Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
在处理文档时,能够轻松地从文档中的特定范围提取内容非常重要。 然而,内容可以由诸如段落、表格、图像等的复杂元素组成。
无论需要提取什么内容,提取该内容的方法将始终由选择在哪些节点之间提取内容来确定。 这些可以是整个文本正文或简单的文本运行。
有许多可能的情况,因此在提取内容时要考虑许多不同的节点类型。 例如,您可能希望在:
在某些情况下,您甚至可能需要组合不同的节点类型,例如在段落和字段之间或在运行和书签之间提取内容。
本文提供了在不同节点之间提取文本的代码实现,以及常见场景的示例。
通常,提取内容的目标是将其复制或单独保存在新文档中。 例如,您可以提取内容和:
这可以使用Aspose.Words和下面的代码实现轻松实现。
本节中的代码使用一个通用和可重用的方法解决了上述所有可能的情况。 该技术的总纲涉及:
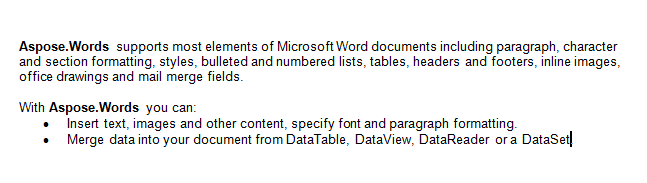
我们将在本文中使用下面的文档。 正如你所看到的,它包含了各种各样的内容。 另请注意,该文档包含从第一页中间开始的第二部分。 书签和注释也存在于文档中,但在下面的屏幕截图中不可见。

要从文档中提取内容,您需要调用下面的ExtractContent方法并传递适当的参数。
该方法的基础涉及查找块级节点(段落和表)并克隆它们以创建相同的副本。 如果传递的标记节点是块级的,那么该方法能够简单地复制该级别上的内容并将其添加到数组中。
但是,如果标记节点是内联的(段落的子节点),那么情况就会变得更加复杂,因为有必要在内联节点分割段落,无论是运行,书签字段等。 标记之间不存在的克隆父节点中的内容将被删除。 此过程用于确保内联节点仍保留父段落的格式。
该方法还将对作为参数传递的节点运行检查,并在任一节点无效时引发异常。 要传递给此方法的参数是:
StartNode和EndNode。 前两个参数是分别定义内容提取开始和结束的节点。 这些节点可以是块级别(Paragraph,Table)或内联级别(例如Run, FieldStart, BookmarkStart 等。):
IsInclusive. 定义标记是否包含在提取中。 如果此选项设置为false,并且传递了相同的节点或连续的节点,则将返回一个空列表:
你可以找到ExtractContent方法的实现 这里. 此方法将在本文的场景中提及。
我们还将定义一个自定义方法,以便从提取的节点轻松生成文档。 此方法用于下面的许多场景,只需创建一个新文档并将提取的内容导入其中。
下面的代码示例演示如何获取节点列表并将它们插入到新文档中:
这演示了如何使用上面的方法来提取特定段落之间的内容。 在这种情况下,我们要提取在文档的前半部分中找到的字母的正文。 我们可以看出这是在第7段和第11段之间。
下面的代码完成此任务。 使用文档上的getChild方法提取适当的段落,并传递指定的索引。 然后,我们将这些节点传递给ExtractContent方法,并声明这些节点将包含在提取中。 此方法将返回这些节点之间复制的内容,然后将其插入到新文档中。
下面的代码示例演示如何使用上面的ExtractContent方法提取特定段落之间的内容:
输出文档包含提取的两个段落。
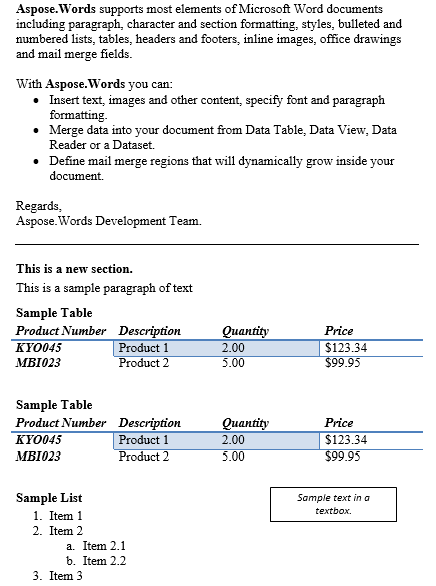
我们可以在块级或内联节点的任何组合之间提取内容。 在下面的这个场景中,我们将提取第一段和第二部分的表格之间的内容,包括在内。 我们通过在文档的第二部分调用getFirstParagraph和getChild方法来获取标记节点,以检索适当的Paragraph和Table节点。 对于轻微的变化,让我们复制内容并将其插入到原始内容下方。
下面的代码示例演示如何使用ExtractContent方法提取段落和表之间的内容:
下面重复的段落和表格之间的内容是结果。
您可能需要提取相同或不同样式的段落之间的内容,例如标有标题样式的段落之间。
下面的代码显示了如何实现这一点。 这是一个简单的例子,它将提取"Heading 1"和"标题3"样式的第一个实例之间的内容,而不提取标题。 为此,我们将最后一个参数设置为false,该参数指定不应包含标记节点。
在适当的实现中,这应该在循环中运行,以从文档中提取这些样式的所有段落之间的内容。 提取的内容复制到新文档中。
下面的代码示例演示如何使用ExtractContent方法提取具有特定样式的段落之间的内容:
下面是前面操作的结果。

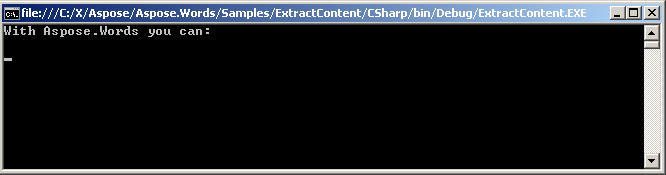
您也可以在内联节点之间提取内容,例如Run。 来自不同段落的Runs可以作为标记传递。 下面的代码显示了如何在同一Paragraph节点之间提取特定文本。
下面的代码示例演示如何使用ExtractContent方法在同一段落的特定运行之间提取内容:
提取的文本显示在控制台上。
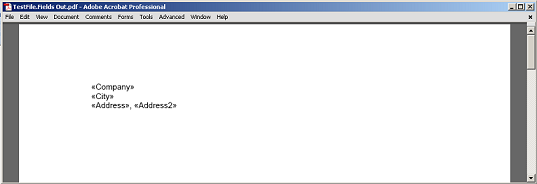
要使用字段作为标记,应传递FieldStart节点。 ExtractContent方法的最后一个参数将定义是否要包含整个字段。 让我们提取"FullName"合并字段和文档中的段落之间的内容。 我们使用DocumentBuilder类的moveToMergeField方法。 这将从传递给它的合并字段的名称返回FieldStart节点。
在我们的例子中,让我们将传递给ExtractContent方法的最后一个参数设置为false,以从提取中排除字段。 我们将提取的内容呈现为PDF。
下面的代码示例演示如何使用ExtractContent方法提取文档中特定字段和段落之间的内容:
提取的内容在字段和段落之间,而没有字段和段落标记节点呈现为PDF。
在文档中,书签中定义的内容由BookmarkStart和BookmarkEnd节点封装。 在这两个节点之间找到的内容组成书签。 您可以将这些节点中的任何一个作为任何标记传递,即使是来自不同书签的标记,只要起始标记出现在文档中的结束标记之前。
在我们的示例文档中,我们有一个书签,名为"Bookmark1"。 此书签的内容在我们的文档中突出显示内容:
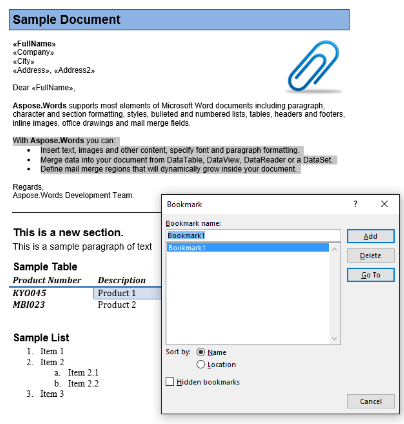
我们将使用下面的代码将此内容提取到新文档中。 IsInclusive参数选项显示如何保留或丢弃书签。
下面的代码示例演示如何使用ExtractContent方法提取书签引用的内容:
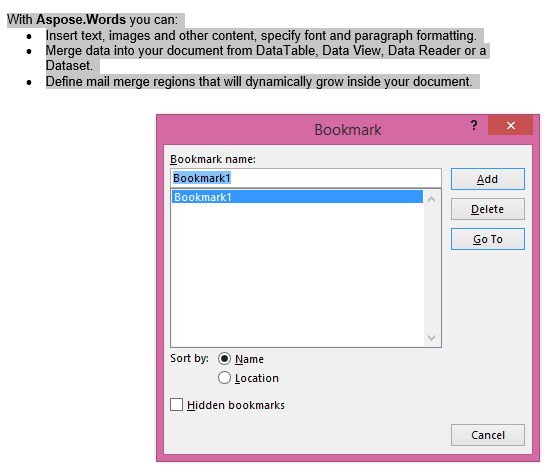
将IsInclusive参数设置为true的提取输出。 副本也将保留书签。
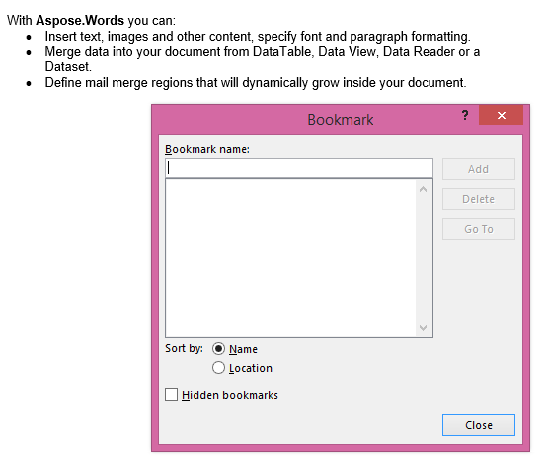
将IsInclusive参数设置为false的提取输出。 副本包含内容,但没有书签。
注释由CommentRangeStart、CommentRangeEnd和注释节点组成。 所有这些节点都是内联的。 前两个节点封装了注释引用的文档中的内容,如下面的屏幕截图所示。
Comment节点本身是一个InlineStory,可以包含段落和运行。 它表示注释的消息,在审阅窗格中被视为注释气泡。 由于此节点是内联的,并且是主体的后代,因此您也可以从该消息中提取内容。
在我们的文件中,我们有一个评论。 让我们通过在Review选项卡中显示标记来显示它:
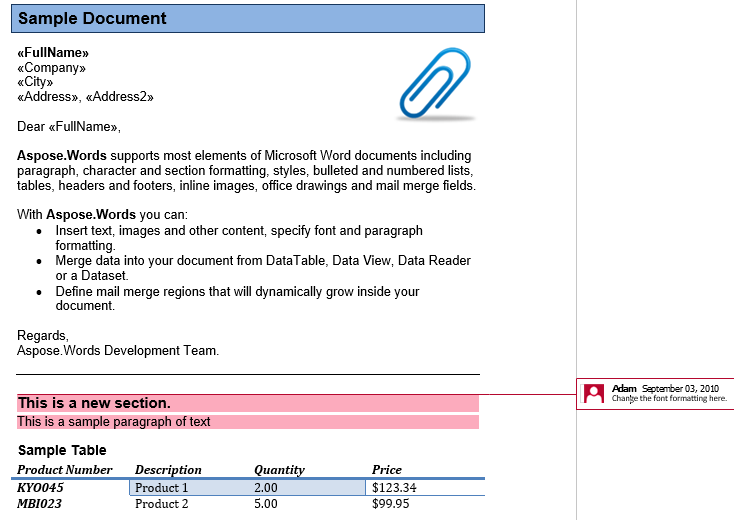
注释封装了标题,第一段和第二部分中的表格。 让我们将此注释提取到一个新文档中。 IsInclusive选项指示注释本身是保留还是丢弃。
下面的代码示例演示如何执行此操作:
首先提取的输出,IsInclusive参数设置为true。 副本也将包含注释。
其次,提取的输出isInclusive设置为false。 副本包含内容,但没有注释。

Aspose.Words不仅可用于通过动态构建Microsoft Word文档或将模板与数据合并来创建Microsoft Word文档,还可用于解析文档,以便提取单独的文档元素,如页眉,页脚,段落,表格,图像等。 另一个可能的任务是找到特定格式或样式的所有文本。
使用DocumentVisitor类实现此使用场景。 该类对应于众所周知的访客设计模式。 使用DocumentVisitor,您可以定义和执行需要在文档树上枚举的自定义操作。
DocumentVisitor提供一组VisitXXX方法,这些方法在遇到特定文档元素(节点)时调用。 例如,当找到文本段落的开头时调用VisitParagraphStart,当找到文本段落的结尾时调用VisitParagraphEnd。 每个DocumentVisitor.VisitXXX方法接受它遇到的相应对象,因此您可以根据需要使用它(例如检索格式),例如VisitParagraphStart和VisitParagraphEnd都接受Paragraph对象。
每个DocumentVisitor.VisitXXX方法返回一个VisitorAction值,用于控制节点的枚举。 您可以请求继续枚举、跳过当前节点(但继续枚举)或停止节点的枚举。
以下是您应该遵循的步骤,以编程方式确定和提取文档的各个部分:
DocumentVisitor为所有DocumentVisitor.VisitXXX方法提供默认实现。 这使得创建新的文档访问者变得更加容易,因为只需要重写特定访问者所需的方法。 没有必要复盖所有访问者方法。
下面的示例演示如何使用访问者模式向Aspose.Words对象模型添加新操作。 在这种情况下,我们创建一个简单的文档转换器为文本格式:
从文档中检索文本的方法有:
SaveFormat.Text参数。 在内部,这将调用另存为文本到内存流中,并返回结果字符串Node.GetText和Node.ToStringWord文档可以包含指定特殊元素的控制字符,如字段、单元格末尾、节末尾等。 可能的单词控制字符的完整列表在ControlChar类中定义。 GetText方法返回节点中包含所有控制字符的文本。
调用ToString仅返回文档的纯文本表示形式,不包含控制字符。 有关导出为纯文本的更多信息,请参阅Using SaveFormat.Text。
下面的代码示例演示在节点上调用GetText和ToString方法之间的区别:
SaveFormat.Text此示例保存文档,如下所示:
下面的代码示例演示如何以TXT格式保存文档:
您可能需要提取文档图像来执行某些任务。 Aspose.Words也允许你这样做。
下面的代码示例演示如何从文档中提取图像:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.