Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
Ci sono alcune situazioni in cui la rimozione completa delle regioni non unite dal documento durante Mail Merge non è desiderata o il documento appare incompleto. Ciò può verificarsi quando l’assenza di dati di input deve essere visualizzata all’utente sotto forma di messaggio anziché la regione completamente rimossa.
Ci sono anche momenti in cui la rimozione della regione inutilizzata da sola non è sufficiente, ad esempio, se la regione è preceduta da un titolo o la regione è contenuta in una tabella. Se questa regione non è utilizzata, il titolo e la tabella rimarranno comunque dopo la rimozione della regione che apparirà fuori posto nel documento.
In questo articolo viene fornita una soluzione per definire manualmente come vengono gestite le aree non utilizzate nel documento. Il codice di base per questa funzionalità viene fornito e può essere facilmente riutilizzato in un altro progetto.
La logica da applicare a ciascuna regione è definita all’interno di una classe che implementa l’interfaccia IFieldMergingCallback. Allo stesso modo, un gestore Mail Merge può essere impostato per controllare come ogni campo viene unito, questo gestore può essere impostato per eseguire azioni su ciascun campo in un’area non utilizzata o sull’intera area. All’interno di questo gestore, è possibile impostare il codice per modificare il testo di un’area, rimuovere nodi o righe e celle vuote, ecc.
In questo esempio, utilizzeremo il documento visualizzato di seguito. Contiene regioni nidificate e un’area contenuta in una tabella.
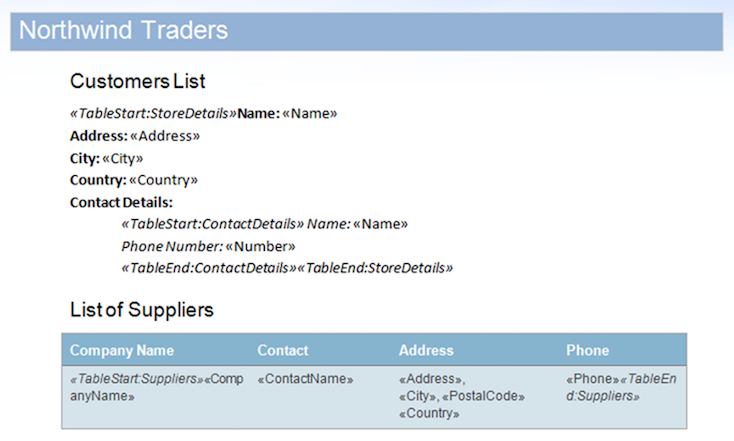
Come dimostrazione rapida, possiamo eseguire un database di esempio sul documento di esempio con il flag MailMergeCleanupOptions.REMOVE_UNUSED_REGIONS abilitato. Questa proprietà rimuoverà automaticamente le regioni non unite dal documento durante un mail merge.
L’origine dati include due record per l’area StoreDetails ma contiene di proposito tutti i dati per le aree figlio ContactDetails per uno dei record. Inoltre, la regione Suppliers non ha nemmeno righe di dati. Ciò farà sì che le aree non utilizzate rimangano nel documento. Il risultato dopo l’unione del documento con questa origine dati è riportato di seguito.

Come indicato nell’immagine, è possibile vedere che la regione ContactDetails per il secondo record e le regioni Suppliers sono state rimosse automaticamente dal motore Mail Merge in quanto non hanno dati. Tuttavia, ci sono alcuni problemi che rendono questo documento di output incompleto:
La tecnica fornita in questo articolo illustra come applicare la logica personalizzata a ciascuna regione non integrata per evitare questi problemi.
Soluzione
Per applicare manualmente la logica a ciascuna regione non utilizzata nel documento, sfruttiamo le funzionalità già disponibili in Aspose.Words.
Il motore Mail Merge fornisce una proprietà per rimuovere le regioni inutilizzate tramite il flag MailMergeCleanupOptions.RemoveUnusedRegions. Questo può essere disabilitato in modo che tali regioni non vengano toccate durante un mail merge. Ciò ci consente di lasciare le regioni non unite nel documento e gestirle manualmente.
Possiamo quindi sfruttare la proprietà MailMerge.FieldMergingCallback come mezzo per applicare la nostra logica personalizzata a queste regioni non unite durante Mail Merge attraverso l’uso di una classe handler che implementa l’interfaccia IFieldMergingCallback.
Questo codice all’interno della classe handler è l’unica classe che dovrai modificare per controllare la logica applicata alle regioni non collegate. L’altro codice in questo esempio può essere riutilizzato senza modifiche in qualsiasi progetto.
Questo progetto di esempio dimostra questa tecnica. Comporta i seguenti passaggi:
Codice
L’implementazione per il metodo ExecuteCustomLogicOnEmptyRegions si trova di seguito. Questo metodo accetta diversi parametri:
Esempio
Mostra come eseguire la logica personalizzata sulle regioni inutilizzate utilizzando il gestore specificato.
Esempio
Definisce il metodo utilizzato per gestire manualmente le regioni non unite.
Questo metodo comporta la ricerca di tutte le regioni non unite nel documento. Questo viene eseguito utilizzando il metodo MailMerge.GetFieldNames. Questo metodo restituisce tutti i campi di unione nel documento, inclusi i marcatori di inizio e fine regione (rappresentati da campi di unione con il prefisso TableStart o TableEnd).
Quando viene rilevato un campo di unione TableStart, questo viene aggiunto come nuovo DataTable al DataSet. Poiché un’area può apparire più di una volta (ad esempio perché è un’area nidificata in cui l’area padre è stata unita a più record), la tabella viene creata e aggiunta solo se non esiste già in DataSet.
Quando è stato trovato e aggiunto al database un inizio regione appropriato, il campo successivo (che corrisponde al primo campo nella regione) viene aggiunto a DataTable. È necessario aggiungere solo il primo campo per ogni campo nell’area da unire e passare al gestore.
Impostiamo anche il valore del campo del primo campo su “FirstField " per semplificare l’applicazione della logica al primo o ad altri campi nell’area. Includendo questo significa che non è necessario codificare il nome del primo campo o implementare codice aggiuntivo per verificare se il campo corrente è il primo nel codice del gestore.
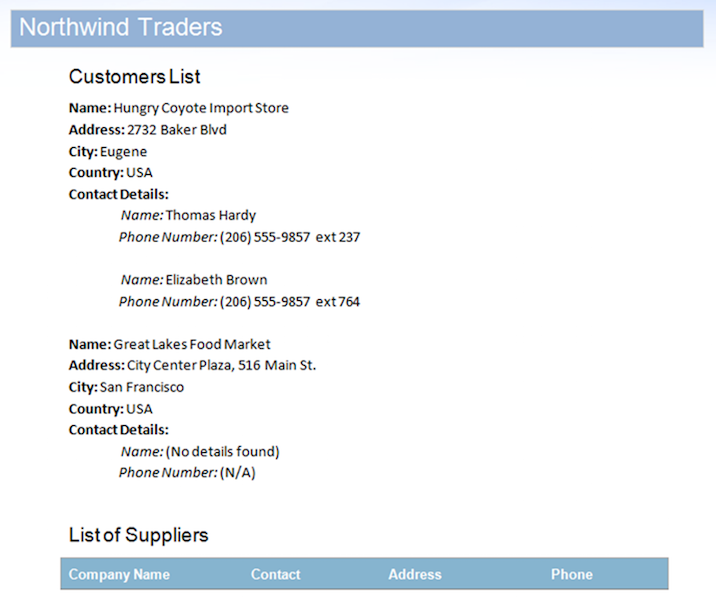
Il codice seguente mostra come funziona questo sistema. Il documento mostrato all’inizio di questo articolo è remerged con la stessa origine dati, ma questa volta, le regioni inutilizzate sono gestite da codice personalizzato.
Esempio
Mostra come gestire le regioni non unite dopo Mail Merge con codice definito dall’utente.
Il codice esegue diverse operazioni in base al nome della regione recuperata utilizzando la proprietà FieldMergingArgs.TableName. Si noti che, a seconda del documento e delle regioni, è possibile codificare il gestore per eseguire la logica dipendente da ciascuna regione o codice che si applica a ogni regione non integrata nel documento o una combinazione di entrambi.
La logica per la regione ContactDetails comporta la modifica del testo di ciascun campo nella regione ContactDetails con un messaggio appropriato che indica che non ci sono dati. I nomi di ciascun campo vengono abbinati all’interno del gestore utilizzando la proprietà FieldMergingArgs.FieldName.
Un processo simile viene applicato alla regione Suppliers con l’aggiunta di codice aggiuntivo per gestire la tabella che contiene la regione. Il codice controllerà se la regione è contenuta all’interno di una tabella (in quanto potrebbe essere già stata rimossa). Se lo è, rimuoverà l’intera tabella dal documento e il paragrafo che lo precede purché sia formattato con uno stile di intestazione, ad esempio “Heading 1”.
Esempio
Mostra come definire la logica personalizzata in un gestore che implementa IFieldMergingCallback eseguito per le regioni non associate nel documento.
Il risultato del codice di cui sopra è mostrato di seguito. I campi non integrati all’interno della prima regione vengono sostituiti con testo informativo e la rimozione della tabella e dell’intestazione consente al documento di apparire completo.

Il codice che rimuove la tabella padre potrebbe anche essere eseguito su ogni regione inutilizzata anziché solo su una regione specifica rimuovendo il controllo per il nome della tabella. In questo caso, se una qualsiasi regione all’interno di una tabella non è stata unita a nessun dato, anche la regione e la tabella contenitore verranno rimosse automaticamente.
Possiamo inserire codice diverso nel gestore per controllare come vengono gestite le regioni non collegate. Utilizzando il codice qui sotto nel gestore invece cambierà il testo nel primo paragrafo della regione di un messaggio utile, mentre eventuali paragrafi successivi nella regione vengono rimossi. Questi altri paragrafi vengono rimossi in quanto rimarrebbero nella regione dopo la fusione del nostro messaggio.
Il testo sostitutivo viene unito al primo campo impostando il testo specificato nella proprietà FieldMergingArgs.Text. Il testo di questa proprietà viene unito al campo dal motore Mail Merge.
Il codice lo applica solo per il primo campo nell’area selezionando la proprietà FieldMergingArgs.FieldValue. Il valore del campo del primo campo nella regione è contrassegnato con " FirstField”. Questo rende questo tipo di logica più facile da implementare su molte regioni in quanto non è richiesto alcun codice aggiuntivo.
Esempio
Mostra come sostituire un’area non utilizzata con un messaggio e rimuovere paragrafi aggiuntivi.
Il documento risultante dopo che il codice sopra è stato eseguito è mostrato di seguito. L’area non utilizzata viene sostituita con un messaggio che indica che non ci sono record da visualizzare.

Come altro esempio, possiamo inserire il codice qui sotto al posto del codice che originariamente gestiva SuppliersRegion. Questo visualizzerà un messaggio all’interno della tabella e unirà le celle invece di rimuovere la tabella dal documento. Poiché la regione risiede all’interno di una tabella con più celle, sembra più bello avere le celle della tabella unite insieme e il messaggio centrato.
Esempio
Mostra come unire tutte le celle padre di un’area inutilizzata e visualizzare un messaggio all’interno della tabella.
Il documento risultante dopo che il codice sopra è stato eseguito è mostrato di seguito.

Infine, possiamo chiamare il metodo ExecuteCustomLogicOnEmptyRegions e specificare i nomi delle tabelle che devono essere gestiti all’interno del nostro metodo di gestione, specificando gli altri da rimuovere automaticamente.
Esempio
Mostra come specificare solo l’area ContactDetails da gestire tramite la classe handler.
Chiamare questo sovraccarico con ArrayList specificato creerà l’origine dati che contiene solo righe di dati per le regioni specificate. Le regioni diverse dall’area ContactDetails non verranno gestite e verranno rimosse automaticamente dal motore Mail Merge. Il risultato della chiamata di cui sopra utilizzando il codice nel nostro gestore originale è mostrato di seguito.
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.