Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
Quando si lavora con i documenti, è importante essere in grado di estrarre facilmente il contenuto da un intervallo specifico all’interno di un documento. Tuttavia, il contenuto può essere costituito da elementi complessi come paragrafi, tabelle, immagini, ecc.
Indipendentemente dal contenuto che deve essere estratto, il metodo per estrarre quel contenuto sarà sempre determinato da quali nodi sono selezionati per estrarre il contenuto tra. Questi possono essere interi corpi di testo o semplici esecuzioni di testo.
Ci sono molte situazioni possibili e quindi molti tipi di nodi diversi da considerare quando si estrae il contenuto. Ad esempio, è possibile estrarre il contenuto tra:
In alcune situazioni, potrebbe anche essere necessario combinare diversi tipi di nodo, ad esempio l’estrazione di contenuto tra un paragrafo e un campo o tra un’esecuzione e un segnalibro.
Questo articolo fornisce l’implementazione del codice per l’estrazione di testo tra diversi nodi, nonché esempi di scenari comuni.
Spesso l’obiettivo di estrarre il contenuto è duplicarlo o salvarlo separatamente in un nuovo documento. Ad esempio, è possibile estrarre il contenuto e:
Questo può essere facilmente ottenuto usando Aspose.Words e l’implementazione del codice qui sotto.
Il codice in questa sezione affronta tutte le possibili situazioni sopra descritte con un metodo generalizzato e riutilizzabile. Lo schema generale di questa tecnica comporta:
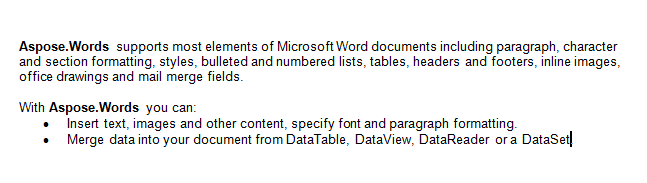
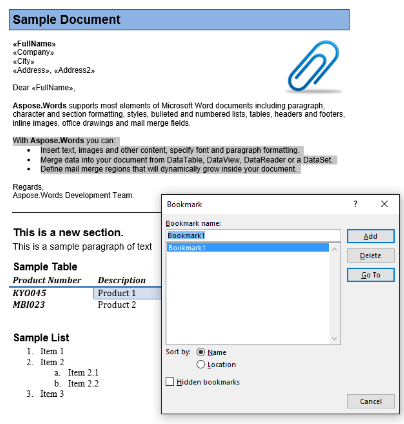
Lavoreremo con il documento qui sotto in questo articolo. Come puoi vedere contiene una varietà di contenuti. Si noti inoltre che il documento contiene una seconda sezione che inizia al centro della prima pagina. Un segnalibro e un commento sono presenti anche nel documento, ma non sono visibili nello screenshot qui sotto.

Per estrarre il contenuto dal documento è necessario chiamare il metodo ExtractContent di seguito e passare i parametri appropriati.
La base di questo metodo consiste nel trovare nodi a livello di blocco (paragrafi e tabelle) e clonarli per creare copie identiche. Se i nodi marker passati sono a livello di blocco, il metodo è in grado di copiare semplicemente il contenuto su quel livello e aggiungerlo all’array.
Tuttavia, se i nodi marker sono in linea (un figlio di un paragrafo), la situazione diventa più complessa, poiché è necessario dividere il paragrafo sul nodo in linea, sia esso una corsa, campi segnalibro ecc. Il contenuto nei nodi padre clonati non presenti tra i marcatori viene rimosso. Questo processo viene utilizzato per garantire che i nodi in linea conservino ancora la formattazione del paragrafo padre.
Il metodo eseguirà anche controlli sui nodi passati come parametri e genera un’eccezione se uno dei due nodi non è valido. I parametri da passare a questo metodo sono:
StartNode e EndNode. I primi due parametri sono i nodi che definiscono dove l’estrazione del contenuto deve iniziare e terminare rispettivamente. Questi nodi possono essere sia a livello di blocco (Paragraph, Table) che a livello in linea (ad es Run, FieldStart, BookmarkStart ecc.):
IsInclusive. Definisce se i marcatori sono inclusi nell’estrazione o meno. Se questa opzione è impostata su false e vengono passati lo stesso nodo o nodi consecutivi, verrà restituito un elenco vuoto:
L’implementazione del metodo ExtractContent è possibile trovare qui. Questo metodo verrà indicato negli scenari in questo articolo.
Definiremo anche un metodo personalizzato per generare facilmente un documento dai nodi estratti. Questo metodo viene utilizzato in molti degli scenari seguenti e crea semplicemente un nuovo documento e importa il contenuto estratto in esso.
Il seguente esempio di codice mostra come prendere un elenco di nodi e inserirli in un nuovo documento:
Questo dimostra come utilizzare il metodo sopra per estrarre il contenuto tra paragrafi specifici. In questo caso, vogliamo estrarre il corpo della lettera trovata nella prima metà del documento. Possiamo dire che questo è tra il 7 ° e 11 ° paragrafo.
Il codice sottostante esegue questa attività. I paragrafi appropriati vengono estratti utilizzando il metodo getChild sul documento e passando gli indici specificati. Passiamo quindi questi nodi al metodo ExtractContent e dichiariamo che questi devono essere inclusi nell’estrazione. Questo metodo restituirà il contenuto copiato tra questi nodi che vengono poi inseriti in un nuovo documento.
Il seguente esempio di codice mostra come estrarre il contenuto tra paragrafi specifici utilizzando il metodo ExtractContent sopra:
Il documento di output contiene i due paragrafi estratti.
Possiamo estrarre il contenuto tra qualsiasi combinazione di nodi a livello di blocco o in linea. In questo scenario di seguito estrarremo il contenuto tra il primo paragrafo e la tabella nella seconda sezione in modo inclusivo. Otteniamo i nodi marcatori chiamando il metodo getFirstParagraph e getChild nella seconda sezione del documento per recuperare i nodi Paragraph e Table appropriati. Per una leggera variazione cerchiamo invece di duplicare il contenuto e inserirlo sotto l’originale.
L’esempio di codice seguente mostra come estrarre il contenuto tra un paragrafo e una tabella utilizzando il metodo ExtractContent:
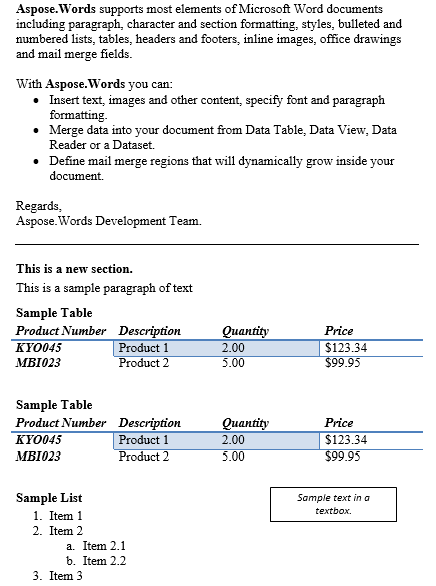
Il contenuto tra il paragrafo e la tabella è stato duplicato di seguito è il risultato.
Potrebbe essere necessario estrarre il contenuto tra paragrafi dello stesso stile o diverso, ad esempio tra paragrafi contrassegnati con stili di intestazione.
Il codice seguente mostra come raggiungere questo obiettivo. È un semplice esempio che estrarrà il contenuto tra la prima istanza degli stili" Heading 1 “e” Header 3 " senza estrarre anche le intestazioni. Per fare ciò impostiamo l’ultimo parametro su false, che specifica che i nodi marker non devono essere inclusi.
In una corretta implementazione, questo dovrebbe essere eseguito in un ciclo per estrarre il contenuto tra tutti i paragrafi di questi stili dal documento. Il contenuto estratto viene copiato in un nuovo documento.
L’esempio di codice seguente mostra come estrarre il contenuto tra paragrafi con stili specifici utilizzando il metodo ExtractContent:
Di seguito è riportato il risultato dell’operazione precedente.

È possibile estrarre il contenuto tra i nodi in linea come un Run pure. Runs da paragrafi diversi può essere passato come marcatori. Il codice seguente mostra come estrarre testo specifico tra lo stesso nodo Paragraph.
L’esempio di codice seguente mostra come estrarre il contenuto tra esecuzioni specifiche dello stesso paragrafo utilizzando il metodo ExtractContent:
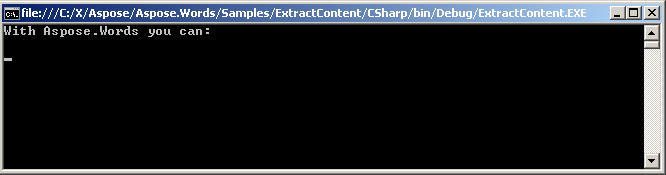
Il testo estratto viene visualizzato sulla console.
Per utilizzare un campo come marcatore, il nodo FieldStart deve essere passato. L’ultimo parametro del metodo ExtractContent definirà se l’intero campo deve essere incluso o meno. Estraiamo il contenuto tra il campo di unione “FullName " e un paragrafo nel documento. Usiamo il metodo moveToMergeField della classe DocumentBuilder. Questo restituirà il nodo FieldStart dal nome del campo di unione passato ad esso.
Nel nostro caso impostiamo l’ultimo parametro passato al metodo ExtractContent su false per escludere il campo dall’estrazione. Renderizzeremo il contenuto estratto a PDF.
L’esempio di codice seguente mostra come estrarre il contenuto tra un campo specifico e un paragrafo nel documento utilizzando il metodo ExtractContent:
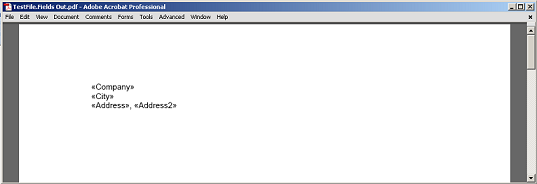
Il contenuto estratto tra il campo e il paragrafo, senza i nodi marcatore campo e paragrafo resi a PDF.
In un documento, il contenuto definito all’interno di un segnalibro viene incapsulato dai nodi BookmarkStart e BookmarkEnd. Il contenuto trovato tra questi due nodi costituisce il segnalibro. È possibile passare uno di questi nodi come qualsiasi marcatore, anche quelli provenienti da segnalibri diversi, purché il marcatore iniziale appaia prima del marcatore finale nel documento.
Nel nostro documento di esempio, abbiamo un segnalibro, chiamato “Bookmark1”. Il contenuto di questo segnalibro è evidenziato contenuto nel nostro documento:
Estrarremo questo contenuto in un nuovo documento utilizzando il codice sottostante. L’opzione del parametro IsInclusive mostra come conservare o eliminare il segnalibro.
L’esempio di codice seguente mostra come estrarre il contenuto a cui fa riferimento un segnalibro utilizzando il metodo ExtractContent:
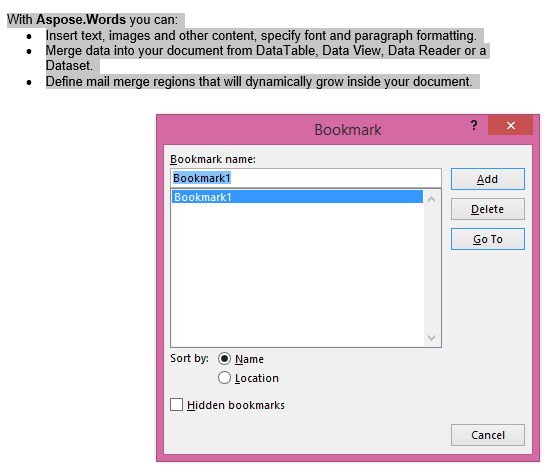
L’output estratto con il parametro IsInclusive impostato su true. La copia manterrà anche il segnalibro.
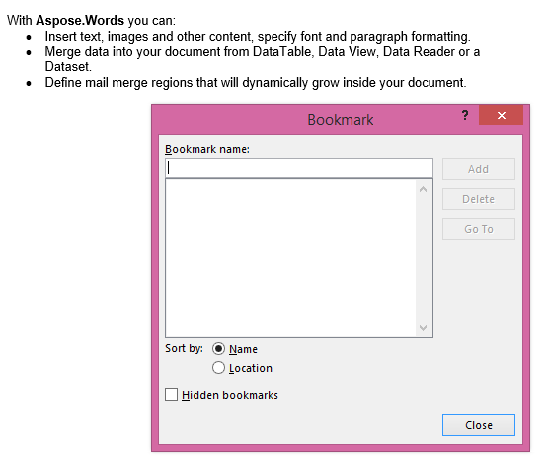
L’output estratto con il parametro IsInclusive impostato su false. La copia contiene il contenuto ma senza il segnalibro.
Un commento è costituito dai nodi CommentRangeStart, CommentRangeEnd e Comment. Tutti questi nodi sono in linea. I primi due nodi incapsulano il contenuto del documento a cui fa riferimento il commento, come si vede nello screenshot qui sotto.
Il nodo Comment stesso è un InlineStory che può contenere paragrafi ed esecuzioni. Rappresenta il messaggio del commento visto come una bolla di commento nel riquadro di revisione. Poiché questo nodo è in linea e un discendente di un corpo, puoi anche estrarre il contenuto dall’interno di questo messaggio.
Nel nostro documento abbiamo un commento. Mostriamolo mostrando il markup nella scheda Revisione:
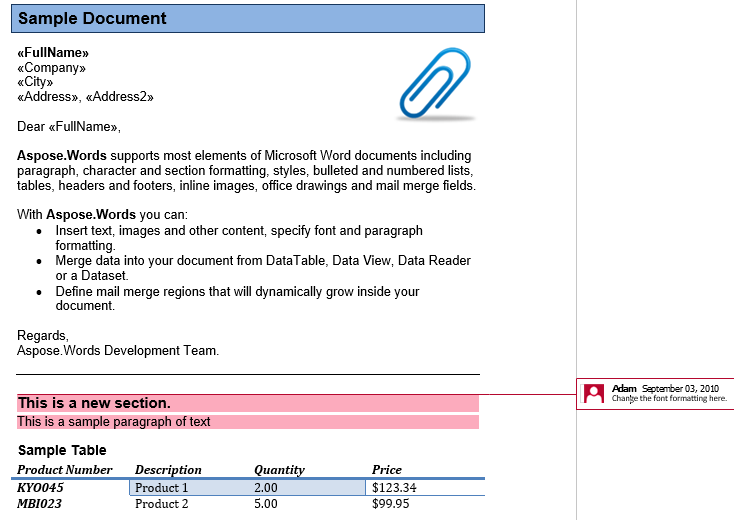
Il commento incapsula l’intestazione, il primo paragrafo e la tabella nella seconda sezione. Estraiamo questo commento in un nuovo documento. L’opzione IsInclusive determina se il commento stesso viene mantenuto o scartato.
Il seguente esempio di codice mostra come farlo è di seguito:
In primo luogo l’output estratto con il parametro IsInclusive impostato su true. La copia conterrà anche il commento.
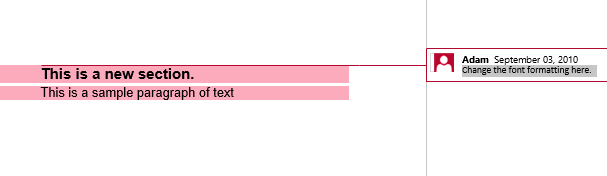
In secondo luogo l’output estratto con isInclusive impostato su false. La copia contiene il contenuto ma senza il commento.

Aspose.Words può essere utilizzato non solo per creare documenti Microsoft Word costruendoli dinamicamente o unendo modelli con dati, ma anche per analizzare documenti al fine di estrarre elementi di documento separati come intestazioni, piè di pagina, paragrafi, tabelle, immagini e altri. Un altro compito possibile è trovare tutto il testo di formattazione o stile specifico.
Utilizzare la classe DocumentVisitor per implementare questo scenario di utilizzo. Questa classe corrisponde al ben noto modello di progettazione dei visitatori. Con DocumentVisitor, è possibile definire ed eseguire operazioni personalizzate che richiedono l’enumerazione sull’albero dei documenti.
DocumentVisitor fornisce un insieme di metodi VisitXXX che vengono richiamati quando viene rilevato un particolare elemento del documento (nodo). Ad esempio, VisitParagraphStart viene chiamato quando viene trovato l’inizio di un paragrafo di testo e VisitParagraphEnd viene chiamato quando viene trovata la fine di un paragrafo di testo. Ogni metodo DocumentVisitor.VisitXXX accetta l’oggetto corrispondente che incontra in modo da poterlo utilizzare secondo necessità (ad esempio recuperare la formattazione), ad esempio sia VisitParagraphStart che VisitParagraphEnd accettano un oggetto Paragraph.
Ogni metodo DocumentVisitor.VisitXXX restituisce un valore VisitorAction che controlla l’enumerazione dei nodi. È possibile richiedere di continuare l’enumerazione, saltare il nodo corrente (ma continuare l’enumerazione) o interrompere l’enumerazione dei nodi.
Questi sono i passaggi da seguire per determinare ed estrarre a livello di codice varie parti di un documento:
DocumentVisitor fornisce implementazioni predefinite per tutti i metodi DocumentVisitor.VisitXXX. Ciò semplifica la creazione di nuovi visitatori di documenti in quanto è necessario sovrascrivere solo i metodi richiesti per il particolare visitatore. Non è necessario sovrascrivere tutti i metodi del visitatore.
Nell’esempio seguente viene illustrato come utilizzare il modello Visitatore per aggiungere nuove operazioni al modello a oggetti Aspose.Words. In questo caso, creiamo un semplice convertitore di documenti in un formato di testo:
I modi per recuperare il testo dal documento sono:
SaveFormat.Text. Internamente, questo richiama salva come testo in un flusso di memoria e restituisce la stringa risultanteNode.GetTexte Node.ToStringUn documento di Word può contenere caratteri di controllo che designano elementi speciali come campo, fine della cella, fine della sezione, ecc. L’elenco completo dei possibili caratteri di controllo delle parole è definito nella classe ControlChar. Il metodo GetText restituisce il testo con tutti i caratteri del carattere di controllo presenti nel nodo.
La chiamata a ToString restituisce la rappresentazione in testo normale del documento solo senza caratteri di controllo. Per ulteriori informazioni sull’esportazione come testo normale, vedere Using SaveFormat.Text.
Il seguente esempio di codice mostra la differenza tra la chiamata dei metodi GetText e ToString su un nodo:
SaveFormat.TextQuesto esempio salva il documento come segue:
Il seguente esempio di codice mostra come salvare un documento in formato TXT:
Potrebbe essere necessario estrarre le immagini del documento per eseguire alcune attività. Aspose.Words ti permette di fare anche questo.
Il seguente esempio di codice mostra come estrarre immagini da un documento:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.