Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
Aspose.Words文档对象模型(DOM)是Word文档的内存表示形式。 Aspose.WordsDOM允许您以编程方式读取、操作和修改Word文档的内容和格式。
本节介绍Aspose.WordsDOM的主要类及其关系。 通过使用Aspose.WordsDOM类,您可以获得对文档元素和格式的编程访问。
当一个文档被读入Aspose.WordsDOM时,就会构建一个对象树,源文档的不同类型的元素都有自己的DOM树对象和各种属性。
当Aspose.Words将Word文档读入内存时,它会创建表示各种文档元素的不同类型的对象。 文本、段落、表或节的每次运行都是一个节点,甚至文档本身也是一个节点。 Aspose.Words为每个文档节点类型定义一个类。
Aspose.Words中的文档树遵循复合设计模式:
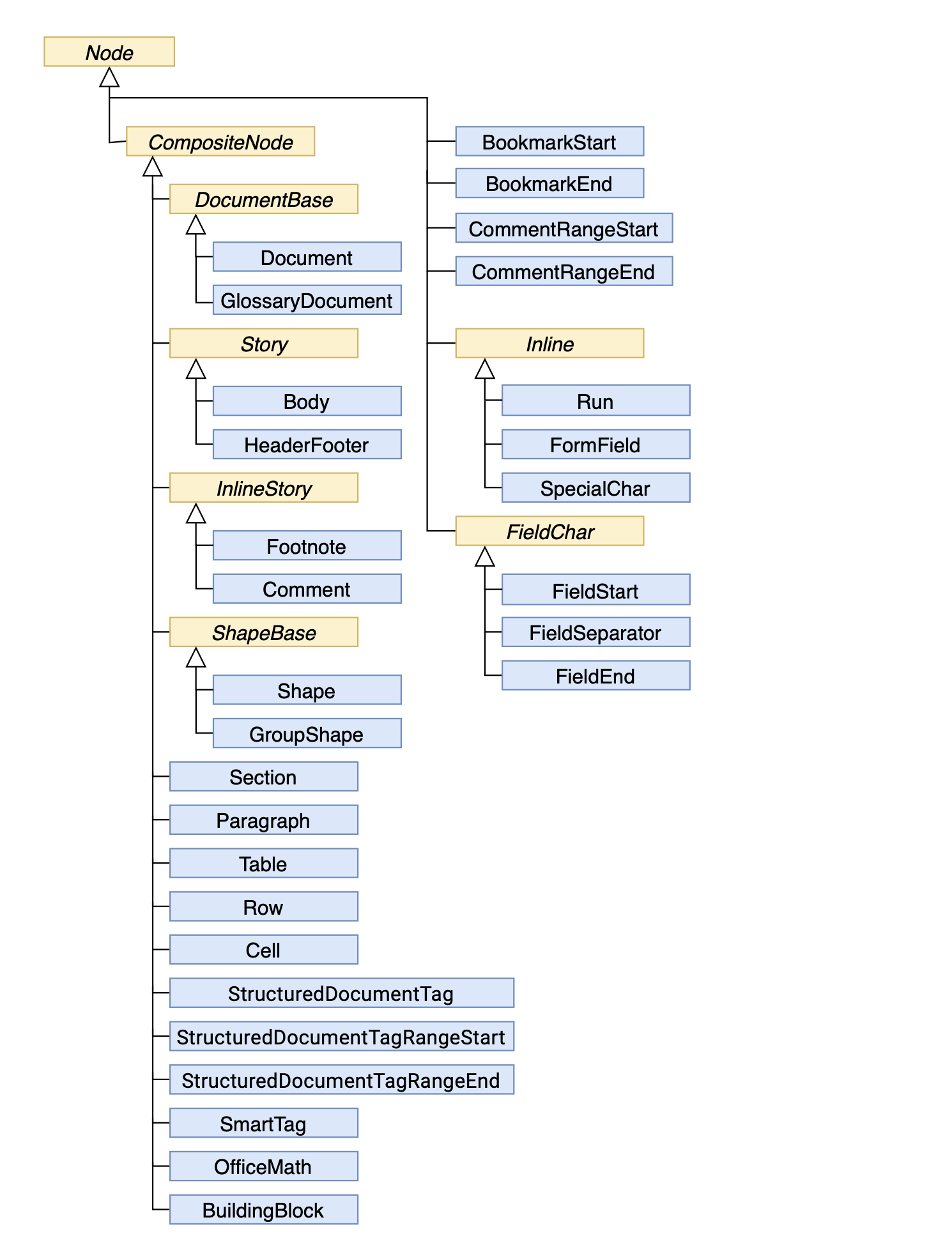
下图显示了Aspose.Words文档对象模型(DOM)的节点类之间的继承。 抽象类的名称用斜体表示。
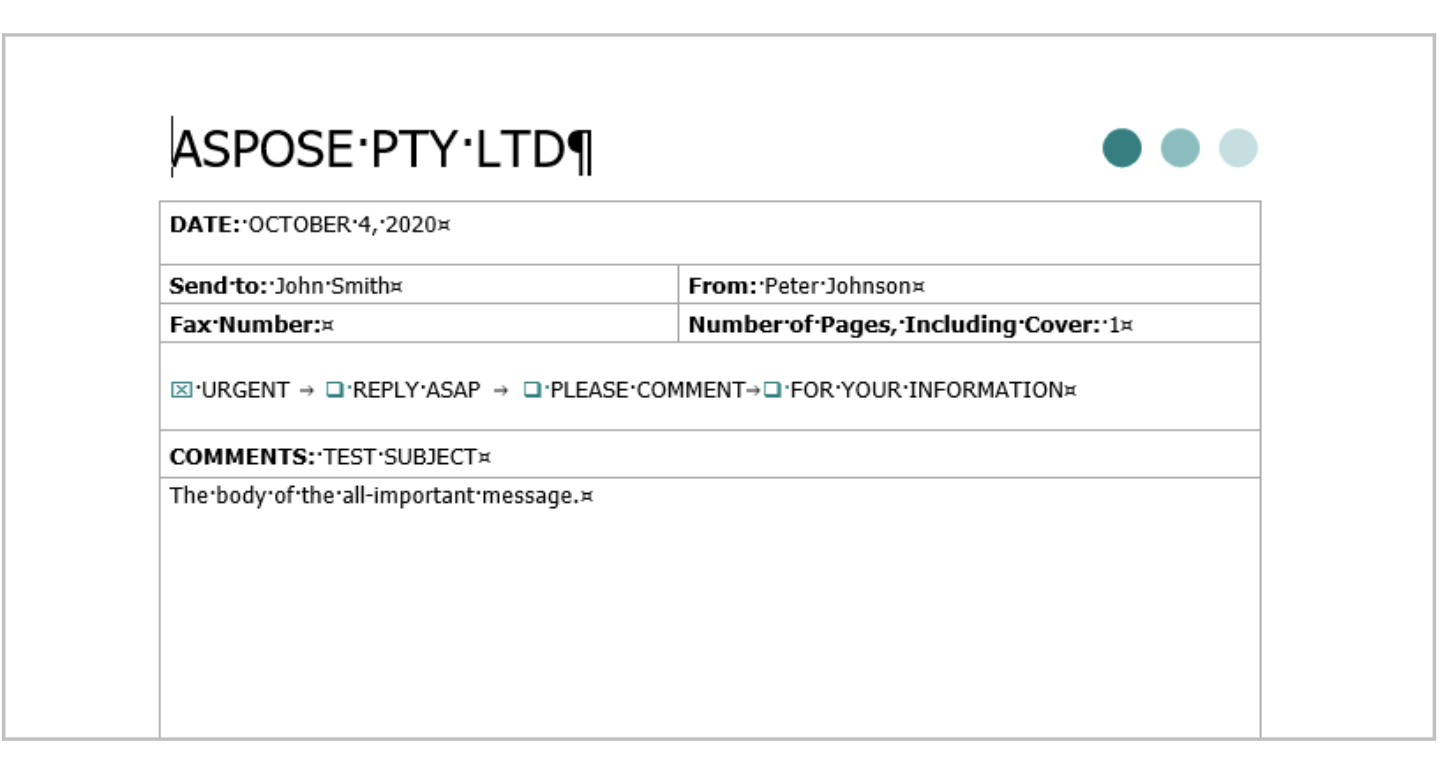
让我们来看一个例子。 下图显示了具有不同类型内容的Microsoft Word文档。
将上述文档读入Aspose.WordsDOM时,将创建对象树,如下面的模式所示。
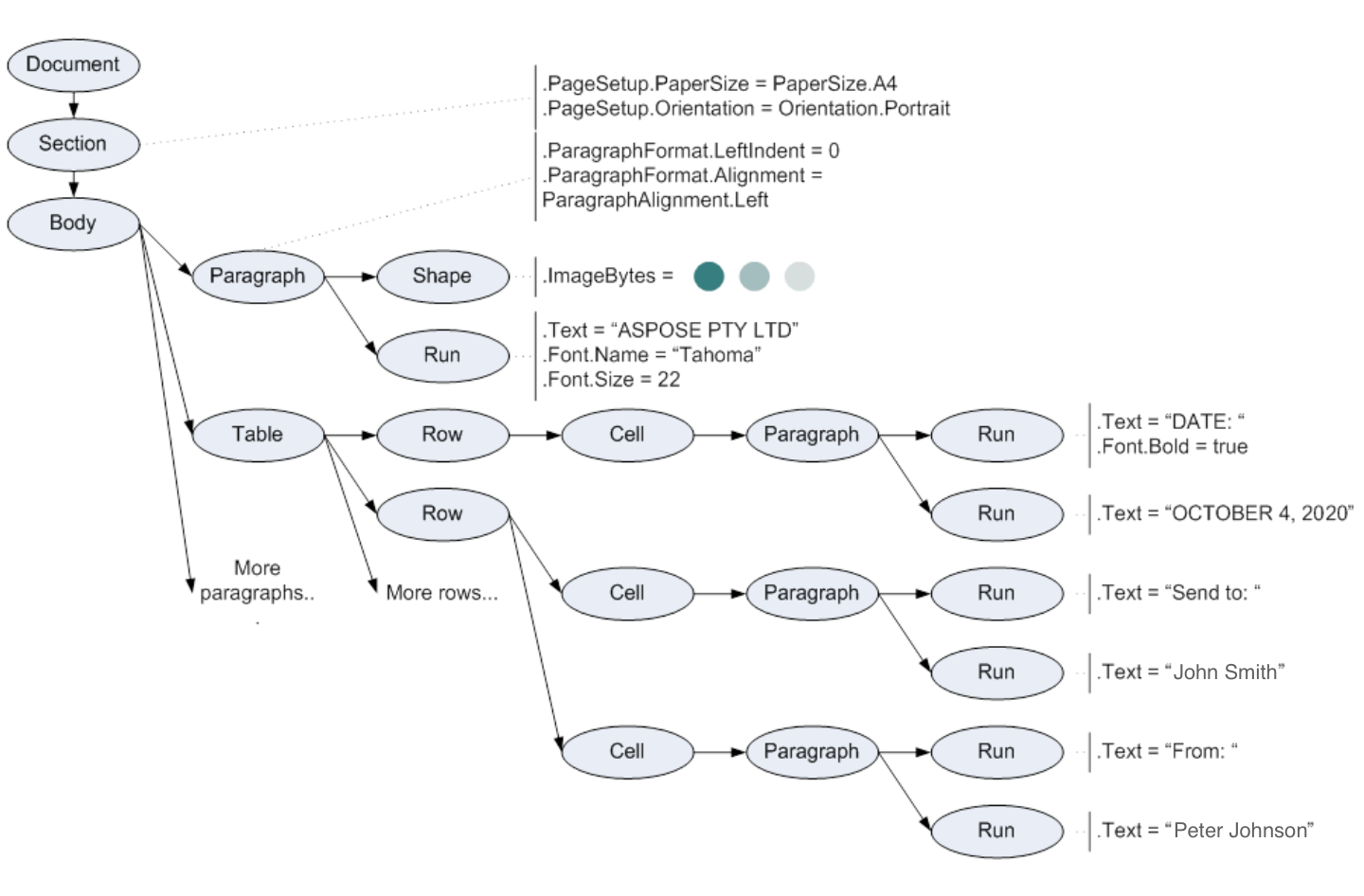
Document, Section, Paragraph, Table, Shape, Run, 图上的所有其他椭圆都是表示Word文档元素的Aspose.Words对象。
Node类型虽然Node类足以将不同的节点彼此区分开来,但Aspose.Words提供了NodeType枚举来简化一些API任务,例如选择特定类型的节点。
每个节点的类型可以使用NodeType属性获得。 此属性返回NodeType枚举值。 例如,Paragraph类表示的段落节点返回NodeType.Paragraph,Table类表示的表节点返回NodeType.Table。
下面的示例演示如何使用NodeType枚举获取节点类型:
Aspose.Words将文档表示为节点树,使您能够在节点之间导航。 本节介绍如何在Aspose.Words中浏览和导航文档树。
当您在文档资源管理器中打开前面介绍的示例文档时,节点树的显示与Aspose.Words中所表示的完全相同。
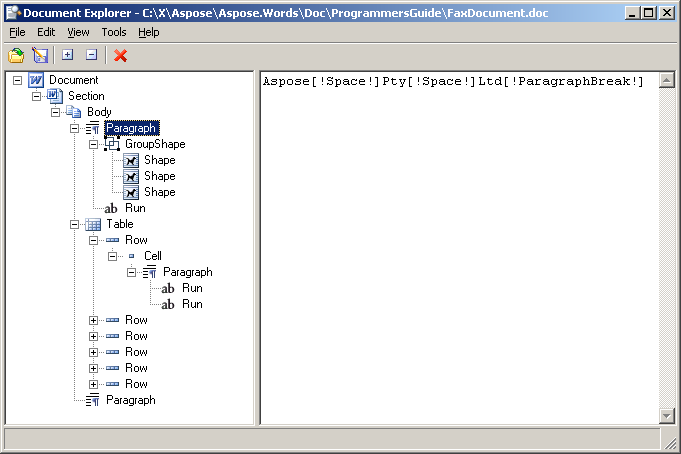
树中的节点之间具有关系:
可以包含其他节点的节点派生自CompositeNode类,所有节点最终派生自Node类。 这两个基类为树结构导航和修改提供了常用的方法和属性。
下面的UML对象图显示了示例文档的几个节点及其通过父、子和兄弟属性相互之间的关系:
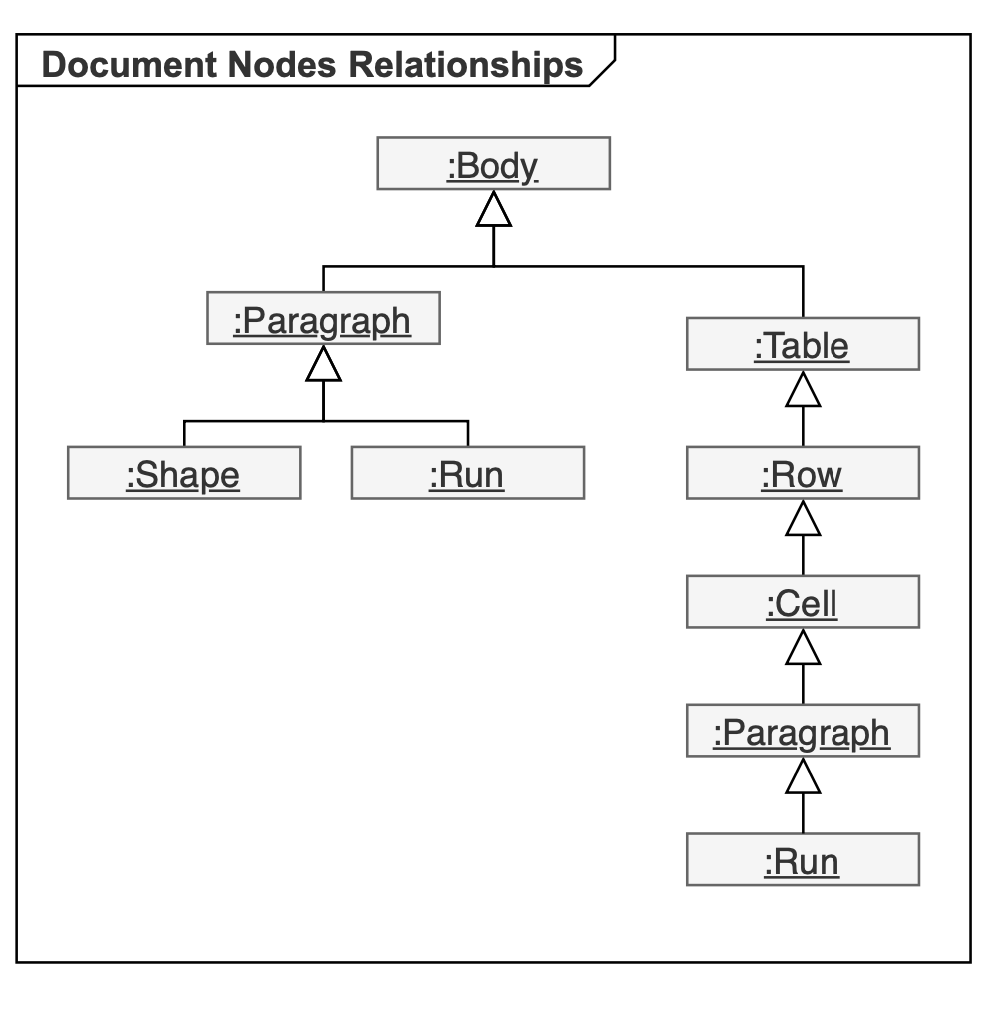
节点始终属于特定文档,即使它刚刚创建或从树中删除,因为重要的文档范围结构(如样式和列表)存储在Document节点中。 例如,不可能有一个没有Document的Paragraph,因为每个段落都有一个为文档全局定义的指定样式。 创建任何新节点时使用此规则。 将新的Paragraph直接添加到DOM需要传递给构造函数的document对象。
使用DocumentBuilder创建新段落时,构建器始终具有通过DocumentBuilder.Document属性链接到它的Document类。
下面的代码示例显示,在创建任何节点时,始终定义将拥有该节点的文档:
每个节点都有一个由ParentNode属性指定的父节点。 在以下情况下,节点没有父节点,即ParentNode为null:
您可以通过调用Remove方法从其父节点中删除节点。下面的代码示例演示如何访问父节点:
访问CompositeNode子节点的最有效方法是通过FirstChild和LastChild属性分别返回第一个和最后一个子节点。 如果没有子节点,这些属性返回null。
CompositeNode
如果节点没有子节点,则ChildNodes属性返回一个空集合。 您可以使用HasChildNodes属性检查CompositeNode是否包含任何子节点。
下面的代码示例演示如何使用ChildNodes集合提供的枚举器枚举CompositeNode的立即子节点:
下面的代码示例演示如何使用索引访问枚举CompositeNode的立即子节点:
您可以分别使用PreviousSibling和NextSibling属性获取紧接在特定节点之前或之后的节点。 如果节点是其父节点的最后一个子节点,则NextSibling属性为null。 相反,如果节点是其父节点的第一个子节点,则PreviousSibling属性为null。
下面的代码示例演示如何高效地访问复合节点的所有直接和间接子节点:
到目前为止,我们已经讨论了返回基类型之一的属性–Node或CompositeNode。 但有时在某些情况下,您可能需要将值转换为特定的节点类,例如Run或Paragraph。 也就是说,在使用复合Aspose.WordsDOM时,您无法完全摆脱铸造。
为了减少强制转换的需要,大多数Aspose.Words类提供了提供强类型访问的属性和集合。 类型化访问有三种基本模式:
类型化属性只是有用的快捷方式,有时提供比从Node.ParentNode和CompositeNode.FirstChild继承的泛型属性更容易的访问。
下面的代码示例演示如何使用类型化属性访问文档树的节点:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.