Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
문서 작업을 할 때는 문서 내의 특정 범위에서 콘텐츠를 쉽게 추출할 수 있어야 합니다. 그러나 내용은 단락,표,이미지 등과 같은 복잡한 요소로 구성 될 수 있습니다.
어떤 콘텐츠를 추출해야 하는지에 관계없이,그 콘텐츠를 추출하는 방법은 항상 어떤 노드가 콘텐츠를 추출하도록 선택되는지에 따라 결정됩니다. 전체 텍스트 본문 또는 간단한 텍스트 실행이 될 수 있습니다.
가능한 많은 상황이 있으므로 콘텐츠를 추출 할 때 고려해야 할 다양한 노드 유형이 있습니다. 예를 들어,다음 간의 콘텐츠를 추출할 수 있습니다:
경우에 따라 단락과 필드 사이 또는 실행과 책갈피 사이의 콘텐츠 추출과 같은 다른 노드 유형을 결합해야 할 수도 있습니다.
이 문서에서는 서로 다른 노드 간에 텍스트를 추출하기 위한 코드 구현과 일반적인 시나리오의 예를 제공합니다.
종종 콘텐츠를 추출하는 목표는 복제하거나 새 문서에 별도로 저장하는 것입니다. 예를 들어 콘텐츠를 추출하고:
이것은Aspose.Words과 아래의 코드 구현을 사용하여 쉽게 달성 할 수 있습니다.
이 섹션의 코드는 위에서 설명한 모든 가능한 상황을 하나의 일반화되고 재사용 가능한 방법으로 해결합니다. 이 기법의 일반적인 개요는:
이 기사의 아래 문서로 작업 할 것입니다. 당신이 볼 수 있듯이 그것은 다양한 콘텐츠가 포함되어 있습니다. 또한 이 문서에는 첫 페이지 중간에서 시작하는 두 번째 섹션이 포함되어 있습니다. 책갈피 및 주석도 문서에 있지만 아래 스크린샷에는 표시되지 않습니다.

문서에서 내용을 추출하려면 아래의ExtractContent메서드를 호출하고 적절한 매개 변수를 전달해야 합니다.
이 방법의 기본 기본은 블록 레벨 노드(단락 및 테이블)를 찾고 동일한 복사본을 만들기 위해 복제하는 것입니다. 만약 전달된 마커 노드가 블록 수준이라면,그 방법은 단순히 그 수준의 콘텐츠를 복사하고 배열에 추가할 수 있습니다.
그러나,마커 노드가 인라인(항의 자식)이라면,상황이 더 복잡해집니다.인라인 노드에서 단락을 분할해야 하기 때문에,실행,북마크 필드 등이 필요합니다. 마커 사이에 없는 복제된 부모 노드의 콘텐츠가 제거됩니다. 이 프로세스는 인라인 노드가 여전히 상위 단락의 서식을 유지하도록하는 데 사용됩니다.
이 메서드는 또한 매개 변수로 전달된 노드에 대한 검사를 실행하고 두 노드 중 하나가 유효하지 않은 경우 예외를 발생시킵니다. 이 메서드에 전달되는 매개 변수는 다음과 같습니다:
StartNode및EndNode. 첫 번째 두 매개 변수는 콘텐츠의 추출이 각각 시작되고 끝나는 곳을 정의하는 노드입니다. 이러한 노드는 블록 레벨(Paragraph,Table)또는 인라인 레벨(예:Run, FieldStart, BookmarkStart 그 밖의):
IsInclusive. 마커가 추출에 포함되는지 여부를 정의합니다. 이 옵션이 거짓으로 설정되어 있고 동일한 노드 또는 연속 노드가 전달되면 빈 목록이 반환됩니다:
ExtractContent메서드의 구현을 찾을 수 있습니다 여기. 이 메서드는 이 문서의 시나리오에서 설명합니다.
또한 추출 된 노드에서 문서를 쉽게 생성 할 수있는 사용자 정의 방법을 정의합니다. 이 방법은 아래의 많은 시나리오에서 사용되며 단순히 새 문서를 만들고 추출된 내용을 가져옵니다.
다음 코드 예제에서는 노드 목록을 가져와 새 문서에 삽입하는 방법을 보여 줍니다:
이것은 위의 방법을 사용하여 특정 단락 사이의 내용을 추출하는 방법을 보여줍니다. 이 경우,우리는 문서의 전반부에있는 편지의 본문을 추출 할 수 있습니다. 우리는 이것이 7 번째와 11 번째 단락 사이에 있음을 알 수 있습니다.
아래 코드는 이 작업을 수행합니다. 적절한 단락은 문서의getChild방법을 사용하여 추출되고 지정된 인덱스를 전달합니다. 그런 다음 이러한 노드를ExtractContent메서드에 전달하고 이러한 노드가 추출에 포함되어야 한다고 명시합니다. 이 메서드는 이러한 노드 간에 복사된 콘텐츠를 반환한 다음 새 문서에 삽입합니다.
다음 코드 예제에서는 위의ExtractContent방법을 사용하여 특정 단락 간의 내용을 추출하는 방법을 보여 줍니다:
출력 문서에는 추출된 두 단락이 포함되어 있습니다.
블록 수준 또는 인라인 노드의 모든 조합간에 콘텐츠를 추출 할 수 있습니다. 아래의 이 시나리오에서는 첫 번째 단락과 두 번째 섹션의 표 사이의 내용을 포괄적으로 추출합니다. 문서의 두 번째 섹션에서getFirstParagraph및getChild메서드를 호출하여 적절한Paragraph및Table노드를 검색하여 마커 노드를 얻습니다. 약간의 변화를 위해 대신 내용을 복제하고 원본 아래에 삽입 할 수 있습니다.
다음 코드 예제에서는ExtractContent메서드를 사용하여 단락과 테이블 간의 내용을 추출하는 방법을 보여 줍니다:
아래의 단락과 표 사이의 내용이 복제되었습니다.
제목 스타일로 표시된 단락과 같이 동일하거나 다른 스타일의 단락 간에 내용을 추출해야 할 수 있습니다.
아래 코드는 이를 달성하는 방법을 보여줍니다. 이것은"Heading 1"과"헤더 3"스타일의 첫 번째 인스턴스 사이의 내용을 추출하는 간단한 예입니다. 이를 위해 마지막 매개 변수를 거짓으로 설정합니다.이 매개 변수는 마커 노드가 포함되지 않도록 지정합니다.
적절한 구현에서,이것은 문서에서 이러한 스타일의 모든 단락 사이의 내용을 추출하기 위해 루프에서 실행되어야합니다. 추출된 콘텐츠가 새 문서에 복사됩니다.
다음 코드 예제에서는ExtractContent메서드를 사용하여 특정 스타일의 단락 간에 콘텐츠를 추출하는 방법을 보여 줍니다:
아래는 이전 작업의 결과입니다.

Run와 같은 인라인 노드 간에 콘텐츠를 추출할 수도 있습니다. Runs다른 단락에서 마커로 전달할 수 있습니다. 아래 코드는 동일한Paragraph노드 사이의 특정 텍스트를 추출하는 방법을 보여줍니다.
다음 코드 예제에서는ExtractContent메서드를 사용하여 동일한 단락의 특정 실행 간에 콘텐츠를 추출하는 방법을 보여 줍니다:
추출된 텍스트가 콘솔에 표시됩니다.
필드를 마커로 사용하려면FieldStart노드를 전달해야 합니다. ExtractContent메서드의 마지막 매개 변수는 전체 필드를 포함할지 여부를 정의합니다. “FullName"병합 필드와 문서의 단락 사이의 내용을 추출해 보겠습니다. 우리는DocumentBuilder클래스의moveToMergeField메소드를 사용합니다. 그러면 전달된 병합 필드의 이름에서FieldStart노드가 반환됩니다.
이 경우ExtractContent메서드에 전달된 마지막 매개 변수를 거짓으로 설정하여 필드를 추출에서 제외합니다. 추출된 내용을PDF로 렌더링합니다.
다음 코드 예제에서는ExtractContent방법을 사용하여 문서의 특정 필드와 단락 간에 콘텐츠를 추출하는 방법을 보여 줍니다:
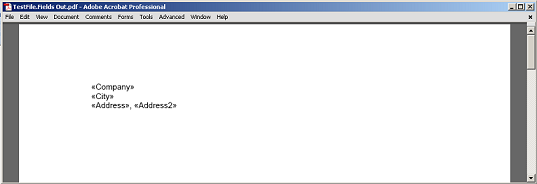
필드 및 단락 마커 노드가PDF으로 렌더링되지 않은 필드와 단락 사이의 추출된 콘텐츠입니다.
문서에서 책갈피 내에 정의된 콘텐츠는BookmarkStart및BookmarkEnd노드에 의해 캡슐화됩니다. 이 두 노드 사이에 있는 콘텐츠가 책갈피를 구성합니다. 문서의 끝 마커 앞에 시작 마커가 나타나는 한 이러한 노드 중 하나를 다른 책갈피의 마커로 전달할 수 있습니다.
샘플 문서에는"북마크 1"이라는 책갈피가 하나 있습니다. 이 책갈피의 내용은 문서에서 강조 표시된 내용입니다:
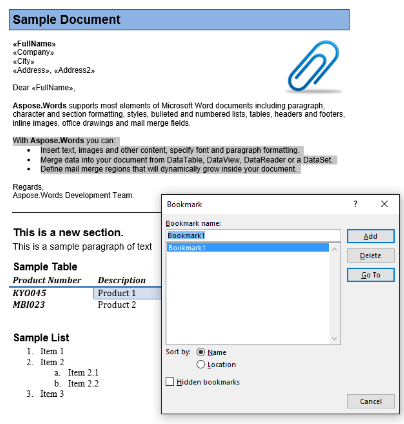
아래 코드를 사용하여 이 콘텐츠를 새 문서로 추출합니다. IsInclusive매개 변수 옵션은 책갈피를 유지하거나 삭제하는 방법을 보여줍니다.
다음 코드 예제에서는ExtractContent방법을 사용하여 책갈피에 참조된 콘텐츠를 추출하는 방법을 보여 줍니다:
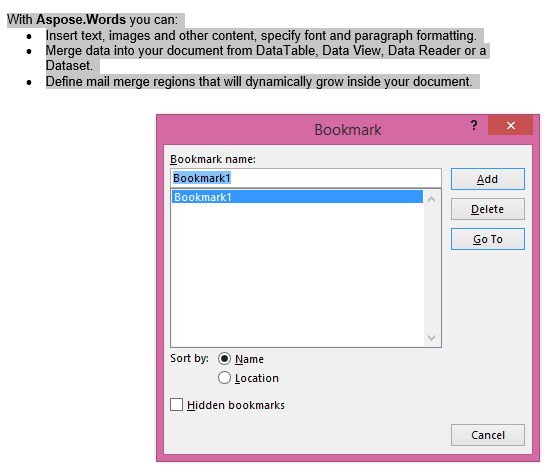
IsInclusive매개 변수가 참으로 설정된 추출된 출력입니다. 복사본도 책갈피를 유지합니다.
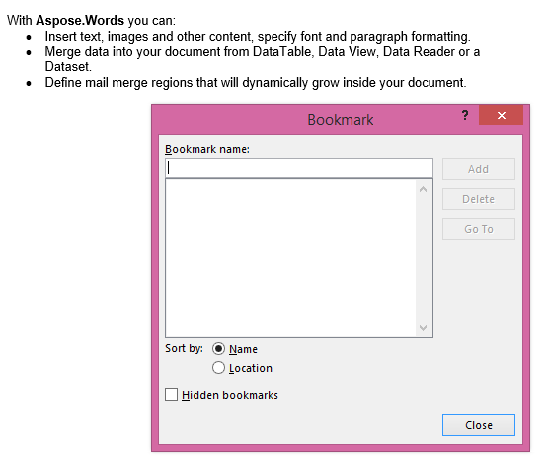
IsInclusive매개 변수가 거짓으로 설정된 추출된 출력입니다. 복사본에는 내용이 포함되어 있지만 책갈피는 없습니다.
주석은CommentRangeStart,CommentRangeEnd및 주석 노드로 구성됩니다. 이 모든 노드는 인라인입니다. 첫 번째 두 노드는 아래 스크린샷에서 볼 수 있듯이 코멘트에서 참조하는 문서의 내용을 캡슐화합니다.
Comment노드 자체는 단락과 실행을 포함할 수 있는InlineStory입니다. 검토 창에서 주석 거품으로 표시되는 주석의 메시지를 나타냅니다. 이 노드는 인라인 및 본문의 자손으로 당신은 또한뿐만 아니라이 메시지 내부의 내용을 추출 할 수 있습니다.
우리 문서에는 한 가지 의견이 있습니다. 검토 탭에 마크업을 표시하여 표시해 보겠습니다:
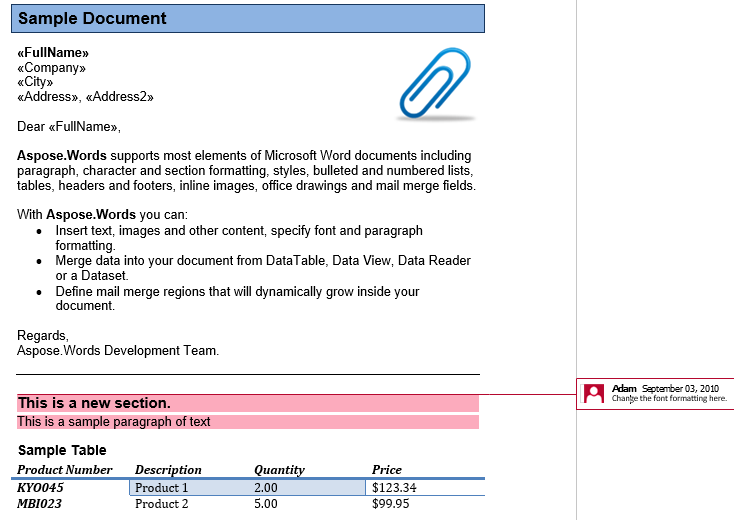
주석은 제목,첫 번째 단락 및 두 번째 섹션의 테이블을 캡슐화합니다. 이 주석을 새 문서로 추출해 보겠습니다. IsInclusive옵션은 주석 자체가 유지되거나 삭제되는지 여부를 지정합니다.
다음 코드 예제에서는 이 작업을 수행하는 방법을 보여 줍니다:
먼저IsInclusive매개변수가 참으로 설정된 추출된 출력입니다. 복사본에는 주석도 포함됩니다.
둘째,isInclusive이 거짓으로 설정된 추출된 출력입니다. 복사본에는 내용이 포함되어 있지만 주석은 없습니다.

Aspose.Words은Microsoft Word문서를 동적으로 작성하거나 템플릿과 데이터를 병합하여 만들 뿐만 아니라 머리글,바닥글,단락,표,이미지 등과 같은 별도의 문서 요소를 추출하기 위해 문서를 구문 분석하는 데에도 사용할 수 있습니다. 또 다른 가능한 작업은 특정 서식 또는 스타일의 모든 텍스트를 찾는 것입니다.
DocumentVisitor클래스를 사용하여 이 사용 시나리오를 구현합니다. 이 클래스는 잘 알려진 방문자 디자인 패턴에 해당합니다. DocumentVisitor을 사용하면 문서 트리에 대한 열거가 필요한 사용자 지정 작업을 정의하고 실행할 수 있습니다.
DocumentVisitor는 특정 문서 요소(노드)가 발견되면 호출되는 VisitXXX 메서드 세트를 제공합니다. 예를 들어, VisitParagraphStart은 텍스트 문단의 시작이 발견되면 호출되고 VisitParagraphEnd은 텍스트 문단의 끝이 발견되면 호출됩니다. 각 DocumentVisitor.VisitXXX 메서드는 발견되는 해당 객체를 수락하므로 필요에 따라 사용할 수 있습니다(예: 서식 검색). 예를 들어 VisitParagraphStart과 VisitParagraphEnd은 모두 Paragraph 객체를 수락합니다.
각DocumentVisitor.VisitXXX메서드는 노드 열거를 제어하는VisitorAction값을 반환합니다. 열거형을 계속하거나,현재 노드를 건너뛰거나(열거형을 계속),노드 열거형을 중지하도록 요청할 수 있습니다.
다음은 문서의 여러 부분을 프로그래밍 방식으로 결정하고 추출하기 위해 따라야 할 단계입니다:
DocumentVisitor은 모든DocumentVisitor.VisitXXX메소드에 대한 기본 구현을 제공합니다. 이렇게 하면 특정 방문자에 필요한 메서드만 재정의해야 하므로 새 문서 방문자를 쉽게 만들 수 있습니다. 모든 방문자 메서드를 재정의할 필요는 없습니다.
다음 예제에서는 방문자 패턴을 사용하여Aspose.Words개체 모델에 새 작업을 추가하는 방법을 보여 줍니다. 이 경우 간단한 문서 변환기를 텍스트 형식으로 만듭니다:
문서에서 텍스트를 검색하는 방법은 다음과 같습니다:
SaveFormat.Text매개 변수를 전달합니다. 내부적으로,이 메모리 스트림에 텍스트로 저장을 호출하고 결과 문자열을 반환합니다Node.GetText및Node.ToString사용워드 문서에는 필드,셀 끝,섹션 끝 등과 같은 특수 요소를 지정하는 제어 문자가 포함될 수 있습니다. 가능한 단어 제어 문자의 전체 목록은ControlChar클래스에서 정의됩니다. GetText메서드는 노드에 있는 모든 컨트롤 문자 문자가 있는 텍스트를 반환합니다.
ToString을 호출하면 컨트롤 문자 없이 문서의 일반 텍스트 표현만 반환됩니다. 일반 텍스트로 내보내는 방법에 대한 자세한 내용은Using SaveFormat.Text을 참조하십시오.
다음 코드 예제에서는 노드에서GetText메서드와ToString메서드를 호출하는 간의 차이점을 보여 줍니다:
SaveFormat.Text사용이 예제에서는 다음과 같이 문서를 저장합니다:
다음 코드 예제에서는TXT형식으로 문서를 저장하는 방법을 보여 줍니다:
일부 작업을 수행하려면 문서 이미지를 추출해야 할 수 있습니다. Aspose.Words이 작업을 수행 할 수 있습니다.
다음 코드 예제에서는 문서에서 이미지를 추출하는 방법을 보여 줍니다:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.