Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
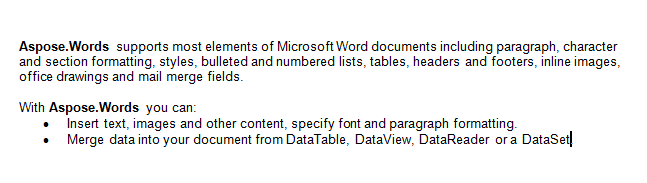
Při práci s dokumenty je důležité, aby bylo možné snadno extrahovat obsah z určitého rozsahu v dokumentu. Obsah se však může skládat ze složitých prvků, jako jsou odstavce, tabulky, obrázky atd.
Bez ohledu na to, jaký obsah je třeba extrahovat, metoda extrahování tohoto obsahu bude vždy určena podle toho, které uzly jsou vybrány k získání obsahu mezi. Mohou to být celé textové těla nebo jednoduché textové runy.
Existuje mnoho možných situací, a proto mnoho různých typů uzlů zvážit při získávání obsahu. Například můžete chtít extrahovat obsah mezi:
V některých situacích můžete dokonce potřebovat kombinovat různé typy uzlů, jako je například získávání obsahu mezi odstavcem a polem, nebo mezi spuštěním a záložkou.
Tento článek poskytuje implementaci kódu pro získávání textu mezi různými uzly, stejně jako příklady běžných scénářů.
Často je cílem extrakce obsahu duplikovat nebo uložit samostatně v novém dokumentu. Například můžete extrahovat obsah a:
Toho lze snadno dosáhnout použitím Aspose.Words a provádění kódu níže.
Kód v tomto oddíle se zabývá všemi možnými výše popsanými situacemi jednou zobecněnou metodou a metodou opětovného použití. Obecný obrys této techniky zahrnuje:
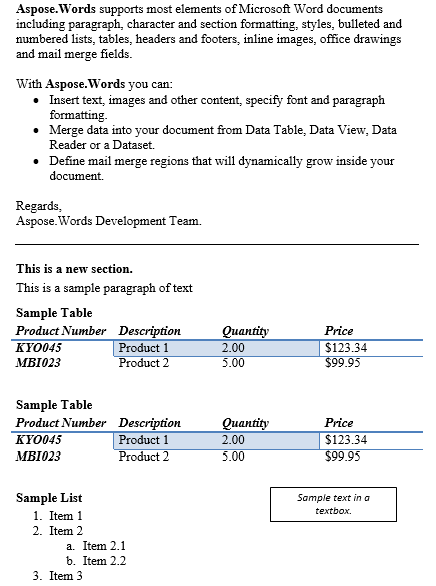
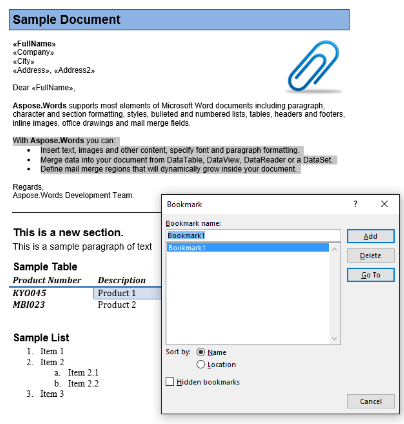
V tomto článku budeme pracovat s níže uvedeným dokumentem. Jak můžete vidět, obsahuje celou řadu obsahu. Dokument také obsahuje druhou část začínající uprostřed první stránky. Záložka a komentář jsou také uvedeny v dokumentu, ale nejsou viditelné v screenshotu níže.

Pro získání obsahu z vašeho dokumentu musíte zavolat ExtractContent metoda níže a předat příslušné parametry.
Základem této metody je nalezení uzlů na úrovni bloků (odstavce a tabulky) a jejich klonování za účelem vytvoření stejných kopií. Pokud jsou prošlé značkovací uzly blokovou úrovní, pak je metoda schopna jednoduše zkopírovat obsah na této úrovni a přidat jej do pole.
Nicméně, pokud jsou markerové uzly inline (dítě odstavce) pak se situace stává složitější, protože je nutné rozdělit odstavec na inline uzlu, ať už je to běh, záložky pole atd. Obsah klonovaných mateřských uzlů, které nejsou přítomny mezi markery, se odstraní. Tento proces se používá k zajištění toho, aby inline uzly stále zachovaly formátování základního odstavce.
Metoda bude také provádět kontroly uzlů, které prošly jako parametry, a hodit výjimku, pokud je buď uzel neplatný. Parametry, které mají být předány této metodě jsou:
StartNode a EndNode. Prvními dvěma parametry jsou uzly, které definují, kde má být extrakce obsahu zahájena a končí. Tyto uzly mohou být oba blokové úrovně (Paragraph , Table ) nebo inline úroveň (např. Run , FieldStart , BookmarkStart atd.:
IsInclusive. Určuje, zda jsou značky zahrnuty do extrakce nebo nikoli. Pokud je tato volba nastavena false a projdou stejným uzlem nebo po sobě jdoucími uzly, poté bude vrácen prázdný seznam:
Provádění ExtractContent metoda, kterou můžete najít Tady. Tato metoda bude uvedena ve scénářích uvedených v tomto článku.
Budeme také definovat vlastní metodu snadno generovat dokument z extrahovaných uzlů. Tato metoda se používá v mnoha níže uvedených scénářích a jednoduše vytváří nový dokument a do něj dováží extrahovaný obsah.
Následující příklad kódu ukazuje, jak vzít seznam uzlů a vloží je do nového dokumentu:
To ukazuje, jak použít výše uvedenou metodu k získání obsahu mezi konkrétními odstavci. V tomto případě chceme získat tělo dopisu nalezeného v první polovině dokumentu. Můžeme říci, že to je mezi 7. a 11. odstavci.
Tento úkol plní následující kód. Příslušné odstavce jsou extrahovány pomocí getChild metoda na dokumentu a předání stanovených indexů. Pak předáme tyto uzly do ExtractContent metoda a uvést, že tyto jsou zahrnuty do extrakce. Tato metoda vrátí zkopírovaný obsah mezi tyto uzly, které jsou pak vloženy do nového dokumentu.
Následující příklad kódu ukazuje, jak extrahovat obsah mezi konkrétními odstavci pomocí ExtractContent metoda výše:
Výstupový dokument obsahuje dva odstavce, které byly extrahovány.
Můžeme extrahovat obsah mezi libovolnými kombinacemi blokové nebo inline uzlů. V následujícím scénáři budeme extrahovat obsah mezi prvním odstavcem a tabulkou v druhé části včetně. Dostaneme značkovací uzly voláním getFirstParagraph a getChild metoda na druhém oddíle dokumentu pro získání vhodného Paragraph a Table uzly. Pro mírnou variaci nechť místo toho zdvojí obsah a vloží jej pod originál.
Následující příklad kódu ukazuje, jak extrahovat obsah mezi odstavcem a tabulkou pomocí ExtractContent metoda:
Obsah mezi odstavcem a tabulkou byl duplikován níže je výsledek.
Možná budete muset extrahovat obsah mezi odstavci stejného nebo odlišného stylu, například mezi odstavci označenými stylu záhlaví.
Níže uvedený kód ukazuje, jak toho dosáhnout. Jedná se o jednoduchý příklad, který bude extrahovat obsah mezi prvními instancemi hlavice 1 a 1 a 3, bez extrahování čísel. K tomu nastavíme poslední parametr na false, který určuje, že by neměly být zahrnuty značkovací uzly.
Ve správném provedení by to mělo probíhat ve smyčce, aby se z dokumentu získal obsah mezi všemi odstavci těchto stylů. Extrahovaný obsah je zkopírován do nového dokumentu.
Následující příklad kódu ukazuje, jak extrahovat obsah mezi odstavci se specifickými styly pomocí ExtractContent metoda:
Níže je výsledek předchozí operace.

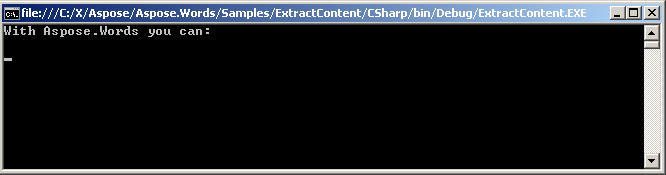
Můžete extrahovat obsah mezi inline uzly, jako je Run Taky. Runs z různých odstavců lze předat jako markery. Níže uvedený kód ukazuje, jak extrahovat konkrétní text mezi stejným Paragraph Uzel.
Následující příklad kódu ukazuje, jak extrahovat obsah mezi konkrétními výsledky stejného odstavce pomocí ExtractContent metoda:
Na konzoli je zobrazen extrahovaný text
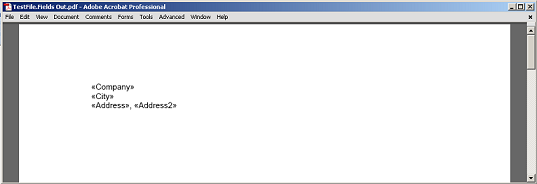
Pro použití pole jako značky, FieldStart Uzel by měl projít. Poslední parametr k ExtractContent metoda definuje, zda má být celé pole zahrnuto nebo nikoli. Nechť extrahují obsah mezi polem sloučení FullName a odstavcem v dokumentu. Používáme moveToMergeField DocumentBuilder třída. Tohle vrátí FieldStart Uzel od jména pole sloučení přešel na něj.
V našem případě nechť nastavit poslední parametr přešel na ExtractContent metoda false vyloučit pole z těžby. Vytěžíme obsah do PDF.
Následující příklad kódu ukazuje, jak extrahovat obsah mezi určitým polem a odstavcem v dokumentu pomocí ExtractContent metoda:
Extrahovaný obsah mezi polem a odstavcem bez pole a bodových značkovacích uzlů do PDF.
V dokumentu je obsah definovaný v záložce zapouzdřen BookmarkStart a záložku End uzly. Obsah nalezený mezi těmito dvěma uzly tvoří záložku. Obou z těchto uzlů můžete předat jako jakýkoli marker, a to i ty z různých záložek, pokud se startovní značka objeví před koncovou značkou v dokumentu.
V našem ukázkovém dokumentu máme jednu záložku s názvem “Záložka 1.” Obsah této záložky je zdůrazněn v našem dokumentu:
Tento obsah budeme extrahovat do nového dokumentu pomocí níže uvedeného kódu. The IsInclusive možnost parametru ukazuje, jak záložku uchovávat nebo vyřadit.
Následující příklad kódu ukazuje, jak extrahovat obsah odkazovaný na záložku pomocí ExtractContent metoda:
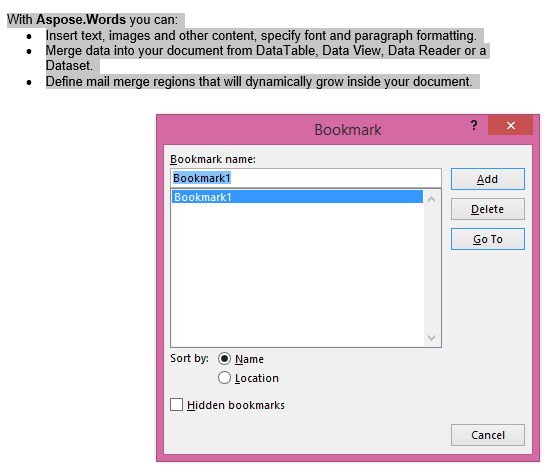
Extrahovaný výstup s IsInclusive parametr nastavený na true. Kopie si také ponechá záložku.
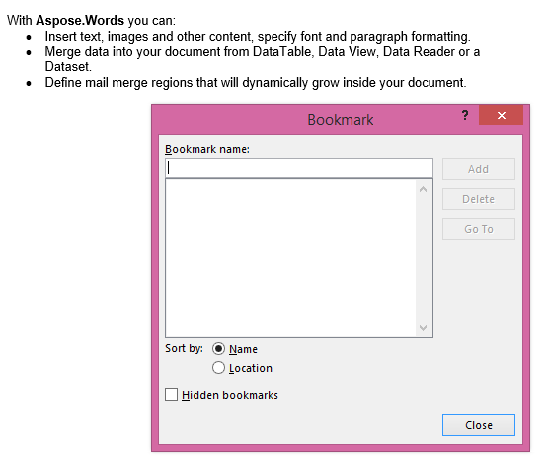
Extrahovaný výstup s IsInclusive parametr nastavený na false. Kopie obsahuje obsah, ale bez záložky.
Komentář se skládá z CommentRangeStart, CommentRangeEnd a Komentovat uzly. Všechny tyto uzly jsou inline. První dva uzly zapoutají obsah v dokumentu, na který odkazuje komentář, jak je vidět ve screenshotu níže.
The Comment Uzel sám o sobě je InlineStory který může obsahovat odstavce a běží. Představuje poselství komentáře, jak je vnímáno jako komentační bublina v tabulce recenze. Vzhledem k tomu, že tento uzel je inline a potomek těla můžete také extrahovat obsah zevnitř této zprávy.
V našem dokumentu máme jednu poznámku. Nechť ji zobrazí zobrazením markupu v záložce Review:
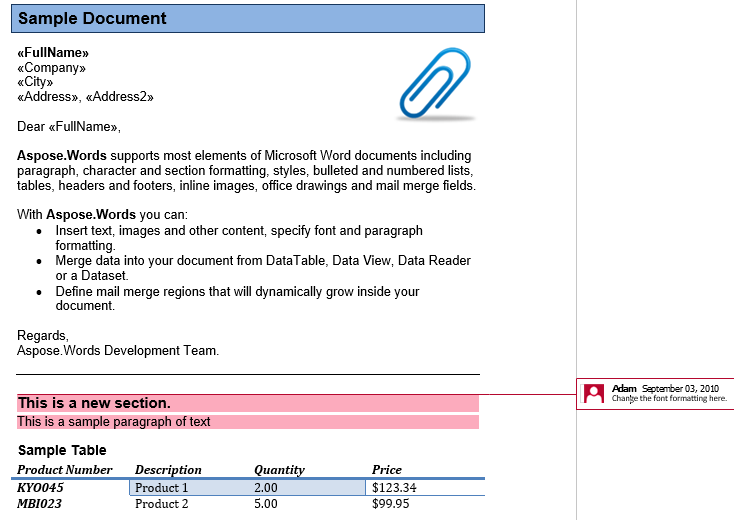
V komentáři je uveden nadpis, první odstavec a tabulka ve druhém oddíle. Nechť tuto poznámku extrahují do nového dokumentu. The IsInclusive možnost diktuje, zda je komentář sám o sobě zachován nebo vyřazen.
Následující příklad kódu ukazuje, jak to udělat, je níže:
Za prvé, extrahovaný výstup s IsInclusive parametr nastavený na true. Kopie bude obsahovat i komentář.
Za druhé, extrahovaný výstup s isInkluzivní nastaveno na false. Kopie obsahuje obsah, ale bez komentáře.

Aspose.Words lze použít nejen pro vytváření Microsoft Word dokumenty dynamicky nebo sloučit šablony s daty, ale také pro analýzu dokumentů s cílem získat samostatné prvky dokumentů, jako jsou hlavičky, zápatí, odstavce, tabulky, obrázky a další. Dalším možným úkolem je najít text konkrétního formátování nebo stylu.
Použijte DocumentVisitor třída k provedení tohoto scénáře využití. Tato třída odpovídá známému designu návštěvníka. S DocumentVisitor, můžete definovat a provádět vlastní operace, které vyžadují výčtu nad stromem dokumentu.
DocumentVisitor poskytuje soubor VisitXXX metody, které se používají v případě, že se nachází určitý prvek dokumentu (noda). Například, VisitParagraphStart volá, když je nalezen začátek textového odstavce a VisitParagraphEnd volá, když je nalezen konec textového odstavce. Každý DocumentVisitor.VisitXXX metoda akceptuje odpovídající objekt, na který se setká, takže jej můžete použít podle potřeby (například načíst formátování), např. obojí VisitParagraphStart a VisitParagraphEnd přijmout Paragraph objekt.
Každý DocumentVisitor.VisitXXX metoda vrací a VisitorAction hodnota, která řídí počet uzlů. Můžete požádat buď pokračovat v výčtu, přeskočit aktuální uzel (ale pokračovat v výčtu), nebo zastavit počet uzlů.
Toto jsou kroky, které byste měli sledovat programově určit a extrahovat různé části dokumentu:
DocumentVisitor poskytuje výchozí implementace pro všechny DocumentVisitor.VisitXXX metody. Díky tomu je snazší vytvořit nové návštěvníky dokumentů, protože pouze metody potřebné pro konkrétního návštěvníka je třeba přepsat. Není nutné překračovat všechny návštěvnické metody.
Následující příklad ukazuje, jak použít vzor Návštěvníka k přidání nových operací do Aspose.Words model objektu. V tomto případě vytvoříme jednoduchý konvertor dokumentu do textového formátu:
Způsoby, jak získat text z dokumentu jsou:
SaveFormat.Text parametr. Interně to vyvolá uložení textu do paměti a vrací výsledný řetězecNode.GetText a Node.ToStringA Slovní dokument může obsahovat kontrolní znaky, které označují zvláštní prvky jako pole, konec buňky, konec sekce atd. Úplný seznam možných znaků kontroly Word je definován v ControlChar třída. The GetText metoda vrací text se všemi znaky ovládacího znaku přítomnými v uzlu.
Volání ToString vrací prostý text reprezentace dokumentu pouze bez kontrolních znaků. Další informace o vývozu jako prostém textu viz Using SaveFormat.Text.
Následující příklad kódu ukazuje rozdíl mezi voláním GetText a ToString metody na uzel:
SaveFormat.TextTento příklad uloží dokument takto:
Následující příklad kódu ukazuje, jak uložit dokument ve formátu TXT:
Možná budete potřebovat extrahovat obrazy dokumentů, abyste mohli provádět některé úkoly. Aspose.Words umožňuje vám to také udělat.
Následující příklad kódu ukazuje, jak extrahovat obrázky z dokumentu:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.