Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
Es gibt Situationen, in denen das vollständige Entfernen nicht zusammengeführter Bereiche aus dem Dokument während Mail Merge nicht erwünscht ist oder dazu führt, dass das Dokument unvollständig aussieht. Dies kann auftreten, wenn das Fehlen von Eingabedaten dem Benutzer in Form einer Nachricht angezeigt werden soll, anstatt den Bereich vollständig zu entfernen.
Es gibt auch Zeiten, in denen das Entfernen der nicht verwendeten Region allein nicht ausreicht, z. B. wenn der Region ein Titel vorangestellt ist oder die Region in einer Tabelle enthalten ist. Wenn dieser Bereich nicht verwendet wird, bleiben Titel und Tabelle nach dem Entfernen des Bereichs erhalten, was im Dokument fehl am Platz aussieht.
Dieser Artikel bietet eine Lösung, um manuell zu definieren, wie nicht verwendete Bereiche im Dokument behandelt werden. Der Basiscode für diese Funktionalität wird mitgeliefert und kann problemlos in einem anderen Projekt wiederverwendet werden.
Die auf jede Region anzuwendende Logik wird in einer Klasse definiert, die die Schnittstelle IFieldMergingCallback implementiert. Auf die gleiche Weise kann ein Mail Merge -Handler eingerichtet werden, um zu steuern, wie jedes Feld zusammengeführt wird. Dieser Handler kann so eingerichtet werden, dass er Aktionen für jedes Feld in einer nicht verwendeten Region oder für die Region als Ganzes ausführt. In diesem Handler können Sie den Code festlegen, um den Text einer Region zu ändern, Knoten oder leere Zeilen und Zellen zu entfernen usw.
In diesem Beispiel verwenden wir das unten angezeigte Dokument. Es enthält verschachtelte Bereiche und einen Bereich in einer Tabelle.
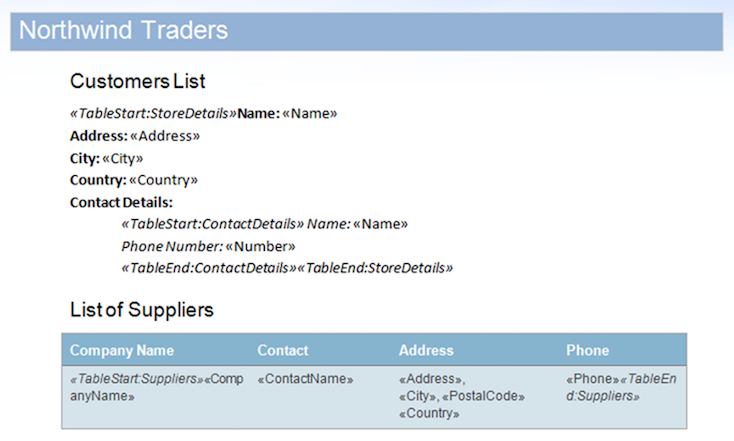
Als schnelle Demonstration können wir eine Beispieldatenbank für das Beispieldokument mit aktiviertem Flag MailMergeCleanupOptions.REMOVE_UNUSED_REGIONS ausführen. Diese Eigenschaft entfernt nicht zusammengeführte Bereiche während eines mail merge automatisch aus dem Dokument.
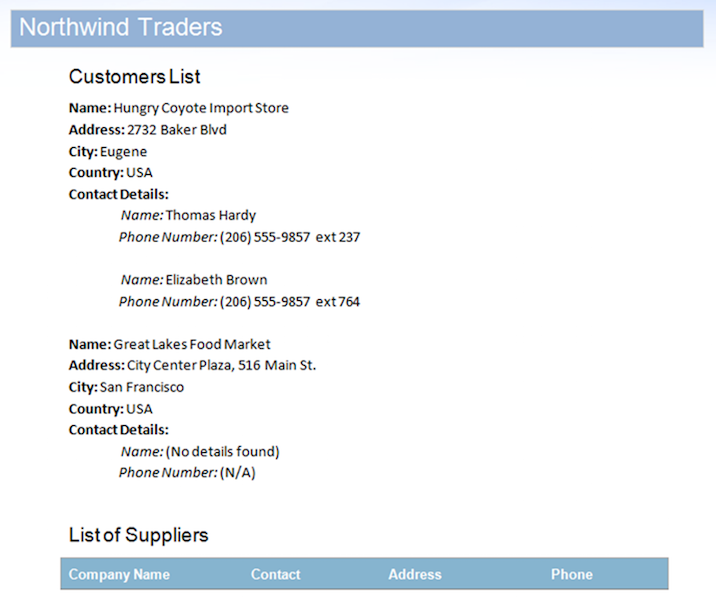
Die Datenquelle enthält zwei Datensätze für die Region StoreDetails, enthält jedoch absichtlich Daten für die untergeordneten Regionen ContactDetails für einen der Datensätze. Darüber hinaus enthält die Region Suppliers auch keine Datenzeilen. Dadurch verbleiben nicht verwendete Bereiche im Dokument. Das Ergebnis nach dem Zusammenführen des Dokuments mit dieser Datenquelle ist unten aufgeführt.

Wie auf dem Bild zu sehen ist, können Sie sehen, dass die Region ContactDetails für den zweiten Datensatz und die Regionen Suppliers von der Mail Merge -Engine automatisch entfernt wurden, da sie keine Daten enthalten. Es gibt jedoch einige Probleme, die dieses Ausgabedokument unvollständig erscheinen lassen:
Die in diesem Artikel bereitgestellte Technik zeigt, wie benutzerdefinierte Logik auf jede nicht zusammengeführte Region angewendet wird, um diese Probleme zu vermeiden.
Lösung
Um Logik manuell auf jeden nicht verwendeten Bereich im Dokument anzuwenden, nutzen wir Funktionen, die bereits in Aspose.Words verfügbar sind.
Die Mail Merge -Engine bietet eine Eigenschaft zum Entfernen nicht verwendeter Bereiche durch das Flag MailMergeCleanupOptions.RemoveUnusedRegions. Dies kann deaktiviert werden, so dass solche Regionen während einer mail merge unberührt bleiben. Dies ermöglicht es uns, die nicht zusammengeführten Bereiche im Dokument zu belassen und sie stattdessen manuell selbst zu bearbeiten.
Wir können dann die Eigenschaft MailMerge.FieldMergingCallback nutzen, um während Mail Merge unsere eigene benutzerdefinierte Logik auf diese nicht zusammengeführten Regionen anzuwenden, indem wir eine Handlerklasse verwenden, die die Schnittstelle IFieldMergingCallback implementiert.
Dieser Code innerhalb der Handlerklasse ist die einzige Klasse, die Sie ändern müssen, um die Logik zu steuern, die auf nicht zusammengeführte Regionen angewendet wird. Der andere Code in diesem Beispiel kann ohne Änderung in jedem Projekt wiederverwendet werden.
Dieses Beispielprojekt demonstriert diese Technik. Es umfasst die folgenden Schritte:
Codes
Die Implementierung für die ExecuteCustomLogicOnEmptyRegions -Methode finden Sie unten. Diese Methode akzeptiert mehrere Parameter:
Beispiel
Zeigt, wie benutzerdefinierte Logik für nicht verwendete Bereiche mit dem angegebenen Handler ausgeführt wird.
Beispiel
Definiert die Methode, mit der nicht zusammengeführte Regionen manuell behandelt werden.
Bei dieser Methode werden alle nicht zusammengeführten Bereiche im Dokument gefunden. Dies wird mit der MailMerge.GetFieldNames -Methode erreicht. Diese Methode gibt alle Seriendruckfelder im Dokument zurück, einschließlich der Start- und Endmarkierungen des Bereichs (dargestellt durch Seriendruckfelder mit dem Präfix TableStart oder TableEnd).
Wenn ein TableStart -Seriendruckfeld gefunden wird, wird dieses als neue DataTable zu DataSet hinzugefügt. Da eine Region mehr als einmal vorkommen kann (z. B. weil es sich um eine verschachtelte Region handelt, in der die übergeordnete Region mit mehreren Datensätzen zusammengeführt wurde), wird die Tabelle nur erstellt und hinzugefügt, wenn sie nicht bereits in DataSet vorhanden ist.
Wenn ein geeigneter Regionsanfang gefunden und der Datenbank hinzugefügt wurde, wird das nächste Feld (das dem ersten Feld in der Region entspricht) zu DataTable hinzugefügt. Für jedes Feld in der Region, das zusammengeführt und an den Handler übergeben werden soll, muss nur das erste Feld hinzugefügt werden.
Wir setzen auch den Feldwert des ersten Felds auf “FirstField”, um die Anwendung von Logik auf das erste oder andere Felder in der Region zu vereinfachen. Wenn Sie dies einschließen, bedeutet dies, dass es nicht erforderlich ist, den Namen des ersten Felds fest zu codieren oder zusätzlichen Code zu implementieren, um zu überprüfen, ob das aktuelle Feld das erste im Handlercode ist.
Der folgende Code zeigt, wie dieses System funktioniert. Das am Anfang dieses Artikels gezeigte Dokument wird mit derselben Datenquelle erneut zusammengeführt, aber diesmal werden die nicht verwendeten Bereiche von benutzerdefiniertem Code verarbeitet.
Beispiel
Zeigt, wie nicht zusammengeführte Regionen nach Mail Merge mit benutzerdefiniertem Code behandelt werden.
Der Code führt verschiedene Operationen basierend auf dem Namen der Region aus, die mit der Eigenschaft FieldMergingArgs.TableName abgerufen wurde. Beachten Sie, dass Sie abhängig von Ihrem Dokument und Ihren Regionen den Handler so codieren können, dass die Logik abhängig von jeder Region oder jedem Code ausgeführt wird, der für jede nicht zusammengeführte Region im Dokument oder eine Kombination aus beiden gilt.
Die Logik für die Region ContactDetails beinhaltet das Ändern des Textes jedes Felds in der Region ContactDetails mit einer entsprechenden Meldung, die besagt, dass keine Daten vorhanden sind. Die Namen der einzelnen Felder werden innerhalb des Handlers mithilfe der Eigenschaft FieldMergingArgs.FieldName abgeglichen.
Ein ähnlicher Prozess wird auf die Region Suppliers angewendet, wobei zusätzlicher Code hinzugefügt wird, um die Tabelle zu behandeln, die die Region enthält. Der Code prüft, ob die Region in einer Tabelle enthalten ist (da sie möglicherweise bereits entfernt wurde). Wenn dies der Fall ist, werden die gesamte Tabelle sowie der vorangehende Absatz aus dem Dokument entfernt, sofern sie mit einem Überschriftenstil formatiert ist, z. B. “Heading 1”.
Beispiel
Zeigt, wie benutzerdefinierte Logik in einem Handler definiert wird, der IFieldMergingCallback implementiert und für nicht zusammengeführte Bereiche im Dokument ausgeführt wird.
Das Ergebnis des obigen Codes ist unten gezeigt. Die nicht zusammengeführten Felder im ersten Bereich werden durch informativen Text ersetzt, und das Entfernen der Tabelle und der Überschrift lässt das Dokument vollständig aussehen.

Der Code, der die übergeordnete Tabelle entfernt, könnte auch für jede nicht verwendete Region anstatt nur für eine bestimmte Region ausgeführt werden, indem die Prüfung auf den Tabellennamen entfernt wird. Wenn in diesem Fall ein Bereich innerhalb einer Tabelle nicht mit Daten zusammengeführt wurde, werden sowohl der Bereich als auch die Containertabelle automatisch entfernt.
Wir können verschiedenen Code in den Handler einfügen, um zu steuern, wie nicht zusammengeführte Regionen behandelt werden. Wenn Sie stattdessen den folgenden Code im Handler verwenden, wird der Text im ersten Absatz der Region in eine hilfreiche Nachricht geändert, während alle nachfolgenden Absätze in der Region entfernt werden. Diese anderen Absätze werden entfernt, da sie nach dem Zusammenführen unserer Nachricht in der Region verbleiben würden.
Der Ersetzungstext wird in das erste Feld eingefügt, indem der angegebene Text in die Eigenschaft FieldMergingArgs.Text gesetzt wird. Der Text aus dieser Eigenschaft wird von der Mail Merge-Engine in das Feld eingefügt.
Der Code wendet dies nur für das erste Feld in der Region an, indem die Eigenschaft FieldMergingArgs.FieldValue überprüft wird. Der Feldwert des ersten Feldes in der Region ist mit “FirstField” gekennzeichnet. Dies erleichtert die Implementierung dieser Art von Logik in vielen Regionen, da kein zusätzlicher Code erforderlich ist.
Beispiel
Zeigt, wie Sie einen nicht verwendeten Bereich durch eine Nachricht ersetzen und zusätzliche Absätze entfernen.
Das resultierende Dokument, nachdem der obige Code ausgeführt wurde, ist unten gezeigt. Der nicht verwendete Bereich wird durch eine Meldung ersetzt, die besagt, dass keine anzuzeigenden Datensätze vorhanden sind.

Als weiteres Beispiel können wir den folgenden Code anstelle des Codes einfügen, der ursprünglich die SuppliersRegion behandelt hat. Dadurch wird eine Meldung in der Tabelle angezeigt und die Zellen werden zusammengeführt, anstatt die Tabelle aus dem Dokument zu entfernen. Da sich der Bereich in einer Tabelle mit mehreren Zellen befindet, sieht es schöner aus, wenn die Zellen der Tabelle zusammengeführt und die Nachricht zentriert werden.
Beispiel
Zeigt, wie alle übergeordneten Zellen eines nicht verwendeten Bereichs zusammengeführt und eine Meldung in der Tabelle angezeigt werden.
Das resultierende Dokument, nachdem der obige Code ausgeführt wurde, ist unten gezeigt.

Schließlich können wir die ExecuteCustomLogicOnEmptyRegions -Methode aufrufen und die Tabellennamen angeben, die in unserer Handler-Methode behandelt werden sollen, während andere angegeben werden, die automatisch entfernt werden sollen.
Beispiel
Zeigt, wie nur die ContactDetails-Region angegeben wird, die von der Handlerklasse verarbeitet werden soll.
Durch Aufrufen dieser Überladung mit dem angegebenen ArrayList wird die Datenquelle erstellt, die nur Datenzeilen für die angegebenen Regionen enthält. Andere Regionen als die ContactDetails-Region werden nicht behandelt und stattdessen automatisch von der Mail Merge-Engine entfernt. Das Ergebnis des obigen Aufrufs unter Verwendung des Codes in unserem ursprünglichen Handler ist unten gezeigt.
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.