Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
При роботі з документами важливо легко витягти вміст з певного діапазону в документі. Однак зміст може складатися з складних елементів, таких як абзаци, таблиці, зображення тощо.
Незалежно від того, який вміст повинен бути вилучений, метод вилучення, який вміст завжди буде визначатися, за допомогою яких вузлів вибираються для отримання вмісту між. Це можуть бути всі текстові органи або прості текстові рядки.
Існує безліч можливих ситуацій і тому багато різних типів вузлів для розгляду при вилучення вмісту. Наприклад, ви можете вилучити вміст:
У деяких ситуаціях, можливо, навіть потрібно об’єднати різні типи вузлів, такі як вилучення вмісту між абзацу і поле, або між забігом і закладкою.
Дана стаття забезпечує виконання коду для вилучення тексту між різними вузлами, а також прикладами поширених сценаріїв.
Часто мета вилучення змісту полягає в тому, щоб дублювати або зберегти його окремо в новому документі. Наприклад, ви можете отримати вміст і:
Це може бути легко досягнуто за допомогою Aspose.Words і виконання коду нижче.
Введіть номер мобільного, який Ви вказали при укладаннi договору з банком - для ідентифікації. Загальний контур цієї техніки передбачає:
1,1 км Зберігаючи вершини, які диктують область змісту, який буде вилучений з вашого документа. Зняття цих вузлів здійснюється Користувачем у своєму коді, на основі чого вони хочуть бути вилучені. 1,1 км Передача цих вузлів до ExtractContent метод, передбачений нижче. Ви також повинні пройти boolean параметр, який стверджує, чи є ці вершини, діють як маркери, повинні бути включені до видобутку або ні. 1,1 км Відновлення списку клонованого вмісту (копійованих вузлів), зазначених для вилучення. Ви можете використовувати цей список вузлів в будь-який зручний спосіб, наприклад, створення нового документа, що містить тільки обраний вміст.
Ми будемо працювати з документом нижче в цій статті. Як ви можете побачити його в різних форматах. Також зауважити, що документ містить другий розділ, що починається в середині першої сторінки. Закладка і коментар також присутні в документі, але не видно на скріншоті нижче.

Щоб витягти вміст з вашого документа, потрібно викликати ExtractContent метод нижче і пропускають відповідні параметри.
Основою даного методу передбачається знаходження вузлів блочного рівня (паграфів і столів) і клонування їх створювати ідентичні копії. Якщо передані маркерні вузли блокуються, то метод здатний просто копіювати вміст на цьому рівні і додати його в масив.
Тим не менш, якщо маркерні вузли знаходяться в лінії (на дитину абзацу), то ситуація стає більш складною, так як необхідно розбити абзацу в інлайн-вузлі, бути її забігом, закладками тощо. Контент у клонованих материнських вузлах не присутній між маркерами. Цей процес використовується для того, щоб вбудовані вузли ще зберігали форматування батьківського абзацу.
Метод також буде виконувати перевірки на вузлах, що пропускаються як параметри і кидає виключення, якщо або вузол недійсний. Параметри, які будуть передані в цей метод:
1,1 км StartNode і EndNodeй Першими двома параметрами є вершини, які визначають, де вилучення змісту є починати і закінчуватися відповідно. Ці вершини можуть бути як рівні блоків (Paragraph й Table ) або рівень inline (наприклад, Run й FieldStart й BookmarkStart т.д.):
Щоб передати поле, необхідно пройти відповідне FieldStart об’єкт.
Пропустити закладки, BookmarkStart і BookmarkEnd вузли повинні бути передані.
Пропустити коментарі, CommentRangeStart і CommentRangeEnd повинні бути використані вузли. 1,1 км IsInclusiveй Захищаючи, якщо маркери включені в видобуток або ні. Якщо цей варіант встановлюється false і ті ж вершини або послідовні вузли пропускаються, після чого буде повернеться порожній список:
Реалізація реалізації ExtractContent метод можна знайти Головнай Цей метод буде зазначений у сценаріїв цієї статті.
Ми також визначаємо користувальницький метод, щоб легко створити документ з вилучених вузлів. Цей метод використовується в багатьох сценаріях нижче і просто створює новий документ і імпорт вилучення вмісту в нього.
Приклад коду показує, як взяти список вузлів і вставити їх в новий документ:
Це показує, як використовувати метод вище для отримання вмісту між певними абзацами. У цьому випадку ми хочемо витягти тіло листа, знайденого в першій половині документа. Ми можемо сказати, що це між 7 і 11 абзацами.
Код нижче виконує це завдання. Вилучення відповідних абзаців з використанням getChild метод на документі і проходження зазначених показників. Потім ми проводимо ці вузли до ExtractContent метод і стан, які вони повинні бути включені до видобутку. Цей метод буде повернений вміст між цими вузлами, які потім вставляються в новий документ.
Приклад коду показує, як витягти вміст між певними абзацами за допомогою ExtractContent метод вище:
Вихідний документ містить два пункти, які були вилучені.
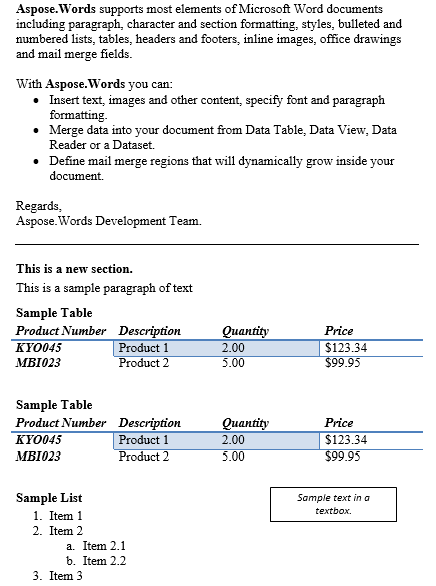
Ми можемо вилучити вміст між будь-якими комбінаціями блочних або внутрішніх вузлів. У цьому сценарії нижче ми виберемо вміст між першим абзацом та столиком у другому розділі включно. Ми отримуємо вузли маркерів за допомогою виклику getFirstParagraph і getChild метод на другий розділ документа для отримання відповідного Paragraph і Table вершини. Для легкої варіації, замість того, щоб дублювати вміст і вставити його нижче оригіналу.
Приклад наступного коду показує, як витягти вміст між абзацом та столиком за допомогою пункту ExtractContent метод:
Зміст абзацу та таблиці було дубліковано нижче.
Ви можете вилучити вміст між абзацами одного або іншого стилю, таких як між абзацами, позначеними стилями.
Код нижче показує, як досягти цього. Це простий приклад, який видобуває вміст між першою інстанцією стилів “Heading 1” та “Header 3” без вилучення заголовків. Для цього ми встановлюємо останній параметр до false, який визначає, що вузли маркера не повинні бути включені.
У правильному виконанні слід виконувати в петлі для вилучення вмісту між усіма пунктами цих стилів з документа. Вилучений вміст копіюється в новий документ.
Приклад коду показує, як витягувати вміст між абзацами з певними стилями за допомогою ExtractContent метод:
Нижче наведено результат попередньої операції.

Ви можете витягувати вміст між вузлами, такими як Run й Runs з різних абзаців можна пропустити як маркери. Введіть номер мобільного, який Ви вказали при укладаннi договору з банком - для ідентифікації. Paragraph вузол.
Приклад наступного коду показує, як витягувати вміст між певними проходами одного абзацу за допомогою ExtractContent метод:
Витягований текст відображається на консолі
Щоб використовувати поле як маркер, FieldStart повинна бути передана вершина. Останній параметр до останнього параметра ExtractContent спосіб визначити, якщо вся поле буде включена або ні. Додайте вміст між полеми злиття “Повний ім’я” та пунктом у документі. Ми використовуємо moveToMergeField метод DocumentBuilder клас. Це буде повернено FieldStart вершина з назви поля зливається до неї.
У нашому випадку ми встановимо останній параметр, переданий до ExtractContent метод до false виключити поле з видобутку. Ми проведемо вилучення вмісту в PDF.
Приклад наступного коду показує, як витягувати вміст між певним полем та абзацом у документі з використанням ExtractContent метод:
Вилучений вміст поля та абзацу, без поля та абзаців, що надходять у PDF.
У документі зміст, який визначається в межах закладки, інкапсульований BookmarkStart і BookmarkEnd вершини. Зміст, знайдений між цими двома вузлами, складають закладку. Ви можете пройти або з цих вузлів як будь-який маркер, навіть з різних зауважень, до тих пір, поки початковий маркер з’являється до закінчення маркеру в документі.
У нашому документі про зразок ми маємо одну замітку, названу “Bookmark1”. Зміст цієї закладки виділяється вмістом в нашому документі:
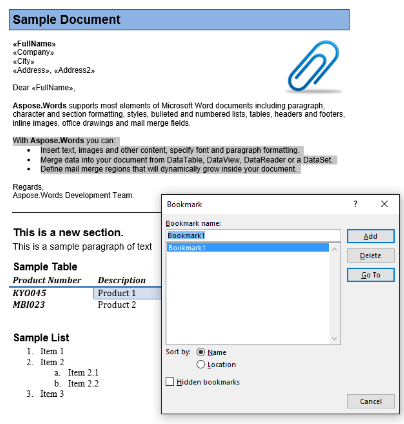
Ми витягуємо цей вміст у новий документ, використовуючи код нижче. Про нас IsInclusive параметр показує, як зберігати або відкинути закладку.
Наприклад, наступний код показує, як витягти вміст, довідкований закладок за допомогою закладки ExtractContent метод:
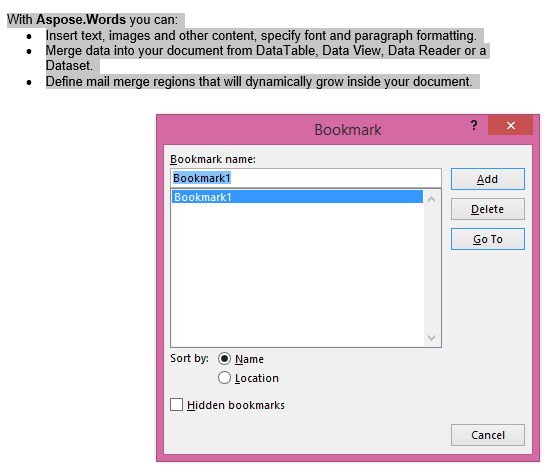
Витяжний вихід з IsInclusive параметр встановити до trueй Копія зберігає закладку.
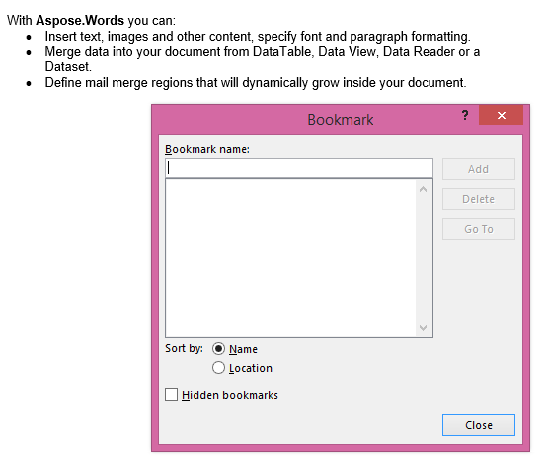
Витяжний вихід з IsInclusive параметр встановити до falseй Копія містить вміст, але без закладки.
Коментарі до The CommentRangeStart Всі ці вершини знаходяться в режимі онлайн. Перші два вузли захоплюють вміст у документі, який посилається коментарем, як показано на скріншоті нижче.
Про нас Comment сама вершина - InlineStory що може містити абзаци та прогони. Це повідомлення про коментар, як видно як коментар бульбашки в оглядовому каструлі. Як це вершина інлайн і спадкоємець тіла ви також можете витягти вміст зсередини цього повідомлення.
У нашому документі ми маємо один коментар. Відобразити його, показувати розмітку в вкладці Огляд:
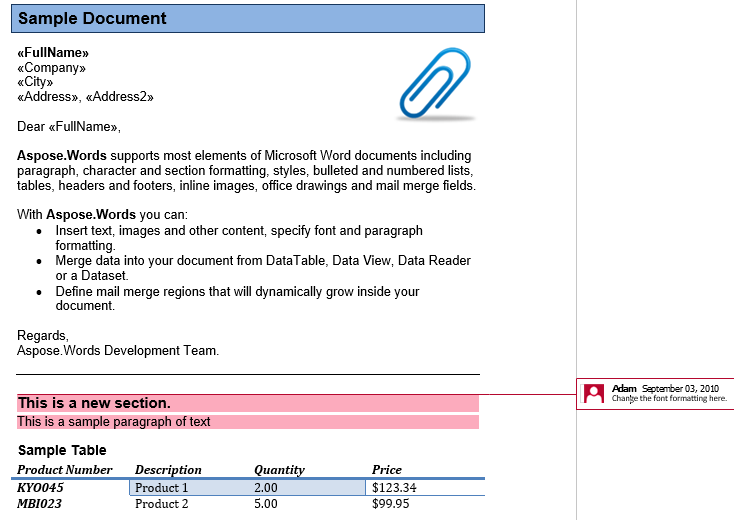
Прокоментуйте заголовок, першу абзацу та таблицю у другому розділі. Додайте цей коментар у новий документ. Про нас IsInclusive варіант диктує, якщо сам коментар зберігається або відхилений.
Приклад наступного коду показує, як це зробити нижче:
По-перше витяжний вихід з IsInclusive параметр встановити до trueй Копія буде містити коментаря.
По-друге витяжний вихід з Інклюзив Увійти falseй Копія містить зміст, але без коментаря.

Aspose.Words можна використовувати не тільки для створення Microsoft Word документи шляхом побудови їх динамічно або зважування шаблонів з даними, але також для оформлення документів для того, щоб витягти окремі елементи документа, такі як заголовки, піддони, абзаци, таблиці, зображення та інші. Ще одним можливим завданням є пошук певного формату або стилю.
Використання DocumentVisitor Клас реалізації цього сценарію використання. Цей клас відповідає відомим візерункам відвідувачів. З DocumentVisitor, ви можете визначити та виконувати користувацькі операції, які вимагають заохочення над деревом документа.
DocumentVisitor забезпечує набір VisitXXX методи, які заподіяні при виникненні певного елемента документа (невід) Наприклад, VisitParagraphStart називається, коли початок знайденого текстового пункту і VisitParagraphEnd називається, коли знайдений кінець тексту. Що DocumentVisitor.VisitXXX метод приймає відповідний об’єкт, який він зустрічається так, що ви можете використовувати його, як це потрібно (прочитати форматування), наприклад, обидва VisitParagraphStart і VisitParagraphEnd Приймати Paragraph об’єкт.
Що DocumentVisitor.VisitXXX метод повертає VisitorAction значення, яка контролює занурення вузлів. Ви можете запитати або продовжити занурення, пропустити поточний вузол (але продовжити занурення), або зупинити занурення вузлів.
Це кроки, які слідувати за програмамично визначити та витягувати різні частини документа:
DocumentVisitor забезпечує виконання за замовчуванням для всіх DocumentVisitor.VisitXXX методи. Це полегшує створення нових відвідувачів документа, як тільки методи, необхідні для конкретного відвідувача, повинні бути перевантажені. Не варто перевизначити всі методи відвідувачів.
Наступний приклад показує, як використовувати шаблон Відвідувача, щоб додати нові операції до Aspose.Words модель об’єкта. У цьому випадку ми створюємо простий конвертер документів у текстовий формат:
Способи отримання тексту з документа:
SaveFormat.Text параметр. Внутрішня, це викликає збереження тексту в потік пам’яті і повертає отриманий рядокNode.GetText і Node.ToStringР Документ Word може містити символи керування, які позначення спеціальних елементів, таких як поле, кінець комірки, кінець розділу тощо. Повний список можливих символів керування Word визначено в ControlChar клас. Про нас GetText метод повертає текст з усіма символами керування, присутніми в вершині.
Зателефонувавши до того, щоб повернути звичайний текстовий лист документа тільки без символів управління. Для отримання додаткової інформації про експорт як звичайний текст див. Using SaveFormat.Textй
Приклад коду показує різницю між викликом GetText і ToString методи на вершині:
SaveFormat.TextЦей приклад зберігає документ наступним чином:
Приклад наступного коду показує, як зберегти документ у форматі TXT:
Ви можете вилучити зображення документів для виконання завдань. Aspose.Words Ви також можете зробити це.
Приклад коду показує, як витягти зображення з документа:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.