Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.
เมื่อทำงานกับเอกสารมันเป็นสิ่งสำคัญที่จะสามารถแยกเนื้อหาจากช่วงเฉพาะภายในเอก อย่างไรก็ตามเนื้อหาอาจประกอบด้วยองค์ประกอบที่ซับซ้อนเช่นย่อหน้าตารางรูปภาพฯลฯ.
โดยไม่คำนึงถึงสิ่งที่เนื้อหาจะต้องถูกแยกเมธอดในการแยกเนื้อหานั้นจะถูกกำหนดโดยที่โห เหล่านี้สามารถเป็นเนื้อหาข้อความทั้งหมดหรือข้อความที่เรียบง่ายทำงาน.
มีหลายสถานการณ์ที่เป็นไปได้และดังนั้นจึงมีหลายชนิดโหนดที่แตกต่างกันที่จะต้องพิจารณา ตัวอย่างเช่นคุณอาจต้องการแยกเนื้อหาระหว่าง:
ในบางสถานการณ์คุณอาจจำเป็นต้องรวมชนิดโหนดต่างๆเช่นการแยกเนื้อหาระหว่างย่อหน้า.
บทความนี้จัดเตรียมการติดตั้งโค้ดสำหรับการแยกข้อความระหว่างโหนดต่างๆรวมทั้งตัวอย่.
บ่อยครั้งที่เป้าหมายของการแยกเนื้อหาคือการทำซ้ำหรือบันทึกแยกต่างหากในเอกสารให ตัวอย่างเช่นคุณสามารถแยกเนื้อหาและ:
นี้สามารถทำได้ง่ายโดยใช้Aspose.Wordsและการดำเนินการรหัสด้านล่าง.
รหัสในส่วนนี้อยู่ทั้งหมดของสถานการณ์ที่เป็นไปได้ที่อธิบายไว้ข้างต้นด้วยวิธีการทั่วไปและ โครงร่างทั่วไปของเทคนิคนี้เกี่ยวข้องกับ:
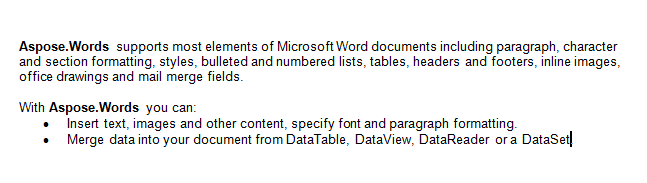
เราจะทำงานกับเอกสารด้านล่างในบทความนี้ ที่คุณสามารถเห็นมันมีความหลากหลายของเนื้อหา นอกจากนี้หมายเหตุเอกสารประกอบด้วยส่วนที่สองเริ่มต้นตรงกลางของหน้าแรก บุ๊กมาร์กและข้อคิดเห็นมีอยู่ในเอกสารด้วยแต่ไม่สามารถมองเห็นได้ในภาพหน้าจอด้านล่าง.

ในการดึงเนื้อหาจากเอกสารของคุณคุณต้องเรียกวิธีการExtractContentด้านล่างและส่งผ่านพารามิเตอร์ที่เหมาะสม.
พื้นฐานพื้นฐานของวิธีนี้เกี่ยวข้องกับการค้นหาโหนดระดับบล็อก(ย่อหน้าและตาราง)และโคลน ถ้าโหนดเครื่องหมายผ่านเป็นระดับบล็อกแล้ววิธีการที่จะสามารถที่จะเพียงแค่คัดลอกเนื้อ.
แต่ถ้าโหนดเครื่องหมายเป็นแบบอินไลน์(ลูกของย่อหน้า)แล้วสถานการณ์จะซับซ้อนมากขึ้นเนื่ เนื้อหาในโหนดพาเรนต์ที่โคลนไม่อยู่ระหว่างเครื่องหมายจะถูกลบออก โพรเซสนี้ถูกใช้เพื่อให้แน่ใจว่าโหนดอินไลน์จะยังคงเก็บการจัดรูปแบบของย่อหน้าพาเรนต์.
เมธอดจะรันการตรวจสอบบนโหนดที่ผ่านเป็นพารามิเตอร์และโยนข้อยกเว้นถ้าโหนดใดไม่ พารามิเตอร์ที่จะส่งผ่านไปยังวิธีนี้คือ:
StartNodeและEndNode สองพารามิเตอร์แรกคือโหนดที่กำหนดที่การสกัดของเนื้อหาคือการเริ่มต้นและสิ้นสุดตามลำ โหนดเหล่านี้สามารถเป็นได้ทั้งระดับบล็อก(Paragraph,Table)หรือระดับอินไลน์(เช่นRun, FieldStart, BookmarkStart ฯลฯ):
IsInclusive. กำหนดว่าเครื่องหมายจะรวมอยู่ในการสกัดหรือไม่ นูป๊อปอัปที่จะให้เลือกความช่วยเหลือหากต้องการทดสอบให้คลิกเมาส์ปุ่มขวาบนที่ใดๆของข้:
การดำเนินการของExtractContentวิธีที่คุณสามารถหา ที่นี่. วิธีการนี้จะถูกอ้างถึงในสถานการณ์ในบทความนี้.
นอกจากนี้เรายังจะกำหนดวิธีการที่กำหนดเองเพื่อให้ง่ายต่อการสร้างเอกสารจากโหนด วิธีนี้ถูกใช้ในหลายสถานการณ์ด้านล่างและเพียงแค่สร้างเอกสารใหม่และนำเข้าเนื้อหาที่.
ตัวอย่างรหัสต่อไปนี้แสดงวิธีใช้รายการของโหนดและแทรกลงในเอกสารใหม่:
นี้แสดงให้เห็นถึงวิธีการใช้วิธีการข้างต้นเพื่อดึงเนื้อหาระหว่างย่อหน้าที่ ในกรณีนี้เราต้องการที่จะดึงร่างกายของตัวอักษรที่พบในช่วงครึ่งแรกของเอกสาร เราสามารถบอกได้ว่านี่คือระหว่าง 7 และ 11 ย่อหน้า.
รหัสด้านล่างทำงานนี้สำเร็จ ย่อหน้าที่เหมาะสมจะถูกแยกออกโดยใช้วิธีการgetChildบนเอกสารและส่งผ่านดัชนีที่ระบุ จากนั้นเราจะส่งผ่านโหนดเหล่านี้ไปยังExtractContentวิธีการและรัฐที่เหล่านี้จะรวมอยู่ในการสกัด. เมธอดนี้จะส่งคืนเนื้อหาที่คัดลอกระหว่างโหนดเหล่านี้ซึ่งถูกแทรกลงในเอกสารใหม่.
ตัวอย่างรหัสต่อไปนี้แสดงวิธีการแยกเนื้อหาระหว่างย่อหน้าที่โดยใช้วิธีการExtractContentด้านบน:
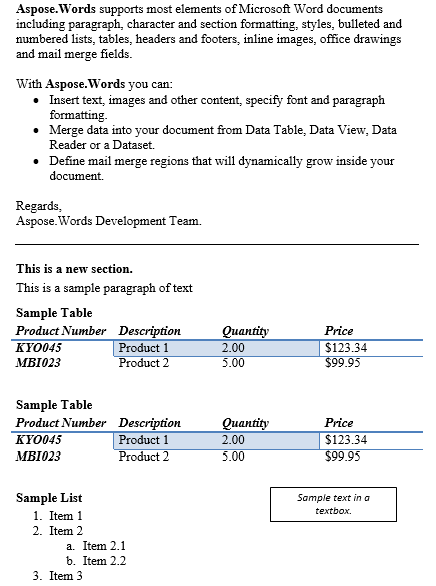
เอกสารผลลัพธ์ประกอบด้วยสองย่อหน้าที่ถูกแยกออก.
เราสามารถแยกเนื้อหาระหว่างชุดใดๆของโหนดระดับบล็อกหรือแบบอินไลน์ ในสถานการณ์สมมตินี้ด้านล่างเราจะแยกเนื้อหาระหว่างย่อหน้าแรกและตารางในส่วนที่ส เราได้รับโหนดเครื่องหมายโดยการเรียกgetFirstParagraphและgetChildวิธีการในส่วนที่สองของเอกสารที่จะดึงที่เหมาะสมParagraphและTableโหนด สำหรับรูปแบบเล็กน้อยให้แทนซ้ำเนื้อหาและแทรกไว้ด้านล่างเดิม.
ตัวอย่างรหัสต่อไปนี้แสดงวิธีการแยกเนื้อหาระหว่างย่อหน้าและตารางโดยใช้วิธีการExtractContent:
เนื้อหาระหว่างย่อหน้าและตารางได้รับการทำซ้ำด้านล่างเป็นผล.
คุณอาจต้องแยกเนื้อหาระหว่างย่อหน้าของสไตล์เดียวกันหรือแตกต่างกันเช่นระหว่างย่อห.
นล่างแสดงให้เห็นถึงวิธีการเพื่อให้บรรลุนี้. มันเป็นตัวอย่างง่ายๆที่จะดึงเนื้อหาระหว่างตัวอย่างแรกของ"Heading 1"และ"ส่วนหัว 3"รูปแบบโดยไม่ต้องแยกส่วนหัวเช่นกัน การทำเช่นนี้เราตั้งค่าพารามิเตอร์ที่ผ่านมาเป็นเท็จซึ่งระบุว่าโหนดเครื่องหมายไม่ควรรว.
ในการใช้งานที่เหมาะสมนี้ควรจะรันในวงเพื่อแยกเนื้อหาระหว่างย่อหน้าทั้งหมดของลักษณ เนื้อหาที่แยกจะถูกคัดลอกลงในเอกสารใหม่.
ตัวอย่างรหัสต่อไปนี้แสดงวิธีการแยกเนื้อหาระหว่างย่อหน้าที่มีลักษณะเฉพาะโดยใช้วิธีการExtractContent:
ด้านล่างเป็นผลมาจากการดำเนินการก่อนหน้านี้.

คุณสามารถแยกเนื้อหาระหว่างโหนดอินไลน์เช่นRunได้เป็นอย่างดี Runsจากย่อหน้าต่างๆสามารถส่งผ่านเป็นเครื่องหมาย รหัสด้านล่างแสดงวิธีการแยกข้อความเฉพาะในระหว่างโหนดParagraphเดียวกัน.
ตัวอย่างโค้ดต่อไปนี้แสดงวิธีแยกเนื้อหาระหว่างการทำงานเฉพาะของย่อหน้าเดียวกันโดยใช้เมธอด ExtractContent:
ข้อความที่แยกจะแสดงบนคอนโซล
เมื่อต้องการใช้ฟิลด์เป็นเครื่องหมายโหนดFieldStartควรส่งผ่าน พารามิเตอร์สุดท้ายของวิธีการExtractContentจะกำหนดว่าฟิลด์ทั้งหมดจะรวมหรือไม่ ลองดึงเนื้อหาระหว่างฟิลด์"FullName"ผสานและย่อหน้าในเอกสาร เราใช้วิธีการmoveToMergeFieldของDocumentBuilderชั้น นี้จะส่งคืนโหนดFieldStartจากชื่อของฟิลด์ผสานที่ส่งผ่านไปยังโหนดนั้น.
ในกรณีของเราให้ตั้งค่าพารามิเตอร์ที่ผ่านมาผ่านไปExtractContentวิธีการที่จะเป็นเท็จที่จะไม่รวมสนาม เราจะแสดงเนื้อหาที่สกัดเป็นPDF.
ตัวอย่างรหัสต่อไปนี้แสดงวิธีการแยกเนื้อหาระหว่างฟิลด์ที่เฉพาะเจาะจงและย่อหน้าในเอกสารโดยใช้วิธีการExtractContent:
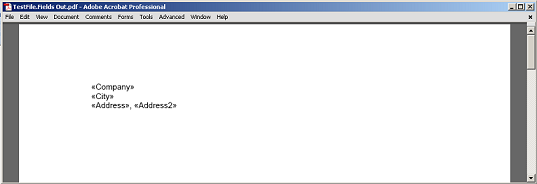
เนื้อหาที่แยกระหว่างฟิลด์และย่อหน้าโดยไม่มีโหนดเครื่องหมายฟิลด์และย่อหน้าแสดงผลเป็นPDF.
ในเอกสารเนื้อหาที่กำหนดภายในบุ๊กมาร์กถูกห่อหุ้มโดยโหนดBookmarkStartและBookmarkEnd เนื้อหาที่พบระหว่างทั้งสองโหนดทำขึ้นที่คั่นหน้าเว็บ คุณสามารถส่งผ่านโหนดใดๆเหล่านี้เป็นเครื่องหมายใดๆแม้แต่คนจากบุ๊กมาร์กที่แตกต่างกันต.
ในเอกสารตัวอย่างของเราเรามีบุ๊คมาร์คหนึ่งชื่อ"บุ๊คมาร์ค 1" เนื้อหาของบุ๊กมาร์กนี้จะถูกเน้นเนื้อหาในเอกสารของเรา:
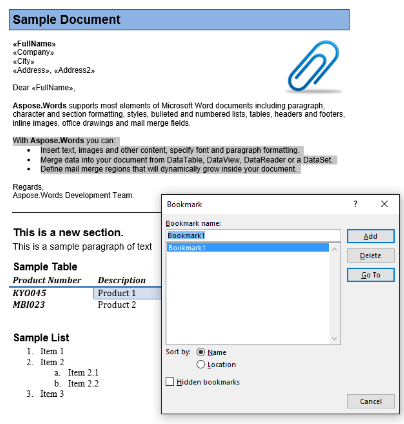
เราจะดึงเนื้อหานี้ลงในเอกสารใหม่โดยใช้รหัสด้านล่าง ตัวเลือกพารามิเตอร์IsInclusiveจะแสดงวิธีเก็บรักษาหรือยกเลิกบุ๊กมาร์ก.
ตัวอย่างรหัสต่อไปนี้แสดงวิธีการแยกเนื้อหาที่อ้างอิงบุ๊กมาร์กโดยใช้วิธีการExtractContent:
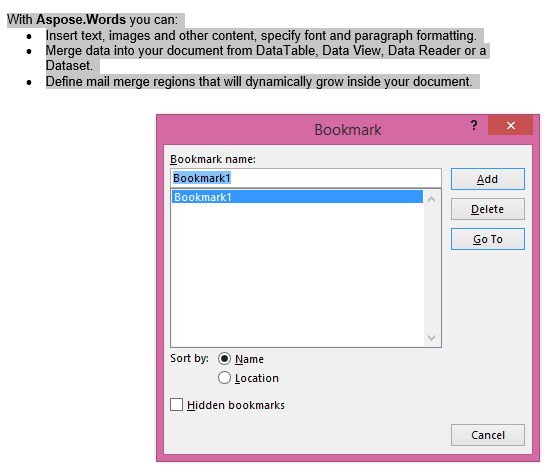
เอาต์พุตที่แยกกับพารามิเตอร์IsInclusiveตั้งค่าเป็นจริง สำเนาจะเก็บบุ๊กมาร์กไว้เช่นกัน.
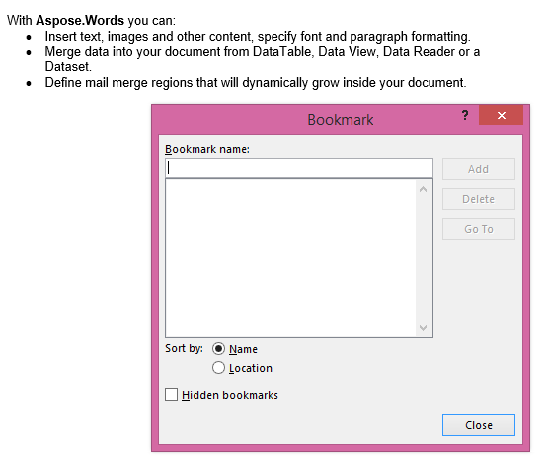
เอาต์พุตที่แยกกับพารามิเตอร์IsInclusiveตั้งค่าเป็นเท็จ สำเนาประกอบด้วยเนื้อหาแต่ไม่มีบุ๊กมาร์ก.
ความคิดเห็นถูกสร้างขึ้นจากCommentRangeStart,CommentRangeEndและโหนดความคิดเห็น ทั้งหมดของโหนดเหล่านี้เป็นแบบอินไลน์ สองโหนดแรกแคปซูลเนื้อหาในเอกสารที่มีการอ้างอิงโดยความคิดเห็น,เท่าที่เห็นในภาพหน้าจอด้านล่าง.
โหนดCommentตัวเองเป็นInlineStoryที่สามารถประกอบด้วยย่อหน้าและรัน มันหมายถึงข้อความของความคิดเห็นที่เห็นเป็นฟองความคิดเห็นในบานหน้าต่างการตรวจ เป็นโหนดนี้เป็นแบบอินไลน์และลูกหลานของร่างกายคุณยังสามารถดึงเนื้อหาจากภายในข้.
ในเอกสารของเราเรามีหนึ่งความคิดเห็น ลองแสดงโดยการแสดงมาร์กอัปในแท็บรีวิว:
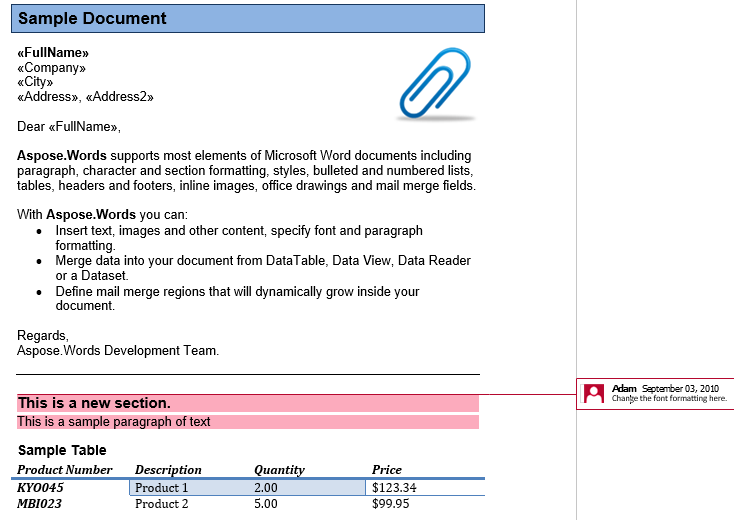
ความคิดเห็นที่ห่อหุ้มหัวข้อ,ย่อหน้าแรกและตารางในส่วนที่สอง. ลองดึงความคิดเห็นนี้ลงในเอกสารใหม่ อ็อพชันIsInclusiveจะบอกถ้าความคิดเห็นถูกเก็บไว้หรือถูกยกเลิก.
ตัวอย่างรหัสต่อไปนี้แสดงวิธีการทำเช่นนี้อยู่ด้านล่าง:
ประการแรกผลลัพธ์ที่สกัดด้วยพารามิเตอร์IsInclusiveตั้งเป็นจริง สำเนาจะมีความคิดเห็นเช่นกัน.
ประการที่สองเอาต์พุตสกัดด้วยisInclusiveตั้งเป็นเท็จ สำเนาประกอบด้วยเนื้อหาแต่ไม่มีความคิดเห็น.

Aspose.Wordsสามารถใช้ได้ไม่เพียงแต่สำหรับการสร้างเอกสารMicrosoft Wordโดยการสร้างเอกสารแบบไดนามิกหรื อีกงานที่เป็นไปได้คือการหาข้อความทั้งหมดของการจัดรูปแบบที่เฉพาะเจาะจงหรือรูปแบ.
ใช้คลาสDocumentVisitorเพื่อใช้สถานการณ์การใช้งานนี้ ชั้นนี้สอดคล้องกับรูปแบบการออกแบบของผู้เข้าชมที่รู้จักกันดี ด้วยDocumentVisitorคุณสามารถกำหนดและดำเนินการการดำเนินงานแบบกำหนดเองที่ต้องการการแจง.
DocumentVisitorให้ชุดของVisitXXXเมธอดที่ถูกเรียกใช้เมื่อพบองค์ประกอบของเอกสาร(โหนด)โดยเฉพาะอย่างยิ่ง ตัวอย่างเช่นVisitParagraphStartถูกเรียกเมื่อพบจุดเริ่มต้นของย่อหน้าข้อความและVisitParagraphEndถูกเรียกเมื่อพบจุดสิ้นสุดของย่อหน้าข้อความ แต่ละวิธีDocumentVisitor.VisitXXXจะยอมรับวัตถุที่สอดคล้องกันซึ่งพบเพื่อให้คุณสามารถใช้ได้ตามต้องการ(พูดเรียกการจัดรูปแบบ)เช่นทั้งVisitParagraphStartและVisitParagraphEndacceptวัตถุParagraph.
แต่ละเมธอดDocumentVisitor.VisitXXXจะส่งคืนค่าVisitorActionที่ควบคุมการแจงนับของโหนด คุณสามารถร้องขออย่างใดอย่างหนึ่งเพื่อดำเนินการต่อการนับข้ามโหนดปัจจุบัน(แต่ยังคง.
เหล่านี้เป็นขั้นตอนที่คุณควรปฏิบัติตามเพื่อตรวจสอบและแยกส่วนต่างๆของเอกสาร:
DocumentVisitorจัดเตรียมการติดตั้งดีฟอลต์สำหรับเมธอดDocumentVisitor.VisitXXXทั้งหมด นี้ทำให้ง่ายต่อการสร้างผู้เข้าชมเอกสารใหม่เป็นเพียงวิธีการที่จำเป็นสำหรับผู้เข้าชมเฉ ไม่จำเป็นต้องแทนที่ทั้งหมดของวิธีการเข้าชม.
ตัวอย่างต่อไปนี้แสดงวิธีการใช้รูปแบบผู้เยี่ยมชมเพื่อเพิ่มการดำเนินงานใหม่กับรุ่นออบเจกต์Aspose.Words ในกรณีนี้เราสร้างแปลงเอกสารที่เรียบง่ายในรูปแบบข้อความ:
วิธีการดึงข้อความจากเอกสารมีดังนี้:
SaveFormat.Text ภายในนี้เรียกบันทึกเป็นข้อความลงในกระแสหน่วยความจำและส่งกลับสตริงผลลัพธ์Node.GetTextและNode.ToStringเอกสารคำสามารถประกอบด้วยอักขระควบคุมที่กำหนดองค์ประกอบพิเศษเช่นฟิลด์สิ้นสุดข รายการอักขระตัวควบคุมคำที่เป็นไปได้ทั้งหมดจะถูกกำหนดในคลาสของControlChar เมธอดGetTextจะส่งคืนข้อความที่มีอักขระตัวควบคุมทั้งหมดที่อยู่ในโหนด.
การโทรToStringจะส่งคืนการแสดงข้อความธรรมดาของเอกสารโดยไม่มีอักขระควบคุมเท่านั้น สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการส่งออกเป็นข้อความธรรมดาโปรดดูที่Using SaveFormat.Text.
ตัวอย่างรหัสต่อไปนี้แสดงความแตกต่างระหว่างการโทรGetTextและToStringเมธอดบนโหนด:
SaveFormat.Textตัวอย่างนี้บันทึกเอกสารดังนี้:
ตัวอย่างรหัสต่อไปนี้แสดงวิธีการบันทึกเอกสารในรูปแบบTXT:
คุณอาจต้องดึงรูปภาพเอกสารเพื่อดำเนินการบางอย่าง Aspose.Wordsช่วยให้คุณสามารถทำเช่นนี้ได้เช่นกัน.
ตัวอย่างรหัสต่อไปนี้แสดงวิธีการแยกภาพจากเอกสาร:
Analyzing your prompt, please hold on...
An error occurred while retrieving the results. Please refresh the page and try again.