Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
Saat bekerja dengan dokumen, penting untuk dapat dengan mudah mengekstrak konten dari rentang tertentu dalam dokumen. Namun, konten dapat terdiri dari elemen kompleks seperti paragraf, tabel, gambar, dll.
Terlepas dari konten apa yang perlu diekstraksi, metode untuk mengekstrak konten tersebut akan selalu ditentukan oleh node mana yang dipilih untuk mengekstrak konten di antaranya. Ini bisa berupa seluruh badan teks atau rangkaian teks sederhana.
Ada banyak kemungkinan situasi dan oleh karena itu banyak jenis simpul yang berbeda untuk dipertimbangkan saat mengekstrak konten. Misalnya, Anda mungkin ingin mengekstrak konten di antara keduanya:
Dalam beberapa situasi, Anda bahkan mungkin perlu menggabungkan jenis simpul yang berbeda, seperti mengekstrak konten antara paragraf dan bidang, atau antara proses dan penanda.
Artikel ini menyediakan implementasi kode untuk mengekstrak teks di antara node yang berbeda, serta contoh skenario umum.
Seringkali tujuan mengekstrak konten adalah untuk menduplikasi atau menyimpannya secara terpisah dalam dokumen baru. Misalnya, Anda dapat mengekstrak konten dan:
Ini dapat dengan mudah dicapai dengan menggunakan Aspose.Words dan implementasi kode di bawah ini.
Kode di bagian ini membahas semua kemungkinan situasi yang dijelaskan di atas dengan satu metode yang digeneralisasikan dan dapat digunakan kembali. Garis besar umum dari teknik ini melibatkan:
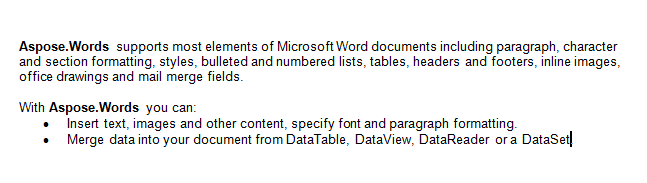
Kami akan mengerjakan dokumen di bawah ini dalam artikel ini. Seperti yang Anda lihat, ini berisi berbagai konten. Perhatikan juga, dokumen tersebut berisi bagian kedua yang dimulai di tengah halaman pertama. Penanda dan komentar juga ada di dokumen tetapi tidak terlihat pada tangkapan layar di bawah.

Untuk mengekstrak konten dari dokumen Anda, Anda perlu memanggil metode ExtractContent di bawah ini dan meneruskan parameter yang sesuai.
Dasar yang mendasari metode ini melibatkan pencarian node tingkat blok (paragraf dan tabel) dan mengkloningnya untuk membuat salinan yang identik. Jika node penanda yang diteruskan adalah level blok, maka metode tersebut dapat dengan mudah menyalin konten pada level tersebut dan menambahkannya ke array.
Namun, jika node penanda sebaris (turunan dari paragraf) maka situasinya menjadi lebih kompleks, karena paragraf perlu dibagi pada node sebaris, baik itu run, bidang bookmark, dll. Konten di node induk yang dikloning yang tidak ada di antara penanda akan dihapus. Proses ini digunakan untuk memastikan bahwa node sebaris akan tetap mempertahankan pemformatan paragraf induk.
Metode ini juga akan menjalankan pemeriksaan pada node yang diteruskan sebagai parameter dan memberikan pengecualian jika salah satu node tidak valid. Parameter yang akan diteruskan ke metode ini adalah:
StartNode dan EndNode. Dua parameter pertama adalah node yang menentukan di mana ekstraksi konten akan dimulai dan diakhiri masing-masing. Node ini dapat berupa level blok (Paragraph, Table) atau level sebaris (mis.Run, FieldStart, BookmarkStart dll.):
IsInclusive. Menentukan apakah penanda disertakan dalam ekstraksi atau tidak. Jika opsi ini disetel ke false dan node yang sama atau node berurutan dilewatkan, maka daftar kosong akan dikembalikan:
Penerapan metode ExtractContent dapat Anda temukan di sini. Metode ini akan dirujuk dalam skenario dalam artikel ini.
Kami juga akan menentukan metode khusus untuk menghasilkan dokumen dengan mudah dari node yang diekstraksi. Metode ini digunakan dalam banyak skenario di bawah ini dan hanya membuat dokumen baru dan mengimpor konten yang diekstraksi ke dalamnya.
Contoh kode berikut menunjukkan cara mengambil daftar simpul dan menyisipkannya ke dalam dokumen baru:
Ini menunjukkan cara menggunakan metode di atas untuk mengekstrak konten di antara paragraf tertentu. Dalam hal ini, kami ingin mengekstrak isi surat yang ditemukan di paruh pertama dokumen. Kita dapat mengatakan bahwa ini adalah antara paragraf ke-7 dan ke-11.
Kode di bawah ini menyelesaikan tugas ini. Paragraf yang sesuai diekstraksi menggunakan metode getChild pada dokumen dan meneruskan indeks yang ditentukan. Kami kemudian meneruskan simpul-simpul ini ke metode ExtractContent dan menyatakan bahwa simpul-simpul ini akan disertakan dalam ekstraksi. Metode ini akan mengembalikan konten yang disalin di antara node-node ini yang kemudian dimasukkan ke dalam dokumen baru.
Contoh kode berikut menunjukkan cara mengekstrak konten di antara paragraf tertentu menggunakan metode ExtractContent di atas:
Dokumen keluaran berisi dua paragraf yang diekstraksi.
Kita dapat mengekstrak konten di antara kombinasi node tingkat blok atau sebaris apa pun. Dalam skenario di bawah ini, kami akan mengekstrak konten antara paragraf pertama dan tabel di bagian kedua secara inklusif. Kita mendapatkan node marker dengan memanggil metode getFirstParagraph dan getChild pada bagian kedua dokumen untuk mengambil node Paragraph dan Table yang sesuai. Untuk sedikit variasi, mari gandakan konten dan sisipkan di bawah aslinya.
Contoh kode berikut menunjukkan cara mengekstrak konten antara paragraf dan tabel menggunakan metode ExtractContent:
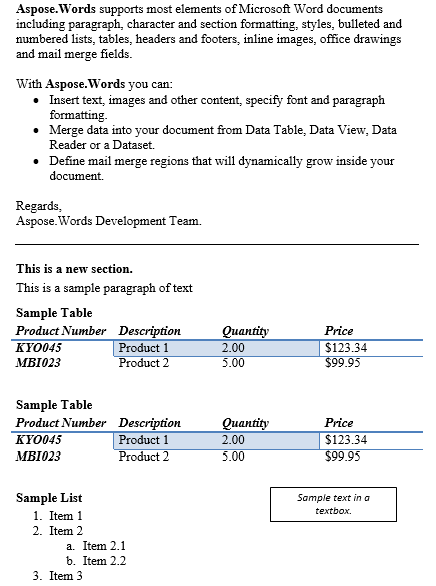
Konten antara paragraf dan tabel telah diduplikasi di bawah ini adalah hasilnya.
Anda mungkin perlu mengekstrak konten di antara paragraf dengan gaya yang sama atau berbeda, seperti di antara paragraf yang ditandai dengan gaya judul.
Kode di bawah ini menunjukkan cara mencapainya. Ini adalah contoh sederhana yang akan mengekstrak konten antara contoh pertama gaya" Heading 1 “dan” Header 3 " tanpa mengekstrak headingnya juga. Untuk melakukan ini, kami menetapkan parameter terakhir ke false, yang menetapkan bahwa node penanda tidak boleh disertakan.
Dalam implementasi yang tepat, ini harus dijalankan dalam satu lingkaran untuk mengekstrak konten di antara semua paragraf gaya ini dari dokumen. Konten yang diekstraksi disalin ke dalam dokumen baru.
Contoh kode berikut menunjukkan cara mengekstrak konten di antara paragraf dengan gaya tertentu menggunakan metode ExtractContent:
Di bawah ini adalah hasil dari operasi sebelumnya.

Anda juga dapat mengekstrak konten di antara simpul sebaris seperti Run. Runs dari paragraf yang berbeda dapat diteruskan sebagai penanda. Kode di bawah ini menunjukkan cara mengekstrak teks tertentu di antara simpul Paragraph yang sama.
Contoh kode berikut menunjukkan cara mengekstrak konten di antara proses tertentu dari paragraf yang sama menggunakan metode ExtractContent:
Teks yang diekstraksi ditampilkan di konsol.
Untuk menggunakan bidang sebagai penanda, simpul FieldStart harus diteruskan. Parameter terakhir untuk metode ExtractContent akan menentukan apakah seluruh bidang akan disertakan atau tidak. Mari kita ekstrak konten di antara bidang gabungan “FullName " dan sebuah paragraf dalam dokumen. Kami menggunakan metode moveToMergeField dari kelas DocumentBuilder. Ini akan mengembalikan simpul FieldStart dari nama bidang gabungan yang diteruskan ke sana.
Dalam kasus kami, mari setel parameter terakhir yang diteruskan ke metode ExtractContent menjadi false untuk mengecualikan bidang dari ekstraksi. Kami akan merender konten yang diekstraksi menjadi PDF.
Contoh kode berikut menunjukkan cara mengekstrak konten antara bidang dan paragraf tertentu dalam dokumen menggunakan metode ExtractContent:
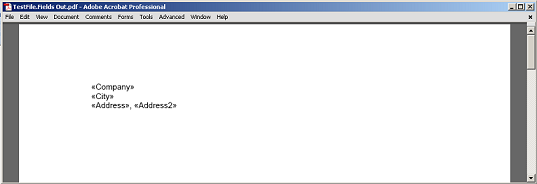
Konten yang diekstraksi antara bidang dan paragraf, tanpa simpul penanda bidang dan paragraf dirender menjadi PDF.
Dalam dokumen, konten yang didefinisikan dalam penanda dienkapsulasi oleh simpul BookmarkStart dan BookmarkEnd. Konten yang ditemukan di antara dua simpul ini membentuk bookmark. Anda dapat meneruskan salah satu dari simpul ini sebagai penanda apa pun, bahkan yang berasal dari penanda yang berbeda, selama penanda awal muncul sebelum penanda akhir dalam dokumen.
Dalam dokumen sampel kami, kami memiliki satu penanda, bernama “Bookmark1”. Konten bookmark ini adalah konten yang disorot dalam dokumen kami:
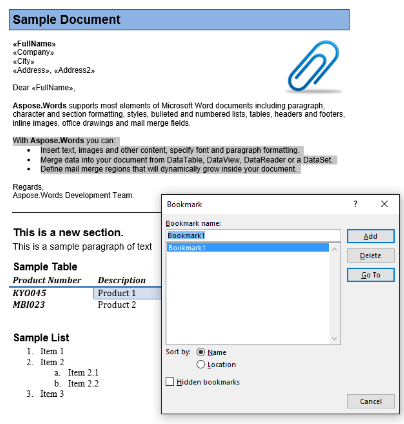
Kami akan mengekstrak konten ini ke dalam dokumen baru menggunakan kode di bawah ini. Opsi parameter IsInclusive menunjukkan cara mempertahankan atau membuang bookmark.
Contoh kode berikut menunjukkan cara mengekstrak konten yang mereferensikan bookmark menggunakan metode ExtractContent:
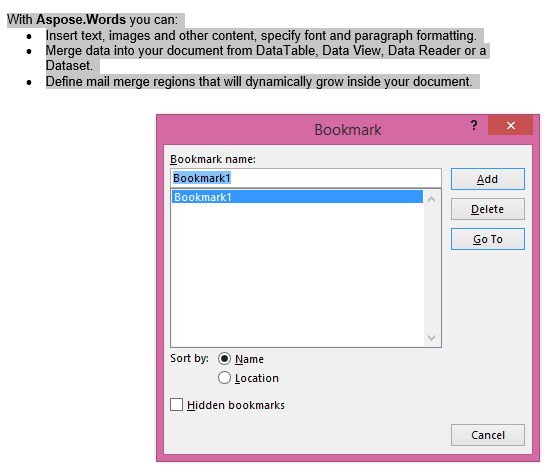
Output yang diekstraksi dengan parameter IsInclusive disetel ke true. Salinan akan mempertahankan bookmark juga.
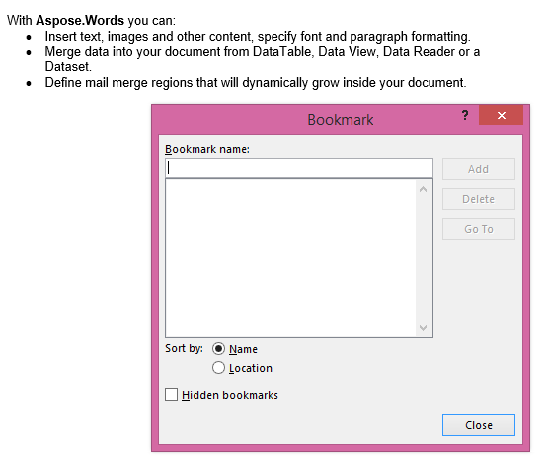
Output yang diekstraksi dengan parameter IsInclusive disetel ke false. Salinan berisi konten tetapi tanpa penanda.
Komentar terdiri dari simpul CommentRangeStart, CommentRangeEnd, dan Komentar. Semua node ini sebaris. Dua node pertama merangkum konten dalam dokumen yang dirujuk oleh komentar, seperti yang terlihat pada tangkapan layar di bawah ini.
Simpul Comment itu sendiri adalah InlineStory yang dapat berisi paragraf dan run. Ini mewakili pesan komentar seperti yang terlihat sebagai gelembung komentar di panel tinjauan. Karena simpul ini sebaris dan merupakan turunan dari isi, Anda juga dapat mengekstrak konten dari dalam pesan ini.
Dalam dokumen kami, kami memiliki satu komentar. Mari kita tampilkan dengan menampilkan markup di tab Tinjau:
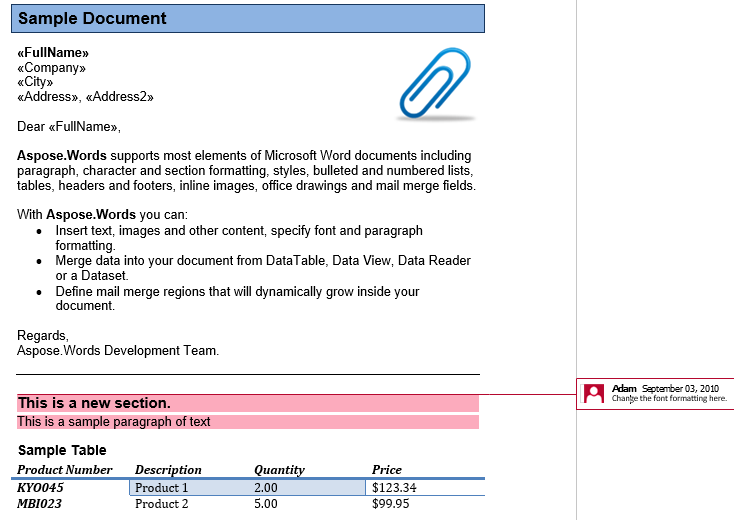
Komentar merangkum judul, paragraf pertama, dan tabel di bagian kedua. Mari kita ekstrak komentar ini ke dalam dokumen baru. Opsi IsInclusive menentukan apakah komentar itu sendiri disimpan atau dibuang.
Contoh kode berikut menunjukkan cara melakukannya di bawah ini:
Pertama, output yang diekstraksi dengan parameter IsInclusive disetel ke true. Salinan akan berisi komentar juga.
Kedua, output yang diekstraksi dengan isInclusive disetel ke false. Salinan berisi konten tetapi tanpa komentar.

Aspose.Words dapat digunakan tidak hanya untuk membuat dokumen Microsoft Word dengan membuatnya secara dinamis atau menggabungkan templat dengan data, tetapi juga untuk mengurai dokumen untuk mengekstrak elemen dokumen terpisah seperti header, footer, paragraf, tabel, gambar, dan lainnya. Tugas lain yang mungkin dilakukan adalah menemukan semua teks dengan format atau gaya tertentu.
Gunakan kelas DocumentVisitor untuk mengimplementasikan skenario penggunaan ini. Kelas ini sesuai dengan pola desain Pengunjung yang terkenal. Dengan DocumentVisitor, Anda dapat menentukan dan menjalankan operasi khusus yang memerlukan pencacahan di atas pohon dokumen.
DocumentVisitor menyediakan satu set metode VisitXXX yang dipanggil saat elemen dokumen (simpul) tertentu ditemukan. Misalnya, VisitParagraphStart dipanggil saat awal paragraf teks ditemukan dan VisitParagraphEnd dipanggil saat akhir paragraf teks ditemukan. Setiap metode DocumentVisitor.VisitXXX menerima objek terkait yang ditemuinya sehingga Anda dapat menggunakannya sesuai kebutuhan (misalnya mengambil pemformatan), mis. baik VisitParagraphStart dan VisitParagraphEnd menerima objek Paragraph.
Setiap metode DocumentVisitor.VisitXXX mengembalikan nilai VisitorAction yang mengontrol pencacahan node. Anda dapat meminta untuk melanjutkan pencacahan, melewati node saat ini (tetapi melanjutkan pencacahan), atau menghentikan pencacahan node.
Ini adalah langkah-langkah yang harus Anda ikuti untuk menentukan dan mengekstrak berbagai bagian dokumen secara terprogram:
DocumentVisitor menyediakan implementasi default untuk semua metode DocumentVisitor.VisitXXX. Ini membuatnya lebih mudah untuk membuat pengunjung dokumen baru karena hanya metode yang diperlukan untuk pengunjung tertentu yang perlu diganti. Tidak perlu mengganti semua metode pengunjung.
Contoh berikut menunjukkan cara menggunakan pola Pengunjung untuk menambahkan operasi baru ke model objek Aspose.Words. Dalam hal ini, kami membuat pengonversi dokumen sederhana menjadi format teks:
Cara untuk mengambil teks dari dokumen adalah:
SaveFormat.Text. Secara internal, ini memanggil save as text ke dalam aliran memori dan mengembalikan string yang dihasilkanNode.GetText dan Node.ToStringDokumen Word dapat berisi karakter kontrol yang menetapkan elemen khusus seperti bidang, akhir sel, akhir bagian, dll. Daftar lengkap kemungkinan karakter kontrol Word didefinisikan dalam kelas ControlChar. Metode GetText mengembalikan teks dengan semua karakter karakter kontrol yang ada di simpul.
Memanggil ToString mengembalikan representasi teks biasa dari dokumen hanya tanpa karakter kontrol. Untuk informasi lebih lanjut tentang mengekspor sebagai teks biasa, lihat Using SaveFormat.Text.
Contoh kode berikut menunjukkan perbedaan antara memanggil metode GetText dan ToString pada sebuah node:
SaveFormat.TextContoh ini menyimpan dokumen sebagai berikut:
Contoh kode berikut menunjukkan cara menyimpan dokumen dalam format TXT:
Anda mungkin perlu mengekstrak gambar dokumen untuk melakukan beberapa tugas. Aspose.Words memungkinkan Anda melakukan ini juga.
Contoh kode berikut menunjukkan cara mengekstrak gambar dari dokumen:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.