Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
Podczas pracy z dokumentami ważne jest, aby móc łatwo wyodrębnić zawartość z określonego zakresu w ramach dokumentu. Treść może jednak składać się ze złożonych elementów, takich jak akapity, tabele, obrazy itp.
Niezależnie od tego, jaką zawartość należy ekstrahować, metoda ekstrakcji tej zawartości zawsze będzie określana przez które węzły są wybierane do ekstrahowania zawartości. Mogą to być całe ciała tekstowe lub proste operacje tekstowe.
Istnieje wiele możliwych sytuacji, a zatem wiele różnych typów węzłów do rozważenia podczas ekstrakcji treści. Na przykład, możesz chcieć wyodrębnić zawartość pomiędzy:
W niektórych sytuacjach może być nawet konieczne połączenie różnych typów węzłów, takich jak pobieranie zawartości pomiędzy akapitem a polem, lub pomiędzy biegiem a zakładką.
Ten artykuł zawiera implementację kodu do ekstrakcji tekstu pomiędzy różnymi węzłami, jak również przykłady wspólnych scenariuszy.
Często celem ekstrakcji treści jest powielenie lub zapisanie jej oddzielnie w nowym dokumencie. Na przykład można pobrać zawartość i:
Można to łatwo osiągnąć używając Aspose.Words oraz wdrożenie kodu poniżej.
Kod w tej sekcji odnosi się do wszystkich możliwych sytuacji opisanych powyżej za pomocą jednej uogólnionej i powtarzalnej metody. Ogólny zarys tej techniki obejmuje:
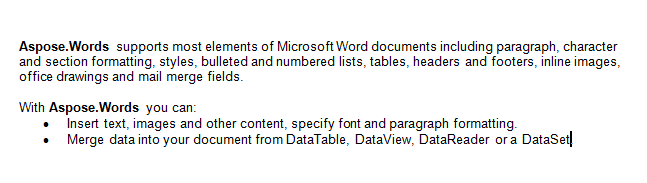
Będziemy pracować z dokumentu poniżej w tym artykule. Jak widać zawiera on wiele różnych treści. Uwaga: dokument zawiera drugą sekcję zaczynającą się na środku pierwszej strony. Zakładka i komentarz są również obecne w dokumencie, ale nie są widoczne na ekranie poniżej.

Aby wyodrębnić zawartość z dokumentu należy zadzwonić ExtractContent metoda poniżej i przekazać odpowiednie parametry.
Podstawą tej metody jest znalezienie węzłów poziomu blokady (akapity i tabele) i klonowanie ich do tworzenia identycznych kopii. Jeśli przepuszczane węzły znacznikowe są block- level, to metoda jest w stanie po prostu skopiować zawartość na tym poziomie i dodać ją do tablicy.
Jeżeli jednak węzły znacznikowe są wtykowe (dziecko akapitu), sytuacja staje się bardziej skomplikowana, ponieważ konieczne jest podzielenie akapitu na węzeł inline, czy to bieganie, zakładki itp. Usuwa się zawartość w sklonowanych węzłach macierzystych niewystępujących pomiędzy znacznikami. Proces ten jest stosowany w celu zapewnienia, że węzły inline nadal zachowują formatowanie punktu macierzystego.
Metoda będzie również przeprowadzać kontrole węzłów przekazywanych jako parametry i rzuca wyjątek, jeśli jeden z węzłów jest nieprawidłowy. Parametry, które należy przekazać tej metodzie, to:
StartNode oraz EndNode. Pierwsze dwa parametry to węzły, które określają, gdzie ma rozpocząć się ekstrakcja zawartości i zakończyć się odpowiednio. Węzły te mogą być obydwoma poziomami bloku (Paragraph , Table ) lub poziom inline (np. Run , FieldStart , BookmarkStart itd.):
IsInclusive. Określa, czy markery są włączone do ekstrakcji, czy nie. Jeśli ta opcja jest ustawiona na false i ten sam węzeł lub kolejne węzły są przekazywane, następnie zostanie zwrócona pusta lista:
Wdrożenie ExtractContent metody można znaleźć Tutaj. Metoda ta zostanie uwzględniona w scenariuszach zawartych w niniejszym artykule.
Zdefiniujemy również metodę niestandardową, aby łatwo wygenerować dokument z wyciągniętych węzłów. Metoda ta jest stosowana w wielu scenariuszach poniżej i po prostu tworzy nowy dokument i importuje do niego wydobytą zawartość.
Poniższy przykład kodu pokazuje jak wziąć listę węzłów i umieścić je w nowym dokumencie:
Wskazuje to, w jaki sposób stosować powyższą metodę w celu wyodrębnienia zawartości pomiędzy poszczególnymi akapitami. W tym przypadku chcemy wyodrębnić ciało listu znalezionego w pierwszej połowie dokumentu. Możemy powiedzieć, że jest to między 7 a 11 akapitem.
Poniższy kod realizuje to zadanie. Właściwe ustępy są ekstrahowane z wykorzystaniem getChild metoda na dokumencie i przekazywanie określonych wskaźników. Następnie przenosimy te węzły do ExtractContent metoda i stwierdzenie, że mają one zostać włączone do ekstrakcji. Metoda ta zwróci skopiowaną zawartość pomiędzy tymi węzłami, które następnie zostaną dodane do nowego dokumentu.
Poniższy przykład kodu pokazuje, jak wyodrębnić zawartość między konkretnymi akapitami za pomocą ExtractContent Metoda powyżej:
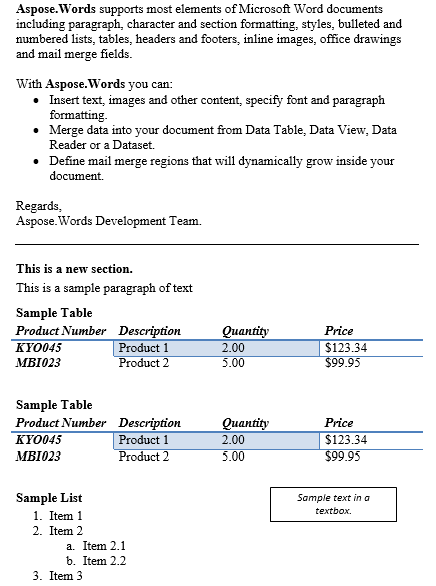
Dokument wyjściowy zawiera dwa akapity, które zostały wydobyte.
Możemy wyodrębnić zawartość pomiędzy dowolnymi kombinacjami węzłów block- level lub inline. W tym scenariuszu poniżej wyodrębnimy treść między akapitem pierwszym a tabelą w sekcji drugiej łącznie. Dostajemy węzły znaczników dzwoniąc getFirstParagraph oraz getChild metoda na drugiej części dokumentu w celu pobrania odpowiedniej Paragraph oraz Table węzły. W przypadku niewielkich zmian powielmy zawartość i wstawimy poniżej oryginału.
Poniższy przykład kodu pokazuje, jak wyodrębnić zawartość między akapitem i tabelą za pomocą ExtractContent Metoda:
Poniżej podsumowano treść akapitu i tabeli.
Może być konieczne wyodrębnienie zawartości między akapitami tego samego lub innego stylu, np. między akapitami oznaczonymi stylami nagłówków.
Poniższy kod pokazuje, jak to osiągnąć. Jest to prosty przykład, który wyciąga zawartość między pierwszą instancją stylów “Nagłówek 1” i “Nagłówek 3” bez wyciągania nagłówków. Aby to zrobić, ustawiamy ostatni parametr na false, który określa, że węzły znacznikowe nie powinny być włączone.
W prawidłowym wykonaniu powinno to być prowadzone w pętli w celu wyodrębnienia treści pomiędzy wszystkimi akapitami tych stylów z dokumentu. Wydobyta zawartość jest kopiowana do nowego dokumentu.
Poniższy przykład kodu pokazuje, jak wyodrębnić zawartość między akapitami z konkretnych stylów za pomocą ExtractContent Metoda:
Poniżej przedstawiono wynik poprzedniej operacji.

Można pobrać zawartość między węzłami inline, takich jak Run Jak również. Runs z różnych punktów mogą być przekazywane jako markery. Poniższy kod pokazuje jak wyodrębnić określony tekst pomiędzy tymi samymi Paragraph węzeł.
Poniższy przykład kodu pokazuje, jak wyodrębnić zawartość pomiędzy poszczególnymi ruchami tego samego akapitu za pomocą ExtractContent Metoda:
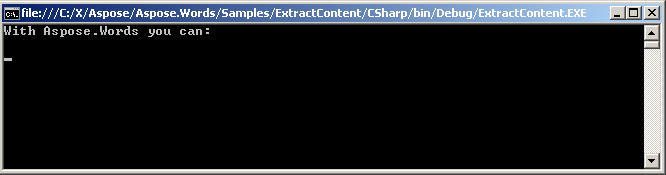
Wyekstrahowany tekst jest wyświetlany na konsoli
Aby użyć pola jako markera, FieldStart Należy przejść przez węzeł. Ostatni parametr ExtractContent metoda określa, czy całe pole ma być włączone, czy nie. Wyciągnijmy zawartość pomiędzy polem “FullName” a akapitem w dokumencie. Używamy moveToMergeField metody DocumentBuilder Klasa. To zwróci FieldStart węzeł z nazwy pola scalenia przeszedł do niego.
W naszym przypadku ustawmy ostatni parametr przekazywany do ExtractContent metoda false wyłączenie pola z ekstrakcji. Dodamy ekstrahowaną zawartość do PDF.
Poniższy przykład kodu pokazuje, jak wyodrębnić zawartość pomiędzy określonym polem i paragrafem w dokumencie za pomocą ExtractContent Metoda:
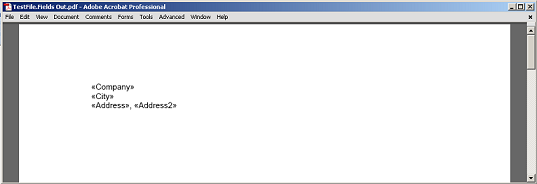
Wyekstrahowana zawartość pomiędzy polem a akapitem, bez pól i węzłów znaczników paragrafów, które są przekazywane do PDF.
W dokumencie zawartość, która jest zdefiniowana w zakładce jest zamykana przez BookmarkStart i węzły BookmarkEnd. Zawartość znaleziona pomiędzy tymi dwoma węzłami tworzy zakładkę. Możesz przekazać jeden z tych węzłów jako każdy marker, nawet jeden z różnych zakładek, o ile znacznik początkowy pojawi się przed znacznikiem kończącym w dokumencie.
W naszym przykładowym dokumencie mamy jedną zakładkę o nazwie “Bookmark1”. Zawartość tej zakładki jest podświetlana w naszym dokumencie:
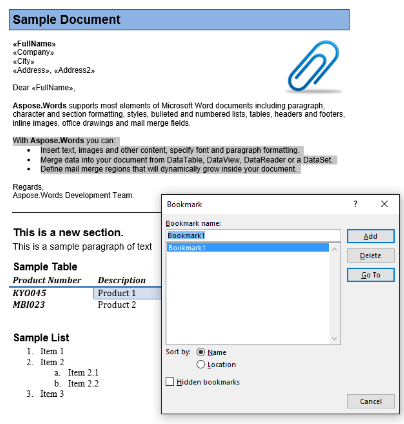
Wyciągniemy tę zawartość do nowego dokumentu używając poniższego kodu. W IsInclusive opcja parametru pokazuje jak zachować lub wyrzucić zakładkę.
Poniższy przykład kodu pokazuje jak wyodrębnić zawartość, do której odnosi się zakładka ExtractContent Metoda:
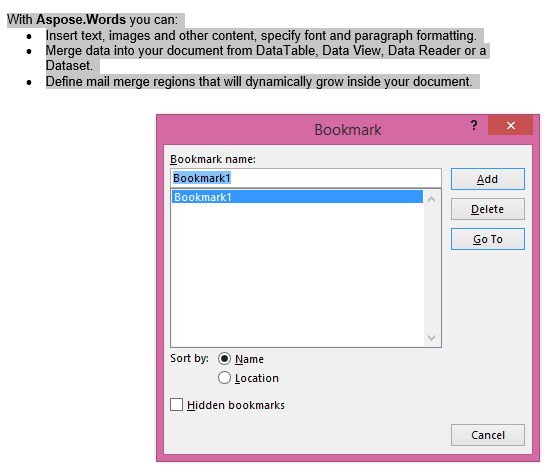
Wyjście ekstrahowane z IsInclusive parametr ustawiony na true. Kopia zachowa również zakładkę.
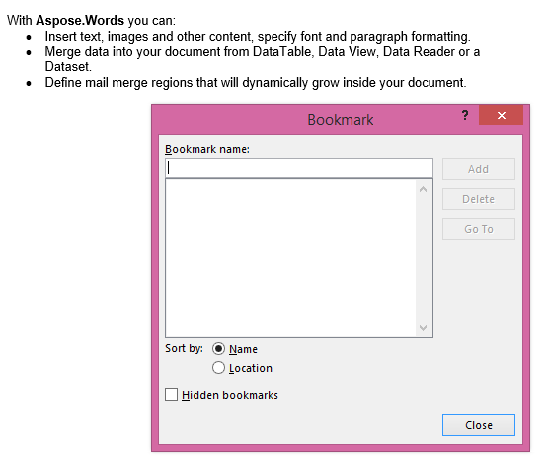
Wyjście ekstrahowane z IsInclusive parametr ustawiony na false. Kopia zawiera zawartość, ale bez zakładki.
Komentarz składa się z węzłów CommentRangeStart, CommentRangeEnd i Comment. Wszystkie węzły są w linii. Pierwsze dwa węzły umieszczają zawartość w dokumencie, do którego odnosi się komentarz, jak widać w poniższym zrzucie ekranu.
W Comment sam węzeł jest InlineStory które mogą zawierać paragrafy i działa. Jest to przesłanie komentarza postrzegane jako bańka komentarza w panelu przeglądu. Ponieważ węzeł ten jest inline i potomkiem ciała można również wydobyć zawartość z wewnątrz tej wiadomości, jak również.
W naszym dokumencie mamy jeden komentarz. Pokażmy to pokazując znaczniki w zakładce Przegląd:
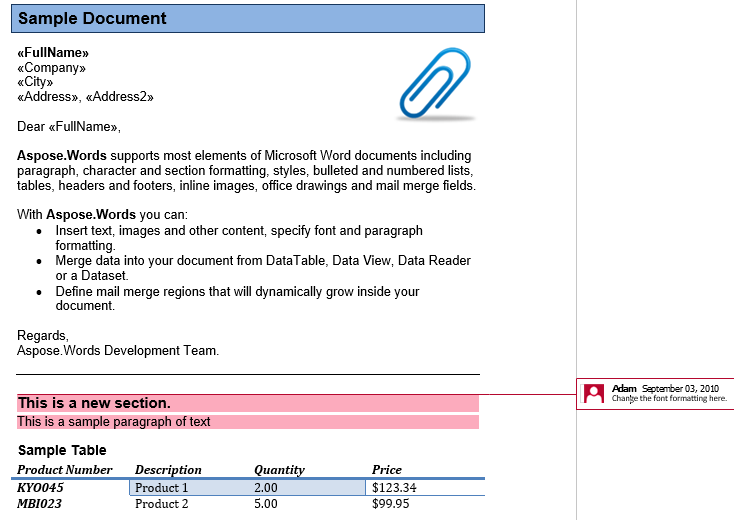
Komentarz obejmuje nagłówek, pierwszy akapit oraz tabelę w sekcji drugiej. Wyciągnijmy ten komentarz do nowego dokumentu. W IsInclusive opcja dyktuje, czy komentarz jest przechowywany lub odrzucany.
Poniżej przedstawiono poniższy przykład kodu:
Po pierwsze ekstrahowane wyjście z IsInclusive parametr ustawiony na true. Kopia zawiera również komentarz.
Po drugie, ekstrahowana produkcja isInclusive ustawiony na false. Kopia zawiera treść, ale bez komentarza.

Aspose.Words może być stosowany nie tylko do tworzenia Microsoft Word dokumenty budując je dynamicznie lub łącząc szablony z danymi, ale również do przetwarzania dokumentów w celu wyodrębnienia oddzielnych elementów dokumentów, takich jak nagłówki, stopki, akapity, tabele, obrazy i inne. Innym możliwym zadaniem jest znalezienie tekstu określonego formatowania lub stylu.
Użyj DocumentVisitor klasy do wdrożenia tego scenariusza użytkowania. Klasa ta odpowiada dobrze znanemu wzorowi projektowemu Odwiedzających. Z DocumentVisitor, można zdefiniować i wykonać niestandardowe operacje, które wymagają wyliczenia nad drzewem dokumentów.
DocumentVisitor zawiera zestaw VisitXXX metody, które są wywoływane przy napotkaniu określonego elementu dokumentu (węzła). Na przykład: VisitParagraphStart jest wywoływany przy odnalezieniu początku akapitu tekstowego oraz VisitParagraphEnd jest wywoływany w momencie znalezienia końca akapitu tekstowego. Każdy DocumentVisitor.VisitXXX metoda akceptuje odpowiedni obiekt, który napotyka, więc można go używać w razie potrzeby (powiedzmy pobrać formatowanie), np. oba VisitParagraphStart oraz VisitParagraphEnd Zaakceptuj Paragraph obiekt.
Każdy DocumentVisitor.VisitXXX metoda zwraca a VisitorAction wartość kontrolująca wyliczenie węzłów. Możesz poprosić o kontynuowanie wyliczania, pominięcie bieżącego węzła (ale kontynuuj wyliczanie) lub zatrzymanie wyliczania węzłów.
Są to kroki, które należy wykonać, aby programowo określić i wyodrębnić różne części dokumentu:
DocumentVisitor zapewnia domyślną implementację dla wszystkich DocumentVisitor.VisitXXX metody. Ułatwia to tworzenie nowych dokumentów odwiedzających, ponieważ tylko metody wymagane dla danego odwiedzającego muszą być nadane. Nie jest konieczne lekceważenie wszystkich metod odwiedzających.
Poniższy przykład pokazuje jak używać wzorca Odwiedzający, aby dodać nowe operacje do Aspose.Words model obiektu. W tym przypadku tworzymy prosty konwerter dokumentów w formacie tekstowym:
Sposoby pobierania tekstu z dokumentu są następujące:
SaveFormat.Text parametr. Wewnętrznie, przywołuje zapis jako tekst do strumienia pamięci i zwraca otrzymany ciągNode.GetText oraz Node.ToStringA Dokument Word może zawierać znaki kontrolne, które wyznaczają specjalne elementy, takie jak pole, koniec komórki, koniec sekcji itp. Pełna lista możliwych znaków kontroli słowa jest zdefiniowana w ControlChar Klasa. W GetText metoda zwraca tekst ze wszystkimi znakami znaków sterowania obecnymi w węźle.
Wywołanie ToString zwraca proste przedstawienie tekstu dokumentu tylko bez znaków kontrolnych. Dalsze informacje na temat wywozu w formie zwykłego tekstu znajdują się w: Using SaveFormat.Text.
Poniższy przykład kodu pokazuje różnicę pomiędzy wywołaniem GetText oraz ToString metody na węźle:
SaveFormat.TextTen przykład zapisuje dokument w następujący sposób:
Poniższy przykład kodu pokazuje jak zapisać dokument w formacie TXT:
Może być konieczne pobranie obrazów dokumentów, aby wykonać niektóre zadania. Aspose.Words pozwala na to również.
Poniższy przykład kodu pokazuje jak wyodrębnić obrazy z dokumentu:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.