Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
При работа с документи е важно лесно да се извлече съдържание от определен диапазон в даден документ. Съдържанието обаче може да се състои от сложни елементи като параграфи, таблици, изображения и др.
Независимо от това какво съдържание трябва да бъде извлечено, методът за извличане на това съдържание винаги ще се определя от кои възли се избират, за да се извлече съдържание между. Това могат да бъдат цели текстови тела или прости текстови работи.
Има много възможни ситуации и следователно много различни видове възли да се вземат предвид при извличане на съдържание. Например, може да искате да извлечете съдържание между:
В някои ситуации може дори да се наложи да комбинирате различни типове възли, като например извличане на съдържание между параграф и поле, или между бягане и отметки.
Тази статия осигурява прилагането на кода за извличане на текст между различни възли, както и примери за общи сценарии.
Често целта на извличането на съдържанието е да се дублира или запази отделно в нов документ. Например, можете да извлечете съдържание и:
Това може лесно да се постигне с помощта Aspose.Words и прилагането на кода по-долу.
Кодът в този раздел адресира всички възможни ситуации, описани по-горе с един общ и повторно използваем метод. Общата схема на тази техника включва:
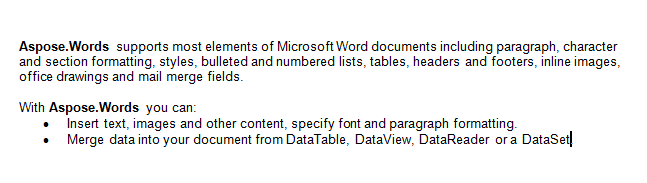
Ще работим с документа по-долу в тази статия. Както виждате, съдържа разнообразие от съдържание. Също така имайте предвид, че документът съдържа втори раздел, започващ в средата на първата страница. В документа също има отметки и коментари, но не са видими на снимката на екрана по-долу.

За да извлечете съдържанието от вашия документ, трябва да се обадите на ExtractContent метод по-долу и да премине съответните параметри.
Основната основа на този метод включва намирането на възли на ниво блок (точки и таблици) и клонирането им, за да се създадат идентични копия. Ако получените маркиращи възли са блоково ниво, тогава методът може просто да копира съдържанието на това ниво и да го добави към масива.
Въпреки това, ако маркерните възли са в линия (дете на параграф), тогава ситуацията става по-сложна, тъй като е необходимо да се раздели параграфа на вътрешния възел, било то тичане, отметки и т.н. Съдържанието в клонираните изходни възли, които не присъстват между маркерите, се премахва. Този процес се използва, за да се гарантира, че вътрешните възли ще запазят формата на параграфа майка.
Методът също така ще извършва проверки на възлите, преминали като параметри и хвърля изключение, ако или възелът е невалиден. Параметрите, които трябва да бъдат предадени на този метод, са:
StartNode както и EndNode. Първите два параметъра са възлите, които определят къде да започне извличането на съдържанието и съответно да приключи. Тези възли могат да бъдат и двата блока ниво (Paragraph , Table ) или вътрешно ниво (напр. Run , FieldStart , BookmarkStart и т.н.:
IsInclusive. Определя дали маркерите са включени в екстракцията или не. Ако е зададена тази опция false и същият възел или последователни възли са преминали, след това празен списък ще бъде върнат:
Изпълнение на ExtractContent метод можете да намерите Ето. Този метод ще бъде посочен в сценариите в тази статия.
Ние също така ще определим потребителски метод за лесно генериране на документ от извлечени възли. Този метод се използва в много от сценариите по-долу и просто създава нов документ и внася извлеченото съдържание в него.
Следният пример за код показва как да се вземе списък с възли и ги вмъква в нов документ:
Това показва как да се използва горният метод за извличане на съдържание между конкретни параграфи. В този случай искаме да извлечем тялото на писмото, намерено в първата половина на документа. Можем да кажем, че това е между 7 и 11-ти параграф.
Кодът по-долу изпълнява тази задача. Съответните параграфи се извличат с помощта на getChild метод на документа и преминаване на посочените индекси. След това предаваме тези възли на ExtractContent метод и се посочва, че те трябва да бъдат включени в екстракцията. Този метод ще върне копираното съдържание между тези възли, които след това се добавят в нов документ.
Следният пример за код показва как да се извлече съдържанието между конкретни параграфи, като се използва ExtractContent метод по- горе:
Изходният документ съдържа двете извлечени параграфи.
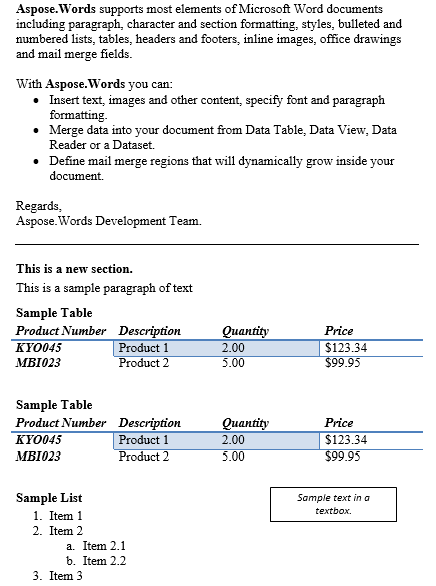
Можем да извлечем съдържание между всяка комбинация от блоково ниво или вътрешни възли. В този сценарий по-долу ще извлечем съдържанието между първия параграф и таблицата във втория раздел, включително. Получаваме маркерите като викаме getFirstParagraph както и getChild метод на втория раздел на документа за извличане на съответния Paragraph както и Table Възли. За малко изменение нека да се дублира съдържанието и да го постави под оригинала.
Следният пример за код показва как да се извлече съдържанието между параграф и таблица, като се използва ExtractContent метод:
Съдържанието между параграфа и таблицата е дублирано по-долу е резултатът.
Може да се наложи да извлечете съдържанието между параграфи от един и същ или различен стил, като например между параграфи, маркирани със стилове на заглавие.
Кодът по-долу показва как да се постигне това. Това е един прост пример, който ще извлече съдържанието между първата инстанция на нареждането на 1 .. и … .. За да направим това, зададохме последния параметър на false, което посочва, че не следва да се включват възлите на маркера.
В правилното изпълнение, това трябва да бъде в цикъл за извличане на съдържание между всички параграфи от тези стилове от документа. Извлеченото съдържание се копира в нов документ.
Следният пример за код показва как да се извлече съдържание между параграфи със специфични стилове използване на ExtractContent метод:
По-долу е резултатът от предишната операция.

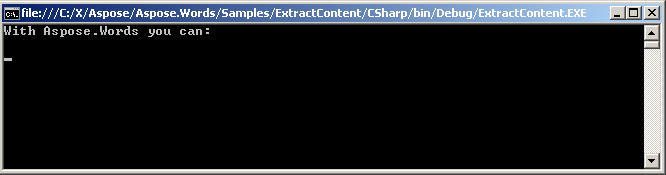
Можете да извлечете съдържание между inline възли като Run Както добре. Runs от различни параграфи могат да се приемат като маркери. Кодът по-долу показва как да се извлече специфичен текст между едно и също Paragraph Възел.
Следният пример за код показва как да се извлече съдържание между специфични работи на същия параграф, като се използва ExtractContent метод:
Извлеченият текст се показва на конзолата
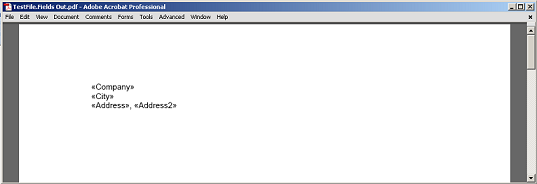
За да използвате поле като маркер, FieldStart Възелът трябва да бъде приет. Последният параметър ExtractContent метод ще определи дали цялото поле трябва да бъде включено или не. Позволявам да се извлече съдържанието между полето на FullName и параграф в документа. Ние използваме moveToMergeField метод на DocumentBuilder Клас. Това ще върне FieldStart Възел от името на сливащото се поле е преминал към него.
В нашия случай нека да зададете последния параметър премина към ExtractContent метод на false да се изключи полето от екстракцията. Ще предадем извлеченото съдържание на PDF.
Следният пример за код показва как да се извлече съдържание между конкретно поле и параграф в документа, като се използва ExtractContent метод:
Извличаното съдържание между полето и параграфа, без полето и параграфа за маркиране, предоставени на PDF.
В документ съдържанието, което се определя в рамките на отметките, се капсулира от BookmarkStart и “Отметки край възли.” Съдържанието, намерено между тези два възела, прави отметките. Можете да преминете всеки един от тези възли като всеки маркер, дори и тези от различни отметки, стига стартовият маркер да се появи преди крайния маркер в документа.
В нашия примерен документ, ние имаме една отметки, наименувана от Bookmark1. Съдържанието на тази отметки е подчертано съдържание в нашия документ:
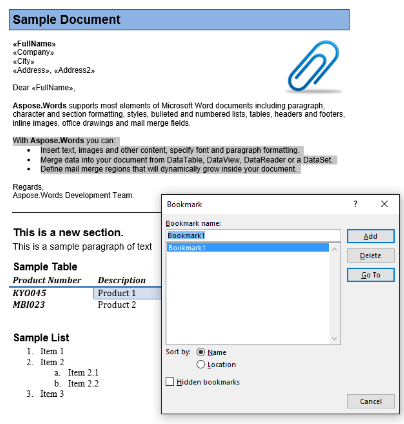
Ще извлечем това съдържание в нов документ с помощта на кода по-долу. На IsInclusive параметърът показва как да се запази или изхвърли отметките.
Следният пример с код показва как да се извлече съдържанието, посочено в отметките, използвайки ExtractContent метод:
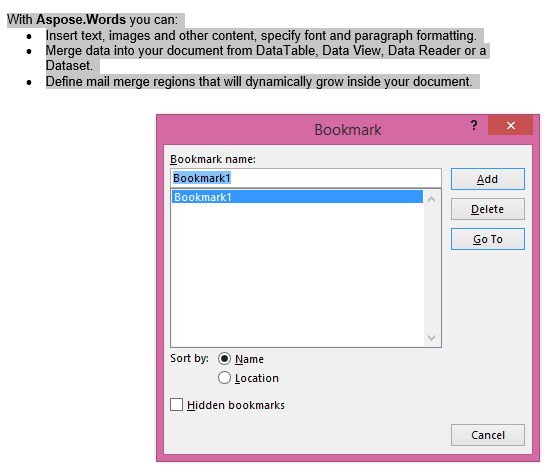
Извлечената продукция с IsInclusive параметър, зададен към true. Копието ще запази и отметките.
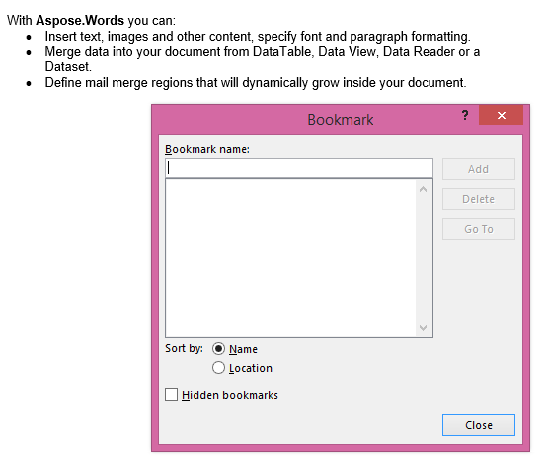
Извлечената продукция с IsInclusive параметър, зададен към false. Копието съдържа съдържанието, но без отметките.
Коментар е направен от коментарRangeStart, CommentRangeEnd и Коментар възли. Всички тези възли са на линия. Първите два възела капсулират съдържанието в документа, което се споменава в коментара, както се вижда на снимката на екрана по-долу.
На Comment Самото възел е InlineStory които могат да съдържат параграфи и да тичат. Той представлява съобщението на коментара, както се вижда като коментар балон в панела за преглед. Тъй като този възел е в линия и потомък на тяло можете също така да извлечете съдържанието от вътре в това съобщение, както добре.
В нашия документ имаме един коментар. Позволявам да го покажете чрез показване на надценката в раздела Преглед:
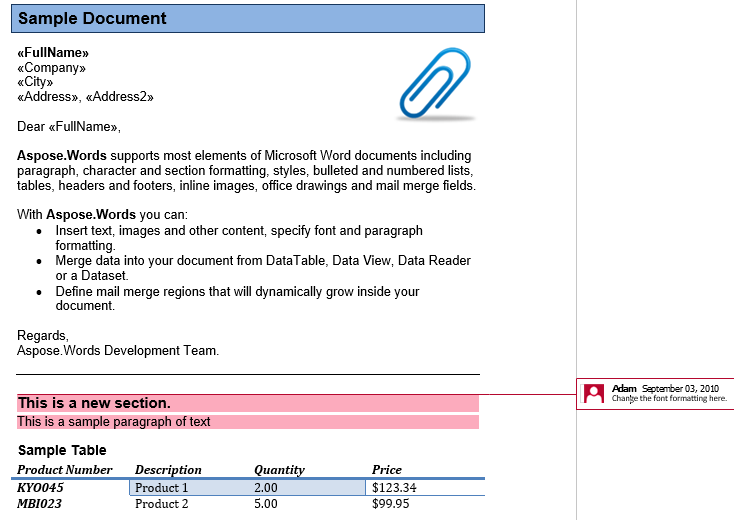
Коментарът обхваща заглавието, първия параграф и таблицата във втория раздел. Позволявам да извлечете този коментар в нов документ. На IsInclusive опцията диктува дали коментарът се съхранява или отхвърля.
Следният пример за код показва как да направите това е по-долу:
Първо, извлечената продукция с IsInclusive параметър, зададен към true. Копието ще съдържа и коментара.
Второ, екстрахираната продукция с ен задаване на false. Копието съдържа съдържанието, но без коментара.

Aspose.Words може да се използва не само за създаване Microsoft Word документи чрез изграждането им динамично или сливане на шаблони с данни, но също и за анализ на документи, за да се извлекат отделни елементи на документи, като заглавни части, подметки, параграфи, таблици, изображения и др. Друга възможна задача е да намерите всички текст на конкретен форматиране или стил.
Използвайте DocumentVisitor клас за изпълнение на този сценарий на използване. Този клас съответства на добре познатия дизайнерски модел. С DocumentVisitor, Можете да определите и изпълните потребителски операции, които изискват изброяване над дървото на документа.
DocumentVisitor осигурява набор от VisitXXX методи, които се използват, когато се среща определен документен елемент (нод). Например, VisitParagraphStart се нарича, когато се намери началото на текстов параграф и VisitParagraphEnd се нарича, когато се намери краят на текстов параграф. Всеки DocumentVisitor.VisitXXX метод приема съответния обект, който той среща, така че можете да го използвате, когато е необходимо (да кажем извличане на форматиране), напр. и двете VisitParagraphStart както и VisitParagraphEnd Прием на Paragraph Възразявам.
Всеки DocumentVisitor.VisitXXX метод връща a VisitorAction стойност, която контролира изброяването на възлите. Можете да поискате или да продължите изброяването, да пропуснете текущия възел (но продължете изброяването), или да спрете изброяването на възлите.
Това са стъпките, които трябва да следвате за програмно определяне и извличане на различни части на документ:
DocumentVisitor осигурява изпълнението по подразбиране за всички DocumentVisitor.VisitXXX методи. Това улеснява създаването на нови посетители на документи, тъй като само методите, необходими за конкретен посетител, трябва да бъдат отменени. Не е необходимо да отменяте всички методи на посещение.
Следният пример показва как да използвате модела на Посетител, за да добавите нови операции към Aspose.Words Модел на обекти. В този случай създаваме прост документен конвертор в текстов формат:
Начините за извличане на текст от документа са:
SaveFormat.Text параметър. Вътрешно, това призовава запис като текст в поток памет и връща получения низNode.GetText както и Node.ToStringA Документът на Word може да съдържа контролни знаци, които определят специални елементи като поле, край на клетката, край на секцията и т.н. Пълният списък на възможните Word контрол символи се определя в ControlChar Клас. На GetText метод връща текст с всички знаци контролен символ присъства в възела.
Обаждането на ToString връща простото текстово представяне на документа само без контролни знаци. За допълнителна информация относно износа като обикновен текст вж. Using SaveFormat.Text.
Следният код пример показва разликата между призоваване на GetText както и ToString методи на възел:
SaveFormat.TextТози пример запазва документа, както следва:
Следният пример за код показва как да запишете документ във формат TXT:
Може да се наложи да извлечете изображения на документи, за да изпълните някои задачи. Aspose.Words ви позволява да направите това, както добре.
Следният пример за код показва как да извлечете изображения от документ:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.