Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
Mail Merge中に文書からマージされていない領域を完全に削除することが望ましくない場合や、文書が不完全に見える場合があります。 これは、領域が完全に削除されるのではなく、入力データがないことをメッセージの形でユーザーに表示する必要がある場合に発生する可能性があります。
また、領域の前にタイトルが付いている場合や、領域がテーブルに含まれている場合など、未使用の領域を単独で削除するだけでは不十分な場合もあ この領域が使用されていない場合、領域が削除された後もタイトルとテーブルは残り、ドキュメント内で場違いに見えます。
この記事では、ドキュメント内の未使用領域の処理方法を手動で定義するための解決策を提供します。 この機能の基本コードが提供されており、別のプロジェクトで簡単に再利用できます。
各領域に適用されるロジックは、IFieldMergingCallbackインターフェイスを実装するクラス内で定義されます。 同様に、Mail Mergeハンドラを設定して各フィールドのマージ方法を制御することができ、このハンドラを設定して、未使用のリージョン内の各フィールドまたはリージョン全体に対してアクションを実行することができます。 このハンドラー内で、領域のテキストを変更したり、ノードを削除したり、空の行やセルなどを削除したりするコードを設定できます。
このサンプルでは、以下に表示されるドキュメントを使用します。 これには、ネストされた領域と、テーブル内に含まれる領域が含まれます。
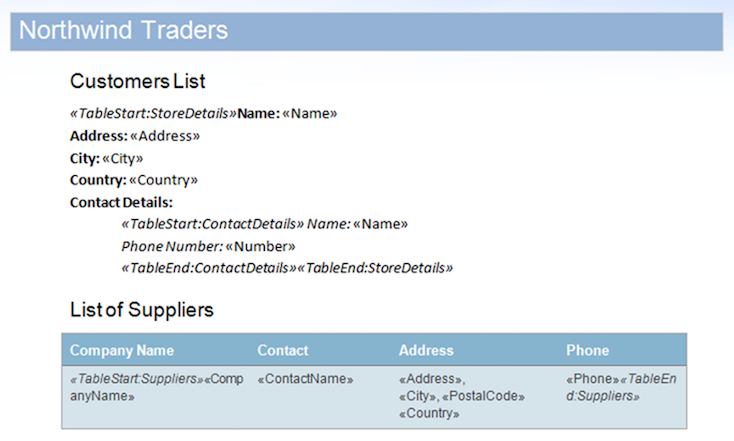
簡単なデモとして、MailMergeCleanupOptions.REMOVE_UNUSED_REGIONSフラグを有効にしてサンプルドキュメント上でサンプルデータベースを実行できます。 このプロパティは、mail merge中に文書からマージされていない領域を自動的に削除します。
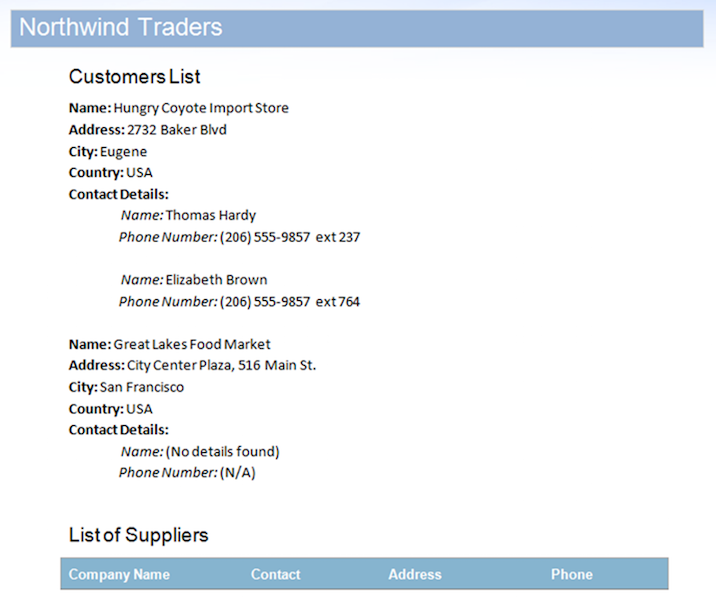
データソースにはStoreDetails領域の2つのレコードが含まれていますが、意図的には、いずれかのレコードの子ContactDetails領域のデータがあります。 さらに、Suppliers領域にはデータ行もありません。 これにより、未使用の領域がドキュメントに残ります。 このデータソースとドキュメントをマージした後の結果は以下のとおりです。

画像に記載されているように、2番目のレコードのContactDetails領域とSuppliers領域はデータがないため、Mail Mergeエンジンによって自動的に削除されていることがわかります。 ただし、この出力ドキュメントが不完全に見えるいくつかの問題があります:
この記事で提供される手法は、これらの問題を回避するために、マージされていない各リージョンにカスタムロジックを適用する方法を示しています。
解決策
ドキュメント内の未使用の各リージョンに手動でロジックを適用するには、Aspose.Wordsで既に利用可能な機能を利用します。
Mail Mergeエンジンは、MailMergeCleanupOptions.RemoveUnusedRegionsフラグを使用して未使用領域を削除するプロパティを提供します。 これは、mail merge中にそのような領域がそのまま残されるように無効にすることができます。 これにより、マージされていない領域をドキュメントに残して、代わりに手動で処理することができます。
次に、IFieldMergingCallback インターフェースを実装するハンドラー クラスを使用して、Mail Merge 中にこれらのマージされていない領域に独自のカスタム ロジックを適用する手段として、MailMerge.FieldMergingCallback プロパティを利用できます。
Handlerクラス内のこのコードは、マージされていない領域に適用されるロジックを制御するために変更する必要がある唯一のクラスです。 このサンプルの他のコードは、どのプロジェクトでも変更せずに再利用できます。
このサンプルプロジェクトは、この手法を示しています。 これには、次の手順が含まれます。:
コード
ExecuteCustomLogicOnEmptyRegionsメソッドの実装は以下の通りです。 このメソッドは、いくつかのパラメータを受け入れます:
例を示します。
指定されたハンドラーを使用して、未使用領域でカスタムロジックを実行する方法を示します。
例を示します。
マージされていない領域を手動で処理するために使用されるメソッドを定義します。
この方法では、文書内のすべてのマージされていない領域を検索します。 これはMailMerge.GetFieldNamesメソッドを使用して実行されます。 このメソッドは、リージョンの開始マーカーと終了マーカー(接頭辞TableStartまたはTableEndの差し込み項目で表されます)を含む、ドキュメント内のすべての差し込み項目を返します。
TableStart差し込み項目が検出されると、これは新しいDataTableとしてDataSetに追加されます。 リージョンは複数回表示される可能性があるため(たとえば、親リージョンが複数のレコードとマージされたネストされたリージョンであるため)、テーブルはDataSetにまだ存在しない場合にのみ作成および追加されます。
適切なリージョンの開始が見つかってデータベースに追加されると、次のフィールド(リージョン内の最初のフィールドに対応)がDataTableに追加されます。 マージされてハンドラーに渡されるリージョン内の各フィールドには、最初のフィールドのみを追加する必要があります。
また、リージョン内の最初のフィールドまたは他のフィールドにロジックを適用しやすくするために、最初のフィールドのフィールド値を"FirstField"に設定します。 これを含めることで、最初のフィールドの名前をハードコードする必要がないことを意味したり、現在のフィールドがハンドラーコードの最初であるかどうかを確認するための追加のコードを実装したりします。
以下のコードは、このシステムがどのように機能するかを示しています。 この記事の冒頭に示されているドキュメントは、同じデータソースで再マージされますが、今回は、未使用の領域はカスタムコードによって処理されます。
例を示します。
Mail Mergeの後のマージされていない領域をユーザー定義コードで処理する方法を示します。
このコードは、FieldMergingArgs.TableNameプロパティを使用して取得された領域の名前に基づいて異なる操作を実行します。 ドキュメントとリージョンに応じて、ドキュメント内のマージされていないすべてのリージョンまたは両方の組み合わせに適用される各リージョンまたはコードに依存してロジックを実行するようにハンドラーをコーディングできます。
ContactDetails領域のロジックには、ContactDetails領域の各フィールドのテキストを、データがないことを示す適切なメッセージで変更することが含まれます。 各フィールドの名前は、FieldMergingArgs.FieldNameプロパティを使用してハンドラー内で照合されます。
同様のプロセスがSuppliers領域に適用され、領域を含むテーブルを処理するための余分なコードが追加されます。 コードは、領域がテーブル内に含まれているかどうかをチェックします(すでに削除されている可能性があるため)。 そうであれば、“Heading 1"などの見出しスタイルで書式設定されている限り、文書からテーブル全体とその前の段落が削除されます。
例を示します。
ドキュメント内のマージされていない領域に対して実行されるIFieldMergingCallbackを実装するハンドラーでカスタムロジックを定義する方法を示します。
上記のコードの結果を以下に示します。 最初の領域内のマージされていないフィールドは有益なテキストに置き換えられ、テーブルと見出しを削除すると文書が完全に見えるようになります。

親テーブルを削除するコードは、テーブル名のチェックを削除することで、特定の領域ではなく、すべての未使用領域で実行するようにすることもできま この場合、テーブル内のいずれかの領域がデータとマージされていない場合、領域とコンテナテーブルの両方も自動的に削除されます。
ハンドラーに別のコードを挿入して、マージされていない領域の処理方法を制御できます。 代わりにハンドラーで以下のコードを使用すると、リージョンの最初の段落のテキストが有用なメッセージに変更され、リージョンの後続の段落は削除されま これらの他の段落は、メッセージをマージした後も地域に残るため、削除されます。
置換テキストは、指定されたテキストをFieldMergingArgs.Textプロパティに設定することにより、最初のフィールドにマージされます。 このプロパティのテキストはMail Mergeエンジンによってフィールドにマージされます。
このコードでは、FieldMergingArgs.FieldValueプロパティをチェックすることにより、地域の最初のフィールドにのみこれが適用されます。 リージョンの最初のフィールドのフィールド値は"FirstField"でマークされています。 これにより、余分なコードを必要としないため、このタイプのロジックを多くのリージョンで実装しやすくなります。
例を示します。
未使用の領域をメッセージに置き換え、余分な段落を削除する方法を示します。
上記のコードが実行された後の結果のドキュメントを以下に示します。 未使用領域は、表示するレコードがないことを示すメッセージに置き換えられます。

別の例として、最初にSuppliersRegionを処理していたコードの代わりに、以下のコードを挿入できます。 これにより、テーブル内にメッセージが表示され、ドキュメントからテーブルを削除する代わりにセルがマージされます。 領域は複数のセルを持つテーブル内にあるため、テーブルのセルをマージしてメッセージを中央に配置する方が見栄えが良くなります。
例を示します。
未使用領域のすべての親セルをマージし、テーブル内にメッセージを表示する方法を示します。
上記のコードが実行された後の結果のドキュメントを以下に示します。

最後に、ExecuteCustomLogicOnEmptyRegionsメソッドを呼び出し、handlerメソッド内で処理するテーブル名を指定し、他のテーブルを自動的に削除するように指定することができます。
例を示します。
Handlerクラスを介して処理されるContactDetails領域のみを指定する方法を示します。
指定されたArrayListを使用してこのオーバーロードを呼び出すと、指定された領域のデータ行のみを含むデータソースが作成されます。 ContactDetails領域以外の領域は処理されず、代わりにMail Mergeエンジンによって自動的に削除されます。 元のハンドラーのコードを使用した上記の呼び出しの結果を以下に示します。
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.