Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
هناك بعض المواقف التي لا تكون فيها إزالة المناطق غير المدمجة تماما من المستند أثناء Mail Merge مرغوبة أو تؤدي إلى ظهور المستند غير مكتمل. يمكن أن يحدث هذا عندما يتم عرض عدم وجود بيانات الإدخال للمستخدم في شكل رسالة بدلا من إزالة المنطقة بالكامل.
هناك أيضا أوقات لا تكون فيها إزالة المنطقة غير المستخدمة من تلقاء نفسها كافية، على سبيل المثال، إذا كانت المنطقة مسبوقة بعنوان أو كانت المنطقة مضمنة في جدول. إذا كانت هذه المنطقة غير مستخدمة، فسيظل العنوان والجدول بعد إزالة المنطقة التي ستبدو في غير مكانها في المستند.
توفر هذه المقالة حلا لتحديد كيفية التعامل مع المناطق غير المستخدمة في المستند يدويا. يتم توفير الرمز الأساسي لهذه الوظيفة ويمكن إعادة استخدامه بسهولة في مشروع آخر.
يتم تعريف المنطق الذي سيتم تطبيقه على كل منطقة داخل فئة تنفذ IFieldMergingCallback واجهة. بنفس الطريقة، يمكن إعداد معالج Mail Merge للتحكم في كيفية دمج كل حقل، ويمكن إعداد هذا المعالج لتنفيذ إجراءات في كل حقل في منطقة غير مستخدمة أو في المنطقة ككل. ضمن هذا المعالج، يمكنك تعيين التعليمات البرمجية لتغيير نص منطقة أو إزالة العقد أو الصفوف والخلايا الفارغة وما إلى ذلك.
في هذه العينة، سنستخدم المستند المعروض أدناه. يحتوي على مناطق متداخلة ومنطقة موجودة داخل جدول.
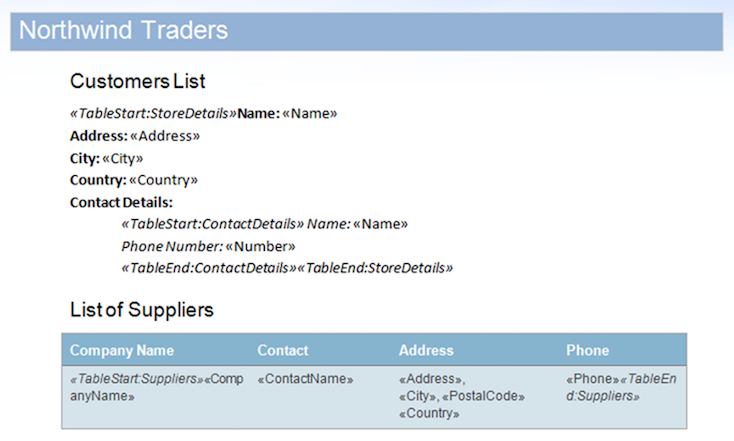
كدليل توضيحي سريع، يمكننا تنفيذ قاعدة بيانات عينة على نموذج المستند مع تمكين علامة MailMergeCleanupOptions.REMOVE_UNUSED_REGIONS. ستقوم هذه الخاصية تلقائيا بإزالة المناطق غير المدمجة من المستند أثناء mail merge.
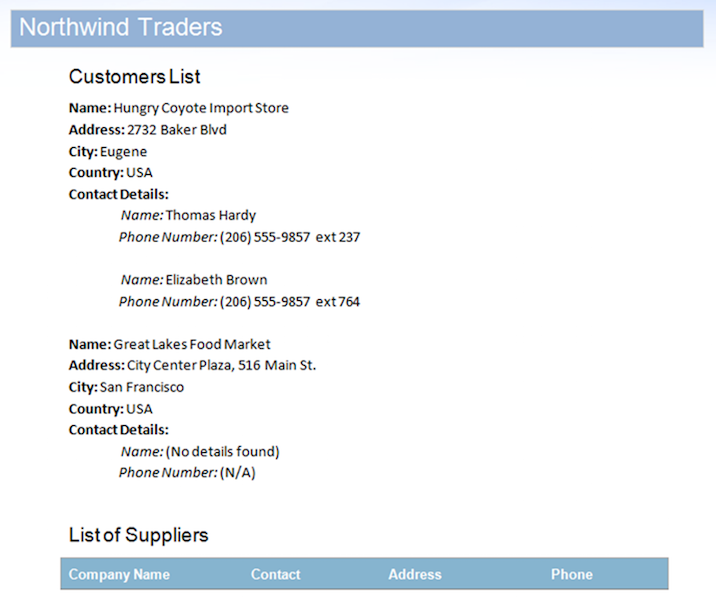
يتضمن مصدر البيانات سجلين لمنطقة StoreDetails ولكن عن قصد يحتوي على أي بيانات لمناطق ContactDetails الفرعية لأحد السجلات. علاوة على ذلك، لا تحتوي المنطقة Suppliers على أي صفوف بيانات أيضا. سيؤدي هذا إلى بقاء المناطق غير المستخدمة في المستند. النتيجة بعد دمج المستند مع مصدر البيانات هذا أدناه.

كما هو مذكور في الصورة، يمكنك أن ترى أن منطقة ContactDetails للسجل الثاني و Suppliers تمت إزالتها تلقائيا بواسطة محرك Mail Merge حيث لا تحتوي على بيانات. ومع ذلك، هناك بعض المشكلات التي تجعل مستند الإخراج هذا يبدو غير مكتمل:
توضح التقنية المتوفرة في هذه المقالة كيفية تطبيق المنطق المخصص على كل منطقة غير مدمجة لتجنب هذه المشكلات.
الحل
لتطبيق المنطق يدويا على كل منطقة غير مستخدمة في المستند، نستفيد من الميزات المتوفرة بالفعل في Aspose.Words.
يوفر المحرك Mail Merge خاصية لإزالة المناطق غير المستخدمة من خلال علامة MailMergeCleanupOptions.RemoveUnusedRegions. يمكن تعطيل هذا بحيث يتم ترك هذه المناطق دون مساس خلال mail merge. يتيح لنا ذلك ترك المناطق غير المدمجة في المستند والتعامل معها يدويا بأنفسنا بدلا من ذلك.
يمكننا بعد ذلك الاستفادة من خاصية MailMerge.FieldMergingCallback كوسيلة لتطبيق منطقنا المخصص على هذه المناطق غير المدمجة خلال Mail Merge من خلال استخدام فئة معالج تنفيذ واجهة IFieldMergingCallback.
هذا الرمز داخل فئة المعالج هو الفئة الوحيدة التي ستحتاج إلى تعديلها للتحكم في المنطق المطبق على المناطق غير المدمجة. يمكن إعادة استخدام الكود الآخر في هذه العينة دون تعديل في أي مشروع.
يوضح هذا المشروع عينة هذه التقنية. يتضمن الخطوات التالية:
الرمز
تم العثور على تنفيذ طريقة ExecuteCustomLogicOnEmptyRegions أدناه. تقبل هذه الطريقة عدة معلمات:
مثال
يوضح كيفية تنفيذ المنطق المخصص في المناطق غير المستخدمة باستخدام المعالج المحدد.
مثال
يحدد الطريقة المستخدمة للتعامل مع المناطق غير المدمجة يدويا.
تتضمن هذه الطريقة العثور على جميع المناطق غير المدمجة في المستند. يتم تحقيق ذلك باستخدام طريقة MailMerge.GetFieldNames. تقوم هذه الطريقة بإرجاع كافة حقول الدمج في المستند، بما في ذلك علامات بداية المنطقة ونهايتها (ممثلة بحقول الدمج بالبادئة TableStart أو TableEnd).
عند مواجهة حقل دمج TableStart، تتم إضافة هذا كـ DataTable جديد إلى DataSet. نظرا لأن المنطقة قد تظهر أكثر من مرة (على سبيل المثال لأنها منطقة متداخلة حيث تم دمج المنطقة الأصلية مع سجلات متعددة)، يتم إنشاء الجدول وإضافته فقط إذا لم يكن موجودا بالفعل في DataSet.
عند العثور على بداية منطقة مناسبة وإضافتها إلى قاعدة البيانات، تتم إضافة الحقل التالي (الذي يتوافق مع الحقل الأول في المنطقة) إلى DataTable. يجب إضافة الحقل الأول فقط لكل حقل في المنطقة ليتم دمجه وتمريره إلى المعالج.
قمنا أيضا بتعيين قيمة الحقل للحقل الأول على “FirstField” لتسهيل تطبيق المنطق على الحقول الأولى أو الحقول الأخرى في المنطقة. من خلال تضمين هذا، فهذا يعني أنه ليس من الضروري ترميز اسم الحقل الأول أو تنفيذ رمز إضافي للتحقق مما إذا كان الحقل الحالي هو الأول في رمز المعالج.
يوضح الرمز أدناه كيفية عمل هذا النظام. يتم إعادة دمج المستند الموضح في بداية هذه المقالة بنفس مصدر البيانات ولكن هذه المرة، يتم التعامل مع المناطق غير المستخدمة بواسطة رمز مخصص.
مثال
يوضح كيفية التعامل مع المناطق غير المدمجة بعد Mail Merge برمز محدد من قبل المستخدم.
ينفذ الكود عمليات مختلفة بناء على اسم المنطقة المسترجعة باستخدام FieldMergingArgs.TableName خاصية. لاحظ أنه بناء على المستند والمناطق الخاصة بك، يمكنك ترميز المعالج لتشغيل المنطق الذي يعتمد على كل منطقة أو رمز ينطبق على كل منطقة غير مدمجة في المستند أو مزيج من الاثنين معا.
يتضمن منطق منطقة ContactDetails تغيير نص كل حقل في منطقة ContactDetails برسالة مناسبة تفيد بعدم وجود بيانات. تتم مطابقة أسماء كل حقل داخل المعالج باستخدام خاصية FieldMergingArgs.FieldName.
يتم تطبيق عملية مماثلة على المنطقة Suppliers مع إضافة رمز إضافي للتعامل مع الجدول الذي يحتوي على المنطقة. سيتحقق الرمز مما إذا كانت المنطقة مضمنة في جدول (حيث ربما تمت إزالتها بالفعل). إذا كان الأمر كذلك، فسيؤدي ذلك إلى إزالة الجدول بأكمله من المستند بالإضافة إلى الفقرة التي تسبقه طالما تم تنسيقه بنمط عنوان على سبيل المثال “Heading 1”.
مثال
يوضح كيفية تعريف المنطق المخصص في معالج ينفذ IFieldMergingCallback الذي يتم تنفيذه للمناطق غير المدمجة في المستند.
تظهر نتيجة الكود أعلاه أدناه. يتم استبدال الحقول غير المدمجة داخل المنطقة الأولى بنص إعلامي وتسمح إزالة الجدول والعنوان للمستند بأن يبدو مكتملا.

يمكن أيضا تشغيل الرمز الذي يزيل الجدول الأصل على كل منطقة غير مستخدمة بدلا من منطقة معينة فقط عن طريق إزالة التحقق من اسم الجدول. في هذه الحالة، إذا لم يتم دمج أي منطقة داخل جدول مع أي بيانات، فسيتم إزالة كل من المنطقة وجدول الحاوية تلقائيا أيضا.
يمكننا إدراج رمز مختلف في المعالج للتحكم في كيفية التعامل مع المناطق غير المدمجة. سيؤدي استخدام الكود أدناه في المعالج بدلا من ذلك إلى تغيير النص في الفقرة الأولى من المنطقة إلى رسالة مفيدة أثناء إزالة أي فقرات لاحقة في المنطقة. تتم إزالة هذه الفقرات الأخرى لأنها ستبقى في المنطقة بعد دمج رسالتنا.
يتم دمج النص البديل في الحقل الأول عن طريق تعيين النص المحدد في الخاصية FieldMergingArgs.Text. يتم دمج النص من هذه الخاصية في الحقل بواسطة محرك Mail Merge.
يطبق الرمز هذا على الحقل الأول فقط في المنطقة عن طريق التحقق من FieldMergingArgs.FieldValue خاصية. يتم تمييز قيمة الحقل للحقل الأول في المنطقة بـ" FirstField". هذا يجعل هذا النوع من المنطق أسهل في التنفيذ على العديد من المناطق حيث لا يلزم وجود رمز إضافي.
مثال
يوضح كيفية استبدال منطقة غير مستخدمة برسالة وإزالة فقرات إضافية.
يظهر المستند الناتج بعد تنفيذ الكود أعلاه أدناه. يتم استبدال المنطقة غير المستخدمة برسالة تفيد بعدم وجود سجلات لعرضها.

كمثال آخر، يمكننا إدراج الرمز أدناه بدلا من الرمز الذي يتعامل في الأصل مع SuppliersRegion. سيؤدي هذا إلى عرض رسالة داخل الجدول ودمج الخلايا بدلا من إزالة الجدول من المستند. نظرا لأن المنطقة موجودة داخل جدول به خلايا متعددة، يبدو من الأجمل دمج خلايا الجدول معا وتركيز الرسالة.
مثال
يوضح كيفية دمج جميع الخلايا الأصلية لمنطقة غير مستخدمة وعرض رسالة داخل الجدول.
يظهر المستند الناتج بعد تنفيذ الكود أعلاه أدناه.

أخيرا، يمكننا استدعاء طريقة ExecuteCustomLogicOnEmptyRegions وتحديد أسماء الجداول التي يجب معالجتها ضمن طريقة المعالج الخاصة بنا، مع تحديد الآخرين المراد إزالتهم تلقائيا.
مثال
يوضح كيفية تحديد المنطقة ContactDetails فقط التي سيتم التعامل معها من خلال فئة المعالج.
سيؤدي استدعاء هذا التحميل الزائد باستخدام ArrayList المحدد إلى إنشاء مصدر البيانات الذي يحتوي فقط على صفوف البيانات للمناطق المحددة. لن يتم التعامل مع مناطق أخرى غير منطقة ContactDetails وستتم إزالتها تلقائيا بواسطة محرك Mail Merge بدلا من ذلك. تظهر نتيجة المكالمة أعلاه باستخدام الرمز في معالجنا الأصلي أدناه.
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.