Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
Чтобы лучше контролировать работу таблиц, узнайте, как манипулировать столбцами и строками.
Управление столбцами, строками и ячейками осуществляется путем обращения к выбранному узлу документа по его индексу. Поиск индекса любого узла включает в себя сбор всех дочерних узлов типа element из родительского узла, а затем использование метода IndexOf для поиска индекса нужного узла в коллекции.
Иногда вам может потребоваться внести изменения в определенную таблицу в документе. Для этого вы можете обратиться к таблице по ее индексу.
В следующем примере кода показано, как получить индекс таблицы в документе:
Аналогичным образом, вам может потребоваться внести изменения в определенную строку в выбранной таблице. Для этого вы также можете обратиться к строке по ее индексу.
В следующем примере кода показано, как получить индекс строки в таблице:
Наконец, вам может потребоваться внести изменения в определенную ячейку, и вы также можете сделать это с помощью индекса ячейки.
В следующем примере кода показано, как получить индекс ячейки в строке:
В объектной модели документа Aspose.Words (DOM) узел Table состоит из Row узлов, а затем из Cell узлов. Таким образом, в объектной модели документа Document из Aspose.Words, как и в документах Word, отсутствует понятие столбца.
По замыслу, строки таблицы в Microsoft Word и Aspose.Words полностью независимы, а основные свойства и операции содержатся только в строках и ячейках таблицы. Это дает таблицам возможность иметь некоторые интересные атрибуты:
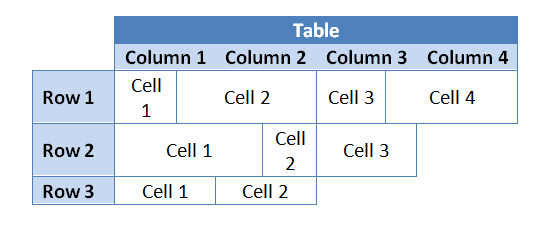
Любые операции, выполняемые со столбцами, на самом деле являются “сокращениями”, которые выполняют операцию путем коллективного изменения ячеек строк таким образом, что это выглядит так, как будто они применяются к столбцам. То есть вы можете выполнять операции со столбцами, просто повторяя индекс одной и той же ячейки строки таблицы.
Следующий пример кода упрощает такие операции, демонстрируя класс facade, который собирает ячейки, составляющие “столбец” таблицы:
В следующем примере кода показано, как вставить пустой столбец в таблицу:
В следующем примере кода показано, как удалить столбец из таблицы в документе:
Вы можете выбрать повторение первой строки таблицы в качестве строки заголовка только на первой странице или на каждой странице, если таблица разделена на несколько частей. В Aspose.Words вы можете повторять строку заголовка на каждой странице, используя свойство HeadingFormat.
Вы также можете пометить несколько строк заголовка, если такие строки расположены одна за другой в начале таблицы. Для этого вам необходимо применить к этим строкам свойства HeadingFormat.
В следующем примере кода показано, как создать таблицу, содержащую строки заголовка, которые повторяются на последующих страницах:
В некоторых случаях содержимое таблицы не должно быть разделено по страницам. Например, если заголовок находится над таблицей, заголовок и таблица всегда должны располагаться вместе на одной странице, чтобы сохранить надлежащий внешний вид.
Есть два отдельных метода, которые полезны для достижения этой функциональности:
Allow row break across pages, который применяется к строкам таблицыKeep with next, который применяется к абзацам в ячейках таблицыПо умолчанию вышеуказанные свойства отключены.
Это предполагает ограничение разбиения содержимого внутри ячеек строки на страницы. В Microsoft Word это можно найти в свойствах таблицы как параметр “Разрешить разбиение строки на страницы”. В Aspose.Words это находится под объектом RowFormat из Row как свойство RowFormat.AllowBreakAcrossPages.
В следующем примере кода показано, как отключить разбиение строк по страницам для каждой строки таблицы:
Чтобы таблица не разбивалась на страницы, нам нужно указать, что мы хотим, чтобы содержимое, содержащееся в таблице, оставалось единым.
Для этого в Aspose.Words используется метод, который позволяет пользователям выбирать таблицу и устанавливать для параметра KeepWithNext значение true для каждого абзаца в ячейках таблицы. Исключением является последний абзац в таблице, для которого должно быть установлено значение false.
В следующем примере кода показано, как настроить таблицу так, чтобы она оставалась вместе на одной странице:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.