Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
ドキュメントを操作するときは、ドキュメント内の特定の範囲からコンテンツを簡単に抽出できることが重要です。 ただし、コンテンツは、段落、表、画像などの複雑な要素で構成されている場合があります。
どのコンテンツを抽出する必要があるかにかかわらず、そのコンテンツを抽出する方法は、コンテンツを抽出するために選択されたノードによって常に決定されます。 これらは、テキスト本文全体または単純なテキスト実行にすることができます。
多くの可能な状況があるため、コンテンツを抽出する際に考慮すべき多くの異なるノードタイプがあります。 たとえば、次の間でコンテンツを抽出することができます:
状況によっては、段落とフィールドの間、または実行とブックマークの間のコンテンツの抽出など、異なるノードタイプを組み合わせる必要がある場合もあ
この記事では、異なるノード間でテキストを抽出するためのコード実装と、一般的なシナリオの例について説明します。
多くの場合、コンテンツを抽出する目的は、コンテンツを複製または新しいドキュメントに個別に保存することです。 たとえば、コンテンツを抽出することができます。:
これは、Aspose.Wordsと以下のコード実装を使用して簡単に実現できます。
このセクションのコードは、1つの一般化された再利用可能な方法で、上記のすべての状況に対処します。 この手法の一般的な概要には、次のものが含まれます:
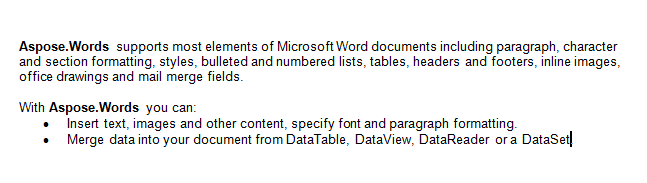
この記事では、以下の文書で作業します。 ご覧のとおり、さまざまなコンテンツが含まれています。 また、ドキュメントには最初のページの中央から始まる2番目のセクションが含まれていることに注意してください。 ブックマークとコメントはドキュメント内にも存在しますが、下のスクリーンショットには表示されません。

ドキュメントからコンテンツを抽出するには、以下のExtractContentメソッドを呼び出し、適切なパラメータを渡す必要があります。
この方法の基礎となる基礎には、ブロックレベルのノード(段落と表)を見つけて、それらを複製して同一のコピーを作成することが含まれます。 渡されたマーカーノードがブロックレベルの場合、メソッドはそのレベルのコンテンツを単純にコピーして配列に追加することができます。
ただし、マーカーノードがインライン(段落の子)の場合、インラインノードで段落を分割する必要があるため、状況はより複雑になります。 マーカーの間に存在しない複製された親ノード内のコンテンツは削除されます。 このプロセスは、インラインノードが親段落の書式設定を保持することを保証するために使用されます。
このメソッドは、パラメーターとして渡されたノードでもチェックを実行し、いずれかのノードが無効な場合は例外をスローします。 このメソッドに渡されるパラメータは次のとおりです:
StartNodeとEndNode。 最初の2つのパラメータは、コンテンツの抽出を開始する場所と終了する場所をそれぞれ定義するノードです。 これらのノードは、ブロックレベル(Paragraph、Table)またはインラインレベル(例:Run, FieldStart, BookmarkStart など。):
IsInclusive. マーカーが抽出に含まれるかどうかを定義します。 このオプションがfalseに設定されていて、同じノードまたは連続したノードが渡された場合、空のリストが返されます:
あなたが見つけることができるExtractContentメソッドの実装 ここに. この方法については、この記事のシナリオで説明します。
また、抽出されたノードからドキュメントを簡単に生成するためのカスタムメソッドも定義します。 このメソッドは、以下のシナリオの多くで使用され、単純に新しいドキュメントを作成し、抽出されたコンテンツをインポートします。
次のコード例は、ノードのリストを取得して新しいドキュメントに挿入する方法を示しています:
これは、上記の方法を使用して特定の段落間のコンテンツを抽出する方法を示しています。 この場合、文書の前半に見つかった文字の本文を抽出します。 これは7番目と11番目の段落の間にあることがわかります。
以下のコードは、このタスクを実行します。 適切な段落は、文書のgetChildメソッドを使用して抽出され、指定されたインデックスを渡します。 次に、これらのノードをExtractContentメソッドに渡し、これらが抽出に含まれることを示します。 このメソッドは、これらのノード間でコピーされたコンテンツを返し、新しいドキュメントに挿入します。
次のコード例は、上記のExtractContentメソッドを使用して特定の段落間のコンテンツを抽出する方法を示しています:
出力文書には、抽出された2つの段落が含まれています。
ブロックレベルノードまたはインラインノードの任意の組み合わせの間でコンテンツを抽出できます。 以下のこのシナリオでは、最初の段落と2番目のセクションのテーブルの間のコンテンツを包括的に抽出します。 適切なParagraphとTableノードを取得するために、文書の第二のセクションでgetFirstParagraphとgetChildメソッドを呼び出すことによってマーカーノードを取得します。 わずかな変化のために、代わりにコンテンツを複製し、元の下に挿入してみましょう。
次のコード例は、ExtractContentメソッドを使用して段落とテーブルの間のコンテンツを抽出する方法を示しています:
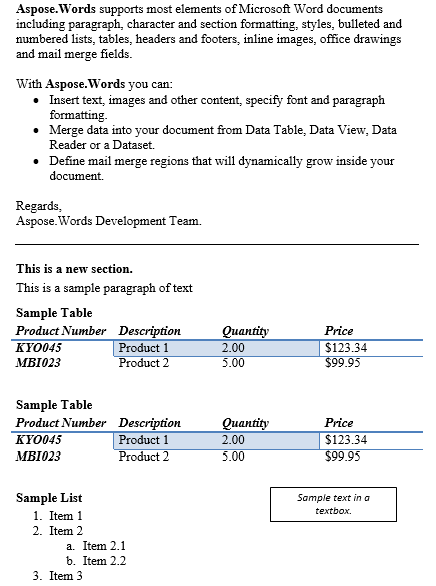
段落と表の間の内容が以下に複製された結果です。
見出しスタイルでマークされた段落間など、同じスタイルまたは異なるスタイルの段落間のコンテンツを抽出する必要がある場合があります。
以下のコードは、これを達成する方法を示しています。 これは、見出しも抽出せずに、“Heading 1"スタイルと"Header3"スタイルの最初のインスタンスの間のコンテンツを抽出する簡単な例です。 これを行うには、最後のパラメータをfalseに設定し、マーカーノードを含めるべきではないことを指定します。
適切な実装では、これをループで実行して、ドキュメントからこれらのスタイルのすべての段落の間のコンテンツを抽出する必要があります。 抽出されたコンテンツが新しいドキュメントにコピーされます。
次のコード例は、ExtractContentメソッドを使用して特定のスタイルを持つ段落間のコンテンツを抽出する方法を示しています:
以下は、前の操作の結果です。

Runなどのインラインノード間でコンテンツを抽出することもできます。 異なる段落のRunsをマーカーとして渡すことができます。 以下のコードは、同じParagraphノードの間にある特定のテキストを抽出する方法を示しています。
次のコード例は、ExtractContentメソッドを使用して、同じ段落の特定の実行間でコンテンツを抽出する方法を示しています:
抽出されたテキストがコンソールに表示されます。
フィールドをマーカーとして使用するには、FieldStartノードを渡す必要があります。 ExtractContentメソッドの最後のパラメータは、フィールド全体を含めるかどうかを定義します。 “FullName"差し込み項目と文書内の段落の間の内容を抽出してみましょう。 私たちはDocumentBuilderクラスのmoveToMergeFieldメソッドを使用します。 これにより、渡された差し込み項目の名前からFieldStartノードが返されます。
この例では、ExtractContentメソッドに渡された最後のパラメータをfalseに設定して、フィールドを抽出から除外しましょう。 抽出されたコンテンツをPDFにレンダリングします。
次のコード例は、ExtractContentメソッドを使用して、ドキュメント内の特定のフィールドと段落の間のコンテンツを抽出する方法を示しています:
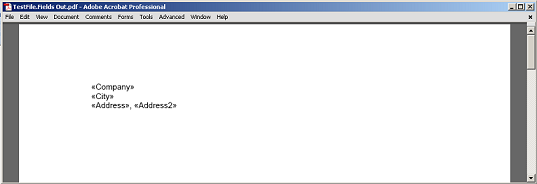
フィールドと段落のマーカーノードをPDFにレンダリングせずに、フィールドと段落の間に抽出されたコンテンツ。
ドキュメントでは、ブックマーク内で定義されているコンテンツは、BookmarkStartノードとBookmarkEndノードによってカプセル化されます。 これらの2つのノードの間にあるコンテンツがブックマークを構成します。 開始マーカーがドキュメント内の終了マーカーの前に表示されている限り、これらのノードのいずれかを任意のマーカーとして渡すことができます。
サンプルドキュメントには、“Bookmark1"という名前のブックマークが1つあります。 このブックマークの内容は、ドキュメント内のコンテンツを強調表示しています:
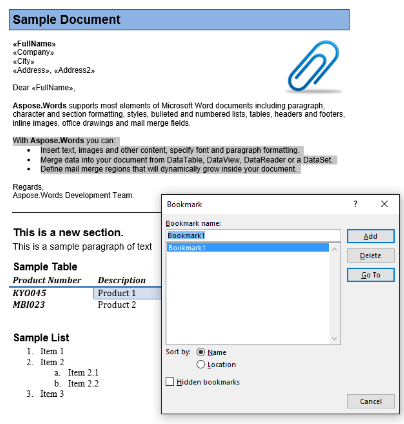
以下のコードを使用して、このコンテンツを新しいドキュメントに抽出します。 IsInclusiveパラメータオプションは、ブックマークを保持または破棄する方法を示します。
次のコード例は、ExtractContentメソッドを使用してブックマークを参照しているコンテンツを抽出する方法を示しています:
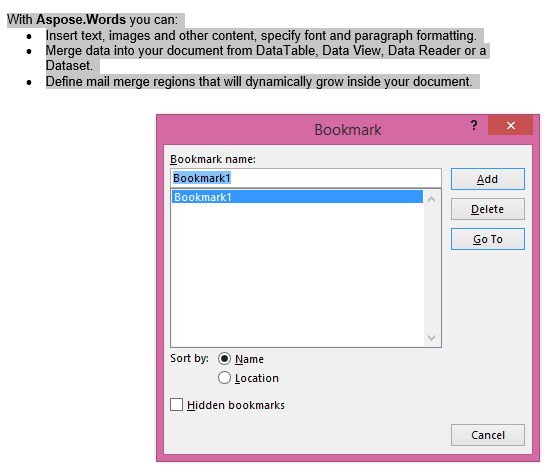
IsInclusiveパラメータがtrueに設定された抽出された出力。 コピーはブックマークも保持します。
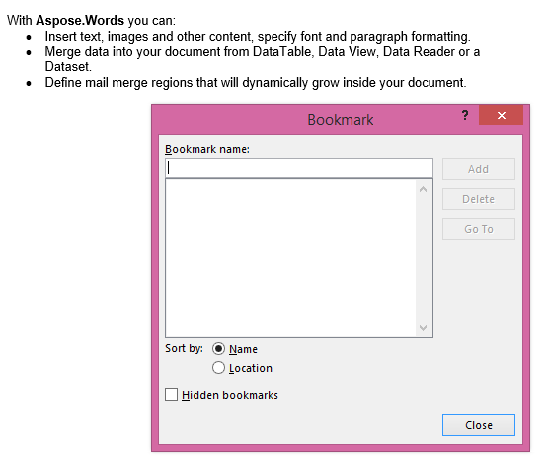
IsInclusiveパラメータがfalseに設定された抽出された出力。 コピーにはコンテンツが含まれていますが、ブックマークは含まれていません。
コメントは、CommentRangeStart、CommentRangeEnd、およびコメントノードで構成されます。 これらのノードはすべてインラインです。 最初の2つのノードは、下のスクリーンショットに示されているように、コメントによって参照されるドキュメント内のコンテンツをカプセル化します。
Commentノード自体は、段落と実行を含めることができるInlineStoryです。 これは、レビューペインでコメントバブルとして表示されるコメントのメッセージを表します。 このノードはインラインであり、本文の子孫であるため、このメッセージ内からコンテンツを抽出することもできます。
私たちの文書には1つのコメントがあります。 レビュータブにマークアップを表示して表示しましょう:
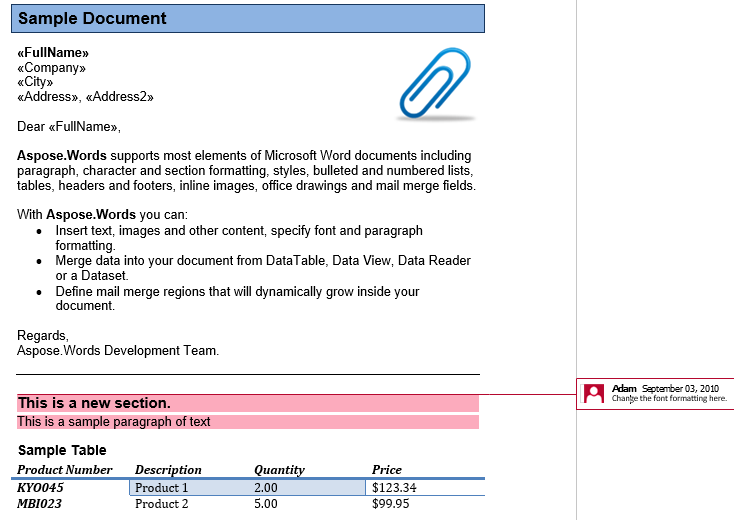
コメントは、見出し、最初の段落、および2番目のセクションのテーブルをカプセル化します。 このコメントを新しい文書に抽出しましょう。 IsInclusiveオプションは、コメント自体が保持されるか破棄されるかを指定します。
次のコード例は、これを行う方法を以下に示しています:
まず、IsInclusiveパラメータをtrueに設定して抽出された出力。 コピーにはコメントも含まれます。
次に、isInclusiveがfalseに設定された抽出された出力。 コピーにはコンテンツが含まれていますが、コメントは含まれていません。

Aspose.Wordsは、Microsoft Wordドキュメントを動的に構築したり、テンプレートをデータとマージしたりすることによって作成するだけでなく、ヘッダー、フッター、段落、表、画像などの別々のドキュメント要素を抽出するためにドキュメントを解析するためにも使用できます。 別の可能なタスクは、特定の書式設定またはスタイルのすべてのテキストを見つけることです。
この使用シナリオを実装するには、DocumentVisitorクラスを使用します。 このクラスは、よく知られている訪問者のデザインパターンに対応しています。 DocumentVisitorを使用すると、ドキュメントツリー上で列挙を必要とするカスタム操作を定義して実行できます。
DocumentVisitorは、特定のドキュメント要素(ノード)が検出されたときに呼び出されるVisitXXXメソッドのセットを提供します。 たとえば、テキスト段落の先頭が見つかったときにVisitParagraphStartが呼び出され、テキスト段落の末尾が見つかったときにVisitParagraphEndが呼び出されます。 各DocumentVisitor.VisitXXXメソッドは遭遇する対応するオブジェクトを受け入れるので、必要に応じて使用できます(たとえば、書式設定を取得します)。VisitParagraphStartとVisitParagraphEndの両方がParagraph
各DocumentVisitor.VisitXXXメソッドは、ノードの列挙を制御するVisitorAction値を返します。 列挙を続行するか、現在のノードをスキップする(ただし列挙を続行する)か、またはノードの列挙を停止するように要求できます。
次の手順は、ドキュメントのさまざまな部分をプログラムで決定して抽出するために実行する必要があります:
DocumentVisitorはすべてのDocumentVisitor.VisitXXXメソッドの既定の実装を提供します。 これにより、特定の訪問者に必要なメソッドのみをオーバーライドする必要があるため、新しいドキュメント訪問者を簡単に作成できます。 すべてのビジターメソッドをオーバーライドする必要はありません。
次の例は、ビジターパターンを使用してAspose.Wordsオブジェクトモデルに新しい操作を追加する方法を示しています。 この場合、単純なドキュメントコンバータをテキスト形式に作成します:
文書からテキストを取得する方法は次のとおりです:
SaveFormat.Textパラメータを渡します。 内部的には、これはsave as textをメモリストリームに呼び出し、結果の文字列を返しますNode.GetTextとNode.ToStringを使用するWord文書には、フィールド、セルの終わり、セクションの終わりなどの特別な要素を指定する制御文字を含めることができます。 使用可能な単語制御文字の完全なリストは、ControlCharクラスで定義されています。 GetTextメソッドは、ノード内に存在するすべての制御文字を含むテキストを返します。
ToStringを呼び出すと、制御文字を含まない文書のプレーンテキスト表現のみが返されます。 プレーンテキストとしてエクスポートする方法の詳細については、Using SaveFormat.Textを参照してください。
次のコード例は、ノードでGetTextメソッドとToStringメソッドを呼び出す際の違いを示しています:
SaveFormat.Textを使用するこの例では、次のようにドキュメントを保存します:
次のコード例は、ドキュメントをTXT形式で保存する方法を示しています:
いくつかのタスクを実行するには、ドキュメントイメージを抽出する必要がある場合があります。 Aspose.Wordsを使用すると、これも行うことができます。
次のコード例は、ドキュメントから画像を抽出する方法を示しています:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.