Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
בעת עבודה עם מסמכים, חשוב להיות מסוגל בקלות להפיק תוכן מטווח מסוים בתוך מסמך. עם זאת, התוכן עשוי לכלול אלמנטים מורכבים כגון פסקאות, טבלאות, תמונות וכו ‘.
ללא קשר לשאלה איזה תוכן צריך להיות מופק, השיטה כדי לחלץ תוכן זה תמיד ייקבע על ידי אילו צמתים נבחרים כדי להפיק תוכן בין. אלה יכולים להיות גוף טקסט שלם או טקסט פשוט פועל.
ישנם מצבים רבים אפשריים ולכן סוגים שונים של צומת לשקול בעת תמצית התוכן. לדוגמה, ייתכן שתרצה להפיק תוכן בין:
במצבים מסוימים, ייתכן אפילו צריך לשלב סוגים שונים של צומת, כגון תמצית תוכן בין פסקה לשדה, או בין ריצה וסימן ספר.
מאמר זה מספק את יישום הקוד עבור תמצית טקסט בין צמתים שונים, כמו גם דוגמאות של תרחישים נפוצים.
לעתים קרובות המטרה של תמצית התוכן היא לשכפל או להציל אותו בנפרד במסמך חדש. לדוגמה, אתה יכול להפיק תוכן ו:
ניתן להשיג זאת בקלות באמצעות Aspose.Words יישום הקוד למטה.
הקוד בסעיף זה מתייחס לכל המצבים האפשריים המתוארים לעיל עם שיטה אחת כללית וניתנת לזיהוי. קווי המתאר הכלליים של טכניקה זו כוללים:
1.1 1. איסוף הצמתים המכתיבים את תחום התוכן שיוציא מהמסמכים שלך. שחזור נקודות אלה מטופל על ידי המשתמש בקוד שלהם, בהתבסס על מה שהם רוצים להיות מופקים. 1.1 1. לעבור את הנקודות האלה אל ExtractContent השיטה סיפקה למטה. כמו כן, עליך לעבור פרמטר בולקטי שקובע אם נקודות אלה, הפועלות כסמן, יש לכלול במיצוי או לא. 1.1 1. החזרת רשימה של תוכן משובש (עמודים מאוישים) שצוין להיות מופק. אתה יכול להשתמש ברשימה זו של צמתים בכל דרך רלוונטית, למשל, יצירת מסמך חדש המכיל רק את התוכן שנבחר.
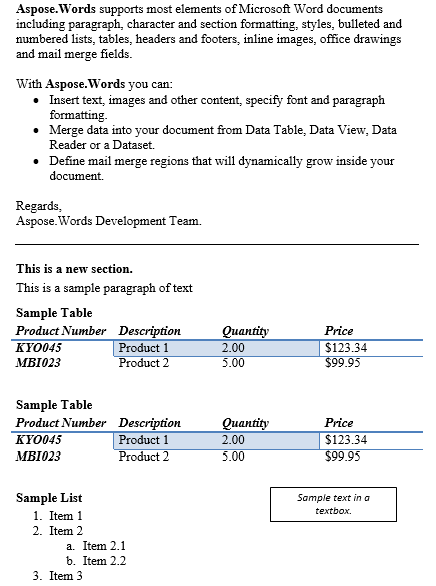
אנו נפעל עם המסמך למטה במאמר זה. כפי שאתה יכול לראות זה מכיל מגוון של תוכן. כמו כן, המסמך מכיל סעיף שני שמתחיל באמצע העמוד הראשון. הערה והערה מופיעים גם במסמך אך אינם גלויים בתצלום המסך למטה.

כדי להפיק את התוכן מהמסמכים שלך אתה צריך להתקשר ExtractContent שיטה למטה ולהעביר את הפרמטרים המתאימים.
הבסיס הבסיסי של שיטה זו כרוך במציאת בלוטות ברמת חסימת (סעיפים וטבלאות) ולהטיש אותם כדי ליצור עותקים זהים. אם צומת הסמן עבר הם ברמת בלוק, השיטה מסוגלת פשוט להעתיק את התוכן ברמה זו ולהוסיף אותו למערך.
עם זאת, אם הצמתים הם קו תחתון (ילד של פסקה) המצב הופך מורכב יותר, שכן יש צורך לפצל את פסקה בצומת קו, להיות זה ריצה, שדות סימן ספר וכו ‘. תוכן בבלוטות ההורות המשובחות אינו נוכח בין הסמן הוסר. תהליך זה משמש כדי להבטיח כי הצמתים באינטרנט עדיין ישמרו את התבנית של פסקת ההורים.
השיטה גם תרוץ בדיקות על הצמתים שעברו כפרמטרים וזרק יוצא מן הכלל אם הצומת אינו חוקי. הפרמטרים שיש לעבור בשיטה זו הם:
1.1 1. StartNode ו EndNode. שני הפרמטרים הראשונים הם המכשולים המגדירים איפה החילוץ של התוכן הוא להתחיל ולסיים בהתאמה. נקודות אלה יכולות להיות גם רמת בלוק (Paragraph , Table ) או רמת Inline (e.g Run , FieldStart , BookmarkStart וכו’): 1.לעבור שדה אתה צריך לעבור את המתאים FieldStart אובייקט 1.כדי להעביר הערות ספרים, BookmarkStart ו BookmarkEnd יש להעביר את הצמתים. 1.כדי להעביר הערות, CommentRangeStart ו CommentRangeEnd יש להשתמש במכשולים. 1.1 1. IsInclusive. Defines אם הסמן נכללים במיצוי או לא. אם אפשרות זו נקבעת false ואותה צומת או צמתים רצופים מועברים, ואז יוחזרו רשימה ריקה:
1 אם **FieldStart** הצומת מועבר אז אפשרות זו מגדירה אם כל השדה יש לכלול או לשלול.
1 אם **BookmarkStart** או **BookmarkEnd** Node מועבר, אפשרות זו מגדירה אם סימן הספר נכלל או רק את התוכן בין טווח הסימון.
1 אם **CommentRangeStart** או **CommentRangeEnd** Node מועבר, אפשרות זו מגדירה אם התגובה עצמה היא לכלול או רק את התוכן בטווח ההערה.
היישום של ExtractContent שיטה שאתה יכול למצוא כאן. שיטה זו תתייחס לתרחישים במאמר זה.
כמו כן, אנו מגדירים שיטה מותאמת ליצירת מסמך בקלות מנקודות מופקות. שיטה זו משמשת ברבים מהתרחישים הבאים ופשוט יוצרת מסמך חדש ומייבאת את התוכן המפלט אליו.
הדוגמה הבאה של הקוד מראה כיצד לקחת רשימה של צמתים ולהכניס אותם למסמך חדש:
זה מדגים כיצד להשתמש בשיטה לעיל כדי להפיק תוכן בין סעיפים ספציפיים. במקרה זה, אנו רוצים לחלץ את הגוף של המכתב שנמצא במחצית הראשונה של המסמך. אנחנו יכולים לומר שזה בין הסעיפים השביעית וה-11.
הקוד הבא מבצע משימה זו. הסעיפים המתאימים מופקים באמצעות getChild שיטה על המסמך ועברת כתבי אישום המפורטים. לאחר מכן אנו עוברים את הנקודות האלה אל ExtractContent שיטה ומדינה כי אלה יש לכלול במיצוי. שיטה זו תחזיר את התוכן המועתק בין נקודות אלה אשר מוכנסות לתוך מסמך חדש.
הדוגמה הבאה של הקוד מראה כיצד להפיק את התוכן בין סעיפים ספציפיים באמצעות הסעיף ExtractContent שיטה למעלה:
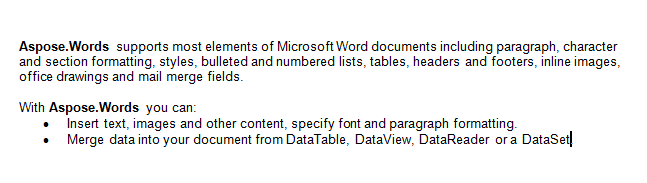
מסמך הפלט מכיל את שתי הסעיפים שהופקו.
אנו יכולים להפיק תוכן בין כל שילובים של צמתים ברמת בלוק או איליין. בתרחיש זה להלן נוציא את התוכן בין הסעיף הראשון לשולחן בחלק השני באופן בלעדי. אנחנו מקבלים את הסמן על ידי קריאה getFirstParagraph ו getChild שיטה על החלק השני של המסמך כדי לשחזר את המתאים Paragraph ו Table צומת עבור וריאציות קלות בואו לשכפל את התוכן ולהכניס אותו מתחת למקור.
הדוגמה הבאה של הקוד מראה כיצד להפיק את התוכן בין פסקה ושולחן באמצעות הסעיף ExtractContent שיטה:
התוכן בין הסעיף והשולחן משוכפל למטה הוא התוצאה.
ייתכן שיהיה עליך להפיק את התוכן בין פסקאות של אותו סגנון או שונה, כגון בין פסקאות המסומנים עם סגנונות כותרת.
הקוד הבא מראה כיצד להשיג זאת. זוהי דוגמה פשוטה שתוציא את התוכן בין הדוגמה הראשונה של סגנונות “Heading 1” ו-“Header 3” מבלי להוציא גם את הכותרות. כדי לעשות זאת, אנו מציבים את הפרמטר האחרון false, אשר מציין כי לא צריך לכלול את הסמן.
ביישום ראוי, זה צריך להיות מופעל בלולאה כדי לחלץ תוכן בין כל פסקאות של סגנונות אלה מן המסמך. התוכן מופק מועתק במסמך חדש.
הדוגמה הבאה של הקוד מראה כיצד להפיק תוכן בין פסקאות עם סגנונות ספציפיים באמצעות הפורמט ExtractContent שיטה:
להלן התוצאה של הפעולה הקודמת.

אתה יכול להפיק תוכן בין בלוטות אינטרנט כגון Run גם. Runs מסעיפים שונים ניתן לעבור כסמן. הקוד להלן מראה כיצד להפיק טקסט ספציפי בין אותו הדבר Paragraph צומת.
הדוגמה הבאה של הקוד מראה כיצד להפיק תוכן בין ריצות ספציפיות של אותה פסקה באמצעות אותה פסקה באמצעות הסעיף ExtractContent שיטה:
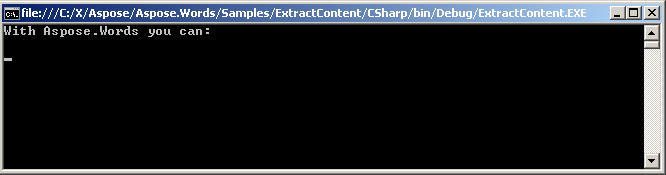
הטקסט מופק מוצג על הקונסולה
להשתמש בשדה כסמן, FieldStart צריך לעבור את הצומת. הפרמטר האחרון ל ExtractContent השיטה תגדיר אם כל השדה ייכלל או לא. בואו נוציא את התוכן בין שדה המיזוג המלא לפסקה במסמך. אנחנו משתמשים moveToMergeField שיטת DocumentBuilder מעמד. זה ישוב FieldStart משמו של שדה המיזוג עבר אליו.
במקרה שלנו, נגדיר את הפרמטר האחרון שעבר ExtractContent שיטה false להוציא את השדה מהמיצוי. אנו נעביר את התוכן המופץ ל- PDF.
הדוגמה הבאה של הקוד מראה כיצד להפיק תוכן בין שדה ספציפי לפסקה במסמך באמצעות השימוש בתוכן ExtractContent שיטה:
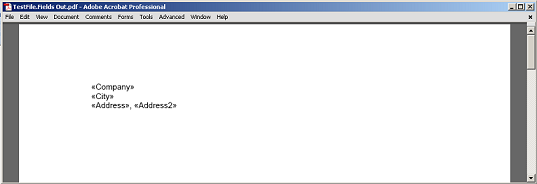
התוכן המוציא בין השדה לפסקה, ללא שדה וסימן פסקאות שניתנו ל- PDF.
במסמך, התוכן שמוגדר בתוך סימן ספר מוזנח על ידי BookmarkStart שם הספר: End nodes התוכן נמצא בין שני צמתים אלה מעלה את סימן הספר. אתה יכול לעבור את הצומתים האלה כמו כל סימן, אפילו אלה מסימנים שונים, כל עוד הסימן מתחיל מופיע לפני הסמן הסופי במסמך.
במסמך המדגם שלנו, יש לנו סימן אחד בשם “Bookmark1”. התוכן של הערה זו מודגש תוכן במסמך שלנו:
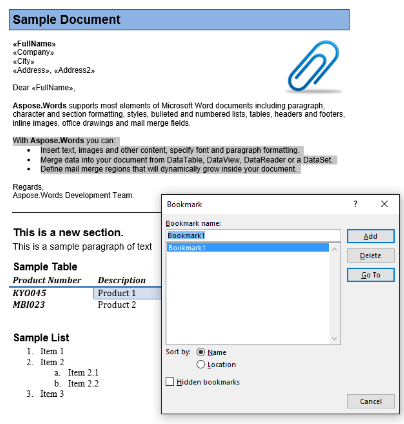
אנו נוציא את התוכן הזה במסמך חדש באמצעות הקוד להלן. The The The IsInclusive אפשרות פרמטר מראה כיצד לשמור או למחוק את סימן הספר.
הדוגמה הבאה של הקוד מראה כיצד לחלץ את התוכן המתייחס לסימן ספר באמצעות הסימן ExtractContent שיטה:
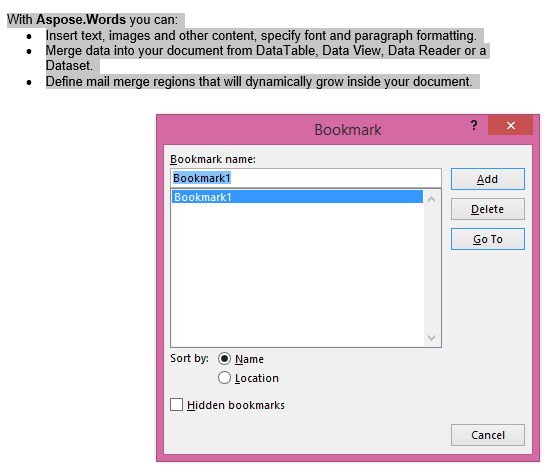
הפלט מופק עם IsInclusive פרמטר true. גם העותק ישמר את סימן הספר.
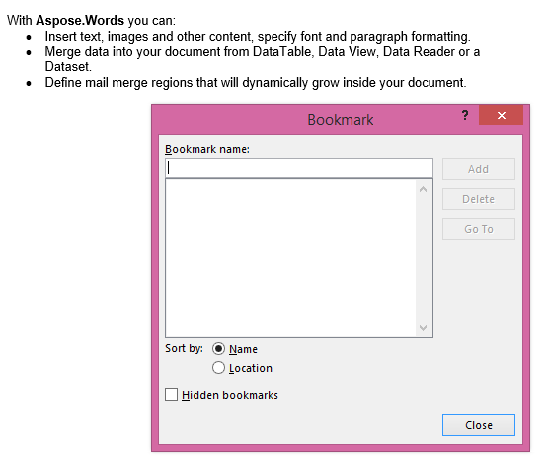
הפלט מופק עם IsInclusive פרמטר false. העותק מכיל את התוכן, אך ללא סימן הספר.
תגובה מורכבת מ- CommentRangeStart, CommentRange End and Comment nodes. כל הצומתים האלה הם פנימיים. שני הצומת הראשונים מבססים את התוכן במסמך אשר מתייחס על ידי ההערה, כפי שנראה בתמונה למטה.
The The The Comment צומת עצמו הוא InlineStory זה יכול להכיל פסקאות וריצה. זה מייצג את המסר של התגובה כפי שנראה כמו בועה תגובה במחבת הביקורת. מכיוון שצומת זה הוא קו פנימי וצאצא של גוף אתה יכול גם לחלץ את התוכן מבפנים הודעה זו.
במסמך שלנו יש תגובה אחת. בואו להציג את זה על ידי הצגת סימון בכרטיסיה:
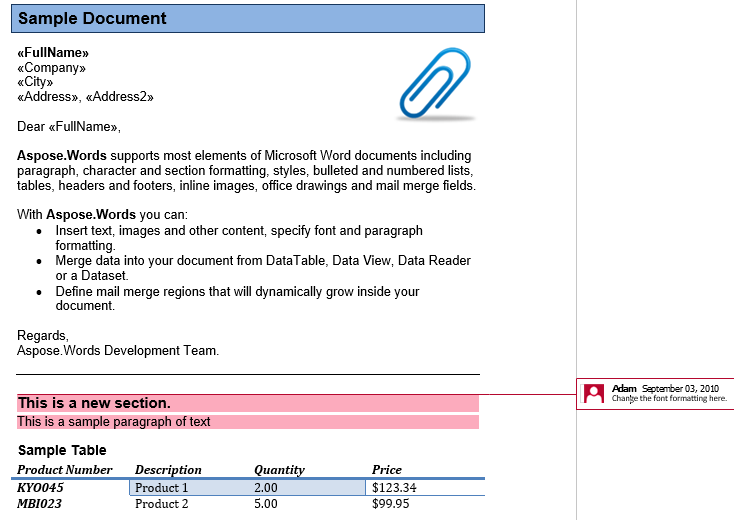
ההערה מעלה את הכותרת, הסעיף הראשון והשולחן בחלק השני. בואו נוציא את ההערה הזו למסמך חדש. The The The IsInclusive אפשרות תכתיב אם התגובה עצמה נשמרת או נמחקה.
דוגמה לקוד הבא מראה כיצד לעשות זאת היא למטה:
ראשית, הפלט המפלט עם IsInclusive פרמטר true. העותק יכלול גם את ההערה.
שנית, הפלט מופק עם כולל להגדיר false. העותק מכיל את התוכן אך ללא התגובה.

Aspose.Words ניתן להשתמש לא רק ליצירת Microsoft Word מסמכים על ידי בנייתם באופן דינמי או מיזוג תבניות עם נתונים, אבל גם עבור מסמכים כדי לחלץ אלמנטים מסמך נפרדים כגון ראשים, רגלים, פסקאות, טבלאות, תמונות ואחרים. משימה אפשרית נוספת היא למצוא את כל הטקסט של פורמט או סגנון ספציפי.
השתמש DocumentVisitor שיעור ליישום תרחיש שימוש זה. מחלקה זו תואמת את דפוס עיצוב המבקרים הידוע. עם DocumentVisitorאתה יכול להגדיר ולבצע פעולות מותאמות אישית הדורשות הארה על עץ המסמך.
DocumentVisitor מספק קבוצה VisitXXX שיטות אשר מופעלות כאשר רכיב מסמך מסוים (node) נתקל. לדוגמה, VisitParagraphStart נקרא כאשר תחילת פסקת טקסט נמצאת ו VisitParagraphEnd הוא נקרא כשסיומו של סעיף טקסט נמצא. כל אחד DocumentVisitor.VisitXXX השיטה מקבלת את האובייקט המתאים שהוא נתקל בו כך שתוכל להשתמש בו כנדרש (לדוגמא לאחזר את הפורמט), למשל. VisitParagraphStart ו VisitParagraphEnd קבל Paragraph אובייקט
כל אחד DocumentVisitor.VisitXXX שיטה מחזירה VisitorAction ערך השולט בהארה של צמתים. אתה יכול לבקש להמשיך את האמרה, לדלג על הצומת הנוכחי (אך להמשיך את האמרה), או לעצור את האמרה של צמתים.
אלה הם השלבים שאתה צריך לעקוב כדי לקבוע וליישם חלקים שונים של מסמך:
DocumentVisitor מספק יישום ברירת מחדל עבור כל DocumentVisitor.VisitXXX שיטות. זה הופך את זה קל יותר ליצור מבקרים חדשים מסמך רק את השיטות הנדרשות עבור מבקר מסוים צריך להיות overridden. אין צורך לעקוף את כל שיטות המבקרים.
הדוגמה הבאה מראה כיצד להשתמש בדפוס המבקרים כדי להוסיף פעולות חדשות Aspose.Words מודל אובייקט במקרה זה, אנו יוצרים מסמך פשוט להמיר לתבנית טקסט:
הדרכים להחזיר טקסט מן המסמך הן:
SaveFormat.Text פרמטר באופן פנימי, זה הופך את הטקסט לזרם זיכרון ומחזיר את המחרוזת וכתוצאה מכךNode.GetText ו Node.ToStringA A A מסמך Word יכול להכיל דמויות שליטה המתכנן אלמנטים מיוחדים כגון שדה, סוף התא, סוף סעיף וכו ‘. הרשימה המלאה של דמויות בקרת מילים אפשריות מוגדרת ב ControlChar מעמד. The The The GetText השיטה מחזירה טקסט עם כל דמויות הדמות השולטות הקיימות בצומת.
קריאה לString מחזירה את ייצוג הטקסט הפשוט של המסמך רק ללא דמויות שליטה. למידע נוסף על ייצוא כטקסט רגיל Using SaveFormat.Text.
הדוגמה הבאה מציגה את ההבדל בין קריאה GetText ו ToString שיטות על צומת:
SaveFormat.Textדוגמה זו מצילה את המסמך כדלקמן:
דוגמה לקוד הבא מראה כיצד לשמור מסמך בפורמט TXT:
ייתכן שתצטרך להפיק תמונות מסמך כדי לבצע משימות מסוימות. Aspose.Words מאפשר לך לעשות זאת גם.
לדוגמה הקוד הבא מראה כיצד להפיק תמונות ממסמכים:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.