Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
Aspose.Wordsドキュメントオブジェクトモデル(DOM)は、Word文書のメモリ内表現です。 Aspose.WordsDOMを使用すると、プログラムでWord文書の内容と書式を読み取り、操作、および変更できます。
このセクションでは、Aspose.WordsDOMの主なクラスとその関係について説明します。 Aspose.WordsDOMクラスを使用すると、文書要素と書式設定へのプログラムによるアクセスを取得できます。
文書がAspose.WordsDOMに読み込まれると、オブジェクトツリーが構築され、ソース文書の異なるタイプの要素には、さまざまなプロパティを持つ独自のDOMtreeオブジェク
Aspose.WordsがWord文書をメモリに読み込むと、さまざまな文書要素を表すさまざまな型のオブジェクトが作成されます。 テキスト、段落、表、またはセクションのすべての実行はノードであり、ドキュメント自体もノードです。 Aspose.Wordsは、すべてのドキュメントノード型のクラスを定義します。
Aspose.Wordsのドキュメントツリーは、複合デザインパターンに従います:
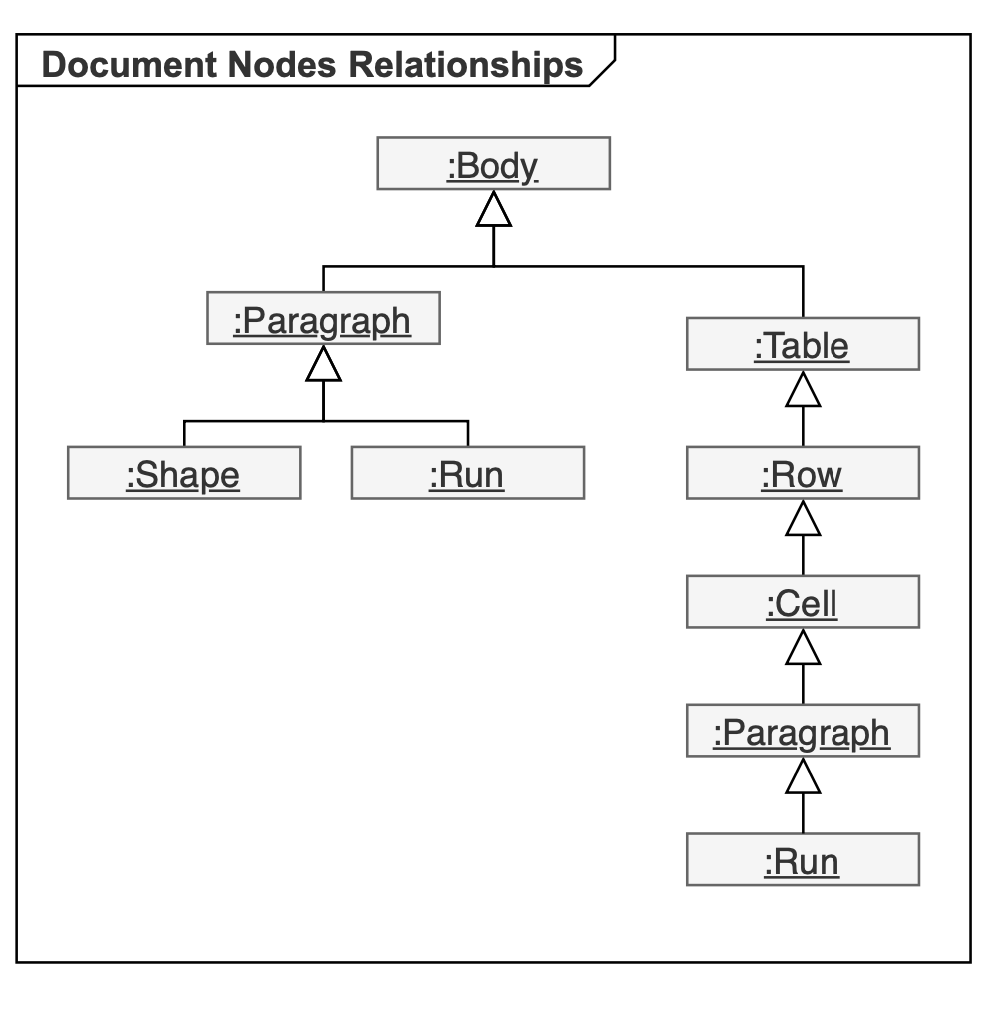
下の図は、Aspose.Wordsドキュメントオブジェクトモデル(DOM)のノードクラス間の継承を示しています。 抽象クラスの名前は斜体で表示されます。
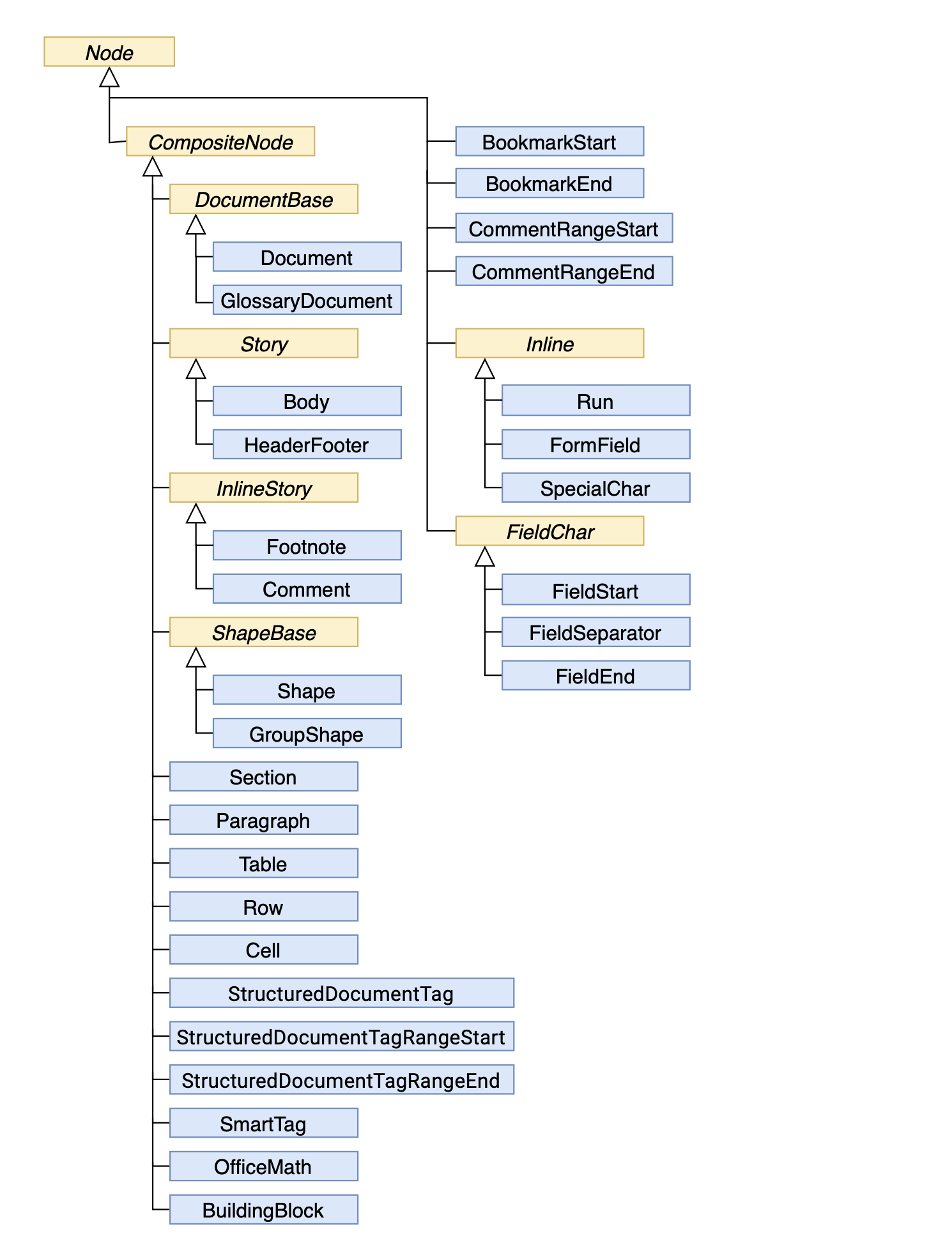
Nodeクラスから継承されていないため、この図には示されていません。
例を見てみましょう。 次の画像は、さまざまな種類のコンテンツを含むMicrosoft Wordドキュメントを示しています。
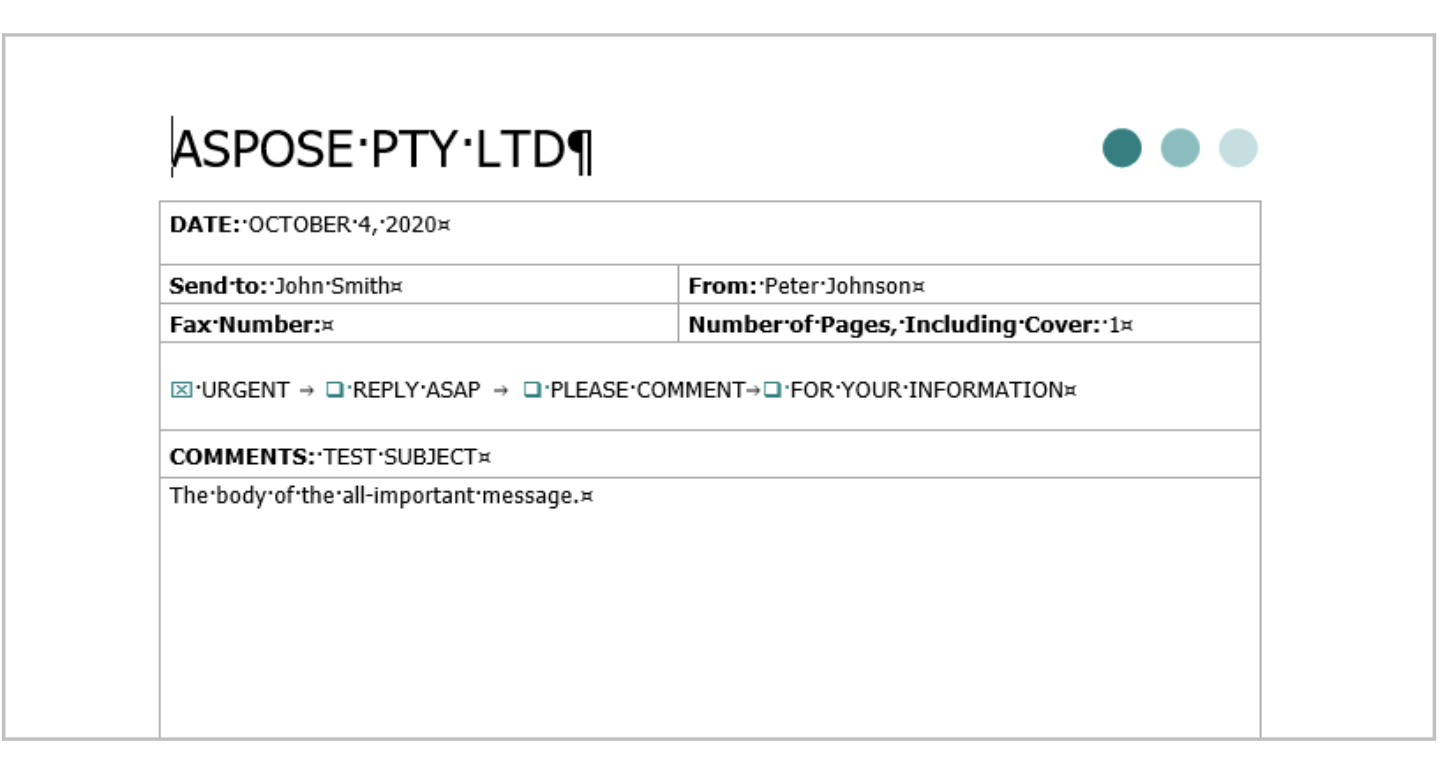
上記の文書をAspose.WordsDOMに読み込むと、以下のスキーマに示すように、オブジェクトのツリーが作成されます。
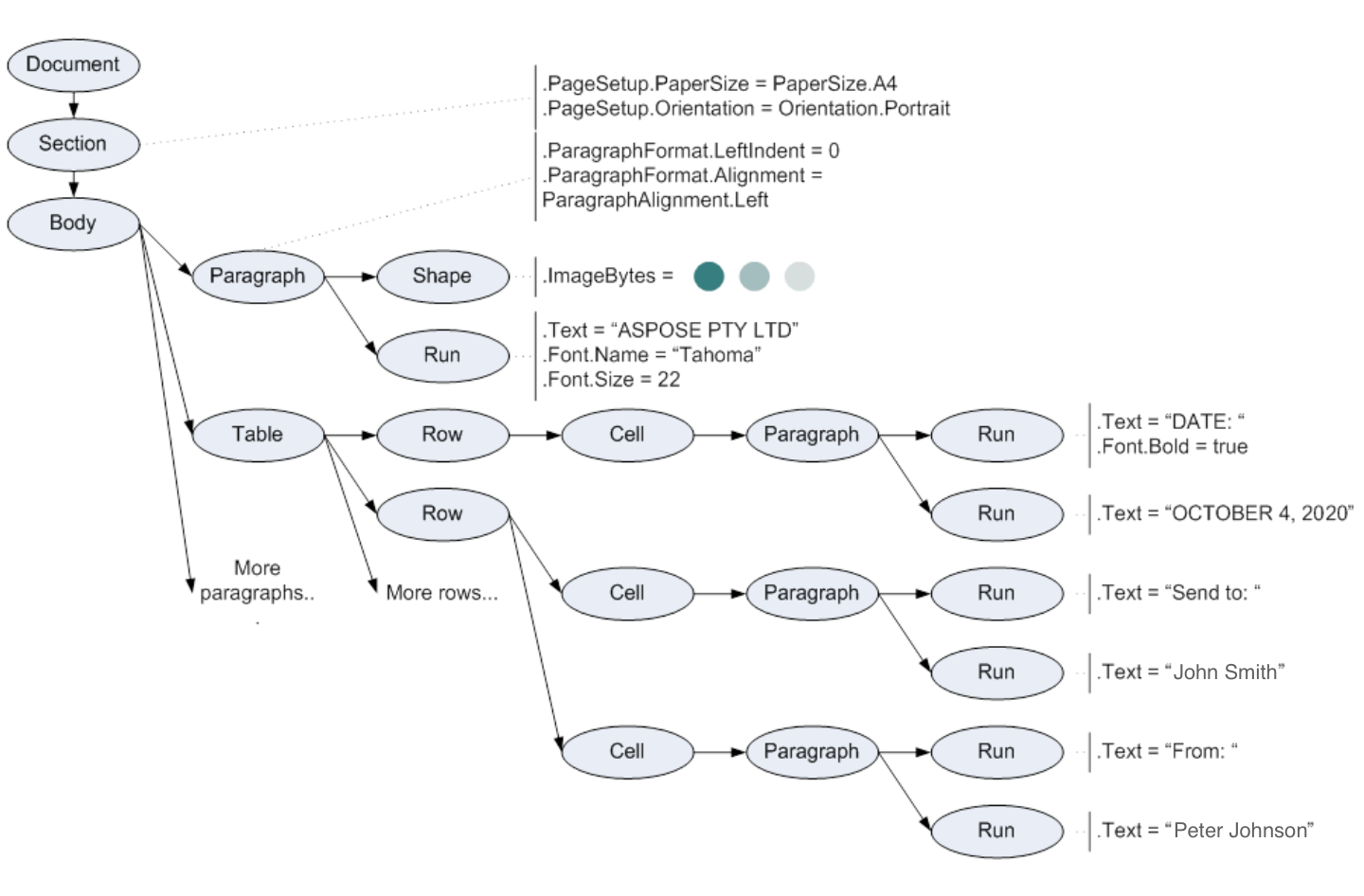
Document, Section, Paragraph, Table, Shape, Run, また、図上の他のすべての楕円は、Word文書の要素を表すAspose.Wordsオブジェクトです。
Nodeタイプ {#get-a-node-type}を取得しますNodeクラスは異なるノードを区別するのに十分ですが、Aspose.Wordsは特定のタイプのノードの選択など、いくつかのAPIタスクを簡素化するためにNodeType列挙を提供します。
各ノードのタイプは、NodeTypeプロパティを使用して取得できます。 このプロパティはNodeType列挙値を返します。 たとえば、Paragraphクラスで表される段落ノードはNodeType.Paragraphを返し、Tableクラスで表されるテーブルノードはNodeType.Tableを返します。
次の例は、NodeType列挙体を使用してノード型を取得する方法を示しています:
Aspose.Wordsはドキュメントをノードツリーとして表し、ノード間を移動できます。 このセクションでは、Aspose.Words内のドキュメントツリーを探索してナビゲートする方法について説明します。
前に示したサンプルドキュメントをドキュメントエクスプローラーで開くと、ノードツリーはAspose.Wordsで表されているとおりに表示されます。
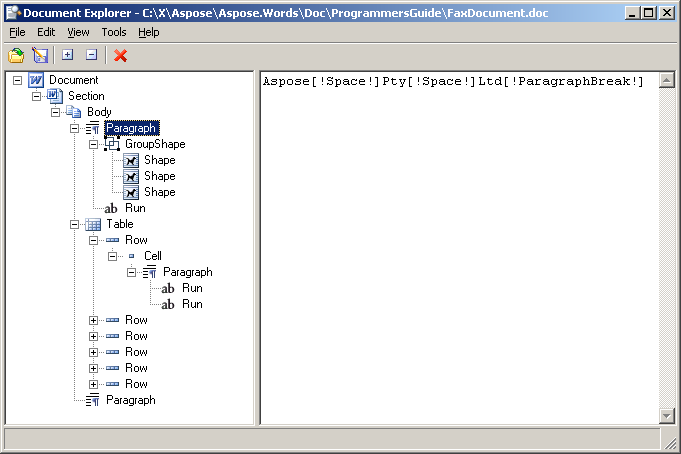
ツリー内のノードは、それらの間の関係を持っています:
他のノードを含むことができるノードはCompositeNodeクラスから派生し、すべてのノードは最終的にNodeクラスから派生します。 これらの2つの基本クラスは、ツリー構造のナビゲーションと変更のための一般的なメソッドとプロパティを提供します。
次のUMLオブジェクト図は、サンプルドキュメントのいくつかのノードと、parent、child、およびsiblingプロパティを介した相互の関係を示しています:
スタイルやリストなどの重要な文書全体の構造がDocumentノードに格納されるため、ノードはツリーから作成または削除されたばかりであっても、常に特定のドキ たとえば、各段落にはドキュメントに対してグローバルに定義されたスタイルが割り当てられているため、DocumentなしでParagraphを持つことはできません。 このルールは、新しいノードを作成するときに使用されます。 新しいParagraphをDOMに直接追加するには、コンストラクタに渡されるdocumentオブジェクトが必要です。
DocumentBuilderを使用して新しい段落を作成する場合、ビルダーには常にDocumentBuilder.Documentプロパティを介してリンクされたDocumentクラスがあります。
次のコード例は、ノードを作成するときに、そのノードを所有するドキュメントが常に定義されることを示しています:
各ノードにはParentNodeプロパティで指定された親があります。 次の場合、ノードには親ノードがありません。ParentNodeはnullです。:
ノードを親から削除するには、Removeメソッドを呼び出します。次のコード例は、親ノードにアクセスする方法を示しています:
CompositeNodeの子ノードにアクセスする最も効率的な方法は、それぞれ最初と最後の子ノードを返すFirstChildプロパティとLastChildプロパティを使用することです。CompositeNodeの子ノードにアクセスする最も効率的な方法は、FirstChildプロパティとLastChildプロパティを使用することです。 子ノードがない場合、これらのプロパティはnullを返します。
CompositeNode
ノードに子がない場合、ChildNodesプロパティは空のコレクションを返します。 HasChildNodesプロパティを使用して、CompositeNodeに子ノードが含まれているかどうかを確認できます。
次のコード例は、ChildNodesコレクションによって提供される列挙子を使用して、CompositeNodeの直接の子ノードを列挙する方法を示しています:
次のコード例は、インデックス付きアクセスを使用してCompositeNodeの直接の子ノードを列挙する方法を示しています:
それぞれPreviousSiblingプロパティとNextSiblingプロパティを使用して、特定のノードの直前または後続のノードを取得できます。 ノードがその親の最後の子である場合、NextSiblingプロパティはnullです。 逆に、ノードがその親の最初の子である場合、PreviousSiblingプロパティはnullです。
次のコード例は、複合ノードのすべての直接および間接の子ノードを効率的に訪問する方法を示しています:
これまでは、基本型の1つであるNodeまたはCompositeNodeを返すプロパティについて説明しました。 ただし、RunやParagraphなどの特定のノードクラスに値をキャストする必要がある場合があります。 つまり、合成であるAspose.WordsDOMで作業するときは、キャストから完全に逃げることはできません。
キャストの必要性を減らすために、ほとんどのAspose.Wordsクラスは厳密に型指定されたアクセスを提供するプロパティとコレクションを提供します。 型指定されたアクセスには3つの基本的なパターンがあります:
型指定されたプロパティは、Node.ParentNodeとCompositeNode.FirstChildから継承された汎用プロパティよりも簡単にアクセスできる便利なショートカットにすぎません。
次のコード例は、型指定されたプロパティを使用してドキュメントツリーのノードにアクセスする方法を示しています:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.