Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
在某些情况下,不需要在Mail Merge期间从文档中完全删除未合并的区域,或者导致文档看起来不完整。 当没有输入数据应该以消息的形式显示给用户而不是区域被完全移除时,这可以发生。
还有一些时候,单独删除未使用的区域是不够的,例如,如果区域前面有标题或区域包含在表中。 如果该区域未使用,则在删除该区域后,标题和表格仍将保留,该区域将在文档中显得不合适。
本文提供了一个解决方案来手动定义如何处理文档中未使用的区域。 提供了此功能的基本代码,可以在另一个项目中轻松重用。
要应用于每个区域的逻辑在实现IFieldMergingCallback接口的类中定义。 同样,可以设置Mail Merge处理程序来控制每个字段的合并方式,可以设置此处理程序来对未使用区域中的每个字段或整个区域执行操作。 在此处理程序中,您可以设置代码以更改区域的文本,删除节点或空行和单元格等。
在此示例中,我们将使用下面显示的文档。 它包含嵌套区域和表中包含的区域。
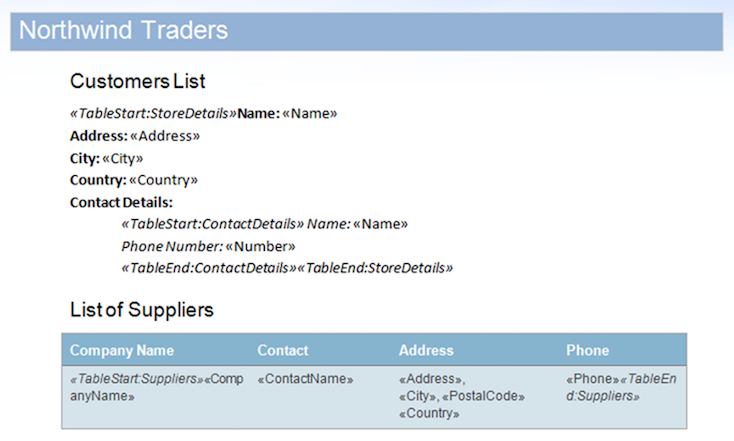
作为一个快速演示,我们可以在启用MailMergeCleanupOptions.REMOVE_UNUSED_REGIONS标志的示例文档上执行示例数据库。 此属性将在mail merge期间自动从文档中删除未合并的区域。
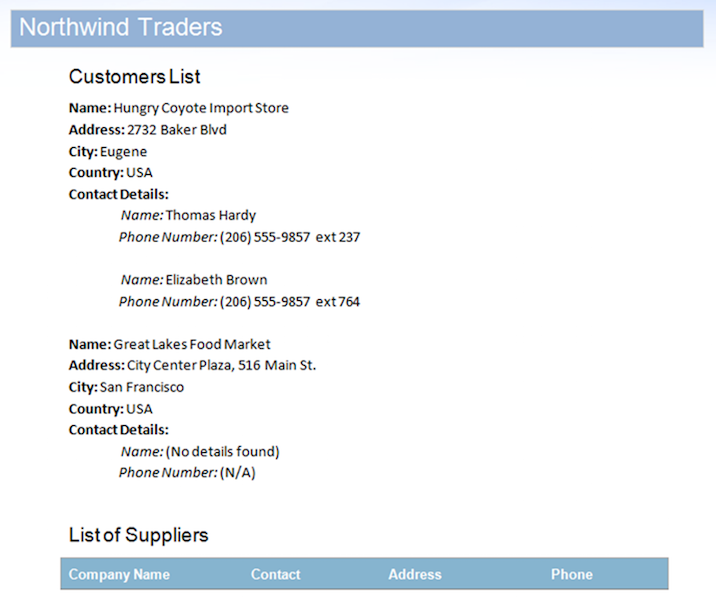
数据源包括StoreDetails区域的两条记录,但有意为其中一条记录的子ContactDetails区域提供任何数据。 此外,Suppliers区域也没有任何数据行。 这将导致未使用的区域保留在文档中。 将文档与此数据源合并后的结果如下。

如上图所示,您可以看到第二条记录的ContactDetails区域和Suppliers区域已被Mail Merge引擎自动删除,因为它们没有数据。 但是,有一些问题使此输出文档看起来不完整:
本文提供的技术演示了如何将自定义逻辑应用于每个未合并的区域以避免这些问题。
解决方案
要手动将逻辑应用于文档中的每个未使用区域,我们利用Aspose.Words中已有的功能。
Mail Merge引擎提供了一个属性,通过MailMergeCleanupOptions.RemoveUnusedRegions标志删除未使用的区域。 这可以被禁用,以便在mail merge期间保持这些区域不变。 这允许我们在文档中留下未合并的区域,并自己手动处理它们。
然后,我们可以利用MailMerge.FieldMergingCallback属性作为一种方法,通过使用实现IFieldMergingCallback接口的处理程序类,在Mail Merge期间将我们自己的自定义逻辑应用于这些未合并的区域。
处理程序类中的此代码是您需要修改的唯一类,以便控制应用于未合并区域的逻辑。 此示例中的其他代码可以在任何项目中重复使用而无需修改。
此示例项目演示了此技术。 它涉及以下步骤:
守则
下面是ExecuteCustomLogicOnEmptyRegions方法的实现。 此方法接受多个参数:
例子:
演示如何使用指定的处理程序在未使用的区域上执行自定义逻辑。
例子:
定义用于手动处理未合并区域的方法。
此方法涉及查找文档中的所有未合并区域。 这是使用MailMerge.GetFieldNames方法完成的。 此方法返回文档中的所有合并字段,包括区域开始和结束标记(由前缀为TableStart或TableEnd的合并字段表示)。
当遇到TableStart合并字段时,它将作为新的DataTable添加到DataSet中。 由于一个区域可能会出现多次(例如,因为它是一个嵌套区域,其中父区域已与多个记录合并),因此只有在DataSet中尚不存在表时才会创建和添加表。
当找到适当的区域开始并将其添加到数据库时,下一个字段(对应于区域中的第一个字段)将添加到DataTable中。 只需要为要合并并传递给处理程序的区域中的每个字段添加第一个字段。
我们还将第一个字段的字段值设置为"FirstField",以便更轻松地将逻辑应用于区域中的第一个或其他字段。 通过包含这个,这意味着没有必要硬编码第一个字段的名称或实现额外的代码来检查当前字段是否是处理程序代码中的第一个。
下面的代码演示了这个系统是如何工作的。 本文开头所示的文档是用相同的数据源重新编写的,但这次,未使用的区域由自定义代码处理。
例子:
演示如何使用用户定义的代码处理Mail Merge之后的未合并区域。
代码根据使用FieldMergingArgs.TableName属性检索的区域的名称执行不同的操作。 请注意,根据您的文档和区域,您可以编写处理程序以运行依赖于每个区域或代码的逻辑,这些逻辑适用于文档中的每个未合并区域或两者的组合。
ContactDetails区域的逻辑涉及使用声明没有数据的适当消息更改ContactDetails区域中每个字段的文本。 每个字段的名称在处理程序中使用FieldMergingArgs.FieldName属性进行匹配。
类似的过程应用于Suppliers区域,并添加额外的代码来处理包含该区域的表。 代码将检查区域是否包含在表中(因为它可能已经被删除)。 如果是,它将从文档中删除整个表以及它前面的段落,只要它的格式为标题样式,例如"Heading 1"。
例子:
演示如何在实现为文档中未合并的区域执行的IFieldMergingCallback的处理程序中定义自定义逻辑。
上面代码的结果如下所示。 第一个区域内的未合并字段将替换为信息性文本,删除表格和标题可使文档看起来完整。

删除父表的代码也可以通过删除表名的检查来在每个未使用的区域上运行,而不仅仅是一个特定的区域。 在这种情况下,如果表中的任何区域未与任何数据合并,则该区域和容器表也将自动删除。
我们可以在处理程序中插入不同的代码来控制如何处理未合并的区域。 在处理程序中使用下面的代码会将区域第一段中的文本更改为有用的消息,同时删除区域中的任何后续段落。 这些其他段落将被删除,因为它们将在合并我们的信息后保留在该地区。
通过将指定文本设置为FieldMergingArgs.Text属性,替换文本将合并到第一个字段中。 此属性中的文本由Mail Merge引擎合并到字段中。
代码通过检查FieldMergingArgs.FieldValue属性,仅对区域中的第一个字段应用此操作。 区域中的第一个字段的字段值用"FirstField"标记。 这使得这种类型的逻辑更容易在许多地区实现,因为不需要额外的代码。
例子:
演示如何用消息替换未使用的区域并删除额外的段落。
执行上述代码后生成的文档如下所示。 未使用的区域将替换为一条消息,指出没有要显示的记录。

作为另一个例子,我们可以插入下面的代码来代替最初处理SuppliersRegion的代码。 这将在表格中显示一条消息并合并单元格,而不是从文档中删除表格。 由于区域驻留在具有多个单元格的表中,因此将表的单元格合并在一起并将消息居中看起来更好。
例子:
演示如何合并未使用区域的所有父单元格并在表中显示消息。
执行上述代码后生成的文档如下所示。

最后,我们可以调用ExecuteCustomLogicOnEmptyRegions方法并指定应该在处理程序方法中处理的表名,同时指定要自动删除的其他表名。
例子:
演示如何仅指定要通过handler类处理的ContactDetails区域。
使用指定的ArrayList调用此重载将创建仅包含指定区域的数据行的数据源。 ContactDetails区域以外的区域将不会被处理,而是由Mail Merge引擎自动删除。 使用我们原始处理程序中的代码进行上述调用的结果如下所示。
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.