Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
Dans certaines situations, il n’est pas souhaitable de supprimer complètement les régions non fusionnées du document pendant Mail Merge ou le document semble incomplet. Cela peut se produire lorsque l’absence de données d’entrée doit être affichée à l’utilisateur sous la forme d’un message au lieu que la région soit complètement supprimée.
Il y a aussi des moments où la suppression de la région inutilisée seule ne suffit pas, par exemple, si la région est précédée d’un titre ou si la région est contenue dans une table. Si cette région n’est pas utilisée, le titre et le tableau resteront toujours après la suppression de la région, ce qui semblera déplacé dans le document.
Cet article fournit une solution pour définir manuellement comment les régions inutilisées du document sont gérées. Le code de base de cette fonctionnalité est fourni et peut être facilement réutilisé dans un autre projet.
La logique à appliquer à chaque région est définie à l’intérieur d’une classe qui implémente l’interface IFieldMergingCallback. De la même manière, un gestionnaire Mail Merge peut être configuré pour contrôler la façon dont chaque champ est fusionné, ce gestionnaire peut être configuré pour effectuer des actions sur chaque champ dans une région inutilisée ou sur la région dans son ensemble. Dans ce gestionnaire, vous pouvez définir le code pour modifier le texte d’une région, supprimer des nœuds ou des lignes et cellules vides, etc.
Dans cet exemple, nous utiliserons le document affiché ci-dessous. Il contient des régions imbriquées et une région contenue dans une table.
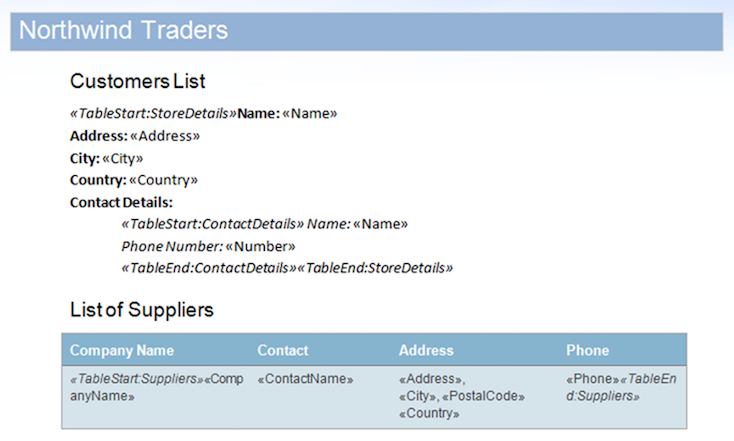
À titre de démonstration rapide, nous pouvons exécuter un exemple de base de données sur l’exemple de document avec l’indicateur MailMergeCleanupOptions.REMOVE_UNUSED_REGIONS activé. Cette propriété supprimera automatiquement les régions non fusionnées du document pendant un mail merge.
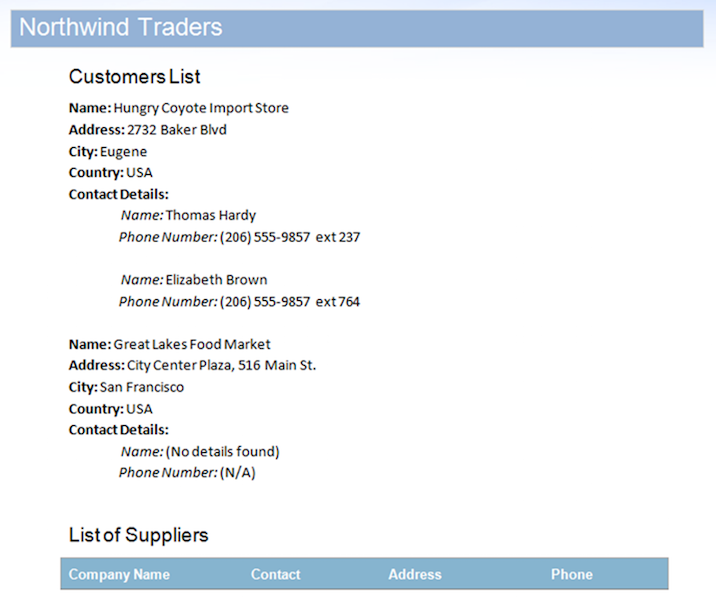
La source de données inclut deux enregistrements pour la région StoreDetails, mais contient délibérément des données pour les régions ContactDetails enfants pour l’un des enregistrements. De plus, la région Suppliers n’a pas non plus de lignes de données. Cela entraînera le maintien des régions inutilisées dans le document. Le résultat après la fusion du document avec cette source de données est ci-dessous.

Comme indiqué sur l’image, vous pouvez voir que la région ContactDetails pour le deuxième enregistrement et les régions Suppliers ont été automatiquement supprimées par le moteur Mail Merge car elles ne contiennent aucune donnée. Cependant, il y a quelques problèmes qui rendent ce document de sortie incomplet:
La technique fournie dans cet article montre comment appliquer une logique personnalisée à chaque région non fusionnée pour éviter ces problèmes.
La Solution
Pour appliquer manuellement la logique à chaque région inutilisée du document, nous tirons parti des fonctionnalités déjà disponibles dans Aspose.Words.
Le moteur Mail Merge fournit une propriété pour supprimer les régions inutilisées via l’indicateur MailMergeCleanupOptions.RemoveUnusedRegions. Cela peut être désactivé afin que ces régions ne soient pas touchées pendant a mail merge. Cela nous permet de laisser les régions non fusionnées dans le document et de les gérer nous-mêmes manuellement à la place.
Nous pouvons ensuite tirer parti de la propriété MailMerge.FieldMergingCallback comme moyen d’appliquer notre propre logique personnalisée à ces régions non fusionnées pendant Mail Merge grâce à l’utilisation d’une classe de gestionnaire implémentant l’interface IFieldMergingCallback.
Ce code dans la classe handler est la seule classe que vous devrez modifier pour contrôler la logique appliquée aux régions non fusionnées. L’autre code de cet exemple peut être réutilisé sans modification dans n’importe quel projet.
Cet exemple de projet démontre cette technique. Cela implique les étapes suivantes:
Le Code
L’implémentation de la méthode ExecuteCustomLogicOnEmptyRegions se trouve ci-dessous. Cette méthode accepte plusieurs paramètres:
Exemple
Montre comment exécuter une logique personnalisée sur des régions inutilisées à l’aide du gestionnaire spécifié.
Exemple
Définit la méthode utilisée pour gérer manuellement les régions non fusionnées.
Cette méthode implique de trouver toutes les régions non fusionnées dans le document. Ceci est accompli en utilisant la méthode MailMerge.GetFieldNames. Cette méthode renvoie tous les champs de fusion du document, y compris les marqueurs de début et de fin de région (représentés par des champs de fusion avec le préfixe TableStart ou TableEnd).
Lorsqu’un champ de fusion TableStart est rencontré, il est ajouté en tant que nouveau DataTable au DataSet. Puisqu’une région peut apparaître plus d’une fois (par exemple parce qu’il s’agit d’une région imbriquée où la région parente a été fusionnée avec plusieurs enregistrements), la table n’est créée et ajoutée que si elle n’existe pas déjà dans DataSet.
Lorsqu’un début de région approprié a été trouvé et ajouté à la base de données, le champ suivant (qui correspond au premier champ de la région) est ajouté au DataTable. Seul le premier champ doit être ajouté pour chaque champ de la région à fusionner et à transmettre au gestionnaire.
Nous définissons également la valeur de champ du premier champ sur “FirstField " pour faciliter l’application de la logique au premier ou aux autres champs de la région. En incluant cela, cela signifie qu’il n’est pas nécessaire de coder en dur le nom du premier champ ou d’implémenter du code supplémentaire pour vérifier si le champ actuel est le premier dans le code du gestionnaire.
Le code ci-dessous montre comment fonctionne ce système. Le document présenté au début de cet article est fusionné avec la même source de données, mais cette fois, les régions inutilisées sont gérées par du code personnalisé.
Exemple
Montre comment gérer les régions non fusionnées après Mail Merge avec du code défini par l’utilisateur.
Le code effectue différentes opérations en fonction du nom de la région récupérée à l’aide de la propriété FieldMergingArgs.TableName. Notez qu’en fonction de votre document et de vos régions, vous pouvez coder le gestionnaire pour exécuter une logique dépendante de chaque région ou code qui s’applique à chaque région non fusionnée du document ou une combinaison des deux.
La logique de la région ContactDetails implique de modifier le texte de chaque champ de la région ContactDetails avec un message approprié indiquant qu’il n’y a pas de données. Les noms de chaque champ sont mis en correspondance dans le gestionnaire à l’aide de la propriété FieldMergingArgs.FieldName.
Un processus similaire est appliqué à la région Suppliers avec l’ajout de code supplémentaire pour gérer la table qui contient la région. Le code vérifiera si la région est contenue dans une table (car elle a peut-être déjà été supprimée). Si c’est le cas, il supprimera l’intégralité du tableau du document ainsi que le paragraphe qui le précède tant qu’il est formaté avec un style de titre par exemple “Heading 1”.
Exemple
Montre comment définir une logique personnalisée dans un gestionnaire implémentant IFieldMergingCallback qui est exécuté pour les régions non fusionnées dans le document.
Le résultat du code ci-dessus est illustré ci-dessous. Les champs non fusionnés dans la première région sont remplacés par du texte informatif et la suppression du tableau et de l’en-tête permet au document d’avoir l’air complet.

Le code qui supprime la table parente pourrait également être exécuté sur chaque région inutilisée au lieu d’une région spécifique en supprimant la vérification du nom de la table. Dans ce cas, si une région à l’intérieur d’une table n’a été fusionnée avec aucune donnée, la région et la table conteneur seront également automatiquement supprimées.
Nous pouvons insérer un code différent dans le gestionnaire pour contrôler la gestion des régions non fusionnées. L’utilisation du code ci-dessous dans le gestionnaire à la place changera le texte du premier paragraphe de la région en un message utile tandis que tous les paragraphes suivants de la région sont supprimés. Ces autres paragraphes sont supprimés car ils resteraient dans la région après la fusion de notre message.
Le texte de remplacement est fusionné dans le premier champ en définissant le texte spécifié dans la propriété FieldMergingArgs.Text. Le texte de cette propriété est fusionné dans le champ par le moteur Mail Merge.
Le code applique cela uniquement au premier champ de la région en vérifiant la propriété FieldMergingArgs.FieldValue. La valeur du champ du premier champ de la région est marquée par " FirstField”. Cela rend ce type de logique plus facile à implémenter dans de nombreuses régions car aucun code supplémentaire n’est requis.
Exemple
Montre comment remplacer une région inutilisée par un message et supprimer des paragraphes supplémentaires.
Le document résultant après l’exécution du code ci-dessus est illustré ci-dessous. La région inutilisée est remplacée par un message indiquant qu’il n’y a aucun enregistrement à afficher.

Comme autre exemple, nous pouvons insérer le code ci-dessous à la place du code gérant à l’origine le SuppliersRegion. Cela affichera un message dans le tableau et fusionnera les cellules au lieu de supprimer le tableau du document. Étant donné que la région réside dans un tableau avec plusieurs cellules, il est plus agréable de fusionner les cellules du tableau et de centrer le message.
Exemple
Montre comment fusionner toutes les cellules parentes d’une région inutilisée et afficher un message dans le tableau.
Le document résultant après l’exécution du code ci-dessus est illustré ci-dessous.

Enfin, nous pouvons appeler la méthode ExecuteCustomLogicOnEmptyRegions et spécifier les noms de tables qui doivent être traités dans notre méthode de gestionnaire, tout en spécifiant les autres à supprimer automatiquement.
Exemple
Montre comment spécifier uniquement la région ContactDetails à gérer via la classe handler.
L’appel de cette surcharge avec le ArrayList spécifié créera la source de données qui ne contient que des lignes de données pour les régions spécifiées. Les régions autres que la région ContactDetails ne seront pas gérées et seront supprimées automatiquement par le moteur Mail Merge à la place. Le résultat de l’appel ci-dessus en utilisant le code de notre gestionnaire d’origine est illustré ci-dessous.
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.