвичай усе добре. Якщо так, має сенс активувати механізм автоматичного перекладу, вбудований у деякі останні реалізації TeX. Але коли файл, створений у такому середовищі, надсилається на інший комп’ютер, обробка, ймовірно, завершиться невдачею або, що ще гірше, може здатися успішною, але насправді призведе до неправильних результатів через відображення неправильних символів.
Пакет inputenc був створений для вирішення цієї проблеми. Його основна мета — повідомити LaTeX про кодування, яке використовується в документі або в частині документа. Це робиться шляхом завантаження пакета з назвою кодування як опцією. Наприклад:
1\usepackage[cp1252]{inputenc} % Windows 1252 (Western Europe) code pageЗ цього моменту LaTeX знає, як інтерпретувати октети в решті документа під час будь-якої інсталяції, незалежно від кодування, яке використовується для інших цілей на цьому комп’ютері.
Типовий приклад наведено нижче. Це короткий текст, написаний у популярній в Росії кодуванні koi8-r. Вихідний код показує, як виглядає текст на комп’ютері з використанням кодування Latin 1 (наприклад, у Німеччині). Вихідні дані демонструють, що LaTeX все ще зміг правильно інтерпретувати текст, оскільки йому було повідомлено, яке вхідне кодування використовувалося.

Нижче наведено список кодувань, які зараз підтримує inputenc. Інтерфейс добре задокументований, і можна легко додати підтримку нових кодувань. Тому варто ознайомитися з документацією пакета inputenc, якщо тут не вказано кодування, яке використовує ваш комп’ютер. Ви також можете шукати в Інтернеті файли кодування для inputenc, створені іншими авторами. Наприклад, кодування, пов’язані з кириличними мовами, поширюються разом з іншими пакетами підтримки шрифтів для кириличних мов.
Стандарт ISO-8859 визначає низку важливих однобайтових кодувань. Кодування, пов’язані з латинським алфавітом, підтримується inputenc. Для операційної системи Windows Microsoft визначила ряд однобайтових кодувань. Крім того, доступні деякі кодування, визначені іншими постачальниками комп’ютерів.
latin1Це кодування ISO-8859-1 (відоме також як Latin 1). Він може представляти більшість західноєвропейських мов, включаючи албанську, каталонську, датську, голландську, англійську, фарерську, фінську, французьку, галісійську, німецьку, ісландську, ірландську, італійську, норвезьку, португальську, іспанську та шведську.latin2Кодування ISO Latin 2 (ISO-8859-2) підтримує слов’янські мови Центральної Європи, які використовують латинський алфавіт. Його можна використовувати для таких мов: хорватська, чеська, німецька, угорська, польська, румунська, словацька та словенська.latin3Цей набір символів (ISO-8859-3) використовується для есперанто, галісійської, мальтійської та турецької мов.latin4Кодування ISO Latin 4 (ISO-8859-4) може представляти такі мови, як естонська, латвійська та литовська.latin5Кодування ISO Latin 5 (ISO 8859-9) тісно пов’язане з Latin 1 і замінює рідко використовувані ісландські літери з Latin 1 турецькими літерами.latin9Latin 9 (або ISO-8859-15) — це ще один невеликий варіант латиниці 1, який додає знак валюти євро, а також кілька інших символів, як-от лігатуру\AE, яких не було у французькій мові та фінська. Він стає все більш популярним як заміна латиниці 1.cp437Кодова сторінка IBM 437 (латиниця MS-DOS, але містить багато графічних символів для малювання рамок).cp850Кодова сторінка IBM 850 (MS-DOS багатомовна, схожа на latin1).cp852Кодова сторінка IBM 852 (MS-DOS багатомовна, схожа на latin2).cp858Кодова сторінка IBM 858 (IBM 850 із доданим символом євро).cp865Кодова сторінка IBM 865 (MS-DOS Норвегія).cp1250Кодова сторінка Windows 1250 (Центральна та Східна Європа).cp1252Кодова сторінка Windows 1252 (Західна Європа).cp1257Кодова сторінка Windows 1257 (Балтія).ansinewWindows 3.1 кодування ANSI; синонім cp1252.decmultiКодування багатонаціонального набору символів DEC.applemacMacintosh (стандартне) кодування.macceMacintosh Central European кодова сторінка.наступнийДалі Комп’ютерне кодування.utf8Підтримка кодування UTF8 Unicode.
Більшість установок TeX типово приймають 8-бітові символи. Тим не менше, без подальших коригувань, таких як ті, які виконує inpuenc, результати можуть бути непередбачуваними: деякі символи можуть зникнути, або ви можете отримати будь-який символ, присутній у поточному шрифті у положенні октету, який може або не бути потрібний гліф. Ця поведінка була типовою протягом тривалого часу, тому її не змінювали в LaTeX2e, оскільки деякі люди покладаються на неї. Однак, щоб переконатися, що такі помилки можна виявити, inputenc пропонує опцію ascii, яка робить будь-який символ за межами діапазону 32-126 незаконним.
1\inputencoding{encoding}Спочатку пакет inputenc був розроблений для визначення кодування, що використовується для документа в цілому - звідси використання параметрів у преамбулі. Однак можна змінити кодування в середині документа за допомогою команди \inputencoding. Ця команда приймає назву кодування як аргумент.
Коли було розроблено inputenc, більшість установок LaTeX були на комп’ютерах, які використовували однобайтові кодування, подібні до тих, що обговорюються в цьому розділі. Однак сьогодні популярне інше кодування, оскільки системи підтримують Unicode: UTF8. Це кодування змінної довжини представляє символи Unicode від одного до чотирьох октетів. Підтримку кодування додано до inputenc через опцію utf8. Технічно він не забезпечує повної реалізації UTF8. Відображаються лише символи Юнікоду, які мають деяке представлення у стандартних шрифтах LaTeX (тобто, переважно набори символів латиниці та кирилиці): усі інші призведуть до відповідного повідомлення про помилку. Крім того, комбіновані символи Unicode не підтримуються, хоча на практиці це конкретне упущення не повинно бути проблемою.
1\usepackage[utf8]{inputenc}
2\usepackage{textcomp} % for Latin interpretation
3-----------------------------------------------
4German umlauts in UTF-8: ^^c3^^a4^^c3^^b6^^c3^^bc
5\par\inputencoding{latin1}% switch to Latin 1
6But interpreted as Latin 1: ^^c3^^a4^^c3^^b6^^c3^^bc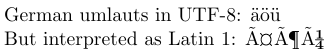
В UTF8 символи ASCII представляють себе самі, а більшість латинських символів представлено двома байтами. У вихідному коді прикладу двобайтові представлення німецьких умляутів у UTF8 показано у шістнадцятковій системі запису TeX, тобто перед кожним октетом стоїть ^^. У редакторі, який не розуміє UTF8, on, ймовірно, побачить їх як подібні до результату, який створюється, коли вони інтерпретуються як символи латиниці 1.
Пакет із більш повною підтримкою UTF8 (включно з підтримкою корейських, китайських і японських ієрогліфів), хоча, відповідно, і складніший у своїй установці, — це пакет ucs, написаний Домініком Унру. Ви можете спробувати це, якщо рішення inputenc не відповідає вашим потребам.
4.3. Вибір кодування шрифту за допомогою пакета fontenc
Щоб увімкнути кодування текстового шрифту для використання з LaTeX, кодування має бути завантажено в преамбулу або клас документа. Точніше, потрібно завантажити визначення для доступу до гліфів у шрифтах із певним кодуванням. Канонічний спосіб зробити це — за допомогою пакета fontenc, який приймає список кодувань шрифтів, розділених комами, як параметр пакета. Останнє з цих кодувань автоматично стає стандартним кодуванням документа. Якщо завантажено кодування кирилиці, список команд, на які впливають \MakeUppercase і \MakeLowercase, автоматично розширюється. Наприклад,
1\usepackage[T2A,T1]{fontenc}завантажить усі необхідні визначення для кодувань кирилиці T2A і T1 і встановить останнє як кодування документа за замовчуванням.
На відміну від звичайної поведінки пакета, цей пакет можна завантажувати кілька разів із різними параметрами команди \usepackage. Це необхідно, щоб дозволити класу документа завантажити певний набір кодувань і дозволити користувачеві завантажити ще більше кодувань у преамбулі. Завантаження кодувань більше одного разу виконується без побічних ефектів, крім потенційної зміни стандартного кодування шрифту документа.
Якщо в документі використовуються пакети підтримки мови (наприклад, ті, що постачаються з системою babel), часто буває так, що необхідні кодування шрифтів уже завантажено пакетом підтримки.
4.4. Як відстежити вибір шрифту за допомогою пакета tracefnt
Щоб виявити проблеми в системі вибору шрифтів, ви можете скористатися пакетом tracefnt. Він підтримує кілька параметрів, які дозволяють налаштовувати кількість інформації, що відображається NFSS на екрані та у файлі стенограми.
errorshowЦей параметр пригнічує всі попередження та інформаційні повідомлення на терміналі; вони будуть записані лише у файл стенограми. Будуть показані лише справжні помилки. Вам слід уважно вивчити файл стенограми перед друком важливої публікації, тому що попередження про заміну шрифту тощо можуть означати, що кінцевий результат буде невірним.warningshowЯкщо вказано цей параметр, попередження та помилки відображаються на терміналі. Цей параметр надає вам таку ж детальну інформацію, як LaTeX2e без завантаженого пакетаtracefnt.infoshowЦя опція є типовою під час завантаження пакетаtracefnt. Додаткова інформація, яка зазвичай записується лише у файл стенограми, тепер також відображається на вашому терміналі.debugshowЦя опція додатково показує інформацію про зміни шрифту тексту та відновлення таких шрифтів у кінці групи дужок або в кінці середовища. Будьте обережні, коли вмикаєте цю опцію, оскільки вона може створити дуже великі файли стенограми.pausingЦей параметр перетворює всі попередження на помилки, щоб допомогти виявити проблеми у важливих публікаціях.loadingЦя опція показує завантаження зовнішніх шрифтів. Проте, якщо формат або клас документа, який ви використовуєте, уже завантажив деякі шрифти, вони не відображатимуться за допомогою цього параметра.
4.5. Як відобразити таблиці шрифтів і зразки за допомогою nfssfont.tex
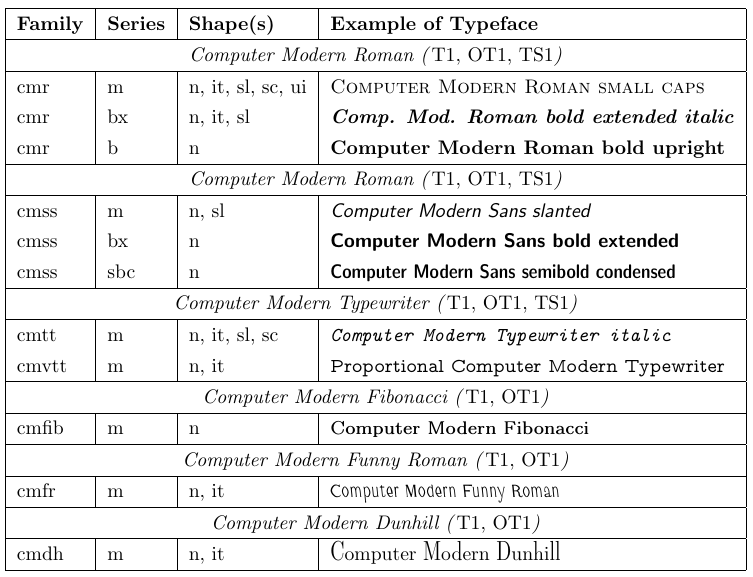
Файл під назвою nfssfont.tex можна використовувати для тестування нових шрифтів, створення таблиць шрифтів, що показують усі символи, і виконання інших операцій, пов’язаних зі шрифтами. Ви можете знайти цей файл у будь-якому дистрибутиві LaTeX. Коли ви запускаєте цей файл через LaTeX, вам буде запропоновано ввести назву шрифту для перевірки. Відповіддю може бути назва зовнішнього шрифту без розширення, наприклад cmr10 (Computer Modern Roman 10pt), якщо ви її знаєте, або порожня назва шрифту. В останньому випадку вам буде запропоновано ввести специфікацію шрифту NFSS: назву кодування (за замовчуванням T1), назву родини шрифту (за замовчуванням cmr), серію шрифтів (за замовчуванням m), форму шрифту ( за замовчуванням n) і розмір шрифту (за замовчуванням 10pt). Потім програма завантажує зовнішній файл, що відповідає цій класифікації.
Далі вам буде запропоновано ввести команду. Найважливішим з них є, мабуть, \table, який створює діаграму шрифтів, як наведену нижче. Команда \text також цікава, оскільки створює довший зразок тексту. Щоб перейти до нового тестового шрифту, введіть \init; щоб завершити перевірку, введіть \bye або \stop; і щоб дізнатися про всі інші доступні тести, введіть \help.
1**********************************************
2* NFSS font test program version <v2.2b>
3*
4* Follow the instructions
5**********************************************
6
7Input external font name, e.g., cmr10
8(or <enter> for NFSS classification of font):
9
10\currfontname=cmr10
11Now type a test command (\help for help):)
12*\table
13
14*\newpage
15*\init
16Input external font name, e.g., cmr10
17(or <enter> for NFSS classification of font):
18
19\currfontname=
20*** NFSS classification ***
21
22Font encoding [T1]:
23
24\encoding=OT1
25(ot1enc.def)
26Font family [cmr]:
27
28\family=cmdh
29Font series [m]:
30
31\series=m
32Font shape [n]:
33
34\shape=n
35Font size [10pt]:
36
37\size=10
38(ot1cmdh.fd) Now type a test command (\help for help):
39*\text
40
41*\bye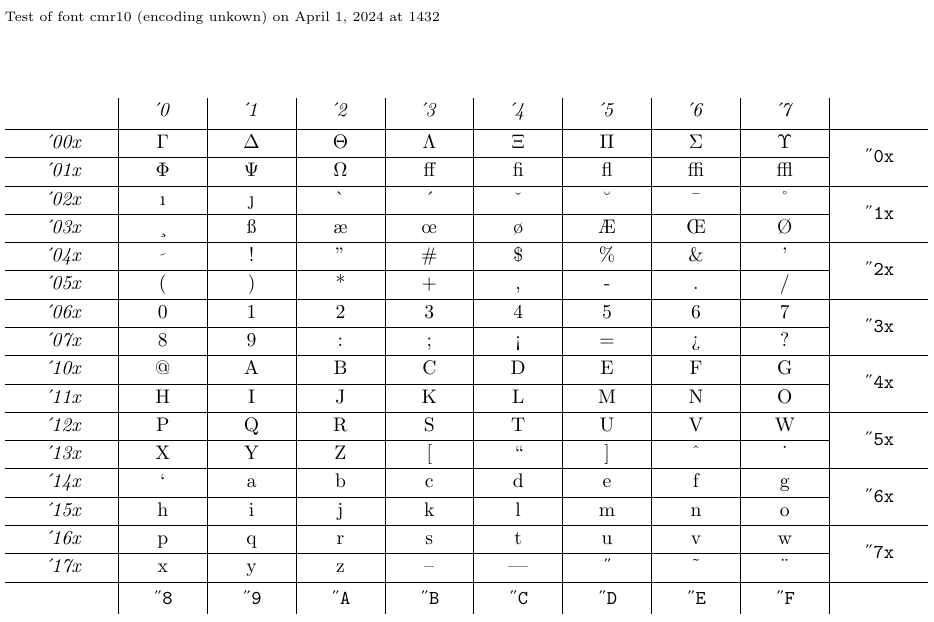

Варто знати про два моменти. По-перше, програма
nfssfont.texвидає неявну команду\init, тому перший рядок введення має або містити назву шрифту, або бути повністю порожнім, щоб вказати, що слідує класифікація NFSS. По-друге, вхідні дані для\initповинні з’являтися в окремих рядках без нічого (навіть коментаря), тому що закінчення рядка вказує на кінець відповіді на підказку на зразокКодування шрифту[T1]: \encoding=, яку ви отримаєте.