Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
A scanned image or photograph of a text document may contain a large number of blocks of various content - text paragraphs, tables, illustrations, formulas, and the like. Detecting, ordering, and classifying areas of interest on a page is the cornerstone of successful and accurate OCR. This process is called content areas detection.
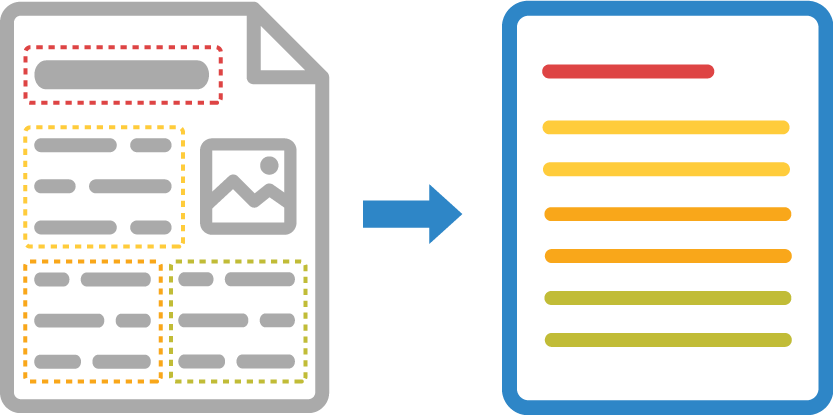
Aspose.OCR offers several content areas detection algorithms, allowing you to choose the one that works best for your specific content.
You can manually override the default content areas detection method if you are unhappy with the results or get unwanted artifacts.
Document structure analysis algorithm is specified in an optional DetectAreasMode parameter of recognition settings.
Aspose.OCR.AsposeOcr recognitionEngine = new Aspose.OCR.AsposeOcr();
// Add an image to OcrInput object
Aspose.OCR.OcrInput input = new Aspose.OCR.OcrInput(Aspose.OCR.InputType.SingleImage);
input.Add("source.png");
// Set content areas detection mode
Aspose.OCR.RecognitionSettings recognitionSettings = new Aspose.OCR.RecognitionSettings();
recognitionSettings.DetectAreasMode = Aspose.OCR.DetectAreasMode.MULTICOLUMN;
// Recognize image
Aspose.OCR.OcrOutput results = recognitionEngine.Recognize(input, recognitionSettings);
foreach(Aspose.OCR.RecognitionResult result in results)
{
Console.WriteLine(result.RecognitionText);
}
Aspose.OCR for .NET supports the following document structure analysis methods provided in DetectAreasMode enumeration:
| Name | Description | Use cases |
|---|---|---|
DetectAreasMode.UNIVERSAL |
Detects all blocks of text in the image, including sparse and irregular text on street photos. Used by default. See DetectAreasMode.UNIVERSAL for additional details. |
Photos Screenshots Advertisements Datasheets Street photos Price tags Food labels |
DetectAreasMode.MULTICOLUMN |
Detects large blocks of text formatted in several columns. See DetectAreasMode.MULTICOLUMN for additional details. |
Contracts Books Articles Newspapers |
DetectAreasMode.LEAN |
Do not analyze document structure. Prioritizes speed and reduces resource consumption by omitting support for complex layouts. | Simple images containing a few lines of text without illustrations or formatting. Applications requiring maximum recognition speed Web applications |
DetectAreasMode.TABLE |
Detects cells in tabular structures. See DetectAreasMode.TABLE for additional details. |
Tables Invoices |
DetectAreasMode.CURVED_TEXT |
Auto-straightens curved lines and finds text blocks inside the resulting image. See DetectAreasMode.CURVED_TEXT for additional details. |
Photos of books, magazine articles, and other curved pages. |
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.