7. LaTeX 的字符编码模型
本文详细介绍 LaTeX 编码。首先讨论 LaTeX 系统内部的字符数据流。接下来深入查看 LaTeX 中字符数据的内部表示模型,并讨论将输入数据通过输入编码映射到该内部表示的机制。最后解释内部表示如何通过输出编码转换为排版所需的形式。
7.1. LaTeX 中的字符数据流
使用 LaTeX 处理文档时,首先会解释一个或多个源文件中的数据。这些表示文档内容的数据以八位字节序列(即字符)存储在源文件中。要正确解释这些八位字节,任何用于处理文件的程序(包括 LaTeX)都必须知道抽象字符与其对应八位字节之间的映射关系。换句话说,程序必须知道编写文件时使用的编码。
如果映射不正确,除非文件只包含在正确和错误编码中都常见的子集字符,否则后续的所有处理基本都会出错。
LaTeX 在此假设了一个基本前提:几乎所有可见的 ASCII 字符(十进制 32‑126)在 ASCII 编码表中对应的数字就是它们的数值。

做出这一假设的原因之一是当今使用的多数 8 位编码共享一个公共的 7 位平面。另一个原因是,为了有效使用 TeX,ASCII 可见部分的大多数字符必须被当作 字母(category letter)类别处理——因为只有具备该类别的字符才能在 TEX 中用于多字符命令名——或 其他(category other)——因为 TEX 不会将例如十进制数字识别为数字的一部分,除非它们具有该类别码。
当一个字符(更精确地说,一个 8 位数)在 TeX 中被声明为 字母 或 其他 类别时,这个 8 位数会透明地通过 TeX。也就是说,TeX 会排版该数字在字体中对应位置的符号。
基于上述假设,用于普通文本的字体必须包含(大多数)可见 ASCII 字符,并且这些字符必须按照 ASCII 编码进行编码。
所有其他 8 位数(即可见 ASCII 之外的数)如果出现在输入文件中,会被赋予 活动(active)类别码,这会使它们在 TeX 中表现为命令。因此,LaTeX 可以通过输入编码将它们转换为我们称为 LaTeX 内部字符表示 (LICR) 的形式。
对于 Unicode 的 UTF‑8 编码,处理方式类似。ASCII 字符自映射为自身,而多字节表示的起始八位字节充当活动字符,扫描其后续八位字节。若映射成功,结果会转换为 LICR 对象;若未映射,LaTeX 将抛出错误。
LICR 对象最重要的一点是:7 位 ASCII 字符的表示对任何编码的更改都是不变的,因为所有输入编码都应对可见 ASCII 透明。
输出(或字体)编码的作用是将内部字符表示映射到当前排版字体中的字形位置,或在某些情况下触发更复杂的操作。例如,它可以在当前字体的某位置上的重音符(accent)上方放置另一个符号,以得到抽象字符的印刷形象。
LICR 能编码 LaTeX 可寻址的所有字符。因此,它远大于单个 TeX 字体能够容纳的字符数量(最多 256 个字形)。在某些情况下,内部字符可以通过组合字形(如带重音的字符)在字体中呈现。然而,当内部字符需要特殊形状而字体中缺少相应字形时,就无法“伪造”。
尽管如此,LaTeX 的字符编码模型支持自动机制从不同字体中获取字形,使得缺失的字符能够被排版,只要系统中有提供该字符的合适额外字体。
7.2. LaTeX 的内部字符表示 (LICR)
文本字符在 LaTeX 中内部有三种表示方式。
作为字符的表示
少量字符以“自身”形式表示。例如,拉丁字母 A 以字符 'A' 表示。此类字符在上表中已展示。它们是可见 ASCII 的子集,在 TeX 中均被赋予 字母 或 其他 类别码。并非所有可见 ASCII 都以这种方式表示,因为有些字符是 TeX 语法的一部分,或并非所有字体都包含。如果在文本中使用 <,当前字体编码决定是得到 <(如 T1)还是倒置感叹号(如 OT1)。
作为字符序列的表示
TeX 的内部连字机制可以从一系列输入字符生成新字符。这实际上是字体的属性,尽管某些序列被显式设计为键盘难以直接输入的字符的快捷方式。只有少数通过此方式生成的字符被视为属于 LaTeX 的内部表示,包括由连字 -- 与 --- 生成的 en‑dash 与 em‑dash,以及由 `` 与 '' 生成的左右双引号(后者通常也可以用单个 " 表示)。虽然大多数字体实现了 !```` 与 ?```` 生成倒置感叹号和问号,但这并非所有字体都具备。因此 所有 此类字符都有一个作为命令的替代内部表示,例如 \textendash 或 \textexclamdown。
作为“字体编码特定”命令的表示
第三种内部表示方式覆盖了大多数字符,即使用特殊的 LaTeX 命令(或命令序列),这些命令在写入文件或作为移动参数时保持未展开。我们将此类特殊命令称为 字体编码特定命令,因为它们的含义取决于 LaTeX 在排版时所使用的当前字体编码。这些命令通过特殊声明(如下所述)进行声明,通常需要针对每个字体编码提供单独的定义。如果当前编码不存在定义,要么使用默认定义(若可用),要么向用户报告错误。
当文档中某处更改字体编码时,这些编码特定命令的定义不会立即更改,因为那会导致大量命令瞬间改变。相反,这些命令的实现方式是:一旦被使用,它们会检查当前定义是否仍适用于当前的字体编码;若不适用,则调用当前字体编码中的对应实现来完成实际工作。
字体编码特定命令的集合不是固定的,而是隐式地定义为所有单独字体编码中定义的命令的并集。因此,当向 LaTeX 添加新的字体编码时,可能需要引入新的编码特定命令。
7.3. 输入编码
加载 inputenc 包后,声明 \DeclareInputText 与 \DeclareInputMath 用于将 8 位输入字符映射为 LICR 对象的功能即可使用。这些命令应仅在编码文件(见下文)、宏包或必要时的文档导言区使用。
这些命令的第一个参数是 8 位数,可采用十进制、八进制或十六进制表示。推荐使用十进制,因为字符 ' 与/或 " 在某些语言支持宏包中可能具有特殊含义,导致八进制或十六进制在错误的加载顺序下失效。
1\DeclareInputText{number}{LICR-object}\DeclareInputText 用于声明文本中的字符映射。第二个参数包含编码特定命令(或命令序列),即该字符编号应映射到的 LICR 对象。例如,
1\DeclareInputText{239}{\"\i}将编号 239 映射为 “i‑umlaut” 的编码特定表示 \"\i。通过这种方式声明的输入字符不能在数学公式中使用。
1\DeclareInputMath{number}{math-object}如果该编号对应的字符用于数学公式,则必须使用 \DeclareInputMath。例如,在输入编码 cp437de(德国 MS‑DOS 键盘)中,
1\DeclareInputMath{224}{\alpha}将编号 224 映射为命令 \alpha。需要注意的是,此声明仅在数学模式下可用,\alpha 在其他模式下是非法的。
1\DeclareUnicodeCharacter{hex-number}{LICR-object}该声明仅在使用 utf8 选项时可用。它将 Unicode 编号映射为 LICR 对象(即可在文本中使用的字符)。例如,
1\DeclareUnicodeCharacter{00A3}{\textsterling}
2\DeclareUnicodeCharacter{011A}{\v E}
3\DeclareUnicodeCharacter{2031}{\textpertenthousand}理论上,两个空间之间应只有唯一的双向映射,这样在选择 utf8 时所有声明就可以自动生成。实际上情况更为复杂。首先,自动生成完整映射会占用大量 TeX 内存;其次,许多 Unicode 字符没有对应的 LICR 对象,反之亦然。inputenc 包通过仅加载与当前文档所用编码对应的 Unicode 映射来解决此问题,并在遇到未映射的 Unicode 字符时给出合适的错误信息。此后,用户需要自行提供合适的映射或加载额外的字体编码。
正如前文所述,输入编码声明可以出现在宏包或文档导言区。为确保能够正常工作,必须首先加载 inputenc 包以选择合适的编码。随后出现的输入编码声明会替代(或补充)当前输入编码已定义的内容。
使用 inputenc 包时,你可能会看到 \@tabacckludge 命令,它代表 “tabbing accent kludge”。该命令用于处理 \=、\` 与 \' 在 tabbing 环境中的特殊含义——这些命令本应表示特定的重音(即编码特定命令),但在 tabbing 环境中有不同的意义。因此,涉及这些重音的映射必须以特殊方式编码。例如,要将编号 232 映射为 “e‑grave” (\e`) 时,应写成:
1\DeclareInputText{232}{\@tabacckludge`e}而不是
1\DeclareInputText{232}{\`e}映射到文本和/或数学
出于技术和概念原因,TeX 在文本与数学之间做了非常严格的区分。除了可见的 ASCII 字符之外,产生字符的命令通常只能在文本或数学模式中使用其中一种,而不能两者兼用。
8 位输入编码的文件
输入编码存放在扩展名为 .def 的文件中,基本名称即为输入编码的名称(例如 latin1.def)。此类文件应仅包含本节讨论的命令。文件应以包含 \ProvidesFile 的标识行开头,例如:
1\ProvidesFile{latin1.def}[2000/07/01 v0.996 Input encoding file]如果存在需要额外宏包才能使用的编码特定命令映射,可以使用 \ProvideTextCommandDefault 声明默认实现。例如:
1\ProvideTextCommandDefault{\textonehalf}{\ensuremath{\frac12}}
2\ProvideTextCommandDefault{\textcent}{\TextSymbolUnavailable\textcent}\TextSymbolUnavailable 会发出警告,指出当前使用的字体不提供该字符。这在仅在加载特定字体时才可用的字符上非常有用(正如对 \textonehalf 的默认实现所示)。
其余部分仅应包含 \DeclareInputText 与 \DeclareInputMath 声明。如前所述,虽然不推荐使用 \DeclareInputMath,但在需要时仍可使用。不要在输入编码文件中使用其他命令,尤其是会阻止文件被多次读取的命令(如 \newcommand),因为编码文件常被多次加载。
UTF‑8 输入映射文件
如前所述,Unicode 到 LICR 对象的映射以只加载当前文档所需映射的方式组织。实现方式是为每个编码 enc.dfu,若该文件存在,则其中包含该编码对应的 Unicode 映射。除了若干 \DeclareUnicodeCharacter 声明外,此类文件只应包含一行 \ProvidesFile。
由于不同字体编码往往提供相同或相似的字符,同一 Unicode 字符的声明可能出现在多个 .dfu 文件中。因此,这些文件中的声明必须完全相同;否则,最后一次加载的声明会覆盖前面的,而不同文档的结果可能不一致。
因此,想为之前未覆盖的编码提供新 .dfu 文件的贡献者,需要仔细检查已有 .dfu 文件中的定义。inputenc 随附的标准文件已经保证了定义的一致性——它们全部由同一列表生成并拆分。完整的现有映射列表可在文件 utf8enc.dfu 中找到。
7.4. 输出编码
正如前文所述,输出编码定义了 LICR 与用于排版的字体中字形(或由字形组合而成的构件)之间的映射。这些映射在 LaTeX 中以两字母或三字母的名称引用(例如 OT1、T3)。如果映射对应于字体中字形的位置,我们就说某字体使用了该编码。下面我们来看这种映射的具体组成部分。
以 ASCII 字符内部表示的字符会直接传递给字体。换言之,TeX 使用 ASCII 码在当前字体中选择对应的字形。例如,字符 'A'(ASCII 码 65)会导致排版字体中位置 65 的字形。这也是为什么 LaTeX 要求文本字体在其 ASCII 码位置上包含所有可见 ASCII 字母——因为此机制是 TeX 的基础,无法改动。因此,对于可见 ASCII,所有输出编码都隐含了一一对应的映射。
以 ASCII 序列表示的字符(例如 “--")的处理方式如下:当首次加载当前字体时,TeX 被告知该字体包含若干所谓的 连字程序。这些程序定义了某些字符序列不应直接排版,而应被替换为字体中的其他字形。例如,TeX 在输入中遇到 “--"(即两次 ASCII 码 45)时,连字程序可能会把它替换为位置 123 的字形(即 en‑dash)。同样,这一机制也无法直接干预。
然而,内部字符表示的最大部分由 字体编码特定命令 组成,这些命令通过下文所述的声明进行映射。所有声明的前两个参数结构相同:第一个是字体编码特定命令(或其序列的第一部分),第二个是编码名称。其余参数取决于声明类型。
于是,编码 XYZ 通过一系列以 XYZ 为第二参数的声明来定义。随后,必须有相应的字体采用该编码。事实上,字体编码的开发通常是逆向进行的——先有已有字体,再为其提供相应的声明。这些声明集合会被赋予一个名称,如 OT1。下面我们以字体 ecrm1000(见字形图表)为例,该字体的编码在 LaTeX 中称为 T1,并为其构造相应的声明。字形图表中蓝色字符在每个文本编码中都应位于相同位置,因为它们会被 LaTeX 透明传递。
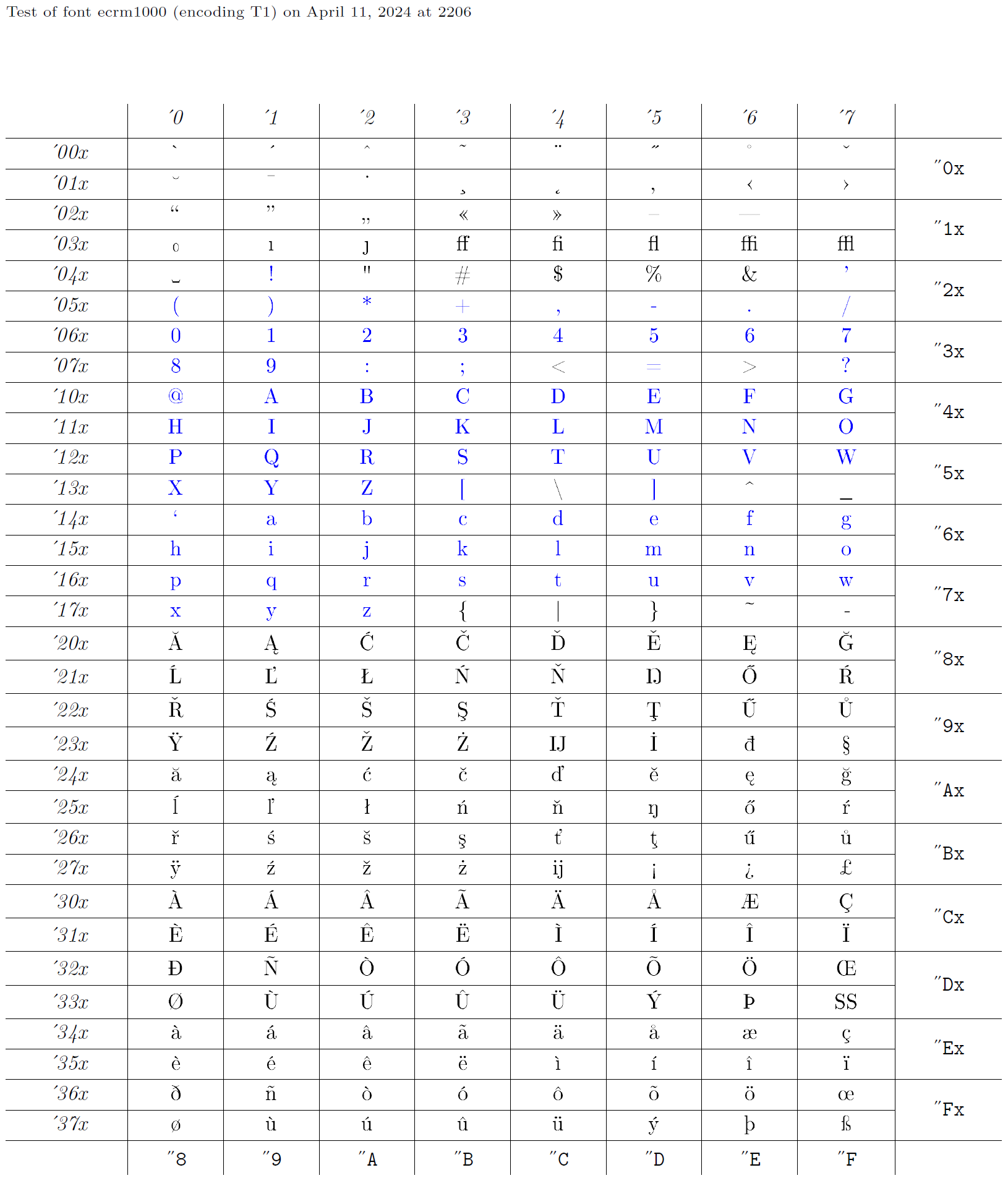
输出编码文件
输出编码文件同样使用 .def 扩展名。文件基名称结构稍有不同:全部小写的编码名称后接 enc(例如 t1enc.def 对应 T1 编码)。
这些文件只应包含本节讨论的声明。由于输出编码文件可能被 LaTeX 多次读取,必须避免使用会阻止重复读取的命令(如 \newcommand)。
输出编码文件同样以标识行开始,例如:
1\ProvidesFile{t1enc.def}[2001/06/05 v1.94 Standard LaTeX file]在为特定编码声明任何编码特定命令之前,必须先让 LaTeX 知道该编码。这通过 \DeclareFontEncoding 完成。此时通常也会声明该编码的默认替代规则,使用 \DeclareFontSubstitution。两者的详细用法请参见
How to set up new fonts。
1\DeclareFontEncoding{T1}{}{}
2\DeclareFontSubstitution{T1}{cmr}{m}{n}现在我们已经向 LaTeX 引入了 T1 编码,接下来可以声明该编码下字体编码特定命令的行为。
1\DeclareTextSymbol{LICR-Object}{encoding}{slot}\DeclareTextSymbol 是最简单的声明形式。内部表示可以直接映射到目标字体中的单个字形。第三个参数 slot(字形位置)可以使用十进制、八进制或十六进制。例如:
1\DeclareTextSymbol{\ss}{T1}{255}
2\DeclareTextSymbol{\AE}{T1}{'306} % font position as octal number
3\DeclareTextSymbol{\ae}{T1}{"E6} % ...as hexadecimal number这些语句声明 \ss、\AE 与 \ae 在 T1 编码的字体中分别对应十进制位置 255、十进制 198(八进制 '306)和十进制 230(十六进制 "E6)。如前所述,使用十进制是最安全的做法;混用进制显然是不好的风格。
1\DeclareTextAccent{LICR-accent}{encoding}{slot}很多字体把变音符号单独存放为字形,以便通过将该变音符与其他字形组合来构造带重音的字符。此类需要放在其他字形之上的重音使用 \DeclareTextAccent 声明。第三个参数 slot 为该重音在字体中的位置。例如:
1\DeclareTextAccent{\"}{T1}{4}定义了 “umlaut” 重音。此后,内部表示如 \"a 在 T1 编码中的意义为:在位置 97(字符 a 的 ASCII 码)上方放置位置 4 的重音,从而排版出带 umlaut 的 a。实际上,这一声明隐式定义了大量内部字符表示——即所有形如 \"<基字形> 的组合,其中 <基字形> 要么是通过 \DeclareTextSymbol 定义的,要么是属于 LICR 的 ASCII 字符(如 a)。
即使是看起来不太合理的组合,例如 \"\P(即段落符加 umlaut),在概念上也会成为一类字体编码特定命令的成员。
1\DeclareTextComposite
2 {LICR-accent}{encoding}{simple-LICR-object}{slot}上图中的字形图表包含大量单独的带重音字符,例如位置 '240(八进制)的 “a with umlaut”。因此,在 T1 中,编码特定命令 \"a 不应通过放置重音来实现,而是直接访问该位置的字形。实现如下:
1\DeclareTextComposite{\"}{T1}{a}{228}该声明指明 \"a 直接排版位置 228 的字形,从而禁用前面的重音声明。对所有其他以 \" 开头的编码特定命令,仍然使用重音声明。例如,\"b 将通过在 b 上方放置重音来生成带 umlaut 的 b。
第三个参数 simple-LICR-object 应为单个字母(如 a)或单个命令(如 \j、\oe)。
1\DeclareTextCompositeCommand
2 {LICR-object}{encoding}{simple-LICR-object}{code}虽然在 T1 编码中未使用此形式,但还有一种更通用的 \DeclareTextComposite 变体,允许在 slot 位置使用任意代码。例如,在 OT1 编码中,为了使环形重音在 A 上方的效果低于 TeX 原始的 \accent 原语,使用了以下声明:
1\DeclareTextCompositeCommand{\'}{OT1}{i}{\@tabacckludge'\i}
2\DeclareTextCompositeCommand{\^}{OT1}{i}{\^\i}一些变音符号并非放在字符上方,而是放在下方。对此没有专门的声明形式,因为实际定位涉及低层 TeX 代码,此时可使用通用的 \DeclareTextCommand。
1\DeclareTextCommand{LICR-object}{encoding}[num][default]{code}例如,T1 编码中的 “下划线” 重音 \b 定义如下:
1\DeclareTextCommand{\b}{T1}[1]
2 {\hmode$bgroup\o$lign{\relax#1\crcr\hidewidth\sh$ft{29}%
3 \vbox to.2ex{\hbox{\char9}\vss}\hidewidth}\egroup}这里的细节并不重要,只需注意 \DeclareTextCommand 类似于 \newcommand:可选的 num 参数指定参数个数(这里是 1),第二个可选 default 参数此处未使用,最后的必选参数包含实际代码。
\DeclareTextCommand 也可用于构建仅包含单一控制序列的字体编码特定命令——此时不使用可选参数,从而得到零参数命令。例如,T1 中没有 “千分号” 的单独字形,但在位置 '30 有一个小写的 “o”。如果将其直接放在 % 后面,就能得到合适的符号。因此可以声明:
1\DeclareTextCommand{\textperthousand} {T1}{\%\char 24}
2\DeclareTextCommand{\textpertenthousand}{T1}{\%\char 24\char 24 }至此,我们已覆盖声明新编码所需的所有命令。正如前文所述,编码定义文件中仅应包含这些命令。
输出编码默认值
现在来看如果在当前字体编码中未对某编码特定命令进行声明,会产生什么情况。一般有两种可能:要么 LaTeX 为该 LICR 对象提供了默认定义,则使用该默认;要么报错提示在当前编码中该 LICR 对象不可用。为 LICR 对象设置默认值的方式有多种。
1\DeclareTextCommandDefault{LICR-object}[num][default]{code}\DeclareTextCommandDefault 为在当前编码缺少特定设置时使用的 LICR-object 提供默认定义。例如,\textregistered 的默认实现将该字符由两个其他字符组合而成:
1\DeclareTextCommandDefault{\textregistered}{\textcircled{\scshape r}}技术上,这些默认定义存储在名称为 ? 的编码中。虽然不建议依赖该实现细节(实现可能在未来改变),但这意味着不能声明名为 ? 的编码。
1\DeclareTextSymbolDefault{LICR-object}{encoding}在多数情况下,默认定义不需要代码,仅指示 LaTeX 从已知存在该字符的某个编码中取字形。比如 textcomp 宏包就包含大量指向 TS1 编码的默认声明。例如:
1\DeclareTextSymbolDefault{\texteuro}{TS1}\DeclareTextSymbolDefault 可用于为任何无参数的 LICR 对象设定默认,而不仅限于在其他编码中使用 \DeclareTextSymbol 声明的对象。
1\DeclareTextAccentDefault{LICR-accent}{encoding}针对带一个参数的 LICR 对象(如重音),也有类似的默认声明形式。例如,LaTeX 核心中包含如下声明:
1\DeclareTextAccentDefault{\"}{OT1}
2\DeclareTextAccentDefault{\t}{OML}这表示如果当前编码未定义 \",则使用 OT1 编码中的实现;同理,获取系结重音时若无更好的选择,则从 OML 中取得。
1\ProvideTextCommandDefault{LICR-object}[num][default]{code}\ProvideTextCommandDefault 用于“提供”另一种默认实现。其工作方式与 \DeclareTextCommandDefault 相同,只在之前未定义默认时才生效。此方式常用于输入编码文件中,为不常见的 LICR 对象提供一些简易默认。例如:
1\ProvideTextCommandDefault{\textonequarter}{\ensuremath{\frac14}}
2\ProvideTextCommandDefault{\textcent}{\TextSymbolUnavailable\textcent}随后 textcomp 包可以用指向真实字形的声明覆盖这些定义。使用 \Provide… 而非 \Declare… 可避免在加载输入编码文件时意外覆盖更好的默认实现。
1\UndeclareTextCommand{LICR-object}{encoding}在某些情况下,需要删除已有声明以确保使用默认声明。这可以通过 \UndeclareTextCommand 完成。例如,textcomp 包会从 OT1 编码中撤销 \textdollar 与 \textsterling 的定义,因为并非所有 OT1 编码的字体都有这些符号。
1\UndeclareTextCommand{\textsterling}{OT1}
2\UndeclareTextCommand{\textdollar} {OT1}如果不进行此删除,来自 TS1 的新默认声明将无法在使用 OT1 编码的字体时生效。
1\UseTextSymbol{encoding}{LICR-object}
2\UseTextAccent{encoding}{LICR-object}{simple-LICR-object}上述 \DeclareTextSymbolDefault 与 \DeclareTextAccentDefault 背后的操作也可以直接使用。例如,假设当前编码为 U,则
1\UseTextSymbol{OT1}{\ss}
2\UseTextAccent{OT1}{\'}{a}的效果等同于以下代码。注意,a 在编码 U 中排版——仅重音来自另一个编码。
1{\fontencoding{OT1}\selectfont\ss}
2{\fontencoding{OT1}\selectfont\'{\fontencoding{U}\selectfont a}}标准 LICR 对象列表
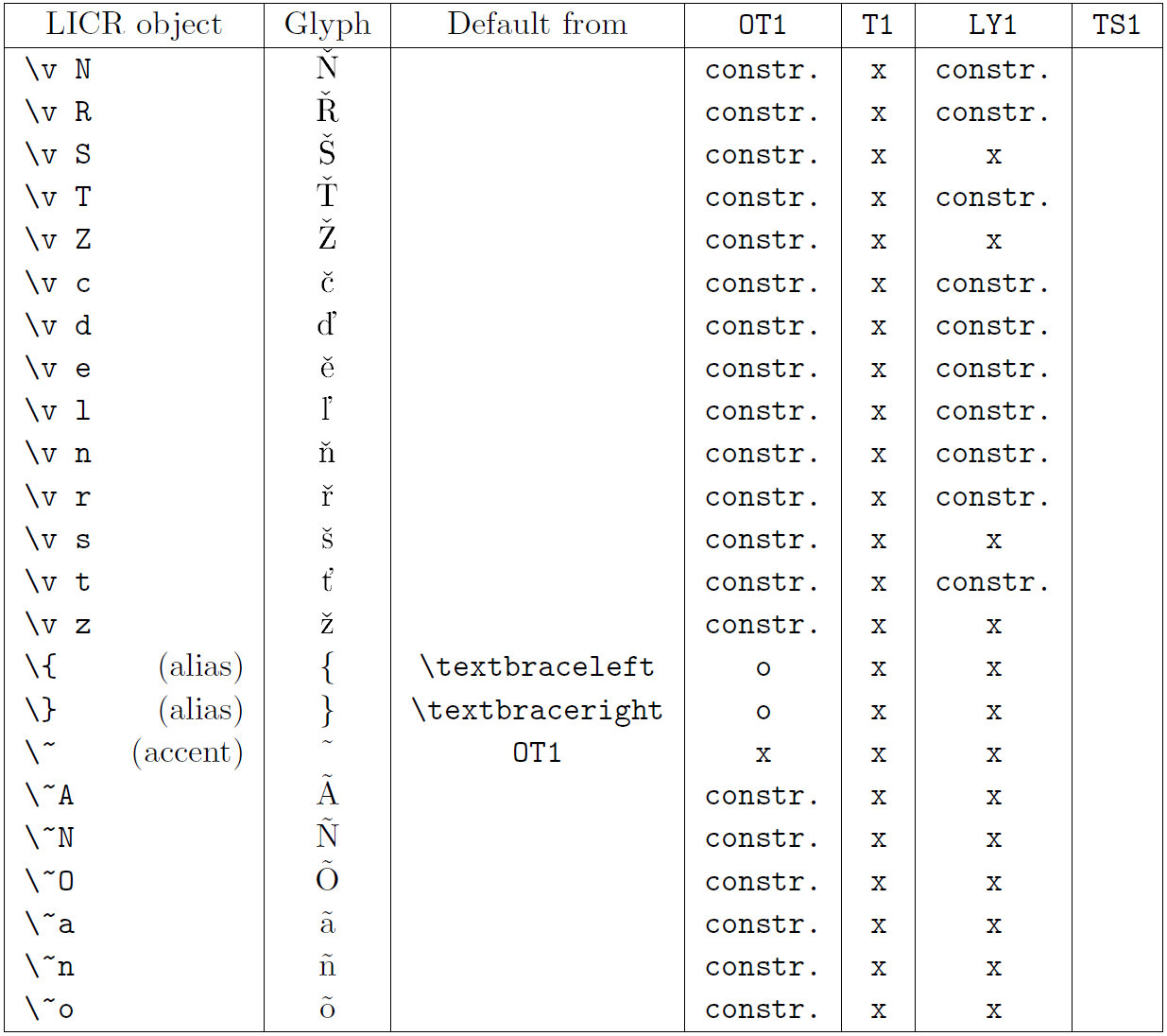
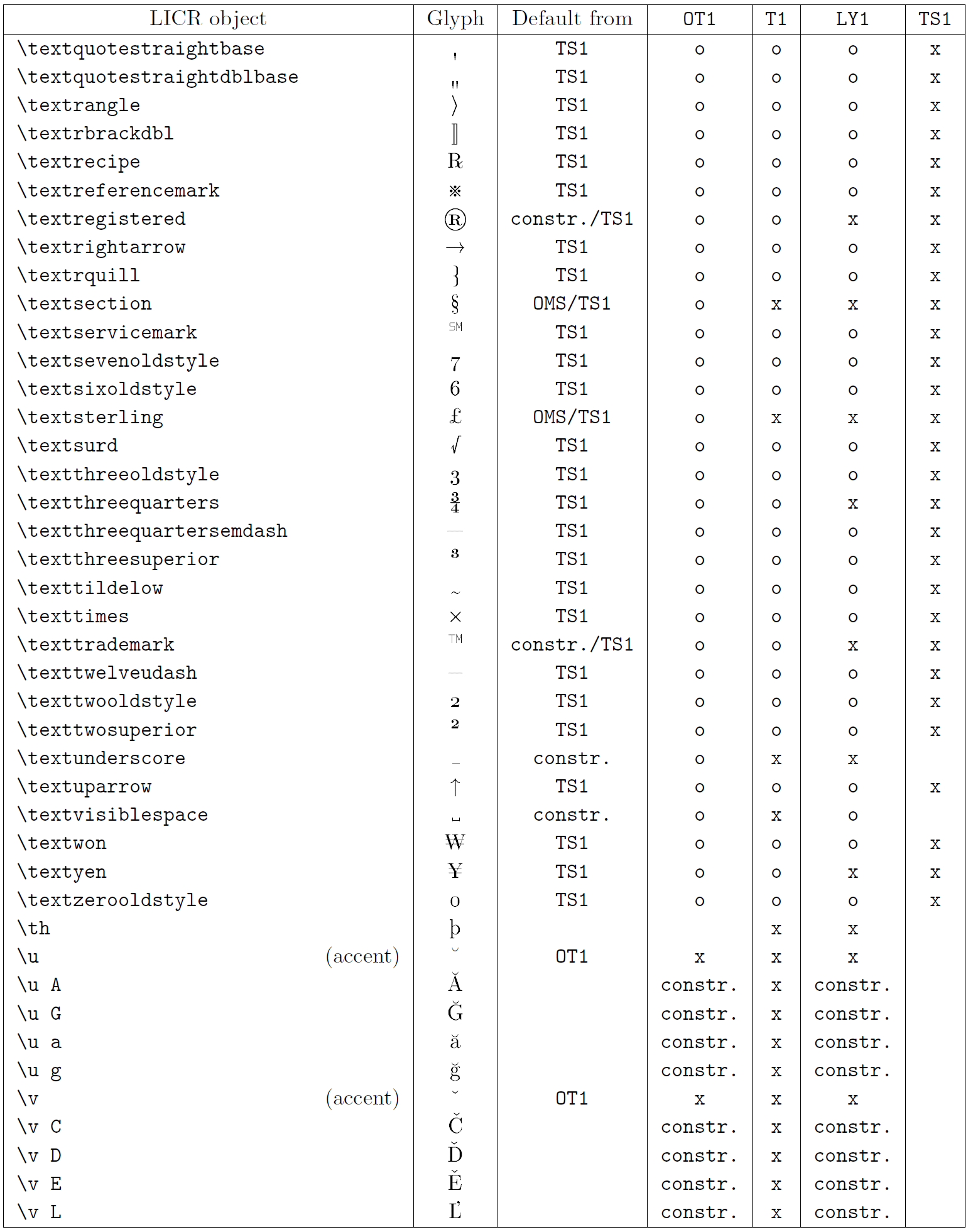
本小节的表格概览了三种主要拉丁语言编码(OT1——原始 TeX 编码、T1——LaTeX 标准编码、LY1——Y&Y 提出的另一 8 位编码)以及通过加载 textcomp 包获得的 TS1(LaTeX 标准文本符号编码)中声明的所有 LICR 对象。
表格第一列按字母顺序列出 LICR 对象名称,并指示哪些对象充当重音。第二列显示该对象的字形示例。
第三列说明对象是否有默认声明。如果列出某个编码,表示默认情况下会从该编码的合适字体中获取字形;constr. 表示通过低层 TeX 代码生成;若列为空,表示没有默认定义,使用时会报 “Symbol unavailable”。如果对象是其他 LICR 对象的别名,则在此列给出别名。
第四至第七列显示对象在对应编码中的可用性。其中,x 表示该对象在该编码的字体中本地可用(作为字形),o 表示通过所有编码的默认可用,constr. 表示由多个字形、重音或其他元素组合生成。如果默认来源于 TS1,则仅在加载 textcomp 包后可用。
LICR 对象 (第 1 部分)
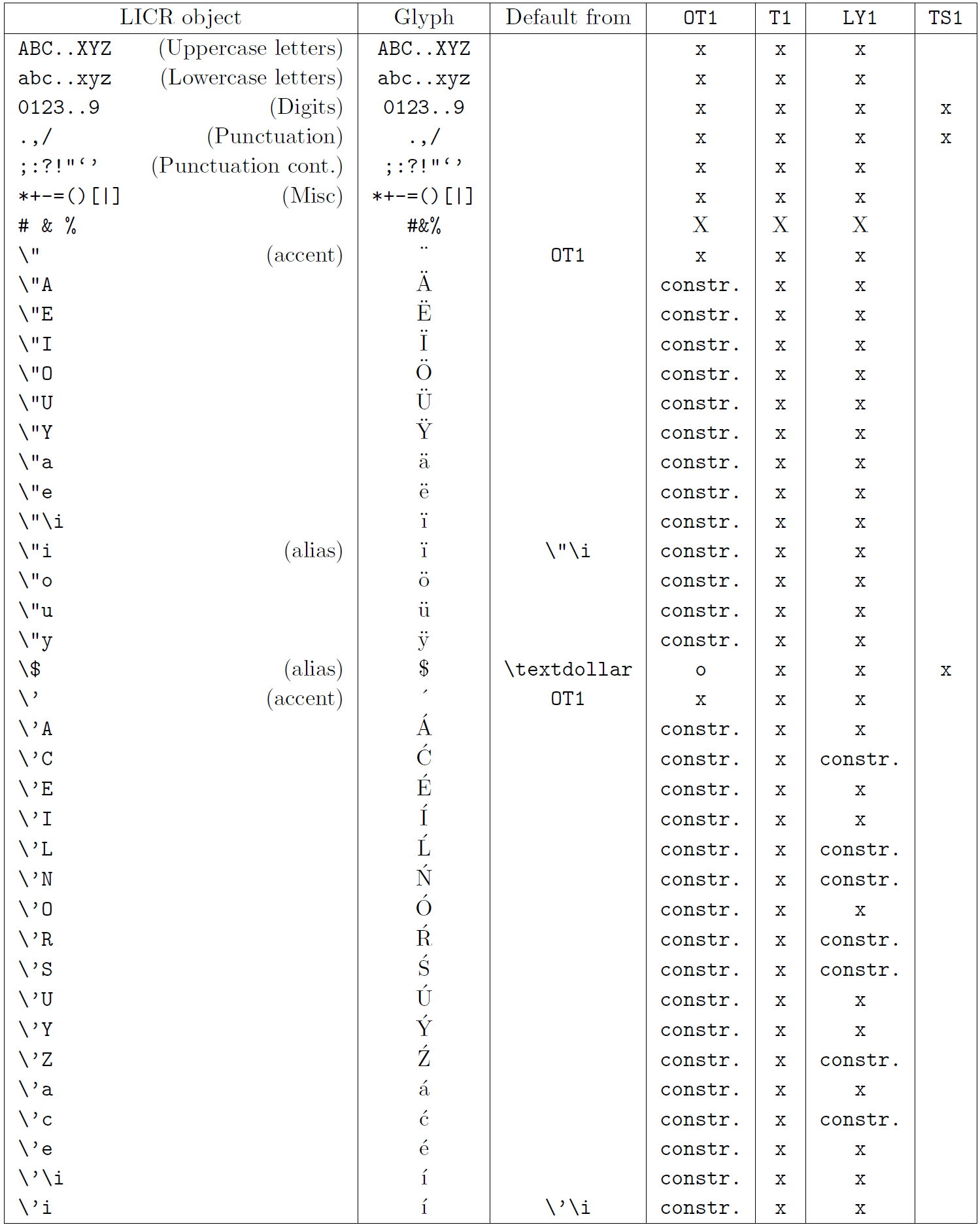
LICR 对象 (第 2 部分)
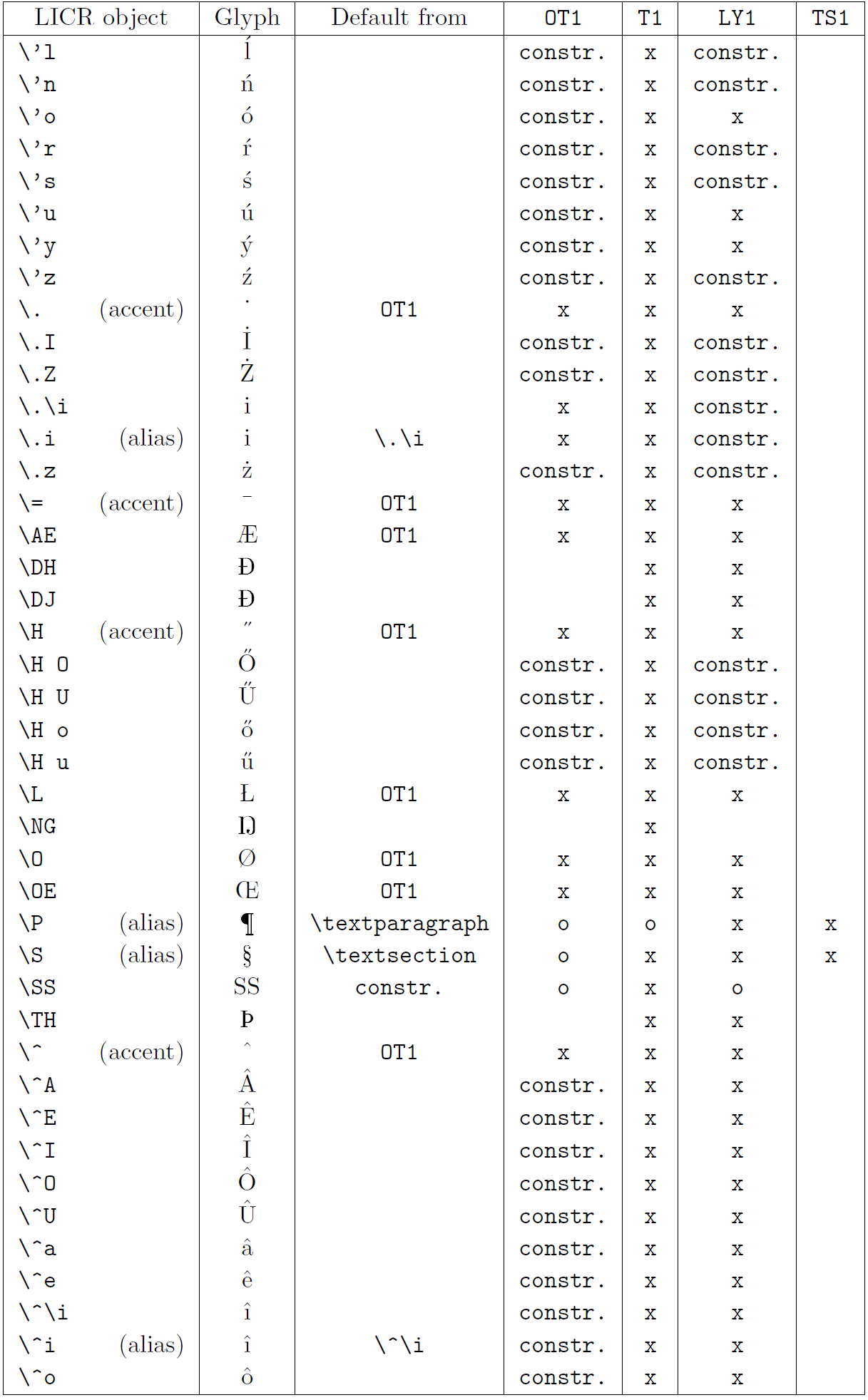
LICR 对象 (第 3 部分)
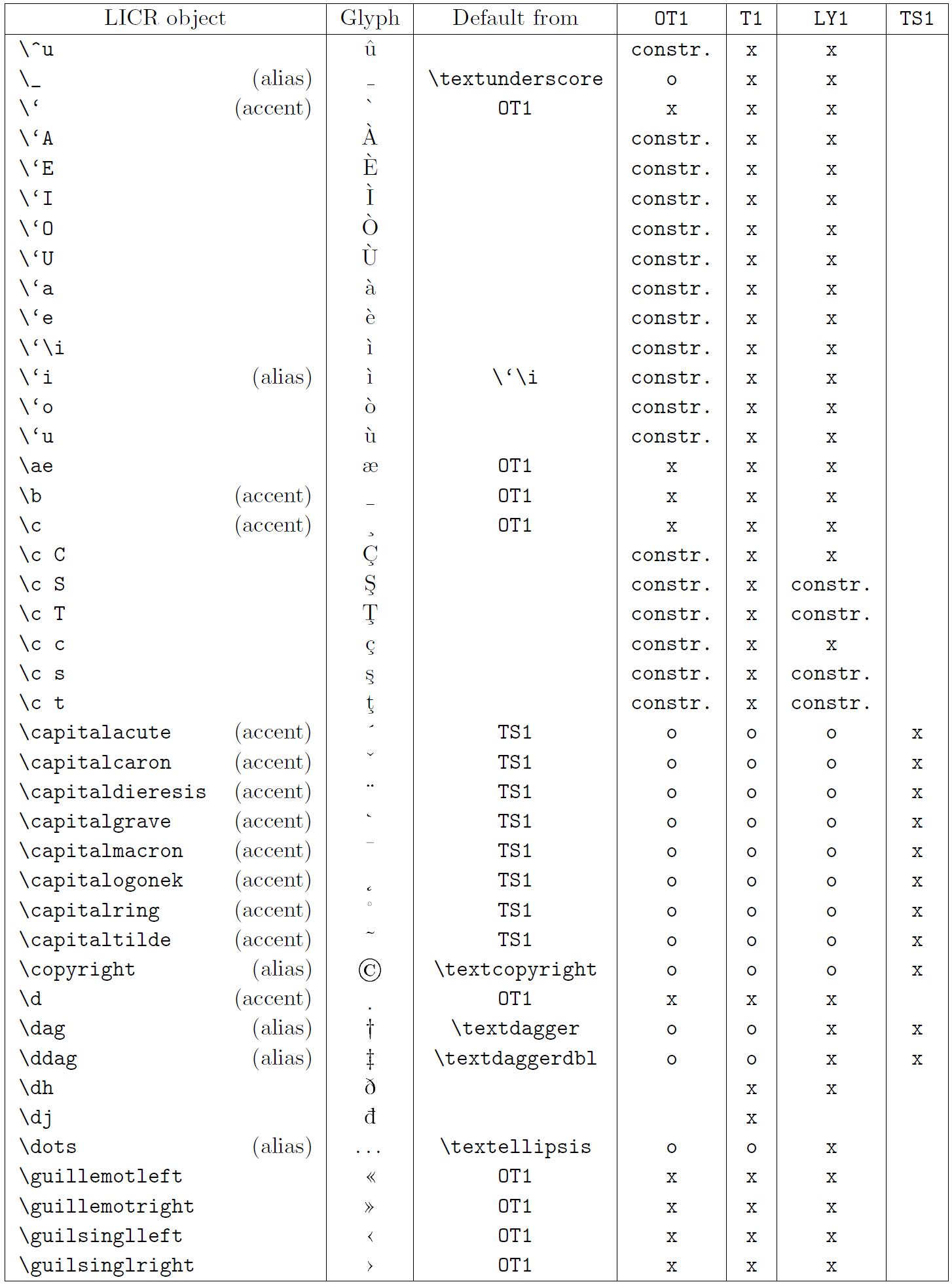
LICR 对象 (第 4 部分)
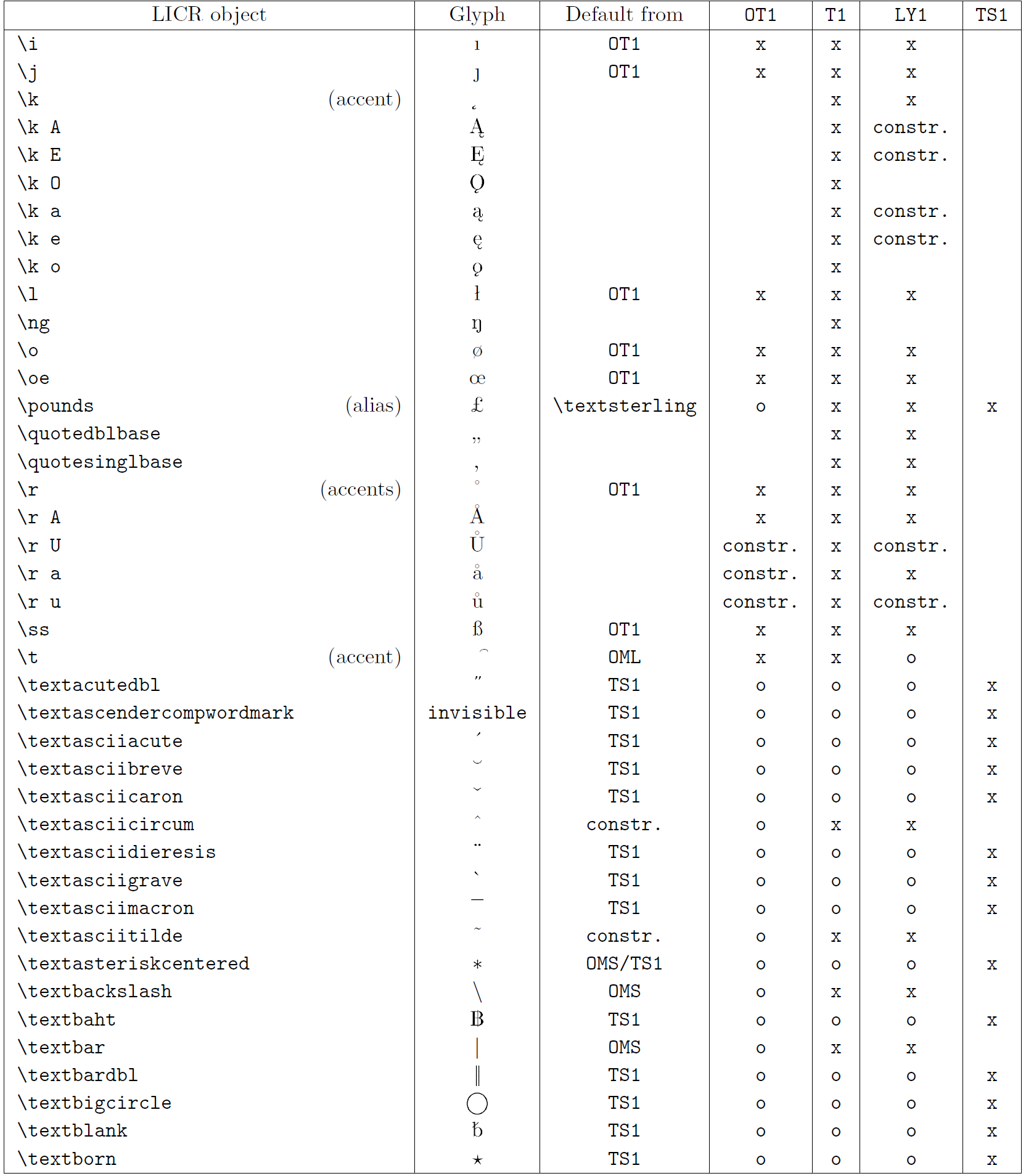
LICR 对象 (第 5 部分)
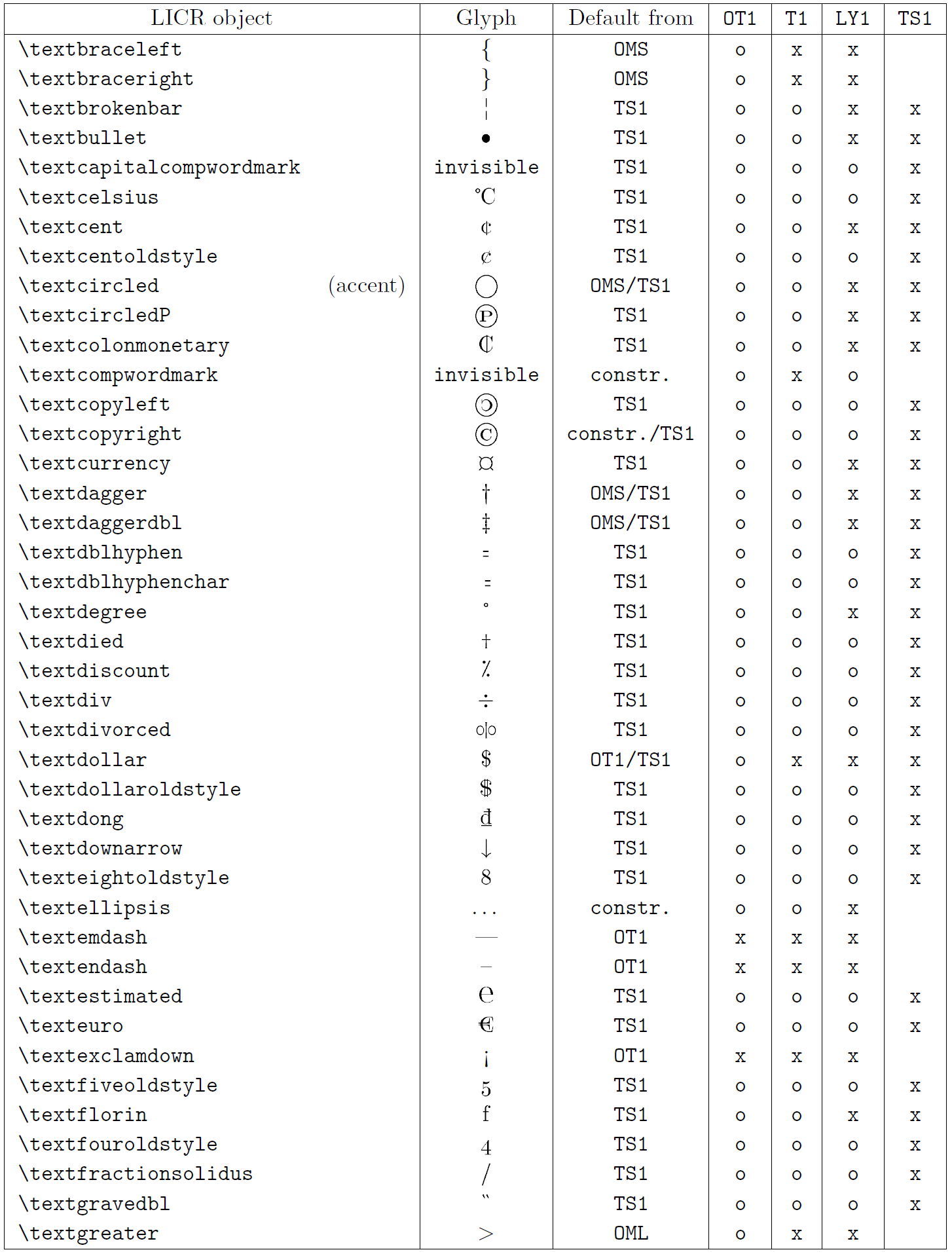
LICR 对象 (第 6 部分)
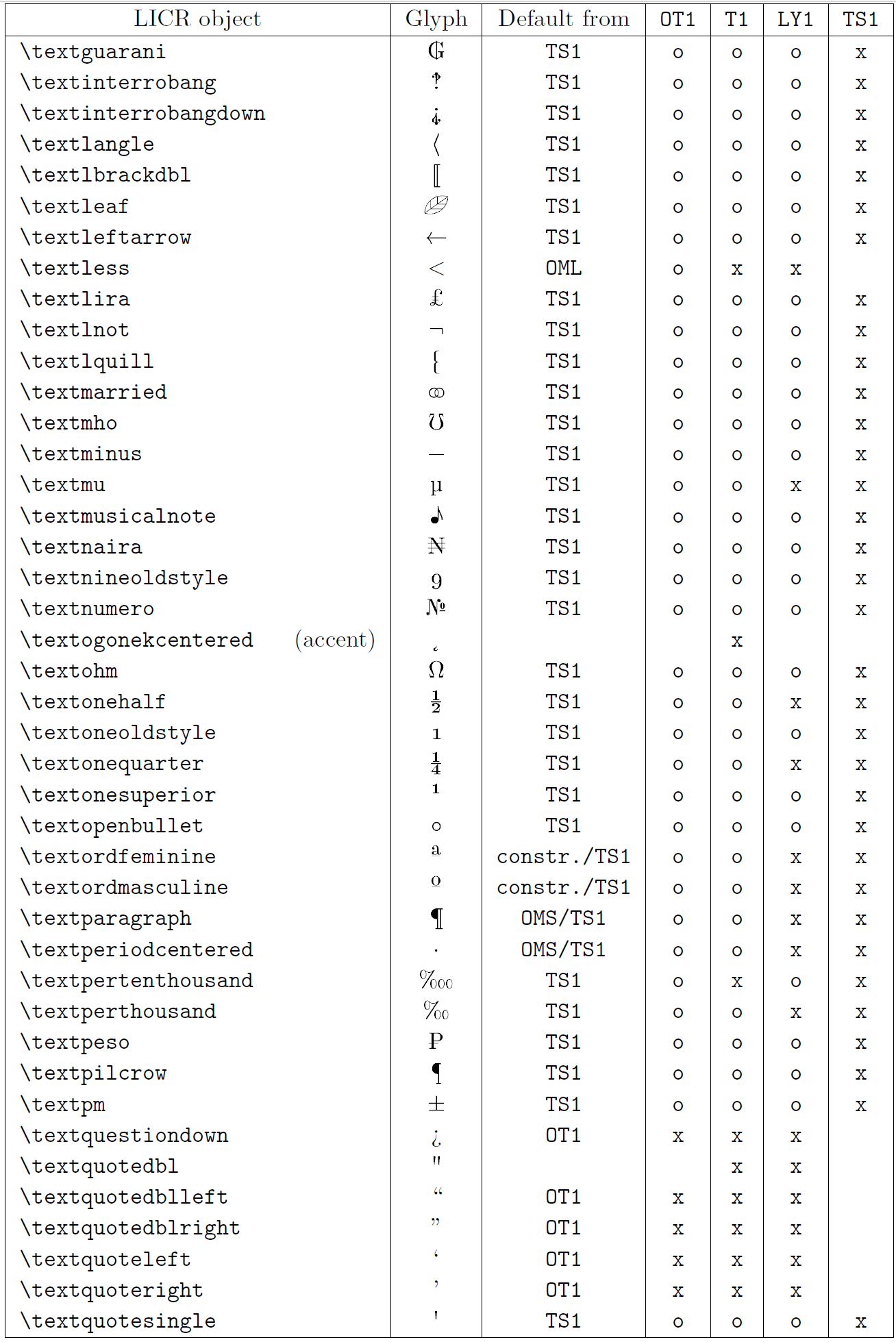
LICR 对象 (第 7 部分)
LICR 对象 (第 8 部分)