Como aplicar lógica personalizada a regiões não mescladas
Existem algumas situações em que a remoção completa de regiões não mescladas do documento durante Mail Merge não é desejada ou faz com que o documento pareça incompleto. Isso pode ocorrer quando a ausência de dados de entrada deve ser exibida ao usuário na forma de uma mensagem, em vez de a região ser completamente removida.
Há também momentos em que a remoção da região não utilizada por si só não é suficiente, por exemplo, se a região for precedida de um título ou se a região estiver contida num quadro. Se esta região não for utilizada, o Título e a tabela continuarão a permanecer após a remoção da região, o que parecerá deslocado no documento.
Este artigo fornece uma solução para definir manualmente como as regiões não utilizadas no documento são tratadas. O código base para esta funcionalidade é fornecido e pode ser facilmente reutilizado noutro projecto.
A lógica a ser aplicada a cada região é definida dentro de uma classe que implementa a interface IFieldMergingCallback. Da mesma forma, um manipulador Mail Merge pode ser configurado para controlar como cada campo é mesclado, este manipulador pode ser configurado para executar ações em cada campo em uma região não utilizada ou na região como um todo. Dentro deste manipulador, você pode definir o código para alterar o texto de uma região, remover nós ou linhas e células vazias, etc.
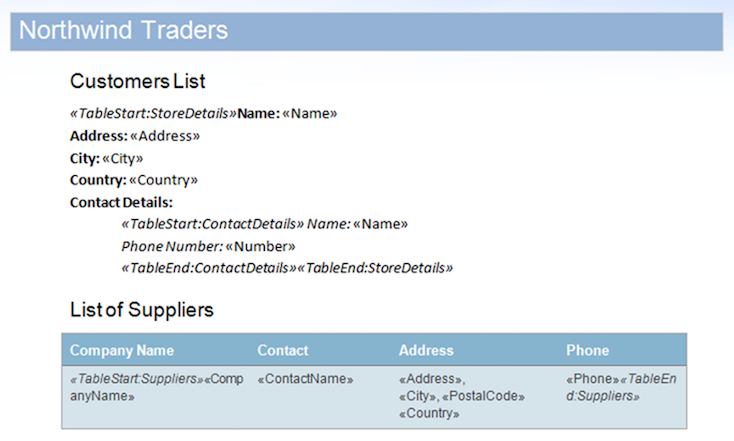
Nesta amostra, utilizaremos o documento apresentado abaixo. Contém regiões aninhadas e uma região contida numa tabela.
Como uma demonstração rápida, podemos executar um banco de dados de amostra no documento de amostra com o sinalizador MailMergeCleanupOptions.REMOVE_UNUSED_REGIONS habilitado. Esta propriedade removerá automaticamente regiões não mescladas do documento durante um mail merge.
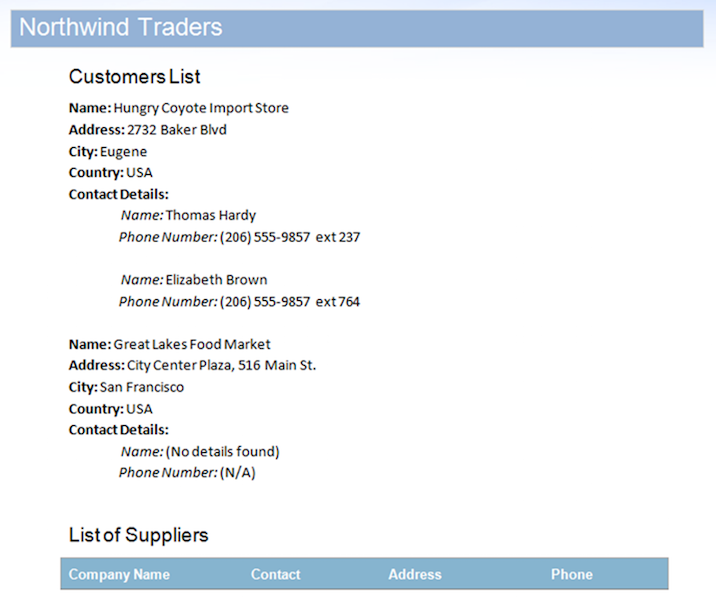
A fonte de dados inclui dois registos para a Região StoreDetails, mas propositadamente tem quaisquer dados para as regiões ContactDetails filhas para um dos registos. Além disso, a Região Suppliers também não possui linhas de dados. Isso fará com que as regiões não utilizadas permaneçam no documento. O resultado após a fusão do documento com esta fonte de dados está abaixo.

Conforme observado na imagem, você pode ver que a região ContactDetails para o segundo registro e as regiões Suppliers foram removidas automaticamente pelo mecanismo Mail Merge, pois não possuem dados. No entanto, existem alguns problemas que fazem com que este documento de saída pareça incompleto:
- A região ContactDetails ainda deixa um parágrafo com o texto"dados de contacto".
- No mesmo caso, não há indicação de que não existam números de telefone, apenas um espaço em branco que possa causar confusão.
- A tabela e o título relacionados à região Suppliers também permanecem após a remoção da região dentro da tabela.
A técnica fornecida neste artigo demonstra como aplicar a lógica personalizada a cada região não mesclada para evitar esses problemas.
A Solução
Para aplicar manualmente a lógica a cada região não utilizada no documento, aproveitamos os recursos já disponíveis em Aspose.Words.
O mecanismo Mail Merge fornece uma propriedade para remover regiões não utilizadas por meio do sinalizador MailMergeCleanupOptions.RemoveUnusedRegions. Isso pode ser desativado para que essas regiões sejam deixadas intactas durante um mail merge. Isso nos permite deixar as regiões não mescladas no documento e, em vez disso, tratá-las manualmente.
Podemos então tirar proveito da propriedade MailMerge.FieldMergingCallback como um meio de aplicar nossa própria lógica personalizada a essas regiões não mescladas durante Mail Merge através do uso de uma classe de manipulador implementando a interface IFieldMergingCallback.
Este código dentro da classe handler é a única classe que você precisará modificar para controlar a lógica aplicada a regiões não mescladas. O outro código desta amostra pode ser reutilizado sem modificação em qualquer projecto.
Este exemplo de projecto demonstra esta técnica. Envolve as seguintes etapas:
- Execute Mail Merge no documento usando sua fonte de dados. O sinalizador MailMergeCleanupOptions.RemoveUnusedRegions está desativado por enquanto queremos que as regiões permaneçam para que possamos lidar com elas manualmente. Quaisquer regiões sem dados serão deixadas sem mistura no documento.
- Chame o método ExecuteCustomLogicOnEmptyRegions. Este método é fornecido nesta amostra. Ele executa ações que permitem que o manipulador especificado seja chamado para cada região não mesclada. Este método é reutilizável e pode ser copiado inalterado para qualquer projecto que o exija (juntamente com quaisquer métodos dependentes).Este método executa as seguintes etapas:
- Define o manipulador especificado pelo Usuário para a propriedade MailMerge.FieldMergingCallback.
- Chama o método CreateDataSourceFromDocumentRegions que aceita os nomes das regiões que contêm Document e ArrayList do utilizador. Este método criará uma fonte de dados fictícia contendo tabelas para cada região não mesclada no documento.
- Executa Mail Merge no documento utilizando a fonte de dados fictícia. Quando Mail Merge é executado com esta fonte de dados, ele permite que o manipulador especificado pelo usuário seja chamado para cada região unmerge e a lógica personalizada aplicada
O Código
A aplicação do método ExecuteCustomLogicOnEmptyRegions encontra-se abaixo. Este método aceita vários parâmetros:
- O objeto Document contendo regiões não mescladas que devem ser tratadas pelo manipulador passado.
- A classe do manipulador que define a lógica a ser aplicada a regiões não mescladas. Este manipulador deve implementar o IFieldMergingCallback interface.
- Através do uso da sobrecarga apropriada, o método também pode aceitar um terceiro parâmetro – uma lista de nomes de regiões como strings. Se isto for especificado, apenas os nomes das regiões restantes do documento especificado na lista serão tratados manualmente. Outras regiões que são encontradas não serão chamadas pelo manipulador e removidas automaticamente. Quando a sobrecarga com apenas dois parâmetros é especificada, todas as regiões restantes do documento são incluídas pelo método a ser tratado manualmente.
Exemplo
Mostra como executar lógica personalizada em regiões não utilizadas usando o manipulador especificado.
Exemplo
Define o método utilizado para tratar manualmente regiões não mescladas.
Este método envolve encontrar todas as regiões não mescladas no documento. Isso é feito usando o método MailMerge.GetFieldNames. Este método retorna todos os campos de mesclagem no documento, incluindo os marcadores de início e fim da região (representados por campos de mesclagem com o prefixo TableStart ou TableEnd).
Quando um campo de mesclagem TableStart é encontrado, ele é adicionado como um novo DataTable ao DataSet. Como uma região pode aparecer mais de uma vez (por exemplo, porque é uma região aninhada onde a região pai foi mesclada com vários registros), a tabela só é criada e adicionada se ainda não existir no DataSet.
Quando um início de região apropriado é encontrado e adicionado à base de dados, o campo seguinte (que corresponde ao primeiro campo da região) é adicionado ao DataTable. Apenas o primeiro campo deve ser adicionado para cada campo na região a ser mesclado e passado para o manipulador.
Também definimos o valor do campo do primeiro campo como “FirstField” para facilitar a aplicação da lógica ao primeiro ou a outros campos da região. Ao incluir isso, significa que não é necessário codificar o nome do primeiro campo ou implementar código extra para verificar se o campo atual é o primeiro no código do manipulador.
O código abaixo demonstra como este sistema funciona. O documento apresentado no início deste artigo é remergido com a mesma fonte de dados, mas desta vez, as regiões não utilizadas são tratadas por código personalizado.
Exemplo
Mostra como lidar com regiões não mescladas após Mail Merge com código definido pelo Usuário.
O código executa operações diferentes com base no nome da região recuperada usando a propriedade FieldMergingArgs.TableName. Observe que, dependendo do documento e das Regiões, você pode codificar o manipulador para executar a lógica dependente de cada região ou código que se aplica a cada região não mesclada no documento ou uma combinação de ambos.
A lógica para a Região ContactDetails envolve alterar o texto de cada campo na Região ContactDetails com uma mensagem apropriada informando que não há dados. Os nomes de cada campo são correspondidos dentro do manipulador usando a propriedade FieldMergingArgs.FieldName.
Um processo semelhante é aplicado à região Suppliers com a adição de código extra para lidar com a tabela que contém a região. O código verificará se a região está contida numa tabela (uma vez que pode já ter sido removida). Se for, removerá toda a tabela do documento, bem como o parágrafo que o precede, desde que esteja formatado com um estilo de cabeçalho, por exemplo, “Heading 1”.
Exemplo
Mostra como definir a lógica personalizada em um manipulador implementando IFieldMergingCallback que é executado para regiões não mescladas no documento.
O resultado do código acima é mostrado abaixo. Os campos não misturados na primeira região são substituídos por texto informativo e a remoção da tabela e do título permite que o documento pareça completo.

O código que remove a tabela pai também pode ser executado em todas as regiões não utilizadas, em vez de apenas em uma região específica, removendo a verificação do nome da tabela. Nesse caso, se qualquer região dentro de uma tabela não foi mesclada com nenhum dado, tanto a região quanto a tabela de contêiner também serão removidas automaticamente.
Podemos inserir código diferente no manipulador para controlar como as regiões não mescladas são tratadas. Usar o código abaixo no manipulador, em vez disso, mudará o texto no primeiro parágrafo da região para uma mensagem útil, enquanto quaisquer parágrafos subsequentes na região são removidos. Estes outros parágrafos são removidos, uma vez que permaneceriam na região após a fusão da nossa mensagem.
O texto de substituição é mesclado no primeiro campo definindo o texto especificado na propriedade FieldMergingArgs.Text. O texto desta propriedade é mesclado no campo pelo mecanismo Mail Merge.
O código aplica isso apenas ao primeiro campo da região, verificando a propriedade FieldMergingArgs.FieldValue. O valor do campo do primeiro campo da região está marcado com " FirstField". Isso torna esse tipo de lógica mais fácil de implementar em muitas regiões, pois nenhum código extra é necessário.
Exemplo
Mostra como substituir uma região não utilizada por uma mensagem e remover parágrafos adicionais.
O documento resultante após a execução do código acima é mostrado abaixo. A região não utilizada é substituída por uma mensagem a indicar que não existem registos a apresentar.

Como outro exemplo, podemos inserir o código abaixo no lugar do código que originalmente manipula o SuppliersRegion. Isso exibirá uma mensagem dentro da tabela e mesclará as células em vez de remover a tabela do documento. Como a região reside em uma tabela com várias células, parece melhor ter as células da tabela mescladas e a mensagem centralizada.
Exemplo
Mostra como mesclar todas as células-mãe de uma região não utilizada e exibir uma mensagem na tabela.
O documento resultante após a execução do código acima é mostrado abaixo.

Finalmente, podemos chamar o método ExecuteCustomLogicOnEmptyRegions e especificar os nomes das tabelas que devem ser manipulados dentro do nosso método handler, enquanto especificamos outros a serem removidos automaticamente.
Exemplo
Mostra como especificar apenas a região ContactDetails a ser tratada através da classe handler.
Chamar essa sobrecarga com o ArrayList especificado criará a fonte de dados que contém apenas linhas de dados para as regiões especificadas. Regiões diferentes da região ContactDetails não serão tratadas e serão removidas automaticamente pelo mecanismo Mail Merge. O resultado da chamada acima usando o código em nosso manipulador original é mostrado abaixo.