Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
Bei der Arbeit mit Dokumenten ist es wichtig, Inhalte aus einem bestimmten Bereich innerhalb eines Dokuments einfach extrahieren zu können. Der Inhalt kann jedoch aus komplexen Elementen wie Absätzen, Tabellen, Bildern usw. bestehen.
Unabhängig davon, welcher Inhalt extrahiert werden muss, wird die Methode zum Extrahieren dieses Inhalts immer dadurch bestimmt, zwischen welchen Knoten Inhalte extrahiert werden sollen. Dies können ganze Textkörper oder einfache Textläufe sein.
Es gibt viele mögliche Situationen und daher viele verschiedene Knotentypen, die beim Extrahieren von Inhalten berücksichtigt werden müssen. Beispielsweise möchten Sie möglicherweise Inhalte extrahieren zwischen:
In einigen Situationen müssen Sie möglicherweise sogar verschiedene Knotentypen kombinieren, z. B. das Extrahieren von Inhalten zwischen einem Absatz und einem Feld oder zwischen einem Lauf und einem Lesezeichen.
Dieser Artikel enthält die Codeimplementierung zum Extrahieren von Text zwischen verschiedenen Knoten sowie Beispiele für gängige Szenarien.
Oft besteht das Ziel des Extrahierens des Inhalts darin, ihn zu duplizieren oder separat in einem neuen Dokument zu speichern. Sie können beispielsweise Inhalte extrahieren und:
Dies kann leicht mit Aspose.Words und der folgenden Code-Implementierung erreicht werden.
Der Code in diesem Abschnitt behandelt alle oben beschriebenen möglichen Situationen mit einer verallgemeinerten und wiederverwendbaren Methode. Der allgemeine Überblick über diese Technik beinhaltet:
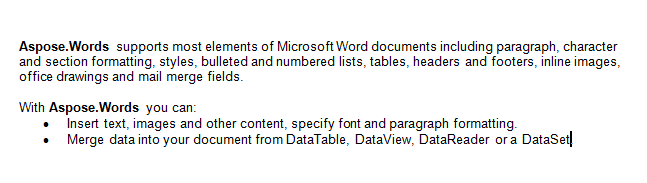
Wir werden mit dem Dokument unten in diesem Artikel arbeiten. Wie Sie sehen, enthält es eine Vielzahl von Inhalten. Beachten Sie auch, dass das Dokument einen zweiten Abschnitt enthält, der in der Mitte der ersten Seite beginnt. Ein Lesezeichen und ein Kommentar sind ebenfalls im Dokument vorhanden, im folgenden Screenshot jedoch nicht sichtbar.

Um den Inhalt aus Ihrem Dokument zu extrahieren, müssen Sie die unten stehende Methode ExtractContent aufrufen und die entsprechenden Parameter übergeben.
Die zugrunde liegende Grundlage dieser Methode besteht darin, Knoten auf Blockebene (Absätze und Tabellen) zu finden und sie zu klonen, um identische Kopien zu erstellen. Wenn die übergebenen Markerknoten Blockebene sind, kann die Methode den Inhalt auf dieser Ebene einfach kopieren und dem Array hinzufügen.
Wenn die Markerknoten jedoch inline sind (ein untergeordnetes Element eines Absatzes), wird die Situation komplexer, da der Absatz am Inline-Knoten aufgeteilt werden muss, sei es ein Lauf, Lesezeichenfelder usw. Inhalt in den geklonten übergeordneten Knoten, der nicht zwischen den Markern vorhanden ist, wird entfernt. Dieser Prozess wird verwendet, um sicherzustellen, dass die Inline-Knoten weiterhin die Formatierung des übergeordneten Absatzes beibehalten.
Die Methode führt auch Überprüfungen der als Parameter übergebenen Knoten durch und löst eine Ausnahme aus, wenn einer der Knoten ungültig ist. Die Parameter, die an diese Methode übergeben werden sollen, sind:
StartNode und EndNode. Die ersten beiden Parameter sind die Knoten, die definieren, wo die Extraktion des Inhalts beginnen bzw. enden soll. Diese Knoten können sowohl Blockebene (Paragraph, Table) als auch Inline-Ebene (z. B.) sein Run, FieldStart, BookmarkStart usw.):
IsInclusive. Definiert, ob die Marker in die Extraktion einbezogen werden oder nicht. Wenn diese Option auf false gesetzt ist und derselbe Knoten oder aufeinanderfolgende Knoten übergeben werden, wird eine leere Liste zurückgegeben:
Die Implementierung der ExtractContent -Methode finden Sie hier. Auf diese Methode wird in den Szenarien in diesem Artikel Bezug genommen.
Wir werden auch eine benutzerdefinierte Methode definieren, um auf einfache Weise ein Dokument aus extrahierten Knoten zu generieren. Diese Methode wird in vielen der folgenden Szenarien verwendet und erstellt einfach ein neues Dokument und importiert den extrahierten Inhalt hinein.
Das folgende Codebeispiel zeigt, wie Sie eine Liste von Knoten erstellen und in ein neues Dokument einfügen:
Dies zeigt, wie Sie mit der obigen Methode Inhalte zwischen bestimmten Absätzen extrahieren. In diesem Fall möchten wir den Text des Briefes extrahieren, der in der ersten Hälfte des Dokuments gefunden wurde. Wir können sagen, dass dies zwischen dem 7. und 11. Absatz liegt.
Der folgende Code führt diese Aufgabe aus. Die entsprechenden Absätze werden mit der getChild -Methode im Dokument extrahiert und übergeben die angegebenen Indizes. Diese Knoten übergeben wir dann an die Methode ExtractContent und geben an, dass diese in die Extraktion einbezogen werden sollen. Diese Methode gibt den kopierten Inhalt zwischen diesen Knoten zurück, die dann in ein neues Dokument eingefügt werden.
Das folgende Codebeispiel zeigt, wie Sie den Inhalt zwischen bestimmten Absätzen mit der obigen ExtractContent -Methode extrahieren:
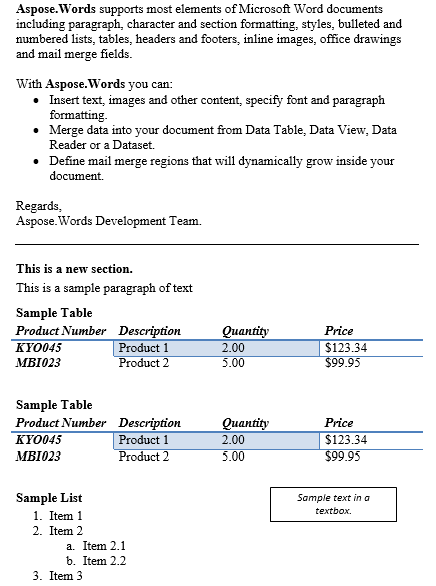
Das Ausgabedokument enthält die beiden extrahierten Absätze.
Wir können Inhalte zwischen beliebigen Kombinationen von Block-Level- oder Inline-Knoten extrahieren. In diesem Szenario werden wir den Inhalt zwischen dem ersten Absatz und der Tabelle im zweiten Abschnitt einschließlich extrahieren. Wir erhalten die Markerknoten, indem wir die Methoden getFirstParagraph und getChild im zweiten Abschnitt des Dokuments aufrufen, um die entsprechenden Knoten Paragraph und Table abzurufen. Für eine leichte Variation duplizieren wir stattdessen den Inhalt und fügen ihn unter das Original ein.
Das folgende Codebeispiel zeigt, wie Sie den Inhalt zwischen einem Absatz und einer Tabelle mit der Methode ExtractContent extrahieren:
Der Inhalt zwischen Absatz und Tabelle wurde unten dupliziert, ist das Ergebnis.
Möglicherweise müssen Sie den Inhalt zwischen Absätzen desselben oder eines anderen Stils extrahieren, z. B. zwischen Absätzen, die mit Überschriftenstilen markiert sind.
Der folgende Code zeigt, wie dies erreicht werden kann. Es ist ein einfaches Beispiel, das den Inhalt zwischen der ersten Instanz der Stile “Heading 1” und “Header 3” extrahiert, ohne auch die Überschriften zu extrahieren. Dazu setzen wir den letzten Parameter auf false, der angibt, dass die Markerknoten nicht enthalten sein sollen.
In einer ordnungsgemäßen Implementierung sollte dies in einer Schleife ausgeführt werden, um Inhalte zwischen allen Absätzen dieser Stile aus dem Dokument zu extrahieren. Der extrahierte Inhalt wird in ein neues Dokument kopiert.
Das folgende Codebeispiel zeigt, wie Inhalte zwischen Absätzen mit bestimmten Stilen mithilfe der ExtractContent-Methode extrahiert werden:
Unten sehen Sie das Ergebnis der vorherigen Operation.

Sie können auch Inhalte zwischen Inline-Knoten wie Run extrahieren. Runs aus verschiedenen Absätzen kann als Marker übergeben werden. Der folgende Code zeigt, wie Sie bestimmten Text zwischen demselben Paragraph -Knoten extrahieren.
Das folgende Codebeispiel zeigt, wie Inhalte zwischen bestimmten Läufen desselben Absatzes mit der Methode ExtractContent extrahiert werden:
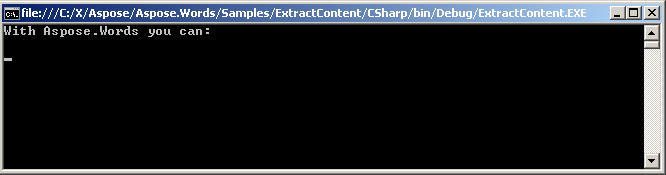
Der extrahierte Text wird auf der Konsole angezeigt.
Um ein Feld als Markierung zu verwenden, sollte der Knoten FieldStart übergeben werden. Der letzte Parameter der ExtractContent -Methode definiert, ob das gesamte Feld eingeschlossen werden soll oder nicht. Extrahieren wir den Inhalt zwischen dem Seriendruckfeld “FullName” und einem Absatz im Dokument. Wir verwenden die Methode moveToMergeField der Klasse DocumentBuilder. Dadurch wird der Knoten FieldStart aus dem Namen des übergebenen Seriendruckfelds zurückgegeben.
In unserem Fall setzen wir den letzten an die ExtractContent -Methode übergebenen Parameter auf false, um das Feld von der Extraktion auszuschließen. Wir werden den extrahierten Inhalt in PDF rendern.
Das folgende Codebeispiel zeigt, wie Sie mit der Methode ExtractContent Inhalte zwischen einem bestimmten Feld und einem Absatz im Dokument extrahieren:
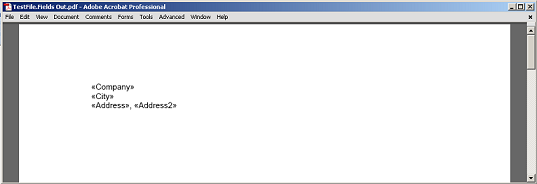
Der extrahierte Inhalt zwischen Feld und Absatz, ohne dass die Feld- und Absatzmarkierungsknoten auf PDF gerendert werden.
In einem Dokument wird der Inhalt, der in einem Lesezeichen definiert ist, durch die Knoten BookmarkStart und BookmarkEnd gekapselt. Der Inhalt, der zwischen diesen beiden Knoten gefunden wird, bildet das Lesezeichen. Sie können jeden dieser Knoten als beliebige Markierung übergeben, auch als Solche aus verschiedenen Lesezeichen, sofern die Startmarkierung vor der Endmarkierung im Dokument angezeigt wird.
In unserem Beispieldokument haben wir ein Lesezeichen mit dem Namen “Lesezeichen 1”. Der Inhalt dieses Lesezeichens ist hervorgehobener Inhalt in unserem Dokument:
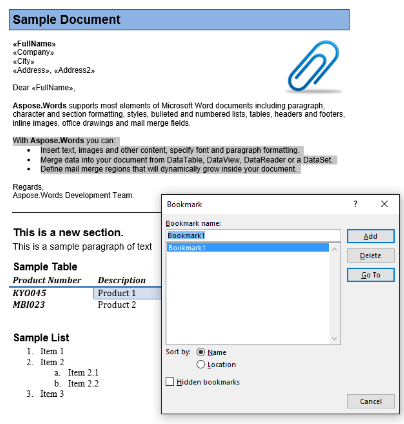
Wir werden diesen Inhalt mit dem folgenden Code in ein neues Dokument extrahieren. Die Parameteroption IsInclusive zeigt, wie das Lesezeichen beibehalten oder verworfen wird.
Das folgende Codebeispiel zeigt, wie Sie den Inhalt, auf den ein Lesezeichen verweist, mit der Methode ExtractContent extrahieren:
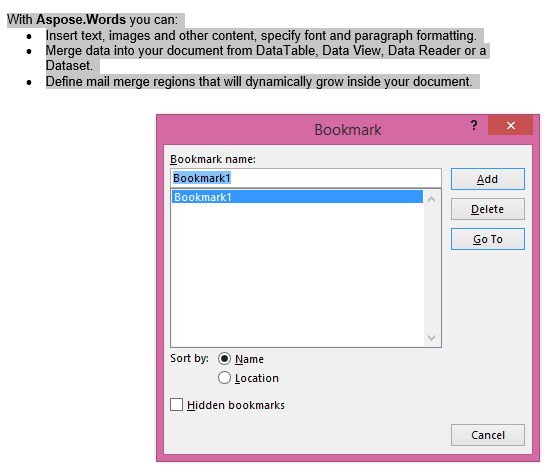
Die extrahierte Ausgabe mit dem Parameter IsInclusive, der auf true gesetzt ist. Die Kopie behält auch das Lesezeichen bei.
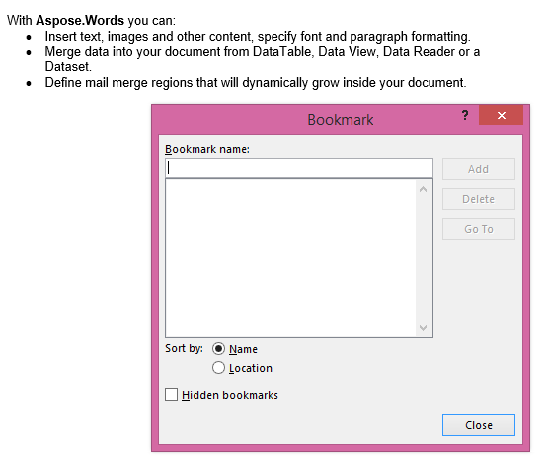
Die extrahierte Ausgabe mit dem Parameter IsInclusive, der auf false gesetzt ist. Die Kopie enthält den Inhalt, jedoch ohne das Lesezeichen.
Ein Kommentar besteht aus den Knoten CommentRangeStart, CommentRangeEnd und Kommentar. Alle diese Knoten sind inline. Die ersten beiden Knoten kapseln den Inhalt des Dokuments ein, auf den der Kommentar verweist, wie in der Abbildung unten zu sehen ist.
Der Comment -Knoten selbst ist eine InlineStory, die Absätze und Läufe enthalten kann. Es stellt die Nachricht des Kommentars dar, die als Kommentarblase im Überprüfungsbereich angezeigt wird. Da dieser Knoten inline ist und von einem Body abstammt, können Sie den Inhalt auch aus dieser Nachricht extrahieren.
In unserem Dokument haben wir einen Kommentar. Lassen Sie es uns anzeigen, indem Sie Markup auf der Registerkarte Überprüfung anzeigen:
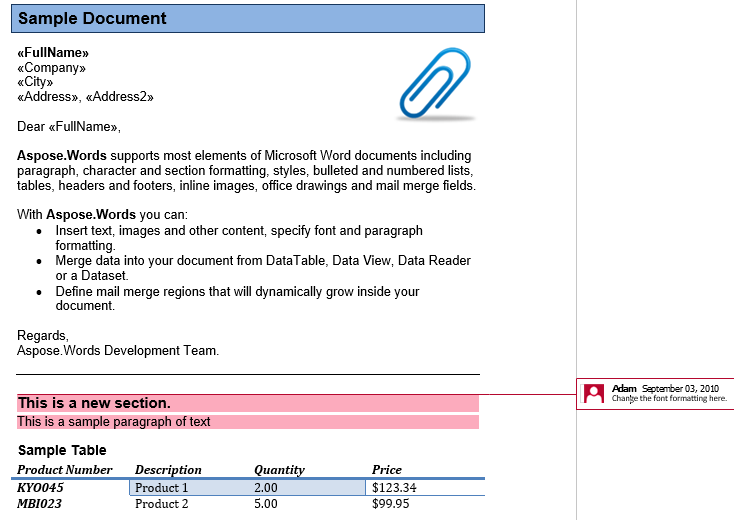
Der Kommentar kapselt die Überschrift, den ersten Absatz und die Tabelle im zweiten Abschnitt ein. Extrahieren wir diesen Kommentar in ein neues Dokument. Die Option IsInclusive bestimmt, ob der Kommentar selbst beibehalten oder verworfen wird.
Das folgende Codebeispiel zeigt, wie dies zu tun ist:
Zuerst die extrahierte Ausgabe mit dem Parameter IsInclusive, der auf true gesetzt ist. Die Kopie enthält auch den Kommentar.
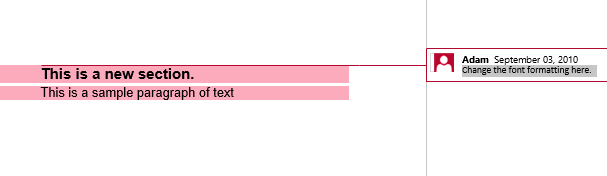
Zweitens wird die extrahierte Ausgabe mit isInclusive auf false gesetzt. Die Kopie enthält den Inhalt, jedoch ohne den Kommentar.

Aspose.Words kann nicht nur zum Erstellen von Microsoft Word -Dokumenten verwendet werden, indem sie dynamisch erstellt oder Vorlagen mit Daten zusammengeführt werden, sondern auch zum Parsen von Dokumenten, um separate Dokumentelemente wie Kopf- und Fußzeilen, Absätze, Tabellen, Bilder und andere zu extrahieren. Eine andere mögliche Aufgabe besteht darin, den gesamten Text mit einer bestimmten Formatierung oder einem bestimmten Stil zu finden.
Verwenden Sie die Klasse DocumentVisitor, um dieses Verwendungsszenario zu implementieren. Diese Klasse entspricht dem bekannten Besucherdesignmuster. Mit DocumentVisitor können Sie benutzerdefinierte Operationen definieren und ausführen, die eine Aufzählung über den Dokumentbaum erfordern.
DocumentVisitor stellt eine Reihe von VisitXXX Methoden bereit, die aufgerufen werden, wenn ein bestimmtes Dokumentelement (Knoten) angetroffen wird. Beispielsweise wird VisitParagraphStart aufgerufen, wenn der Anfang eines Textabsatzes gefunden wird, und VisitParagraphEnd wird aufgerufen, wenn das Ende eines Textabsatzes gefunden wird. Jede DocumentVisitor.VisitXXX -Methode akzeptiert das entsprechende Objekt, auf das sie stößt, damit Sie es nach Bedarf verwenden können (z. B. die Formatierung abrufen), z. B. akzeptieren sowohl VisitParagraphStart als auch VisitParagraphEnd ein Paragraph -Objekt.
Jede DocumentVisitor.VisitXXX -Methode gibt einen VisitorAction-Wert zurück, der die Aufzählung von Knoten steuert. Sie können entweder anfordern, die Aufzählung fortzusetzen, den aktuellen Knoten zu überspringen (aber die Aufzählung fortzusetzen) oder die Aufzählung von Knoten zu stoppen.
Dies sind die Schritte, die Sie ausführen sollten, um verschiedene Teile eines Dokuments programmgesteuert zu bestimmen und zu extrahieren:
DocumentVisitor stellt Standardimplementierungen für alle DocumentVisitor.VisitXXX-Methoden bereit. Dies erleichtert das Erstellen neuer Dokumentenbesucher, da nur die für den jeweiligen Besucher erforderlichen Methoden überschrieben werden müssen. Es ist nicht erforderlich, alle Besuchermethoden zu überschreiben.
Das folgende Beispiel zeigt, wie Sie das Besuchermuster verwenden, um dem Aspose.Words-Objektmodell neue Operationen hinzuzufügen. In diesem Fall erstellen wir einen einfachen Dokumentenkonverter in ein Textformat:
Die Möglichkeiten zum Abrufen von Text aus dem Dokument sind:
SaveFormat.Text. Intern ruft dies das Speichern als Text in einen Speicherstrom auf und gibt die resultierende Zeichenfolge zurückNode.GetText und Node.ToStringEin Word-Dokument kann Steuerzeichen enthalten, die spezielle Elemente wie Feld, Zellende, Abschnittsende usw. kennzeichnen. Die vollständige Liste der möglichen Wortsteuerzeichen ist in der Klasse ControlChar definiert. Die Methode GetText gibt Text mit allen im Knoten vorhandenen Steuerzeichenzeichen zurück.
Der Aufruf von ToString gibt die Klartextdarstellung des Dokuments nur ohne Steuerzeichen zurück. Weitere Informationen zum Export als Klartext finden Sie unter Using SaveFormat.Text.
Das folgende Codebeispiel zeigt den Unterschied zwischen dem Aufruf der Methoden GetText und ToString auf einem Knoten:
SaveFormat.TextIn diesem Beispiel wird das Dokument wie folgt gespeichert:
Das folgende Codebeispiel zeigt, wie Sie ein Dokument im Format TXT speichern:
Möglicherweise müssen Sie Dokumentbilder extrahieren, um einige Aufgaben auszuführen. Mit Aspose.Words können Sie dies auch tun.
Das folgende Codebeispiel zeigt, wie Bilder aus einem Dokument extrahiert werden:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.