Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
Lorsque vous travaillez avec des documents, il est important de pouvoir extraire facilement le contenu d’une plage spécifique d’un document. Cependant, le contenu peut être constitué d’éléments complexes tels que des paragraphes, des tableaux, des images, etc.
Quel que soit le contenu à extraire, la méthode d’extraction de ce contenu sera toujours déterminée par les nœuds sélectionnés entre lesquels extraire le contenu. Il peut s’agir de corps de texte entiers ou de simples exécutions de texte.
Il existe de nombreuses situations possibles et donc de nombreux types de nœuds différents à prendre en compte lors de l’extraction de contenu. Par exemple, vous souhaiterez peut-être extraire du contenu entre:
Dans certaines situations, vous devrez peut-être même combiner différents types de nœuds, tels que l’extraction de contenu entre un paragraphe et un champ, ou entre une exécution et un signet.
Cet article fournit l’implémentation du code pour extraire du texte entre différents nœuds, ainsi que des exemples de scénarios courants.
Souvent, le but de l’extraction du contenu est de le dupliquer ou de l’enregistrer séparément dans un nouveau document. Par exemple, vous pouvez extraire du contenu et:
Ceci peut être facilement réalisé en utilisant Aspose.Words et l’implémentation de code ci-dessous.
Le code de cette section aborde toutes les situations possibles décrites ci-dessus avec une méthode généralisée et réutilisable. Les grandes lignes de cette technique impliquent:
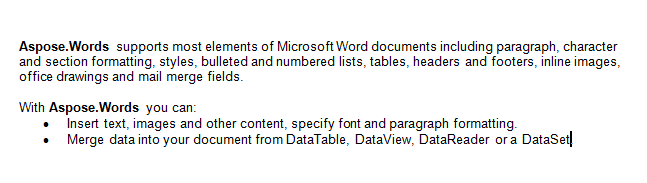
Nous allons travailler avec le document ci-dessous dans cet article. Comme vous pouvez le voir, il contient une variété de contenus. Notez également que le document contient une deuxième section commençant au milieu de la première page. Un signet et un commentaire sont également présents dans le document mais ne sont pas visibles dans la capture d’écran ci-dessous.

Pour extraire le contenu de votre document, vous devez appeler la méthode ExtractContent ci-dessous et transmettre les paramètres appropriés.
La base sous-jacente de cette méthode consiste à trouver des nœuds au niveau du bloc (paragraphes et tableaux) et à les cloner pour créer des copies identiques. Si les nœuds marqueurs passés sont au niveau du bloc, la méthode peut simplement copier le contenu à ce niveau et l’ajouter au tableau.
Cependant, si les nœuds marqueurs sont en ligne (un enfant d’un paragraphe), la situation devient plus complexe, car il est nécessaire de diviser le paragraphe au niveau du nœud en ligne, qu’il s’agisse d’une exécution, de champs de signets, etc. Le contenu des nœuds parents clonés non présents entre les marqueurs est supprimé. Ce processus est utilisé pour s’assurer que les nœuds en ligne conserveront toujours la mise en forme du paragraphe parent.
La méthode exécutera également des vérifications sur les nœuds passés en paramètres et lèvera une exception si l’un des nœuds n’est pas valide. Les paramètres à transmettre à cette méthode sont:
StartNode et EndNode. Les deux premiers paramètres sont les nœuds qui définissent respectivement le début et la fin de l’extraction du contenu. Ces nœuds peuvent être à la fois au niveau du bloc (Paragraph, Table) ou au niveau en ligne (par exemple Run, FieldStart, BookmarkStart etc.):
IsInclusive. Définit si les marqueurs sont inclus dans l’extraction ou non. Si cette option est définie sur false et que le même nœud ou des nœuds consécutifs sont passés, une liste vide sera renvoyée:
L’implémentation de la méthode ExtractContent que vous pouvez trouver ici. Cette méthode sera mentionnée dans les scénarios de cet article.
Nous allons également définir une méthode personnalisée pour générer facilement un document à partir de nœuds extraits. Cette méthode est utilisée dans de nombreux scénarios ci-dessous et crée simplement un nouveau document et y importe le contenu extrait.
L’exemple de code suivant montre comment prendre une liste de nœuds et les insérer dans un nouveau document:
Cela montre comment utiliser la méthode ci-dessus pour extraire du contenu entre des paragraphes spécifiques. Dans ce cas, nous voulons extraire le corps de la lettre trouvée dans la première moitié du document. On peut dire que c’est entre le 7ème et le 11ème paragraphe.
Le code ci-dessous accomplit cette tâche. Les paragraphes appropriés sont extraits en utilisant la méthode getChild sur le document et en passant les index spécifiés. Nous passons ensuite ces nœuds à la méthode ExtractContent et déclarons qu’ils doivent être inclus dans l’extraction. Cette méthode renverra le contenu copié entre ces nœuds qui sont ensuite insérés dans un nouveau document.
L’exemple de code suivant montre comment extraire le contenu entre des paragraphes spécifiques à l’aide de la méthode ExtractContent ci-dessus:
Le document de sortie contient les deux paragraphes qui ont été extraits.
Nous pouvons extraire du contenu entre n’importe quelle combinaison de nœuds au niveau du bloc ou en ligne. Dans ce scénario ci-dessous, nous extrairons le contenu entre le premier paragraphe et le tableau de la deuxième section inclusivement. Nous obtenons les nœuds marqueurs en appelant la méthode getFirstParagraph et getChild sur la deuxième section du document pour récupérer les nœuds Paragraph et Table appropriés. Pour une légère variation, dupliquons plutôt le contenu et insérons-le sous l’original.
L’exemple de code suivant montre comment extraire le contenu entre un paragraphe et un tableau à l’aide de la méthode ExtractContent:
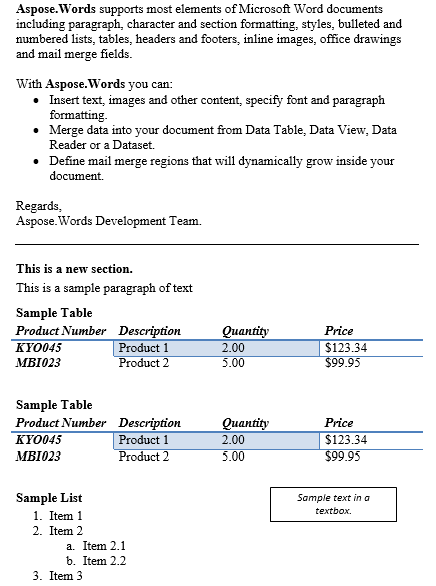
Le contenu entre le paragraphe et le tableau a été dupliqué ci-dessous est le résultat.
Vous devrez peut-être extraire le contenu entre des paragraphes de style identique ou différent, par exemple entre des paragraphes marqués de styles de titre.
Le code ci-dessous montre comment y parvenir. C’est un exemple simple qui extraira le contenu entre la première instance des styles “Heading 1” et “En-tête 3” sans extraire également les en-têtes. Pour ce faire, nous définissons le dernier paramètre sur false, ce qui spécifie que les nœuds marqueurs ne doivent pas être inclus.
Dans une implémentation correcte, cela devrait être exécuté en boucle pour extraire le contenu entre tous les paragraphes de ces styles du document. Le contenu extrait est copié dans un nouveau document.
L’exemple de code suivant montre comment extraire du contenu entre des paragraphes avec des styles spécifiques à l’aide de la méthode ExtractContent:
Ci-dessous le résultat de l’opération précédente.

Vous pouvez également extraire du contenu entre des nœuds en ligne tels qu’un Run. Runs de différents paragraphes peuvent être passés comme marqueurs. Le code ci-dessous montre comment extraire du texte spécifique entre le même nœud Paragraph.
L’exemple de code suivant montre comment extraire du contenu entre des exécutions spécifiques du même paragraphe à l’aide de la méthode ExtractContent:
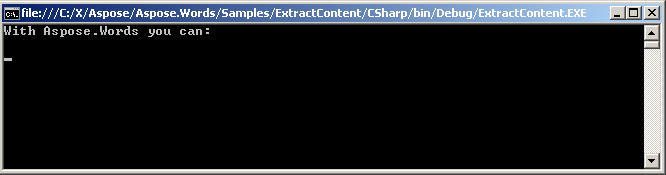
Le texte extrait est affiché sur la console.
Pour utiliser un champ comme marqueur, le nœud FieldStart doit être passé. Le dernier paramètre de la méthode ExtractContent définira si le champ entier doit être inclus ou non. Extrayons le contenu entre le champ de fusion" FullName " et un paragraphe du document. Nous utilisons la méthode moveToMergeField de la classe DocumentBuilder. Cela renverra le nœud FieldStart à partir du nom du champ de fusion qui lui a été transmis.
Dans notre cas, définissons le dernier paramètre passé à la méthode ExtractContent sur false pour exclure le champ de l’extraction. Nous allons rendre le contenu extrait à PDF.
L’exemple de code suivant montre comment extraire du contenu entre un champ et un paragraphe spécifiques du document à l’aide de la méthode ExtractContent:
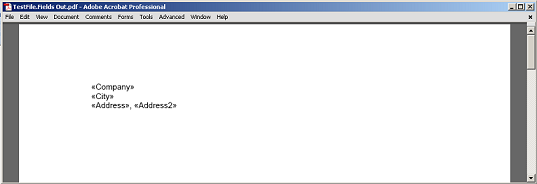
Le contenu extrait entre le champ et le paragraphe, sans les nœuds de marqueur de champ et de paragraphe rendus à PDF.
Dans un document, le contenu défini dans un signet est encapsulé par les nœuds BookmarkStart et BookmarkEnd. Le contenu trouvé entre ces deux nœuds constitue le signet. Vous pouvez passer l’un de ces nœuds comme n’importe quel marqueur, même ceux de signets différents, tant que le marqueur de départ apparaît avant le marqueur de fin dans le document.
Dans notre exemple de document, nous avons un signet, nommé “Signet1”. Le contenu de ce signet est mis en évidence dans notre document:
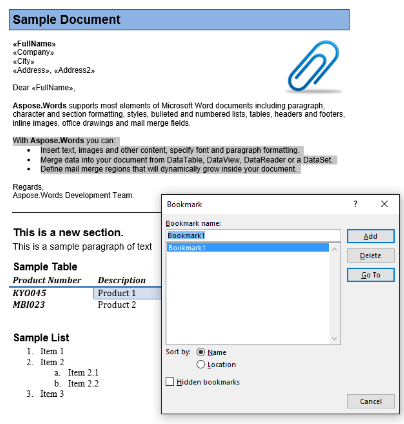
Nous allons extraire ce contenu dans un nouveau document en utilisant le code ci-dessous. L’option de paramètre IsInclusive indique comment conserver ou supprimer le signet.
L’exemple de code suivant montre comment extraire le contenu référencé par un signet à l’aide de la méthode ExtractContent:
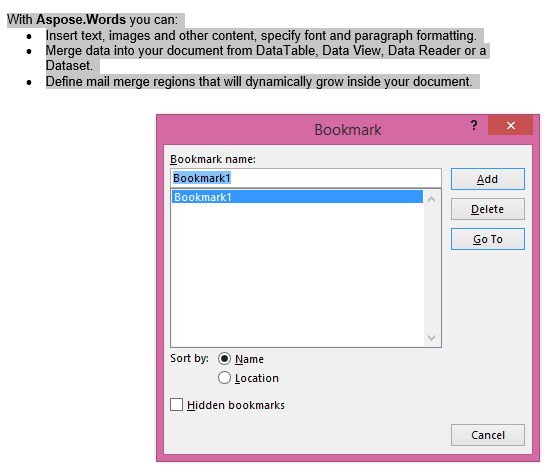
La sortie extraite avec le paramètre IsInclusive défini sur true. La copie conservera également le signet.
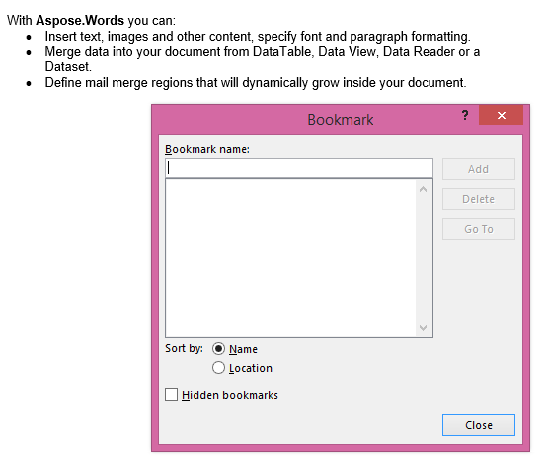
La sortie extraite avec le paramètre IsInclusive défini sur false. La copie contient le contenu mais sans le signet.
Un commentaire est composé des nœuds CommentRangeStart, CommentRangeEnd et Comment. Tous ces nœuds sont en ligne. Les deux premiers nœuds encapsulent le contenu du document référencé par le commentaire, comme le montre la capture d’écran ci-dessous.
Le nœud Comment lui-même est un InlineStory qui peut contenir des paragraphes et des exécutions. Il représente le message du commentaire sous la forme d’une bulle de commentaire dans le volet de révision. Comme ce nœud est en ligne et un descendant d’un corps, vous pouvez également extraire le contenu de l’intérieur de ce message.
Dans notre document, nous avons un commentaire. Affichons-le en affichant le balisage dans l’onglet Révision:
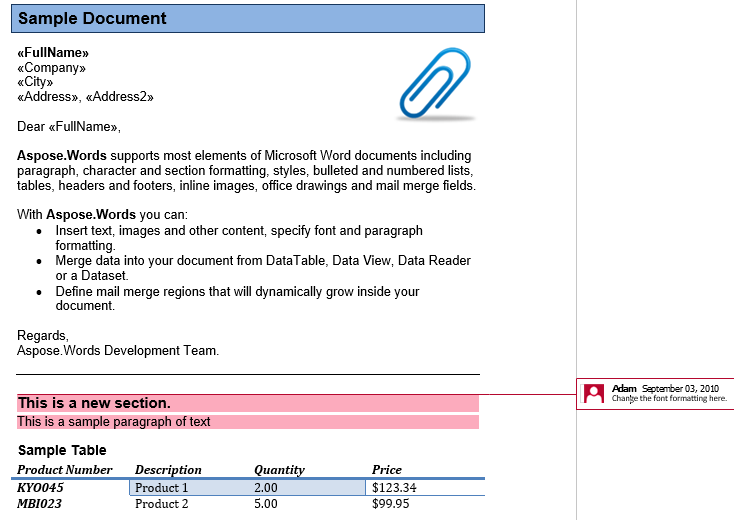
Le commentaire résume l’en-tête, le premier paragraphe et le tableau de la deuxième section. Extrayons ce commentaire dans un nouveau document. L’option IsInclusive indique si le commentaire lui-même est conservé ou supprimé.
L’exemple de code suivant montre comment procéder ci-dessous:
Tout d’abord la sortie extraite avec le paramètre IsInclusive défini sur true. La copie contiendra également le commentaire.
Deuxièmement, la sortie extraite avec isInclusive défini sur false. La copie contient le contenu mais sans le commentaire.

Aspose.Words peut être utilisé non seulement pour créer Microsoft Word documents en les construisant dynamiquement ou en fusionnant des modèles avec des données, mais également pour analyser des documents afin d’extraire des éléments de document distincts tels que des en-têtes, des pieds de page, des paragraphes, des tableaux, des images et autres. Une autre tâche possible consiste à trouver tout le texte d’une mise en forme ou d’un style spécifique.
Utilisez la classe DocumentVisitor pour implémenter ce scénario d’utilisation. Cette classe correspond au modèle de conception des visiteurs bien connu. Avec DocumentVisitor, vous pouvez définir et exécuter des opérations personnalisées qui nécessitent une énumération sur l’arborescence du document.
DocumentVisitor fournit un ensemble de VisitXXX méthodes qui sont invoquées lorsqu’un élément de document particulier (nœud) est rencontré. Par exemple, VisitParagraphStart est appelé lorsque le début d’un paragraphe de texte est trouvé et VisitParagraphEnd est appelé lorsque la fin d’un paragraphe de texte est trouvée. Chaque méthode DocumentVisitor.VisitXXX accepte l’objet correspondant qu’elle rencontre afin que vous puissiez l’utiliser au besoin (par exemple, récupérer la mise en forme), par exemple VisitParagraphStart et VisitParagraphEnd acceptent un objet Paragraph.
Chaque méthode DocumentVisitor.VisitXXX renvoie une valeur VisitorAction qui contrôle l’énumération des nœuds. Vous pouvez demander soit de continuer l’énumération, d’ignorer le nœud actuel (mais de continuer l’énumération), soit d’arrêter l’énumération des nœuds.
Voici les étapes à suivre pour déterminer et extraire par programmation diverses parties d’un document:
DocumentVisitor fournit des implémentations par défaut pour toutes les méthodes DocumentVisitor.VisitXXX. Cela facilite la création de nouveaux visiteurs de document car seules les méthodes requises pour le visiteur particulier doivent être remplacées. Il n’est pas nécessaire de remplacer toutes les méthodes de visiteur.
L’exemple suivant montre comment utiliser le modèle de visiteur pour ajouter de nouvelles opérations au modèle d’objet Aspose.Words. Dans ce cas, nous créons un simple convertisseur de document au format texte:
Les moyens de récupérer du texte à partir du document sont:
SaveFormat.Text. En interne, cela appelle enregistrer sous forme de texte dans un flux de mémoire et renvoie la chaîne résultanteNode.GetText et Node.ToStringUn document Word peut contenir des caractères de contrôle qui désignent des éléments spéciaux tels que le champ, la fin de la cellule,la fin de la section, etc. La liste complète des caractères de contrôle de mot possibles est définie dans la classe ControlChar. La méthode GetText renvoie du texte avec tous les caractères de caractère de contrôle présents dans le nœud.
L’appel de ToString renvoie la représentation en texte brut du document uniquement sans caractères de contrôle. Pour plus d’informations sur l’exportation en texte brut, voir Using SaveFormat.Text.
L’exemple de code suivant montre la différence entre l’appel des méthodes GetText et ToString sur un nœud:
SaveFormat.TextCet exemple enregistre le document comme suit:
L’exemple de code suivant montre comment enregistrer un document au format TXT:
Vous devrez peut-être extraire des images de document pour effectuer certaines tâches. Aspose.Words vous permet de le faire aussi.
L’exemple de code suivant montre comment extraire des images d’un document:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.