Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
Mail Merge동안 문서에서 병합되지 않은 영역을 완전히 제거하는 것이 바람직하지 않거나 문서가 불완전해 보이는 경우가 있습니다. 이것은 입력 데이터가 없는 지역이 완전히 제거되는 대신 메시지 형태로 사용자에게 표시되어야 할 때 발생할 수 있습니다.
또한 사용되지 않는 영역을 자체적으로 제거하는 것만으로는 충분하지 않은 경우도 있습니다.예를 들어,영역이 제목 앞에 있거나 영역이 테이블에 포함되어있는 경우입니다. 이 영역이 사용되지 않으면 제목과 테이블이 여전히 남아 영역을 제거한 후에도 문서에서 부적절하게 보일 것입니다.
이 문서에서는 문서에서 사용되지 않는 영역을 처리하는 방법을 수동으로 정의하는 솔루션을 제공합니다. 이 기능에 대한 기본 코드가 제공되며 다른 프로젝트에서 쉽게 재사용 할 수 있습니다.
각 영역에 적용할 논리는IFieldMergingCallback인터페이스를 구현하는 클래스 내에 정의됩니다. 같은 방식으로Mail Merge처리기를 설정하여 각 필드가 병합되는 방법을 제어 할 수 있습니다.이 처리기는 사용되지 않는 영역의 각 필드 또는 전체 영역에서 작업을 수행하도록 설정할 수 있습니다. 이 핸들러 내에서 영역의 텍스트를 변경하거나 노드 또는 빈 행과 셀 등을 제거하도록 코드를 설정할 수 있습니다.
이 샘플에서는 아래에 표시된 문서를 사용할 것입니다. 여기에는 중첩 된 영역과 테이블 내에 포함 된 영역이 포함됩니다.
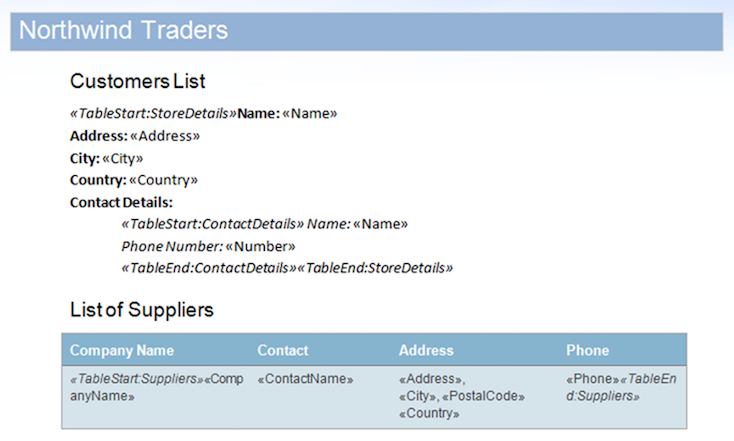
빠른 데모로MailMergeCleanupOptions.REMOVE_UNUSED_REGIONS플래그가 활성화 된 샘플 문서에서 샘플 데이터베이스를 실행할 수 있습니다. 이 속성은mail merge동안 문서에서 병합되지 않은 영역을 자동으로 제거합니다.
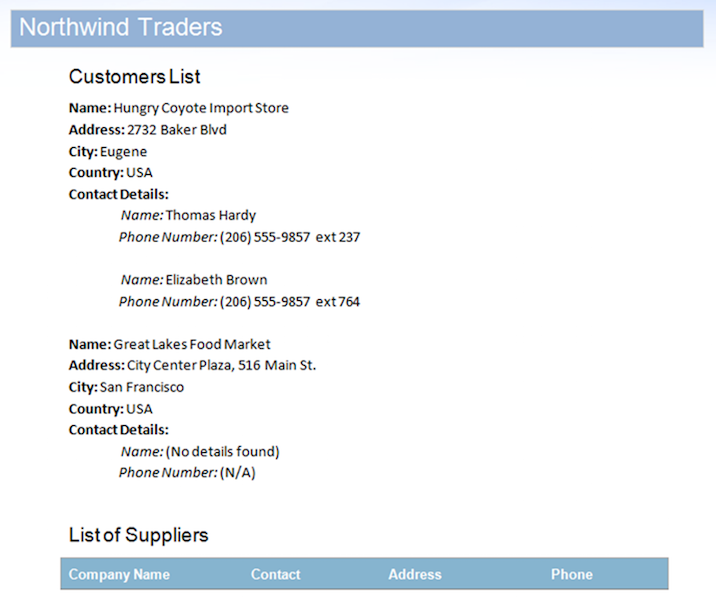
데이터 원본에는StoreDetails영역에 대한 두 개의 레코드가 포함되어 있지만 의도적으로 레코드 중 하나에 대한 하위ContactDetails영역에 대한 데이터가 있습니다. 또한Suppliers영역에는 데이터 행이 없습니다. 이렇게 하면 사용되지 않는 영역이 문서에 남아 있습니다. 이 데이터 원본과 문서를 병합 한 후의 결과는 다음과 같습니다.

이미지에서 언급했듯이 두 번째 레코드의ContactDetails영역과Suppliers영역은 데이터가 없기 때문에Mail Merge엔진에 의해 자동으로 제거되었음을 알 수 있습니다. 그러나 이 출력 문서를 불완전하게 보이게 하는 몇 가지 문제가 있습니다:
이 문서에서 제공하는 기술은 이러한 문제를 방지하기 위해 병합되지 않은 각 영역에 사용자 지정 논리를 적용하는 방법을 보여 줍니다.
솔루션
문서의 사용되지 않는 각 영역에 논리를 수동으로 적용하려면Aspose.Words에서 이미 사용할 수 있는 기능을 활용합니다.
Mail Merge엔진은MailMergeCleanupOptions.RemoveUnusedRegions플래그를 통해 사용되지 않는 영역을 제거하는 속성을 제공합니다. mail merge동안 이러한 영역이 그대로 유지되도록 비활성화 할 수 있습니다. 이렇게 하면 문서에서 병합되지 않은 영역을 그대로 두고 대신 직접 수동으로 처리할 수 있습니다.
그런 다음MailMerge.FieldMergingCallback속성을 사용하여IFieldMergingCallback인터페이스를 구현하는 핸들러 클래스를 사용하여Mail Merge동안 이러한 병합되지 않은 영역에 자체 사용자 정의 논리를 적용 할 수 있습니다.
처리기 클래스 내의 이 코드는 병합되지 않은 영역에 적용되는 논리를 제어하기 위해 수정해야 하는 유일한 클래스입니다. 이 샘플의 다른 코드는 프로젝트에서 수정 없이 재사용할 수 있습니다.
이 샘플 프로젝트는이 기술을 보여줍니다. 다음 단계가 포함됩니다.:
코드
ExecuteCustomLogicOnEmptyRegions방법의 구현은 아래에서 찾을 수 있습니다. 이 메서드는 여러 매개 변수를 허용합니다:
예
지정된 처리기를 사용하여 사용하지 않는 영역에서 사용자 지정 논리를 실행하는 방법을 보여 줍니다.
예
병합되지 않은 영역을 수동으로 처리하는 데 사용되는 메서드를 정의합니다.
이 방법은 문서에서 병합되지 않은 모든 영역을 찾는 것을 포함합니다. 이것은MailMerge.GetFieldNames방법을 사용하여 수행됩니다. 이 메서드는 영역 시작 및 끝 마커(접두사TableStart또는TableEnd가 있는 병합 필드로 표시됨)를 포함하여 문서의 모든 병합 필드를 반환합니다.
TableStart병합 필드가 발견되면 이 필드는DataSet에 새로운DataTable으로 추가됩니다. 영역이 두 번 이상 나타날 수 있으므로(예를 들어 부모 영역이 여러 레코드와 병합된 중첩된 영역이기 때문에)테이블은DataSet에 이미 존재하지 않는 경우에만 만들어지고 추가됩니다.
적절한 영역 시작이 발견되어 데이터베이스에 추가되면 다음 필드(영역의 첫 번째 필드에 해당)가DataTable에 추가됩니다. 병합되고 처리기에 전달될 영역의 각 필드에 대해 첫 번째 필드만 추가해야 합니다.
또한 첫 번째 필드의 필드 값을"FirstField"로 설정하여 지역의 첫 번째 필드나 다른 필드에 논리를 더 쉽게 적용할 수 있도록 합니다. 이를 포함하면 첫 번째 필드의 이름을 하드 코딩할 필요가 없거나 현재 필드가 핸들러 코드의 첫 번째인지 확인하기 위해 추가 코드를 구현할 필요가 없습니다.
아래 코드는 이 시스템이 어떻게 작동하는지 보여줍니다. 이 문서의 시작 부분에 표시된 문서는 동일한 데이터 원본으로 다시 병합되지만 이번에는 사용하지 않는 영역이 사용자 지정 코드로 처리됩니다.
예
사용자 정의 코드로Mail Merge이후에 병합되지 않은 영역을 처리하는 방법을 보여 줍니다.
코드는FieldMergingArgs.TableName속성을 사용하여 검색된 영역의 이름에 따라 다른 작업을 수행합니다. 문서 및 지역에 따라 처리기를 코딩하여 문서의 병합되지 않은 모든 영역 또는 둘의 조합에 적용되는 각 영역 또는 코드에 따라 논리를 실행할 수 있습니다.
ContactDetails영역의 논리는 데이터가 없다는 적절한 메시지와 함께ContactDetails영역의 각 필드의 텍스트를 변경하는 것을 포함합니다. 각 필드의 이름은FieldMergingArgs.FieldName속성을 사용하여 처리기 내에서 일치합니다.
비슷한 프로세스가Suppliers영역에 적용되며,영역을 포함하는 테이블을 처리하기 위해 추가 코드를 추가합니다. 코드는 해당 영역이 테이블 내에 포함되어 있는지 확인합니다(이미 제거되었을 수 있음). 만약 그렇다면,문서에서 전체 테이블과 그 앞에 있는 단락을 제거할 것입니다.예를 들어"Heading 1"라는 제목 스타일로 포맷되어 있는 한 말이죠.
예
문서에서 병합되지 않은 영역에 대해 실행되는IFieldMergingCallback을 구현하는 처리기에서 사용자 지정 논리를 정의하는 방법을 보여 줍니다.
위의 코드의 결과는 아래와 같습니다. 첫 번째 영역 내의 병합되지 않은 필드는 정보 텍스트로 대체되며 테이블과 제목을 제거하면 문서가 완성되어 보일 수 있습니다.

부모 테이블을 제거하는 코드는 테이블 이름에 대한 검사를 제거하여 특정 지역 대신 사용되지 않는 모든 지역에서 실행되도록 만들 수 있습니다. 이 경우 테이블 내부의 영역이 데이터와 병합되지 않은 경우 영역과 컨테이너 테이블 모두 자동으로 제거됩니다.
처리기에 다른 코드를 삽입하여 병합되지 않은 영역이 처리되는 방법을 제어 할 수 있습니다. 대신 처리기에서 아래 코드를 사용하면 영역의 첫 번째 단락의 텍스트가 유용한 메시지로 변경되고 영역의 후속 단락은 제거됩니다. 그들은 우리의 메시지를 병합 한 후 지역에 남아있을 것 같은 이러한 다른 단락은 제거됩니다.
대체 텍스트는 지정된 텍스트를FieldMergingArgs.Text속성으로 설정하여 첫 번째 필드에 병합됩니다. 이 속성의 텍스트는Mail Merge엔진에 의해 필드에 병합됩니다.
이 코드는FieldMergingArgs.FieldValue속성을 검사하여 영역의 첫 번째 필드에만 적용됩니다. 영역의 첫 번째 필드의 필드 값은"FirstField"로 표시됩니다. 이것은 추가 코드가 필요하지 않기 때문에 많은 지역에서 이러한 유형의 논리를 더 쉽게 구현할 수 있습니다.
예
사용하지 않는 영역을 메시지로 바꾸고 추가 단락을 제거하는 방법을 보여줍니다.
위의 코드가 실행된 후의 결과 문서는 아래와 같습니다. 사용하지 않는 영역은 표시할 레코드가 없다는 메시지로 대체됩니다.

또 다른 예로,우리는 원래SuppliersRegion을 처리하는 코드 대신 아래의 코드를 삽입할 수 있습니다. 그러면 테이블 내에 메시지가 표시되고 문서에서 테이블을 제거하는 대신 셀을 병합합니다. 이 영역은 여러 셀이 있는 테이블 내에 있으므로 테이블의 셀이 함께 병합되고 메시지가 중앙에 있는 것이 더 좋습니다.
예
사용되지 않는 영역의 모든 부모 셀을 병합하고 테이블 내에 메시지를 표시하는 방법을 보여 줍니다.
위의 코드가 실행된 후의 결과 문서는 아래와 같습니다.

마지막으로ExecuteCustomLogicOnEmptyRegions메서드를 호출하고 처리기 메서드 내에서 처리해야 하는 테이블 이름을 지정하고 자동으로 제거할 다른 이름을 지정할 수 있습니다.
예
처리기 클래스를 통해 처리할ContactDetails영역만 지정하는 방법을 보여 줍니다.
지정된ArrayList로 이 오버로드를 호출하면 지정된 영역에 대한 데이터 행만 포함된 데이터 원본이 만들어집니다. ContactDetails영역 이외의 영역은 처리되지 않으며 대신Mail Merge엔진에 의해 자동으로 제거됩니다. 원래 핸들러의 코드를 사용하여 위의 호출 결과가 아래에 나와 있습니다.
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.