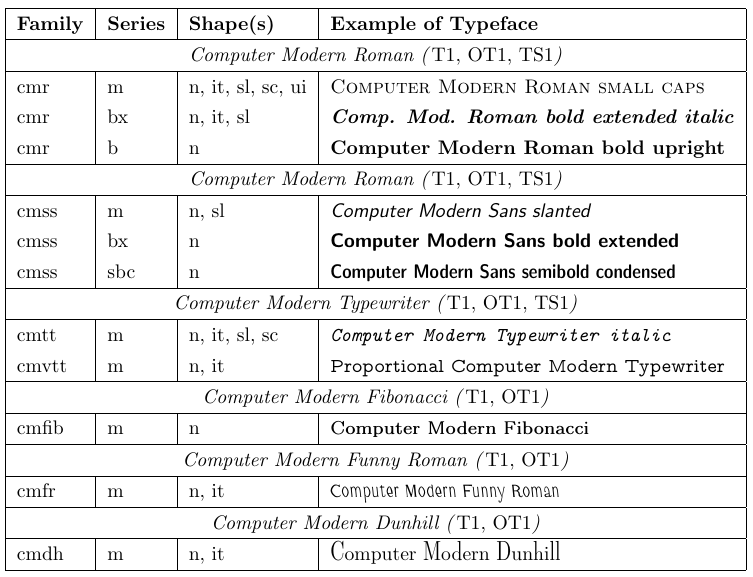
4. 标准 LaTeX 字体
本文简要介绍了随 LaTeX 一起分发的标准文本字体。随后讨论了 LaTeX 对输入编码和字体编码的标准支持。文章最后描述了一个用于追踪 LaTeX 字体处理的宏包以及另一个用于显示字形表的宏包。
4.1. Computer Modern Roman
一套名为 Computer Modern 的字体由 Donald Knuth 与 TeX 一起开发。直到 1990 年代初,这些字体几乎是唯一能与 TeX(从而与 LaTeX)一起使用的字体。每套字体仅包含 128 个字形,因此不能把带音调的字符单独作为字形提供。于是使用这些字体时,带音调的字符必须通过 TeX 的 \accent 原语生成,这又意味着带音调字符的单词无法自动断字。虽然在英文文档中这一限制尚可接受,但对其他语言来说显而易见是个缺点。
这些缺陷在欧洲的 TeX 用户中引起了极大关注,最终促成了 1989 年 TeX 的一次重新实现,以在内部和外部都支持 8 位字符。1990 年开发了用于文本字体的标准 8 位编码(T1),它包含了大量带音调字符,能够支持基于拉丁字母的 30 多种语言。随后,Computer Modern 字体族被重新实现,并设计了额外字符,使得这些字体能够完整符合该编码方案。
4.2. 选择输入编码:inputenc 宏包
如果你可以通过单键敲击或其他输入方法(例如,先敲 ` 再敲 a 得到 à)直接输入带音调字符,并且编辑器能够正确显示它们……

…… 那么理想情况下,你可以直接把这样的文本交给 LaTeX,而不必手动输入 \`a、\^e 等。
对于法语、德语等语言,这种做法是可行的。然而,对于俄语和希腊语等语言,直接输入是必需的,因为这些语言的几乎每个字符在 LaTeX 中都有对应的命令名称。例如,默认的俄语定义 \reftextafter 包含如下文本(意为 “在下一页”):
1\cyrn\cyra\ \cyrs\cyrl\cyre\cyrd\cyru\cyryu\cyrshch\cyre\cyrishrt
2\ \cyrs\cyrt\cyrr\cyra\cyrn\cyri\cyrc\cyre常人不太可能每天都键入这种内容。尽管如此,它具有完全可移植的优势,能够在任何 LaTeX 安装上被正确解释。另一方面,如果能够在合适的键盘上直接键入
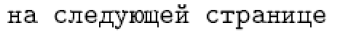
显然更为理想,前提是 LaTeX 能够识别这种输入。问题在于,文件中存储的并不是我们在上面序列中看到的字符,而是表示这些字符的字节(八位字节)。在不同的环境(使用不同的编码)下,同样的字节可能对应不同的字符。
只要所有操作都在同一台计算机上进行,并且所有程序以相同方式解释文件中的字节,通常没有问题。如果是这种情况,可以启用一些较新 TeX 实现内置的自动翻译机制。但当在此环境下生成的文件被发送到另一台计算机时,处理很可能会失败,甚至更糟——看似成功却会因为显示错误字符而产生错误结果。
inputenc 宏包正是为了解决此类问题而创建的。它的主要作用是让 LaTeX 知晓文档(或文档的一部分)使用的编码。实现方式是以选项形式加载宏包并指明编码名称,例如:
1\usepackage[cp1252]{inputenc} % Windows 1252(西欧)代码页从此以后,无论在何种安装环境下,LaTeX 都能够正确解释文档其余部分的字节,而不受该计算机上其他用途的编码影响。
下面给出一个典型示例。它是一段使用 koi8-r 编码的短文本,该编码在俄罗斯很常用。源码中显示的文本是使用拉丁‑1 编码(例如在德国)的计算机所看到的样子。输出则表明 LaTeX 仍然能够正确解释文本,因为我们已经告知它所使用的输入编码。

下面列出了 inputenc 当前支持的编码。该接口文档齐全,且可以轻松添加新编码。因此,如果你的计算机使用的编码未在列表中,建议查阅 inputenc 宏包文档。你也可以在网络上搜索其他作者为 inputenc 创建的编码文件。例如,许多与西里尔文字相关的编码随其他西里尔语言的字体支持宏包一起分发。
ISO‑8859 标准定义了若干重要的单字节编码。与拉丁字母相关的编码均受 inputenc 支持。对于 Windows 操作系统,Microsoft 定义了若干单字节编码。此外,还可以使用其他厂商定义的编码。
latin1这是 ISO‑8859‑1 编码(又称 Latin 1)。它可以表示大多数西欧语言,包括阿尔巴尼亚语、加泰罗尼亚语、丹麦语、荷兰语、英语、法罗语、芬兰语、法语、加利西亚语、德语、冰岛语、爱尔兰语、意大利语、挪威语、葡萄牙语、西班牙语和瑞典语。latin2ISO Latin 2 编码(ISO‑8859‑2)支持使用拉丁字母的中欧斯拉夫语言。可用于克罗地亚语、捷克语、德语、匈牙利语、波兰语、罗马尼亚语、斯洛伐克语和斯洛文尼亚语。latin3该字符集(ISO‑8859‑3)用于世界语、加利西亚语、马耳他语和土耳其语。latin4ISO Latin 4 编码(ISO‑8859‑4)可表示爱沙尼亚语、拉脱维亚语和立陶宛语等语言。latin5ISO Latin 5 编码(ISO 8859‑9)与 Latin 1 关系密切,用土耳其字母取代了 Latin 1 中很少使用的冰岛字母。latin9Latin 9(或 ISO‑8859‑15)是 Latin 1 的另一小变体,新增了欧元符号以及一些在法语和芬兰语中缺失的字符,如\AE连字。它正日益成为 Latin 1 的替代品。cp437IBM 437 代码页(MS‑DOS 拉丁字符集,但包含许多绘制方框的图形字符)。cp850IBM 850 代码页(MS‑DOS 多语言,类似 latin1)。cp852IBM 852 代码页(MS‑DOS 多语言,类似 latin2)。cp858IBM 858 代码页(在 IBM 850 基础上加入欧元符号)。cp865IBM 865 代码页(MS‑DOS 挪威)。cp1250Windows 1250(中东欧)代码页。cp1252Windows 1252(西欧)代码页。cp1257Windows 1257(波罗的海)代码页。ansinewWindows 3.1 ANSI 编码;是 cp1252 的同义词。decmultiDEC 多国字符集编码。applemacMacintosh(标准)编码。macceMacintosh 中欧代码页。nextNext Computer 编码。utf8Unicode 的 UTF‑8 编码支持。
大多数 TeX 安装默认接受 8 位字符。然而,如果不进行进一步的调整(例如 inputenc 所做的),结果可能难以预测:某些字符可能消失,或者你会得到当前字体在对应字节位置的字符,这并不一定是期望的字形。此行为在很长时间里都是 LaTeX2e 的默认设置,因为有些人依赖它。不过,为了确保此类错误能够被捕获,inputenc 提供了 ascii 选项,使得所有超出 32‑126 范围的字符均被视为非法。
1\inputencoding{encoding}最初,inputenc 宏包的设计目的是为整个文档指定一种编码——因此在导言区使用选项。但也可以在文档中部使用 \inputencoding 命令来切换编码。该命令的参数是所需的编码名称。
当 inputenc 开发时,大多数 LaTeX 安装使用的是单字节编码(即本节讨论的编码)。如今,随着系统对 Unicode 的支持,UTF‑8 已成为另一种流行编码。UTF‑8 是一种可变长度编码,使用一到四个字节表示一个 Unicode 字符。inputenc 通过 utf8 选项加入了对该编码的支持。技术上,它并未提供完整的 UTF‑8 实现,只映射那些在标准 LaTeX 字体中已有表示的 Unicode 字符(主要是拉丁和西里尔字符集):其余字符会产生相应的错误信息。此外,Unicode 组合字符不受支持,但这在实际使用中通常不是问题。
1\usepackage[utf8]{inputenc}
2\usepackage{textcomp} % for Latin interpretation
3-----------------------------------------------
4German umlauts in UTF-8: ^^c3^^a4^^c3^^b6^^c3^^bc
5\par\inputencoding{latin1}% switch to Latin 1
6But interpreted as Latin 1: ^^c3^^a4^^c3^^b6^^c3^^bc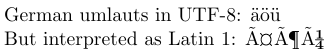
在 UTF‑8 中,ASCII 字符自行表示,而大多数拉丁字符由两个字节表示。在示例源码中,德语元音的两字节 UTF‑8 表示采用 TeX 的十六进制记法,即每个字节前加 ^^。在不理解 UTF‑8 的编辑器中,这些可能会被误认为是 Latin 1 字符的输出。
如果需要更全面的 UTF‑8 支持(包括对韩文、中文和日文字符的支持),可以使用由 Dominique Unruh 编写的 ucs 宏包。如果 inputenc 的方案无法满足需求,请尝试该宏包。
4.3. 使用 fontenc 宏包选择字体编码
要在 LaTeX 中启用文本字体编码,需要在导言区或文档类中加载相应的编码。更确切地说,必须加载能够访问特定编码字体字形的定义。完成此操作的典型方式是通过 fontenc 宏包,后者接受以逗号分隔的字体编码列表作为宏包选项。列表中的最后一个编码会自动成为文档的默认编码。如果加载了西里尔编码,\MakeUppercase 和 \MakeLowercase 影响的命令列表也会自动扩展。例如:
1\usepackage[T2A,T1]{fontenc}将会加载西里尔 T2A 和 T1 编码所需的全部定义,并将后者设为文档默认的字体编码。
与普通宏包的行为不同,fontenc 可以多次加载,每次使用不同的选项调用 \usepackage。这对于文档类先加载一组编码,而用户随后在导言区再加载更多编码是必要的。多次加载不会产生副作用,唯一的影响可能是改变文档的默认字体编码。
如果文档中使用了语言支持宏包(例如 babel 系统自带的宏包),通常这些宏包已经预先加载了所需的字体编码。
4.4. 使用 tracefnt 宏包追踪字体选择
为了检测字体选择系统中的问题,你可以使用 tracefnt 宏包。它提供了多个选项,可自定义 NFSS 在终端和日志文件中显示的信息量。
errorshow该选项会抑制终端上所有警告和信息,只在日志文件中记录。仅显示真实错误。你应在打印重要出版物之前仔细检查日志文件,因为有关字体替换等的警告可能意味着最终结果不正确。warningshow指定该选项后,警告和错误都会在终端显示。此设置提供的细节与未加载tracefnt时 LaTeX2e 的默认行为相同。infoshow这是加载tracefnt时的默认选项。除写入日志文件之外,额外的信息也会在终端显示。debugshow该选项额外显示文本字体的更改以及在大括号组或环境结束时恢复字体的信息。启用此选项时要小心,因为会产生非常大的日志文件。pausing该选项会把所有警告转换为错误,以帮助在重要出版物中检测问题。loading该选项显示外部字体的加载过程。但如果你使用的格式或文档类已经加载了一些字体,则这些字体不会被此选项显示。
4.5. 使用 nfssfont.tex 显示字体表和示例
名为 nfssfont.tex 的文件可用于测试新字体、生成显示所有字符的字体表以及执行其他与字体相关的操作。该文件随任何 LaTeX 发行版一起提供。运行该文件时,程序会提示你输入要测试的字体名称。输入可以是没有扩展名的外部字体名(例如 cmr10,即 Computer Modern Roman 10pt),也可以留空,此时系统会要求你提供 NFSS 字体规格:编码名称(默认 T1)、字体族名(默认 cmr)、字形系列(默认 m)、字形形状(默认 n)以及字体大小(默认 10pt)。随后程序会加载对应分类的外部文件。
接下来,系统会要求你输入一个命令。最常用的命令可能是 \table,它会生成如下所示的字体表。\text 命令同样有趣,它会生成一段较长的文本样本。要切换到新测试字体,输入 \init;要结束测试,输入 \bye 或 \stop;要了解所有可用的测试,请输入 \help。
1**********************************************
2* NFSS font test program version <v2.2b>
3*
4* Follow the instructions
5**********************************************
6
7Input external font name, e.g., cmr10
8(or <enter> for NFSS classification of font):
9
10\currfontname=cmr10
11Now type a test command (\help for help):)
12*\table
13
14*\newpage
15*\init
16Input external font name, e.g., cmr10
17(or <enter> for NFSS classification of font):
18
19\currfontname=
20*** NFSS classification ***
21
22Font encoding [T1]:
23
24\encoding=OT1
25(ot1enc.def)
26Font family [cmr]:
27
28\family=cmdh
29Font series [m]:
30
31\series=m
32Font shape [n]:
33
34\shape=n
35Font size [10pt]:
36
37\size=10
38(ot1cmdh.fd) Now type a test command (\help for help):
39*\text
40
41*\bye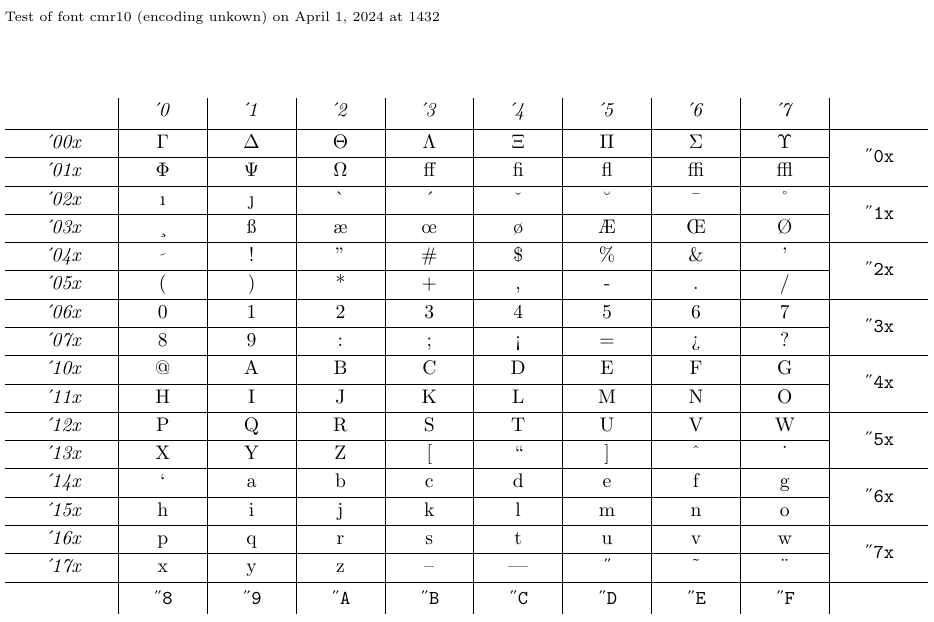

有两点需要注意。首先,
nfssfont.tex程序会隐式执行一次\init命令,因此第一行输入要么包含字体名称,要么保持完全为空,以表明随后进入 NFSS 分类。其次,\init的输入必须单独占据一行,且不能有任何其他内容(甚至不能有注释),因为行结束标志了对类似Font encoding[T1]: \encoding=之类提示的响应结束。