Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
При работе с документами важно иметь возможность легко извлекать содержимое из определенного диапазона в документе. Однако содержимое может состоять из сложных элементов, таких как абзацы, таблицы, изображения и т.д.
Независимо от того, какой контент необходимо извлечь, метод извлечения этого контента всегда будет определяться тем, какие узлы выбраны для извлечения содержимого между ними. Это могут быть целые текстовые фрагменты или простые текстовые фрагменты.
Существует множество возможных ситуаций и, следовательно, множество различных типов узлов, которые следует учитывать при извлечении содержимого. Например, вы можете захотеть извлечь содержимое между:
В некоторых ситуациях вам может даже потребоваться объединить различные типы узлов, например, для извлечения содержимого из абзаца и поля или из запуска и закладки.
В этой статье приводится реализация кода для извлечения текста между различными узлами, а также примеры распространенных сценариев.
Часто целью извлечения содержимого является дублирование или сохранение его отдельно в новом документе. Например, вы можете извлечь содержимое и:
Этого можно легко достичь, используя Aspose.Words и приведенную ниже реализацию кода.
Приведенный в этом разделе код рассматривает все возможные ситуации, описанные выше, с помощью одного обобщенного метода, который можно использовать повторно. В общих чертах этот метод включает:
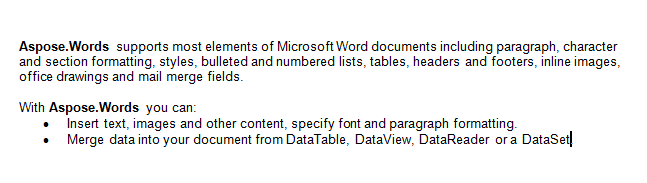
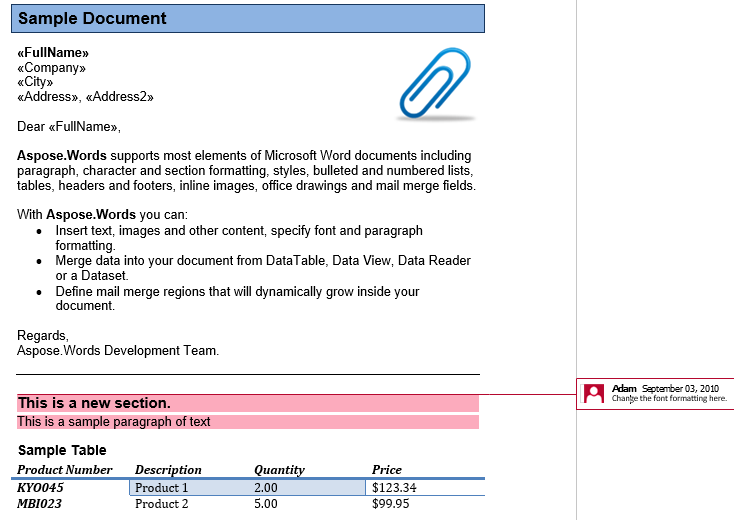
В этой статье мы будем работать с документом, представленным ниже. Как вы можете видеть, он содержит разнообразный контент. Также обратите внимание, что документ содержит второй раздел, начинающийся с середины первой страницы. Закладка и комментарий также присутствуют в документе, но не видны на скриншоте ниже.

Чтобы извлечь содержимое из вашего документа, вам нужно вызвать метод ExtractContent, приведенный ниже, и передать соответствующие параметры.
В основе этого метода лежит поиск узлов на уровне блоков (абзацев и таблиц) и их клонирование для создания идентичных копий. Если переданные маркерные узлы относятся к уровню блоков, то метод может просто скопировать содержимое на этом уровне и добавить его в массив.
Однако, если узлы-маркеры являются встроенными (дочерними по отношению к абзацу), ситуация становится более сложной, поскольку необходимо разделить абзац на встроенном узле, будь то прогон, поля закладок и т.д. Содержимое в клонированных родительских узлах, отсутствующее между маркерами, удаляется. Этот процесс используется для обеспечения того, чтобы встроенные узлы по-прежнему сохраняли форматирование родительского абзаца.
Метод также выполняет проверку узлов, переданных в качестве параметров, и генерирует исключение, если какой-либо из узлов является недопустимым. В этот метод передаются следующие параметры:
StartNode и EndNode. Первые два параметра - это узлы, которые определяют, где должно начинаться и заканчиваться извлечение содержимого соответственно. Эти узлы могут быть как блочного уровня (Paragraph, Table ), так и встроенного (например, Run, FieldStart, BookmarkStart и т.д.).:
IsInclusive. Определяет, будут ли маркеры включены в извлечение или нет. Если для этого параметра установлено значение false и передается один и тот же узел или последовательные узлы, то будет возвращен пустой список:
Реализацию метода ExtractContent вы можете найти здесь. Этот метод будет описан в сценариях, описанных в этой статье.
Мы также определим пользовательский метод, позволяющий легко создавать документ из извлеченных узлов. Этот метод используется во многих сценариях, описанных ниже, и просто создает новый документ и импортирует в него извлеченное содержимое.
В следующем примере кода показано, как взять список узлов и вставить их в новый документ:
Это демонстрирует, как использовать описанный выше метод для извлечения содержимого между определенными абзацами. В данном случае мы хотим извлечь текст письма, найденного в первой половине документа. Мы можем сказать, что это между 7-м и 11-м абзацами.
Приведенный ниже код выполняет эту задачу. Соответствующие абзацы извлекаются с использованием метода getChild в документе и с передачей указанных индексов. Затем мы передаем эти узлы методу ExtractContent и указываем, что они должны быть включены в извлечение. Этот метод вернет скопированное содержимое между этими узлами, которое затем будет вставлено в новый документ.
В следующем примере кода показано, как извлечь содержимое между определенными абзацами, используя метод ExtractContent, описанный выше:
Итоговый документ содержит два абзаца, которые были извлечены из него.
Мы можем извлекать содержимое между любыми комбинациями узлов на уровне блоков или встроенных узлов. В приведенном ниже сценарии мы будем извлекать содержимое между первым абзацем и таблицей во втором разделе включительно. Мы получаем узлы-маркеры, вызывая методы getFirstParagraph и getChild во втором разделе документа, чтобы получить соответствующие узлы Paragraph и Table. Для небольшого изменения давайте вместо этого продублируем содержимое и вставим его под оригинал.
В следующем примере кода показано, как извлечь содержимое из абзаца и таблицы с помощью метода ExtractContent:
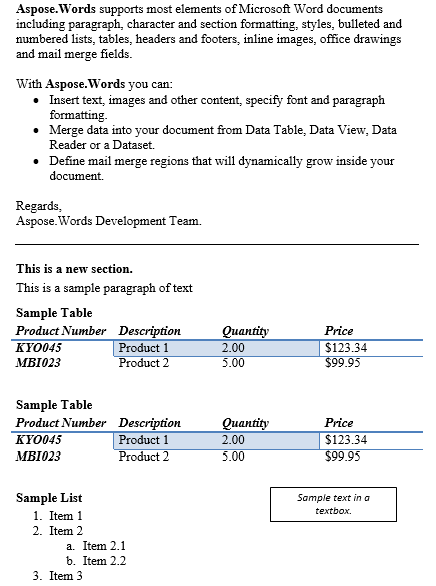
Содержание между абзацем и таблицей было продублировано, ниже приведен результат.
Возможно, вам потребуется извлечь содержимое между абзацами одного и того же или разного стиля, например, между абзацами, помеченными стилями заголовков.
Приведенный ниже код показывает, как этого добиться. Это простой пример, который позволяет извлекать содержимое между первым экземпляром стилей “Heading 1” и “Заголовок 3” без извлечения заголовков. Для этого мы устанавливаем последнему параметру значение false, которое указывает, что узлы-маркеры не должны быть включены.
При правильной реализации это должно выполняться в цикле для извлечения содержимого между всеми абзацами этих стилей из документа. Извлеченное содержимое копируется в новый документ.
В следующем примере кода показано, как извлекать содержимое между абзацами с определенными стилями, используя метод ExtractContent:
Ниже приведен результат предыдущей операции.

Вы также можете извлекать содержимое между встроенными узлами, такими как Run. в качестве маркеров можно использовать Runs из разных абзацев. В приведенном ниже коде показано, как извлекать определенный текст из одного и того же узла Paragraph.
В следующем примере кода показано, как извлекать содержимое между конкретными запусками одного и того же абзаца, используя метод ExtractContent:
Извлеченный текст отображается на консоли.
Чтобы использовать поле в качестве маркера, необходимо передать узел FieldStart. Последний параметр метода ExtractContent определяет, следует ли включать все поле целиком или нет. Давайте выделим содержимое между полем слияния “FullName” и абзацем в документе. Мы используем метод moveToMergeField класса DocumentBuilder. Он вернет узел FieldStart из имени переданного ему поля слияния.
В нашем случае давайте установим для последнего параметра, переданного методу ExtractContent, значение false, чтобы исключить поле из извлечения. Мы преобразуем извлеченное содержимое в PDF.
В следующем примере кода показано, как извлечь содержимое из определенного поля и абзаца в документе с помощью метода ExtractContent:
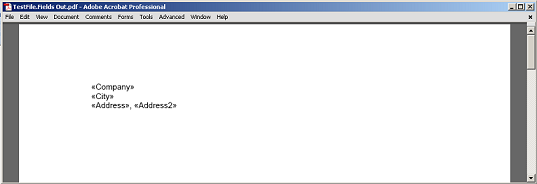
Извлеченное содержимое между полем и абзацем без узлов-маркеров поля и абзаца, отображаемых как PDF.
В документе содержимое, определенное в закладке, инкапсулируется узлами BookmarkStart и BookmarkEnd. Содержимое, находящееся между этими двумя узлами, составляет закладку. Вы можете передать любой из этих узлов в качестве любого маркера, даже из разных закладок, при условии, что начальный маркер отображается в документе перед конечным маркером.
В нашем примере документа у нас есть одна закладка с именем “Bookmark1”. Содержимое этой закладки является выделенным содержимым в нашем документе:
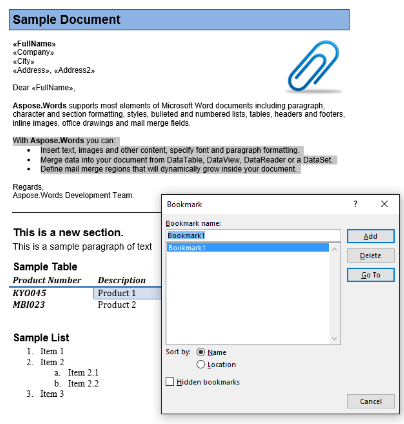
Мы извлекем это содержимое в новый документ, используя приведенный ниже код. Параметр IsInclusive показывает, как сохранить или удалить закладку.
В следующем примере кода показано, как извлечь содержимое, на которое ссылается закладка, используя метод ExtractContent:
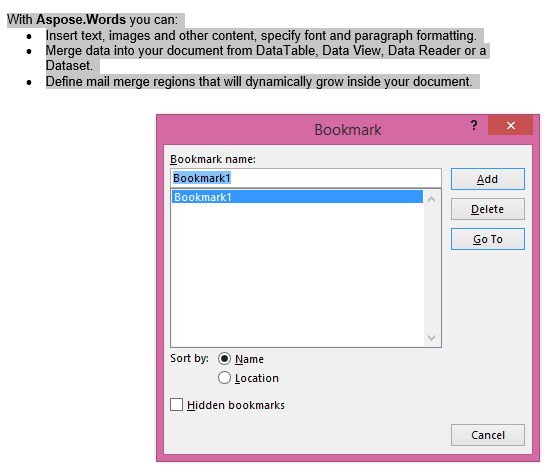
Извлеченный результат с параметром IsInclusive, равным true. В копии также будет сохранена закладка.
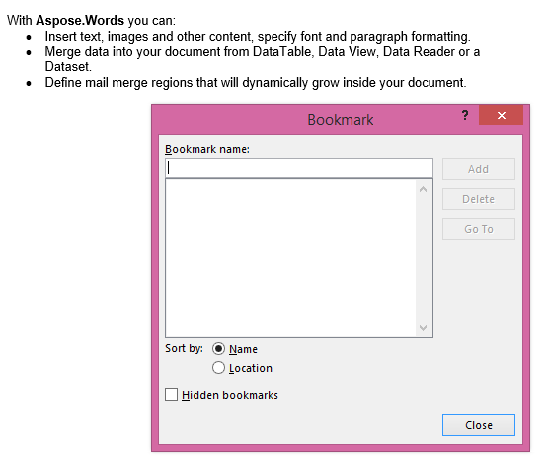
Извлеченный результат с параметром IsInclusive, равным false. Копия содержит содержимое, но без закладки.
Комментарий состоит из узлов CommentRangeStart, CommentRangeEnd и Comment. Все эти узлы являются встроенными. Первые два узла инкапсулируют содержимое документа, на который ссылается комментарий, как показано на скриншоте ниже.
Узел Comment сам по себе является узлом InlineStory, который может содержать абзацы и заголовки. Он представляет собой сообщение комментария, отображаемое в виде пузырька комментариев на панели просмотра. Поскольку этот узел является встроенным и является потомком тела, вы также можете извлечь содержимое из этого сообщения.
В нашем документе есть один комментарий. Давайте отобразим его, показав разметку на вкладке Обзор:
Комментарий содержит заголовок, первый абзац и таблицу во втором разделе. Давайте перенесем этот комментарий в новый документ. Параметр IsInclusive определяет, следует ли сохранить сам комментарий или удалить его.
В следующем примере кода показано, как это сделать, приведенном ниже:
Сначала извлеките выходные данные с параметром IsInclusive, равным true. Копия также будет содержать комментарий.
Во-вторых, извлеченный вывод с значением isInclusive, равным false. Копия содержит содержимое, но без комментария.

Aspose.Words может использоваться не только для создания Microsoft Word документов путем их динамического создания или объединения шаблонов с данными, но и для синтаксического анализа документов с целью извлечения отдельных элементов документа, таких как верхние и нижние колонтитулы, абзацы, таблицы, изображения и другие. Другая возможная задача - найти весь текст определенного формата или стиля.
Используйте класс DocumentVisitor для реализации этого сценария использования. Этот класс соответствует хорошо известному шаблону оформления посетителей. С помощью DocumentVisitor вы можете определять и выполнять пользовательские операции, которые требуют перечисления в дереве документа.
DocumentVisitor предоставляет набор из VisitXXX методов, которые вызываются при обнаружении определенного элемента документа (узла). Например, VisitParagraphStart вызывается при обнаружении начала текстового абзаца, а VisitParagraphEnd вызывается при обнаружении конца текстового абзаца. Каждый метод DocumentVisitor.VisitXXX принимает соответствующий объект, с которым он сталкивается, чтобы вы могли использовать его по мере необходимости (скажем, восстановить форматирование), например, как VisitParagraphStart, так и VisitParagraphEnd принимают объект Paragraph.
Каждый метод DocumentVisitor.VisitXXX возвращает значение VisitorAction, которое управляет перечислением узлов. Вы можете запросить либо продолжить перечисление, пропустить текущий узел (но продолжить перечисление), либо остановить перечисление узлов.
Вот шаги, которые вы должны выполнить, чтобы программно определить и извлечь различные части документа:
DocumentVisitor предоставляет реализации по умолчанию для всех методов DocumentVisitor.VisitXXX. Это упрощает создание новых посетителей документа, поскольку необходимо переопределять только методы, необходимые для конкретного посетителя. Нет необходимости переопределять все методы посетителя.
В следующем примере показано, как использовать шаблон посетителя для добавления новых операций в объектную модель Aspose.Words. В этом случае мы создаем простой конвертер документов в текстовый формат:
Существуют следующие способы извлечения текста из документа:
SaveFormat.Text. Внутренне это вызывает функцию сохранения в виде текста в потоке памяти и возвращает результирующую строкуNode.GetText и Node.ToStringДокумент Word может содержать управляющие символы, которые обозначают специальные элементы, такие как поле, конец ячейки, конец раздела и т.д. Полный список возможных управляющих символов Word определен в классе ControlChar. Метод GetText возвращает текст со всеми управляющими символами, присутствующими в узле.
Вызов ToString возвращает только текстовое представление документа без управляющих символов. Дополнительную информацию об экспорте в виде обычного текста смотрите в Using SaveFormat.Text.
В следующем примере кода показана разница между вызовом методов GetText и ToString на узле:
SaveFormat.TextВ этом примере документ сохраняется следующим образом:
В следующем примере кода показано, как сохранить документ в формате TXT:
Для выполнения некоторых задач вам может потребоваться извлечь изображения из документов. Aspose.Words это также позволяет это сделать.
В следующем примере кода показано, как извлекать изображения из документа:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.