Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
Ao trabalhar com documentos, é importante poder extrair facilmente o conteúdo de um intervalo específico dentro de um documento. No entanto, o conteúdo pode consistir em elementos complexos, como parágrafos, tabelas, imagens, etc.
Independentemente de qual conteúdo precisa ser extraído, o método para extrair esse conteúdo será sempre determinado por quais nós são selecionados para extrair conteúdo entre. Estes podem ser corpos de texto inteiros ou execuções de texto simples.
Existem muitas situações possíveis e, portanto, muitos tipos de nós diferentes a serem considerados ao extrair conteúdo. Por exemplo, você pode querer extrair conteúdo entre:
Em algumas situações, pode até ser necessário combinar diferentes tipos de nós, como extrair conteúdo entre um parágrafo e um campo, ou entre uma execução e um marcador.
Este artigo fornece a implementação de código para extrair texto entre diferentes nós, bem como exemplos de cenários comuns.
Muitas vezes, o objetivo de extrair o conteúdo é duplicá-lo ou salvá-lo separadamente em um novo documento. Por exemplo, você pode extrair conteúdo e:
Isso pode ser facilmente alcançado usando Aspose.Words e a implementação do código abaixo.
O código desta secção aborda todas as situações possíveis acima descritas com um método generalizado e reutilizável. O esboço geral desta técnica envolve:
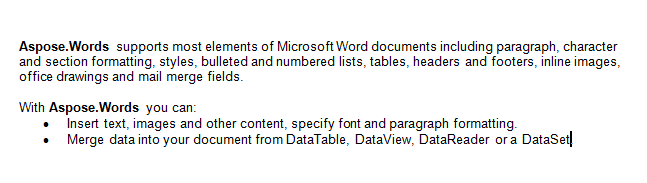
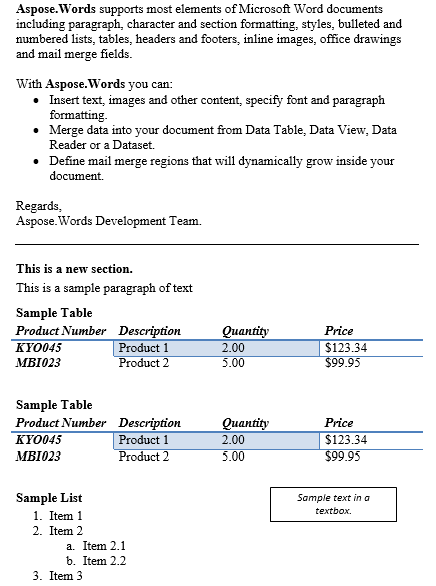
Trabalharemos com o documento abaixo neste artigo. Como você pode ver, ele contém uma variedade de conteúdos. Observe também que o documento contém uma segunda seção que começa no meio da primeira página. Um marcador e um comentário também estão presentes no documento, mas não são visíveis na imagem abaixo.

Para extrair o conteúdo do seu documento, você precisa chamar o método ExtractContent abaixo e passar os parâmetros apropriados.
A base subjacente a este método consiste em encontrar nós a nível de bloco (parágrafos e tabelas) e cloná-los para criar cópias idênticas. Se os nós do marcador passados forem de nível de bloco, o método poderá simplesmente copiar o conteúdo nesse nível e adicioná-lo à matriz.
No entanto, se os nós do marcador forem inline (um filho de um parágrafo), a situação torna-se mais complexa, pois é necessário dividir o parágrafo no nó inline, seja uma execução, campos de marcadores, etc. O conteúdo nos nós pai clonados não presentes entre os marcadores é removido. Esse processo é usado para garantir que os nós embutidos ainda mantenham a formatação do parágrafo pai.
O método também executará verificações nos nós passados como parâmetros e lançará uma exceção se um dos Nós for inválido. Os parâmetros a serem passados para este método são:
StartNode e EndNode. Os dois primeiros parâmetros são os nós que definem onde a extração do conteúdo deve começar e terminar, respectivamente. Esses nós podem ser de nível de bloco (Paragraph, Table) ou nível embutido (por exemplo Run, FieldStart, BookmarkStart etc.):
IsInclusive. Define se os marcadores estão incluídos na extração ou não. Se esta opção for definida como false e o mesmo nó ou nós consecutivos forem passados, uma lista vazia será retornada:
A implementação do método ExtractContent você pode encontrar aqui. Este método será referido nos cenários do presente artigo.
Também definiremos um método personalizado para gerar facilmente um documento a partir de nós extraídos. Este método é usado em muitos dos cenários abaixo e simplesmente cria um novo documento e importa o conteúdo extraído para ele.
O exemplo de código a seguir mostra como pegar uma lista de nós e inseri-los em um novo documento:
Isso demonstra como usar o método acima para extrair conteúdo entre parágrafos específicos. Neste caso, queremos extrair o corpo da carta encontrada na primeira metade do documento. Podemos dizer que isso está entre os parágrafos 7 e 11.
O código abaixo cumpre esta tarefa. Os parágrafos apropriados são extraídos usando o método getChild no documento e passando os índices especificados. Em seguida, passamos esses nós para o método ExtractContent e declaramos que eles devem ser incluídos na extração. Este método devolverá o conteúdo copiado entre estes nós que são então inseridos num novo documento.
O exemplo de código a seguir mostra como extrair o conteúdo entre parágrafos específicos usando o método ExtractContent acima:
O documento de saída contém os dois parágrafos que foram extraídos.
Podemos extrair conteúdo entre quaisquer combinações de nós em nível de bloco ou inline. Neste cenário a seguir, extrairemos o conteúdo entre o primeiro parágrafo e a tabela na segunda seção, inclusive. Obtemos os nós marcadores chamando o método getFirstParagraph e getChild na segunda seção do documento para recuperar os nós Paragraph e Table apropriados. Para uma ligeira variação, vamos duplicar o conteúdo e inseri-lo abaixo do original.
O exemplo de código a seguir mostra como extrair o conteúdo entre um parágrafo e uma tabela usando o método ExtractContent:
O conteúdo entre o parágrafo e a tabela foi duplicado abaixo é o resultado.
Pode ser necessário extrair o conteúdo entre parágrafos do mesmo estilo ou de um estilo diferente, como entre parágrafos marcados com estilos de título.
O código abaixo mostra como conseguir isso. É um exemplo simples que extrairá o conteúdo entre a Primeira Instância dos estilos “Heading 1” e “cabeçalho 3” sem extrair os títulos também. Para fazer isso, definimos o último parâmetro como false, que especifica que os nós do marcador não devem ser incluídos.
Em uma implementação adequada, isso deve ser executado em um loop para extrair o conteúdo entre todos os parágrafos desses estilos do documento. O conteúdo extraído é copiado para um novo documento.
O exemplo de código a seguir mostra como extrair conteúdo entre parágrafos com estilos específicos usando o método ExtractContent:
Abaixo está o resultado da operação anterior.

Você também pode extrair conteúdo entre nós embutidos, como a Run. Runs de diferentes parágrafos podem ser passados como marcadores. O código abaixo mostra como extrair texto específico entre o mesmo nó Paragraph.
O exemplo de código a seguir mostra como extrair conteúdo entre execuções específicas do mesmo parágrafo usando o método ExtractContent:
O texto extraído é apresentado na consola.
Para usar um campo como marcador, o nó FieldStart deve ser passado. O último parâmetro do método ExtractContent definirá se o campo inteiro deve ser incluído ou não. Vamos extrair o conteúdo entre o campo de mesclagem" FullName " e um parágrafo no documento. Usamos o método moveToMergeField da classe DocumentBuilder. Isso retornará o nó FieldStart do nome do campo de mesclagem passado para ele.
No nosso caso, vamos definir o último parâmetro passado para o método ExtractContent como false para excluir o campo da extração. Vamos renderizar o conteúdo extraído para PDF.
O exemplo de código a seguir mostra como extrair conteúdo entre um campo específico e um parágrafo no documento usando o método ExtractContent:
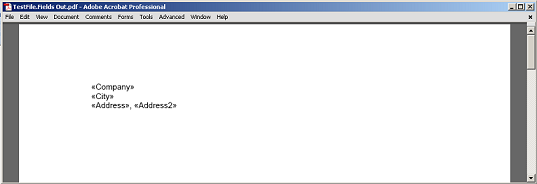
O conteúdo extraído entre o campo e o parágrafo, sem os nós do campo e do marcador de parágrafo renderizados para PDF.
Em um documento, o conteúdo definido em um marcador é encapsulado pelos nós BookmarkStart e BookmarkEnd. O conteúdo encontrado entre estes dois nós constitui o marcador. Você pode passar qualquer um desses nós como qualquer marcador, mesmo aqueles de marcadores diferentes, desde que o marcador inicial apareça antes do marcador final no documento.
No nosso documento de exemplo, temos um marcador, denominado “Bookmark1”. O conteúdo deste marcador é o conteúdo destacado no nosso documento:
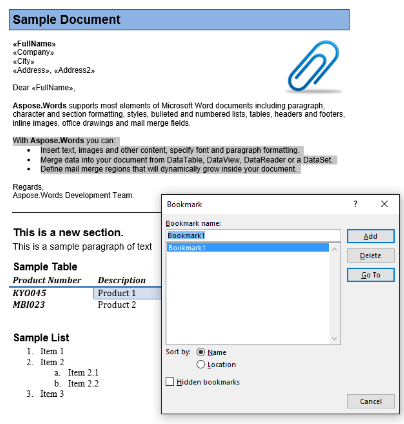
Vamos extrair este conteúdo para um novo documento usando o código abaixo. A opção de parâmetro IsInclusive mostra como reter ou descartar o marcador.
O exemplo de código a seguir mostra como extrair o conteúdo referenciado a um marcador usando o método ExtractContent:
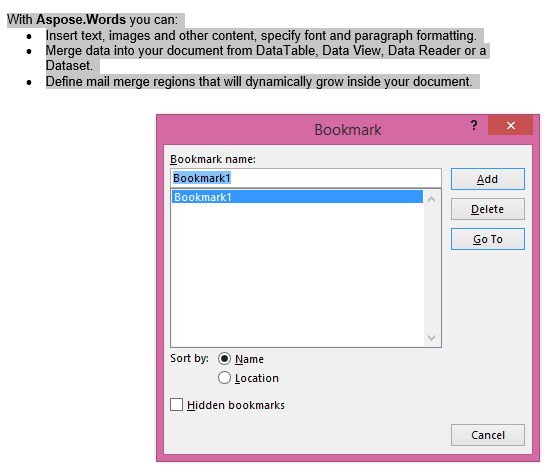
A saída extraída com o parâmetro IsInclusive definido como true. A cópia também manterá o marcador.
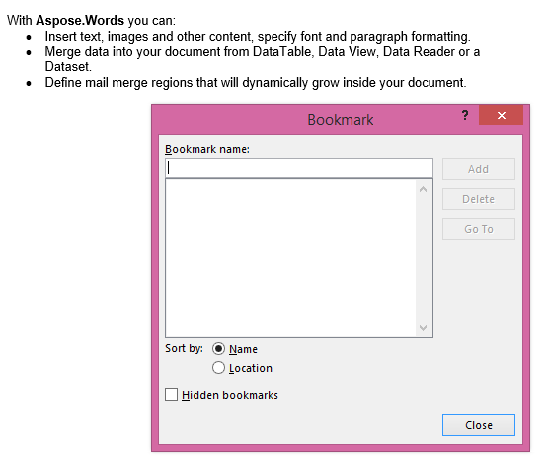
A saída extraída com o parâmetro IsInclusive definido como false. A cópia contém o conteúdo, mas sem o marcador.
Um comentário é composto pelos nós CommentRangeStart, CommentRangeEnd e Comment. Todos esses nós são inline. Os dois primeiros nós encapsulam o conteúdo do documento que é referenciado pelo comentário, como pode ser visto na imagem abaixo.
O nó Comment em si é um InlineStory que pode conter parágrafos e execuções. Representa a mensagem do comentário como visto como uma bolha de comentário no painel de revisão. Como este nó é embutido e descendente de um corpo, você também pode extrair o conteúdo de dentro desta mensagem.
No nosso documento temos um comentário. Vamos exibi-lo mostrando a marcação na guia Revisão:
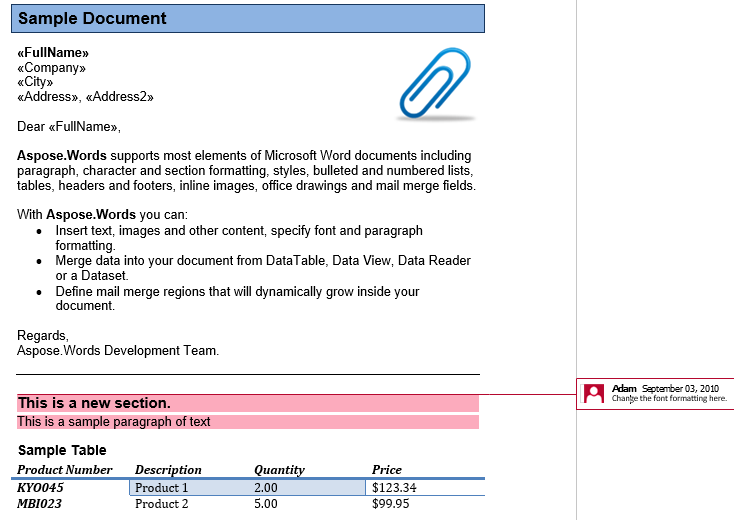
O comentário contém o título, o primeiro parágrafo e o quadro da segunda secção. Vamos extrair este comentário para um novo documento. A opção IsInclusive determina se o comentário em si é mantido ou descartado.
O exemplo de código a seguir mostra como fazer isso abaixo:
Em primeiro lugar, a saída extraída com o parâmetro IsInclusive definido como true. A cópia também conterá o comentário.
Em segundo lugar, a saída extraída com isInclusive definida como false. A cópia contém o conteúdo, mas sem o comentário.

Aspose.Words pode ser usado não apenas para criar Microsoft Word documentos, construindo-os dinamicamente ou mesclando modelos com dados, mas também para analisar documentos para extrair elementos de documentos separados, como cabeçalhos, rodapés, parágrafos, tabelas, imagens e outros. Outra tarefa possível é encontrar todo o texto de formatação ou estilo específico.
Use a classe DocumentVisitor para implementar esse cenário de uso. Esta classe corresponde ao conhecido padrão de design do visitante. Com DocumentVisitor, é possível definir e executar operações personalizadas que requerem enumeração sobre a árvore de documentos.
DocumentVisitor fornece um conjunto de VisitXXX métodos que são invocados quando um elemento de documento específico (nó) é encontrado. Por exemplo, VisitParagraphStart é chamado quando o início de um parágrafo de texto é encontrado e VisitParagraphEnd é chamado quando o final de um parágrafo de texto é encontrado. Cada método DocumentVisitor.VisitXXX aceita o objeto correspondente que encontra para que você possa usá-lo conforme necessário (digamos, recuperar a formatação), por exemplo, VisitParagraphStart e VisitParagraphEnd aceitam um objeto Paragraph.
Cada método DocumentVisitor.VisitXXX retorna um valor VisitorAction que controla a enumeração de nós. Você pode solicitar a continuação da enumeração, ignorar o nó atual (mas continuar a enumeração) ou interromper a enumeração de nós.
Estas são as etapas que você deve seguir para determinar e extrair programaticamente várias partes de um documento:
DocumentVisitor fornece implementações padrão para todos os métodos DocumentVisitor.VisitXXX. Isso facilita a criação de novos visitantes de documentos, pois apenas os métodos necessários para o visitante específico precisam ser substituídos. Não é necessário substituir todos os métodos do visitante.
O exemplo a seguir mostra como usar o padrão de Visitante para adicionar novas operações ao modelo de objeto Aspose.Words. Neste caso, criamos um conversor de documentos simples em formato de texto:
As formas de recuperar texto do documento são:
SaveFormat.Text. Internamente, isso invoca Salvar como texto em um fluxo de memória e retorna a string resultanteNode.GetText e Node.ToStringUm documento do Word pode conter caracteres de controlo que designam elementos especiais, tais como campo, fim da célula, fim da secção, etc. A lista completa dos possíveis caracteres de controlo de palavras é definida na classe ControlChar. O método GetText retorna texto com todos os caracteres de caracteres de controle presentes no nó.
Chamar ToString retorna a representação de texto simples do documento apenas sem caracteres de controle. Para mais informações sobre a exportação em texto simples, Ver Using SaveFormat.Text.
O exemplo de código a seguir mostra a diferença entre chamar os métodos GetText e ToString em um nó:
SaveFormat.TextEste exemplo guarda o documento da seguinte forma:
O exemplo de código a seguir mostra como salvar um documento no formato TXT:
Pode ser necessário extrair imagens de documentos para executar algumas tarefas. Aspose.Words permite que você faça isso também.
O exemplo de código a seguir mostra como extrair imagens de um documento:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.