Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
Bij het werken met documenten is het belangrijk om inhoud binnen een document gemakkelijk uit een specifiek bereik te halen. De inhoud kan echter bestaan uit complexe elementen zoals paragrafen, tabellen, afbeeldingen, enz.
Ongeacht welke inhoud moet worden gewonnen, de methode om dat gehalte te extraheren zal altijd worden bepaald door welke knooppunten worden geselecteerd om inhoud tussen te extraheren. Dit kunnen hele tekstlichamen zijn of eenvoudige tekstruns.
Er zijn veel mogelijke situaties en daarom veel verschillende knooppunttypes te overwegen bij het extraheren van inhoud. U kunt bijvoorbeeld inhoud uitpakken tussen:
In sommige situaties moet je zelfs verschillende knooppunttypes combineren, zoals inhoud extraheren tussen een alinea en een veld, of tussen een run en een bladwijzer.
Dit artikel geeft de code implementatie voor het extraheren van tekst tussen verschillende knooppunten, evenals voorbeelden van gemeenschappelijke scenario’s.
Vaak is het doel van het extraheren van de inhoud om het apart te dupliceren of op te slaan in een nieuw document. U kunt bijvoorbeeld inhoud extraheren en:
Dit kan gemakkelijk worden bereikt met behulp van Aspose.Words en de implementatie van de code hieronder.
De code in deze sectie behandelt alle hierboven beschreven situaties met één algemene en herbruikbare methode. De algemene opzet van deze techniek omvat:
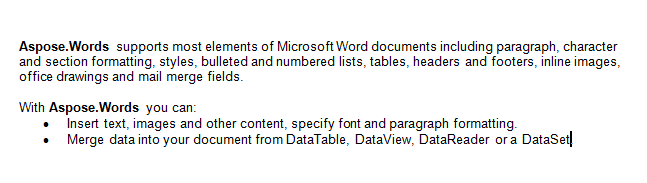
We werken met het document hieronder in dit artikel. Zoals je kunt zien bevat het een verscheidenheid aan inhoud. Let ook op, het document bevat een tweede sectie beginnend in het midden van de eerste pagina. Een bladwijzer en commentaar zijn ook aanwezig in het document, maar zijn niet zichtbaar in de screenshot hieronder.

Om de inhoud uit uw document te halen moet u de ExtractContent methode hieronder en geef de juiste parameters door.
De onderliggende basis van deze methode is het vinden van knooppunten op blokniveau (paragrafen en tabellen) en het klonen ervan om identieke kopieën te maken. Als de aangegeven knooppunten blok-niveau zijn dan is de methode in staat om gewoon de inhoud op dat niveau te kopiëren en toe te voegen aan de array.
Echter, als de marker knooppunten zijn inline (een kind van een alinea) dan wordt de situatie complexer, omdat het nodig is om de paragraaf op de inline knooppunt te splitsen, of het nu een run, bladwijzer velden etc. Inhoud in de gekloonde ouderknooppunten die niet aanwezig zijn tussen de markers wordt verwijderd. Dit proces wordt gebruikt om ervoor te zorgen dat de inline-knooppunten de opmaak van de alinea van de moeder blijven behouden.
De methode zal ook controles uitvoeren op de knooppunten doorgegeven als parameters en gooit een uitzondering als beide knooppunten ongeldig is. De parameters die aan deze methode moeten worden doorgegeven zijn:
StartNode en EndNode. De eerste twee parameters zijn de knooppunten die bepalen waar de extractie van de inhoud begint en eindigt op respectievelijk. Deze knooppunten kunnen zowel blokniveau (Paragraph , Table ) of inlineniveau (bv. Run , FieldStart , BookmarkStart enz.):
IsInclusive. Bepaalt of de markeringen al dan niet in de extractie zijn opgenomen. Als deze optie ingesteld is false en dezelfde knoop of opeenvolgende knooppunten worden doorgegeven, dan zal een lege lijst worden teruggegeven:
De tenuitvoerlegging van het ExtractContent methode kunt u vinden Hier. Deze methode zal in de scenario’s in dit artikel worden genoemd.
We zullen ook een aangepaste methode definiëren om gemakkelijk een document te genereren van uitgepakte knooppunten. Deze methode wordt gebruikt in veel van de onderstaande scenario’s en maakt gewoon een nieuw document en importeert de gewonnen inhoud in het.
Het volgende voorbeeld van code laat zien hoe je een lijst van knooppunten neemt en ze in een nieuw document invoegt:
Hieruit blijkt hoe de hierboven beschreven methode moet worden gebruikt om het gehalte tussen specifieke paragrafen te extraheren. In dit geval willen we de inhoud van de brief uit de eerste helft van het document halen. We kunnen zien dat dit tussen de 7e en 11e alinea’s ligt.
De onderstaande code vervult deze taak. De desbetreffende alinea’s worden met behulp van de getChild methode op het document en het doorgeven van de gespecificeerde indices. Vervolgens geven we deze knooppunten door aan de ExtractContent methode en vermelden dat deze in de extractie moeten worden opgenomen. Deze methode zal de gekopieerde inhoud tussen deze knooppunten teruggeven die vervolgens in een nieuw document worden ingevoegd.
Het volgende voorbeeld van code laat zien hoe de inhoud tussen specifieke alinea’s met behulp van de ExtractContent methode hierboven:
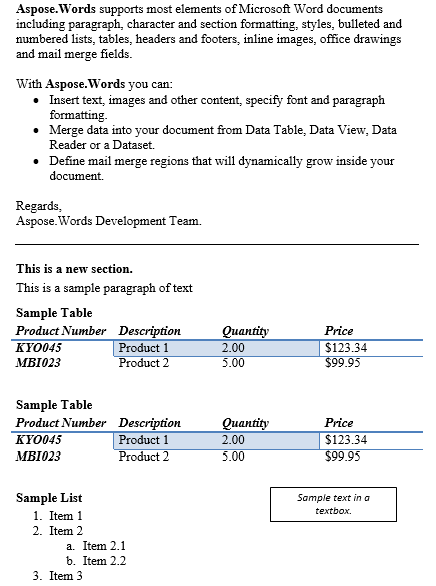
Het uitvoerdocument bevat de twee alinea’s die eruit zijn gehaald.
We kunnen inhoud extraheren tussen combinaties van blok-niveau of inline knooppunten. In dit scenario hieronder zullen we de inhoud tussen de eerste alinea en de tabel in het tweede deel inclusief extraheren. We krijgen de markers knooppunten door te bellen getFirstParagraph en getChild methode op het tweede deel van het document om de juiste Paragraph en Table knooppunten. Voor een lichte variatie laten we de inhoud dupliceren en onder het origineel plaatsen.
Het volgende voorbeeld van code laat zien hoe de inhoud tussen een alinea en een tabel met behulp van de ExtractContent methode:
De inhoud tussen de alinea en de tabel is hieronder gedupliceerd is het resultaat.
Het kan nodig zijn om de inhoud te extraheren tussen paragrafen van dezelfde of andere stijl, zoals tussen paragrafen gemarkeerd met kopstijlen.
De onderstaande code laat zien hoe dit te bereiken. Het is een eenvoudig voorbeeld dat de inhoud zal extraheren tussen de eerste instantie van de “Heading 1” en “Header 3” stijlen zonder ook de rubrieken te extraheren. Om dit te doen zetten we de laatste parameter op false, waarin staat dat de markerknooppunten niet mogen worden opgenomen.
Bij een correcte implementatie moet dit in een lus worden uitgevoerd om inhoud tussen alle paragrafen van deze stijlen uit het document te halen. De gewonnen inhoud wordt gekopieerd naar een nieuw document.
Het volgende voorbeeld van code laat zien hoe inhoud tussen paragrafen met specifieke stijlen met behulp van de ExtractContent methode:
Hieronder is het resultaat van de vorige bewerking.

U kunt inhoud extraheren tussen inline knooppunten zoals een Run Ook. Runs van verschillende paragrafen kan worden doorgegeven als markers. De onderstaande code laat zien hoe je een specifieke tekst tussen dezelfde Paragraph Node.
Het volgende voorbeeld van code laat zien hoe je inhoud tussen specifieke runs van dezelfde paragraaf met behulp van de ExtractContent methode:
De opgehaalde tekst wordt op de console weergegeven
Om een veld als marker te gebruiken, de FieldStart knooppunt moet worden doorgegeven. De laatste parameter voor de ExtractContent methode zal bepalen of het gehele veld moet worden opgenomen of niet. Laten we de inhoud uitpakken tussen het veld “FullName” en een paragraaf in het document. Wij gebruiken de moveToMergeField DocumentBuilder Klasse. Dit zal de FieldStart knooppunt van de naam van het merge veld doorgegeven aan het.
In ons geval laten we de laatste parameter die aan de ExtractContent methode om false om het veld van de extractie uit te sluiten. We zullen de gewonnen inhoud naar PDF teruggeven.
Het volgende voorbeeld van code laat zien hoe inhoud tussen een specifiek veld en paragraaf in het document te extraheren met behulp van de ExtractContent methode:
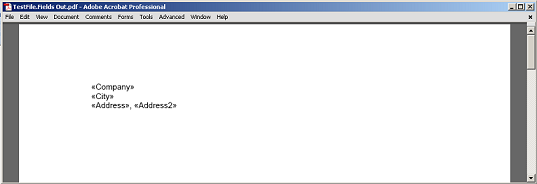
De verzamelde inhoud tussen het veld en de alinea, zonder het veld en de puntmarkeringsknooppunten die aan PDF zijn weergegeven.
In een document wordt de inhoud die wordt gedefinieerd binnen een bladwijzer ingekapseld door de BookmarkStart en BookmarkEnd knooppunten. De inhoud tussen deze twee knooppunten vormt de bladwijzer. Je kunt een van deze knooppunten doorgeven als een markeerder, zelfs die van verschillende bladwijzers, zolang de beginmarkering verschijnt voor de eindmarkering in het document.
In ons voorbeeld document, hebben we een bladwijzer, genaamd Bookmark1. De inhoud van deze bladwijzer is gemarkeerd in ons document:
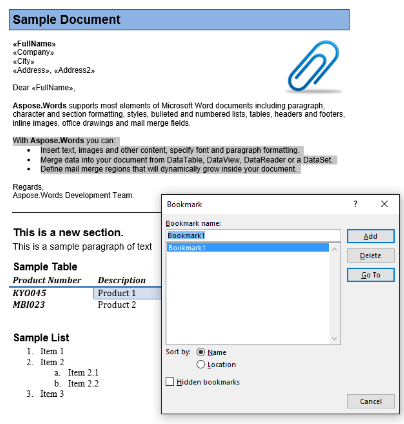
We zullen deze inhoud uitpakken in een nieuw document met de onderstaande code. De IsInclusive parameteroptie laat zien hoe u de bladwijzer kunt behouden of weggooien.
Het volgende voorbeeld van code toont hoe u de inhoud waarnaar een bladwijzer verwijst kunt uitpakken met behulp van de ExtractContent methode:
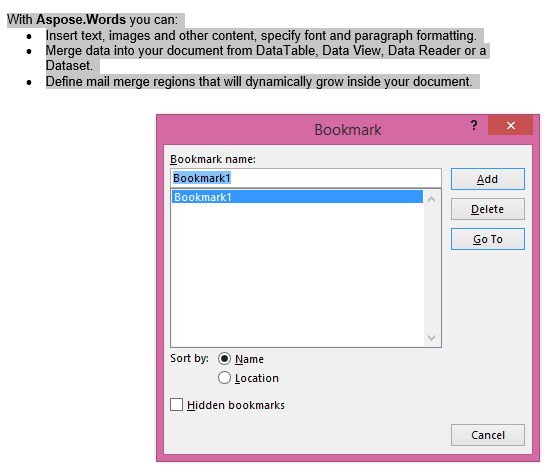
De gewonnen output met de IsInclusive parameter ingesteld op true. De kopie zal ook de bladwijzer behouden.
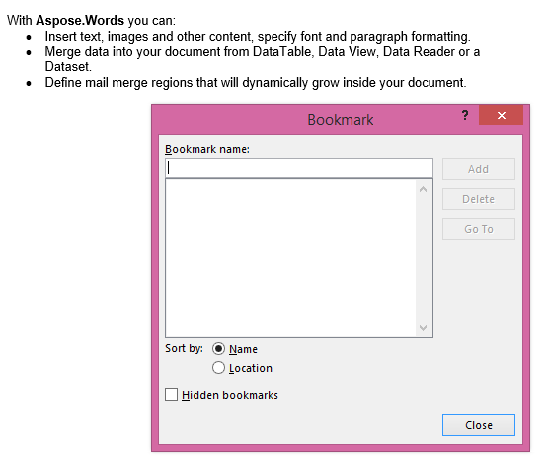
De gewonnen output met de IsInclusive parameter ingesteld op false. De kopie bevat de inhoud maar zonder de bladwijzer.
Een commentaar bestaat uit de reactieRangeStart, reactieRangeEnd en commentaar knooppunten. Al deze knopen zijn inline. De eerste twee nodes inkapselen de inhoud in het document die wordt verwezen door het commentaar, zoals te zien in de screenshot hieronder.
De Comment knooppunt zelf is een InlineStory die alinea’s en runs kunnen bevatten. Het vertegenwoordigt de boodschap van het commentaar als een commentaarbel in het herzieningspaneel. Aangezien dit knooppunt inline is en een afstammeling van een lichaam kun je ook de inhoud uit deze boodschap halen.
In ons document hebben we één opmerking. Laat het weergeven door markup te tonen in het tabblad Beoordeling:
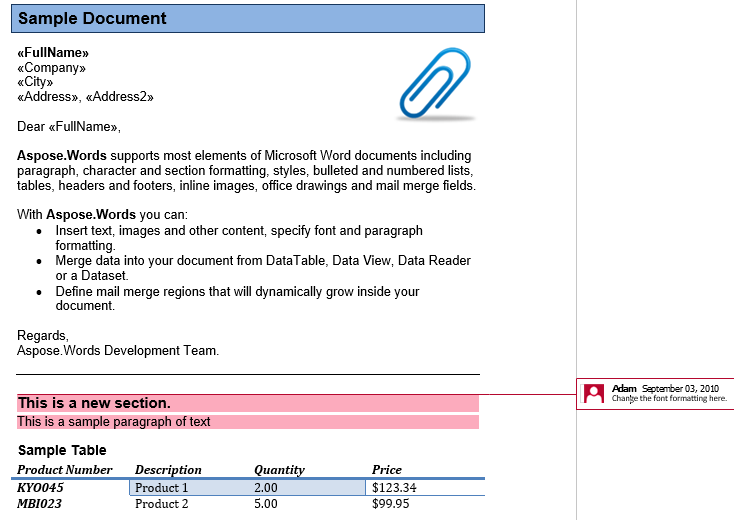
Het commentaar omvat de titel, eerste alinea en de tabel in het tweede deel. Laten we deze opmerking uitpakken in een nieuw document. De IsInclusive optie dicteert als het commentaar zelf wordt gehouden of weggegooid.
Het volgende voorbeeld van code laat zien hoe dit te doen is hieronder:
In de eerste plaats de gewonnen output met de IsInclusive parameter ingesteld op true. De kopie zal ook het commentaar bevatten.
In de tweede plaats is de gewonnen output met isInclusief ingesteld op false. De kopie bevat de inhoud maar zonder commentaar.

Aspose.Words kan niet alleen worden gebruikt voor het aanmaken Microsoft Word documenten door ze dynamisch te bouwen of templates te samenvoegen met gegevens, maar ook voor het ontleden van documenten om afzonderlijke documentelementen zoals headers, voetteksten, paragrafen, tabellen, afbeeldingen en andere te extraheren. Een andere mogelijke taak is het vinden van alle tekst van specifieke opmaak of stijl.
Gebruik de DocumentVisitor klasse om dit gebruiksscenario te implementeren. Deze klasse komt overeen met het bekende bezoekersontwerppatroon. Met DocumentVisitorU kunt aangepaste bewerkingen definiëren en uitvoeren die een opsomming over de documentboom vereisen.
DocumentVisitor levert een reeks van VisitXXX methoden die worden gebruikt wanneer een bepaald documentelement (knooppunt) wordt aangetroffen. Bijvoorbeeld, VisitParagraphStart wordt aangeroepen wanneer het begin van een tekst paragraaf wordt gevonden en VisitParagraphEnd wordt aangeroepen wanneer het einde van een tekst paragraaf wordt gevonden. Elk DocumentVisitor.VisitXXX methode accepteert het bijbehorende object dat het tegenkomt, zodat u het kunt gebruiken als nodig (zeg het ophalen van de opmaak), bijvoorbeeld beide VisitParagraphStart en VisitParagraphEnd a Paragraph object.
Elk DocumentVisitor.VisitXXX methode geeft a VisitorAction waarde die de opsomming van knooppunten regelt. U kunt verzoeken de opsomming voort te zetten, het huidige knooppunt over te slaan (maar door te gaan met de opsomming), of de opsomming van knooppunten te stoppen.
Dit zijn de stappen die u moet volgen om programmatisch verschillende delen van een document te bepalen en uit te pakken:
DocumentVisitor biedt standaard implementaties voor alle van de DocumentVisitor.VisitXXX methoden. Dit maakt het makkelijker om nieuwe documentbezoekers te creëren, aangezien alleen de methoden die voor de specifieke bezoeker nodig zijn, overschreven moeten worden. Het is niet nodig om alle bezoekersmethoden te omzeilen.
Het volgende voorbeeld laat zien hoe u het Bezoekerspatroon gebruikt om nieuwe bewerkingen toe te voegen aan de Aspose.Words objectmodel. In dit geval maken we een eenvoudige documentconverter in een tekstformaat:
De manieren om tekst uit het document op te halen zijn:
SaveFormat.Text parameter. Intern, dit aanroepen opslaan als tekst in een geheugenstroom en geeft de resulterende stringNode.GetText en Node.ToStringA Word-document kan controle karakters die speciale elementen zoals veld, einde van de cel, einde van sectie, enz. aan te duiden bevatten. De volledige lijst van mogelijke Word control tekens wordt gedefinieerd in de ControlChar Klasse. De GetText methode geeft tekst terug met alle controle karakter tekens aanwezig in het knooppunt.
Aanroepen ToString geeft de platte tekstweergave van het document alleen terug zonder controletekens. Voor meer informatie over export als platte tekst zie Using SaveFormat.Text.
Het volgende voorbeeld toont het verschil tussen het aanroepen van de GetText en ToString methoden op een knooppunt:
SaveFormat.TextDit voorbeeld slaat het document als volgt op:
Het volgende voorbeeld van code laat zien hoe een document in TXT-formaat kan worden opgeslagen:
Het kan nodig zijn om documentafbeeldingen uit te pakken om enkele taken uit te voeren. Aspose.Words laat je dit ook doen.
Het volgende voorbeeld van code laat zien hoe je afbeeldingen uit een document haalt:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.