Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
Hay algunas situaciones en las que no se desea eliminar por completo las regiones no fusionadas del documento durante Mail Merge o el documento parece incompleto. Esto puede ocurrir cuando la ausencia de datos de entrada se debe mostrar al usuario en forma de mensaje en lugar de eliminar completamente la región.
También hay ocasiones en las que eliminar la región no utilizada por sí sola no es suficiente, por ejemplo, si la región está precedida por un título o si la región está contenida en una tabla. Si esta región no se usa, el título y la tabla permanecerán después de eliminar la región, lo que se verá fuera de lugar en el documento.
Este artículo proporciona una solución para definir manualmente cómo se manejan las regiones no utilizadas en el documento. Se proporciona el código base para esta funcionalidad y se puede reutilizar fácilmente en otro proyecto.
La lógica que se aplicará a cada región se define dentro de una clase que implementa la interfaz IFieldMergingCallback. De la misma manera, se puede configurar un controlador Mail Merge para controlar cómo se fusiona cada campo, este controlador se puede configurar para realizar acciones en cada campo en una región no utilizada o en la región en su conjunto. Dentro de este controlador, puede configurar el código para cambiar el texto de una región, eliminar nodos o filas y celdas vacías, etc.
En esta muestra, usaremos el documento que se muestra a continuación. Contiene regiones anidadas y una región contenida dentro de una tabla.
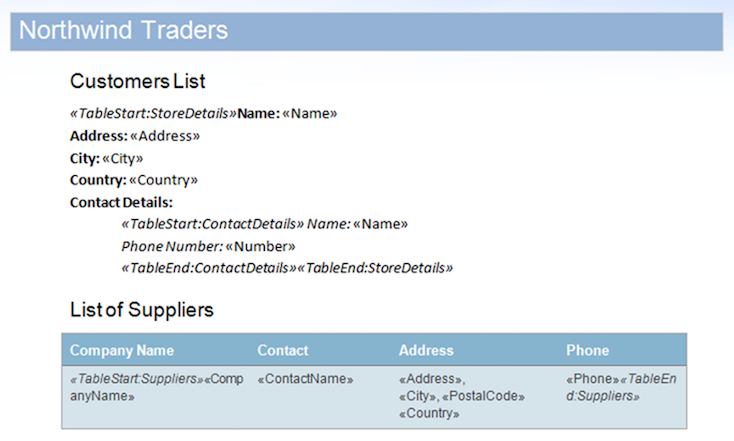
Como demostración rápida, podemos ejecutar una base de datos de muestra en el documento de muestra con el indicador MailMergeCleanupOptions.REMOVE_UNUSED_REGIONS habilitado. Esta propiedad eliminará automáticamente las regiones no fusionadas del documento durante un mail merge.
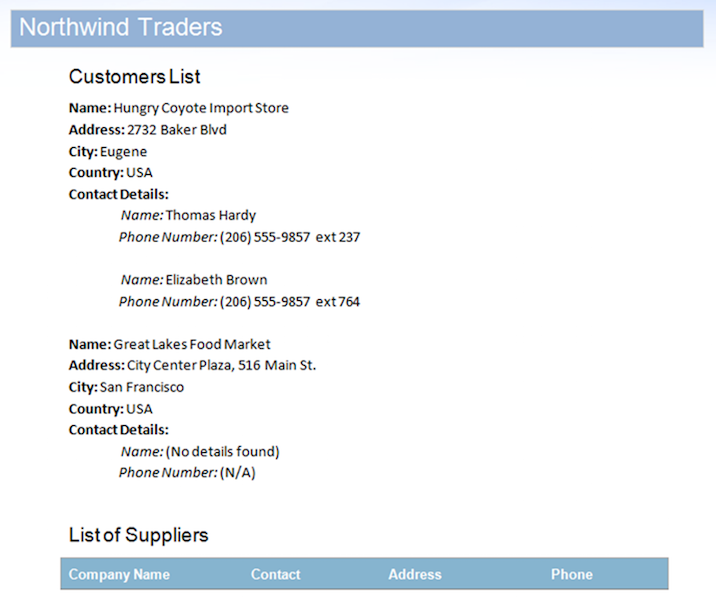
La fuente de datos incluye dos registros para la región StoreDetails, pero intencionalmente tiene datos para las regiones secundarias ContactDetails de uno de los registros. Además, la región Suppliers tampoco tiene filas de datos. Esto hará que las regiones no utilizadas permanezcan en el documento. El resultado después de fusionar el documento con esta fuente de datos se muestra a continuación.

Como se indica en la imagen, puede ver que la región ContactDetails para el segundo registro y las regiones Suppliers han sido eliminadas automáticamente por el motor Mail Merge ya que no tienen datos. Sin embargo, hay algunos problemas que hacen que este documento de salida parezca incompleto:
La técnica proporcionada en este artículo demuestra cómo aplicar lógica personalizada a cada región no fusionada para evitar estos problemas.
La Solución
Para aplicar lógica manualmente a cada región no utilizada del documento, aprovechamos las funciones que ya están disponibles en Aspose.Words.
El motor Mail Merge proporciona una propiedad para eliminar regiones no utilizadas a través del indicador MailMergeCleanupOptions.RemoveUnusedRegions. Esto se puede deshabilitar para que dichas regiones no se toquen durante un mail merge. Esto nos permite dejar las regiones no fusionadas en el documento y manejarlas manualmente nosotros mismos.
Luego podemos aprovechar la propiedad MailMerge.FieldMergingCallback como un medio para aplicar nuestra propia lógica personalizada a estas regiones no fusionadas durante Mail Merge mediante el uso de una clase de controlador que implemente la interfaz IFieldMergingCallback.
Este código dentro de la clase handler es la única clase que necesitará modificar para controlar la lógica aplicada a las regiones no fusionadas. El otro código de este ejemplo se puede reutilizar sin modificaciones en ningún proyecto.
Este proyecto de muestra demuestra esta técnica. Implica los siguientes pasos:
El Código
La implementación del método ExecuteCustomLogicOnEmptyRegions se encuentra a continuación. Este método acepta varios parámetros:
Ejemplo
Muestra cómo ejecutar lógica personalizada en regiones no utilizadas utilizando el controlador especificado.
Ejemplo
Define el método utilizado para manejar manualmente regiones no fusionadas.
Este método implica encontrar todas las regiones no fusionadas en el documento. Esto se logra utilizando el método MailMerge.GetFieldNames. Este método devuelve todos los campos de combinación del documento, incluidos los marcadores de inicio y finalización de la región (representados por campos de combinación con el prefijo TableStart o TableEnd).
Cuando se encuentra un campo de combinación TableStart, se agrega como un nuevo DataTable al DataSet. Dado que una región puede aparecer más de una vez (por ejemplo, porque es una región anidada donde la región principal se ha fusionado con varios registros), la tabla solo se crea y agrega si aún no existe en DataSet.
Cuando se encuentra un inicio de región apropiado y se agrega a la base de datos, el siguiente campo (que corresponde al primer campo de la región) se agrega al DataTable. Solo se requiere agregar el primer campo para cada campo en la región que se fusionará y se pasará al controlador.
También establecemos el valor del campo del primer campo en “FirstField " para facilitar la aplicación de la lógica al primero u otros campos de la región. Al incluir esto, significa que no es necesario codificar el nombre del primer campo o implementar código adicional para verificar si el campo actual es el primero en el código del controlador.
El siguiente código demuestra cómo funciona este sistema. El documento que se muestra al principio de este artículo vuelve a aparecer con la misma fuente de datos, pero esta vez, las regiones no utilizadas se manejan mediante código personalizado.
Ejemplo
Muestra cómo manejar regiones no fusionadas después de Mail Merge con código definido por el usuario.
El código realiza diferentes operaciones en función del nombre de la región recuperada mediante la propiedad FieldMergingArgs.TableName. Tenga en cuenta que, dependiendo de su documento y regiones, puede codificar el controlador para que ejecute lógica dependiente de cada región o código que se aplique a cada región no fusionada en el documento o una combinación de ambos.
La lógica para la región ContactDetails implica cambiar el texto de cada campo en la región ContactDetails con un mensaje apropiado que indique que no hay datos. Los nombres de cada campo se comparan dentro del controlador utilizando la propiedad FieldMergingArgs.FieldName.
Se aplica un proceso similar a la región Suppliers con la adición de código adicional para manejar la tabla que contiene la región. El código verificará si la región está contenida dentro de una tabla (ya que es posible que ya se haya eliminado). Si es así, eliminará toda la tabla del documento, así como el párrafo que la precede, siempre que esté formateada con un estilo de encabezado, por ejemplo, “Heading 1”.
Ejemplo
Muestra cómo definir lógica personalizada en un controlador que implementa IFieldMergingCallback que se ejecuta para regiones no fusionadas en el documento.
El resultado del código anterior se muestra a continuación. Los campos sin combinar dentro de la primera región se reemplazan con texto informativo y la eliminación de la tabla y el encabezado permite que el documento parezca completo.

El código que elimina la tabla principal también podría ejecutarse en cada región no utilizada en lugar de solo en una región específica eliminando la verificación del nombre de la tabla. En este caso, si alguna región dentro de una tabla no se fusionó con ningún dato, tanto la región como la tabla contenedora también se eliminarán automáticamente.
Podemos insertar código diferente en el controlador para controlar cómo se manejan las regiones no fusionadas. En su lugar, usar el código a continuación en el controlador cambiará el texto en el primer párrafo de la región a un mensaje útil, mientras que se eliminarán los párrafos posteriores de la región. Estos otros párrafos se eliminan ya que permanecerían en la región después de fusionar nuestro mensaje.
El texto de reemplazo se combina en el primer campo estableciendo el texto especificado en la propiedad FieldMergingArgs.Text. El motor Mail Merge fusiona el texto de esta propiedad en el campo.
El código aplica esto solo para el primer campo de la región marcando la propiedad FieldMergingArgs.FieldValue. El valor de campo del primer campo de la región está marcado con " FirstField”. Esto hace que este tipo de lógica sea más fácil de implementar en muchas regiones, ya que no se requiere código adicional.
Ejemplo
Muestra cómo reemplazar una región no utilizada con un mensaje y eliminar párrafos adicionales.
El documento resultante después de que se haya ejecutado el código anterior se muestra a continuación. La región no utilizada se reemplaza con un mensaje que indica que no hay registros para mostrar.

Como otro ejemplo, podemos insertar el código a continuación en lugar del código que originalmente manejaba el SuppliersRegion. Esto mostrará un mensaje dentro de la tabla y fusionará las celdas en lugar de eliminar la tabla del documento. Dado que la región reside dentro de una tabla con varias celdas, parece mejor fusionar las celdas de la tabla y centrar el mensaje.
Ejemplo
Muestra cómo fusionar todas las celdas principales de una región no utilizada y mostrar un mensaje dentro de la tabla.
El documento resultante después de que se haya ejecutado el código anterior se muestra a continuación.

Finalmente, podemos llamar al método ExecuteCustomLogicOnEmptyRegions y especificar los nombres de tabla que deben manejarse dentro de nuestro método handler, mientras especificamos otros que se eliminarán automáticamente.
Ejemplo
Muestra cómo especificar solo la región ContactDetails que se manejará a través de la clase handler.
Llamar a esta sobrecarga con el ArrayList especificado creará la fuente de datos que solo contiene filas de datos para las regiones especificadas. Las regiones que no sean la región ContactDetails no se manejarán y, en cambio, el motor Mail Merge las eliminará automáticamente. El resultado de la llamada anterior usando el código en nuestro controlador original se muestra a continuación.
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.