Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
هنگام کار با اسناد، مهم است که بتوانید به راحتی محتوای یک محدوده خاص را در یک سند استخراج کنید. با این حال، محتوا ممکن است شامل عناصر پیچیده ای مانند پاراگراف ها، جداول، تصاویر و غیره باشد.
صرف نظر از اینکه چه محتوایی باید استخراج شود، روش استخراج آن محتوا همیشه تعیین می شود که کدام گره ها برای استخراج محتوا بین آنها انتخاب می شوند. این می تواند کل متن بدن و یا متن ساده اجرا می شود.
موقعیت های احتمالی زیادی وجود دارد و بنابراین انواع گره های مختلفی برای استخراج محتوا وجود دارد. برای مثال، ممکن است بخواهید محتوای بین:
در برخی شرایط، حتی ممکن است لازم باشد انواع گره های مختلف مانند استخراج محتوا بین یک پاراگراف و یک فیلد یا بین یک اجرا و یک نشانه را ترکیب کنید.
این مقاله پیاده سازی کد برای استخراج متن بین گره های مختلف و همچنین نمونه هایی از سناریوهای رایج را ارائه می دهد.
اغلب هدف از استخراج محتوا این است که آن را به طور جداگانه در یک سند جدید تکرار یا ذخیره کنید. به عنوان مثال، شما می توانید محتوا را استخراج کنید و:
این کار را می توان با استفاده از Aspose.Words و پیاده سازی کد زیر به راحتی انجام داد.
کد در این بخش به تمام موقعیت های احتمالی که در بالا توضیح داده شد با یک روش عمومی و قابل استفاده مجدد می پردازد. طرح کلی این تکنیک شامل:
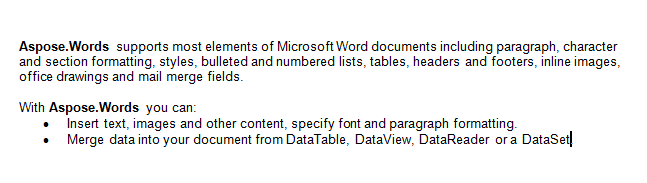
ما با سند زیر در این مقاله کار خواهیم کرد. همانطور که می بینید حاوی محتوای متنوعی است. همچنین توجه داشته باشید که این سند شامل بخش دوم است که در وسط صفحه اول شروع می شود. یک نشانه و نظر نیز در سند وجود دارد اما در تصویر زیر قابل مشاهده نیست.

برای استخراج محتوا از سند خود باید روش ExtractContent زیر را فراخوانی کنید و پارامترهای مناسب را منتقل کنید.
اساس اساسی این روش شامل یافتن گره های سطح بلوک (پاراگراف ها و جداول) و شبیه سازی آنها برای ایجاد نسخه های یکسان است. اگر گره های نشانگر عبور شده در سطح بلوک باشند، روش می تواند به سادگی محتوای آن سطح را کپی کند و آن را به آرایه اضافه کند.
با این حال، اگر گره های نشانگر خطی باشند (فرزند یک پاراگراف)، وضعیت پیچیده تر می شود، زیرا لازم است پاراگراف را در گره خطی تقسیم کنید، چه اجرا شود، زمینه های نشانه گذاری و غیره. محتوای در گره های والدین کلون شده که بین نشانگرها وجود ندارد حذف می شود. این فرآیند برای اطمینان از اینکه گره های خطی هنوز قالب بندی پاراگراف اصلی را حفظ می کنند، استفاده می شود.
این روش همچنین چک هایی را در گره های منتقل شده به عنوان پارامترها اجرا می کند و اگر هر یک از گره ها نامعتبر باشد، یک استثنا را پرتاب می کند. پارامترهایی که باید به این روش منتقل شوند عبارتند از:
StartNode و EndNode. دو پارامتر اول گره هایی هستند که تعریف می کنند که استخراج محتوا به ترتیب در کجا شروع و پایان می یابد. این گره ها می توانند هر دو سطح بلوک (Paragraph، Table) یا سطح خطی (به عنوان مثال Run, FieldStart, BookmarkStart و غیره):
IsInclusive. مشخص می کند که آیا نشانگرها در استخراج گنجانده شده اند یا نه. اگر این گزینه به false تنظیم شود و همان گره یا گره های متوالی منتقل شوند، یک لیست خالی بازگردانده می شود:
پیاده سازی روش ExtractContent که می توانید پیدا کنید اینجا. این روش در سناریوهای این مقاله ذکر خواهد شد.
ما همچنین یک روش سفارشی برای تولید آسان یک سند از گره های استخراج شده تعریف خواهیم کرد. این روش در بسیاری از سناریوهای زیر استفاده می شود و به سادگی یک سند جدید ایجاد می کند و محتوای استخراج شده را وارد آن می کند.
مثال کد زیر نشان می دهد که چگونه یک لیست از گره ها را بگیرید و آنها را در یک سند جدید قرار دهید:
این نشان می دهد که چگونه از روش بالا برای استخراج محتوا بین پاراگراف های خاص استفاده کنید. در این حالت می خواهیم بدنه نامه موجود در نیمه اول سند را استخراج کنیم. ما می توانیم بگوییم که این بین پاراگراف های 7 و 11 است.
کد زیر این کار را انجام می دهد. پاراگراف های مناسب با استفاده از روش getChild در سند استخراج می شوند و شاخص های مشخص شده را منتقل می کنند. سپس این گره ها را به روش ExtractContent منتقل می کنیم و بیان می کنیم که این ها باید در استخراج گنجانده شوند. این روش محتوای کپی شده بین این گره ها را که سپس در یک سند جدید وارد می شوند، باز می گرداند.
مثال کد زیر نشان می دهد که چگونه محتوای بین پاراگراف های خاص را با استفاده از روش ExtractContent بالا استخراج کنیم:
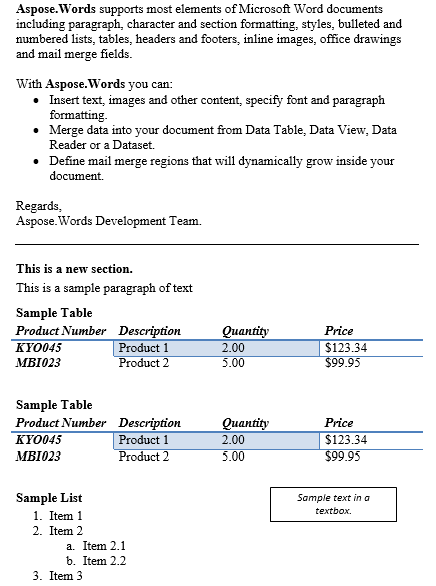
سند خروجی شامل دو پاراگراف است که استخراج شده است.
ما می توانیم محتوا را بین هر ترکیبی از گره های سطح بلوک یا خطی استخراج کنیم. در این سناریو زیر ما محتوای بین پاراگراف اول و جدول در بخش دوم را به طور کامل استخراج خواهیم کرد. ما گره های نشانگر را با فراخوانی روش getFirstParagraph و getChild در بخش دوم سند برای بازیابی گره های مناسب Paragraph و Table دریافت می کنیم. برای یک تغییر کوچک بیایید به جای آن محتوای را تکرار کنیم و آن را زیر اصل قرار دهیم.
مثال کد زیر نشان می دهد که چگونه محتوای بین یک پاراگراف و جدول را با استفاده از روش ExtractContent استخراج کنیم:
محتوای بین پاراگراف و جدول در زیر تکرار شده است نتیجه است.
ممکن است لازم باشد محتوای بین پاراگراف های سبک یکسان یا متفاوت مانند بین پاراگراف هایی که با سبک های عنوان مشخص شده اند را استخراج کنید.
کد زیر نشان می دهد که چگونه این کار را انجام دهید. این یک مثال ساده است که محتوای بین اولین نمونه از سبک های “Heading 1” و “Header 3” را بدون استخراج عناوین نیز استخراج می کند. برای انجام این کار ما آخرین پارامتر را به false تنظیم می کنیم، که مشخص می کند که گره های نشانگر نباید شامل شوند.
در یک پیاده سازی مناسب، این باید در یک حلقه اجرا شود تا محتوای بین تمام پاراگراف های این سبک ها از سند استخراج شود. محتوای استخراج شده در یک سند جدید کپی می شود.
مثال کد زیر نشان می دهد که چگونه محتوای بین پاراگراف ها را با سبک های خاص با استفاده از روش ExtractContent استخراج کنیم:
در زیر نتیجه عملیات قبلی است.

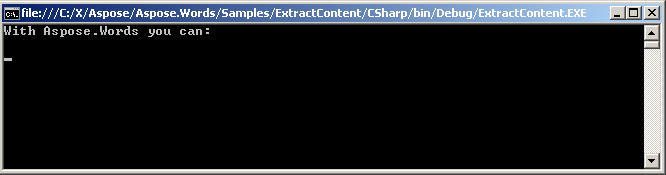
شما می توانید محتوا را بین گره های خطی مانند Run نیز استخراج کنید. Runs از پاراگراف های مختلف می تواند به عنوان نشانگر منتقل شود. کد زیر نشان می دهد که چگونه متن خاص را بین همان گره Paragraph استخراج کنیم.
مثال کد زیر نشان می دهد که چگونه محتوای بین اجراهای خاص همان پاراگراف را با استفاده از روش ExtractContent استخراج کنیم:
متن استخراج شده در کنسول نمایش داده می شود.
برای استفاده از یک فیلد به عنوان یک نشانگر، گره FieldStart باید منتقل شود. آخرین پارامتر به روش ExtractContent تعریف خواهد کرد که آیا کل فیلد باید شامل شود یا نه. بیایید محتوای بین فیلد ادغام “FullName” و یک پاراگراف در سند را استخراج کنیم. ما از روش moveToMergeField کلاس DocumentBuilder استفاده می کنیم. این گره FieldStart را از نام فیلد ادغام به آن منتقل می کند.
در مورد ما بیایید آخرین پارامتر منتقل شده به روش ExtractContent را به false تنظیم کنیم تا فیلد را از استخراج حذف کنیم. ما محتوای استخراج شده را به PDF ارائه خواهیم داد.
مثال کد زیر نشان می دهد که چگونه محتوای بین یک فیلد خاص و پاراگراف در سند با استفاده از روش ExtractContent استخراج شود:
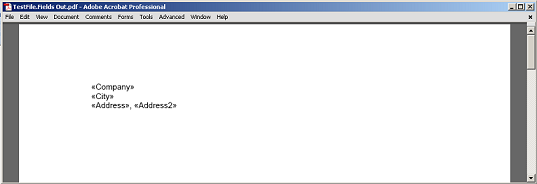
محتوای استخراج شده بین فیلد و پاراگراف، بدون گره های نشانگر فیلد و پاراگراف به PDF ارائه شده است.
در یک سند، محتوایی که در یک نشانه تعریف شده است توسط گره های BookmarkStart و BookmarkEnd بسته بندی شده است. محتوای موجود بین این دو گره نشانک را تشکیل می دهد. شما می توانید هر یک از این گره ها را به عنوان هر نشانگر، حتی آنهایی که از نشانه های مختلف هستند، عبور دهید، تا زمانی که نشانگر شروع قبل از نشانگر پایان در سند ظاهر شود.
در نمونه سند ما، ما یک نشانه داریم، به نام"Bookmark1". محتوای این نشانک در سند ما برجسته شده است:
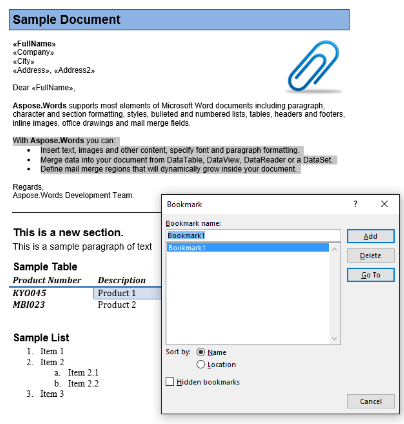
ما این محتوا را با استفاده از کد زیر به یک سند جدید استخراج خواهیم کرد. گزینه پارامتر IsInclusive نشان می دهد که چگونه علامت گذاری را حفظ یا دور بریزید.
مثال کد زیر نشان می دهد که چگونه محتوای ارجاع شده را با استفاده از روش ExtractContent استخراج کنیم:
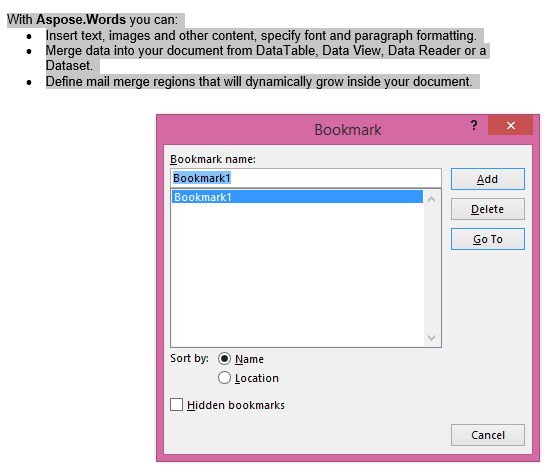
خروجی استخراج شده با پارامتر IsInclusive به true تنظیم شده است. نسخه هم علامت کتاب رو حفظ ميکنه
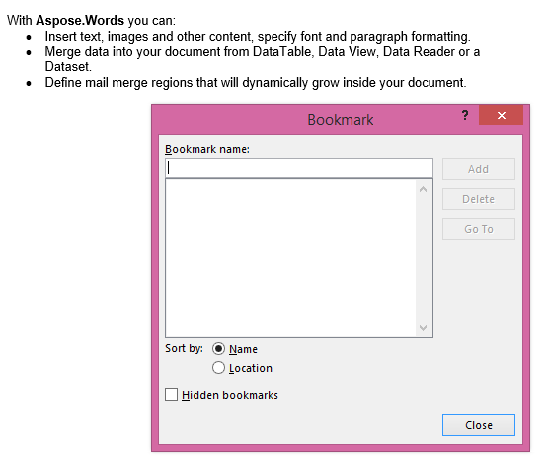
خروجی استخراج شده با پارامتر IsInclusive به false تنظیم شده است. نسخه شامل محتوا است اما بدون علامت کتاب.
یک نظر از گره های CommentRangeStart، CommentRangeEnd و نظر تشکیل شده است. همه این گره ها خطی هستند. دو گره اول محتوای سند را که توسط نظر ارجاع داده شده است، همانطور که در تصویر زیر دیده می شود، خلاصه می کند.
خود گره Comment یک InlineStory است که می تواند شامل پاراگراف ها و اجرا شود. این پیام نظر را به عنوان یک حباب نظر در صفحه بررسی نشان می دهد. از آنجا که این گره خطی است و از نسل یک بدن است شما همچنین می توانید محتوای داخل این پیام را نیز استخراج کنید.
در سند ما یک نظر داریم. بیایید آن را با نشان دادن نشانه گذاری در برگه بررسی نمایش دهیم:
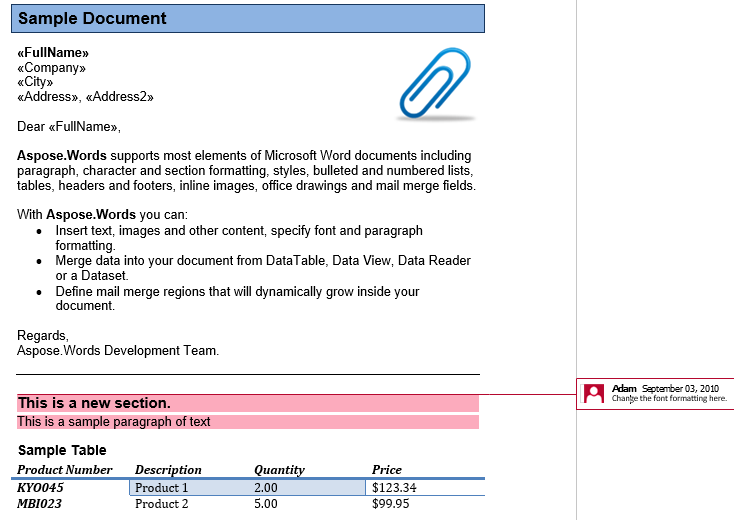
این نظر عنوان، پاراگراف اول و جدول را در بخش دوم خلاصه می کند. بیایید این نظر را به یک سند جدید تبدیل کنیم. گزینه IsInclusive تعیین می کند که آیا خود نظر حفظ شده یا رد شده است.
مثال کد زیر نشان می دهد که چگونه این کار را انجام دهید در زیر است:
اول خروجی استخراج شده با پارامتر IsInclusive به true تنظیم شده است. نسخه شامل نظر هم خواهد بود.
دوم خروجی استخراج شده با isInclusive به false تنظیم شده است. نسخه شامل محتوا است اما بدون نظر.

Aspose.Words می تواند نه تنها برای ایجاد Microsoft Word اسناد با ساخت آنها به صورت پویا یا ادغام قالب ها با داده ها، بلکه برای تجزیه اسناد به منظور استخراج عناصر سند جداگانه مانند سرصفحه ها، پای صفحه ها، پاراگراف ها، جداول، تصاویر و دیگران استفاده شود. یکی دیگر از وظایف ممکن این است که تمام متن قالب بندی یا سبک خاص را پیدا کنید.
برای اجرای این سناریوی استفاده از کلاس DocumentVisitor استفاده کنید. این کلاس با الگوی طراحی بازدید کننده شناخته شده مطابقت دارد. با DocumentVisitor می توانید عملیات سفارشی را که نیاز به شمارش بر روی درخت سند دارند تعریف و اجرا کنید.
DocumentVisitor مجموعه ای از روش های VisitXXX را فراهم می کند که هنگام برخورد با یک عنصر سند خاص (گره) فراخوانده می شود. به عنوان مثال، VisitParagraphStart زمانی فراخوانده می شود که ابتدای یک پاراگراف متنی پیدا شود و VisitParagraphEnd زمانی فراخوانده می شود که پایان یک پاراگراف متنی پیدا شود. هر روش DocumentVisitor.VisitXXX شیء مربوطه را که با آن روبرو می شود قبول می کند تا بتوانید در صورت نیاز از آن استفاده کنید (به عنوان مثال بازیابی قالب بندی)، به عنوان مثال هر دو شیء VisitParagraphStart و VisitParagraphEnd یک شیء Paragraph را قبول کنید.
هر روش DocumentVisitor.VisitXXX یک مقدار VisitorAction را باز می گرداند که شمارش گره ها را کنترل می کند. شما می توانید درخواست کنید که یا شمارش را ادامه دهید، گره فعلی را حذف کنید (اما شمارش را ادامه دهید)، یا شمارش گره ها را متوقف کنید.
این گام هایی است که باید برای تعیین و استخراج بخش های مختلف یک سند به صورت برنامه ریزی شده دنبال کنید:
DocumentVisitor پیاده سازی های پیش فرض برای تمام روش های DocumentVisitor.VisitXXX را فراهم می کند. این کار ایجاد بازدید کنندگان جدید سند را آسان تر می کند زیرا تنها روش های مورد نیاز برای بازدید کننده خاص باید نادیده گرفته شود. لازم نیست که تمام روش های بازدید کننده را نادیده بگیریم.
مثال زیر نشان می دهد که چگونه از الگوی بازدید کننده برای اضافه کردن عملیات جدید به مدل شیء Aspose.Words استفاده کنیم. در این حالت، ما یک مبدل سند ساده به قالب متن ایجاد می کنیم:
راه های بازیابی متن از سند عبارتند از:
SaveFormat.Text را منتقل کنید. در داخل، این save as text را به یک جریان حافظه فرا می خواند و رشته حاصل را باز می گرداندNode.GetText و Node.ToStringیک سند ورد می تواند شامل کاراکترهای کنترل باشد که عناصر خاصی مانند فیلد، انتهای سلول، انتهای بخش و غیره را تعیین می کند. لیست کامل کاراکترهای کنترل کلمه ممکن در کلاس ControlChar تعریف شده است. روش GetText متن را با تمام کاراکترهای کاراکتر کنترل موجود در گره باز می گرداند.
فراخوانی ToString نمایش متن ساده سند را تنها بدون کاراکترهای کنترل باز می گرداند. برای اطلاعات بیشتر در مورد صادرات به عنوان متن ساده به Using SaveFormat.Text مراجعه کنید.
مثال کد زیر تفاوت بین فراخوانی روش های GetText و ToString در یک گره را نشان می دهد:
SaveFormat.Textاین مثال سند را به شرح زیر ذخیره می کند:
مثال کد زیر نشان می دهد که چگونه یک سند را در فرمت TXT ذخیره کنید:
ممکن است برای انجام برخی کارها نیاز به استخراج تصاویر سند داشته باشید. Aspose.Words به شما اجازه می دهد این کار را نیز انجام دهید.
مثال کد زیر نشان می دهد که چگونه تصاویر را از یک سند استخراج کنید:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.