Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
В некоторых ситуациях полное удаление несоединенных областей из документа во время Mail Merge нежелательно или приводит к тому, что документ выглядит неполным. Это может произойти, когда пользователю вместо полного удаления области следует отобразить отсутствие входных данных в виде сообщения.
Бывают также случаи, когда одного удаления неиспользуемого региона недостаточно, например, если перед регионом стоит заголовок или регион содержится в таблице. Если эта область не используется, то заголовок и таблица все равно останутся после удаления области, что будет выглядеть неуместно в документе.
В этой статье предлагается решение, позволяющее вручную определить, как обрабатываются неиспользуемые области в документе. Базовый код для этой функции предоставляется и может быть легко использован повторно в другом проекте.
Логика, применяемая к каждой области, определяется внутри класса, реализующего интерфейс IFieldMergingCallback. Точно так же можно настроить обработчик Mail Merge для управления объединением каждого поля, этот обработчик можно настроить для выполнения действий с каждым полем в неиспользуемой области или с регионом в целом. В этом обработчике вы можете задать код для изменения текста области, удаления узлов или пустых строк и ячеек и т.д.
В этом примере мы будем использовать документ, показанный ниже. Он содержит вложенные области и область, содержащуюся в таблице.
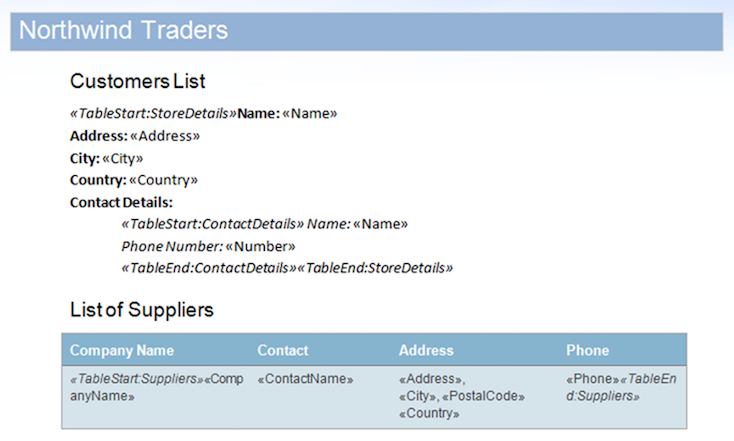
В качестве краткой демонстрации мы можем запустить образец базы данных в образце документа с включенным флагом MailMergeCleanupOptions.REMOVE_UNUSED_REGIONS. Это свойство автоматически удалит несоединенные области из документа в течение mail merge.
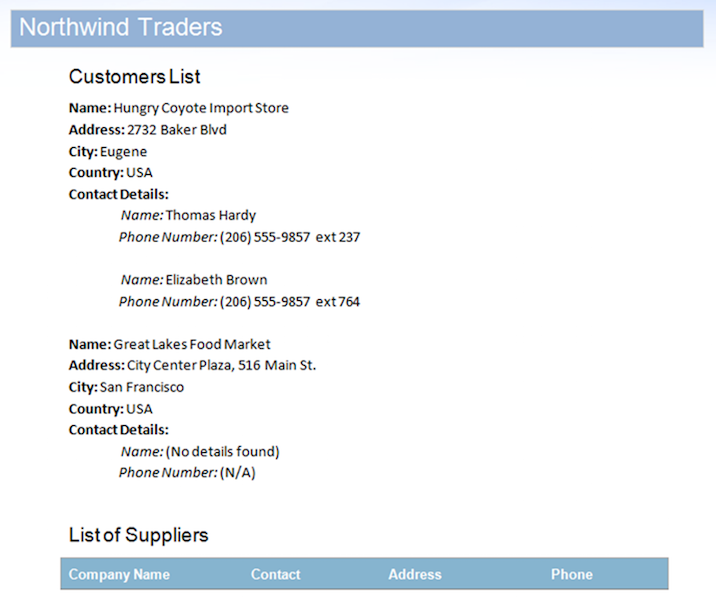
Источник данных содержит две записи для области StoreDetails, но намеренно содержит какие-либо данные для дочерних областей ContactDetails для одной из записей. Кроме того, в области Suppliers также нет строк данных. Это приведет к тому, что в документе останутся неиспользуемые области. Результат после объединения документа с этим источником данных приведен ниже.

Как показано на рисунке, вы можете видеть, что область ContactDetails для второй записи и области Suppliers были автоматически удалены обработчиком Mail Merge, поскольку в них нет данных. Однако есть несколько проблем, из-за которых этот выходной документ выглядит неполным:
Методика, представленная в этой статье, демонстрирует, как применить пользовательскую логику к каждой несоединенной области, чтобы избежать этих проблем.
Решение
Чтобы вручную применить логику к каждой неиспользуемой области документа, мы используем возможности, уже доступные в Aspose.Words.
Механизм Mail Merge предоставляет свойство удалять неиспользуемые области с помощью флага MailMergeCleanupOptions.RemoveUnusedRegions. Это можно отключить, чтобы такие области оставались нетронутыми в течение mail merge. Это позволяет нам оставлять не объединенные области в документе и обрабатывать их вручную самостоятельно.
Затем мы можем воспользоваться свойством MailMerge.FieldMergingCallback как средством применения нашей собственной пользовательской логики к этим несоединенным областям во время Mail Merge с помощью класса-обработчика, реализующего интерфейс IFieldMergingCallback.
Этот код в классе handler - единственный класс, который вам нужно будет изменить, чтобы управлять логикой, применяемой к несоединенным областям. Другой код в этом примере можно повторно использовать без изменений в любом проекте.
Этот примерный проект демонстрирует эту технику. Он включает в себя следующие шаги:
Код
Ниже приведена реализация метода ExecuteCustomLogicOnEmptyRegions. Этот метод принимает несколько параметров:
Пример
Показывает, как выполнить пользовательскую логику в неиспользуемых областях с помощью указанного обработчика.
Пример
Определяет метод, используемый для ручной обработки несоединенных областей.
Этот метод предполагает поиск всех несоединенных областей в документе. Для этого используется метод MailMerge.GetFieldNames. Этот метод возвращает все объединяемые поля в документе, включая маркеры начала и конца области (представленные объединяемыми полями с префиксом TableStart или TableEnd).
При обнаружении поля слияния TableStart оно добавляется как новое DataTable к DataSet. Поскольку область может отображаться более одного раза (например, потому что это вложенная область, в которой родительская область была объединена с несколькими записями), таблица создается и добавляется только в том случае, если она еще не существует в DataSet.
Когда подходящее начало региона найдено и добавлено в базу данных, к DataTable добавляется следующее поле (соответствующее первому полю в регионе). Для каждого поля в регионе, которое должно быть объединено и передано обработчику, требуется добавить только первое поле.
Мы также установили значение первого поля равным “FirstField”, чтобы упростить применение логики к первому или другим полям в регионе. Включение этого параметра означает, что нет необходимости жестко кодировать имя первого поля или реализовывать дополнительный код для проверки того, является ли текущее поле первым в коде обработчика.
Приведенный ниже код демонстрирует, как работает эта система. Документ, показанный в начале этой статьи, повторно объединен с тем же источником данных, но на этот раз неиспользуемые области обрабатываются пользовательским кодом.
Пример
Показывает, как обрабатывать несоединенные области после Mail Merge с помощью пользовательского кода.
Код выполняет различные операции на основе названия региона, полученного с помощью свойства FieldMergingArgs.TableName. Обратите внимание, что в зависимости от вашего документа и регионов вы можете запрограммировать обработчик для запуска логики, зависящей от каждого региона, или кода, который применяется к каждому отдельному региону в документе, или их комбинации.
Логика для области ContactDetails заключается в изменении текста каждого поля в области ContactDetails с соответствующим сообщением об отсутствии данных. Имена каждого поля сопоставляются в обработчике с помощью свойства FieldMergingArgs.FieldName.
Аналогичный процесс применяется к области Suppliers с добавлением дополнительного кода для обработки таблицы, содержащей эту область. Код проверит, содержится ли область в таблице (поскольку она, возможно, уже была удалена). Если это так, то из документа будет удалена вся таблица целиком, а также предшествующий ей абзац, если он отформатирован в стиле заголовка, например “Heading 1”.
Пример
Показывает, как определить пользовательскую логику в обработчике, реализующем IFieldMergingCallback, который выполняется для несвязанных областей в документе.
Результат выполнения приведенного выше кода показан ниже. Не объединенные поля в первой области заменены информативным текстом, а удаление таблицы и заголовка позволяет документу выглядеть завершенным.

Код, который удаляет родительскую таблицу, также можно было бы заставить выполняться в каждом неиспользуемом регионе, а не только в определенном регионе, удалив проверку имени таблицы. В этом случае, если какой-либо регион внутри таблицы не был объединен с какими-либо данными, как регион, так и таблица-контейнер также будут автоматически удалены.
Мы можем вставить другой код в обработчик, чтобы управлять обработкой разделенных областей. Использование приведенного ниже кода в обработчике вместо этого изменит текст в первом абзаце области на полезное сообщение, в то время как все последующие абзацы в области будут удалены. Эти другие абзацы удалены, поскольку они останутся в регионе после объединения нашего сообщения.
Заменяющий текст вводится в первое поле путем установки указанного текста в свойстве FieldMergingArgs.Text. Текст из этого свойства вводится в поле с помощью механизма Mail Merge.
Код применяет это только к первому полю в регионе, проверяя свойство FieldMergingArgs.FieldValue. Значение первого поля в регионе помечается как “FirstField”. Это упрощает реализацию этого типа логики во многих регионах, поскольку не требуется никакого дополнительного кода.
Пример
Показывает, как заменить неиспользуемую область сообщением и удалить лишние абзацы.
Полученный документ после выполнения приведенного выше кода показан ниже. Неиспользуемая область заменяется сообщением о том, что в ней нет записей для отображения.

В качестве другого примера, мы можем вставить приведенный ниже код вместо кода, который изначально обрабатывал SuppliersRegion. Это приведет к отображению сообщения внутри таблицы и объединению ячеек вместо удаления таблицы из документа. Поскольку область находится в таблице с несколькими ячейками, лучше объединить ячейки таблицы вместе и расположить сообщение по центру.
Пример
Показывает, как объединить все родительские ячейки неиспользуемой области и отобразить сообщение в таблице.
Результирующий документ после выполнения приведенного выше кода показан ниже.

Наконец, мы можем вызвать метод ExecuteCustomLogicOnEmptyRegions и указать имена таблиц, которые должны обрабатываться в нашем методе-обработчике, указав при этом другие, которые будут автоматически удалены.
Пример
Показывает, как указать только область ContactDetails, которая будет обрабатываться с помощью класса handler.
При вызове этой перегрузки с указанным значением ArrayList будет создан источник данных, содержащий только строки данных для указанных областей. Области, отличные от области ContactDetails, обрабатываться не будут и вместо этого будут автоматически удалены механизмом Mail Merge. Результат приведенного выше вызова с использованием кода из нашего исходного обработчика показан ниже.
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.